基于迭代加權圖像的藏文古籍逐級分類仿真
2021-11-17 07:36:54沈淑濤高飛梁家瑞
計算機仿真 2021年7期
沈淑濤,高飛,梁家瑞
(1. 西藏大學,信息科學技術學院,西藏 拉薩 850000;2.太原理工大學,軟件學院,山西 榆次 030600 )
1 引言
我國的藏文古籍數量多,且內容豐富,是中華民族文化遺產的主要組成部分。但是藏文古籍涉及的種類復雜,在研究藏文古籍時,想要從中挑選出所需的古籍十分困難,國內學者一直在研究有效的解決方法。
文獻[1]提出了通過學習向量量化算法對藏文古籍進行分類的方法。首先根據需要篩選出古籍因子,采用學習向量量化算法對因子進行分類,再使用列文夸特算法建造古籍模型對其分類。但該方法并沒有將兩種方法融合,導致出現分類不精準的問題。文獻[2]提出了通過表示法對迭代加權圖像的藏文古籍進行分類的方法,首先研究藏文古籍圖像的信息分類方法,然后提取藏文古籍中有明顯特點的圖像信息,最后使用表示法表示出不同的藏文古籍迭代加權圖像信息。但是該方法在提取明顯特點的圖像時,因沒有篩選過程,導致提取出冗余圖像,浪費了大量篩選時間。文獻[3]提出先通過對藏文古籍進行調整,并進行歸屬判定,再通過統計操作對其判定結果進行統計。但該方法因藏文古籍的種類復雜,該方法只能針對其實驗目進行判定,該方法不具有普適性。
針對上述問題本文提出了一種基于迭代加權圖像的藏文古籍逐級分類方法,該方法能更精準的分類藏文古籍,且分類效率較高。
2 迭代加權算法
2.1 迭代模型
針對藏文古籍逐級分類問題,傳統方法通常使用廣義內積值的樣本選取方法對藏文古籍進行逐級分類。但此類方法依賴協方差矩陣的分類準度。如果初始分類存在較大誤差,便很難分類出有用的樣本。且需要長時間對樣本進行大量的協方差矩陣訓練,但只能粗略地去除訓練樣本的合數,導致分類性能下降。
為了解決上述問題,本文采用基于迭代加權圖像的藏文古籍逐級分類方法。為便于分析,假設環境由兩種區域組成。
(1-α0)00+α001
(1)

在最少均方誤差要求下計算式(2)最優權問題。

(2)
由傳統方法知式(2)的最優質權為

(3)

通過式(3)能看出,最優權的分子只能與均勻樣本相關,當樣本總數到達一定數量時,最優權與不均衡出現反比。可能使不均勻程度達到最大化,不均勻程度的樣本因不均勻程度達到最大化,導致其所加的權值出現最少量。
廣義內積值與其本身的均值差距越大,則不均衡的效果越強,同時在樣本總數目有限的狀態中,其廣義內積的均值即不是理論均值。
通過以上分析可知,本文所使用迭代加權方法中的統計均值與廣義內積值中的方差對所有樣本進行加權處理,消除相對不均衡樣本在協方差矩陣里的比重,導致更改樣本升高產生的逐級分類精準度下降,為了調整不均衡壞點對與廣義內積的影響,應先利用構建的廣義內積直方圖對廣義內積值進行評估。再考慮樣本在總數量有限的情況下利用協方差矩陣會出現的差度。本文使用迭代模式對協方差矩陣的分類進行準度提高。方法的流程如圖1所示。
下列為本文方法的操作流程:
1)設定起始協方差矩陣:利用傳統方法的樣本協方差矩陣計算起始協方差矩陣
(4)
式中M代表總數訓練樣本。
2)對廣義內積值進行計算,再統計其幾率分布情況:先使用獲取的協方差矩陣算出全部樣本單元的廣義內積值zi

(5)
接著利用直方圖來計算出廣義內積值的幾率分布狀況P(zi),i=1,2,…,M。
3)權值計算:每一種樣本的權重經過計算其廣義內積值的誤差以及廣義內積值所得到的數據,其合理權值的重要點是獲得的反應均衡數據廣義內積值。
正常情況下,可理解訓練樣本內的均衡數據占據大部分位置,不均勻數據占比略小。因為均勻數據的廣義內均值與不均衡數據之間的廣義內積值相似度較高,包含較大差異,所以在對廣義內積值的計算幾率分布內,其均衡數據的幾率要大于不均勻數據。
為了能夠獲取較為適當的廣義內積值,避免受到不均衡樣本的廣義內積值對均值的影響,只使用樣本幾率較大的均值進行計算。

