一種基于塊雅可比迭代的高階FR 格式隱式方法1)
2021-11-09 08:46:22于要杰
力學學報 2021年6期
關鍵詞:方法
于要杰 劉 鋒 高 超 馮 毅,2)
*(西北工業大學航空學院,西安 710072)
?(加州大學爾灣分校機械與航天工程系,美國加利福尼亞州 92697-3975)
**(成都流體動力創新中心,成都 610071)
引言
高階精度數值格式因其高分辨率、低色散和低耗散等特點正日益受到關注[1-2].相比目前工業界最常用的二階精度格式,高階精度格式被認為在花費相同計算代價的前提下具備獲得更高精度數值結果的巨大潛力.當前最常見的高階精度數值格式主要包括基于結構網格的高階有限差分方法[3-4]、非結構網格上的有限體積法[5-6]以及基于局部單元近似的間斷有限元(discontinuous Galerkin,DG)[7-8]、譜體積(spectral volume,SV)[9]和譜差分(spectral difference,SD)[10]等方法.
最近,一種基于非結構網格的高階精度通量重構格式(flux reconstruction,FR)因其構造簡單且更加通用而愈加流行.FR 格式最先于2007 年由Huynh[11-12]提出并證明了,至少對于一維線性方程,FR 格式通過不同修正多項式的選擇,不僅囊括了DG 和SD 這兩種格式,并且能夠產生新的高階格式.2009 年,Wang和Gao 等[13]提出“lifting collocation penalty,LCP”格式并將其推廣到歐拉方程和Navier-Stokes 方程.由于FR 和LCP 這兩種格式具有高度的相似性和內在聯系,因此后來也被Huynh 和王志堅[14]聯合命名為FR/CPR (correction procedure via reconstruction) 格式.2011 年,Vincent 等[15]提出了一種針對一維線性對流方程的能量穩定的FR 格式,即VCJH 格式,后續又在此格式的基礎上開發了三維并行CFD 求解器Hi-FiLES[16]和PyFR[17].如今,FR 已不僅是一種高階格式,它還為幾種現有的高階格式,例如SD 和DG,提供了一個統一的框架.相比DG 和SD 的原有形式,FR 在概念上更加簡單且計算效率更高[18].關于FR和DG 間的聯系,Allaneau 和Jameson[19]和De Grazia等[20]已經進行了深入研究.
盡管FR 格式已經取得了較大的進步,但將其應用于復雜外形流動的數值模擬時,仍然有一些難點問題需要解決,例如計算效率的問題、曲面邊界處理方法、間斷偵測方法與限制器的構造等.其中,計算效率的問題在很大程度上制約了FR 格式在實際工程中的應用.在當前的FR 格式應用中,時間離散多采用存儲需求小且易實現的顯式Runge-Kutta 類方法[21].但隨著格式精度的提高,FR 對應的CFL 穩定性條件越來越嚴格,時間推進步長會受到明顯的限制.對一些復雜流動問題(流場中存在邊界層、剪切層等小尺度流動結構)的計算更是如此.因此,發展FR 格式的加速收斂方法,具有十分重要的工程應用價值.目前常用的加速收斂方法在算法層面主要有隱式時間推進方法、當地時間步長、殘差光順、多重網格以及物理層面的并行計算技術等.在這些方法中,隱式時間推進方法的加速效果是十分明顯的[22].相比顯式時間方法,隱式方法受CFL 穩定性條件的約束小,可以選取更大的時間推進步長,進而能夠有效地提高CFD 求解的效率.近年來已有學者提出了多種基于FR 格式的隱式時間方法,例如LU-SGS 方法[23]、預處理GMERS 方法[24]、無矩陣(Jacobianfree) Newton Krylov 方法[25]以及多色高斯-賽德爾(multi-colored Gauss Seidel,MCGS) 方法[26]等.這些文章中以數值實驗證明,使用隱式方法的FR 格式相比顯式具有非常明顯的計算效率提升.以上這些隱式時間方法大都是在CPU 架構上實現,由于基于局部單元近似的FR 格式的絕大多數操作都是在局部單元中進行,計算量較為集中,因此更適合GPU 計算.當前,基于CPU 并行策略的有限體積求解器一般只能使用并行集群性能峰值的5%~10%,而使用GPU 計算的FR 格式計算速度最高可以達到性能峰值的58%左右[27].因此,基于GPU 并行的隱式時間推進方法有望進一步提高FR 格式的計算效率.
近年來,GPU 計算在CFD 領域中的應用已經越來越普遍.已有的研究結果表明[27-29],對于相同規模的問題,GPU 并行能夠較大程度地提升高階CFD 程序的計算效率.例如,Romero 等[30]利用顯式時間方法的VCJH 格式計算非定常流動問題,發現GPU 并行相比基于MPI 并行的CPU 節點具有更高的計算效率.Vermeire 等[31]使用PyFR 求解器在多個GPU 卡上以三維Taylor-Green 渦和SD7003 翼型為例進行隱式大渦模擬計算,發現與使用CPU 節點并行的商業CFD 軟件Star-CCM+相比,在計算成本相當的前提下,5 階FR 計算得到的模擬結果更精細.最近,Jourdan 和Wang 等[32]在美國“Summit”超級計算機上使用FR/CPR 高階求解器,分別利用了800 個節點的CPU 和4800 個GPU 卡進行了大渦模擬計算,發現使用顯式時間推進方法時,在六面體和四面體這兩種網格單元類型上,GPU 相比CPU 并行分別有一個和兩個量級左右的加速效果.
在上述的大規模CFD 數值模擬中,基于FR 格式的GPU 計算使用的都為顯式時間方法.為了探索如何進一步提高FR 格式的求解效率,本文以二維歐拉方程為例,提出一種基于高階FR 格式的單GPU并行隱式時間求解方法.通過塊Jacobi 迭代的方式,改變了經過隱式離散后全局線性方程組左端矩陣的特征,克服了影響求解并行性的相鄰單元依賴.最終,將解全局線性方程組轉化解一系列局部單元線性方程組,進而又通過LU 分解法并行求解這些局部線性方程組.數值實驗表明,相比顯式方法而言,該隱式方法在計算效率方面至少有一個量級的提升.并且,該隱式方法不局限于FR 格式,對DG 和SD 等基于局部單元近似的高階格式也具有參考意義.
