改進自訓練模型在業務質差用戶識別中的應用
2021-11-11 06:04:18余立李哲高飛袁向陽楊永
電信科學 2021年10期
余立,李哲,高飛,袁向陽,楊永
(1. 中國移動通信有限公司研究院,北京 100053; 2. 中國移動通信集團公司,北京 100033)
1 引言
隨著移動互聯網發展,我國移動互聯網用戶突破13億戶,占全球網民規模的32.17%[1],隨著新型技術(如5G、云計算等)的發展,用戶對上網速度、穩定性等要求越來越高。
質差用戶指在使用移動通信網絡服務時,由于網絡質量問題或其他因素對服務體驗不滿的用戶。網絡質量問題導致的質差用戶,對網絡服務的滿意度會降低,且可能存在投訴、轉網等行為。
質差用戶群體流失概率較高,他們是各大網絡運營商重點關注與關懷對象。傳統質差用戶識別通過數據采集系統對用戶上網過程中產生的行為單據XDR(X data record)進行分析,即可過濾潛在的質差用戶。但各用戶感知無法統一,不滿意原因及不滿意的業務也并不一致,傳統分析方法可識別的投訴用戶比例較低,無法滿足現網投訴處理要求。故通過將已存在的滿意度低或投訴行為的質差用戶與XDR進行關聯標注后,利用機器學習算法,實現對質差用戶進行分類識別與預測。
通過現網收集的XDR數據中存在以下問題。
? 不同省份網絡基礎設備存在一定差異,數據中特征字段并不完全相同,且部分字段填充率較低,無法直接利用。
? 數據進行標簽化標注時,不同省份字段計算方法可能存在差異,且數據量巨大,導致標注成本高昂。
? 已投訴用戶單據中投訴原因眾多,部分原因來自于非網絡問題,存在大量對抗樣本,導致樣本本身含有較大噪聲,訓練時會影響模型性能。
2 半監督學習
有監督學習需大量的有標簽數據訓練模型,在質差用戶識別模型中,一條有標簽數據包含兩部分:用戶XDR數據和是否為質差用戶。前部分數據通過數據采集系統獲得,后部分標簽信息需豐富的專家知識,往往判定成本較高,造成整體訓練成本的增加[2]。
現網每日會產生海量的用戶XDR數據,通過標注再進行訓練,模型時效性較差,無法準確描述現網實時運行狀況。半監督學習與有監督學習相比可以利用現網實時海量無標簽數據,效率較高;與無監督學習相比可以保證模型準確率。
