基于Python爬蟲技術的虛假數據溯源與過濾
2021-11-17 03:12:50周力臻
計算機仿真 2021年3期
陳 叢,周力臻
(福建師范大學協和學院,福建 福州 350117)
1 引言
隨著嵌入式計算與傳感器技術的不斷發展,推動了無線傳感網絡的迅速崛起,并廣泛應用于軍事、醫療、建筑等領域[1]。與傳感網絡不同,無線傳感網絡將海量廉價小型傳感器節點隨機布置在不同區域,利用自組織形式生成網絡,同時采用多跳方式將信息傳輸給用戶,每個節點都具有數據采集、處理、定位與連接等功能。但無線傳感網絡屬于開放式網絡,其計算性能、儲存空間較為有限,抗捕獲能力較弱,攻擊者可通過捕獲節點獲得其中敏感信息,并對其注入虛假數據,如果不能及時過濾掉這些虛假數據,則會導致網絡癱瘓,引發錯誤報警,影響用戶決策[2]。為此,該領域研究者對該問題進行了很多研究,并取得了一定成果。
文獻[3]提出基于能量感知路由和節點過濾的虛假數據過濾方法。該方法將距離與能量相結合,提出能量感知和節點過濾方法。與傳統密碼交換機制不同,該方法在會話構建前有策略的將重點密鑰傳輸到部分節點中,而不是全部節點;在選擇過濾節點時不但參考距離,且綜合分析節點剩余能量與密鑰傳播信息,有效過濾虛假數據,更好的均衡網絡能耗。該方法可有效根據部分節點進行過濾,但該方法過濾的數據覆蓋范圍存在一定局限。文獻[4]提出多路虛假數據分層過濾方法。該方法在完成網絡布置后,對每個節點分配相應密鑰,利用密集認證方式建立封閉區域,并通過密鑰明確簇內節點和驗證節點之間的關系,轉發需要檢測的數據包,判定其包括的節點碼、哈希值等信息是否正確;根據sink節點對數據包進行對比與丟棄,以此實現多路虛假數據分層過濾。該方法可以準確過濾掉虛假數據,但對網絡虛假數據出現的溯源追蹤與定位考慮甚少。
基于上述方法存在的不足,本文利用Python爬蟲技術進行虛假數據溯源與途中過濾。爬蟲技術通過一定規則自動抓取網頁信息的一種程序。其目的是將目標數據下載到本地,便于后續分析。Python語言是一種較為簡潔的開源編程式語言,具有標準庫與第三方庫,用戶可結合自己喜好選取最適合的編輯工具來編寫爬蟲程序。本文設計了Python爬蟲系統,利用該系統生成數據包,實現虛假數據溯源與途中過濾。與傳統方法相比可以有效追蹤虛假數據的溯源,且過濾的數據范圍較大,具有一定優勢。
2 虛假數據覆蓋的網絡劃分
為了實現網絡虛假數據的溯源與途中過濾,本文首先對虛假數據所處的網絡環境進行劃分。將虛假數據網絡覆蓋部分分割為同樣大小的網格,任意一個節點均有固定監測范圍,在此范圍內發生的全部狀況都能被節點感知。其中,網格便是監測網格。此外節點根據設置的概率,隨機挑選多個不在自身監測范圍內的網絡,將其作為認證網格,節點對認證網格發生的狀況進行驗證。網絡劃分情況如圖1 所示。