1 控制方程
無黏流動的控制方程為歐拉方程,其二維形式如下
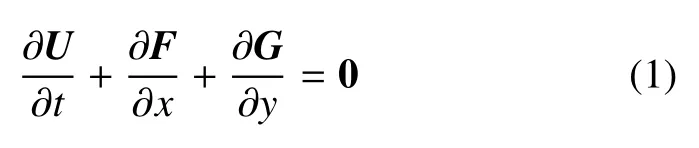
其中,U=[ρ,ρu,ρv,ρE]為守恒變量,F和G分別為x和y方向的無黏通量
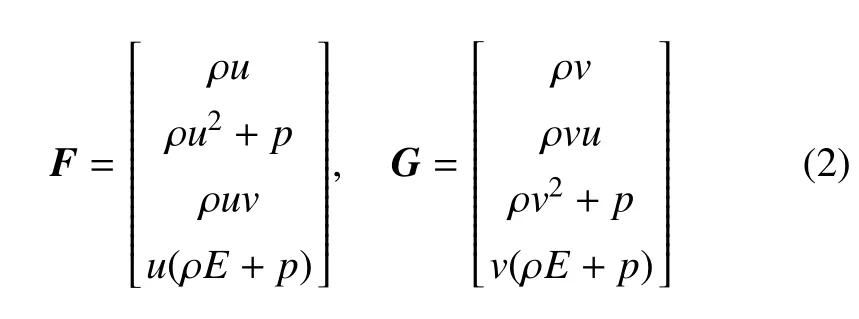
式中,ρ 是密度,u和v分別表示x和y方向的速度,p為壓強,E代表單位質量流體的總能量。本文中假設流體為理想氣體,則有
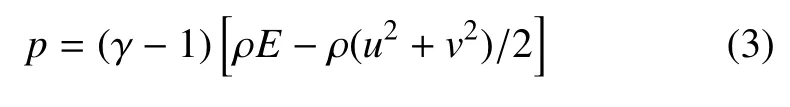
其中,γ=Cp/Cv為比熱容比,本文中其值為1.4.
2 高階通量重構格式
本節將以二維標量守恒律為例來簡要地介紹FR格式的基本思想.在區域Ω ∈R2上的一般形式的二維標量守恒律形式為
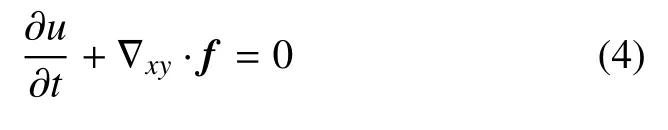
其中,u=u(x,y,t)為標量守恒量,f=(f,g)為通量項,f=f(u)和g=g(u)分別為f在x和y方向的分量.
下面將區域Ω 分割為N個互不重疊的四邊形子區域且子區域滿足如下條件

為了數學書寫的方便以及計算效率方面考慮,首先通過如圖1 所示的變換將物理域(x,y)上任意Ωn轉換到計算域(ξ,η)上的一個標準單元ΩS(為了敘述簡潔,下面將省略下標n).

圖1 將任意四邊形單元變換到一個標準單元Fig.1 Mapping of an arbitrary physical space quadrilateral element to the standard reference quadrilateral element
經過以上變換后,子區域Ωn上的方程(4) 變換為
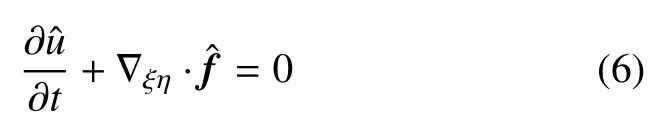
其中,頂標“?”代表其為計算域(ξ,η)上的變量,計算域(ξ,η)和物理域(x,y)上的變量存在如下關系
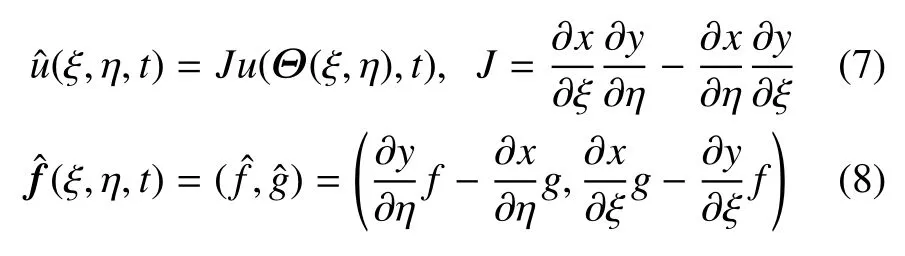

其中,右上標“δ”代表近似解,“D”表示是單元上的局部解,是求解點(ξi,ηj)處的近似解,li和lj是相對應的拉格朗日插值多項式.在單元內部是連續的,但在相鄰單元之間是間斷的.圖2 中給出了p=2 時在四邊形單元上求解點和后續用于通量修正的邊界面通量點的分布.
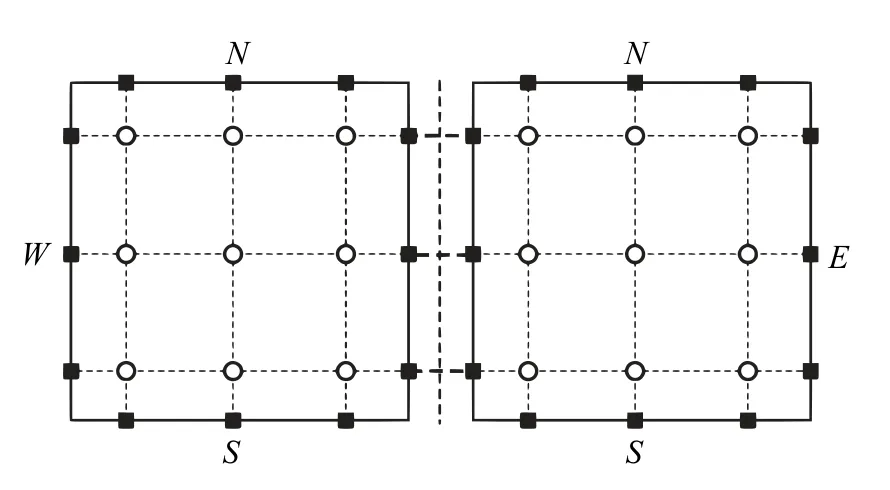
圖2 兩個四邊形單元上求解點(圓圈)和通量點(方塊)的分布(p=2)Fig.2 Arrangement of solution points(circles)and flux points(squares)on a pair of quadrilateral elements(p=2)
在計算散度項之前,首先進行通量項的構造和計算.參照方程(9) 中近似解的構造,同樣可以獲取局部通量.但由于僅在單元內部連續,而在單元之間并不連續.為了滿足格式守恒性的要求,FR 通過增加修正項的方式構造在單元界面處連續的通量.因此,連續的全局通量由單元內的局部通量和修正通量構成上式中,局部通量通過p階的插值多項式進行近似


綜上,經過FR 格式空間離散之后的半離散方程為
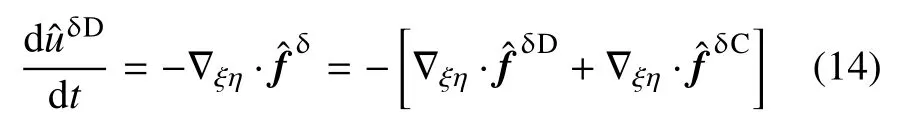
上述常微分方程組可進一步通過顯式或隱式的時間推進方法進行求解.