質差用戶識別為分類問題,已知的半監督分類問題主要分為5類,具體優劣勢見表1。

表1 半監督分類方法優劣勢
? 基于圖的半監督模型將標簽數據和未標簽數據構建為圖,圖中節點為數據點,邊為節點權重,通過尋找圖的最小分割,然后計算反向傳播權重,其可應用于圖片、中文文本、數據分類等各類場景,但是當新樣本加入時,需要重新訓練得到圖模型,計算開銷較大[3-4]。
? 基于分歧的半監督模型通過選擇差異化基模型,進行組合降低“錯誤”分類樣本對模型的不良影響,提升模型預測準確率,但是其對基模型選擇設定要求較高,并且運算效率也較低[5-6]。
? 半監督支持向量機是將支持向量機應用到半監督模型中,將樣本空間映射到高維空間,并選擇合適平面將樣本集劃分,但是模型受參數影響,最終模型準確率較低[7]。
? 協同訓練(co-training)用有標簽樣本的兩個視圖分別訓練兩個弱分類器,再利用分類器對未標注樣本預測中高置信度樣本訓練另一個分類器;即用一個視圖中獲得的知識來訓練另一個視圖。缺點是對樣本要求高,要求具有兩個充分冗余且滿足條件獨立性的視圖,實際情況下較難滿足[8-9]。
? 自訓練(self-training)需要一個基分類器和少量樣本數據可以實現,核心思想是先學習有標簽數據,然后計算無標簽樣本置信度,并將置信度高的樣本加入訓練集,缺點是如果無標簽樣本預測錯誤,則隨著訓練的深入,會造成錯誤的累計[10-12]。
基于對以上半監督方法的研究,本文選取一種改進自訓練模型,通過設置基模型參數以及較高的置信度閾值,引入多個基模型學習器,降低傳統自訓練中出現的誤差累計現象,提高模型訓練精度。
3 改進自訓練應用
3.1 改進自訓練模型
自訓練模型是一種增量模型,首先建立基分類器模型,通過有標簽數據進行訓練,然后利用訓練好的基模型不斷預測數據集中無標簽數據,從中選擇置信度高樣本,將其加入有標簽數據中進行基模型循環訓練。在滿足設定停止迭代條件后,得到具有最高分類精度和最強的泛化性能的最終分類器。模型在迭代過程中不可避免會產生誤分樣本,基模型學習誤分樣本會產生錯誤累計,最終影響模型效果。為降低錯誤累計,本文做出以下改進:設置模型性質不同、性能相同的3種基模型,分別進行預測后,通過投票初步選定偽標簽樣本,隨后計算其置信度,將置信度高的偽樣本加入模型訓練集中進行循環迭代。改進自訓練模型示意圖如圖1所示。
