基于稀疏度自適應的視覺圖像三維清晰重構
2021-11-17 03:56:32馬麗茵
計算機仿真 2021年3期
關鍵詞:方法
石 磊,馬麗茵
(北方民族大學,寧夏 銀川 750021)
1 引言
人類通過視覺系統獲取大量的外界信息,其中圖像信息占主要部分[1]。在信息處理領域中圖像處理技術是重要內容,人們對圖像分辨率的要求隨著圖像在不同行業中的廣泛應用不斷提高[2-3]。圖像分辨率成為重要指標可以對圖像的質量進行衡量。由于系統噪聲、大氣振動、離散采樣、成像器件與目標之間存在的相對運動等影響,會降低圖像分辨率,導致在實際應用過程中采集的圖像都無法滿足人們的需求[4-5]。為了提高圖像的分辨率,需要對圖像進行三維重構處理。
文獻[6]提出基于非局部全變差的圖像三維重構方法,該方法根據目標圖像結構與參考圖像結構之間存在的相似性,獲得小波域中圖像的搜索集,將其作為范數,利用非局部全變差建立圖像重構目標函數,并采用快速合成分離算法對目標函數求解,實現圖像的三維重構,該方法沒有對圖像進行去噪處理,導致圖像的峰值信噪比較低。文獻[7]提出基于卷積神經網絡的圖像三維重建方法,該方法利用銳化方法和差值方法對圖像進行預處理,通過差值操作獲得圖像的三維矩陣,在深層殘差網絡中輸入三維特征映射獲得圖像紋理細節信息,通過亞像素卷積操作實現圖像的三維重構,該方法對圖像進行預處理時沒有保留圖像的細節信息,導致圖像分辨率較低。文獻[8]提出基于殘差神經網絡的圖像重構方法,該方法建立殘差神經網絡結構對圖像做壓縮處理,通過上采樣獲得特征圖,并對特征圖進行優化,融合優化后的特征圖實現圖像的三維重構,該方法在重構過程中受噪聲干擾較為嚴重,增加了重構時間,存在重構效率低的問題。
為了解決上述方法中存在的問題,提出基于稀疏度自適應的視覺圖像三維清晰重構方法。
2 視覺圖像去噪處理
基于稀疏度自適應的視覺圖像三維清晰重構方法在非局部相似性原理的基礎上提取相似圖像塊并對其進行分組,通過核回歸系數獲取圖像中存在的集合信息,建立每組圖像塊的字典。將圖像分為邊緣、平滑和紋理三個種類,根據噪聲水平和分組類型設計字典對應的原子大小,融合字典獲得變分模型,通過變分模型實現圖像的三維重構。
1)圖像分組


(1)
式中,ga代表的是高斯核函數,其標準差為a;h代表的是衰減系數,可以對函數的衰減速度進行控制;u0代表的是灰度值方差;Ω2代表的是局部區域,其中心點為(i,j)。分析上述公式可知,可以利用歐幾里得距離衡量兩個局部區域在視覺圖像中的相似度[9]。w(i,j),(i′,j′)的值隨著歐幾里得距離的減小而增大。
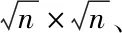
fi=[λyi+(1-λ)wi]
(2)
式中,λ代表的是權重因子,在區間(0,1)內取值。采用K-means聚類算法劃分圖像塊,由G組圖像塊構成噪聲圖像Y:

(3)
2)建立原子尺寸字典
根據每組圖像的結構特征,建立對應的字典,稀疏表示圖像,圖像去燥模型的表達式如下

(4)
式中,i描述的是圖像組對應的序號;m描述的是塊在第i個圖像組中對應的序號;Di代表的是字典,通過第i個圖像組所學習獲得;Ai描述的是稀疏編碼系數。
每幅視覺圖像通常由紋理細節、邊緣細節和平滑區域構成,利用不同原子尺寸的字典處理圖像的每一部分,提高圖像的去噪效果。
基于稀疏度自適應的視覺圖像三維清晰重構方法采用的字典學習算法由以下兩個步驟構成:
①劃分圖像信息。
②在圖像分組的基礎上確定原子尺寸。
圖像組的整體信息可以通過圖像組Yg對應的質心ygc進行描述,其計算公式如下
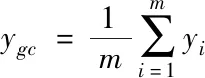
(5)
基于稀疏度自適應的視覺圖像三維清晰重構方法通過基于數理統計的變化稀疏對圖像中區域的同質性進行測量,提高圖像分組的精準度。變化系數cv(i)的計算公式如下
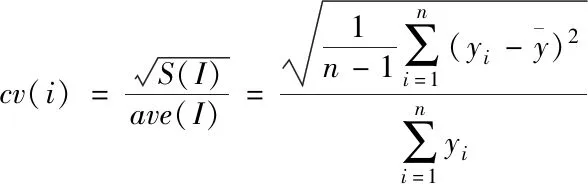
(6)
式中,I為正方形區域,其中心為yi。同質性隨著變化系數的增大而變小。根據變化系數cv(i)的計算結果對圖像塊進行分類,將其分為邊緣范疇、平滑區域范疇和紋理范疇。
計算每個圖像組對應的原子尺寸,圖像中存在的邊緣細節和紋理細節可以通過小原子尺寸的字典得以保留,平滑區域圖像中存在的較大噪聲和原始信號可以通過較大原子尺寸的字典進行區分,提高去噪效果[10]。利用加權稀疏對圖像組的字典原子尺寸進行計算
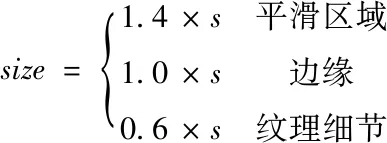
(7)
式中的系數s可通過噪聲均方差σ進行確定。
3)建立變分模型


(8)
上式的左邊第一項為數據保真項;R(α)描述的是限定解空間中存在的正則項。
考慮子信道pp′,qq′,根據式(17)可得到信道時變互相關性.圖6和7分別是t=0和2 s時的歸一化信道互相關性.圖6和7表明,信道互相關性隨時間發生變化,因此具有時變特性.當發射天線陣間隔固定時,隨著接收天線陣間隔增加,信道互相關性下降.而當接收天線陣間隔固定時,隨著發射天線陣間隔增加,信道互相關性呈現波動特性.
3 視覺圖像三維清晰重構
3.1 K-SVD字典訓練
基于稀疏度自適應的視覺圖像三維清晰重構方法通過K-SVD字典訓練算法訓練類型不同的圖像樣本。
可利用下式優化問題描述K-SVD字典的訓練實質
(9)
式中,T0代表的是非零元個數在稀疏系數中的最大值;Y代表的是樣本集;X代表的是稀疏矩陣;D代表的是超完備字典。
K-SVD字典訓練算法的主要步驟如下:
1)為字典D賦值。
2)采用追蹤算法結合字典D對樣本yi對應的稀疏系數向量xi進行計算。
3)利用xi對字典D進行更新,設dk代表的是字典D更新后存在的第k列原子;Ek代表的是誤差矩陣,其計算公式如下
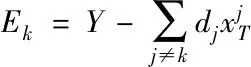
(10)
通過下述公式描述樣本集分解后的形式
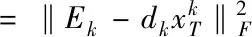
(11)
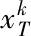

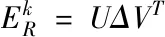
(12)

當稀疏誤差達到收斂值或達到限制迭代次數時,停止迭代,獲得最終的訓練字典D。
3.2 感知矩陣
感知矩陣A=Rψ在大部分情況下需要符合限制等距性條件,即對于所有常數δk∈(0,1)和K-稀疏信號α,感知矩陣都要符合下式:
(1-δk)‖α‖2≤‖Aα‖2≤(1+δk)‖α‖2
(13)
基于稀疏度自適應的視覺圖像三維清晰重構方法利用超完備字典替換正交變換基,在上述背景下,感知矩陣可描述為A=RD。為了滿足限制等距性條件,基于稀疏度自適應的視覺圖像三維清晰重構方法選用互相干MC代替感知矩陣,設μ(A)代表的是感知矩陣A對應的互相干,其計算公式如下
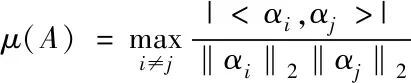
(14)
式中,αi代表的是感知矩陣A中存在的第i列向量。

(15)
存在下式
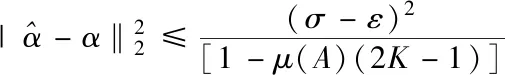
(16)
上式描述了互相干參數、稀疏度和重建性能之間存在的關系。
3.3 匹配跟蹤
在圖像重構階段基于稀疏度自適應的視覺圖像三維清晰重構方法將logistic回歸函數引入正則化正交匹配追蹤算法中,利用引進的函數計算原子對應的閾值Tn

(17)
原子在每次迭代中都滿足|ui|≥Tn·max|u|。
視覺圖像三維清晰重構的過程如下:
1)計算感知矩陣與殘差之間存在的相關系數u={uj|uj=
2)通過logistic函數獲取原子對應的閾值Tn[12],選擇的原子候選集J需要符合|uj|≥Tn·max|uj|。
3)正則化處理候選集J中存在的子集J0。在符合|ui|≤2|uj|的子集中選擇存在最大能量值的子集。
4)對索引集進行更新。

