多種AI算法在新冠疫情文本情緒識別中的實踐
2021-11-17 08:16:12仇建民
江蘇通信 2021年5期
仇建民
中國電信股份有限公司江蘇分公司
0 引言
1 任務分析
1.1 任務背景
新型冠狀病毒(COVID-19)感染的肺炎疫情牽動著全國人民的心。習近平總書記指出:要鼓勵運用大數據、人工智能、云計算等數字技術,在疫情監測分析、病毒溯源、防控救治、資源調配等方面更好地發揮支撐作用。為助力疫情防控和疫情之后的經濟社會恢復工作,北京市經信局主辦了一場科技戰疫公益挑戰賽。為了幫助政府掌握真實的社會輿論情況,科學、高效地做好防控宣傳和輿情引導工作,本賽題針對疫情相關話題開展網民情緒識別的任務。
1.2 任務說明
給定微博文本內容,設計算法對微博內容進行情緒識別,判斷微博內容是積極的、消極的還是中性的,是文本三分類任務。
2 實驗
2.1 數據準備
2.1.1 數據預處理
為保證后續各類算法實驗對比的公平,數據統一進行預處理,后續各類算法均使用處理后的標準數據集。本文使用了以下4種數據預處理方法:(1)數據去噪。只保留微博內容、情感傾向兩個字段,并刪除空值、異常值等無效數據。(2)去除標點符號等特殊字符。因微博存在表情等數據會變成特殊字符,故統一刪除字符,只保留中文、英文、數字,并將多余重復的空格合并為一個空格。(3)繁體字轉簡體字。將全部繁體字轉換為簡體字。(4)去除微博中無意義的詞語。因為微博場景的特殊性,刪除“展開全文”“網頁鏈接”“轉發微博”等微博特定詞匯。
預處理完成后,最終的樣本由原始的100 000條文本,縮減為99 373條文本。
2.1.2 劃分相同的訓練集、驗證集
將預處理完成的數據集拆分為訓練集(79 498條,占比80%)、驗證集(19 875條,占比20%),為確保在后續的各類算法實踐中,使用完全相同的訓練集和驗證集。使用sklearn.model_selection中的train_test_split進行訓練集和驗證集的劃分,通過設置隨機種子確保每個模型的訓練集和驗證集保持一致。
sklearn代碼如下:
包括聚維酮碘,季銨鹽絡合碘和三碘氧化合物。聚維酮碘和季銨鹽絡合碘消毒效果受有機物影響很大,所以均不能作環境消毒,但可作飲水、皮膚和器械消毒。只有三碘氧化合物可作環境和帶動物消毒。
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2,random_state=1
2.2 建模及調優
2.2.1 評價指標說明
選取19 875條驗證集的準確率(accuracy)作為評價指標。計算公式:

可見,準確率越高,證明模型越好。
2.2.2 機器學習算法實踐
(1)機器學習算法建模、調優。本文在機器學習算法上采用了5種模型組合,分別為:CountVectorizer+MultinomialNB、CountVectorizer+BernoulliNB、TfidfVectorizer+MultinomialNB、TfidfVectorizer+BernoulliN、TfidfVectorizer+LightGBM。
