基于深度學習的生成式文本摘要技術綜述
2021-11-18 02:18:24朱永清趙菲菲慕曉冬尤軒昂
計算機工程 2021年11期
朱永清,趙 鵬,趙菲菲,慕曉冬,白 坤,尤軒昂
(1.火箭軍工程大學 作戰保障學院,西安 710025;2.陸軍邊海防學院,西安 710025)
0 概述
自動文本摘要技術最早應用于加拿大政府的天氣預報工作,后來被應用于金融分析、醫療數據整理、法律文本處理等多個領域進行輔助決策。在神經網絡和深度學習被廣泛使用之前,大部分摘要類實現方法都是以抽取的方式,例如文獻[1-3]利用基于圖排序的摘要方法,文獻[4]利用基于啟發式規則的摘要方法,文獻[5]利用基于有監督學習的摘要方法,文獻[6-8]利用基于神經網絡的摘要方法,文獻[9-10]利用基于次模函數的摘要方法,文獻[11-13]利用基于預訓練模型的摘要方法,等。以上方法均可以理解為序列到序列的抽取式摘要方法,即從原文中分析并提取出最重要的原文完整句子,進行簡單拼接后得到一個抽取式摘要結果。在現實中的人工條件下,摘要更多的是生成式的過程,即在閱讀一段、一篇或多篇文段后,經過腦內抽象分析得到一個抽象理解,之后結合自己的知識結構輸出為一段高度概括的內容。因此,隨著深度學習的快速發展,自動文本摘要的方法逐漸由抽取式向生成式偏移。現已有不少國內[14-15]和國外[16-18]的研究人員對目前的自動文本摘要方法進行了綜述分析,但是針對生成式自動文本摘要的文獻綜述,如文獻[19-20],在直接將目前生成式自動文本摘要等價于基于深度學習后便不再深入分析,缺乏問題導向和足夠深入的研究,對于目前最新研究成果分析不夠充分。
本文針對生成式文本摘要技術,指出其在深度學習下的發展優勢和關鍵問題,描述生成式摘要系統的基本結構和數據預處理的相關基礎知識,并以關鍵問題為導向,展示基于深度學習的生成式摘要模型突出的研究成果,比較優秀的深度預訓練和創新方法融合模型。此外,介紹生成式摘要系統常用的數據集和評價標準,并對這一技術的發展局限性及發展前景進行分析。
1 研究背景及現狀分析
信息摘要是對海量數據內容的提煉和總結,以簡潔、直觀的摘要來概括用戶所關注的主要內容,方便用戶快速了解關注目標。文本類摘要作為眾多模態信息摘要中最常見的類型,通過篩選、提煉、總結等方式得到與原文語義相近但極大程度縮短長度的句段。隨著各類文本信息數量的爆炸式增長,公眾需求大量增加,自動文本摘要技術起到了重要作用。
基于深度學習的生成式自動文本摘要任務模型主要具有以下優點:
1)靈活性高,允許生成的摘要中出現新的字詞或短語。
2)相比于抽取式摘要,生成式摘要模型的思路更符合實際需求,其結果更貼近人工摘要的結果。
3)生成式摘要能夠在建立完整語義信息的同時有效避免過多冗余信息。
同時,基于深度學習的生成式自動文本摘要任務模型存在以下關鍵問題:
1)未登錄詞(Out of Vocabulary,OOV)問題。在處理文本時,通常會有一個字詞庫,未登錄詞就是不在字詞庫中的單詞。這個字詞庫可以是提前加載的,可以是自己臨時定義的,也可以是從訓練數據集提取的,如何處理未登錄詞是文本摘要任務的關鍵問題之一。
2)生成重復問題。利用注意力得分從分布中采樣得到的字詞連續重復生成,導致語法不通或語義不明。
3)長程依賴問題。在長文檔或多文檔摘要任務中,較長文檔或多文檔遠距離語義抽取能力不足。
4)評價標準問題。生成的摘要好壞,不僅單純地由評價指標決定,同時也需要考慮語義相關性、語法準確性、流暢性等問題。
2 數據預處理及基本框架
目前生成式自動文本摘要主流的基本框架是結合數據預處理[21-22]和編解碼器的序列到序列框架[23-24],其中涉及CNN[25]、RNN[26]、LSTM/GRU[27-28]、Transformer[29-30]、BERT[31]及其變體RoBERTa[32]等作為編碼器或解碼器的基本模型。