圖1 虛假數據覆蓋的網絡劃分
圖1 中,存在L個主密鑰組,節點必須加入其中一個密鑰組,并利用此組中的密鑰生成監測和認證網格相對的密鑰。若某事件發生時,由該事件節點形成數據報告;然后,節點使用其掌握的事件發生地點密鑰為詞條數據增添消息認證碼MAC(Message Authentication Code)。
每條合法的數據報告需包含T個MAC,且形成這T個消息認證碼節點必須出自不同密鑰組。當途中節點接收數據報告后,需明確事件發生地址,結合掌握的密鑰斷定是否對數據報告進行檢測與認證。如果不對其認證,則根據一定概率對數據包進行標記[5],并轉發此數據報告;如果認證失敗,直接丟棄此數據報告。通過對虛假數據覆蓋的網絡劃分,明確其存在的位置以及設置相關密鑰,降低算法復雜度。
3 基于Python爬蟲的虛假數據溯源與途中過濾
3.1 Python爬蟲系統設計
3.1.1 爬蟲抓取過程分析
網絡爬蟲是開發者編寫的計算機程序或腳本[6],利用設置的規則,在上述構建的網格中向蜘蛛網一樣對網頁不停擴張,從中獲取目標數據的過程,其抓取過程如圖2所示。

圖2 網絡爬蟲抓取過程
由圖2可知,抓取過程是一個循環執行過程,經過不停循環獲得新的網頁信息。以鏈接構成的集合作為種子源,將其放入待爬取隊列中,按照設置的規則從中選取某個鏈接,并將請求發送到遠程服務器,等待服務器返回內容;爬蟲得到網頁信息后,對內容進行解析,提取重要數據儲存在數據庫中。此外,獲取新的超鏈接,經過去重處理,進入新一輪數據提取。
3.1.2 系統需求分析
利用Python語言設計的爬蟲系統能夠為不同領域用戶提供數據采集服務的通用型系統。為達到一定效果,系統需具備下述功能:
1)適用較多采集場景:系統設計需適用于不同場景,為不同用戶提供服務。
2)界面可視化:結合使用場景,設計圖形化界面,確保用戶在瀏覽信息同時,記載用戶操作的相關信息,生成爬蟲任務腳本。
3)執行爬蟲任務:將腳本信息變為能夠識別的內容,結合指令驅動[7],完成數據提取。
4)負載均衡:需針對不同性能機器分配適當任務量。
3.1.3 Python爬蟲系統設計
Python爬蟲系統硬件結構分為客戶模塊、服務模塊、爬取模塊與儲存模塊,如圖3所示。
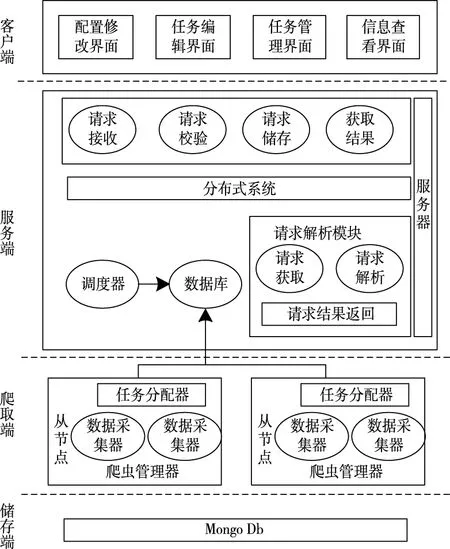
圖3 爬蟲系統整體架構
其中,客戶端是系統交互的入口,提供編輯、任務管理、信息查看等界面。服務端對客戶請求及時處理,執行爬蟲任務的分配與調度工作。
為追溯虛假數據,降低不同模塊之間耦合度,對該系統的硬件部分進行設計。
