數據預處理中缺失數據處理方法的研究綜述和展望
2021-11-18 03:55:12姚超
科學與生活 2021年20期

摘要:數據預處理是提升數據質量的重要方法,它主要涉及到數據審計、數據清洗、數據變換、數據集成、其他預處理方法等多個方面,本文主要研究數據清洗中的缺失數據處理方法。本文主要闡述了缺失數據的類型、缺失數據處理所面臨的主要問題和挑戰、填補缺失數據的方法及數據缺失處理最新的研究趨勢,通過分析得出今后對于缺失數據的研究將會逐步回到該數據所屬的特定領域,充分結合該領域的特點與規律來對缺失數據進行填補,而不僅僅針對數據本身或基于其統計學上的特征進行填補。
關鍵詞:數據預處理;缺失數據處理;缺失數據填補
1 引言
數據預處理是指在主要的處理以前對數據進行的一些處理[1]。現如今,數據的數量越來越龐大,且來來源多種多樣,因此出現數據異常(也稱為臟數據)的可能性不斷增加。這些臟數據不能直接用于數據分析和數據挖掘,或數據分析和數據挖掘的結果不夠理想。為了提升數據分析和數據挖掘的質量,數據預處理的重要性與日俱增,并且已經成為數據科學中的基本步驟。其中,數據預處理主要包含以下幾個方面:數據審計、數據清洗、數據變換、數據集成、其他預處理方法等。本文將主要針對數據清洗中的缺失數據處理進行展開。
真實數據集中通常都含有缺失數據,缺失數據的存在會明顯地降低算法或模型的有效性,因此,缺失數據處理是一個不可或缺的數據預處理過程。
在處理缺失數據前,了解缺失數據的類型是非常有必要的。缺失數據類型根據缺失隨機程度的不同分為完全隨機缺失(Missing Completely at Random,MCAR)、隨機缺失(Missing at Random,MAR)、非隨機缺失(Missing not at Random,NMAR)[2]。這三種類型的缺失數據特征及示例如表1所示。
在現實生活中,雖然非隨機缺失相對于其它兩種缺失類型來說更加常見,但是處理起來卻是最麻煩的。處理非隨機缺失時必須遵循一定的假設,即把它先轉化成隨機缺失,然后再按照隨機缺失的機制進行處理[3]。數據集的缺失類型也會影響填充算法的選擇及填充的最終效果[4]。
2 主要研究問題
為了盡可能減少缺失數據對算法或模型的有效性的影響,我們必須要針對這些缺失數據進行一定的處理。
針對缺失數據的處理一般分為兩類:一類是直接刪除含有缺失值的數據點,這種方法簡單易操作,但缺點是在缺失比例較高時,該方法會造成信息的大量流失從而降低有效性。另一類是缺失值填補方法,用估計值來代替缺失值。
因此,對于缺失數據的處理主要問題與挑戰是:當缺失比例較大時,如何對缺失值進行填補可以達到最好的效果,即對缺失值進行填補要盡量讓填補值接近真實值,以避免對經填補后的數據集在分析時與原始數據集分析結果產生偏差。
3 缺失數據填補方法
一般情況,缺失數據填補方法主要分為基于統計學的填補方法和基于機器學習的填補方法[5]。
3.1 基于統計學的填補方法
基于統計學的重構方法有均值填補法、中位數填補法、眾數填補法、多項式擬合法、級比生成法、三次樣條插值法和遞推式非鄰均值補全法等。