在編碼器之前,需要實現數據的預處理,包括分詞、詞嵌入等。分詞是中文特有的需求,在實際的深度學習過程中,雖然無論是語義關聯還是文本生成都是基于字而非基于詞的,但是分詞的作用仍然很重要,它有利于下一步融合注意力機制的權重分配,其中,BERT、GPT[33-35]等預訓練模型以及fastBERT[36]等蒸餾后的預訓練模型[37-38]所使用的基于WordPiece[39]的分詞方法,常用于提高模型生成的準確性和合理性。詞嵌入包括文檔嵌入[40-42]以及位置嵌入,是數據預處理中最重要的一環,每一個單詞對應唯一的詞向量,詞嵌入的誕生促使機器可以通過數學的方法對其進行分析建模推演,這些向量是高維度的,通過分析這些高緯度向量,可以找出很多利于分析的規律。隨著機器學習的發展,趨向使用各種預訓練模型加以適當微調,即可完成數據預處理工作,因此,預訓練模型已經成為詞嵌入的常態配置。
目前在利用深度學習技術進行自動文本摘要方面已經有了不少研究成果,重點在于編碼器和解碼器的序列到序列框架。在將一個序列輸入框架之后,通過編碼器得到隱藏上下文向量,然后將其作為輸入送入解碼器,在解碼過程中計算概率分布得到輸出。目前,越來越多基于序列到序列框架的模型被提出,但基本上都是基于RUSH 等[43]提出的加入注意力機制的序列到序列框架,如圖1 所示。該模型有助于更好地生成摘要,已經成為生成式自動文本摘要模型的主要框架。
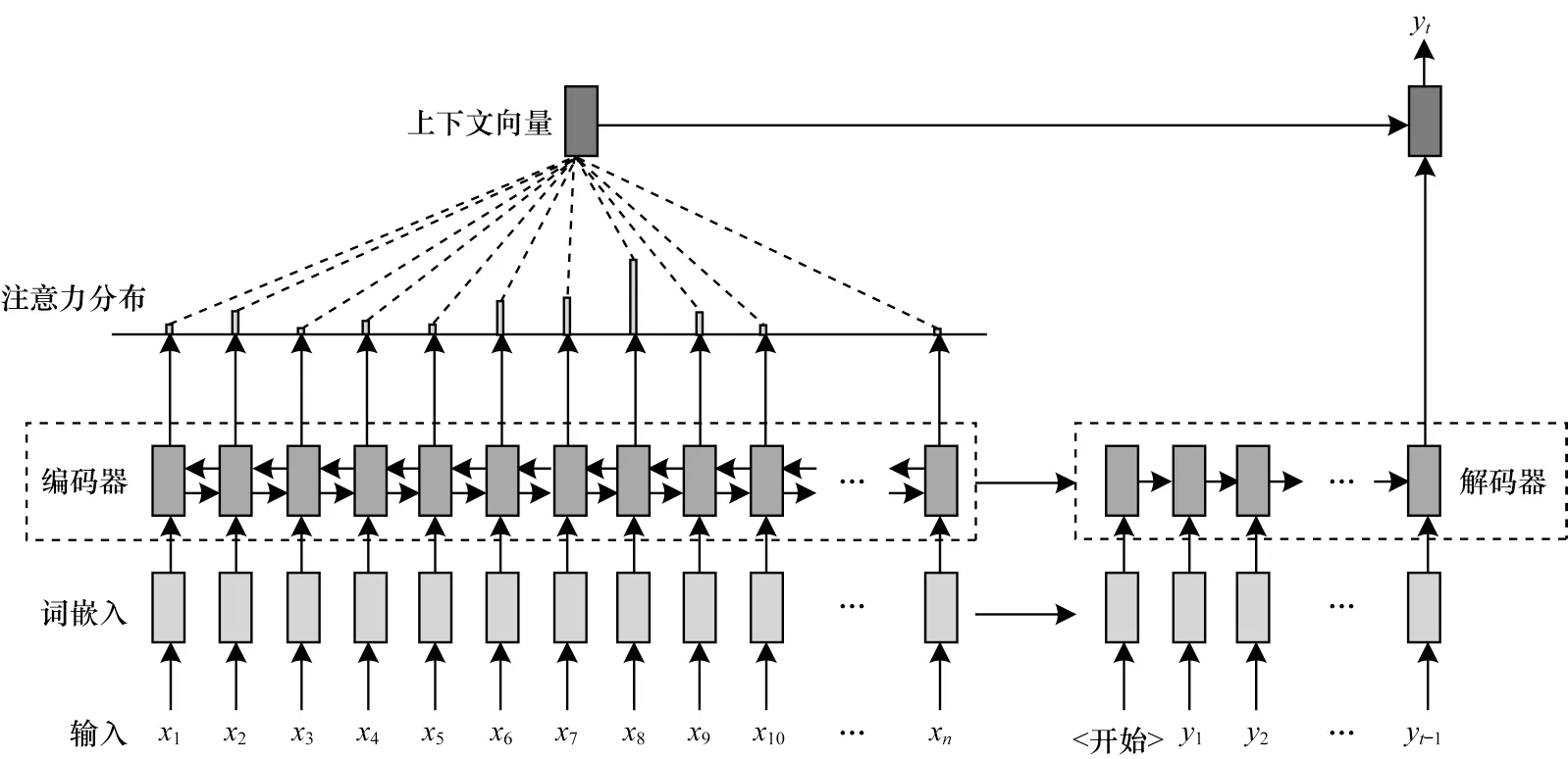
圖1 帶注意力機制的序列到序列神經網絡模型框架Fig.1 Framework of sequence to sequence neural network model with attention mechanism
3 模型關鍵技術分析及效果對比
針對上文所述基于深度學習的生成式文本摘要模型中存在的關鍵問題,下文分析相應問題的解決方案,介紹常用深度預訓練生成摘要模型技術,以及基于深度學習的創新性生成摘要模型技術,并對主流生成式摘要模型在不同數據集上的效果進行對比分析。
3.1 針對未登錄詞問題的解決方案
未登錄詞問題是生成式文本摘要任務中的首要問題,最開始的解決方法有替換成特殊字符“UNK”,或進行刪除操作,或從原文中隨機抽取替換,但都會影響摘要生成效果。
針對該問題,SEE等[44]提出指針生成器網絡(Point-Generator Network,PGN),即復制機制。針對序列到序列基本模型經常不準確再現事實細節的問題,通過指針從源文本中針對性復制單詞的方式,緩解了OOV 問題,既允許摘要單詞通過指針復制源文檔單詞的方式生成,也允許一定概率下從固定字詞庫中采樣生成。復制機制對于準確地復制罕見但必須出現的單詞至關重要,如人名、地名等專有名詞。該方法已經成為生成式文本摘要模型最常用的網絡模型之一。但該模型存在一個問題,即摘要中的新穎性字詞依賴于字詞庫中的新穎性字詞,這使得模型機制對于字詞庫有較大程度的依賴性。
針對PGN存在的問題,CHAKRABORTY 等[45]分析指針生成網絡解決未登錄詞問題過程中不能生成新詞問題的根本原因,并通過增加未登錄詞懲罰機制,優化可以生成新詞的生成式摘要模型效果。
3.2 針對生成重復問題的解決方案
生成重復問題指的是,基于注意力的序列到序列模型生成的摘要在注意力機制的影響下有傾向于生成重復字詞的情況,導致出現不必要的冗余或語法錯誤等問題。針對該問題,SEE 等[44]提出覆蓋(coverage)機制,利用注意力分布追蹤目前應被選中的單詞,當再次注意指向與上一時間步同一內容時予以懲罰,解決基于注意力的序列到序列模型生成句子中經常有重復片段現象的問題。
