面向復雜查詢請求的SQL自動生成模型
2021-11-22 09:51:44彭敦陸
小型微型計算機系統 2021年11期
余 波,彭敦陸
(上海理工大學 光電信息與計算機工程學院,上海 200093)
1 引 言
數據庫中存儲了海量的高價值數據,用戶可以通過執行SQL與結構化數據直接進行交互,也可以通過設計好的交互界面進行交互.但SQL的使用難度限制了非技術用戶,交互界面的設計也限制了使用的范圍.通過自然語言直接與結構化數據進行交互,可以充分利用結構化數據的價值,為用戶帶來體驗和效率的提升,該任務在現實生活中具有許多重要的潛在應用,例如問題解答[1]和導航控制[2].在一些應用場景,如基于關系數據庫智能問答系統,Text2SQL,即將自然語言描述的文本問題自動轉換成恰當的SQL語句是基于關系數據庫智能問答系統的核心,這也是本文的專注的任務.
盡管Text2SQL的研究非常有意義,由于數據標注依賴于高度專業知識,并且要求注釋者掌握SQL語法,因而目前只有少量的Text2SQL公共數據集用于模型訓練.WikiSQL[3]是一個大規模的Text2SQL數據集,其中包括80,654個文本和SQL人工注釋對.
圖1是該數據集的SQL語句模式,其要完成的預測任務屬于固定模式,不需要預測SQL語句中的所有內容,即只預測關鍵內容(圖1中的標有“$”的部分),這種方法稱為基于草圖的方法.表1是利用該數據集完成一個Text2SQL任務的簡單示例.
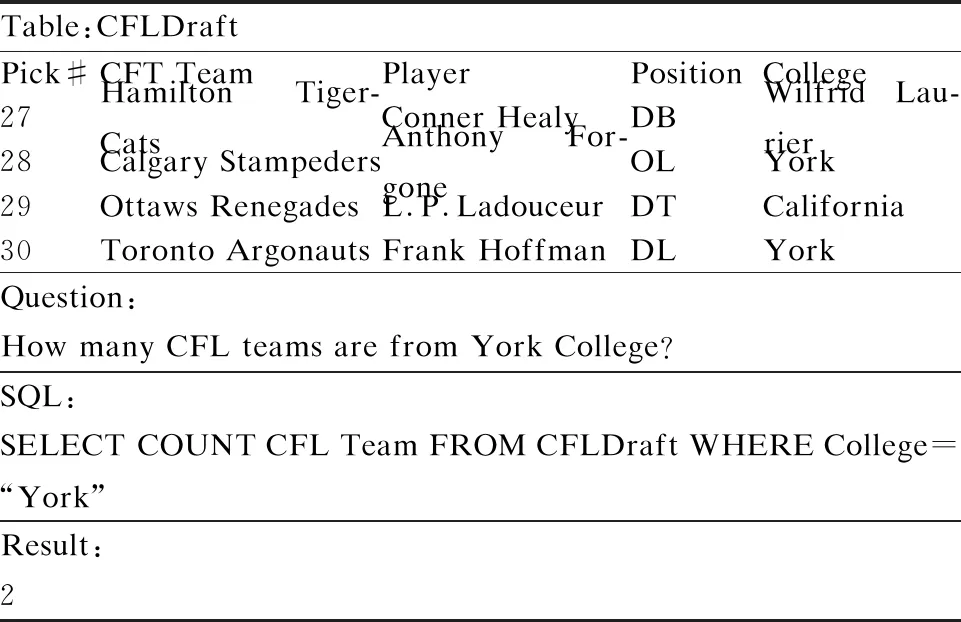
表1 WikiSQL示例
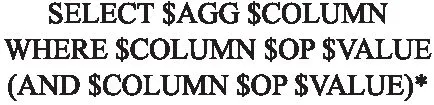
圖1 WikiSQL的草圖
基于草圖的Text2SQL的第1項工作是SQLNet[4],它將Text2SQL任務轉換為6個子任務.這些子任務可預測需要填充的草圖中標有“$”的部分.對于WikiSQL數據集,基于草圖的后續研究也使用類似的任務劃分,例如TypeSQL[5],MQAN[6],SQLova[7],X-SQL[8]等.SQLova和X-SQL引入了預訓練的模型BERT[9],它們效果更好并基本達到WikiSQL數據集的極限.
