信息相似性下網絡對抗文本重復數據分級索引
2021-11-19 11:16:10曹福凱MuhdKhaizerOmar
計算機仿真 2021年10期
高 晶,曹福凱,閆 明,Muhd Khaizer Omar
(1.華北理工大學冀唐學院,河北唐山063210;2.華北理工大學,河北唐山063210;3.Faculty of Educational Studies Universiti Putra Malaysia,PutrajayaUPM Serdang,Selangor,Malaysia,43400)
1 引言
處在大數據時代,互聯網已經成為人們查找資料的重要檢索平臺,人類時時刻刻離不開互聯網應用,因此必須保證網絡數據的完整,確保檢索結果十分全面,就這一問題展開研究[1-2]。
朱命冬[3]等人提出面向不確定文本數據的余弦相似性重復數據分級索引方法,該方法通過計算余弦距離并進行轉換,改進索引結構MVP-tree,同時利用余弦相似度面向不確定性數據的相似度計算方法,并結合分布式環境下k NN和Rk NN查詢算法精確分類數據,實現重復數據分級索引。該方法未將數據進行降維處理,導致運行空間維度較高,加長了時間消耗,降低了分級效率。韓英[4]等人提出云計算環境下具有相似性的重復數據分級索引方法。該方法將云終端作為重復數據的中轉站,實時獲取網絡數據,計算歷史數據的相似度,篩選出合適的數據塊,經過訓練生成基礎分類器,利用KL散度計算權重系數,確定分類器的有效權值,以此為依據,構成一個集成分類器,實現重復數據分級索引,該方法在重復數據分級前沒有對數據進行預處理,導致無法找出分類特征項,存在分級準確率低的問題。馬曉慧[5]等人提出一種基于語義相似性的重復數據分級索引方法,該方法計算了待分類文本與詞典之間的語義相似度,將語義距離和嵌入的特征結合起來進行分類,以解決語義特征利用不足的問題。并采用詞向量、詞典匹配和特征向量來對重復數據分類性能進行了評估,實現重復數據分級索引,該方法沒有計算數據特征項權重再進行相似數據的分類,出現相似數據不全的情況,從而降低相似數據的提取率。
為了解決上述問題,提出信息相似性下網絡對抗文本重復數據分級索引。
2 網絡數據的預處理
網絡中的各種文本數據皆不相同,導致互聯網無法辨識初始數據,因此需對數據進行預處理,將所有文本轉換成互聯網可識別的特定模式。
2.1 構建向量空間模型
利用向量空間模型表示網絡文本是目前最廣泛的使用模型,該模型是在線性代數的基礎上設計出的較為簡易的模型,此模型是最具操作性及計算性的可進行局部匹配的模型,因此可以更加精確匹配數據。其本質是利用向量空間表示網絡數據,構成此向量的分別是數據特征項及特征項權重[6]。特征項權重是衡量數據可利用程度的重要指標,當系統中存在數據Ti,i=(1,2,…,n),得出關于數據T的向量空間模型如下所示
T:(t1,w1,t2,ww,…,tn,wn)
(1)
式中,tn代表網絡數據文本的特征項,wn代表特征項相應的權重大小。
