基于稀疏表示的半監督線性子空間學習
2021-11-19 03:25:14唐曉晴
電腦與電信 2021年8期
唐曉晴
(南京理工大學紫金學院計算機學院,江蘇 南京 210023)
關鍵字:半監督;稀疏表示;線性子空間;投影矩陣;人臉數據庫
1 引言
線性子空間學習作為降維以及特征提取的技術現已廣泛應用于計算機視覺以及模式識別等重要領域,其最為著名的是人臉識別應用。其代表方法已有很多,比如基于主成分分析(Principal Component Analysis,PCA)進行的人臉識別,基于線性判別分析(Linear Discriminant Analysis,LDA)進行的人臉識別[1-3]等。總的來說,子空間學習方法就是根據一定的準則函數來學習得到一個子空間或者投影矩陣[4,5]。根據是否使用訓練樣本的標簽又可將上述方法分為監督學習和非監督學習兩大類[6]。
雖然監督學習方法可以有效提高分類的結果,但是現有的監督學習方法仍存在著局限性,尤其是標簽樣本的獲得往往需要大量的人力和財力。隨著圖像數據數量的快速增長,獲取無標簽數據更加有利,使得僅能處理有標簽數據的監督學習方法的局限性顯得更加明顯。考慮到有標簽數據較難獲得而廉價的無標簽樣本卻很容易獲得,半監督學習方法吸引了越來越多的研究者們的注意[7-11]。半監督學習方法是位于監督學習與非監督學習之間的一種學習方法。當訓練樣本為大量無標簽和少量有標簽的數據集時,使用該方法可以較好地提高學習能力。與監督學習方法相比,半監督學習的優點在于利用未標記的數據來估計數據間的結構信息從而幫助有標簽的數據進行預測。因此,在研究基于大量的無標簽的樣本和少量的有標簽樣本的半監督學習方法是有意義的。利用無標簽進行半監督學習的做法一般有以下兩種:(1)利用無標簽樣本來微調生成模型中的參數;(2)明確有標簽和無標簽的樣本,將它們合成一個訓練集來訓練半監督模型。本文就是基于第2種思想提出了基于稀疏表示的半監督線性子空間學習。其基本思想是利用無標簽樣本和有標簽樣本間的相關性來形成一個基于半監督學習的投影矩陣P。
本文提出了如圖1所示的基于稀疏表示的半監督線性子空間學習方法。該方法能較好地解決標簽樣本的少量性,因此具有更好的實用性。
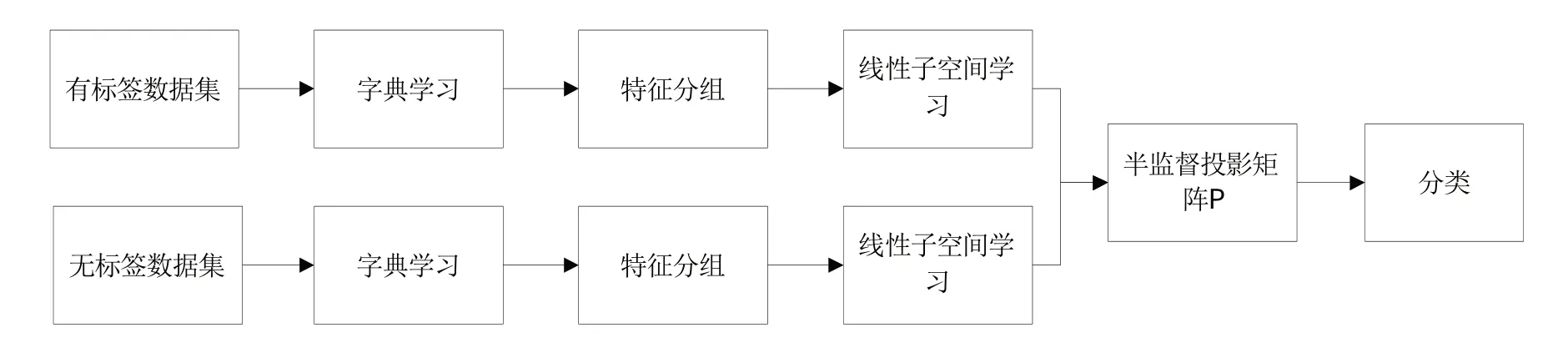
圖1 基于稀疏表示的半監督線性子空間學習
2 基于稀疏表示的半監督線性子空間學習
線性子空間聚類的一個重要優勢是分類效果較好且方法簡單。通過學習投影矩陣P,可以達到對高維數據的降維;與此同時,在降維后的子空間中,原始圖像的有用信息得到了加強,從而提高了分類的準確率。由圖1可知,本文主要分為三大部分,即字典學習、特征分組以及線性子空間學習。
2.1 字典學習和稀疏表示