對于WikiSQL數據集,盡管一些模型(例如:SQLova,X-SQL)幾乎已達到極限,但這并不能證明單表Text2SQL任務已被完全解決.與實際應用場景相比,WikiSQL有很多簡化,表2是追一科技AI競賽的TableQA數據集和WikiSQL數據集的比較.從表2中可見,在TableQA數據集中,select和where字句數量更多,where條件操作符更加復雜,value的形式多樣.盡管WikiSQL和TableQA都屬于單表Text2SQL數據集,但與WikiSQL相比,TableQA更復雜,也更符合實際需求,這使得對WikiSQL的Text2SQL方法(例如SQLova,X-SQL)用于TableQA及類似數據集上難以取得令人滿意的成績.

表2 數據集對比表
早期的工作采用注意力和復制機制的序列到序列方法,近幾年的工作重點是將SQL語法合并到神經模型中.語言表示建模的最新進展證明了從大型外部數據源進行遷移學習的價值.對于WikiSQL,SQLova模型的工作展示了這種預訓練技術對當前技術的顯著改進.鑒于這種趨勢,我們提出了2-SQL模型,這是一種改進的基于預訓練深度學習模型.與原有提取where字句中值的解決思路不同,在2-SQL模型提出了一個全新的范式:將抽取式任務轉化為一個語義匹配問題.其優點在于準確地提取where子句中多個值,而不只是準確地提取一個值.模型在Where子句中通過枚舉運算符與值,生成一系列的候選組合,簡化了運算符的選擇.
2 相關工作
WikiSQL數據集雖然是目前規模最大的有監督數據集,但其數據形式過于簡單,且難度較低.對于SQL語句,條件的表達只支持最基礎的>、<、=,條件之間的關系只有and,不支持聚組、排序、嵌套等其它眾多常用的SQL語法,不需要聯合多表查詢答案,真實答案所在表格已知等諸多問題的簡化.所以,在這個數據集上,SQL執行結果的準確率目前已經達到了91.8%.但是,這樣的數據集并不符合真實的應用場景,因為在真實的場景中,用戶問題中的值很可能不是數據表中所出現的,需要一定的泛化才可以匹配到.另外,真實的表之間存在錯綜復雜的鍵關聯關系,想要得到真實答案,通常需要聯合多張表進行查詢.再者,每一張表都有不同的意義,并且每張表中列的意義也都不同,甚至可能相同名字的列,在不同的表格中所代表的含義是不同的.總之,真實場景中,用戶的問題表達會很豐富,會使用各種各樣的條件來篩選數據,諸如此類的實際因素還有很多.由此可見,與實際應相比,WikiSQL數據集起到的作用十分有限.
龐大的數據集使人們能夠采用深層神經網絡技術來完成這項任務,并且最近引起了廣泛關注.盡管對神經語義解析器的早期研究沒有對輸出空間進行語法特定的約束,但許多模型通過使用SQL語法限制輸出空間,可以在WikiSQL上獲得出色的性能效果.Victor Zhong[3]等人提出的初始模型獨立地生成了目標SQL查詢的兩個組成部分,select子句和where子句,其性能優于提出的序列到序列基線模型.SQLNet引入了序列到集合的模型,進一步簡化了生成任務,在該模型中,僅根據序列到序列結構生成條件值,造成模型對SQL條件的順序不敏感.TypeSQL帶有自然語言標記的附加“類型”信息,使用了從序列到集合的結構.Coarse2Fine首先生成粗略的中間輸出,然后通過解碼完整的where子句來優化結果.Pointer-SQL[10]提出了一種序列到序列模型,該模型使用基于注意力的復制機制和基于值的損失函數.Seq2seq[11]在輸入自然語言的自動注釋之后使用了一個序列到序列的模型.MQAN提出了一個多任務問答網絡,該網絡可以使用注意力機制來學習多種自然語言處理任務.Wenlu Wang等人提出可執行的指導解碼,其中在解碼期間將部分非可執行SQL查詢候選對象從輸出候選對象中刪除.SQLova使用BERT作為編碼器,然后獲得查詢語句的語義表示.基于查詢語句的語義表示,提出了3種變體模型:SHALLOW層,DECODER層和NL2SQL層,并獲得了新的結果.NL2SQL層的結構類似于SQLNet.X-SQL使用MTDNN[12]初始化BERT,并提出了一個更簡單的Text2SQL模型.它使用[XLS]代替[CLS]標簽,并獲得更好的下文語義表示.根據WikiSQL數據集的特征,X-SQL在沒有where子句的示例中使用[EMPTY].另外,X-SQL將列選擇作為排名任務,使用Kullback-Leibler(KL)作為優化目標,從而提高了列選擇的準確性.X-SQL在WikiSQL數據集上取得了最先進的結果.
