基于神經網絡的復句判定及其關系識別研究
2021-11-18 02:18:32賈旭楠魏庭新曲維光顧彥慧周俊生
計算機工程 2021年11期
賈旭楠,魏庭新,曲維光,3,顧彥慧,周俊生
(1.南京師范大學 計算機科學與技術學院,南京 210023;2.南京師范大學 國際文化教育學院,南京 210097;3.南京師范大學 文學院,南京 210097)
0 概述
復句是由2 個或2 個以上的單句構成的句子,它下接小句,上承篇章,是語言的基本單位之一。由于復句有2 套或2 套以上主語謂語,而單句只有1 套主謂體系,因此判定一個句子是否為單復句對于句法分析、依存解析、AMR 自動解析及相應的下游任務非常重要。對于復句語義的構成,文獻[1]指出復句除了本身的語義外,還與分句之間的邏輯語義有關,復句的語義等價于該句子的邏輯語義與各分句的語義之和。由于篇章的各種邏輯語義關系在復句中都有所體現,因此復句關系識別是篇章語義關系研究的起點和基礎,對篇章語義解析以及機器閱讀理解、關系抽取等下游任務都有著非常重要的作用。
對于復句的研究,語言學界主要集中在復句的邏輯語義關系的分類等,在自然語言處理領域,研究人員的關注則集中在顯式復句的關系詞識別和隱式復句關系識別2 個方面。然而,顯式復句和隱式復句的識別主要靠人工標注,現有文獻中并沒有顯式復句與隱式復句的自動識別研究。在漢語中,由于標點符號還具有語氣停頓功能,含有多個形式分句的句子不一定是復句;同時由于大量緊縮句的存在,沒有標點符號的句子也不一定是單句,這些都給單復句的自動識別造成一定困難。在隱式復句關系識別方面,雖然目前研究較多,但目前最好的性能也僅有56.20%[2],還有進一步的提升空間。
本文提出復句判定及復句關系識別聯合模型,旨在同時解決復句判定和復句關系識別問題,實現復句的自動判定及復句關系的自動識別。在復句判定任務中通過Bi-LSTM 對句子進行編碼,采用注意力機制挖掘更深層次的語義信息后,通過卷積神經網絡(CNN)提取句子中的局部信息,最終對其進行分類。在復句關系識別任務中使用詞向量Bert增強句子的語義表示,采用Tree-LSTM 對成分標記和句子中的單詞進行聯合建模后,并對建模結果進行分類。
1 相關工作
復句作為自然語言中重要的語法單位[3],在語言學上的理論成果較為豐富,且研究范圍也較為廣泛。對于復句的邏輯語義關系分類,代表性的研究主要有:文獻[4]提出的兩分法,依據分句之間的語義關系,將復句分為聯合復句和偏正復句兩大類;文獻[5]將聯合復句分為并列、遞進、順承、選擇、解說5 個小類,將偏正復句分為轉折、因果、假設、目的、條件5 個小類;另外一種是文獻[6]提出的三分法,復句三分法的一級分類分為廣義因果關系、廣義并列關系和廣義轉折關系三大類,因果關系分為因果、推斷、假設、條件、目的等,并列關系分為并列、連貫、遞進、選擇等,轉折關系分為轉折、讓步等。