雖然覆蓋機制解決了生成重復的問題,但是對于生成重復的情況并沒有做區分,因為有些主語是必須要重復生成的。因此,如果只是一味地避免重復,對于生成式摘要而言是一種懲罰,會導致這類本該重復生成的詞會被替換為未生成過的其他詞,降低了摘要的質量。為實現有選擇性的覆蓋,CHUNG等[46]提出MPG 模型,修正了主題詞無法選擇性重復生成的問題,提高了生成摘要的質量。
此外,LIN 等[47]提出了一個全局編碼框架。該框架基于源上下文的全局信息來控制從編碼器到解碼器的信息流,其由一個卷積選通單元組成,用于執行全局編碼,以改善源端信息的表示,在提高生成摘要質量的同時也達到了減少重復的目的。COHAN等[48]針對長序列摘要字詞重復生成的問題,跟蹤注意力作用范圍,提出解碼器覆蓋范圍作為注意力功能的附加輸入,以避免注意力重復指向相同的內容。
3.3 針對長程依賴問題的解決方案
長程依賴問題指的是,面對較長或主旨不集中的輸入信息,通過加大輸入長度提高上下文向量的語義抽取能力時,后期輸入內容對上下文向量語義的影響基本消失的問題。
在基于注意力機制的序列到序列基礎模型基礎上,CHOPRA 等[49]以卷積注意力作為編碼器并以循環神經網絡(Recurrent Neural Network,RNN)作為解碼器,NALLAPATI 等[26]結合龐大字詞庫,利用RNN 作為編碼器解碼器來提高生成摘要質量,但都深受RNN 長程依賴問題的影響。為減少該問題影響,COHAN 等[48]提出分層RNN 用以捕捉文檔話語結構,利用語篇相關信息來修改詞級注意功能,緩解長程依賴問題。CELIKYILMAZ 等[50]使用長短時記憶網絡(Long-Short Term Memory,LSTM)抽取句子的語義表示,利用深度代理通信(DCA)的方式解決長距離情況下如何更好進行信息聚留的問題,并采用最大似然估計、語義銜接、逐句間強化學習策略等方式提高生成摘要的準確性、連貫性、抽象程度。LIN 等[47]將雙向LSTM 作為編碼器,將單向LSTM 作為解碼器,并增加自注意(Self-Attention)模塊,挖掘某一時刻標記(Token)之間的關系,提高全局信息關注能力,從而減少長程依賴影響。
目前,越來越多研究著眼于利用預訓練模型進行生成式摘要生成。YANG 等[51]針對BERT 輸入長度受限的問題,提出通過對句子單獨應用推理來解決這個問題,然后聚合句子分數來產生文檔分數的思想,以緩解BERT 的長程依賴問題。
3.4 針對評價標準問題的解決方案
評價標準問題包括兩點:1)生成式摘要任務訓練模型需要考慮ROUGE 函數不可微而不適用于梯度計算的問題;2)生成式摘要任務中的評價標準常采用人工評價或ROUGE 自動評價標準,但是生成式摘要的ROUGE 評價結果并不能充分說明摘要質量,歸根于生成式摘要結果評價指標希望更看重整體語義匹配程度,而ROUGE 更看重字詞組合的形式匹配。針對以上2 個評價標準問題,在設計損失函數時,需要考慮如何將ROUGE 標準融入損失函數及其優化計算方法,同時設計兼具語義相似性和字詞匹配度的損失函數。
針對第1個評價標準問題,NG等[52]提出針對ROUGE 的單詞嵌入方法,提高了摘要評估效果,其在使用斯皮爾曼(Spearman)和肯德爾(Kendall)秩系數測量時不測量詞匯重疊,而是通過詞嵌入來計算摘要中使用的詞的語義相似度,達到與人類評估更好的相關性,并避免2 個單詞序列具有相似含義時由于詞典表示法的差異而受到ROUGE 不公平處罰的影響。AYANA 等[53]將不可微而無法直接用作損失函數的ROUGE、BLEU 等評測指標引入訓練目標函數中,使用最小風險訓練策略進行優化計算,改進了標題生成的效果。CELIKYILMAZ 等[50]使用強化學習的自我批判訓練方法計算不可微的ROUGE 函數。LI 等[54]提出在卷積序列到序列框架中使用自臨界序列訓練SCST 技術直接優化模型,緩解了曝光偏差問題并實現了不可微的摘要度量ROUGE 的計算。