模型調優思路如下:首先,CountVectorizer、TfidfVectorizer調優:通過設置ngram_range參數,分別取(1,1)、(1,2)、(1,3),用來觀察一元模型(unigrams)、二元模型( bigrams)和三元模型(trigrams)。其次,MultinomialNB、BernoulliNB調優:通過窮舉alpha,alpha從0.01開始,步長為0.01,到1結束,輪詢100次,選擇準確率最佳的模型。最后,LightGBM調優:以驗證集的準確率為指標,通過早停(earlystopping)功能獲取準確率最佳的模型。
需要說明的是:TfidfVectorizer+LightGBM實踐中,由于筆者算力有限(機器內存較小),ngram_range=(1,2)以及ngram_range=(1,3)未能嘗試,這兩個模型運行時由于內存溢出而報錯。
(2)機器學習算法對比結論。以上5種算法的最佳準確率對比如圖1所示。從實驗結果可以得出以下結論:首先,TfidfVectorizer+LightGBM準確率最佳,為72.88%,且在ngram_range=(1,1)參數下,LightGBM準確率顯著超過MultinomialNB和BernoulliNB。其次,在另一個算法確定的情況下,TfidfVectorizer的準確率顯著超過CountVectorizer,說明在文本特征提取上,TfidfVectorizer優于CountVectorizer。最后,在另一個算法確定的情況下,MultinomialNB的準確率顯著超過BernoulliNB,說明MultinomialNB更合適文本分類場景,BernoulliNB可能更適用于數據符合伯努利分布的場景。
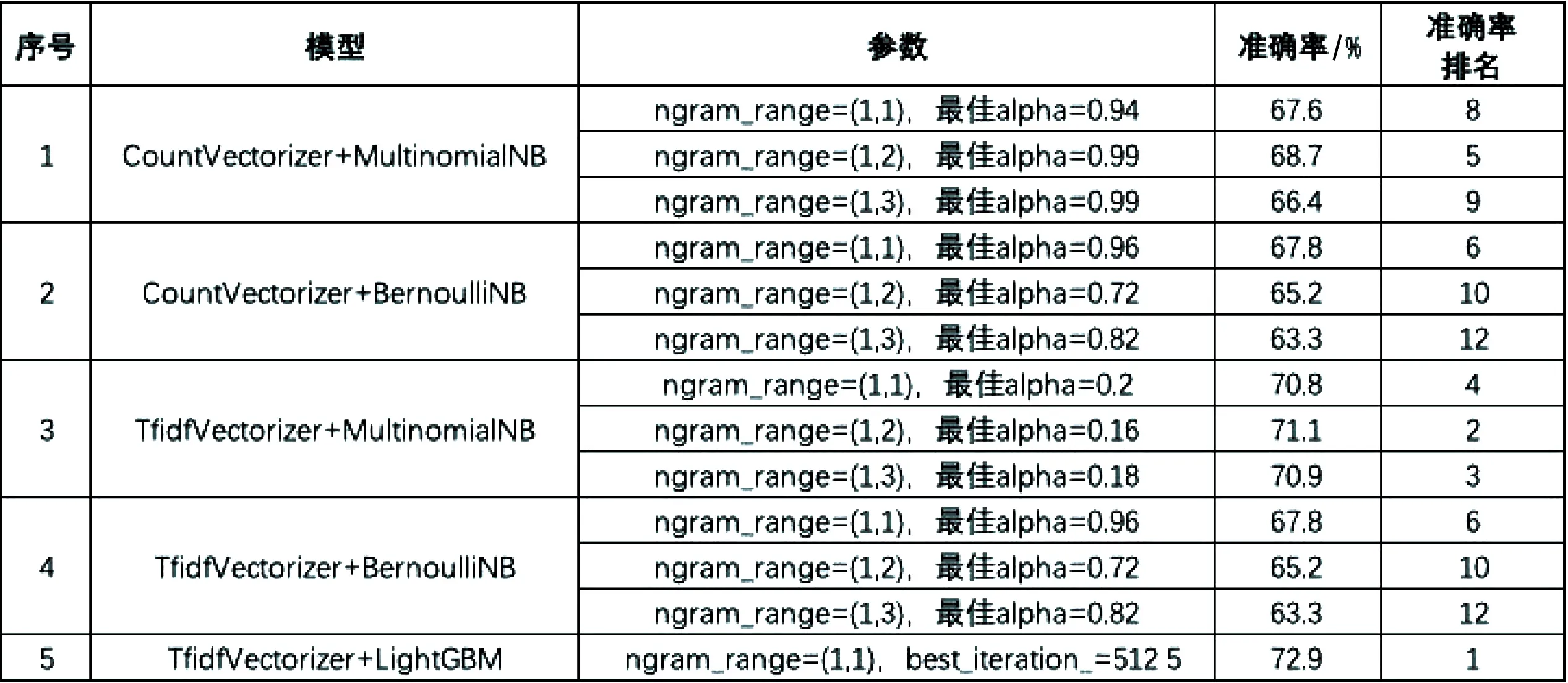
圖1 機器學習算法在此案例中的準確率對比
2.2.3 深度學習算法實踐
(1)深度學習算法建模、調優。
通過Word2Vec算法對數據集的語料進行訓練,設置詞向量維度為128維,迭代訓練15輪,訓練完成后得到78 486個詞匯及詞向量。選取部分詞匯及詞向量,比如“武漢”“肺炎”,通過相似度匹配,找到相似度Top10的詞匯,發現基本符合常識。
模型調優思路:第一,考慮到雙向序列模型可以考慮整個句子的信息,即使在句子中間,也可以綜合考慮過去的信息和將來的信息,因此在網絡層使用BiGRU(雙向GRU)代替GRU(Gate Recurrent Unit)。第二,為避免模型過擬合,超過2個epoch驗證集的準確率若無提升,則將學習率減半;超過4個epoch驗證集的準確率若無提升,則earlystopping。