計算空間向量間的相似度,假設任選兩個數據文本分別為T1:(w11,w12,…,w1n)及T2:(w21,w22,…,w2n),則文本間向量內積的表達式為
(2)
2.2 計算特征項權重
將表示文本的向量空間模型構建完成后,需要立即計算特征項權重大小,進一步對文本進行向量化處理。權重的實質是無論特征項出現次數多或少,都只專注此特征項的可利用程度[7]。
由于TF-IDF權重計算方法即顧忌詞頻問題又考慮文本長度問題,因此廣泛使用該方法計算特征項權重大小,TF-IDF權重由IDF及TF組成,其中TF就是文本中的詞頻,即文本中的某個數據出現的次數,為防止詞頻大小影響文本長度,因此在計算中會提前處理詞頻大小,IDF就是逆文檔頻率,即衡量較為普通的特征項,其運算方式是文本總數與含有此特征項的文本數量的比值,并對此數值進行運算獲取比值,運算公式為
wi=log2(N/ni)×TFi
(3)
式中,wi代表在文本中特征項ti的權重值,N代表訓練文本的總數,ni代表文本中含有特征項的文本數量,TFi代表特征項ti出現的次數。
若出現某特征項只存在個別文本內的情況,證明此特征項的集中程度較高,隨之提升了它的利用率。
2.3 特征降維算法
向量空間模型所處的維度極高的,且此向量空間中的每一維表示一個文本特征項的權重值,若在進行數據處理時直接利用此模型,由于高維度的原因會出現時間消耗較高的問題,因此在構建完向量空間模型后必須通過特征抽取的方法對模型進行降維。
特征抽取是將原有的特征項高維空間通過線性或非線性兩種方法將高維空間轉換成低維空間,并生成全新的低維向量空間,此向量空間不屬于原有向量空間。
2.3.1 PAC算法
PAC算法又叫主分量分析法[8],它將原始變量線性配對并在線性變換下構成文本的主要成分,進而完成高維空間到低維空間的轉換。
假設網絡中有n個訓練樣板,且樣板中都含有p維度,則構成的矩陣為
(4)
1)PAC算法步驟
訓練樣本的關系系數的運算矩陣
(5)
其中,rij表示矩陣變量間的系數。
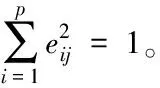
2)文本的利用率
通過上述過程得出文本在網絡中的利用率公式為
(6)
式中,i=1,2,…,p,λk表示文本中的第k個主成分,且k≤p。
則疊加后的全部利用率為
(7)
文本的利用率需大于等于85%小于等于95%即為合格。
2.3.2 LDA算法
PAC算法是只針對數據簡單、指標易選的線性轉換空間降維而言。除此之外都需使用非線性轉換的空間降維方法進行降維,即LDA算法,它的主要原理就是將處在高維空間的文本映射到最佳鑒別矢量空間中進行降維,此算法可確保樣本在低維空間中仍然具有較好的可區分性[9]。
假設網絡中有n個樣本,分成w1和w2兩個種類,w1中有n1個樣本,w2中有n2個樣本,且每個樣本都有p個維度,利用映射函數將樣本全部轉化為一維的函數公式為
y=wTx
(8)
映射函數y的最終結果可直接判別樣本的類別。