隨著理論研究的不斷深入,復句的相關研究逐漸從理論轉向信息處理領域,關聯詞作為復句的重要信息。文獻[7]對語料進行分析并總結出一個復句關聯詞庫,采用基于規則的方法對關聯詞進行自動識別;文獻[8]考慮到關聯詞與語境的關系,以復句關聯詞所處的語境以及關聯詞搭配為特征進行特征提取,使用貝葉斯模型實現關聯詞的識別;文獻[9]充分利用句子的詞法信息、句法信息、位置信息,采用決策樹對復句進行復句關系分類,在顯式復句中取得了較好的效果;文獻[10]用極大似然估計計算關聯詞對于各類關系的指示能力,構造關聯詞-關系類型矩陣,預測句子的復句關系類別;文獻[11]提出了一種基于句內注意力機制的多路卷積神經網絡結構對漢語復句關系進行識別,其研究對象既包括顯式復句也包括隱式復句,F1 值達到85.61%,但其僅在并列、因果、轉折三類復句關系中進行識別,并沒有涵蓋自然語言中的大部分復句類別;文獻[12]采用在卷積神經網絡中融合關系詞特征的FCNN 模型,對復句關系進行分類,準確率達到97%,但其研究對象僅為二句式非充盈態復句;文獻[13]利用關聯詞的詞性分布規則標注潛在關聯詞,對比關聯詞庫中的模式表,標注出其語義關系。
由于隱式復句中沒有關聯詞連接分句,因此隱式復句關系的識別較顯式而言更為困難,目前專門針對復句判定、復句關系識別的研究比較少,大部分研究都是針對篇章進行的,然而由于漢語復句與篇章之間存在天然的聯系,有關篇章的研究仍有許多值得借鑒的地方。文獻[10]實現了基于有指導方法的隱式關系識別模型,融入依存句法特征和句首詞匯特征,采用對數據不平衡容忍度較高的SVM 實現對篇章關系的識別;文獻[14]以詞匯、上下文信息及依存樹結構信息作為特征訓練最大熵分類器,以實現復句關系的自動識別;文獻[2]在中文篇章樹庫(CDTB)上提出了模擬人類重復閱讀和雙向閱讀過程的注意力機制網絡模型,得到論元信息的交互表示。
2 基于注意力機制的復句判定模型
復句判定是指對于給定句子,復句判定系統能夠準確地識別出是否為復句。如表1 中的例句1 即為包含關聯詞的顯式復句,例句2 為緊縮型復句,例句3 為無關聯詞的隱式復句,上述3 類統稱為復句,例句4 為單句。

表1 單復句示例Table 1 Examples of simple and complex sentences
本文以循環神經網絡為基礎實現復句的自動判定,模型主要分為輸入模塊、編碼模塊、輸出模塊3 個部分,其模型結構如圖1 所示。
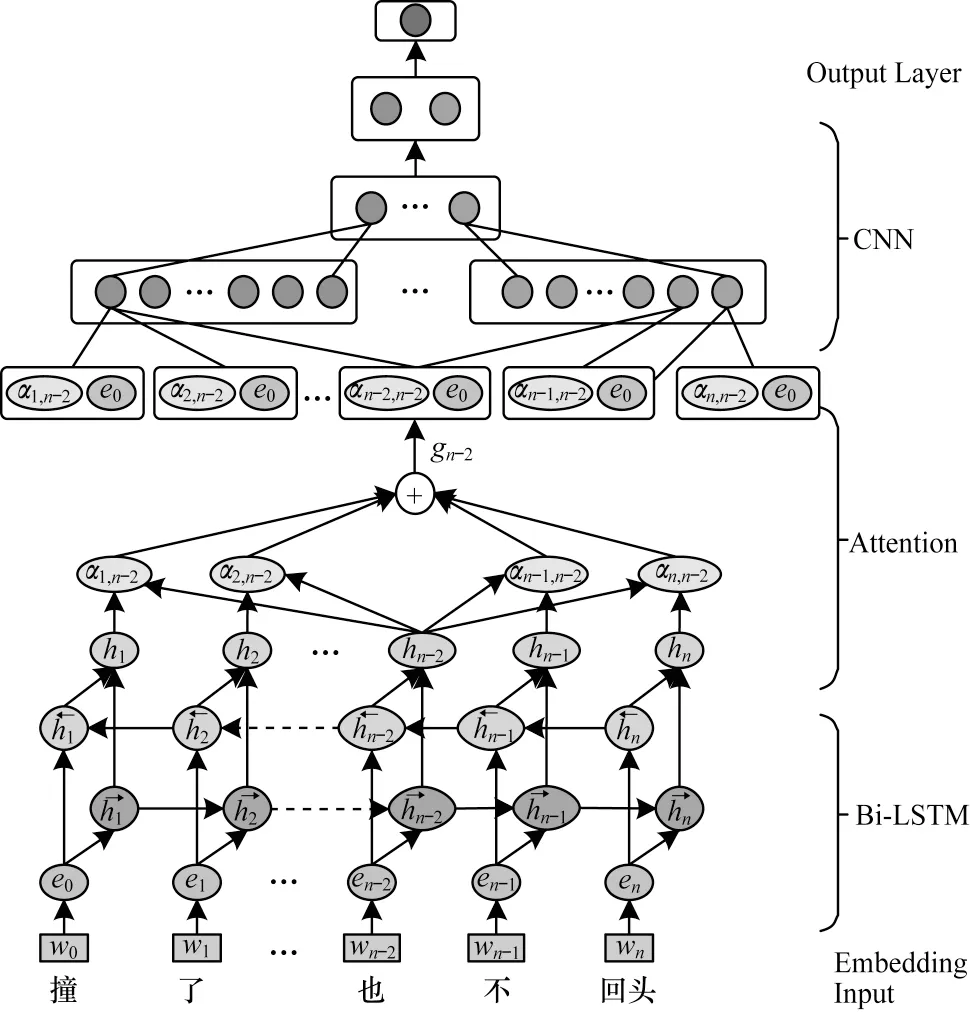