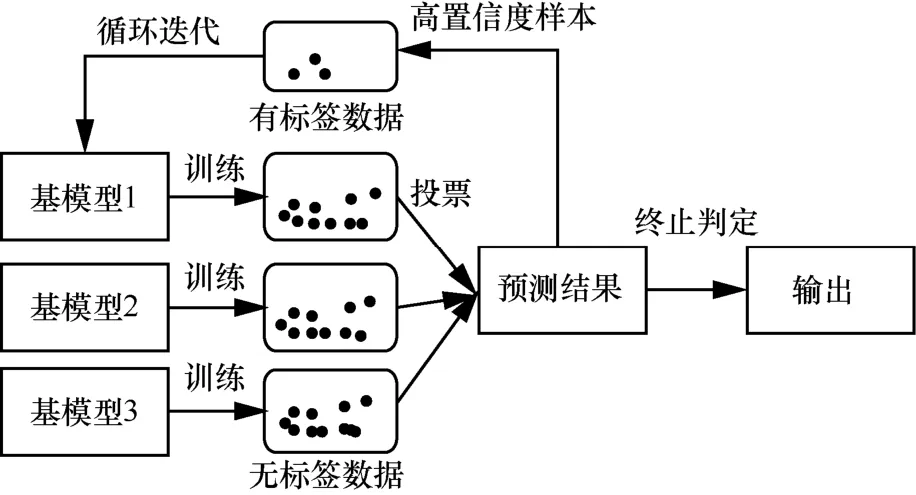
圖1 改進自訓練模型示意圖
其基本流程如下:
(1)根據有標簽數據集訓練3種基模型;
(2)利用訓練得到的基模型預測無標簽數據;
(3)選擇置信度高的樣本,將其加入有標簽數據集;
(4)循環訓練模型;
(5)判斷是否滿足迭代條件,重復(1)~(3)。
改進自訓練模型算法見算法1。
算法1
輸入有標記樣本集:
每i輪基學習器為 K1i、 K2i、 K3i;
每i輪預測得到樣例數為pi;
流程
(1)初始化設置 K10、 K20、 K30;
(2)i=1;
(3)利 用 K10、 K20、 K30擬 合Dl得 到 K11、 K21、 K31;
(4)利用 K11、 K21、 K31訓練Du,得到pi例樣本不同分類情況下置信度;
(5)進行選擇,將pi例預測樣本加入Dl;
(6)利用新樣本集Dl訓練,得到 K12、 K22;
(7)循環(4)~(6),直到滿足迭代終止條件。
3.2 基模型選取
質差用戶識別是一種分類問題,最終評價標簽為質差用戶和非質差用戶兩種。當前主流機器學習分類模型有貝葉斯分類器(NB)、Logistic模型、支持向量機、樹模型(如隨機森林(RF)和極限梯度提升(XGBoost)等[13])。本模型選擇樸素貝葉斯分類器、XGBoost、隨機森林為基模型進行訓練。
(1)樸素貝葉斯分類器
該模型描述如下:設訓練集中包含m個類H=(H1,H2,… ,Hm),n個條件屬性X=(X1,X2, …,Xn),并且假設所有條件屬性X為類變量H的子節點,并相互獨立,則當待分類樣本x=(x1,x2,…,xn)分配到類Hm時,根據貝葉斯定理可得:
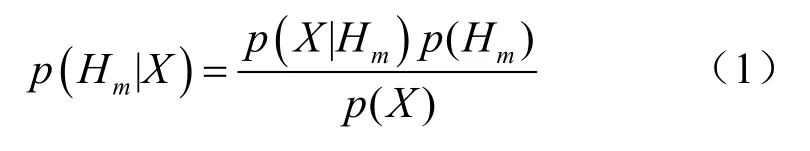
由于在本監督學習中需要使用大量的無標簽數據進行模型訓練,式(1)修改為:
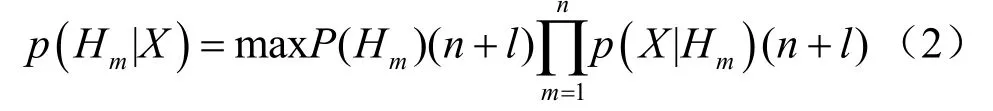
其中,(n+l) 表示迭代后有標簽樣本集與增加標記后的無標簽樣本集的合集,該合集增加了無標簽數據中預測得到的高置信度數據。
(2)極限梯度提升和隨機森林