(6)
式中θ={i|P(zi)≥p},m代表集合θ中古籍的數量,p=μP(zi)代表設置的幾率值,μP(zi)代表(zi)的均值。
每一種樣本的權值為
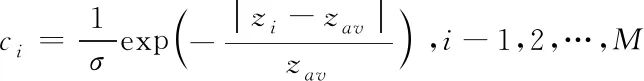
(7)

4)改進協方差矩陣:利用獲取的權值對樣本進行加權處理,即可得到分類的協方差j。
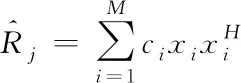
(8)
綜上,本文使用迭代加權算法建立樣本并對其進行迭代加權自適應,使后續的逐級分類更簡單,提高了后續逐級分類的精準度和分類性能。
2.2 藏文古籍迭代加權圖像信息特征提取
藏文古籍的章篇較短,所有藏文古籍會累積出大量的圖像信息,圖像信息會導致獲得的向量空間維度較高。藏文古籍迭代加權信息特征提取的難度在于特征圖像的選擇和權值計算。藏文古籍的特征空間維度過大,會干擾逐級分類的精準度與效率,所以在進行分類時,需調低藏文古籍迭代加權圖像信息的空間維度,挑選出可以為分類提供較大貢獻的圖像信息,從而進行特征提取。
對藏文古籍迭代加權圖像進行特征提取時,需計算出藏文古籍圖像的頻率,計算公式如下所示
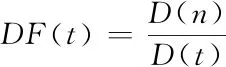
(9)
其中,D(n)表示藏文古籍迭代加權圖像特征的問本數,D(t)代表藏文古籍的數量,DF代表藏文古籍迭代加權圖像頻率。DF代表經過計算藏文古籍的復雜度來測出藏文古籍文本信息特征,復雜程度越低,適用性越廣泛。當復雜程度和藏文古籍總數呈線性關系時,集成速度快,有用信息少。當DF值升高時,有用信息越多。計算出藏文古籍迭代加權頻率后,需對迭代加權圖像信息與藏文古籍種類的相關性進行判斷,判斷公式如下所示。
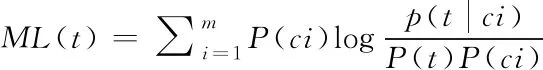
(10)
其中,ML代表藏文古籍類別和迭代加權圖像信息的關聯性,在特征選擇時擬定計算特征詞t與估計類比ci,從而判斷特征和類別的相關聯度。藏文古籍的某種類別ci出現的幾率較高,相關性就越高,P(ci)代表第i類出現的幾率,p(t|ci)代表特征詞t與估計類別ci同時出現的幾率。這種過程受邊緣幾率影響較大,可能會出現評估函數不選擇高頻而使用稀有,對后面的計算過程產生干擾。使用IG融入分類信息,融入的分類信息越多,該特征就越重要,IG融入分類用下列公式表示