圖1 基于循環神經網絡的復句判定模型Fig.1 Model of complex sentence identification based on recurrent neural network
2.1 判定模型輸入模塊
2.2 判定模型編碼模塊
對復句的判定需要著眼于整個句子的內容,句子中某一個詞的語義信息由上下文信息共同決定,因此采用Bi-LSTM 對句子中的詞語表示進行建模,以便較準確地獲得句子的語義信息,通過前向LSTM 和后向LSTM 計算得到句子向量表示,將兩者拼接得到當前狀態的向量表示。由于復句由2 個或2 個以上分句組成,與單句相比,句法結構更加復雜,長度更長,因此一層遍歷所得到的語義信息往往是不足的,采用多層Bi-LSTM 能夠避免梯度爆炸、梯度消失等問題。本文采用了多層Bi-LSTM 來學習文本數據中的層次化信息、增加語義建模的準確性。
由于復句語義關系是由分句語義的交互作用而形成的,因此本文采用了能夠衡量內部相關性的Self Attention[16]。計算方式如式(1)~式(3)所示:
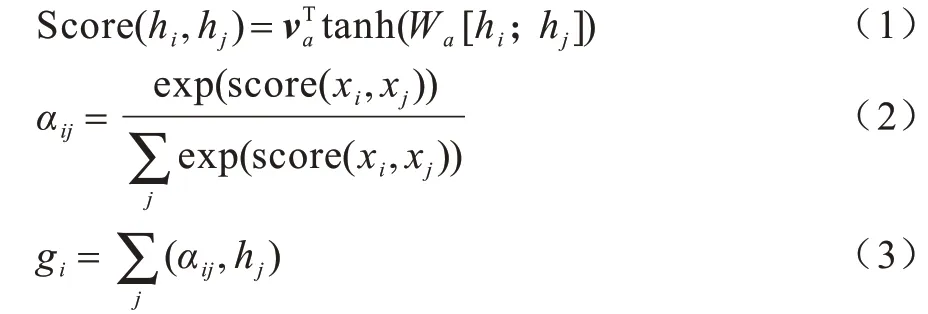
為挖掘文本中更深層次的語義信息,引入了卷積神經網絡(CNN),通過卷積核提取出相鄰單詞的特征,對卷積層輸出的結果進行池化操作,從而將最重要的特征提取出來。本文采用max-over-timepooling 操作,即將最大值作為最重要的特征。
2.3 判定模型輸出模塊
該模型在全連接層后通過softmax 函數對給定句子進行復句的判定預測。

其中:W和b分別為權重和偏置;C為經過模型編碼后的輸出。此外,本文所使用的損失函數為負對數似然函數。
3 基于Tree-LSTM 的復句關系識別模型
識別復句關系對于把握句子整體語義有至關重要的作用,也是本文另一項重要任務。表2 為4 種出現頻率較高的復句關系類別示例。

表2 復句關系類型示例Table 2 Examples of complex sentence relation types
本文基于Tree-LSTM 的復句關系識別模型的輸入為給定句子的2 個論元,輸出為復句關系預測結果。該模型由輸入模塊、成分句法樹模塊、編碼模塊和輸出模塊構成,模型結構如圖2 所示,下面依次對上述4 個模塊進行展開。
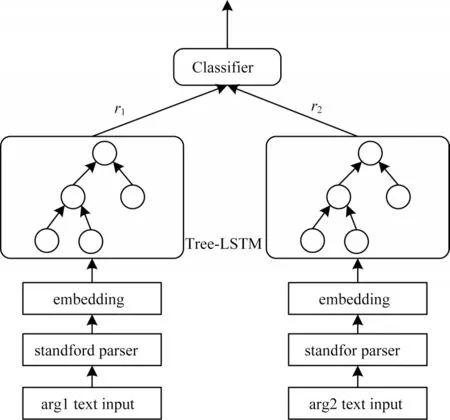
圖2 基于Tree-LSTM 的復句關系識別模型Fig.2 Model of complex sentence relation recognition based on Tree-LSTM
3.1 成分句法樹
