關于點擊率大數據的高階深度分解機預測仿真
2021-11-17 04:00:12張換梅董云云
計算機仿真 2021年3期
張換梅,董云云,2
(1.晉中學院計算機科學與技術學院,山西 晉中 030619;2.太原理工大學信息與計算機學院,山西 太原 030024)
1 引言
互聯網與云計算在提供豐富業務功能的同時,產生海量中間數據,網絡應用通過數據收集、提取和分析,從中獲取所需信息,對用戶進行畫像,從而完成業務的精準投放。尤其對于電子商務、移動、搜索引擎等互聯網場景,大量收集用戶數據,處理過載信息,并完成用戶模型預測,是其業務優化與收益增長的重要手段。其中,點擊率(Click-through Rate,)是目前互聯網應用中主要的數據過濾方式[1-2],但是在多源異構的海量數據分析中,預測模型和方案需要具有良好的動態時變特性,從而滿足推薦業務要求。對于大數據的預測,就是根據數據集的學習,得到一種映射關系。在點擊率預測時,其映射輸出分為點擊與不點擊,即輸出具有離散性[3]。當系統較為線性時,通常可以采用邏輯回歸[4]方案對數據進行預測,并在邏輯回歸基礎上,采取似然估計或其它方式對預測模型進行計算。這種方案雖然簡便高效,但是不能分辨數據間的非線性關聯和高階特征。于是,在非線性系統中,通常引入多項式回歸方案[5]。利用映射關系來描述多階系統,基于這種映射關系,可以對數據特征的耦合關聯進行深入學習,但是可能引發特征數量與維度的泛濫,難以處理高階和稀疏情況。由于分解機[6]能夠避免大量特征耦合關聯權重的學習計算,同時具有良好的稀疏數據處理性能,因此,本文設計一種高階深度分解機點擊率數據預測方法。在分解機設計時,利用特征耦合性替代傳統的權重關系,提高對交互特征和稀疏特征的描述精度;同時采取映射二次項轉換來降低特征映射復雜度,從而使分解機能夠向高維擴展。基于高階分解機,將與結合構造了深度學習網絡,并引入對比散度和對學習網絡的樣本訓練性能做進一步優化。
2 高階分解機特征映射模型
針對數據特征耦合情況,在分解機算法中引入隱向量,取代權重計算,利用其長度來改變系統變量。對于只有兩特征耦合的情況,分解機的映射關系描述如下

(1)