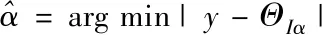
(18)
4 實驗結果與分析
為了驗證基于稀疏度自適應的視覺圖像三維清晰重構方法的整體有效性,需要對基于稀疏度自適應的視覺圖像三維清晰重構方法進行測試。實驗過程中用到的視覺圖像為Bandrill、Barbara、Lena,上述圖像均為512*512,在MATLAB R2010a環境中進行實驗,硬件條件為內存4.0GB,頻率3.30GHz,Intel(R)Core(TM)I3-2120CPU。分別采用基于稀疏度自適應的視覺圖像三維清晰重構方法(方法1)、基于非局部全變差的圖像三維重構方法(方法2)、基于卷積神經網絡的圖像三維重建方法(方法3)通過峰值信噪比和重構速度兩個參數進行測試。
圖1為分塊大小為16*16的Bandrill、Barbara、Lena圖像在采樣率不同時,不同方法重構時間和峰值信噪比的對比結果。

圖1 不同采樣率條件下各種方法性能圖
分析圖1可知,方法1在采樣率低于0.5時可在較短的時間內獲得良好的圖像重構結果。方法2和方法3的重構效果隨著采樣率的增大明顯提升,但運行時間較長,因為方法2需要確定圖像信號的稀疏度,方法3需要根據視覺圖像的噪聲水平計算閾值,以上兩種系數是不存在于視覺圖像中的,因此花費了較長的時間。方法1在重構視覺圖像之前,結合變分模型和學習字典對圖像進行去噪處理,消除了噪聲對圖像重構產生的干擾,縮短了重構時間,提高了峰值信噪比。
為了進一步驗證方法的整體有效性,將圖像分辨率作為測試指標,圖像分辨率越好,表明圖像的重構質量越高,方法1、方法2和方法3的圖像分辨率如圖2所示。
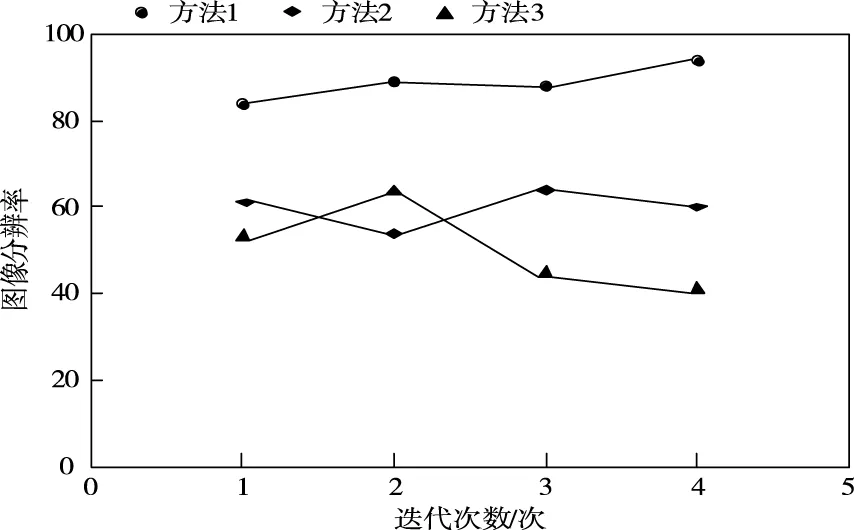
圖2 不同方法的圖像分辨率結果
分析圖2中的數據可知,方法1在多次迭代中的圖像分辨率均高于方法2和方法3,因為方法1在去噪過程中利用小原子尺寸字典保留圖像中存在的邊緣和紋理細節信息,利用較大原子尺寸的字典區分圖像中的噪聲和原始信號,提高了圖像的去噪效果,進而提高了圖像的分辨率。
5 結束語
在圖像處理過程中圖像重構是重要部分,圖像重構的本質是有效地重建圖像中存在的局部破損信息,使重構圖像的整體視覺效果接近原始圖像。在特技渲染、機器視覺、圖像解壓縮、視頻修復等領域圖像重構具有重要的應用價值和研究意義。目前視覺圖像重構方法存在峰值信噪比低、重構時間長和圖像分辨率低的問題,提出基于稀疏度自適應的視覺圖像三維清晰重構方法,結合變分模型和學習字典對圖像進行去噪處理,采用稀釋度自適應正則化正交匹配追蹤算法實現視覺圖像的三維重構,提高了峰值信噪比,縮短了重構時間,增強了圖像分辨率,為后續的圖像處理過程奠定了基礎。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