根據以上思路,本文在深度學習算法上采用了2種模型組合,分別為Word2Vec+BiGRU、BERT(Bidirectional Encoder Representation from Transformers)+BiGRU。
(2)深度學習算法對比結論。
兩種組合模型在訓練集和驗證集的準確率分布情況如圖2所示。實驗結果對比如圖3所示,可以得出以下結論:預訓練好的BERT模型在Embedding層的效果顯著優于Word2Vec。
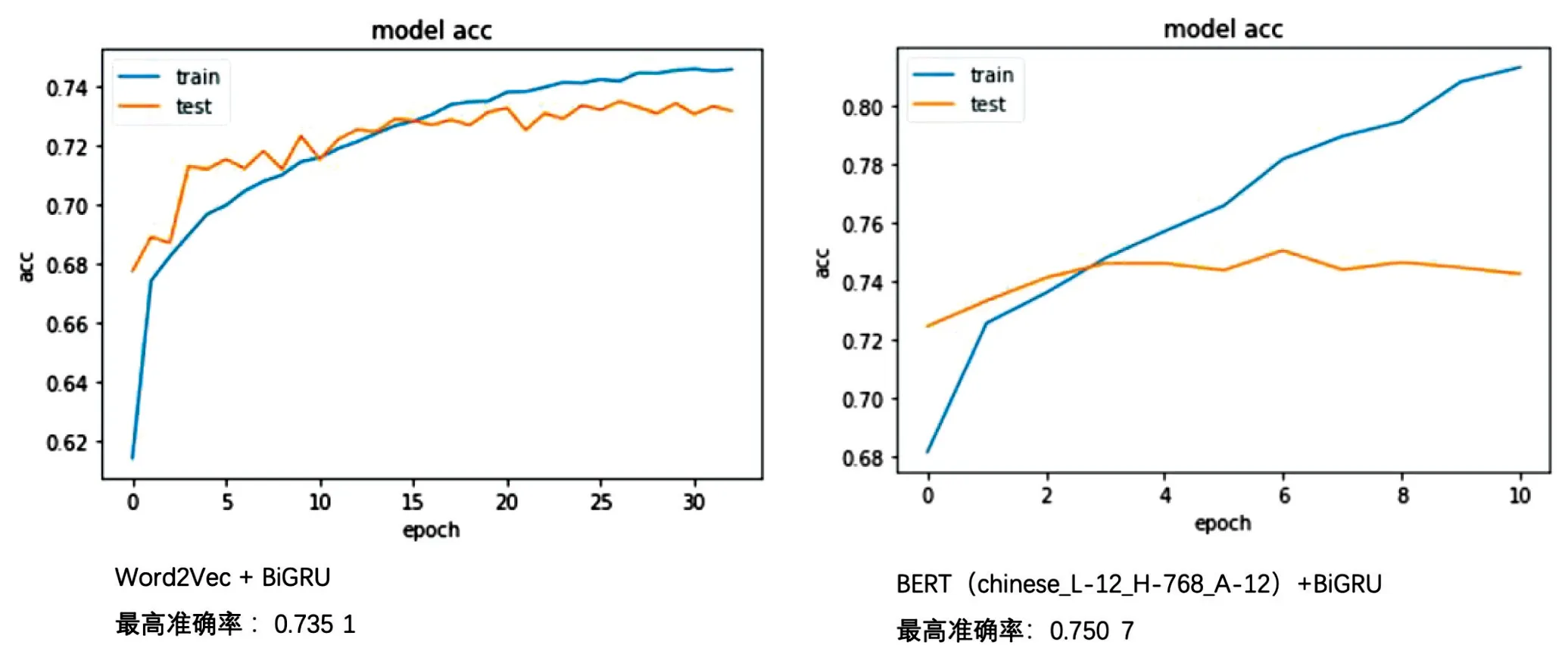
圖2 Word2Vec+BiGRU、BERT+BiGRU實驗結果

圖3 深度學習算法在此案例中的準確率對比
2.3 實驗結果匯總對比
綜合以上機器學習和深度學習算法實踐結果,匯總7種組合模型,選取每種模型在驗證集的最佳準確率進行對比,結果如圖4所示。由準確率可以發現:深度學習2種算法的平均準確率為74.3%,遠超過機器學習5種算法的平均準確率69.7%,且深度學習算法最低準確率為73.5%,也超過機器學習算法的最高準確率72.9%。在機器學習算法中,TfidfVectorizer準確率高于CountVectorizer;MultinomialNB準確率高于BernoulliNB;LightGBM準確率高于樸素貝葉斯。深度學習算法中,BERT準確率高于Word2vec。

圖4 機器學習、深度學習算法在此案例中的準確率對比
3 結束語
本文使用了比賽主辦方提供的公開數據,并拆分為訓練集和驗證集,使用驗證集的準確率作為評價指標,使用7種機器學習、深度學習模型進行文本分類并分別進行調優,得出以下結論:(1)在文本分類任務上,深度學習算法相比機器學習算法有較為明顯的優勢。(2)在機器學習算法中:在文本特征提取上,TfidfVectorizer優于CountVectorizer;MultinomialNB相比BernoulliNB更合適文本分類場景;LightGBM集成模型分類效果優于樸素貝葉斯。(3)在深度學習算法中:預訓練好的BERT模型在Embedding層的效果優于Word2Vec。(4)綜合以上,BERT+BiGRU準確率最高,為75.1%,最終選取BERT+BiGRU為預測模型。后續可以BERT+BiGRU模型為基礎,在具體的神經網絡層進行改進調優,進一步提升文本分類的準確率。
猜你喜歡
音樂天地(音樂創作版)(2022年1期)2022-04-26 13:51:10
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
人大建設(2020年5期)2020-09-25 08:56:22
快樂作文(1.2年級)(2020年8期)2020-09-10 07:22:44
37°女人(2020年5期)2020-05-11 05:58:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