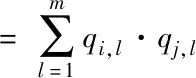
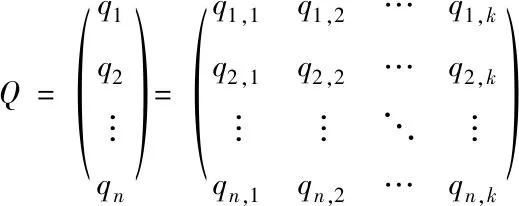
(2)
當隱向量的大小是k,分解機的特征映射復雜度表示為O(kn2)。為了降低復雜度,改善其多階性能,把映射二次項采取如下轉換
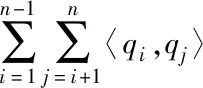
(3)
轉換后的特征映射復雜度是O(kn)。優化之前,當數據量增加時,復雜度呈指數增長;優化之后,當數據量增加時,復雜度呈線性增長,顯然更有利于大數據的處理。
兩特征耦合符合稀疏數據場景,即耦合變量不充足,通過隱向量與系數矩陣能夠有效描述特征交互關聯,有利于提高預測效果。根據二階分解機,很容易將其應用于高階場景。于是,三階分解機的映射關系如下

(4)
式中,qi,k、qj,k構成系數矩陣Q;pi,k、pj,k、pl,k構成系數矩陣P。此時,為保持線性復雜度,對其映射三次項采取如下轉換
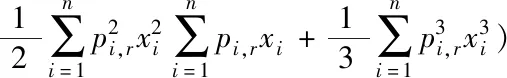
(5)
在進行模型學習時,考慮到點擊率的二分類特性,在特征預測的過程中設計損失函數如下
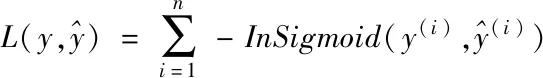
(6)
式中Sigmoid(·)函數用于把輸入數據映射至輸出結果二值類上,它的計算方式為Sigmoid(x)=(1+e-x)-1。
分解機特征映射模型的計算變量為w0、wi、系數矩陣Q。在經過映射模型轉換后,對其采取SGD方法訓練,通過損失函數求偏導得到變量梯度更新方式
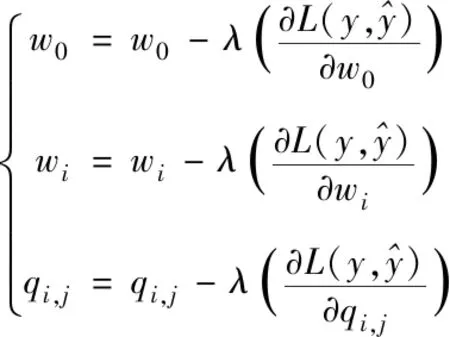
(7)
式中的λ代表學習率。在點擊率二分類情況下,損失函數的偏導計算方式如下
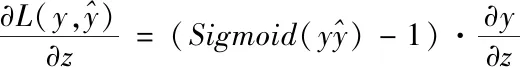
(8)
于是,二階特征預測變量的梯度描述為

(9)
對于三階映射模型,偏導計算后其特征預測變量的梯度描述為
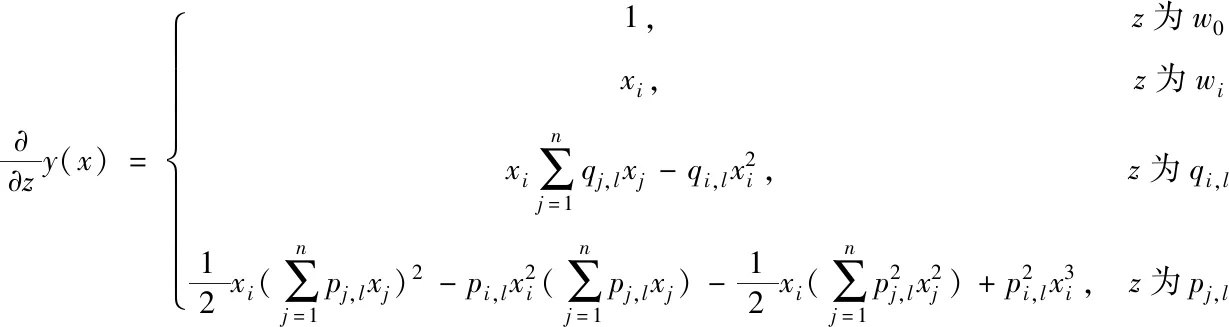
(10)