針對第2 個評價標準問題,FABBRI 等[55]使用神經摘要模型輸出以及專家摘要和外包人工標注摘要,以全面和一致的方式重新評估了12 個自動評估指標,并使用這些自動評估指標對23 個最近的摘要模型進行了基準測試,得到一個更完整的文本摘要評估協議,提高摘要自動評估指標的普適性。
3.5 包含深度預訓練框架的生成式文本摘要模型
深度學習發展至今,隨著Transformer 框架的提出,原先由基于RNN、LSTM、GRU 等模型作為編碼器和解碼器的序列到序列模型,已經發展為基于Transformer 的序列到序列模型,逐漸形成了深度預訓練模型的主要框架。同時,對于訓練集的需求也由有監督學習向無監督學習轉化,大幅提升了缺乏足夠有標簽數據情況下的模型性能。
目前,生成式文本摘要領域最常用的深度預訓練模型包括MASS[56]、TAAS[57]、UniLM[58-59]、T5[60]、STEP[61]、BART[62]、PEGASUS[63]、ProphetNet[64]等。MASS[56]模型使用的方法是掩蔽序列到序列的生成,避免在給定句子剩余部分的情況下重構句子片段,隨機選擇一個句子片段。TAAS[57]模型包含了1 個利用潛在主題表示文檔潛在語義結構的主題感知抽象摘要模型框架。UniLM[58-59]模型包含3 種語言建模任務的聯合訓練,即單向(從左到右和從右到左)、雙向(單詞級掩碼,帶有下一句預測)和序列到序列(單詞級掩碼)預測。T5[60]模型展示了擴大模型大小(至110 億個參數)和預訓練語料庫的優勢,并引入了C4 大規模文本語料庫。該模型利用隨機損壞的文本段進行預訓練,這些文本段具有不同的掩碼比和段的大小。STEP[61]模型包含3 個與抽象摘要任務有關且都基于恢復源文本而設計的預訓練目標,即句子重新排序(SR)、下一句生成(NSG)和屏蔽文檔生成(MDG)。與在更大的語料庫(≥160 GB)上進行模型預訓練相比,該模型在語料庫只有19 GB 的情況下仍然可以獲得相當甚至更好的性能。BART[62]模型引入去噪自動編碼器對序列間模型進行預訓練,利用任意的噪聲函數破壞文本,并學習重構原始文本。對于生成任務,噪聲函數是文本填充,其使用單個掩碼標記來掩碼隨機采樣的文本范圍。PEGASUS[63]模型提出了新的預訓練目標間隙句生成GSG(Gap Sentences Generation),從文檔中選擇并屏蔽整個句子,并將間隙句連接成偽摘要。ProphetNet[64]模型提出一個新穎的自監督學習目標函數,即預測未來N元組(Predicting FutureN-gram)。與傳統序列到序列模型中Teacher-forcing 每一時刻只預測下一個字符不同,該模型每一時刻都在學習如何同時預測未來N個字符。
以上基于Transformer 的序列到序列深度預訓練框架的生成式文本摘要模型優勢,在于不需要過多的有標記數據,僅憑借大量無標記語料庫進行預訓練再用少量標記數據微調即可,隨著預訓練語料庫內容的不斷擴充,促使生成摘要的得分不斷提高。值得注意的是,這類框架極大地弱化了對標記數據的需求和調試的門檻,但也大幅提高了語料庫精細程度及硬件訓練的門檻,同時目前關于這些預訓練模型可解釋性相關研究仍然缺乏,對于如何在預訓練框架中優化生成式摘要的未登錄詞、生成重復、長程依賴、評價標準等核心問題,缺乏足夠深入的研究。
3.6 融合深度學習創新方法的生成式文本摘要模型
為提高基于深度學習的生成式摘要模型性能,研究者通過嘗試與其他領域模型及方法的創新融合,在不同方面推進了生成式摘要模型的發展。