3 隱式時間推進方法
二維歐拉方程經過空間離散之后得到的半離散方程可進一步寫作如下形式

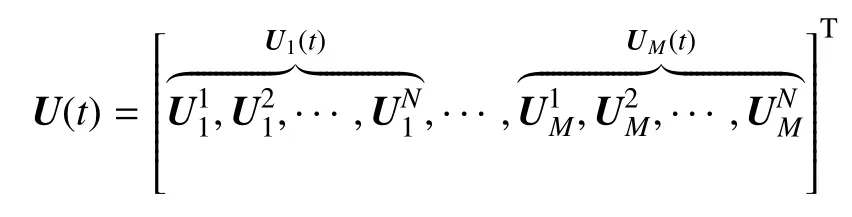
在上式中為M×N×4 維度的全局解向量,其中,M和N分別代表網格單元總數以及每個單元內求解點的個數,UM(t)為第M個單元上的局部解,是第M個單元第N個求解點上包含守恒變量的解向量.
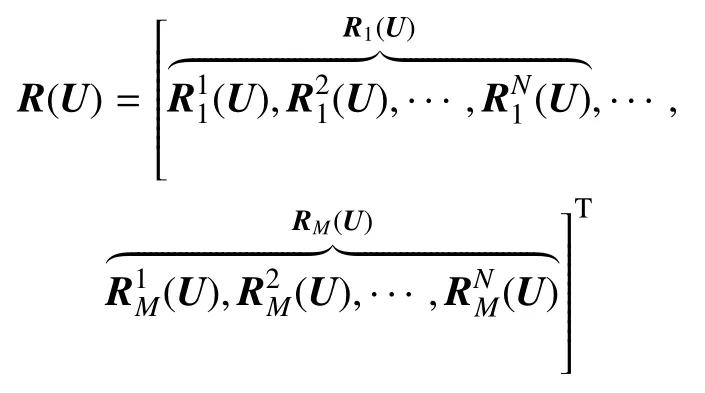
代表右端殘差項,RM(U)是第M個單元上的局部殘差,為第M個單元第N點上殘差.
由于本文計算的是定常流動,無需考慮時間精度,因此時間項的離散使用一階向后隱式差分格式.方程(15)經過該方法離散后可得
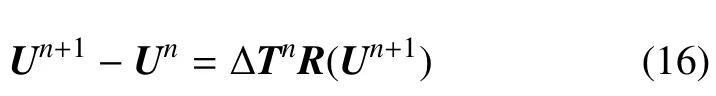
式中,Un=U(tn)和Un+1=U(tn+1)分別為tn和tn+1時刻的解.ΔTn為一個包括時間步長的對角矩陣,其與Un具有相同的維數,其具體形式為

由于方程(16)中的R(Un+1)是非線性的,通過泰勒展開對其線性化,則有

上式中,?R/?U|Un為全局雅可比矩陣.將方程(18)代入方程(16)并整理得
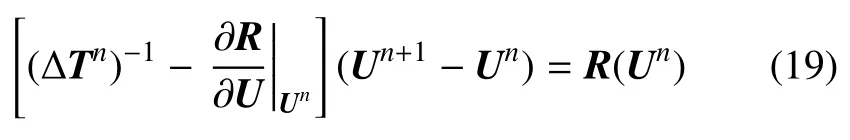
上式中,tn+1時的解Un+1需要先求解線性方程組才能獲取.
3.1 塊雅可比迭代
線性方程組的求解可分為直接法和迭代法.當網格規模較大時,使用直接法求解效率低下且內存占用較大.因此本文通過迭代法求解方程(19),所用的迭代方法為雅可比迭代.
首先對方程(19) 左端的矩陣進行分解.令A=[(ΔTn)-1-?R/?U|Un].則A=D-N可看作是由分塊對角矩陣D和剩余非對角部分N組成.其中,分塊對角矩陣D為

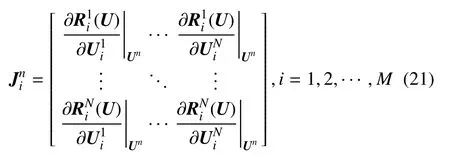
與此同時,N的矩陣形式是
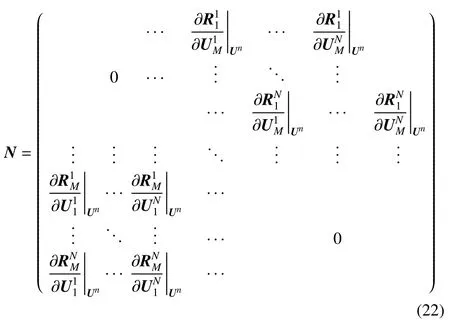
式中的N為一稀疏矩陣.經過上述分解之后,對全局線性方程組(19)進行迭代求解,可得
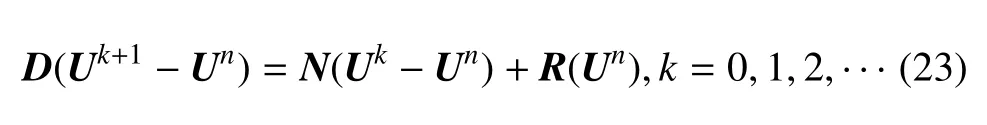
在上式中,k為雅可比迭代指標.當k→∞時,雅可比迭代解Uk+1趨近于下一個時刻的解Un+1.對于定常問題的計算,k只需要設置為有限的值,當n→∞,Uk+1和Un最終都將趨向于所求的定常解.