由梯度計算可知,特征預測復雜度也是O(kn)。從模型映射到特征預測都具有線性復雜度,有利于大數據處理效率。預測模型的階數并不是越高越好,二階處理適用于數據屬性為非線性的情況,三階處理適用于屬性耦合較強的情況。另外,由于本文將分解機與深度學習結合,階數過高不利于學習,所以三階以上的分析意義不大。
3 深度網絡學習
本文采用BP神經網絡與RBM構造深度學習網絡,RBM是一種無向圖,圖1描述了它的拓撲。其中,q代表顯式層,c代表隱式層,W代表q與c的耦合權值。系統輸入數據由q層進入,在c層完成特征處理。
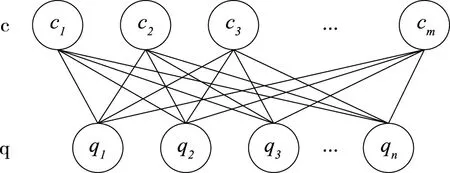
圖1 RBM拓撲結構
考慮到RBM缺乏監督學習,為了彌補RBM的此缺陷,深度學習網絡設計為若干層RBM與單層BP網絡,圖2為深度學習網絡模型。利用RBM實現數據特征識別操作,利用BP神經網絡實現特征分類操作。輸入數據首先經過多層RBM訓練,將特征識別結果送至BP神經網絡層做最后的分類處理,BP神經網絡層還會對網絡參數采取適當調整,從而優化網絡參數。
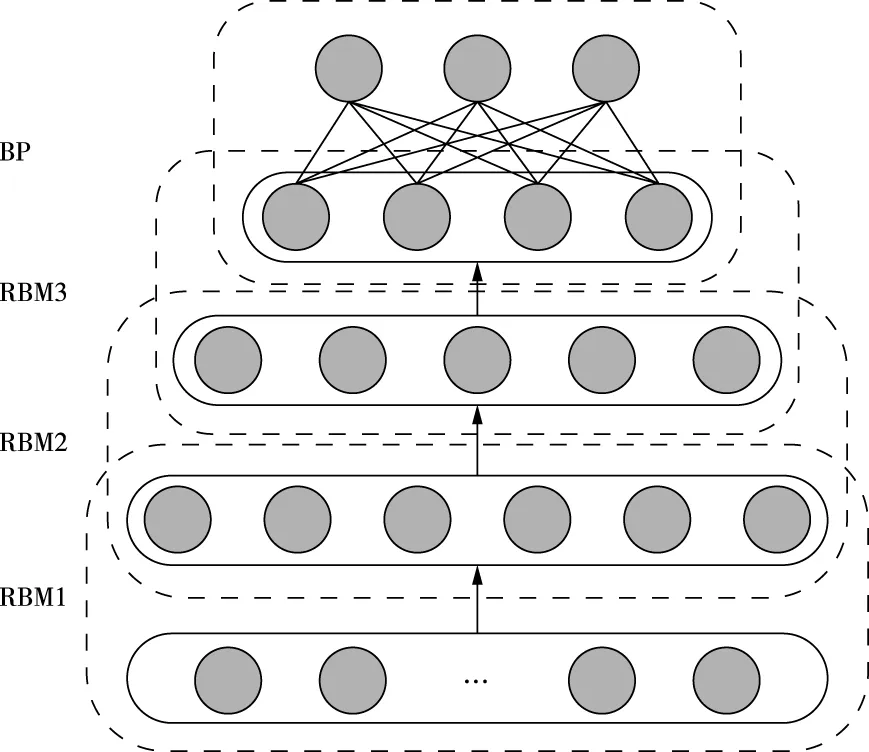
圖2 深度學習網絡模型
在RBM網絡中,將隱式層的偏置記作offq,顯式層的偏置記作offc,則根據顯式層能夠推導出隱式層,公式如下
(11)
因為RBM網絡具有對稱性,所以根據隱式層也能夠推導出顯式層,公式如下
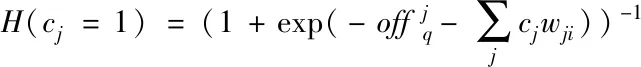
(12)
輸入集合q在經過RBM網絡處理后輸出集合c,RBM網絡利用集合c與式(11)推導出隱式層集合q′,并與輸入集合q比較得到偏置。網絡訓練過程就是搜索出最優的輸入輸出聯合概率p(q,c)。為了得到p(q,c),這里首先計算輸入輸出的能量,公式如下

(13)
根據RBM輸入輸出能量,得到其聯合概率如下
p(q,c)∝exp(E(q,c))
(14)
然后計算RBM網絡的梯度,公式如下:
(15)
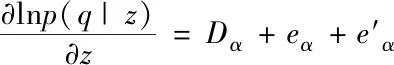
(16)
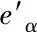