以往的Text2Sql算法大多數基于列提取where字句的值,當數據集出現where字句中含有多個值,會導致無法準確提取值的情況,因此不能很好的解決復雜的TableQA數據集生成SQL的問題.而我們提出的2-SQL模型可以有效地提高此類樣本的SQL生成精度.
3 問題定義
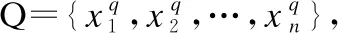
通過充分利用SQL查詢語句特定的語法,將SQL生成結果定義為圖2的結構,將序列生成轉化為多個分類問題,只需要對帶“$”的部分進行填充即可獲得標準的SQL查詢語句S.其中,SELECT和WHERE代表SQL關鍵字,我們假定每個SQL語句必須包含SELECT和WHERE.$WOP代表連接操作,關系集為[“”,“AND”,“OR”],“”表示where子句中只有一個關系表達式;$COLUMN表示數據庫的列名.我們將select子句的列命名為選擇列,where子句的列命名為條件列.$AGG表示聚合函數,操作集為[“”,“AVG”,“ MAX”,“MIN”,“COUNT”,“ SUM”],“”表示無操作;$OP表示條件操作,操作集為[“>”,“ <”,“ ==”,“!=”];$VALUE表示條件列的值,并且值必須是數據庫的內容;(…)*代表至少有一個.
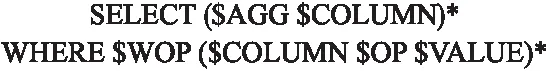
圖2 TableQA的草圖
4 方法和模型
為解決自然語言生成SQL查詢語句的問題,本文的模型將分為兩個模塊,MODULE1負責S-NUM、S-COL、S-AGG、W-CONN-OP和W-COL子模塊的生成,MODULE2接受MODULE1輸出的W-COL,負責W-COL-VAL和W-COL-OP子模塊的生成.
本文的整體模型2-SQL的架構如圖3所示.由圖可見模型包括3個部分:編碼器、列表示層和相關子模塊層.編碼器使用BERT-wwm-ext[13],由于中文單詞比漢字具有更多的連貫性和語義信息,訓練BERT時,Google的BERT將漢字符視為掩碼,而BERT-wwm-ext則將中文單詞視為掩碼.BERT-wwm-ext通過使用整個單詞掩碼策略,可以更好地學習中文單詞向量表示.相關研究顯示,與Google的BERT相比,BERT-wwm-ext對中文NLP任務的效果更好.此外,BERT-wwm-ext的訓練語料庫比原始維基數據更大,單詞量增加540萬.選擇列和條件列是基于草圖的Text2SQL任務的瓶頸.
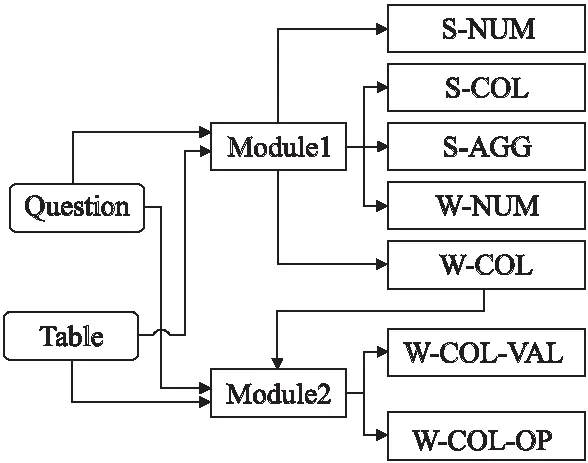
圖3 整體模型
模型采用使用X-SQL中的“內容增強層”作為列語義表示.整個2-SQL模型包含7個子模型,分別為S-NUM,S-COL,S-AGG,W-CONN-OP,W-COL,W-COL-VAL,W-COL-OP子模塊.