XGBoost和RF都是基于樹模型的集成模型,但是兩者有所區別。XGBoost為并行化Boosting處理,RF為串行化Bagging處理[14]。
給定數據集D=(Xi,yi),輸入Xi并通過線性疊加模式預測iy。并設學習使用k棵樹,模型如式(3)、式(4)所示。
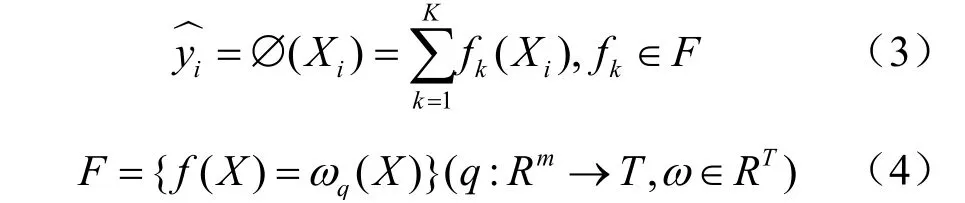
其中,()fX代表回歸樹,F代表回歸集合,()qX表示將X分到了某個葉子節點上,T為葉子節點的數量,ω為葉子節點分數,ωq(X)代表f(X)對樣本的預測。
通過二階泰勒展開式和正則項調整得到目標函數如式(5)所示。
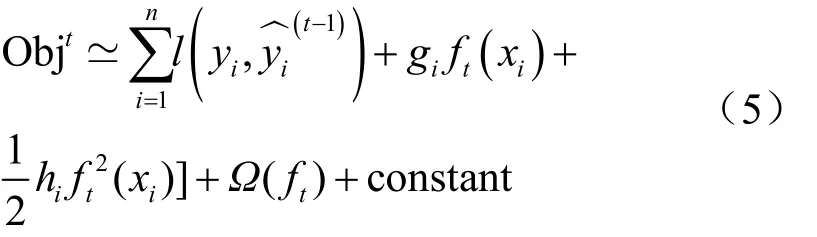
4 實驗與分析
4.1 數據預處理
(1)數據收集
本次仿真實驗使用數據采集系統中的正常XDR數據和現網投訴XDR數據。其中包含199 998條、46項字段的正常XDR數據以及3 355條、125項字段的投訴XDR數據。
(2)字段選取
正常XDR數據的46項字段中,包含較多非結構化離散字段(如小區ID、所屬城市、IPV類型等),并且部分字段缺失值比重較大,通過處理最終得到連續型字段15項。
(3)標準化處理
部分機器學習模型需要數據處于同一量綱,所以進行數值量綱轉化、標準化處理。處理后數據變化到均值為0、方差為1范圍內。
(4)樣本均衡
因為質差用戶識別為二分類問題,所以需要保證原始訓練數據樣本集分布相同。使用隨機采樣方法,最終案例數據集組成見表2。
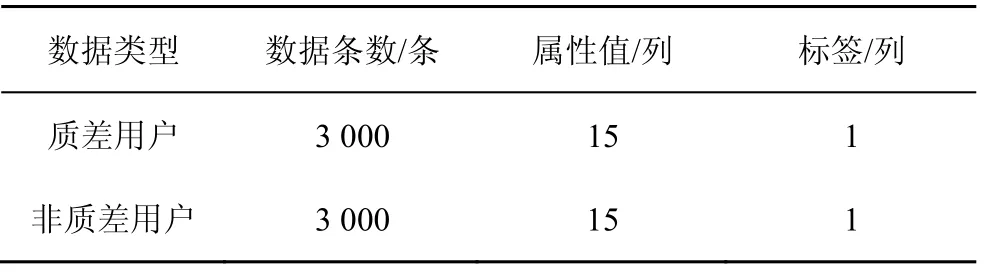
表2 數據集組成
(5)關鍵參數
TCP建鏈成功到第一條事務請求的時延(tcp_ack_srv_dur):在終端和服務器完成TCP建鏈請求后,到終端發出業務請求前的時間間隔。
第一個HTTP響應包時延(fisrt_http_ response_ time):在業務請求過程中,第一次業務請求發出后到接收第一次業務請求響應的時間間隔。
TCP建鏈確認時延(fisrt_http_response_ time):在TCP建鏈過程中,第二次握手SYNACK報文發出后到收到第三次握手ACK報文的時間間隔。
4.2 分類器評價標準