為了避免非對角部分N的計算.對方程(23)兩側同時減去D(Uk-Un),則有

上式經進一步整理后可得
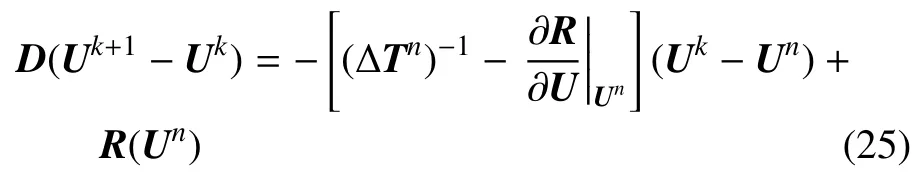
和方程(18)類似,將R(Uk)在R(Un)處進行泰勒展開
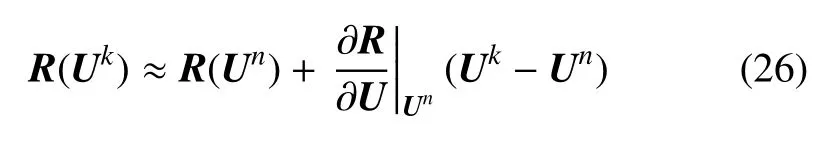
上式可進一步寫成
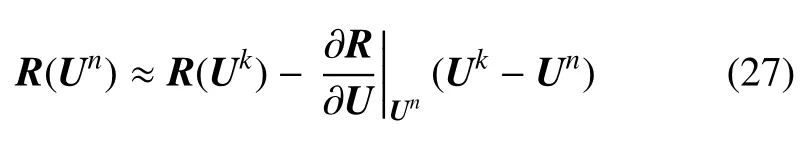
將方程(27)代入到方程(25)中消去全局矩陣相關的一項?R/?U|Un(Uk-Un),并最終整理可得
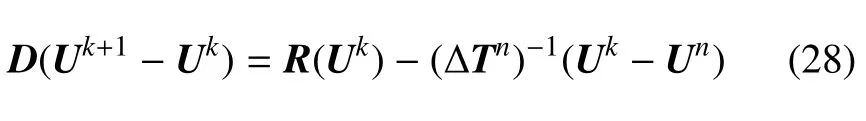
式中,D=diag{D1,D2,···,DM}.
方程(28)和方程(19)相比,它的左端矩陣D是一個分塊對角矩陣,這使得求解全局線性方程組(19)的問題解耦為求解一系列局部單元上的小型線性方程組.
值得注意的是,全局矩陣A的分解方式并不唯一,如將其分解為分塊上三角矩陣U和分塊下三角矩陣L,即為Gauss-Seidel 迭代法.此時需要求解的方程的左端矩陣為分塊下三角矩陣L.由于此時Uk+1存在數據依賴問題,無法同時更新,為了并行地求解該方程,需要使用圖著色技術,所得方法即為更復雜的MCGS 法[26].
3.2 局部線性方程組的求解
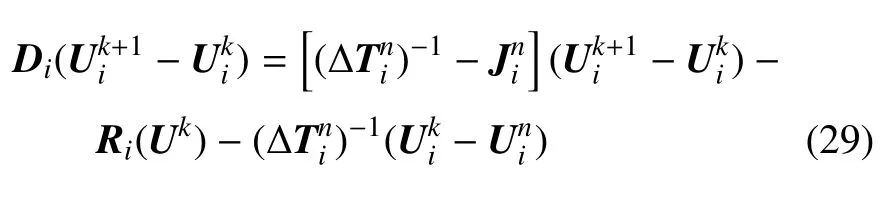
方程(28)可進一步寫成一系列局部單元線性方程組.對于第i(1 ≤i≤M)個單元,則有上式中,i為單元指標,n是時間迭代指標,k為雅可比迭代指標.為第i個單元對應的單元雅可比矩陣,在下一小節中將討論其具體計算方法.以上獲取的M個局部線性方程組(29),其左端矩陣規模較小,在程序中通過調用cuBLAS 函數庫使用LU 分解法實現同步求解.
3.3 單元雅可比矩陣的計算
本文中所用是解析法與自動微分相結合的方法.由式(13)可知,第i個單元上,FR 格式離散后的殘差Ri是不連續通量的散度和修正通量的散度之和.則單元雅可比矩陣為
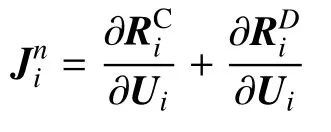

4 數值實驗
本節中以二維Bump 流動和NACA0012 翼型無黏繞流兩個算例來展示隱式方法的精度和效率.為了進行計算效率的對比研究,所有算例均同時使用顯式和隱式兩類方法進行.顯式方法為具有TVD 性質的三級Runge-Kutta(TVD RK3)方法[21],同時使用局部時間步長和多重網格(pmulti-grid)方法加速其收斂.隱式方法為本文中所提出的塊雅可比迭代的方法.隱式方法的時間步長ΔTn由CFL 數決定,CFL數初始值為2,并隨迭代步數指數增長,最大值為104.
所有算例均使用高階并行通量重構軟件HAFR(heterogeneous architecture flux reconstruction) 在型號為英偉達GeForce RTX 2080ti 的單個GPU 卡上計算.為了保證FR 方法在邊界的精度不至于下降,算例中用到的網格是由開源網格生成軟件Gmsh 生成的二階曲邊網格.計算的收斂性通過密度殘差的L2范數判斷,當其下降到10-14以下或平穩而不再下降時便認為計算已穩態收斂并終止.
4.1 無黏亞聲速Bump 算例
本算例是 international workshop on high-order CFD methods[39]給定的一個二維無黏驗證算例.該問題的物理域為[-1.5,1.5]×[0,0.8],底邊的幾何描述為y=0.062 5e-25x2.左側為亞聲速入口邊界條件(給定入口總壓和總溫),右側出口為出口邊界條件(給定靜壓),上下邊界均為滑移壁面邊界條件.來流的馬赫數Ma=0.5 且攻角為零度.盡管該流動的精確解未知,但由于流動為亞聲速無黏流動且流場光滑,因此可通過熵來衡量解的精度,流場中熵的計算公式如下

式中的積分在HAFR 程序中通過10 階高斯積分法進行計算.