S-NUM:預測所選列的數量.
S-COL:預測SQL語句查詢表的哪一列.
S-AGG:預測對S-COL子任務使用什么聚合函數操作,有avg、min、max、count、sum.
W-CONN-OP:預測where字句中各條件之間的并列關系,可以是 and 或者 or.
W-COL:預測where字句的條件列.
W-COL-OP:預測where字句中條件列的操作符,有>、<、==、!=.
W-COL-VAL:預測where字句中的值.
4.1 編 碼
現有的在大型未標記的語言語料庫上進行預訓練的單詞表示,例如GloVe[14],在WikiSQL中已顯示出優異的結果.多個團隊開發了上下文的詞表示法,例如ELMO[15]和BERT在許多NLP任務中表現出優異的性能.與英文單詞相比,中文單詞包含更多的語義信息.我們使用BERT-wwm-ext作為BERT的初始權重,[SEP]在查詢語句和列名之間進行分隔.每個輸入中包含查詢語句以及列名,查詢語句輸入T1…TL(L是查詢語句中詞的數量),列名輸入Th1,1…ThNh,MNh,,編碼如下:
[CLS],T1,T2…TL[SEP],Th1,1,Th1,2,…[SEP],…[SEP],ThNh,1,…,ThNh,MNh[SEP]
其中,Thj,k,是第j個表頭的第k個令牌,Mj是第j個表頭的令牌的總數,Nh是表頭的總數.每個令牌都由令牌嵌入,類型嵌入和位置嵌入組成.[CLS]和[SEP]是用于分類和上下文分離的特殊標記.將自然語言查詢與整個表的所有列名放在一起進行編碼,用來表示問題與表兩者信息之間存在交互.
X-SQL和SQLova都使用BERT編碼,但與SQLova相比,X-SQL在BERT編碼后沒有用復雜的結構,但是可以更好地生成SQL語句.另外,本文認為BERT編碼后,添加復雜結構會削弱整個模型的性能.BERT可以滿足多任務表示學習需求,因此與X-SQL類似,本文在使用BERT編碼器之后,不再使用復雜的結構.
4.2 列名特征向量
輸入序列由BERT編碼獲得語義向量W,標記為W=h[cls],hq1,…,hqn,h[sep],hc11,…,h[sep],hc21,…,h[sep].
語義向量W的維數為d,輸入序列包含一個查詢序列和多個表頭序列,每個序列通過[SEP]標簽連接.h[cls]是特殊令牌[CLS]的表示,hqi是查詢語句中第i個令牌的表示,hcmi是第m列中第i個令牌的表示,n是查詢的長度,m是數據庫中的列數.與X-SQL相似,模型使用全局信息h[cls]通過注意力機制來增強每一列的語義表示.
將第i列中的令牌數表示為ni,編碼器通過計算上下文增強模式編碼器輸出hci來匯總各列:
(1)
αit=softmax(Sit)
(2)
(3)
其中,U,V∈Rm×d,Sit計算h[cls]與第i列中的第t個令牌之間的相似性.這里,使用簡單的點乘函數,雖然序列編碼器的輸出中已經捕獲了一定程度的上下文,但這種影響是有限的,因為自注意力往往只集中在某些區域.另一方面,[CLS]中捕獲的全局上下文信息足夠多樣化,因此可用于補充順序編碼器中的模式表示.αit是第i列中第t個令牌的關注權重.
4.3 子模塊輸出
輸出層由序列編碼器輸出h[cls],hq1,…,hqn,上下文增強模式編碼器輸出hc1,…,hcn,該任務拆分成兩個部分,MODULE1(見圖4)負責S-NUM,S-COL、S-AGG、W-CONN-OP和W-COL子模塊的生成,MODULE2接受MODULE1輸出的W-COL,負責W-COL-VAL、W-COL-OP子模塊的生成.
4.3.1 MODULE1
通過將h[cls]和hci歸一化可獲得最終的列表示向量rci.