在進行點擊率深度網絡學習時,為避免發生過擬合,在BP神經網絡層采用Dropout機制,該機制神經網絡原理如圖3所示。Dropout機制就是在學習階段將所有神經元都賦予對應的活躍概率pa,其中任何神經元可能處于活躍狀態或者失活狀態,定義其理想輸出是pax。當神經元處于活躍狀態時,采用活躍概率作為它在網絡中的權值。同時,Dropout機制還會利用隨機方式選取神經元,與其它神經元進行協作,降低彼此共適能力,最終防止過擬合情況的發生。

圖3 Dropout機制神經網絡
4 仿真與結果分析
4.1 仿真數據集與實驗指標
本文采用Kaggle作為仿真數據集,并在Tensorflow平臺實現預測模型,模擬點擊率預測方法的實際效果。Kaggle是一個競賽數據集,表1對其中主要字段進行了具體描述。實驗過程中從Kaggle隨機抽取定量帶有標簽的數據,并以5:1的比例分為學習集與測試集。實驗設定學習速度是,Dropout的失活概率是。
采用損失函數Logloss和AUC作為點擊率預測性能的衡量指標。為了能夠適應不同方法,這里將Logloss函數衡量定義如下
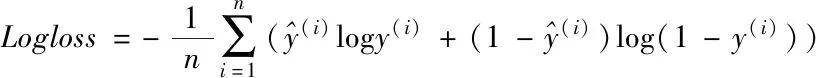
(17)

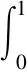
(18)
式中f表示假陽率。因為特征類別差異會形成f的差異,所以通過f曲線圍成的面積得到AUC。
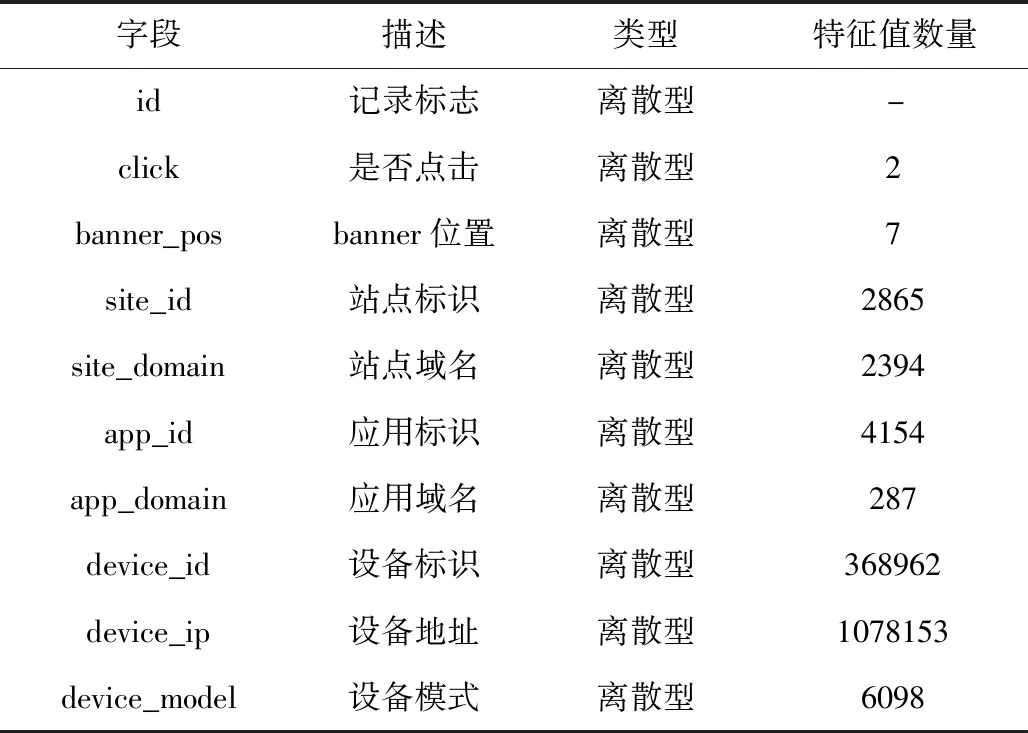
表1 實驗數據集描述
4.2 結果與性能分析
在深度網絡對學習樣本集進行迭代學習時,得到測試樣本集的Logloss與預測準確度的斂散變化情況,結果如圖4所示。可以看出,在深度網絡學習的過程中,迭代至20代時Logloss就已經達到最優解收斂,此時預測準確度達到最佳,損失函數Logloss值對應0.422,預測準確度對應0.907。在迭代次數增加時,原本應該受到過度擬合的影響,使Logloss回升,準確度減小,但是由于引入了Dropout機制,避免局部最優解間的競爭,有效改善了神經元的共適能力。同樣在學習樣本集迭代過程中,得到測試樣本集的AUC指標變化情況,結果如圖5所示。可以看出,在迭代至20代時AUC也收斂至最優解,此時AUC對應0.874。從上述實驗結果可以得到,分解機特征映射模型能夠有效應對高階高維特征,降低處理的復雜度,使得本文提出的點擊率預測方法具有良好的預測速度。