計算中所使用的網格由粗到細(即h-refinement)為:R1(12×4),R2(24×8),R3(48×16)和R4(96×32),圖3 是R2 網格的示例.對于同一網格,同時還將使用p=2,3,4 階的插值多項式(即p-refinement)進行計算.
圖3 本算例中所用的24×8 的四邊形網格Fig.3 Quadrangular mesh(24×8)used in the case
首先從數值精度的角度分析計算結果.表1 為HAFR 程序使用塊雅可比迭代隱式方法在四組網格上,插值多項式為p=2,3,4 階時的熵以及數值精度.從表中可知,對任意一階插值多項式階數而言,網格加密的過程中熵也隨之降低.同時,給定某組網格,提高插值多項式的階數也同樣會導致熵的降低.正如圖4 所示,在R2 網格上使用p=3 和p=4 階插值多項式得到的下壁面馬赫數等值線相比p=2 的更為光滑.此外還觀察到,對于p=2,3,4 階插值多項式,在4 組網格上獲取的數值精度,都近似達到p+1階這一理論值,這也驗證了HAFR 的計算精度.

圖4 在24×8 的網格上使用p=2,3,4 階插值多項式計算所得的馬赫數云圖Fig.4 Mach number contours calculated on the 24×8 mesh with p=2,3,4 polynomial orders
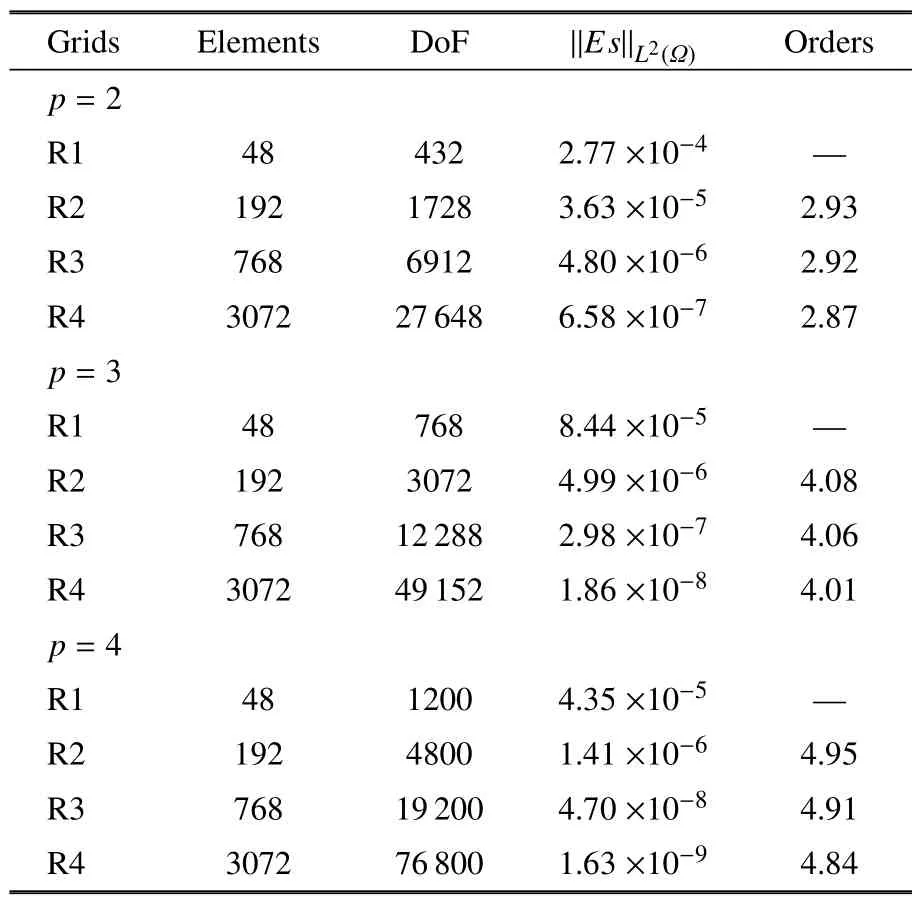
表1 在四組網格上,使用p=2,3,4 階多項式時的熵和數值精度Table 1 Entropies and numerical orders on four different grids with p=2,3,4 polynomial orders
下面從計算效率的角度進行分析.圖5 是HAFR程序使用顯式和隱式兩種方法在4 組網格上、插值多項式為p=2,3,4 階時密度殘差隨迭代次數的收斂情況.
在圖5 中,左右兩列子圖分別為使用塊雅可比迭代隱式和TVD RK3 顯式時間方法的計算結果.從迭代次數來看,對同一階插值多項式,顯式方法和隱式方法收斂所需的迭代次數都隨著網格的加密而增大.對于同一網格,使用更高階的插值多項式都會導致迭代次數的增多.但同時發現,隱式方法的迭代次數隨自由度(degree of freedom,DoF)增幅較小,并且對于同一網格或同一階插值多項式,隱式方法所需的迭代次數要遠遠小于顯式方法.例如,在R1 網格上,隱式方法收斂的的迭代次數均在80 步以內,而顯式方法最快也需要1000 步左右才能收斂.