(4)
此計算是針對每個子任務分別完成的,以使列表示向量與每個子任務所關注的自然語言問題更好地保持一致.2-SQL中使用BERT語義表示和列表示來預測圖2中帶“$”的部分.模型將TableQA數據集上的Text2SQL任務的MODULE1分為多個子任務,每個子任務負責預測SQL語句的不同部分,子任務之間的依賴關系如圖4所示.
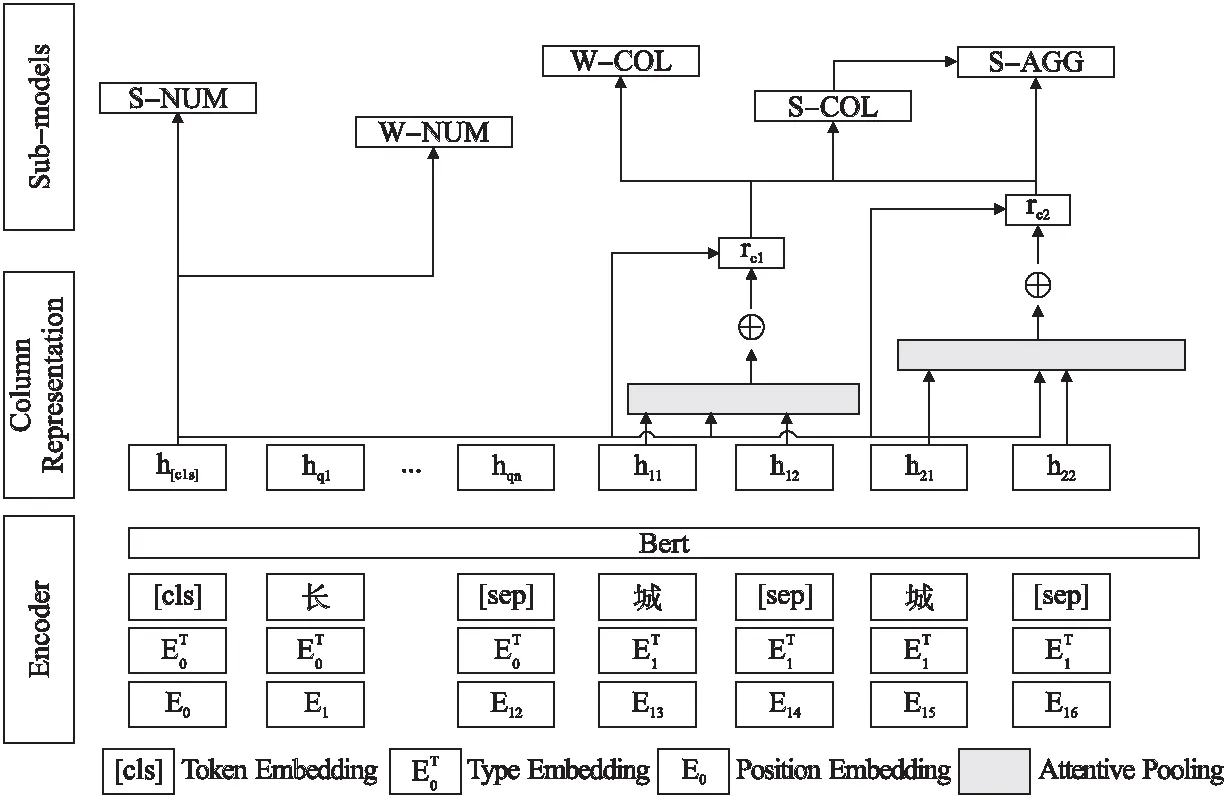
圖4 MODULE1神經網絡結構
子任務S-NUM預測所選列的數目,預測集為[1,2].子任務W-CONN-OP預測條件列的數量和條件列之間的關系,預測集為[“”,“and-1”,“or-1”,“and-2”,“or-2”,“and-3”,“or-3”].S-NUM是二分類問題,W-CONN-OP是七分類問題.兩個子任務使用全局信息h[cls]作為輸入.S-NUM和W-CONN-OP的分類公式如下所示.
pS-NUM=softmax(WS-NUMh[cls])
(5)
pW-CONN-OP=softmax(WW-CONN-OPh[cls])
(6)
其中,pS-NUM和pW-CONN-OP分別表示S-NUM和W-CONN-OP的輸出概率.WS-NUM和WW-CONN-OP可學習的參數.WS-NUM∈R1×d,WW-CONN-OP∈R7×d.注:S-NUM和W-CONN-OP只依賴于h[cls].
