
ES+Pandas實現文檔中數據提取
2021-11-03 09:23:52卡斯柯信號有限公司劉艷青王婷婷
電子世界 2021年18期
關鍵詞:報告
卡斯柯信號有限公司 劉艷青 王婷婷
眾所周知,典型的軟件生命周期模型包括:迭代模型、快速原型模型、V模型、W模型。每個模型中都必然包含的幾部分:需求、用例、報告。需求的作用往往是決定了軟件功能的走向,用例是根據需求描述設計出來并對軟件功能進行測試的參考依據,報告往往是決定軟件是否能夠發布的重要參考要素。報告中一般要羅列出需求、用例的最終狀態,遺留的問題以及需求、用例的測試通過率等等。需求和用例在邏輯上存在N對N的關系,部分公司使用線上系統,將需求和用例條目化管理,這樣就能很好的根據用例狀態提取需求的狀態,但是也有大部分公司使用word文檔管理需求和用例,這種情況將耗費大量的人力在測試報告的編寫上。
1 現狀
對于小型的軟件而言,可能只有1份需求、1份用例,對于這種軟件而言,編寫報告的難度并不大,也可以人工完成。但是如果是一個大型的系統,例如1個系統包含5個子系統,每個子系統中又包含多個軟件,那么這個項目的文檔工作將是巨大的,尤其是測試完成后報告的數據收集將是一個非常耗時的過程,以我們公司的產品為例,新系統報告編寫的時間一般是在2周左右。進一步分析會發現,大部分的時間是用在需求狀態的收集上。主要原因是最上層的大系統無法精準的測試一些功能,因此需要子系統或者軟件級完成測試,或者需要多個子系統共同完成測試,因此這部分需求會直接分配給其它階段。但是系統級的報告中又需要收集這些需求的狀態及證據,這個收集的工作會涉及到不同的部門不同的人員,因此整個工作特別耗時,如何能夠提高這項工作的效率呢?首先需要了解人工收集這些狀態需要參考的文檔,然后根據人工查找的邏輯,將整個工作程序化。用工具代替人力收集需求狀態。
2 嘗試使用ES+Pandas實現文檔中數據的收集
非關系型數據庫中ES因交互性好,支持全文檢索、倒排索引、對文檔內容的搜索速度快的特點,經常被用于實時日志分析。因此,對于使用word及excel管理需求、用例和報告的項目,ES可以更快的查詢到需求對應的用例及用例的執行結果。
首先,要將word及excel中需要的信息,條目化并存到ES數據庫中,這里建議使用正則表達式識別要存儲的內容,使用正則表達式的前提就是,需要提取的內容要滿足一定的格式要求,例如有明確的起始與結尾標識。一個標準的需求一定是要包含需求ID,需求內容,需求屬性標簽的,可以根據業務需求,通過正則表達式將后續要用到的信息全部提取出來,本文主要提取了需求ID、需求內容及需求來源。一個標準的用例一定是包含用例ID,用例描述,執行步驟,追蹤的需求等。本文主要是提取了用例ID,用例描述,追蹤的需求ID。對于每一個階段的測試,都有一個對應需求的分配情況,本文稱作VAT表格,這個表格中包含了需求ID,需求描述,需求屬性及分配階段,這里的分配階段都是由測試人員提前定義好的。最后需要的就是每個階段的用例執行結果,包括用例ID、用例描述、用例執行結果、備注等,本文主要提取了用例ID、用例描述、用例執行結果。ES數據庫索引結構如圖1,各文檔存儲規則如圖2。

圖1 ES索引結構
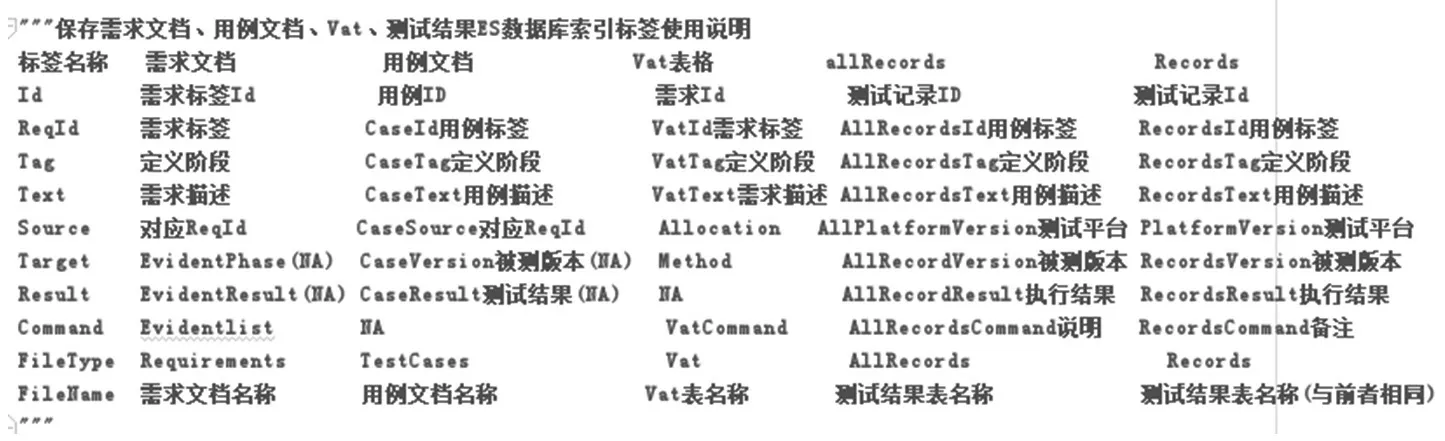
圖2 各字段使用情況說明
其次,需要總結整個測試數據生成的邏輯,以圖3中這個系統結構為例,大系統1對應的系統需求可能會分給到A、B、C、A1、A2、B1、B2任意一個階段。

圖3 樣例項目
如何能夠找到對應的需求狀態呢?通過整理分析,邏輯大概如下:
(1)分配給本階段的需求狀態:通過本階段用例的source屬性將用例和需求的關系找出來,每條需求理論上是對應了1~N個測試用例,收集這些用例的執行結果,如果所有用例均為通過,則認為需求通過,否則,認為需求不通過。這里需要將關聯到的所有用例ID及用例狀態、缺陷ID作為證據回填到需求的備注中。