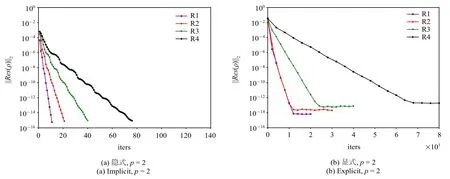
圖5 在四組網格上,插值多項式為p=2,3,4 階時,使用隱式和顯式方法所得到的密度殘差||Res(ρ)||2 隨迭代次數的變化Fig.5 Density residual||Res(ρ)||2 versus the iteration numbers for the explicit and implicit time-marching schemes on four different grids with p=2,3,4 polynomial orders
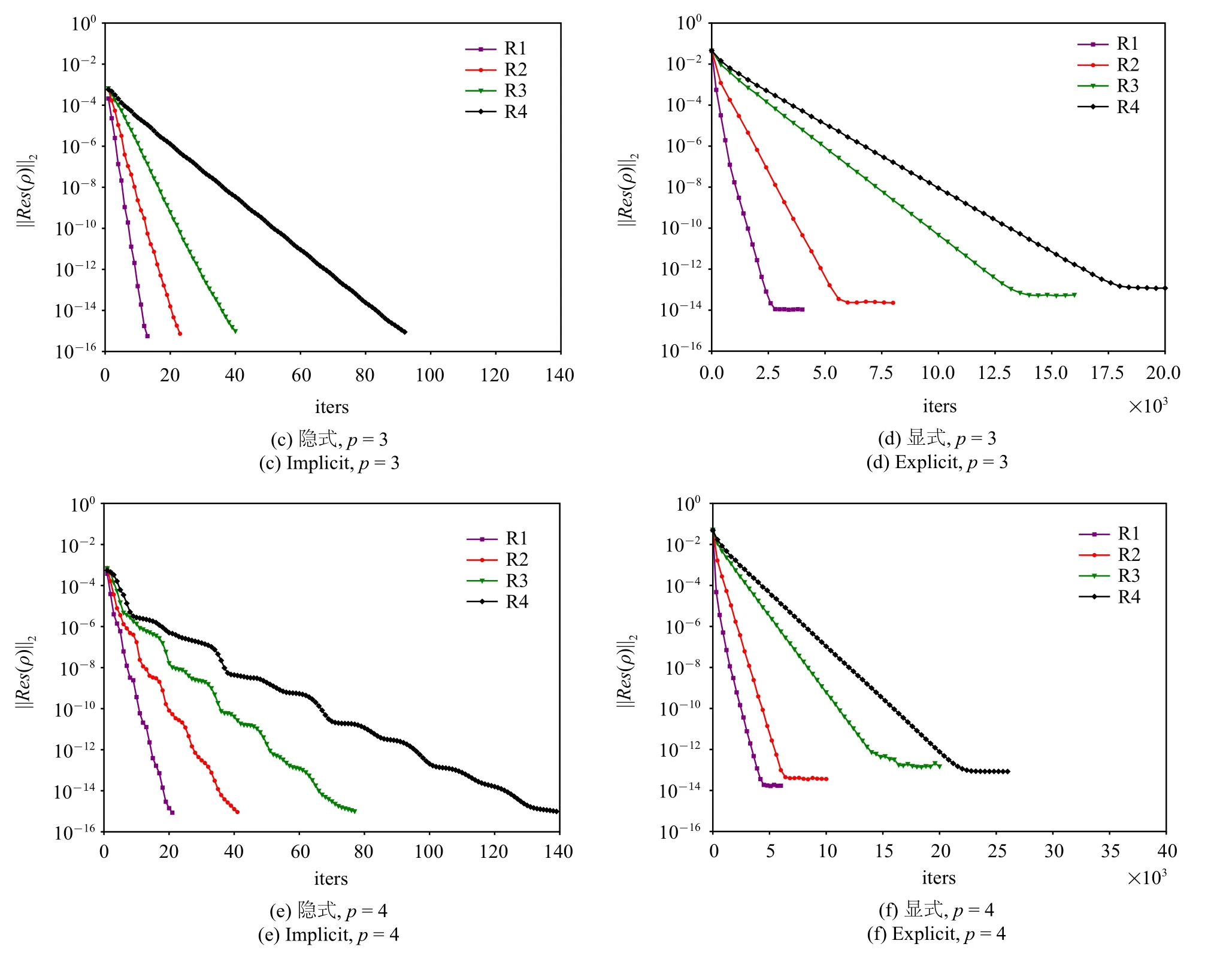
圖5 在四組網格上,插值多項式為p=2,3,4 階時,使用隱式和顯式方法所得到的密度殘差||Res(ρ)||2 隨迭代次數的變化(續)Fig.5 Density residual||Res(ρ)||2 versus the iteration numbers for the explicit and implicit time-marching schemes on four different grids with p=2,3,4 polynomial orders(continued)
在密度殘差收斂方面,使用隱式方法的計算的密度殘差均能收斂到10-14這一量級.但顯式方法的收斂性隨著自由度的增大變差,其值下降到某個量級后將無法下降,例如使用p=2 階插值多項式時,在R1 網格上的密度殘差能夠收斂10-14量級,但在R4 網格上僅能下降到10-13這一量級.
在GPU 計算時間方面,表2 為HAFR 程序采用塊雅可比迭代隱式方法在4 組網格上,使用p=2,3,4 階插值多項式計算收斂所用的迭代次數和GPU 墻鐘時間.從表2 可知,隱式方法計算收斂所用時間隨著自由度的增大而增大.

表2 在四組網格上,插值多項式為p=2,3,4 階時,使用隱式時間方法時的迭代次數和墻鐘時間Table 2 Iteration numbers and wall-clock times for the implicit time-marching scheme on four different grids with p=2,3,4 polynomial orders
圖6 是HAFR 程序分別使用塊雅可比隱式和TVD RK3 顯式時間方法,在不同網格上,使用p=2,3,4 階插值多項式時所用的墻鐘時間對比.從圖6中可看到,對每一組計算,隱式方法收斂所用的時間明顯小于顯式方法.在所有算例中,隱式方法相比顯式至少有一個量級的加速效果.