假設X=[x1,x2,...xm]∈Rn*m為訓練集,本文的主要思想是將其每一個樣本xi(i∈{1,2,...m})分成兩部分,一部分為具有較高識別能力的另一部分為具有較低識別能力的由此X=Xa+Xb,其中對于一個線性投影矩陣P,可以得到PX=PXa+PXb,通過投影矩陣P,使得在Xa中的特征得到保留,在Xb中的特征得到抑制。最后將投影到P上的測試樣本使用KNN進行分類。
要解決上述問題,一個重要步驟是如何進行樣本特征的分解。由于人臉數據較高的維度以及特殊的空間關系,本文中使用學習得到的字典D來表示樣本的特征。其形式描述如下:對于每一個樣本人臉xi,將其分成q個有部分重疊的樣本塊,從而得到h=m*q個樣本塊。假設每個樣本塊tj(j=1,2,...,h)的維數為l,則訓練集可以表示為:T=[t1,t2,..,th]。根據訓練集T,可以把字典學習的問題轉化為求解如下形式的優化問題:
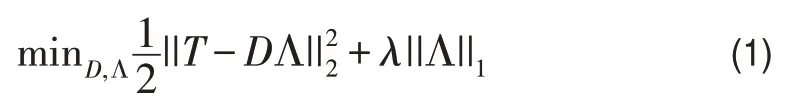
其中λ是常數系數,T∈Rh*l表示輸入的訓練集,D=[d1,d2,...,dk]∈Rl*k表示字典,Λ=[α1,α2,...,αh]∈Rk*h表示訓練數據集的稀疏系數矩陣。
在字典學習階段,一般采用迭代的方法可以求解式(1)。首先固定字典D,則式子(1)轉化為一個求稀疏矩陣Λ的問題;然后固定系數矩陣Λ,則(1)轉化為一個求字典D的二次約束的最小平方問題。根據K-奇異分解算法(KSVD),首先運用正交匹配追蹤(OMP)算法求解稀疏矩陣Λ,接著更新字典D。通過多次迭代求解可以得到字典D[12-15]。
通過學習得到字典D以及稀疏表示理論后,可以將每一個樣本tj表示為如下的形式:
tj=Dαj=αj(1)d1+αj(2)d2+...+αj(k)dk,也就是說每個樣本塊可以寫成k個部分的和,即tj=tj,1+tj,2+...+tj,k。通過將屬于圖像xi的樣本塊進行組合,則得到xi=xi,1+xi,2+...+xi,k。其中xi,z是屬于圖像xi的樣本塊tj,z相連得到的,其中重疊部分的像素用均值來表示xi,z。
2.2 半監督的子空間學習
在稀疏表示之后,每一個樣本圖像xi被分解為k個特征圖像xi,z,本文的目的是根據這k個特征的識別能力分為具有較高識別能力的特征和具有較低識別能力的特征,從而進行更有效的子空間學習。
2.2.1特征分組
由于半監督學習的樣本為大量無標簽和少量有標簽樣本,因此對這兩類數據集進行分組時,將使用不同準則。
對于無標簽樣本,由于不知道樣本圖像xi的類別標簽,從而認為每一個樣本都是一個類別,假設特征xi,z的標準差越大,我們就認為該特征在區分樣本時含有更多的信息;根據這一準則,特征圖像被分為較高識別能力和較低識別能力兩部分。用表示特征圖像xi,z的均值,則xi,z的標準差可以表示為:
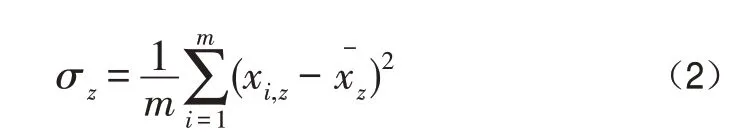