成分句法樹能夠清晰地將句子中所包含的句法及句法單位之間存在的關系展示出來。在自然語言中,不同類型短語所對應的語義的重要性也各不相同,在一般情況下相較于動詞短語,介詞短語對復句關系影響較小。
圖3 為復句“孟山都在歐洲遭遇滑鐵盧,肯定會開拓市場彌補損失”中2個分句的成分句法樹表示,在arg1中存在介詞短語“在歐洲”和動詞短語“遭遇滑鐵盧”,在arg2 中有動詞短語“開拓市場”“彌補損失”,通過比較2 個論元的動詞短語,容易分析出2 個論元呈現因果關系,如果把arg1 中的介詞短語和arg2 中的動詞短語進行比較則難以得出上述結論。由此可見,句子中的成分信息對于復句關系識別具有一定的輔助作用,故本文采用Stanford Parser 得到句子中每個論元的成分句法樹,將成分句法樹的標記嵌入到詞語的embedding中。
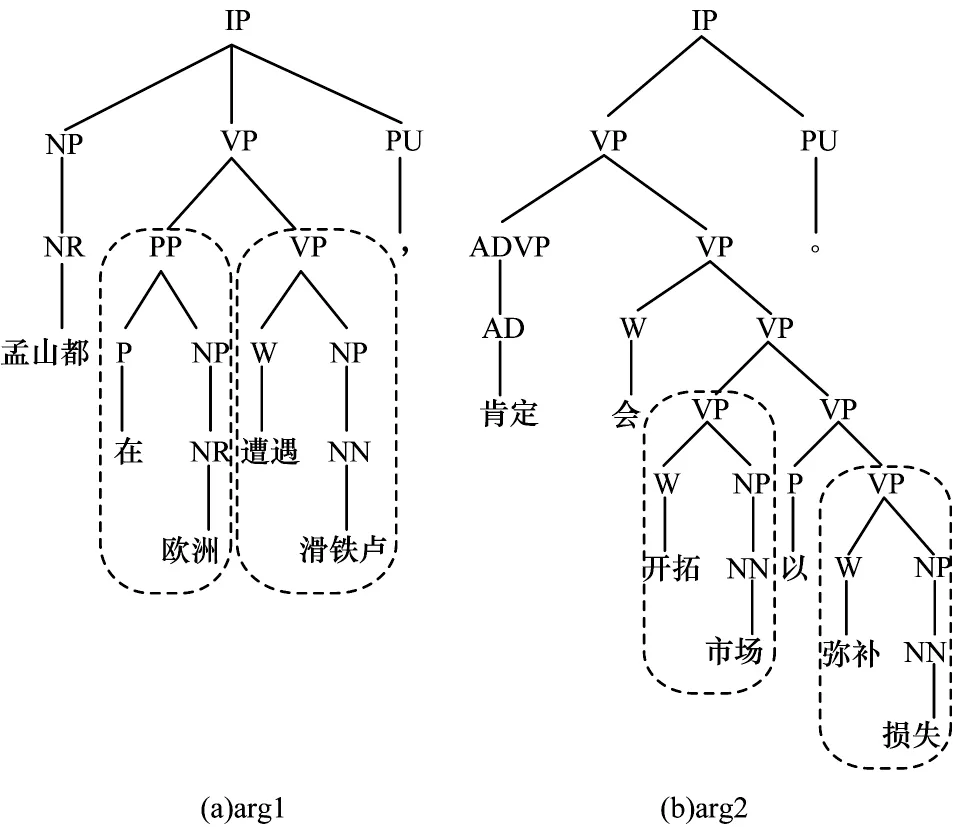
圖3 成分句法樹實例Fig.3 Example of constituent syntactic tree
3.2 識別模型輸入模塊
本文通過文獻[17]提出的預訓練語言模型Bert構造詞語的向量表示,采用隨機初始化的方式構造成分句法樹標記向量,對于輸入的句子c={c1,c2,…,cn},其中ci={wordi,tagi},1≤i≤n,ci包含在i這個位置上所對應的詞以及該詞在成分句法樹中所對應的標記,對于每一個詞ci,將其詞向量和標記向量進行拼接,得到對應的向量表示ei=[wi;ti]。
3.3 識別模型編碼模塊
雖然鏈式的LSTM 已經取得了較好的效果,但是句子的語義不僅僅是由單個詞的語義進行簡單的拼接而成的,句子的結構信息也起著至關重要的作用,本文在編碼時采用了能夠捕獲句子語義信息的同時也考慮句子的結構信息的Tree-LSTM[18]。
與LSTM 類似,Tree-LSTM 由1個輸入門、1個輸出門和多個遺忘門構成,遺忘門的個數與樹節點數一致,即本文采用的方法有2 個遺忘門。但Tree-LSTM 的當前狀態并不取決于上一時刻的隱藏層狀態,而是取決于孩子節點的隱藏層狀態,其計算方式也在LSTM 的基礎上做出了調整,如式(5)~式(7)所示:
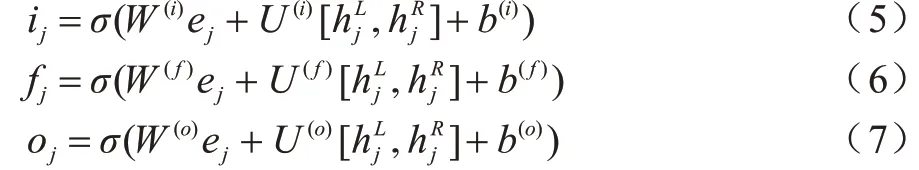
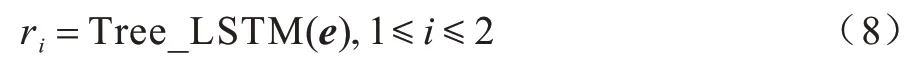
在通過Tree-LSTM 編碼后,在復句關系識別任務中采用前饋神經網絡,對Tree-LSTM 編碼后的結果進行編碼,在關聯詞的分類任務中采用了卷積神經網絡對輸出結果進行編碼。
3.4 識別模型輸出模塊
在輸出模塊中,最終將復句中2 個論元的表示送入softmax 函數得到復句關系分類的概率,計算公式如下:

其中:D為訓練時所用的數據集;R為復句關系的類型;yi(x)為訓練樣本x的標簽(x)為通過本文模型得到的樣本x被預測為屬于類型i的概率值。
4 復句判定及復句關系識別聯合模型
在統計模型的基礎上,可將模型分為管道式模型和聯合模型兩大類。管道式模型的方式容易傳遞誤差,導致模型的性能衰減,且各環節獨立進行預測,忽略了2 個任務之間的相互影響,無法處理全局的依賴關系。聯合模型則是將各個模型通過整體的優化目標整合起來,從整體的結構中學習全局特征,從而使用全局性信息來優化局部預測的性能。因此,本文采取聯合模型同時進行復句判定和復句關系識別。模型結構如圖4 所示,主要分為輸入模塊、編碼模塊、輸出模塊3 個部分。
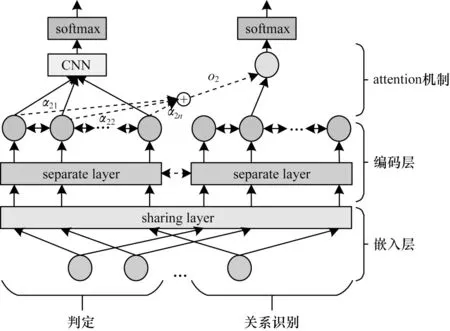
圖4 復句判定及復句關系識別聯合模型結構Fig.4 Joint model structure of complex sentence identification and compelx sentence relation recognition
4.1 聯合模型輸入模塊
在自然語言處理的相關任務中,一個單詞的特征或者含義不應該因為任務的不同而不同,統一的向量表示使聯合學習模型不過分地傾向于某一任務,增加了模型的泛化能力,故本文在嵌入層中復句判定和復句關系識別任務的嵌入層中共享向量表示。
參數共享是聯合模型中較為常見的一種方式,可以分為硬共享和軟共享2 種。硬共享指多個模型之間的共享部分直接使用同一套參數,使模型學習到可以表示多個任務的解;軟共享通常是通過計算多個模型之間的共享部分的參數之間的差異,使其差異盡可能得小,并保留任務的獨立性。為了使模型在底層的句子表示中使復句的判定和復句關系識別任務可以相互借鑒,故本文在參數共享中選擇了參數軟共享方式,使多個模型中需要共享部分的參數差異盡可能得小,這種參數共享方式能夠使模型在學習多個任務共有的表示下保留任務的獨特性,對不同的任務學習不同的句子表示。

4.2 聯合模型編碼模塊
對于復句判定任務,編碼層采用Bi-LSTM 進行編碼,獲得句子的上下文表示信息,將Bi-LSTM 的結果作為CNN 的輸入,得到句子的局部特征表示。
在復句關系識別任務中,為了得到句子的結構化信息,采用Tree-LSTM 進行編碼。此外,由于復句判定任務中學到的句子表示有助于豐富復句關系識別任務中的信息,因此本文引入了注意力機制對這部分信息進行學習。在復句判定編碼層輸出的上下文詞表示為,復句關系識別編碼器獲得的輸出記為,通過下式計算:

4.3 聯合模型輸出模塊