基于統計學的重構方法較為簡便快速,但是填補的數據偏差較大,且忽略了數據之間相關性等[6]。
3.2 基于機器學習的填補方法
機器學習技術包括:K近鄰、人工神經網絡、支持向量機、決策樹和隨機森林等。
這些算法都是根據已有數據建立相應模型,然后使用模型來估計該樣本的缺失數據。
3.3 填補方法對比
在廖祥超[3]的研究中,他固定樣本缺失率為10%,以單個變量隨機缺失和多個變量隨機缺失兩種模式生成相應的缺失數據集,在此基礎上用均值、隨機、線性回歸、多重填補、KNN、決策樹、隨機森林、支持向量機、神經網絡這九個方法進行填補,并從填補誤差和建模效果的角度對不同填補結果進行比較。從填補誤差的角度看:在個體方面,回歸填補法和神經網絡填補法得到的值與真實值相等的個數要多于其它的填補方法;但是從整體來看,支持向量機填補法和KNN填補法的平均絕對誤差(Mean Absolute Error,MAE)和均方誤差(Mean Square Error,MSE)要優于其他方法。在缺失率相同的3個多個變量缺失的數據中,他經過對比發現多重填補法、KNN填補法、隨機森林填補法的填補效果要明顯高于其它填補方法。
楊弘[7]研究團隊針對混合型缺失數據(即同時存在連續變量和分類變量),模擬四種缺失比例(10%、20%、30%、50%)的測試數據,在隨機缺失(MAR)假設下采用MissForest(缺失森林算法,一種基于隨機森林的一種迭代填補算法)、因子分析(factorial analysis for mixed data,FAMD,基于主成分分析法)、KNN填補法和基于參數調整的鏈式方程多重填補(multivariate imputation by chained equations,MICE)對測試數據進行缺失值填補。經過對比發現:FAMD與MissForest相比,對分類變量填補表現優越;缺失比例為10%時,FAMD與MissForest表現優于KNN和MICE;缺失比例達到20%時,FAMD明顯優于其它三種方法,但是MissForest表現亦可;缺失比例達到30%時,四種模型表現明顯下降,處理效果均不太理想;缺失比例達到50%時,雖然FAMD仍有兩個變量符合優良標準,但對某些變量估計誤差較大,其它三種方法填補均失效。
因此,在對缺失數據進行填補時,我們需要結合實際的缺失數據類型、缺失比例、是否為多變量缺失等多方面因素進行綜合考慮,然后選取合適的填補方法進行缺失數據填補以期望達到最優的效果。
4 最新研究
4.1 研究趨勢
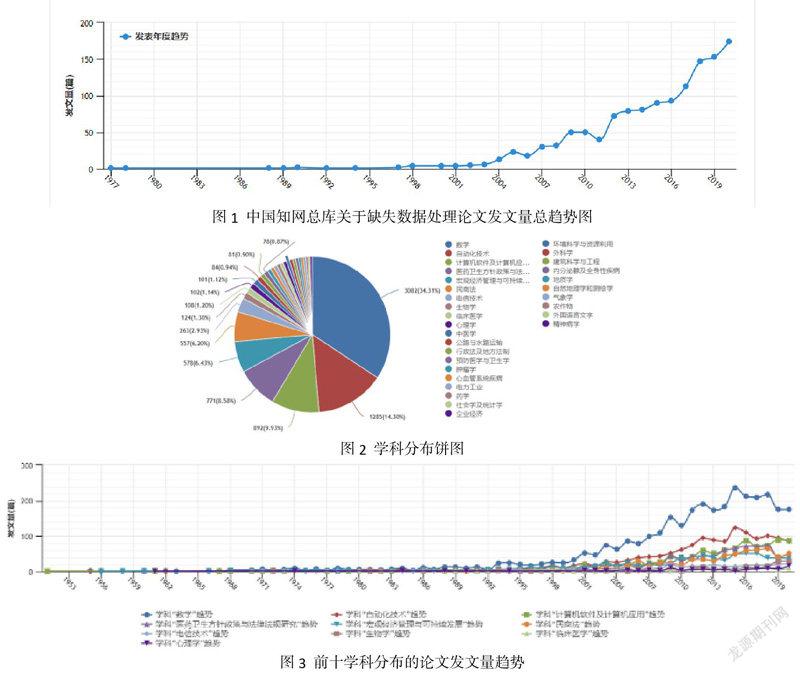
在中國知網總庫(含中文和英文)中檢索“缺失數據”或“缺失值”(使用“中英文擴展”),并篩選出與缺失數據處理相關的主要主題,總共檢索到5945篇論文,結合中國知網的結果分析功能可以得到關于該研究的一個總體趨勢(圖1),并結合學科進行分別統計可以得到針對缺失數據在學科上的一個分布情況(圖2),最后選取前十分布的學科進行一個趨勢統計(圖3)。