通過對標準差進行降序排序,選取前τ*k(其中τ為常數)為較高識別能力的,剩下的為較低識別能力。為了便于表達,本文假設特征記為較高識別能力部分(MDP);記為較低識別能力部分(LDP)。如圖2即為無標簽樣本的MDP與LDP的結果圖。

圖2 無標簽樣本的MDP與LDP
對于有標簽樣本,由于樣本的標簽是已知的,可以根據Fisher比率進行分類[16]。若特征樣本的Fisher比率越大,我們就認為該特征樣本在區分樣本時含有更多的信息。特征圖像xi,z的Fisher比率計算方式如式(3):
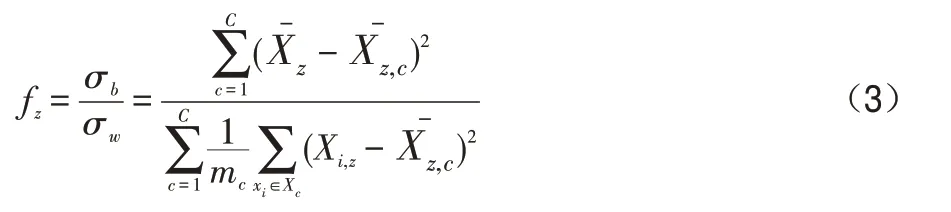
其中Xc是標簽為c的樣本集,表示特征樣本xi,z的均值,表示屬于類別c(其中c=1,2,...,C)的xi,z均值。mc為類別c的數目。與無標簽的樣本相似,選取前τ*k為較高識別能力的,剩下的為較低識別能力,從而得到MDP部分的以及LDP部分的如圖3即為標簽樣本的MDP與LDP的結果圖。

圖3 標簽樣本的MDP與LDP
2.2.2子空間學習
通過特征分組之后,無標簽數據集可以表示為X=Xa+Xb,其中每一個樣本可以表示為同樣的有標簽數據集也可以表示為其中每一個樣本可以表示為本文的目標是訓練得到一個投影矩陣P,使得對于任意一個測試樣本y,可以使用Py作為該測試樣本的特征,從而進行分類。
由上面的信息可以得到,Xa以及X'a對于識別樣本具有較高的識別能力,但是如果只使用Xa以及X'a來學習投影矩陣P,那么結果肯定不是很適合,因為Xb和X'b的部分同樣也含有有用的信息。為了有效利用兩部分的信息,需要最大化較高識別能力部分能量的同時最小化較低識別能力部分的能量。因此,提出如下(4)的最優化問題:

3 實驗
本實驗使用的是matlab語言進行編寫,稀疏字典的學習使用SPAMS開源庫進行訓練和學習。SPAMS開源庫的學習可以參考鏈接http://spams-devel.gforge.inria.fr/index.html。下文所涉及的不同方法均是在相同的服務器上進行測試,均采用聯想筆記本小新,處理器為R7-4800U,內存為16G,操作系統為Windows10。
為了驗證半監督學習方法的識別能力,本文在兩個不同的公共數據集上進行實驗:AR數據集、extended Yale B數據集。本文重點在于驗證半監督學習的有效性,因此在實驗過程中將本文的半監督學習方法與無監督學習以及監督學習進行對比。在參數選擇方面,字典塊的大小為8*8,字典的元素個數為64。
3.1 Extended Yale B
extended Yale B[17]數據集是在9個動作以及64種光照條件下形成的38個人臉。每個人臉的64張圖片僅在頭部和臉部表情有一點不同。本文隨機選擇每個人的前32張中的5張作為訓練集,剩余的32張中的5張作為測試集。該數據集上得到的實驗結果比較如圖4所示。圖中的縱坐標為識別率,其值的計算為OA(Overall Accuracy),即在測試集上分類正確的數量與測試集的總體數量之間的比值。