GUO 等[65]通過融合具有問題生成和蘊涵生成等輔助任務的多任務學習模型,提高了抽象摘要的蘊含源文本核心信息能力,并提出新的多任務體系結構,總體上提高了摘要模型的學習顯著性和蘊含能力。XU 等[66]融合圖卷積網絡模型,使用圖來連接文檔中句子的解析樹,并使用堆疊圖卷積網絡來學習文檔的語法表示,通過選擇性注意機制提取語義和結構方面的顯著信息并優化生成摘要結果。ZOU等[61]融合自建大規模語料庫,使用無監督訓練方法,達到了有監督訓練的效果。ZHENG 等[67]為播客領域的生成式摘要提供了基線分析,突出分析了當前先進預訓練模型在該領域的效果。CHEN 等[68]針對對話摘要生成問題提出一個多視圖序列到序列模型,從不同的視圖中提取非結構化日常聊天的會話結構來表示會話,利用多視圖解碼器來合并不同的視圖以生成對話摘要。ZHENG 等[57]通過融合神經主題模型,有效提高了摘要生成效果及全局語義蘊含。FABBRI 等[69]引入一種稱為維基轉換的通用方法,以無監督、特定于數據集的方式微調摘要的預處理模型,在零樣本抽象摘要模型性能比較中取得了最優,同時為少樣本情況提供了研究依據。ZAGAR等[70]提出跨語言生成式摘要模型,針對小語種資源少的問題,使用一個基于深度神經網絡和序列到序列架構的預處理英語摘要模型來總結斯洛文尼亞新聞文章,通過使用額外的語言模型進行目標語言評估來解決解碼器不足的問題。
通過上述研究可以發現,利用其他領域的知識遷移可以提高生成式自動文本摘要的生成效果。
3.7 模型對比
以上對深度學習下的生成式文本摘要模型的分類與說明,表明專用模型精于解決于特定問題,具有不同的算法原理、編解碼器、適用范圍、優勢、局限性等,因此,需要根據實際情況進行研究后再使用,融合出更優秀的生成式自動文本摘要模型。針對專用模型的編解碼器、解決核心問題的方案比較如表1所示。
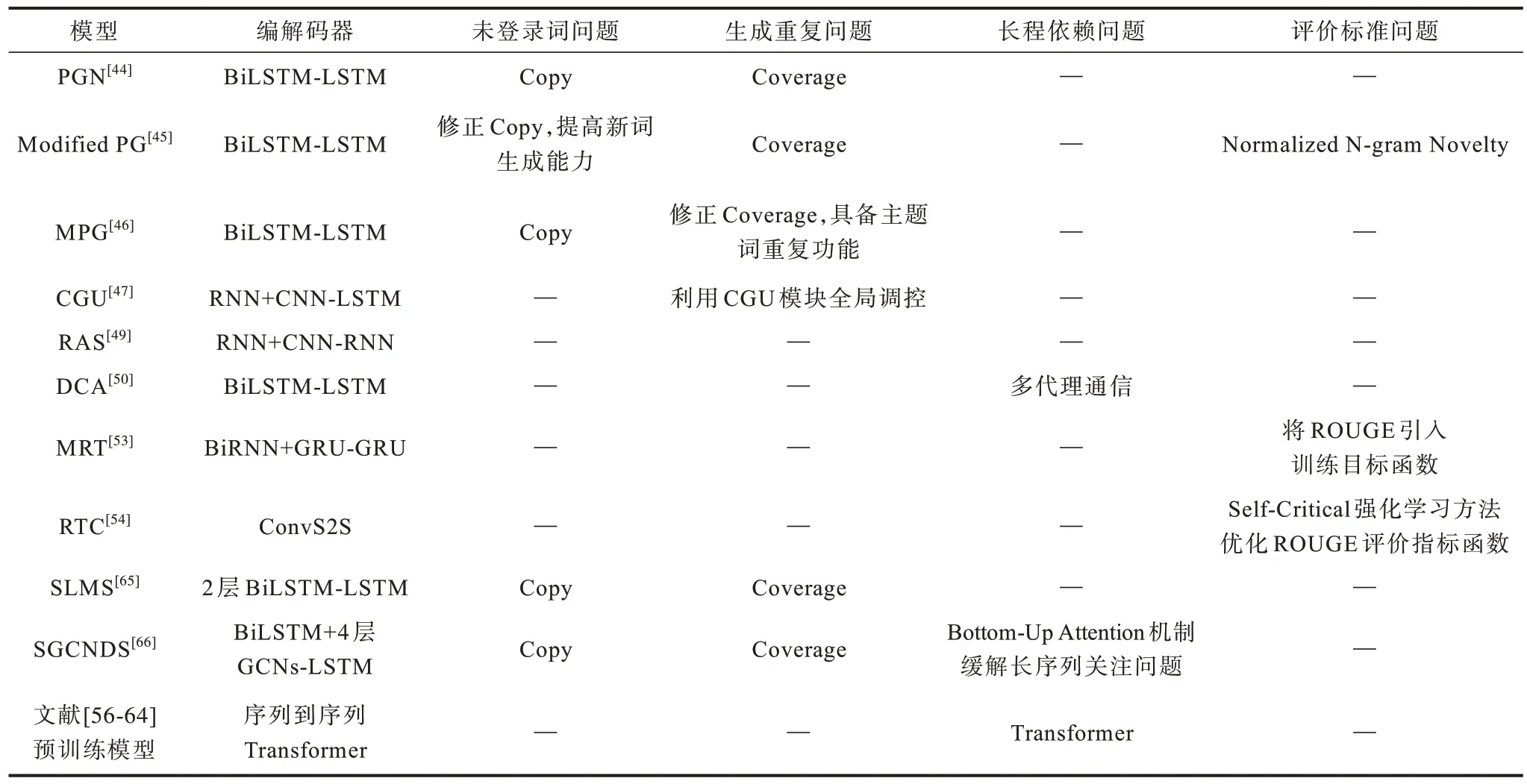
表1 不同模型的編解碼器、核心問題解決方案比較Table 1 Comparison of codec and core problem solving methods of different models
由表1可見,指針網絡(PGN)中的Copy 和Coverage 模塊是較多模型處理未登錄詞和生成重復問題的主要模塊,而處理長程依賴和評價標準問題的方法各不相同,缺乏較為權威的標桿模型。對于預訓練模型,利用Transformer 的多頭注意力可緩解長程依賴問題,經過大容量語料庫的訓練,學到的序列內字詞之間的關系也更全面,降低了遇到未登錄詞和生成重復的幾率,因此,很少有專門針對4 個核心問題的模塊。各模型的算法核心技術、適用范圍、優勢和局限性比較如表2 所示。
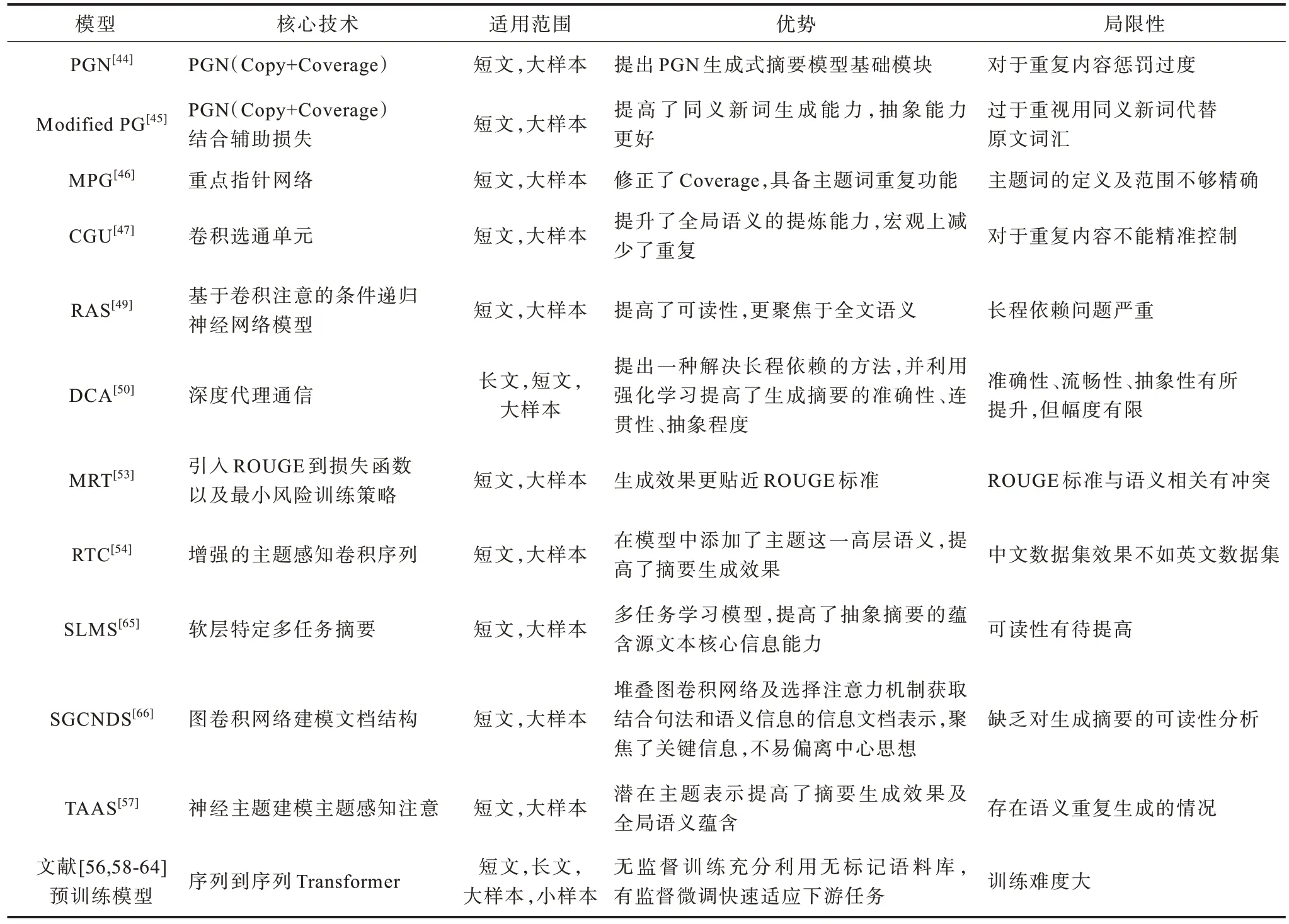
表2 不同模型的算法核心、適用范圍、優勢和局限性比較Table 2 Comparison of core algorithm,application scope,advantages and limitations of different models
3.8 實驗效果對比與分析
目前主流模型主要采用Cnn&Dailymail stories[26,44]、Gigaword[43,71]、DUC-2004、LCSTS[72]這4種數據集。評價標準通常采用ROUGE[73]標準中的ROUGE-1、ROUGE-2 和ROUGE-L。將不同模型在各個數據集上的ROUGE 分數進行對比,如表3 所示,數據取自各模型的最優分,加粗表示該項數據各模型中的最優值。可以看出,基于深度學習的生成式摘要模型,ROUGE-1、ROUGE-2、ROUGE-L 評價得分在Cnn&Dailymail 數據集上最高分別提高了8.53、8.65、8.02 分,在Gigaword語料庫上分別提高了8.67、8.05、8.80 分,在DUC-2004數據集上分別提高了4.60、3.81、5.63 分,在LCSTS 數據集上分別提高了6.92、7.88、7.28 分,總體效果提升顯著。