從圖1中可以看出,與缺失數據處理相關的研究論文呈快速上升趨勢。這主要是因為近幾年整個大數據行業的興起,使得人們對數據處理的關注度日漸提升,為了能夠更加有效地分析與挖掘數據中的規律與價值,人們對數據質量的要求也日益增高,而研究缺失數據處理方法是其中非常重要的一個環節。結合圖2可以看出,雖然在數學或計算機領域仍有大量的研究工作以改進各種算法來提升缺失數據填補的效果,但是整體趨勢開始一點下降。而在圖3中可以看出,在其他學科領域中,針對缺失數據填補方法的研究呈逐年上升的趨勢。
4.2 結合特定領域規律的填補方法
通過圖3可以發現其他的學科領域在進行數據分析與挖掘時對缺失數據處理的方法越來越重視,且其處理方法并不局限于統計學或機器學習等方法,有很多研究者開始從其數據所屬專業領域本身出發,結合其領域中的特定規律與特點以及統計學或機器學習等方法來進行缺失數據的填補。
武佳卉[6]研究團隊提出了一種基于物理特性的新能源電力數據填補方法,其主要思想是充分利用新能源出力的物理特性,實現通過已知的新能源場站輸出功率求得待填補電場的輸出功率,有效改善了數據填補效果。
在姚小龍[8]的研究中,在分析光伏出力特性的基礎上,提出了一種基于光伏出力相關性的缺失數據填補方法,在其研究中發現該預測方法能夠顯著減小預測誤差并提升預測精度。
5 總結與展望
現如今大家都是基于當前一些統計學或機器學習算法進行改進以期望得到更優的一種缺失數據填補方法。這些改進算法確實在一定程度上提升了數據填補的效果,但是提升的空間有限。結合第四節的分析,可以得出今后對于缺失數據的研究將會逐步回到該數據所屬的特定領域,充分結合該領域的特點與規律來對缺失數據進行填補,深入挖掘分析數據與數據之間或數據集之間的內在規律,并結合這些規律去進行缺失數據的填補,這樣所獲得的填補效果將會更加貼合真實情況。
參考文獻
[1] 百度百科.數據預處理[EB/OL].https://baike.baidu.com/item/%E6%95%B0%E6%8D%AE%E9%A2%84%E5%A4%84%E7%90%86,2020-12-13.
[2] Wikipedia. Missing data [EB/OL]. https://en.wikipedia.org/wiki/Missing_data,2020-12-13.
[3] 廖祥超.九種常用缺失值插補方法的比較[D].云南師范大學,2017.
[4] 金連.不完全數據中缺失值填充關鍵技術研究[D].哈爾濱工業大學,2013.
[5] 劉莎,楊有龍.基于灰色關聯分析的類中心缺失值填補方法[J].四川大學學報(自然科學版),2020,57(05):871-878.
[6] 武佳卉,邵振國,楊少華,肖頌勇 ,吳國昌.數據清洗在新能源功率預測中的研究綜述和展望[J].電氣技術,2020,21(11):1-6.
[7] 楊弘,田晶,王可,張青,韓清華,張巖波.混合型缺失數據填補方法比較與應用[J].中國衛生統計,2020,37(03):395-399.
[8] 姚小龍.分布式光伏發電全氣象系統及區域出力預測方法研究[D].浙江工業大學,2019.
作者簡介:
姚超(1987-),男,湖北武漢人,工程師,碩士,主要研究方向為大數據和軟件技術。