在得到新的向量表示后,將編碼后的結果通過softmax 函數進行進行復句判定和復句關系識別。若在聯合模型中輸入的句子被判定為單句時,該句子在進行復句關系識別后會進行后處理,將其復句關系識別的結果更正為無關系。
在聯合模型中損失函數的定義是一個十分棘手的問題,若2 個任務之間出現梯度不平衡的問題會導致參數的更新傾向于某個單獨的任務,降低所有模型的表現效果。故本文計算2 個任務之間的損失采用靜態加權求和的方式,將不同任務之間的損失進行組合,計算公式如下:
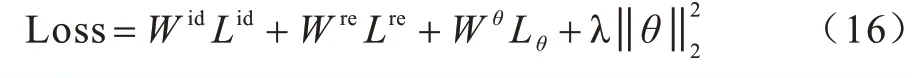
其中:Wid和Lid分別為復句判定模型的權重和總損失;Wre和Lre分別為復句關系識別任務中的模型的權重和總損失;θ為模型的參數;Lθ為參數軟共享所構成的參數距離損失。
5 實驗結果與分析
5.1 數據集
本文中 所使用 的語料是由CAMR[19](Chinese Abstract Meaning Representation)和篇章結構樹庫[20]中抽取的復句語料。圖5 為CAMR 中復句的結構示例。

圖5 CAMR 復句結構示例Fig.5 Example of CAMR complex sentence structure
在CAMR 中共標記了并列、因果、條件、轉折、時序、遞進、選擇、讓步、反向選擇9 類復句關系,但由于后5 類僅占語料的4.23%,因此對這5 類進行了歸并,得到了如表3 所示的數據集,其中無關系類別為單句,共5 359 種。
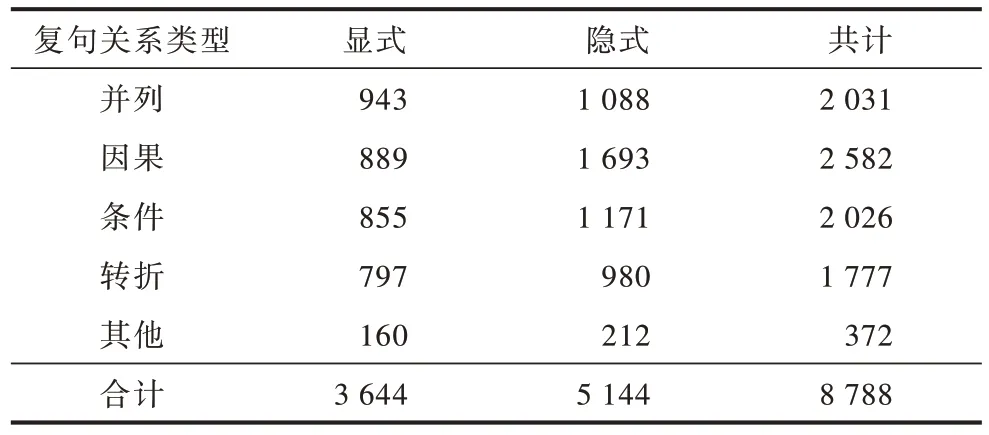
表3 語料庫中復句關系統計Table 3 Statistics of complex sentence relations in corpus
5.2 復句判定
在復句判定實驗中訓練集、測試集的比例為4∶1,由于深度學習算法容易出現過擬合的問題,因此在每一層的輸出中進行Dropout[21]操作,采用Adam[22]算法對模型進行優化,實驗中所涉及的參數設置如表4 所示。
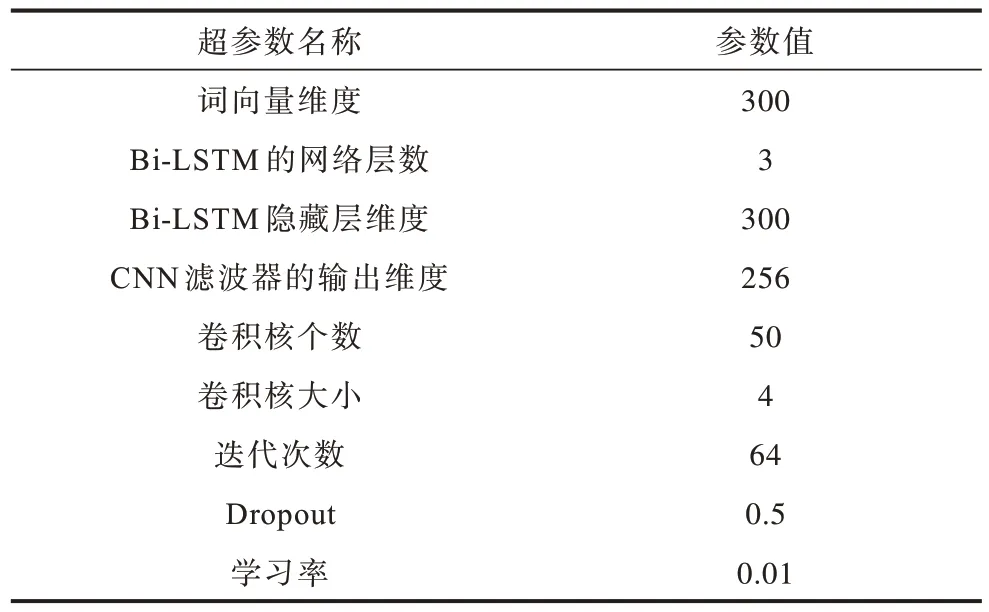
表4 復句判定模型的超參數設置Table 4 Hyperparameter settings of complex sentence identification models
表5 為復句判定任務的實驗結果,可以看到僅使用Bi-LSTM 時準確率(P)達到94.81%,但召回率(R)較低,這是因為Bi-LSTM 著眼于復句的整體語義,若復句句法結構不夠典型則效果較差,無法識別。Attention 機制能夠捕獲分句間對揭示語義有提示作用的詞語或搭配信息,因此F1 值提升了6.07 個百分點。CNN 的加入則是突出了分句內部對語義有提示作用的局部信息,因此性能進一步提高。這說明對于復句而言,除了整體語義外,局部語義及分句間的語義交互作用對揭示復句語義有著同樣重要的作用。