S-COL,預測select語句的列.將select語句選擇列Ci的概率建模為:
pS-COL(Ci)=softmax(WS-COLrci)
(7)
這里,pS-COL(Ci)表示在S-COL子任務中數據表的第i列被選擇的概率.WS-COL是可學習的參數.WS-COL∈R1×d.注,S-COL只依賴于rci.
S-AGG,預測select語句所選列的聚合函數.S-AGG的目標集是[“”,“avg”,“max”,“min”,“count”,“sum”],這是一個六分類問題.聚合函數的概率計算為:
pS-AGG=softmax(WS-AGGrci)
(8)
這里,pS-AGG表示在S-AGG子任務中選擇數據表第i列后聚合函數被選擇的概率.WS-AGG是可學習的參數.WS-AGG∈R6×d.注,S-AGG只依賴于rci.
W-COL預測where子句中的條件列.將where字句選擇列Ci的概率建模為:
pW-COL(Ci)=softmax(WC-COLrci)
(9)
其中,pW-COL(Ci)表示在W-COL子任務中數據表的第i列被選擇的概率.WC-COL是可學習的參數.WC-COL∈R1×d.注,W-COL只依賴于rci.
4.3.2 MODULE2
X-SQL算法是基于列語義向量提取where子句中的值,但TableQA數據集where子句中含有多個值,其無法準確的提取目標值.2-SQL模型將提取where字句中值的方式改進為范式轉變的模式,MODULE2通過接受MODULE1中W-COL輸出的where字句的所選列進行預測,通過枚舉運算符與值,生成一系列的候選組合,將提取值任務轉換為語義匹配問題.一個自然語句問題會對應多候選樣本,轉化成多個二分類問題.
在TableQA數據集中,數據表的每列標記為TEXT或者REAL類型.在抽取where字句的value值時,TEXT類型的列選取的value生成自數據表;REAL類型的列選取的value利用正則表達式從自然語言問句抽取.MODULE2的輸入數據格式,見圖5.

圖5 MODULE2輸入數據格式
W-COL-VAL和W-COL-OP子任務分別預測where字句中的value和操作符,MODULE2對一個自然語句問句中where字句的多個候選樣本進行二分類,預測集為[0,1].子任務W-COL-OP預測where字句中列的操作符,預測集為[“”,“>”,“<”,“==”,“!=”].MODULE2分類如式(10)所示.
p=sigmoid(Wh[cls])
(10)
這里p表示候選樣本的輸出概率.W是可學習的參數,W∈R1×d.
4.4 訓練
在訓練的過程中,其目標函數是所有子任務損失函數的總和,通過最小化目標函數值的方式來進行參數更新.
子任務采用傳統標準的交叉熵損失函數,由于已知子句中各部分預測的真實結果,因此各子任務之間互不影響,可并行訓練.交叉熵損失函數公式如下所示:
(11)
這里,N為樣本總數.M為類別的數量.yic為指示變量(0或1),如果該類別和樣本i的類別相同就是1,否則是0.pic為對于觀測樣本i屬于類別的預測概率.
5 實驗結果與分析
與真正的單表SQL生成場景相比,WikiSQL數據集做了很多簡化.SQLova模型團隊認為其提出的模型已經超過了WikiSQL上的人類水平.與SQLova相比,X-SQL模型達到了更好的性能.可以認為,WikiSQL上的SQL生成任務基本解決了.因此,本文的實驗不再基于WikiSQL,而是針對更復雜的TableQA.
TableQA數據集包含45918個“query-SQL”對.與WikiSQL相比,SQL語句更加復雜,包括圖2中復雜SQL的所有模式.TableQA所選列的數目可以多于一列,包含更多的條件,并添加“或”邏輯關系,查詢是多種多樣的,數據庫的內容可能不會出現在相應的查詢中.TableQA是追一科技在人工智能競賽中建立的.追一科技承諾開放所有數據,但至今,只有訓練和驗證數據,測試數據尚未開放.我們將驗證數據分為兩部分:一部分用于參數調整,另一部分用于測試.訓練數據、驗證數據和測試數據的數量分別為41522、2198和2198.