1)算法步驟
在映射過程中需保證w值為最優,以方便映射后的樣本數據便于分類,并規定均值點的表達式如下所示
(9)
則樣本映射到合適的矢量空間后的均值點為
(10)
映射后的樣本數據的中心點需遠離地面,且距離越大越好,即滿足下列表達式
(11)
但映射后的空間樣本類別方差越小越好,方差表達式為
(12)
滿足上列兩點要求即可求解映射函數。
空間向量映射函數完成求解后就將文本分類函數轉化為求解最優解的問題,則最優解為
w=(u1-u2)(s1+s2)-1
(13)
式中,s代表原始樣本數據的方差。
經過上述經過可總結出當y≥0時,文本屬于c1類別,否則為c2類別。
3 重復數據分級索引
在進行數據分級索引時需要先對數據進行相似度計算再進行分類,以便分類更加準確[10]。
3.1 計算數據屬性相似度
通常情況下,計算文本數據的相似度都是利用編輯距離法,此方法可通過字符間的距離來體現文本間的相似度[11]。
在編輯距離的基礎上計算出兩個屬性值之間的距離為0,并根據轉換公式求出兩個字符之間的相似度為1,但其中一個字符的屬性值是0.2,因此兩個字符之間的相似度為0.8,由時可總結出,屬性值的大小會對最終的相似度計算產生影響。因此需要完善屬性值的不確定性。
當數據庫中數據之間互相獨立時,其屬性值也一定是獨立的,則同時生成兩個屬性值的概率就是兩個屬性值發生的概率的乘積,假設任意兩個屬性值的概率乘積是在屬性層次上的WA權值,可獲取WA權值表達式為
WA1=βα
(14)
式中,β表示任意兩個數據中的一個數據的屬性值,α表示任意兩個數據中的另一個數據的屬性值。
將具有屬性值和不具有屬性值的字符進行比較或將都不具有屬性值的字符進行比較都不存在意義,因此只比較具有屬性值的字符即可[12]。
3.2 樸素貝葉斯分類器
經過計算求出文本數據可能發生的概率后,利用樸素貝葉斯分類算法將所有數據進行最終分類,且此算法只適合數據間屬性值相互獨立的情況下使用,此算法的過程分為準備、訓練及應用三個階段。
1)準備工作階段
將數據根據其特征項進行分類,組成訓練樣本,即在分類器中輸入其特征項和需要分類的數據,獲取訓練樣本。
2)分類器訓練階段
此階段主要產生分類器,預測特征項劃分對類別條件的概率,并運算出所有類別在訓練樣本中出現的概率,最后在計算機中輸入準備階段的結果,即可獲取分類器。
3)應用階段
利用分類器對分類型進行分類,在計算機中輸入準備分類的項目及分類器,即可獲得所有類別。
將訓練文本中的每個詞匯當成一個事件,訓練文本即為事件集合,根據貝葉斯定理公式可得
P(C|X)=[P(C)P(X|C)]/P(X)
(15)
式中,X代表待分類文本的特征向量,C代表規定的文本類別體系。
文本分類的實質就是將向量形式表現的文本劃分到類別中,即計算出向量形式表現的文本歸類成某一類別的概率,則訓練樣本屬于類別cj的概率計算方式為
P(cj|x1,x2,…,xn)
=[P(cj)P(x1,x2,…,xn|cj)]/P(c1,c2,…,cn)