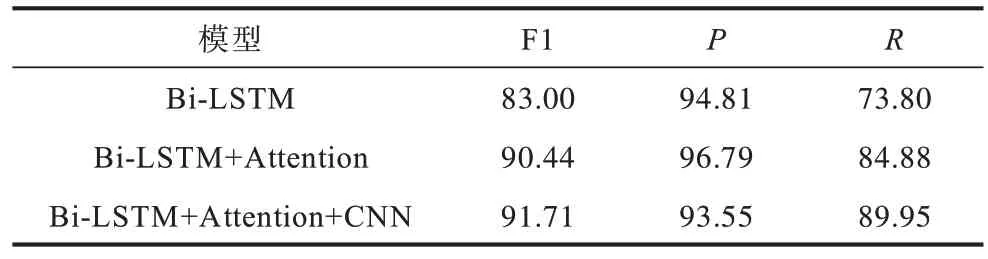
表5 復句判定實驗結果Table 5 Experimental results of complex sentence identification %
為了更好地分析模型的性能,本文對測試集中的顯式復句和隱式復句的實驗結果進行分析,其實驗結果如表6 所示。
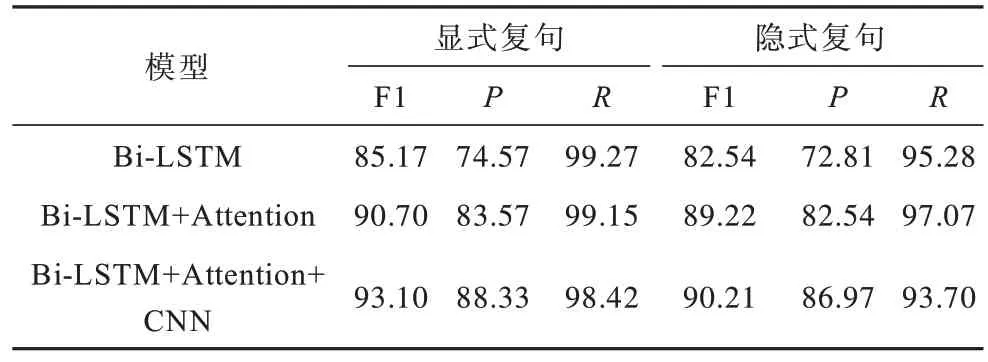
表6 顯式及隱式復句判定實驗結果Table 6 Experimental results of explicit and implicit complex sentence identification %
從表6 可以看出,與表5 相似,無論是在顯式復句還是在隱式復句中,加入Attention 和CNN 以后的F1 值均高于其他2 種方法,這再次證明了局部信息的引入有助于提升模型對復句判定的性能。另外,通過比較顯式復句和隱式復句的判定結果可以發現,顯式復句的F1 值比隱式復句的F1 值高2.89 個百分點,這是因為隱式復句中并沒有關聯詞這一明顯的淺層特征,在編碼時其內部的語義信息較難挖掘,導致隱式復句判定結果較低。
5.3 復句關系識別
在復句關系識別任務中所涉及的超參數如表7所示,復句關系識別任務的結果展示如表8 所示。
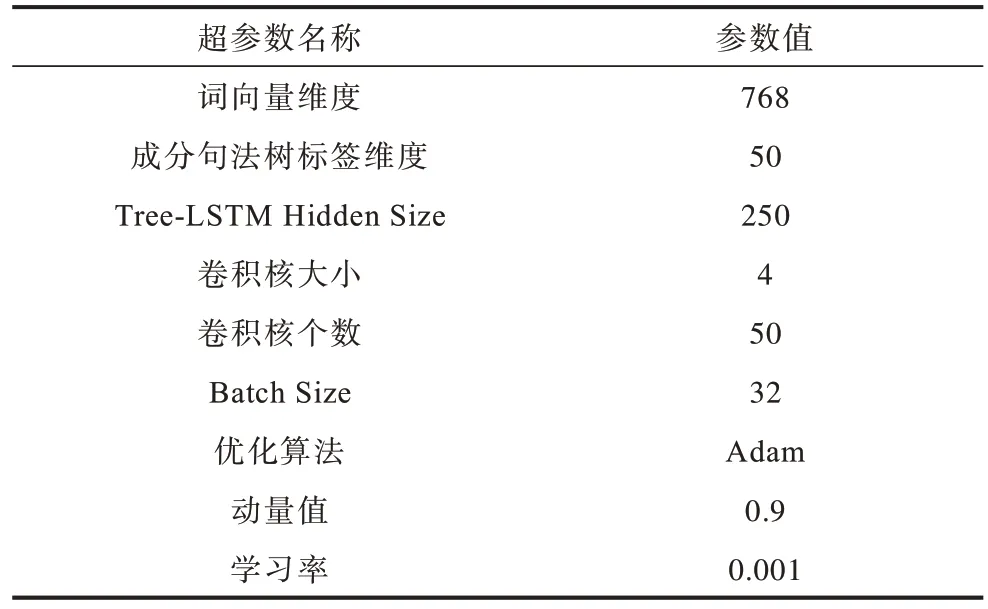
表7 復句關系識別模型的超參設置Table 7 Hyperparameter settings of complex sentence relation recognition model

表8 復句關系識別實驗結果Table 8 Experimental results of relation recognition of complex sentences %
表8 中LSTM 模型表示只考慮句子的上下文語義信息,對句子的語義進行建模,但句子的語義信息并不只是每個詞語義的疊加,與句子的結構信息有一定的關系,Tag+Tree-LSTM 模型考慮句子的句法結構信息,并在編碼過程中融入成分句法樹的標簽信息,這種方式相較于只考慮上下文語義信息的LSTM 而言,效果提升了0.27 個百分點;在Tag+Tree-LSTM 中采用了隨機初始化的詞向量方式,但預訓練的詞向量能夠更好地反映出詞語詞之間的關系以及句子的語義信息,故在Tag+Tree-LSTM 的基礎上加入了句子級的詞向量Bert,模型的性能提高了3.37 個百分點。