實驗使用兩個指標來評估SQL生成的準確性:邏輯形式精度(LF)和執行精度(X).邏輯形式精度(LF),直接將生成的SQL語句與基本事實進行比較,并檢查它們是否匹配;執行精度(X),執行生成的SQL語句和基本事實來得到SQL查詢結果,并檢查它們的結果是否匹配.
表3顯示了每個子任務的準確性.2-SQL模型提取where字句中值的方式改進為范式轉變的模式,通過枚舉運算符與值,生成一系列的候選組合,將提取值任務轉換為多分類問題.實驗結果表明,W-COL-VAL子模塊比以往的模型提高了0.9%邏輯形式精度,W-COL-OP子模塊比以往的模型提高了0.8%邏輯形式精度.表4給出了幾種模型在TableQA驗證數據集和測試數據集的邏輯形式精度(LF)和執行精度(X).
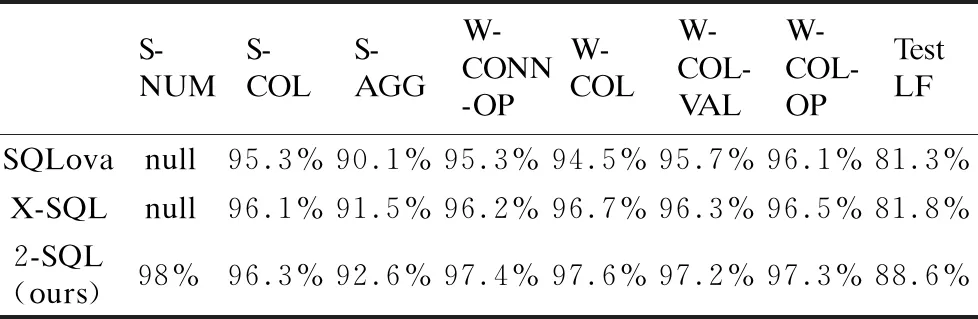
表3 模型的子任務在TableQA測試集的表現(S-NUM為null,表示模型無該子任務)
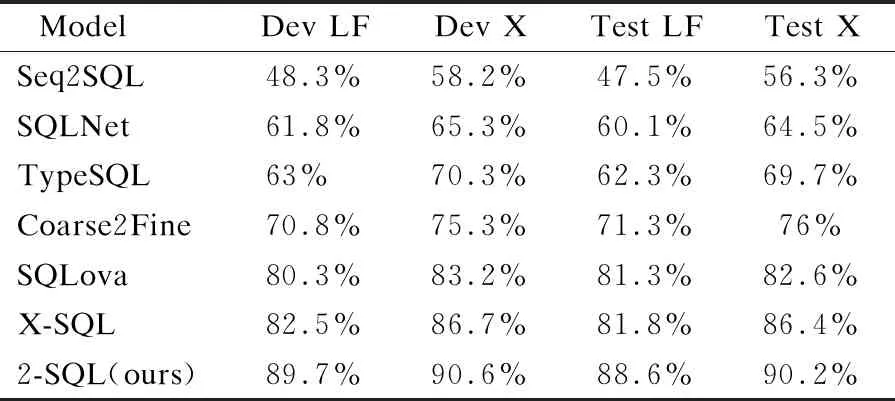
表4 各種模型在TableQA的表現
通過在數據庫中執行SQL語句所返回的答案和預測值進行對比評估,我們的模型在TableQA數據集上都明顯優于以前的模型.2-SQL比以往的模型提高了6.8%的邏輯形式精度,3.8%的執行精度.
6 總 結
本文提出了2-SQL來完成更復雜的單表SQL生成任務,并將提取where子句中值的方式轉換為語義匹配問題.使用了TableQA作為實驗數據,與WikiSQL相比,TableQA更復雜,更符合實際應用.2-SQL模型是一個多任務聯合學習框架,模型不僅通過聯合學習提高多個子任務的精度,而且在提取where子句中值時,通過枚舉運算符與值,生成一系列的候選組合,將提取值任務轉換為語義匹配問題.這種基于匹配的抽取框架的功能尚未得到充分利用.將來,可以采用更多形式的匹配模型來實例化所提出的框架.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