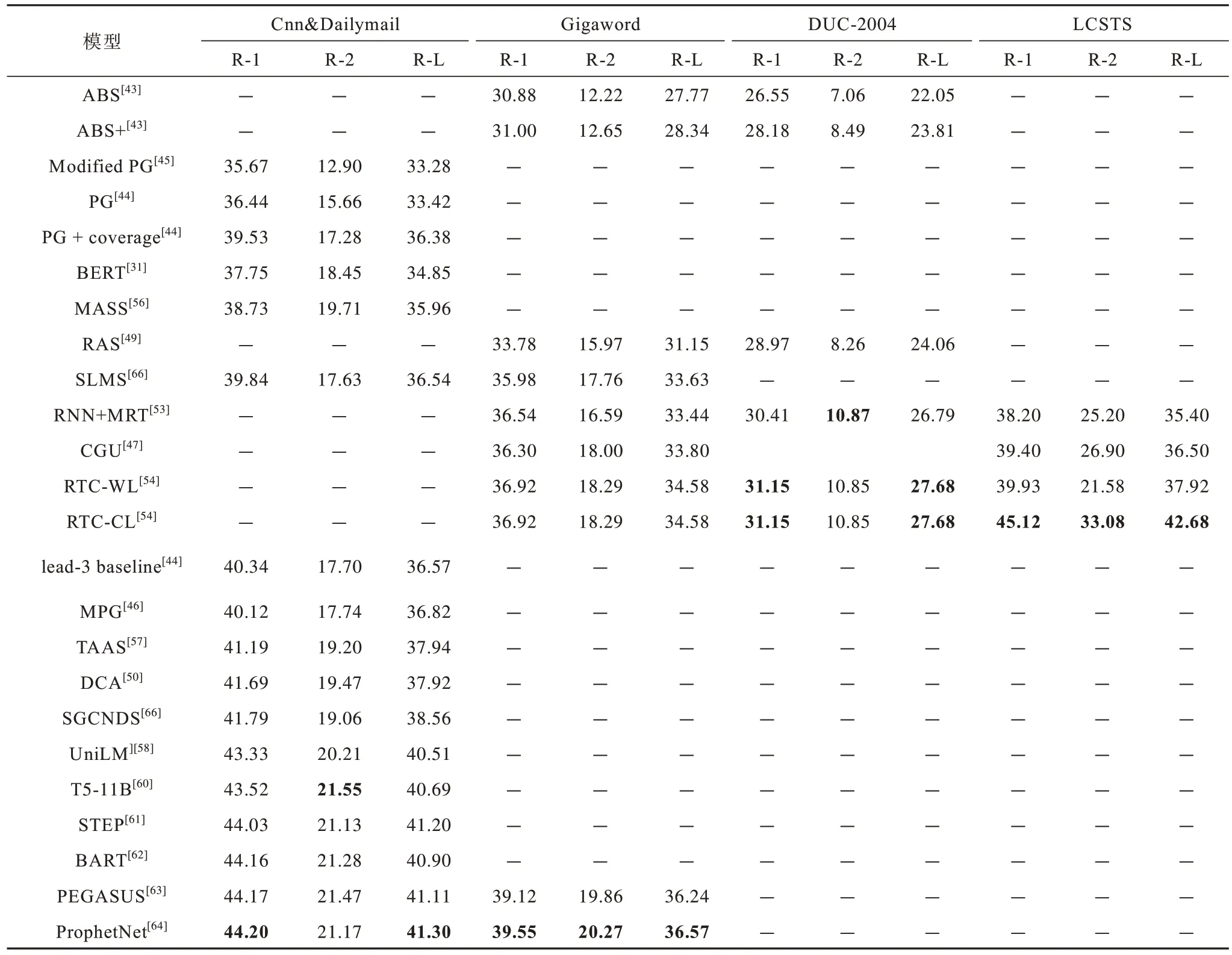
表3 不同數據集上常用模型的ROUGE 分數對比Table 3 Comparison of ROUGE scores of common models on different datasets
基于深度學習的生成式摘要模型較傳統模型有較大程度的突破,但仍有較大的進步空間,主要包括:
1)ProphetNet模型[62]在英文數據集Cnn&Dailymail 和Gigaword 上的效果最好,其他預訓練模型如UniLM、T5、STEP、BART、PEGASUS 等均有不弱于ProphetNet 的表現,差距不明顯。
2)雖然RTC 模型[54]在中文數據集LCSTS 上的效果最好,但由于預訓練模型尚未在中文數據集LCSTS上進行實驗,因此模型的中英文泛化能力有待進一步驗證。在目前生成式摘要領域中,中文的進展相較于英文是短暫且緩慢的,實驗數據遠遠不夠。
3)這些模型總體上能夠較大程度地提升摘要生成效果,但大部分模型都僅在一兩個數據集上進行實驗,不夠完備。
4)大部分模型都基于短文本摘要,目前在長文本、多文檔文本、特定領域文本等方面缺乏模型及其效果的數據對比。
4 常用數據集及評價標準
4.1 常用數據集
適用于生成式自動文本摘要任務的常用數據集包括Cnn&Dailymail 數據集、Gigaword 語料庫、會議共享數據集、LCSTS 單文本摘要數據集等。
1)Cnn&Dailymail 數據集。Cnn&Dailymail 是單文本摘要數據集,由30 萬篇新聞短文摘要對組成,該數據集為英文數據集。
2)Gigaword 語料庫。Gigaword 語料庫包含 約380 萬個訓練樣本、19 萬個驗證樣本和1 951 個測試樣本用于評估。輸入摘要對由源文章的標題行和第一句組成,該數據集為英文數據集。
3)會議共享數據集。常用的會議共享數據集包括DUC 和NLPCC 數據集。DUC(Document Understanding Conference)是摘要評估領域的國際評測會議,各大文本摘要系統均熱衷于此進行測評比較,這里提供的數據集都是小型數據集,用于評測模型。最常用的是DUC-2004 數據集,該會議共享數據集為英文數據集。NLPCC(Natural Language Processing and Chinese Computing)是CCF 國際自然語言處理與中文計算會議,NLPCC2015、NLPCC2017、NLPCC2018均有摘要任務相關的摘要數據集,該會議共享數據集為中文數據集。
4)LCSTS 單文本摘要數據集。LCSTS(Largescale Chinese Short Text Summarization dataset),是哈工大提出的從新浪微博獲取的短文本新聞摘要中文數據集。該語料庫由240 萬篇真實的漢語短文組成,每一篇文章的作者都給出了簡短的摘要,其中手工標記了10 666 個簡短摘要與相應的簡短文本的相關性。
5)其他數據集。除了以上數據集,還可以通過其他不同途徑獲取數據集,如文獻[74]發布的一個基于新浪微博的中文數據集,共包含863 826 個樣本,以及通過參加摘要類比賽獲取相關數據集等。