(16)
式中,P(cj)表示文本特征向量屬于cj的概率。
利用式(16)求出的最大概率就是文本向量的類別,由此可知文本分類問題就是求解概率的最大值。
當式(16)為恒定值時,此時的概率代表所有類別的疊加概率,則此時的求解表達式為
(17)
根據貝葉斯定理可知每個特征向量屬性值乘積的聯合概率為
(18)
此公式即為將重復數據進行最終分級的分類函數。其中,P(xi|cj)及P(cj)的概率值公式分別為
(19)
式中,N表示訓練文本總數,N(C=cj)表示歸于cj類別的文本數量,M表示經過預處理后的訓練樣本數量,N(Xi=xi,C=cj)表示具有屬性值的文本數量。
4 實驗與結果
為了驗證所提方法的整體有效性,在Window7操作系統中對信息相似性下網絡對抗文本重復數據分級索引方法、文獻[3]方法、文獻[4]方法進行分級效率、準確率和相似數據提取率測試。
4.1 分級效率對比結果
由圖1中的數據可知,在同一環境下比較所提方法、文獻[3]方法和文獻[4]方法的分級時間消耗,所提方法時間消耗不僅低于其它兩種方法,且時間消耗平穩,而其它兩種方法的時間消耗較高,波動較大,因為所提方法在分類所有文本等級實現重復數據分級前通過構建向量空間模型對數據進行降維處理,減少運行時間的消耗,提高了分級效率。
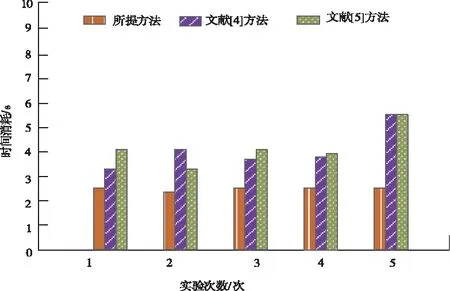
圖1 不同方法的分級效率
4.2 準確率對比結果
比較三種方法的分級準確率可直接反映出方法的優劣,分析圖2可知,所提方法的準確率經過多次訓練其準確率始終保持在80%以上,其它兩種準確率均不穩定且低于80%,因為所提方法在進行分級文本前對網絡數據進行了預處理,提前找出分類特征項,減少其分類錯誤,從而提高了分級準確率。
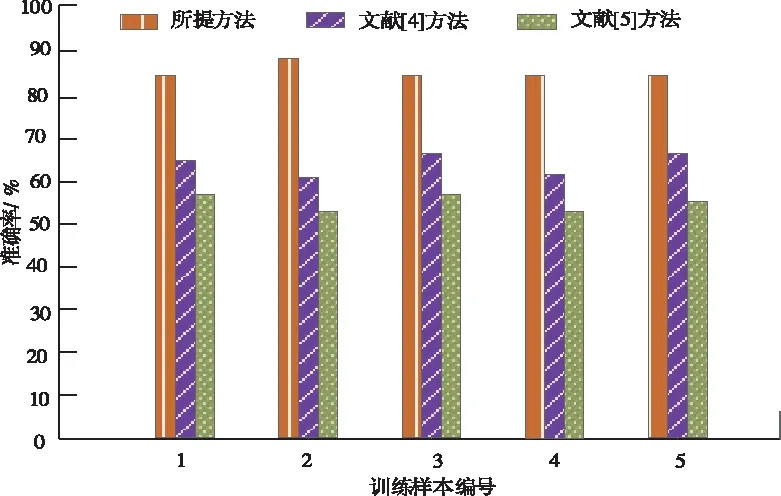
圖2 不同方法的分級準確率
4.3 相似數據提取率對比結果
在進行分類相似數據前需要提取出所有相似數據,因此比較提取相似數據的數量也是判斷方法的重要指標,由圖3可知,與文獻[3]方法和文獻[4]方法相比,所提方法在網絡數據中提取出的相似數據最多,因為所提方法在進行最終分類網絡重復數據前計算出網絡數據特征項權重,更加準確地提取出相似數據,從而升高了相似數據的提取率。
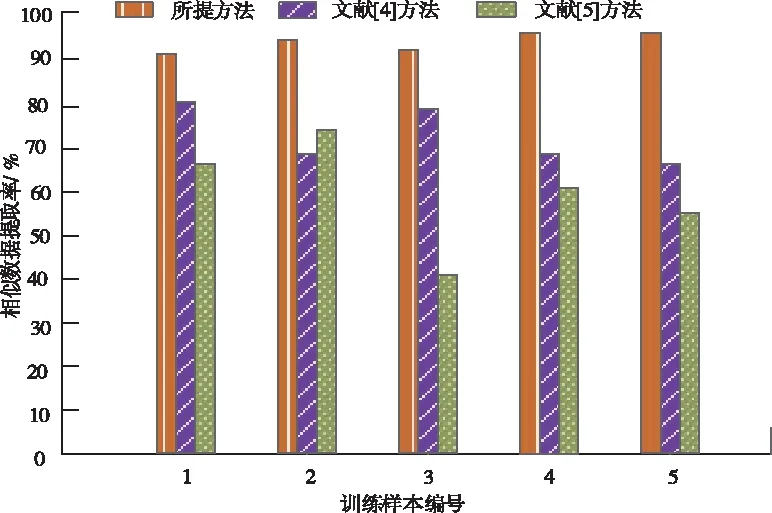
圖3 三種方法相似數據的提取率
5 結束語
針對當前方法的不足,提出信息相似性下網絡對抗文本重復數據分級索引方法。該方法將網絡數據進行降維及特征提取等預處理再計算其相識度,最后利用樸素貝葉斯分類器實現重復數據分級索引。經試驗表明,所提方法分級效率高、準確率高和相似數據提取率高。此方法對計算機要求極高,接下來將研究如何在普通計算機環境下也可進行分級索引。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