圖4 Logloss預測準確度曲線
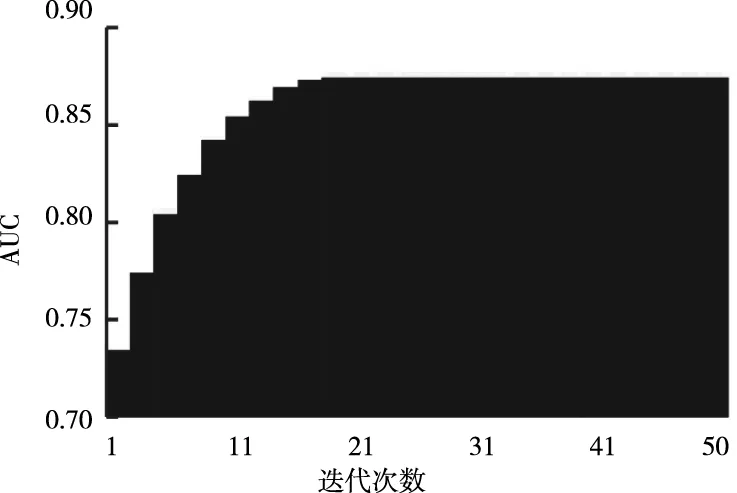
圖5 隨迭代次數變化曲線
將本文(THIS)提出的點擊率預測方法與FNN[7]、OPNN[8]、FM[9]、FDNN[10]、DBN[10]進行性能比較,基于Kaggle數據集分別得到各方法對應的Logloss和AUC指標,結果如圖6所示。通過對比可以得出,本文方法對于點擊率大數據預測具有更好的Logloss和AUC值。這種性能的提升是由于模型學習時,考慮到點擊率的二分類特性,在特征預測的過程中優化了損失函數,結合深度網絡學習,輸入數據經過RBM訓練提取出數據特征,再經由BP神經網絡實現特征分類操作,同時,BP對網絡參數采取優化更新,當預測模型性能出現下降或者梯度減弱時,深度分解機能夠提高對高階交互特征的提取分類。
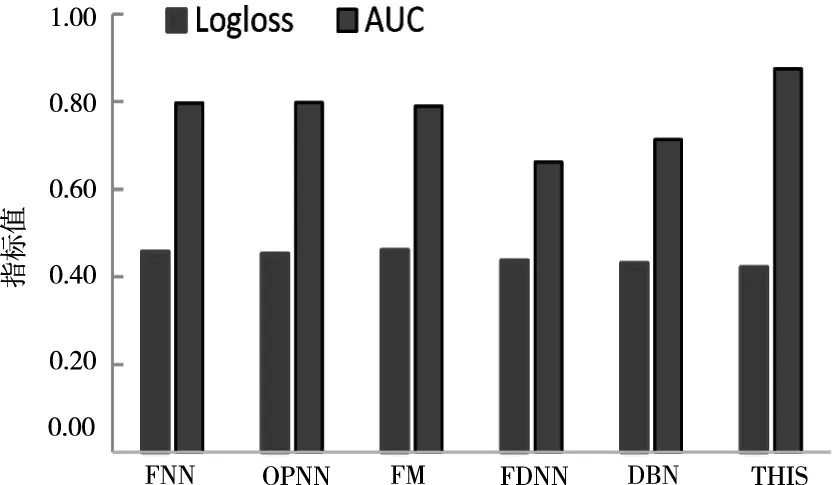
圖6 不同方法的預測性能對比
5 結束語
針對邏輯回歸與多項式回歸等模型在具有高維、高階,以及非線性關聯等特征的點擊率數據預測模型中表現出的缺陷,本文設計了一種高階分解機模型。為達到良好的解耦效果,完成數據特征的準確高效提取,研究工作主要做了如下改進創新:
1)采用隱向量代替權重計算,通過映射關系轉換降低復雜度,同時利用損失函數求偏導得到變量梯度更新。
2)在高階分解機模型基礎上,引入了深度網絡學習,利用RBM實現數據特征識別操作,利用神經網絡實現特征分類操作。
基于Kaggle數據集的仿真,通過Logloss和AUC指標數據驗證了高階深度分解機能夠有效處理高階稀疏點擊率大數據的預測,且具有良好的預測速度與預測準確度,在樣本訓練至約20代便可達到最佳預測效果,最優準確率達到0.907。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