(11)
式中,P(ki)代表包括特征信息的藏文古籍,P(ti)代表不包含特征信息的藏文古籍。IG相對高頻特征圖像信息的提取所含利成分越多,迭代加權特征圖像的IG值越高,對逐級分類提供的貢獻就越高。所以在對迭代圖像信息進行特征選擇時,通常提取IG值較高的特征圖像提取特征信息,定制特征向量。反之對于沒有特征信息的迭代加權圖像無法計算IG值,提取信息的精準度較低。
2.3 藏文古籍迭代加權圖像文本表示
藏文古籍迭代圖像代表對圖像文本進行形式化處理,使用計算機理解迭代加權圖像信息文本,制造索引模型。當前使用較為廣泛的模型有空間向量模型、自然圖像模型與概率模型。通過大量實驗證明,空間向量模型在表示迭代加權圖像時更有效。空間向量模型可以把大量迭代加權圖像表達為特征信息矩陣,把類似圖像變換為特征向量相似度比較,逐級分類過程將更清晰。特征信息矩陣如表1所示
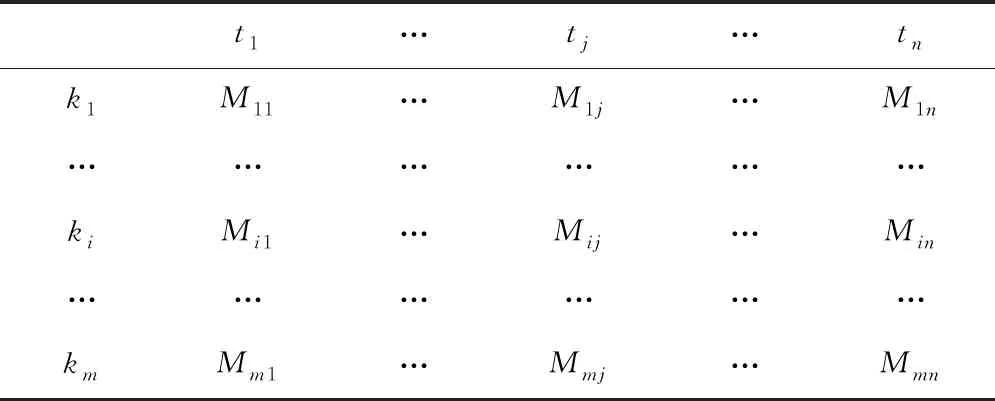
表1 特征信息矩陣
在特征矩陣中,t代表特征圖像,k代表藏文古籍,n代表藏文古籍迭代加權圖像的數量,m代表有待分類的藏文古籍,將所有古籍中的迭代加權圖像表示為三維空間中的某個點,示例k(d)=((t1,k1),(tj,k1),(tm,k1)…(tn,km)),M代表向量的特征值,經過矩陣判斷特征信息在藏文古籍內的重要性,計算出迭代加權圖像和藏文古籍的相關性。經過對迭代加權圖像賦予的概率值計算出其在藏文古籍中的貢獻程度,從而對藏文古籍進行逐級分類。
3 實驗結果分析
實驗環境為Intel Celeron Tulatin1GHz CPU和384MBSD內存的硬件環境和MATLAB6.1的軟件環境。本文實驗中,為了評測本文方法的性能,使用文獻[2]方法與本文方法進行較比。書籍樣本總數是651,共分為4類,其中每種分類區域的藏文所占比列分別是60%,40%,30%,20%。
3.1 收斂性驗證
為了更為簡單的觀察本文方法的收斂性能,給出輸出收斂性的計算公式:
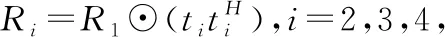
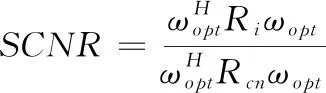
(12)
其中Rs代表目標古籍的協方差矩陣,Rcn代表迭代加權圖像的協方差矩陣。設定輸出SCNR權對SCNR最大值的差進行處理。

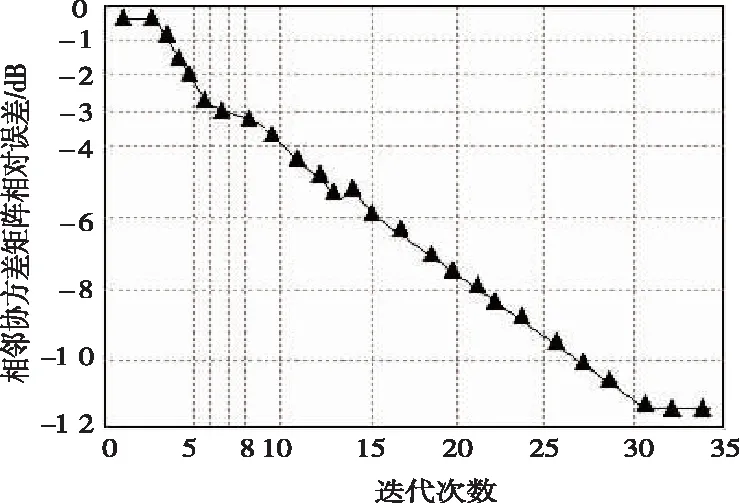
圖2 迭代加權方法收斂曲線圖
3.2 分類效果驗證
圖3是研究方法和傳統方法的逐級分類結果對比圖。分別對藏文古籍進行編碼,1-353是第一區域,354-417是第二區域,418-545是第三區域,546-641是第四區域。圖3(a)中顯示的是傳統方法的分類結果,雖然分類了所有古籍,但是第2區域與第3區域的權值顯然大于第1區域。所以,傳統方法并不會有效的對藏文古籍進行逐級分類,而圖3(b)為研究方法的分類結果圖,圖中第2區域的權值顯然要小于第1權值,第4區域和第3區域的權值則明顯小于第1區域,就是不均勻程度越高加權值就越小,這證明本文方法可以有效的逐級分類藏文古籍。
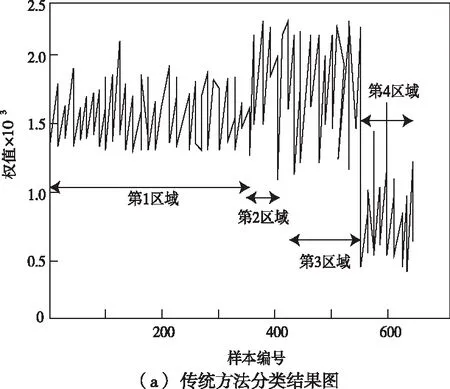
圖3 不同方法分類藏文古籍結果圖
通過上述實驗能夠看出,通過本文方法逐級分類的迭代加權圖像藏文古籍,能夠清楚看的到各階級的分類階梯,而使用傳統方法分類出的藏文古籍,區域較為雜亂并且分類并不完整。
3.3 檢索效果驗證
為進一步驗證研究方法的應用有效性,將該方法運用到實際藏文古籍檢索中。該方法可對古籍題名、作者、語種、類別及收藏情況進行篩選檢索,檢索界面如圖4所示。
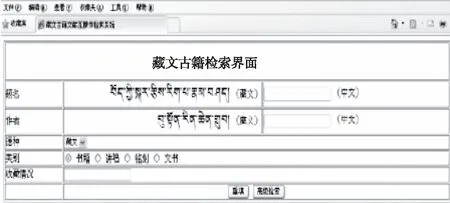
圖4 藏文古籍檢索界面
以檢索藏文著作《藏歷時論學智者生悅論》為例,運用迭代加權圖像的藏文古籍逐級分類方法進行檢索。結果表明該方法能快速有效地進行分類檢索,且分類層級明晰,說明對藏文古籍檢索是有幫助的。檢索結果如圖5所示。