表9 所示為本模型與其他模型的實驗結果對比,相比于文獻[14]針對漢語篇章結構語料庫提出的基于多層注意力的TLAN 方法,本文提出的方法采用Tree-LSTM 能夠充分利用句子的結構信息,預訓練詞向量Bert 的引入對漢語中一詞多義現象有所解決,因此本文所提出的Tag+Tree-LSTM+Bert 模型F1 值達到58.17%,相較于TLAN 模型,提升了1.97 個百分點。

表9 模型實驗結果對比Table 9 Comparison of the model experimental results %
表10 所示為復句判定和復句關系識別任務構成的管道式模型實驗結果,與前文中提出的Tag+Tree-LSTM+Bert 模型相比,pipeline 模型的實驗結果比直接進行復句關系識別任務的模型低,這是因為pipeline 需要先進行復句判定任務,然后再進行復句關系識別。
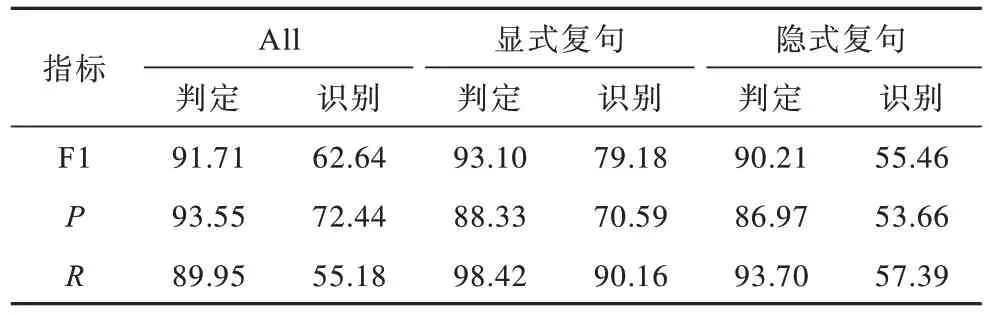
表10 復句判定及復句關系識別pipeline 模型結果Table 10 Pipeline model results of complex sentence identification and complex relation recognition %
5.4 復句判定及復句關系識別聯合模型
在聯合模型中,通過聯合學習利用任務之間可以相互作用的特征,表11 為復句判定及復句關系識別聯合模型的實驗結果。
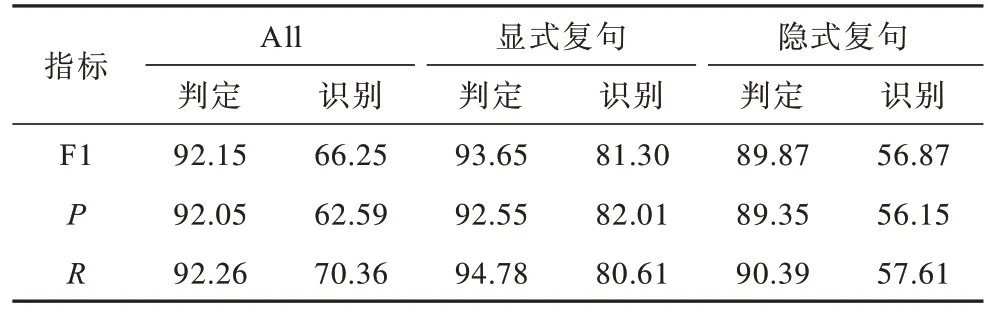
表11 聯合模型實驗結果Table 11 Experimental results of joint model %
通過比較表10 和表11 可以發現,無論是在復句判定任務還是在復句關系識別任務中,聯合模型的F1 值相比管道式模型都有所提高,表11 聯合模型中復句判定任務的F1 值較表10 中管道式模型提高了0.44 個百分點,聯合模型復句關系識別的F1 值為66.25%,與管道式模型的實驗結果62.64%相比提高了3.61 個百分點,這是因為聯合模型能夠有效地減少模型之間的誤差傳遞。
6 結束語
本文基于神經網絡方法對復句判定及復句關系識別任務進行研究,構造復句判定和復句關系識別聯合模型,通過減少管道式誤差傳遞以實現復句的自動判定和復句關系的自動識別。實驗結果驗證了本文方法的有效性。由于神經網絡方法對語料規模較為依賴,因此下一步將繼續擴充語料規模,提高網絡模型性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
外語學刊(2011年1期)2011-01-22 03:38:33