對于每個待檢測的用戶數據,分類器最終可能產生4種不同的結果,本實驗中對不同情況解釋如下。
? TP(true positive):質差用戶,且模型預測結果為質差用戶。
? TN(true negative):非質差用戶,且模型預測結果為非質差用戶。
? FP(false positive):非質差用戶,但模型預測結果為質差用戶。
? FN(false negative):質差用戶,但模型預測結果為非質差用戶。
基于以上4種情況,引入精準度、F1值和AUC3項指標進行評判。精準度和F1主要判斷分類器預測結果的準確性,AUC主要判斷分類器對質差用戶區分能力的強弱。
精準度即精確率,在本實驗中表示正確判斷為質差用戶的樣本占全部質差樣本的比例:
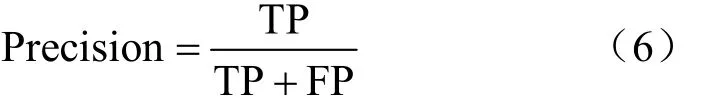
F1值是由Precision和Recall的調和平均數,在本實驗中表示在保持一定精確率同時,盡可能保證所有質差用戶可以被模型識別即保證召回率,兩者相互平衡。
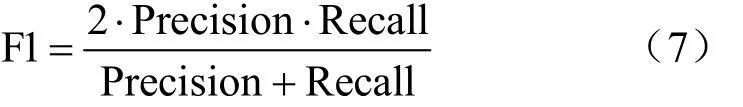
AUC值是ROC曲線下方的面積。ROC曲線繪制的橫坐標是FPR,而縱坐標是TPR。當無法直接衡量學習性能時,AUC值越大,表明模型效果越好。
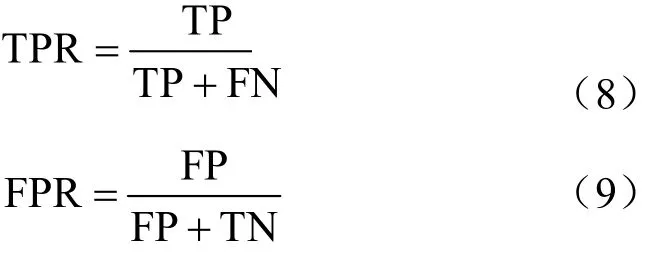
4.3 實驗結果與對比分析
針對實驗數據,分別使用全監督方法、半監督方法、無監督方法進行擬合。其中全監督方法選用XGBoost模型,半監督方法使用本文提出的改進自訓練模型,無監督方法選用圖傳播label spreading模型。結果對比見表3。
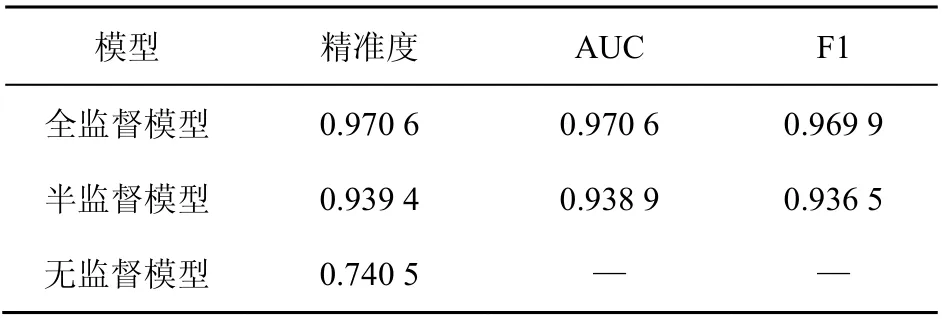
表3 3種模型運行結果
對比3類模型精準度可得到如下結論:全監督模型效果最好,各項評價指標數值最高;無監督模型效果最差,因為在模型訓練過程中不可避免會學習到數據中噪聲,影響模型評價指標;而半監督模型介于兩者之間,可以充分利用大量無標簽數據,此外還可以保證較高精準度。
為了進一步驗證半監督模型優越性,將以上3類模型進行對比。其中在半監督和無監督模型中,橫軸設置為樣本標簽缺失值比率。在全監督模型中,橫軸設置為訓練集劃分比率。不同缺失值比率下模型精準度變化如圖2所示。