1)爬蟲管理器:該管理器對物理節點啟動提供適當虛擬節點。結合節點負載狀況,對虛擬節點數量進行調整,確保節點以最佳狀態執行爬取任務,簡化系統負載程度。
2)爬蟲采集器:主要任務為數據采集。包含任務解析與數據管理子模塊。
3)內嵌瀏覽器:利用QT(Qualification Test)框架作為內嵌瀏覽器,采用Qpush Button部件設置訪問按鈕,確保信息鏈接和網頁相互對應。
在上述硬件設置后,對系統軟件運行機制進行設置。從系統爬取數據角度描述系統軟件各模塊如何協作,如圖4 所示。
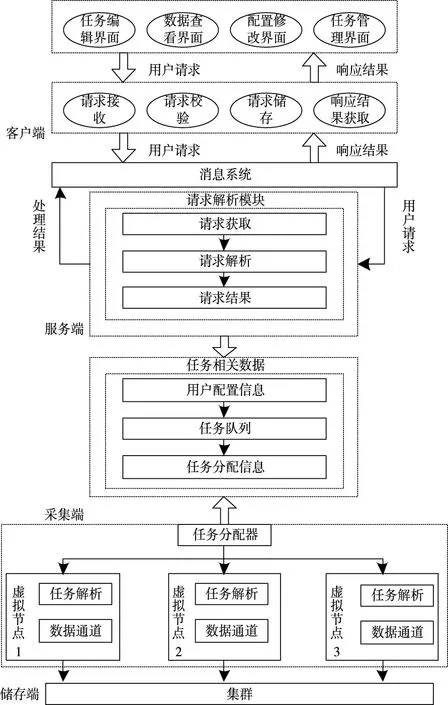
圖4 軟件運行機制
3.2 關聯建立與密鑰分配
根據上述構建爬蟲系統,通過密鑰分配生成數據包,分析密鑰驗證的合法性,實現虛假數據溯源與途中過濾。
假設存在大小未是N的全局密鑰池G,將其等分為n個不重合的分區{Ui,0≤i≤n-1},任意一個分區密鑰數量表示為m(N=n×m)。在部署區域將節點任意挑選一個分區進行保存,將此種密鑰設為R型密鑰。
在完成節點部署后,若某節點的ID最小,將此節點當作簇頭CH。由于感知半徑大于傳輸半徑,因此,設簇內全部節點可以同時感知發生事件。CH采集簇內數據生成hello包:{y,CH,S1,S2,…,Sy},y表示計數器,原始值是簇內節點數量,S1,S2,…,Sy為簇中節點。
CH將hello向sink方向傳輸,傳輸跳數取決于y。首個中轉節點Si接收包后,刪除節點數最后一位,記錄Sy。Si與Sy是一對協作節點,Si處于上游,而Sy為下游。Si將自身節點號插入節點數組首位,并轉發數據包,繼續執行爬蟲過程,此時計數器y減去1。
hello數據包傳輸y跳后停止操作,位于最后的中轉節點Sj形成一個僅包括其本身節點的ACK包:{Sj},且將其按照hello數據包的方向進行傳輸。中轉階段順次將自身節點引入到數據包末位,簇內節點從包中ACK記載協作節點序號[8-9]。
協作節點間利用消息共享一對密鑰,密鑰類型表示為A′。簇內節點隨機挑選一個R型密鑰對A‘密鑰進行加密,同時傳輸給簇頭,簇頭將這些信息壓縮再傳輸到sink節點。構建協作關系的區域可以對數據進行認證,將其稱作封鎖區。
3.3 虛假數據包的生成
在建立關聯后,如果檢測到突發事件,簇頭將感知值傳輸給每個簇中的節點。獲得信息的節點S將感知數值與設定的閾值e比較,如果低于設定閾值,認為兩個數據相同,并任意選出一個R型密鑰與其A型密鑰生成簽名:MR,MA,將其傳輸給簇頭,當簇頭采集t個節點簽名信息后形成數據報告
R0={C;e;R1,R2,…,Rt;MR1,MR2,…,MRt
A1,A2,…,At;MA1,MA2,…,MAt}