目前生成式自動文本摘要領域的主流數據集偏向于英文,由于國內在該領域的研究滯后于國外,因此對于中文數據集的制作、共享、使用及研究程度不深。此外,常用數據集多為短文本數據集,長文本或多文檔數據集尤為缺乏。隨著深度學習的不斷發展,各研究對于數據集的需求急速加大,需要各界學者持續加大對于該領域數據集的全方面研究力度,其中包括長文本摘要數據集、多文檔摘要數據集、多語言混合摘要數據集、科研或醫學或法律等方面具有領域特色的細粒度摘要數據集,等。
4.2 評價標準
生成式自動文本摘要評價標準可以分為人工測評方法和自動測評方法2 種。人工測評即專家進行人工評判,綜合考慮摘要的流暢性、中心思想相關性、可解釋性等方面進行評價。本文主要介紹自動測評的評價標準,其中分為內部評價和外部評價標準2 類,內部評價標準包含信息量、連貫性、可讀性、長度、冗余度等,外部評價標準為間接評價,包含檢索準確度、分類準確度等。在生成式自動文本摘要任務中,ROUGE(Recall-Oriented Understudy for Gisting Evaluation)[73]是一種常用的評價標準。ROUGE重在召回率,將系統生成的自動摘要與人工生成的標準摘要做對比,通過統計兩者之間重疊的基本單元數目,來評價摘要的質量。在當前環境下,ROUGE 是最常用的自動文本摘要評價標準,而ROUGE-1、ROUGE-2、ROUGE-L 是其中最常用于評價自動文本摘要效果的3 個子標準。
雖然ROUGE 評價標準已經得到了廣泛的認可,但是抽取式摘要方向在深度學習提出之前占據了自動文本摘要領域的主導地位,ROUGE 評價方法也深受影響。在隨深度學習快速發展的生成式摘要任務領域,該方法評測質量比不上人工,因為它只是從基本語義單元的匹配上去評測候選摘要和標準摘要之間的相似性,缺少語義方面的維度比較,注重外部評價而欠缺內部評價。針對ROUGE 不可微的缺陷,不少研究在設計損失函數時,將ROUGE 評價標準融入損失函數并訓練優化方法[53]。
針對ROUGE 缺少內部評價的缺陷,越來越多研究者提出內部評價優先的評價標準,ZHANG 等[75]提出命名為BERTScore 的文本自動生成評價指標,計算候選句子中每個標記與引用中每個標記的相似性分數,即使用具有上下文信息的BERT 嵌入來計算相似度。在多個機器翻譯和圖像字幕基準上的評估結果表明,在與人類判斷的相關性這一維度,該評價指標比現有的度量標準更準確,甚至優于特定任務的監督度量標準,可以作為自動文本摘要評價標準之一。FABBRI 等[64]將BERTScore 作為建立摘要模型評價體系的12 個指標之一,用以評價摘要模型的連貫性、一致性、流暢性、關聯性等特性。CHAKRABORTY 等[45]使用自定義的歸一化n-gram新穎性標準對生成式摘要進行比較,實現新詞生成方面的較大突破,但新穎性主導勢必會導致ROUGE評分一定程度的降低。BHANDARI 等[76]研究無人評判下的自動評估有效性問題,提出不局限于狹窄評分范圍,同時從摘要生成的難易性、抽象性和覆蓋面間進行綜合評估,強調了需要收集人類的判斷來識別值得信賴的度量標準,表示比較相關性時應使用統一寬度的箱以確保更穩健的分析,指出比較抽象數據集上的摘要系統時需要謹慎使用自動評價標準。
雖然越來越多的研究者認清并針對ROUGE 的缺陷提出各種假設和實驗方案,但仍沒有一個方案取代ROUGE 這一評價標準,因此,設計一個更為合適和權威的綜合外部評價和內部評價的摘要評價標準,是目前文本摘要任務領域的一個重要研究方向。
5 發展局限性及前景分析