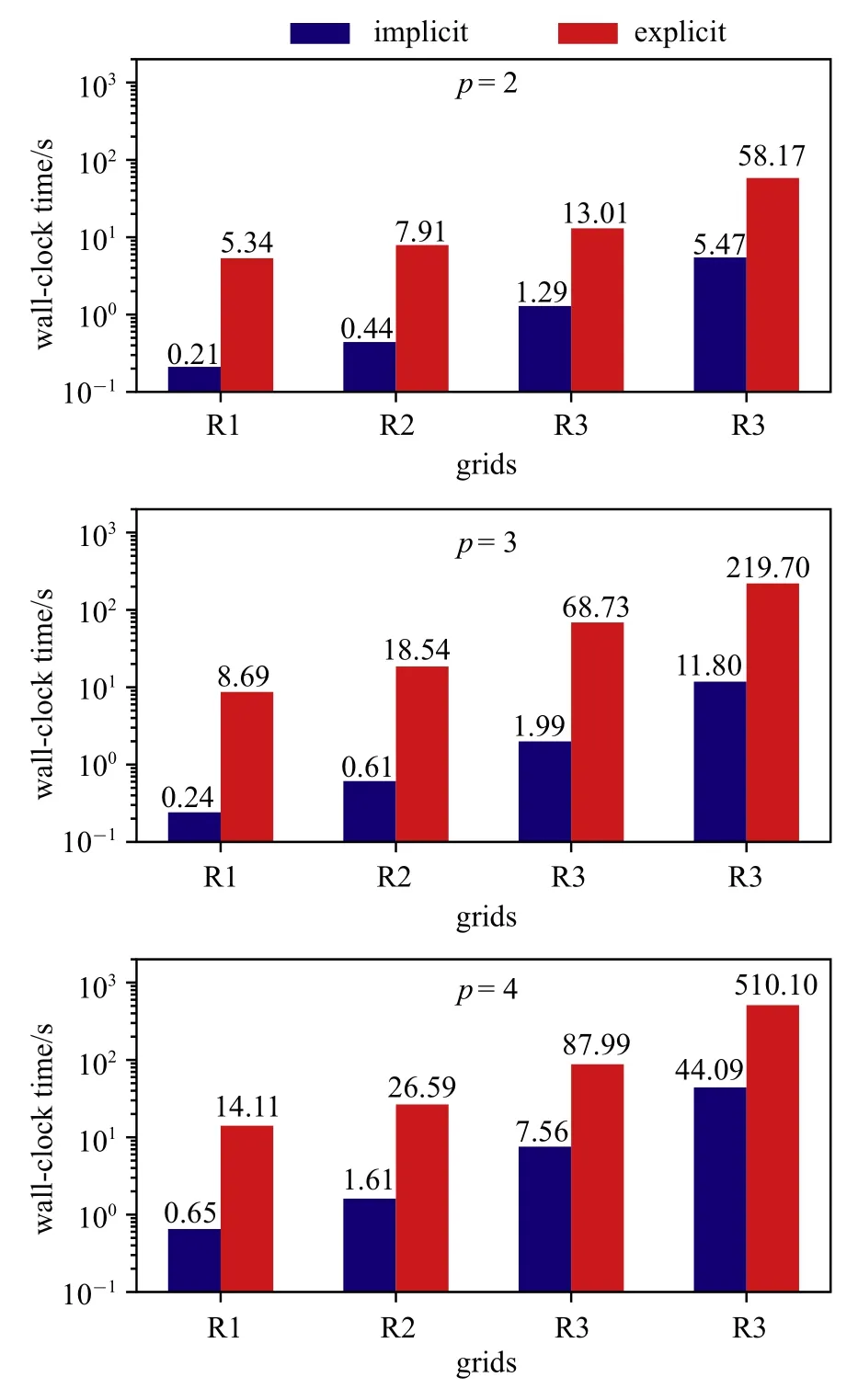
圖6 在四組網格上,插值多項式為p=2,3,4 階時,使用隱式和顯式方法所用的計算時間Fig.6 Wall-clock times for the explicit and implicit time-marching schemes on four different grids with p=2,3,4 polynomial orders
4.2 NACA0012 翼型無黏繞流
在上一個Bump 算例中所使用的網格較為均勻,為了進一步考察在非均勻網格條件下塊雅可比迭代隱式方法的計算效率,下面對NACA0012 翼型無黏繞流進行數值模擬.在此算例中,自由來流的馬赫數為0.5 且攻角為零度.NACA0012 翼型表面為滑移壁面條件,遠場為特征邊界條件,遠場與翼型的距離大約為100 個弦長.
計算中用到的網格為Gmsh 生成的O 型網格,網格分為3 組:R1(32×32),R2(44×64)和R3(128×128).圖7 為R1(32×32) 網格的示意圖.對于同一網格,還將分別使用p=2,3,4 階的插值多項式(即prefinement)進行計算.
圖7 本算例中所用的32×32 的O 型四邊形網格Fig.7 O-type quadrangular mesh(32×32)used in this case
下面對 NACA0012 數值模擬結果進行分析.表3 為HAFR 程序采用塊雅可比迭代隱式方法在三組網格上,使用p=2,3,4 階插值多項式計算收斂所用的迭代次數和GPU 墻鐘時間.和上個算例中類似,可觀察到無論是網格加密還是提高插值多項式階數,這兩種增大自由度的方式都會導致迭代次數和GPU計算時間的增多.
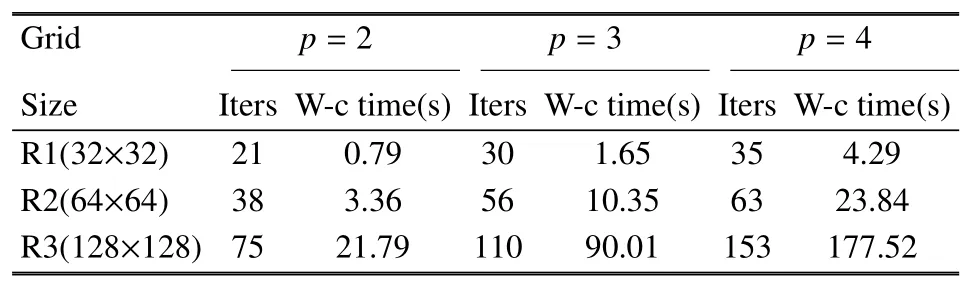
表3 在三組網格上,插值多項式為p=2,3,4 階時,使用隱式時間方法時的迭代次數和墻鐘時間Table 3 Iteration numbers and wall-clock times for the implicit time-marching schemes on three different grids with p=2,3,4 polynomial orders
圖8 是HAFR 程序分別使用隱式和顯式時間方法,在不同網格上,使用插值多項式為p=2,3,4 時所用的墻鐘時間對比.從圖8 中可知,對于每一組計算,使用塊雅可比迭代隱式方法收斂所用的時間相比TVD RK3 顯式方法至少有一個量級的加速效果.

圖8 在三組網格上,插值多項式為p=2,3,4 階時,使用隱式和顯式方法所用的墻鐘時間Fig.8 Wall-clock times for the explicit and implicit time-marching schemes on three different grids with p=2,3,4 polynomial orders
圖9 為HAFR 程序使用顯式和隱式兩種方法在三組網格上、插值多項式為p=2,3,4 階時密度殘差隨迭代次數的收斂情況.在圖9 中,左右兩列子圖分別為使用塊雅可比迭代隱式和TVD RK3 顯式時間方法的結果.從迭代次數來看,對同一階插值多項式,顯式方法和隱式方法收斂所需的迭代次數都隨著網格的加密而增大.對于同一網格,使用更高階的插值多項式會導致迭代次數的增多.但同時,相比顯式方法,隱式方法的迭代次數隨自由度增幅較小,并且對于同一網格或同一階插值多項式,隱式方法所需的迭代次數要遠遠小于顯式方法.