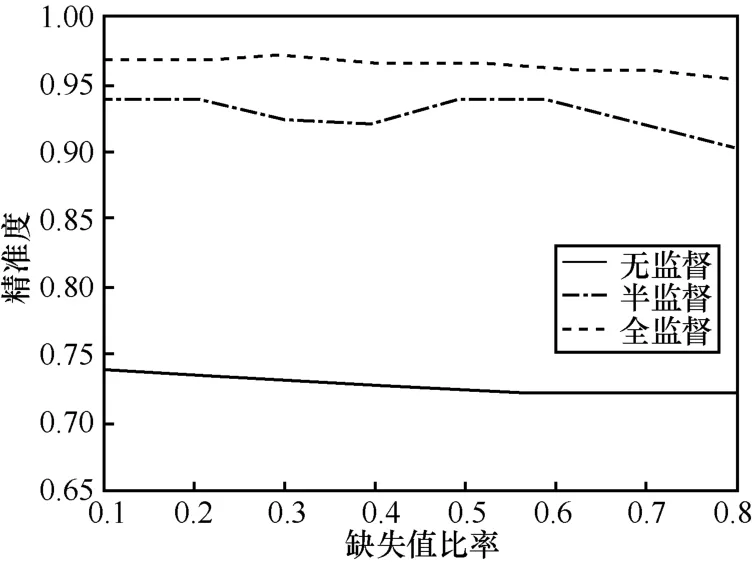
圖2 3類模型精準度對比
通過圖2可知,隨著缺失值比率增加,3類模型精準度都在下降,半監督模型仍然處于一定精準度變化區間內,可以滿足模型識別精準度要求。
在半監督改進自訓練模型中,使用迭代訓練對無標簽數據進行標注,當缺失值比率相比于上次訓練變化幅度低于0.1%時,模型迭代停止。具體數值和曲線變化如圖3和表4所示。
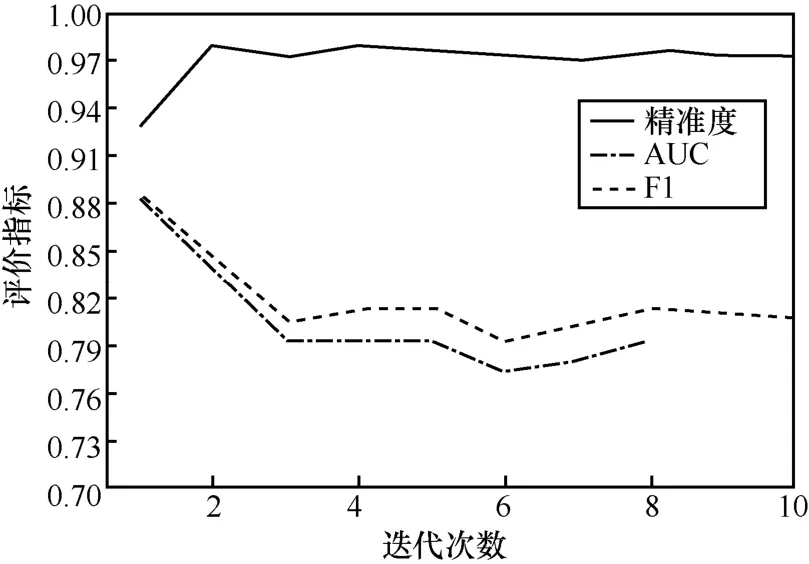
圖3 半監督模型評價指標變化趨勢
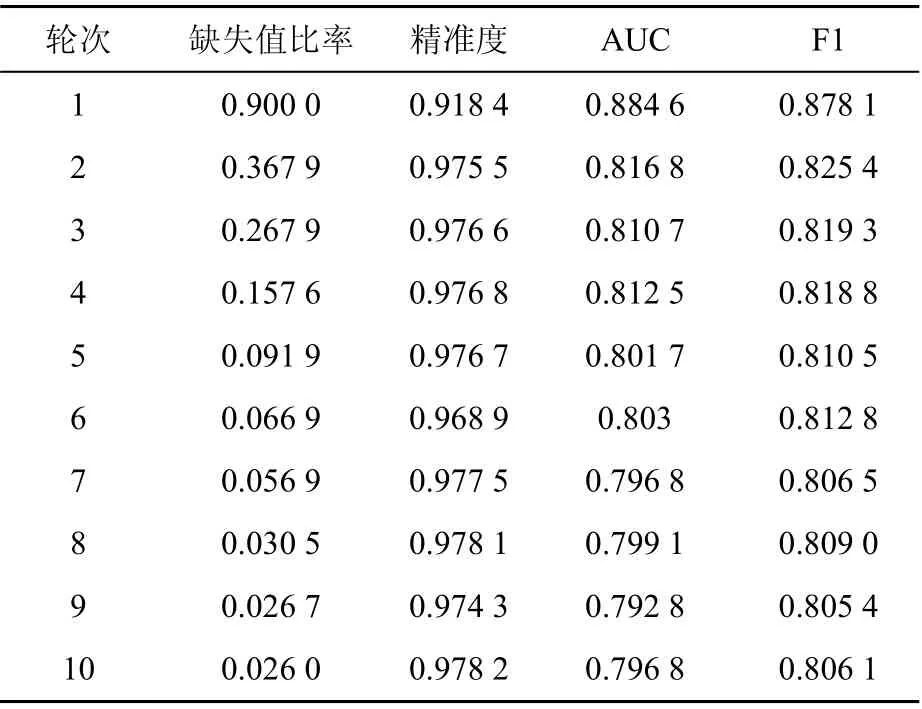
表4 半監督模型變化趨勢
如表4所示,設置默認參數和初始樣本缺失值比率(Ratio)后,模型開始訓練。通過10輪迭代計算后,Ratio變化幅度0.07%符合迭代終止條件,迭代停止。觀察表4中數據可知,缺失值比率列數值下降明顯,精準度、AUC、F1 3項評價指標有一定波動,且浮動下降。這是因為模型在自訓練過程中不可避免會學習到樣本集中的噪聲,最終模型性能受到一定影響。為進一步提升模型識別精準度,在之后的模型訓練過程中,需改進基模型選擇設計方案,并通過提高閾值、增加樣本預測可靠性水平等方法,降低訓練過程的誤分類樣本噪聲。
5 結束語
本文針對質差用戶識別問題,設計一種改進自訓練的半監督模型,采用無標簽樣本占90%的訓練集時,最終模型精準度維持在90%左右。相比于全監督模型和無監督模型,該模型在保證一定性能指標前提下,能夠充分利用無標簽樣本數據,在現網應用中可有效降低數據標注成本,同時避免了人為主觀因素對于質差規則設定的影響,可以有效實現質差用戶識別。未來的工作重點為進一步提高該模型性能,降低在循環迭代中噪聲對于模型性能的影響。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年4期)2020-09-21 03:39:12
數學物理學報(2020年2期)2020-06-02 11:29:24
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