圖5 檢索結果
3.4 分類時間對比
為了進一步驗證研究方法分類藏文古籍的有效性,利用傳統方法與研究方法對逐漸增加的1600份藏文古籍樣本進行分類,對比兩種方法的分類時長。具體實驗結果如圖6所示。
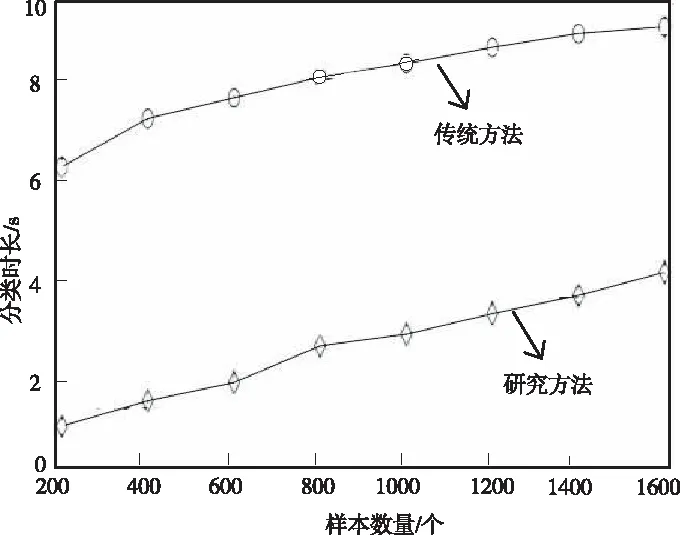
圖6 不同方法分類藏文古籍時長結果圖
通過上述實驗能夠看出,兩種方法的分類時長隨著藏文古籍樣本增多而增加。在樣本數量個數為200個~1600個區間內,傳統方法的分類時長約為6~10s,而研究方法的分類時長約為1~4s,遠遠小于傳統方法的分類時間。說明本文基于迭代加權圖像的藏文古籍逐級分類方法能對藏文古籍進行高效分類,具有一定的科研意義。
4 結論
針對藏文古籍分類中存在的分類不完整和分類效率低的問題,本文提出了一種基于迭代加權圖像的藏文古籍逐級分類方法。該方法首先使用迭代加權算法,基于藏文古籍構建出迭代加權模型,從而使其自適應處理需要大量訓練樣協方差矩陣,然后通過訓練出協方差矩陣和廣義內積進行融合,之后對迭代加權圖像進行計算,從而改進后續分類時出現的分類準度下降問題,最后通過對藏文古籍迭代加權圖像進行信息特征提取,來達到逐級分類的目的,實驗證明本文方法,能夠完整的對藏文古籍進行逐級分類,并且分類的速度較為迅速。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