(1)
式中,C表示跳數計數器,其原始值表示為y;R1,…,Rt屬于R型密鑰,MR1為密鑰R1生成的MAC;A1…At描述節點號,MA1是A1節點利用對偶密鑰生成的MAC。利用布隆過濾器[10]將兩種MAC映射為d比特字符串,即
F=b0,b1…bd-1
(2)
則生成的虛假數據包為
R={C;e;R1,R2,…,Rt;A1,A2,…,At;F1;F2}
(3)
式中,t的取值是過濾性能與能耗情況的折中。
3.4 虛假數據溯源過程
當sink節點獲得數據包后,使用共享密鑰證明MAC是否合法,如果不合法,啟動溯源過程。
當檢測到存在虛假數據時,選擇新的虛假數據包,向上一跳傳輸一個查找請求信息Q,當節點A1收到消息后,查詢緩沖區域,并對信息Q進行廣播,其鄰居節點獲取查詢信息后,檢查緩沖區日志,若沒有查詢到有關內容,則不發送應答信息ACK;若查找到有關內容u.a[i].SrcID==Q.SrcID,則利用sink節點共享密鑰生成Mu,即

(4)
并將應答信息傳輸到A1,傳輸過程描述為

(5)

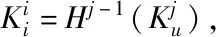
當節點A1獲得全部應答信息后,斷定各信息中A1的前一跳節點是否一致,根據緩沖區查詢結果,挑選與前一跳節點相同的查詢結果,并將回復信息傳輸到sink節點。A1傳輸到sink節點的回復消息形式為
A1→sink=IDu1,…,IDut,IDd1,IDd2,Q.SrcID
Q.Seqno,Mu1,…,Mut
(6)
當sink節點獲得上游節點回復的信息后,必須斷定信息中是否包括節點認證,再結合共享密鑰驗證信息的合法性,經過驗證后,獲取IDd1與IDd2值。當獲得全部回復信息后,可以重構路徑,溯源到虛假數據。
3.5 虛假數據的途中過濾
在Python爬蟲系統中,虛假數據途中過濾詳細步驟為:
1)核對數據包內是否存在t對{Rk,MRk};{Ak,MAk}元組,如果不存在則將數據包刪除;
2)核對數據包內t個R型密鑰是否出自t個不同區域,若不存在,則刪除數據包;
3)如果節點具有數據包內一個R型密鑰,則使用此密鑰重新獲得R型MAC,且與數據包內原有MAC進行比較,若不同則刪除數據包;
4)如果節點中不具有任何一個密鑰,則將數據包直接過濾,實現虛假數據的過濾。
4 仿真分析
4.1 仿真環境及參數
本文使用C++語言構建模擬仿真平臺,在一個半徑為100 m區域內,隨機布置1000個傳感器節點,主密鑰數量設置為6個,在圓形監測區域內,源節點與sink節點分別布置在圓心與圓的四周。具體仿真參數如表1所示。

表1 仿真參數
4.2 仿真方案