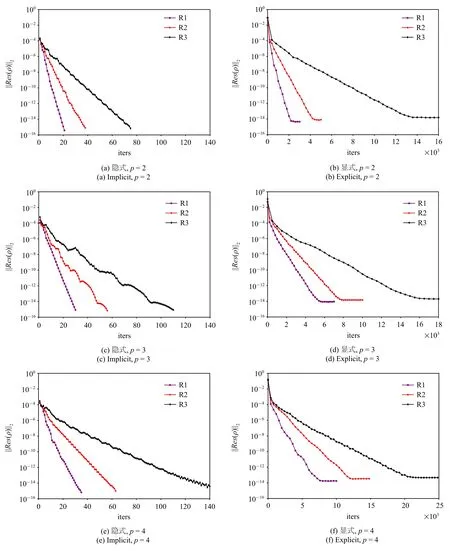
圖9 在三組網格上,插值多項式為p=2,3,4 階時,使用隱式和顯式方法所得到的密度殘差||Res(ρ)||2 隨迭代次數的變化Fig.9 Density residual||Res(ρ)||2 versus the iteration numbers for the explicit and implicit time-marching schemes on three different grids with p=2,3,4 polynomial orders
在密度殘差收斂方面,在3 組網格計算中,使用塊雅可比迭代隱式方法計算的密度殘差均能收斂到10-14這一量級.但TVD RK3 顯式時間方法的收斂性隨著自由度的增大變差,其值下降到某個量級后將無法下降.因此從殘差收斂角度,基于塊雅可比迭代的隱式方法要優于TVD RK3 顯式方法.
綜上,隨著自由度的增大,顯式和隱式方法收斂所需的迭代次數都會增多.但對于同一網格或同一階插值多項式,隱式方法所需的迭代次數和計算時間要明顯小于顯式方法,且隱式方法的殘差下降幅度要比顯式方法更大.
5 結論
為了提高FR 方法的求解效率,本文提出一種基于雅可比塊迭代的高階FR 格式求解定常二維歐拉方程的單GPU 隱式時間推進方法.通過雅可比塊迭代的方式,克服了影響求解并行性的相鄰單元依賴,使得只需存儲和計算對角塊矩陣.最終將求解全局線性方程組轉化為求解一系列局部單元線性方程組.這些局部的線性方程組在GPU 上又可利用LU 分解法并行求解.
文中通過二維無黏Bump 流動和NACA0012 無黏繞流兩個算例表明:隨著自由度的增大,塊雅可比迭代隱式方法收斂所需的迭代次數和計算時間都會增多.但對于同一網格或同一階插值多項式,該隱式方法所需的迭代次數要明顯小于TVD RK3 顯式方法,且此隱式方法的殘差下降幅度要比TVD RK3 顯式方法更大.在計算時間方面,對于文中的每一組計算,雅可比塊迭代隱式方法收斂所用的GPU 計算時間明顯小于TVD RK3 顯式方法,且計算效率至少有一個量級的提高.
附錄
二維歐拉方程的雅克比矩陣為
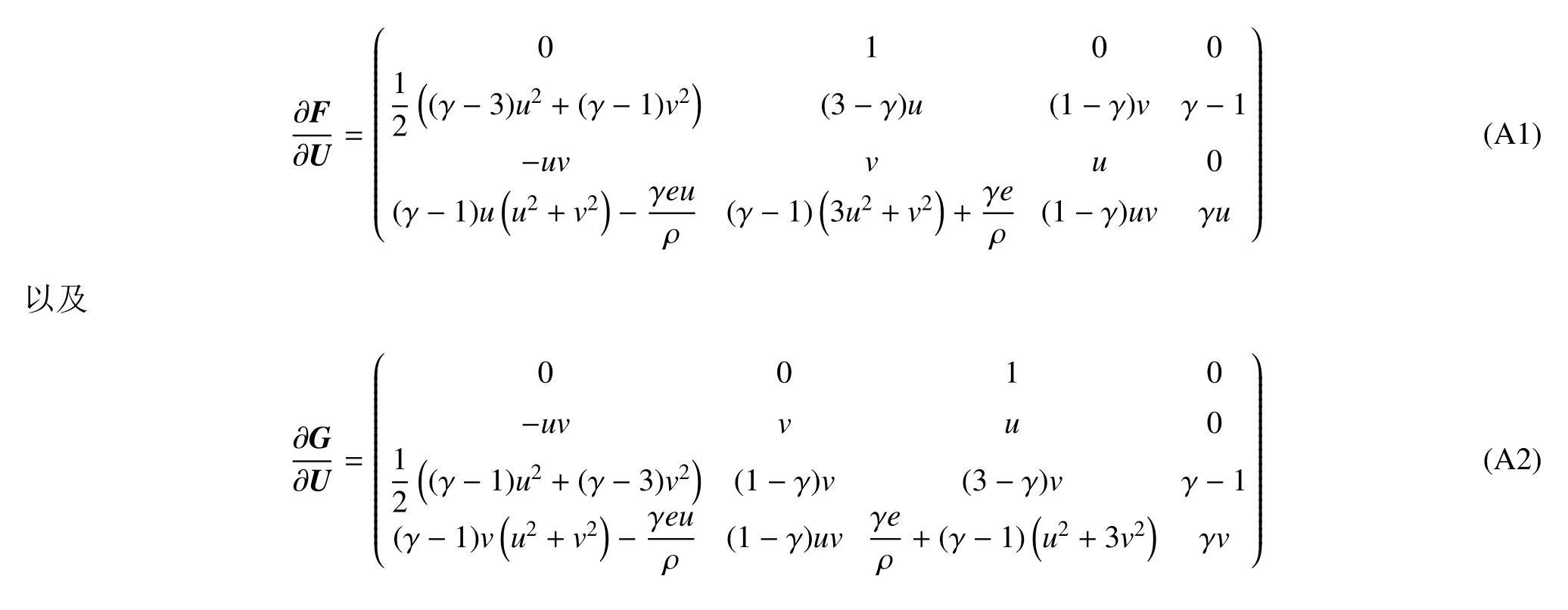
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