(2)分配給子系統A、子系統B及軟件C的需求狀態:通過大系統1的需求與子系統A、子系統B或者軟件C的需求的關聯關系,找到對應的子系統需求或者軟件C的需求,再根據子系統需求或者軟件需求找到對應的用例ID,最后再查找用例結果。同樣需要將最終找到的用例ID及用例狀態、缺陷ID作為證據回填到需求的備注中。
(3)分配給軟件A1、軟件A2、軟件B1、硬件B2的需求狀態:與第二種情況類似,只是需要通過需求間的追蹤關系先找到A1、A2、B1、B2對應的需求,再找到對應的用例。同樣需要將最終找到的用例ID及用例狀態、缺陷ID作為證據回填到需求的備注中。
邏輯整理出來后,如何實現呢?我們發現,其實每個需求、每個用例、每個測試報告,都相當于一個關系型數據庫中的表,他們有自己的屬性,每個表之前還有些關聯關系,在ES的基礎上,如何能夠快速實現這樣的邏輯呢,這里我們想到了Pandas庫,這個庫一般用于數據分析,但是在我們這種場景下使用也是非常合適的。我們將每個類型的文檔存儲為一個DataFrame,可以通過DataFrame的merge方法實現表格的關聯,找到需求和用例之間的對應關系,需求和需求間的對應關系等。
用例與需求的對應關系:
pd.merge(Cases_Table,Requirements_Table,how=‘left’,left_on = ‘CaseSource’, right_on = ‘ReqId’)
其中Cases_Table是用例表格,Requirements_Table是需求表格,兩個表格使用左連接做關聯,左邊的Cases_Table使用CaseSource屬性,右邊的Requirements_Table使用ReqId屬性。作用就是,基于用例中CasesSource屬性找到對應的需求,然后將他們合并成一張新的表格,以此找到用例和需求的對應關系。
需求與需求的對應關系:
pd.merge(AllRequirements_Table,AllRequirements_Table,how =‘left’,left_on = ‘Source, right_on = ‘ReqId’)
其中,AllRequirements_Table是所有需求表格,兩個表格使用左連接做關聯,左邊的AllRequirements_Table使用Source屬性,右邊的AllRequirements_Table使用ReqId屬性。作用就是基于需求的source找到對應的需求,然后將他們合并成一張新的表格,以此找到需求和需求的對應關系。
總結:如果項目滿足如下幾個特點,則可以嘗試使用ES+Pandas實現報告的自動生成:(1)需求、用例、測試報告使用離線文檔存儲,文檔格式包括:word、excel、csv等;(2)需求、用例、報告可以提取出條目化信息,如每個需求、用例均有清晰的ID、描述及范圍;(3)人工通過現有文檔能夠編寫報告,但是編寫報告耗時較多。
猜你喜歡
新西部(2022年3期)2022-04-13 22:20:53
小哥白尼(趣味科學)(2020年7期)2020-05-22 06:48:38
童話世界(2018年25期)2018-10-10 08:14:52
浙江共產黨員(2017年11期)2017-11-15 09:22:06
南方人物周刊(2017年32期)2017-10-28 22:48:36
南風窗(2016年26期)2016-12-24 21:48:09
中國衛生(2016年8期)2016-11-12 13:27:10
南風窗(2015年22期)2015-09-10 07:22:44
南風窗(2015年14期)2015-09-10 07:22:44
南風窗(2015年7期)2015-04-03 01:21:48