隨著深度學習的快速發展,語義提取模型從早期使用正則和傳統的機器學習方法向pipeline 的方式進化,再進化到端到端的自動摘要模塊textsum[77]和序列到序列框架。同時,模型使用的特征抽取器也逐步進化,從CNN、RNN 到LSTM/GRU,再到基于Transformer 的MASS[56]、TAAS[57]、UniLM[58-59]、T5[60]、STEP[61]、BART[62]、PEGASUS[63]、ProphetNet[64]等 預訓練模型,信息抽取能力越發強大。深度學習理論發展至今,預訓練的語料庫數據越來越龐大,模型學習能力越來越強。但是,預訓練的基礎是對語料庫的預訓練,而語料庫總有極限也很快會到達極限,那么預訓練模型的突破必然會受限于語料庫的數量和質量。同時,模型網絡越發龐大意味著參數的急劇增長,必須對此進行研究,否則模型系統會出現越來越大的黑盒。黑盒的不可解釋性和不可控性必然阻礙人工智能的可信賴程度,從而可能導致未來發展的不可控性。
本文針對深度學習的生成式文本摘要技術指出以下6 個方面的發展前景:
1)目前各模型在ROUGE 得分方面穩中有進,多數模型建立的目標中包含關鍵問題的部分作為目標函數,但更值得深究的是與關鍵問題之間的關聯程度,因此,應繼續探索解決生成式自動文本摘要關鍵問題(未登錄詞、生成重復、長程依賴等)的解決方案,盡可能在一個模型中解決多個問題,研究仍有較大探索空間。
2)推動制定更權威的生成式自動文本摘要評價標準,改進ROUGE 偏向外部評價的缺陷,提高對于生成式摘要模型輸出的準確性、語義相關性、冗余性、流暢性等屬性的評價標準權威性。
3)促進傳統摘要模型思想與基于深度學習的生成式自動文本摘要模型思想進一步融合。例如抽取式與生成式的融合:針對長文檔,首先利用抽取式模型將重要句子抽取,轉化為符合中心思想的中短文檔,再將文檔送入生成式模型進一步壓縮為短摘要。
4)強化可解釋性方面的研究,加速與知識圖譜領域的融合,如常識的引入、提高挖掘知識蘊含或推理知識的能力、注意力模塊方面在不同的位置或形式對于摘要結果的可解釋性等。
5)加速摘要模型的創新性發展,如推動與其他領域或任務模型相融合、改進語義抽取模型、多語言的融合模型、長短文及多文檔綜合性文摘模型、多模態摘要模型、腦機信號分布融入甚至取代注意力分布的摘要模型、用無監督小數據集訓練代替有監督大數據集訓練的摘要模型等。
6)深化摘要任務的下游任務發展,如基于摘要的整編(例如某部門的年終總結可由下屬不同職能的分部部門年終總結摘要整編生成)、基于摘要的二次摘要(例如部門某方面的年終總結由下屬相同職能的分部部門年終總結摘要整編生成。此外,第3 個趨勢前景也屬于一種二次摘要任務)、基于摘要的合理研判(如對于投資市場,通過對投資對象的實時新聞等進行匯總并生成摘要總結,并基于摘要總結研判投資趨勢)、基于摘要的事實分析(針對生成的摘要內容可能偏離事實的問題,通過融入知識圖譜或多專家模型等方法,比對結果后修正生成摘要的事實準確程度)等。
6 結束語
基于深度學習的生成式文本摘要任務是自然語言處理領域的核心任務之一,其中蘊含的各類問題需要被關注并加以解決,傳統基于淺層神經網絡的方法已經逐漸被基于深度學習的方法超越,但是新的模型方法也有自身的問題。本文總結基于深度學習的生成式文本摘要任務領域相關文獻資料,分析未登錄詞、生成重復、長程依賴、評價標準這4 個核心問題,并以此為分類標準對模型進行分類,研究各模型針對核心問題的解決效果,通過匯總模型設計、數據集、評價指標、生成效果等方面性能,對比分析各模型自身的優勢及局限性,并給出相應的解決方案。在此基礎上,對該技術未來發展進行局限性分析與前景展望。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
小學教學參考(2015年20期)2016-01-15 08:44:38
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
語文知識(2014年1期)2014-02-28 21:59:13