在上述仿真環境下,通過對比所提方法、基于能量感知路由和節點過濾以及傳感器網絡多路虛假數據分層過濾方法,以虛假數據途中過濾效果、虛假數據過濾的覆蓋性以及虛假數據追蹤定位準確性為指標,驗證所提方法的科學有效性。
4.3 實驗結果
4.3.1 虛假數據途中過濾效果
在虛假數據途中過濾效果分析中,通過分析虛假數據途中過濾比例與傳輸跳數之間的關系,反映方法的過濾效果。實驗對比了所提方法、基于能量感知路由和節點過濾方法以及傳感器網絡多路虛假數據分層過濾方法的過濾效果,如圖5 所示。
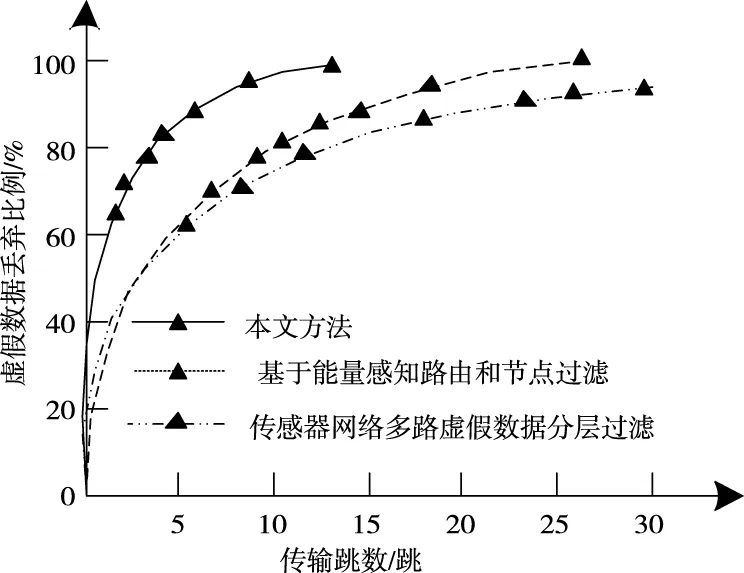
圖5 虛假數據途中過濾效果分析
分析圖5中可以看出,利用本文方法時,虛假數據的大部分在前5跳即可被過濾,而其它數據也在前15跳全部過濾完成,而其它兩種方法在前5跳基本無法過濾虛假數據,在15跳后仍有數據沒有被過濾。相比之下所提方法途中過濾性能明顯優于其它兩種方法。
4.3.2 虛假數據過濾范圍覆蓋性能分析
實驗分析了所提方法、基于能量感知路由和節點過濾方法以及傳感器網絡多路虛假數據分層過濾方法在過濾時的覆蓋性能,將部署區域的網絡節點數量分別設置為1000、2000和3000個,在每種情況下分別進行100次實驗。實驗結果如表2 所示。
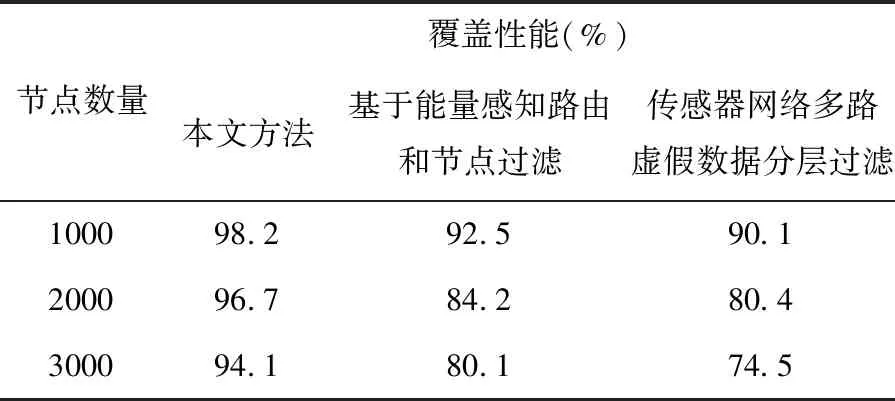
表2 不同過濾方法覆蓋性能對比
由表2可知,隨著節點數量的不斷增長,本文方法的覆蓋性能始終保持較高水平,而其它方法覆蓋性下降較快,導致虛假數據過濾效果不理想,驗證了所提方法的有效性。
4.3.3 虛假數據追溯跟蹤定位精度分析
實驗采用三種方法對虛假數據進行溯源定位,比較虛假數據成功定位的概率,實驗結果如圖6 所示。
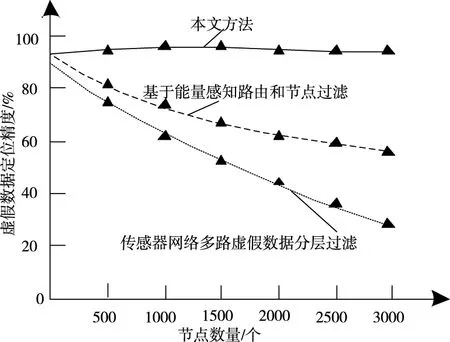
圖6 不同方法追溯跟蹤性能對比
從圖6中可以看出,所提方法對虛假數據定位的精度更高,始終高于90 %,而其它兩種方法定位精度呈現下降趨勢,且始終低于所提方法,這是由于所提方法利用Python爬蟲系統對虛假數據進行溯源,收集更多數據報告,提高成功定位的精度。
5 結論
針對傳感器虛假數據的注入,利用Python爬蟲技術設計爬蟲系統,建立封鎖區域、生成數據包以及判斷數據是否合法啟動溯源程序,并對虛假數據進行途中過濾。與傳統方法相比具有以下優勢:
1)采用所提方法對虛假數據中途過濾的效果較好,且過濾的覆蓋性能具有一定優勢。
2)采用所提方法對虛假數據溯源的定位精度始終高于90 %,具有一定可信度。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