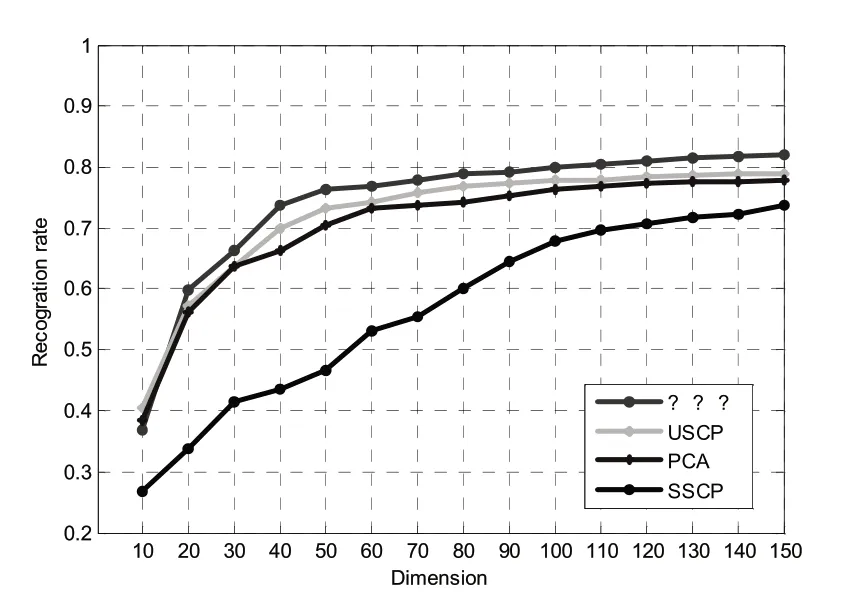
圖4 extended Yale B實驗結果
從圖4可以得到,本文提出的半監督線性子空間學習方法在該數據庫上取得了較好的效果,比非監督學習(unsupervised sparse coding based projection,USCP)[6]方法高出2%左右;與此同時與具有相同樣本標簽數目的監督學習(supervised sparsecoding based projection,SSCP)[6]相比也有著明顯的提高。由此可見有效利用標簽樣本和無標簽樣本而形成的半監督學習方法十分有利于人臉的識別。
3.2 AR數據集
AR數據集[18]包含126個人(其中70個為男性,56個為女性)的4000張彩色人臉照片,其大小為576*768。一共有兩個場景,每一個場景包含120個人以及14張彩色圖片,每一個場景有:中性表情,微笑,憤怒,尖叫,戴著太陽眼鏡,戴著圍巾等情況。本文選擇120張人臉進行實驗,將其人臉大小裁剪為32*32。該數據集上得到的實驗結果比較如圖5所示。圖中的縱坐標為識別率,其值的計算為OA(Overall Accuracy),即在測試集上分類正確的數量與測試集的總體數量之間的比值。
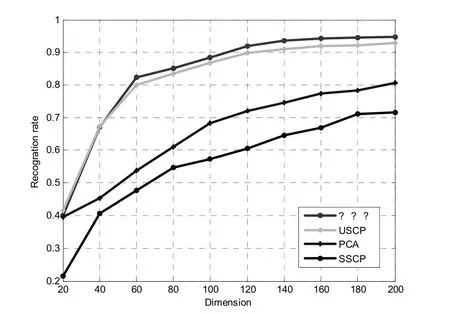
圖5 AR數據庫實驗結果
從圖5可以得到,本文的方法在AR數據庫上取得了較好的效果,相較于與非監督學習(unsupervised sparse coding based projection,USCP)[6]相比,半監督學習因包含有標簽樣本的信息而使得分類結果提高了將近2%左右;與相同標簽樣本數目的監督學習(supervised sparse coding based projection,SSCP)[6]相比,使用半監督學習方法因包含大量的無標簽的信息而使得實驗結果有了顯著的提高。
4 結語
本文針對標簽樣本價格昂貴且不易獲得、無標簽樣本廉價且豐富的特點提出了一種基于稀疏表示的半監督子空間學習方法。該方法將有標簽樣本與無標簽合成一個訓練集進行半監督模型訓練。首先有標簽樣本和無標簽樣本各自訓練得到一個字典,然后將每一個樣本根據其特性分成MDP和LDP兩個部分,最后通過保留MDP部分和抑制LDP部分求解得到投影矩陣P。實驗證明,該方法高于非監督樣本以及具有相同標簽樣本數目監督學習方法。
猜你喜歡
人大建設(2020年4期)2020-09-21 03:39:12
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
浙江人大(2014年4期)2014-03-20 16:20:16
