基于卷積神經網絡的多傳感器下坐姿識別研究
2021-11-22 08:53:54陳浩龍
計算機技術與發展 2021年11期
陳浩龍
(南京中醫藥大學 人工智能與信息技術學院,江蘇 南京 210046)
0 引 言
近年來,青少年因坐姿習慣差而引發的亞健康問題形勢嚴峻,坐姿不當也為長期坐著辦公的人群埋下病根,頸椎病、腰椎間盤突出癥等疾病的患病人群有年輕化的趨勢,在此背景下,坐姿矯正成了當下急需解決的問題。
坐姿矯正之前需要對矯正者進行坐姿監測,系統會對不良坐姿進行識別而提醒矯正者,促使其主動地養成坐姿端正的好習慣從而實現坐姿矯正。
如今基于設備的姿態識別方式主要有以下兩個:
方式一是計算機視覺領域的基于視頻圖像的識別技術,比較出名的項目則是美國卡耐基梅隆大學(CMU)的OpenPose項目。郭園等人[1]就曾基于OpenPose學習坐姿分析研究桌椅人機適應性;魏華良等人[2]基于視頻監控對兒童學習坐姿姿態進行識別并提醒。使用視頻識別涉及到被拍攝者的隱私、拍攝環境等問題,且監控設備成本高昂。
方式二是利用各種可穿戴傳感器,如物理傳感器等進行姿態識別。坐姿姿態識別需要測量用傳感器輕便靈活、精度高、靈敏度高、成本低。文獻[3]使用的是手機內置三維加速度傳感器,傳感器選用簡潔,但可移植性不高;文獻[4-5]同樣使用智能手機自帶的傳感器,雖然使用滑動濾波器在對數據預處理的噪聲去除中取得了很好的去噪效果,處理過程較為復雜,人工操作多。除次以外,即便使用文獻[6-7]中所說的MPU6050或MPU9250加速度傳感器,但仍需要人工進行濾波處理。而文獻[8]所使用的是JY-901加速度傳感器,該傳感器集成高精度的陀螺儀、加速度傳感器、地磁場傳感器,內置卡爾曼動態濾波算法,減少使用者信號處理過程中的復雜步驟,有效降低噪聲,提高測量精度,綜合考量其優點,JY-901將被選為本方案的傳感器。
而文中所使用的多傳感器聯合監測姿態數據,提供了對動作細節的多維度分析識別,從而提高動作識別的范圍和精度。文中將從數據采集與預處理、模型訓練、結果分析對比等各個方面闡述基于多傳感器的坐姿姿態識別的研究方案。
1 系統設計
系統設計流程分為數據采集、數據預處理、模型搭建和測試四個部分,如圖1所示。數據采集部分將由傳感器提供下位機的硬件支持,并將記錄的數據傳至計算機生成數據文件。在輸入至神經網絡之前進行剔除、加窗、特征提取等數據預處理,在不斷測試和優化模型中得出最終適合本研究方案的神經網絡算法。

圖1 系統設計流程
2 數據采集與預處理
本數據集來源是由三個固定在如圖2人體部位上的JY-901傳感器,分別位于頸部、中背部、腰部,選取這三個特殊部位以判斷人體坐姿姿勢。

圖2 傳感器固定位置
穿戴者將串好的三個傳感器如上所述在身上加以固定并端坐好,打開位于上位機的MiniIMU軟件確認傳感器工作狀態良好。開始記錄后,穿戴者將分別進行正坐、前傾、左傾、右傾的活動,每一個活動將在一段時間內連續進行,數據采集結束后各項數據將以文本的形式保存至本地。
2.1 數據構建
2.1.1 構建標簽
坐姿姿態識別由于將采用監督式學習算法,所以需要人工對數據集設置標簽。由于文中選取正坐、前傾、左傾、右傾四個坐姿姿態,因此將正坐、前傾、左傾、右傾四個動作分別以標號1、2、3、4記錄。
2.1.2 構建數據集
生成的原數據文本每一條具有多維信息,文中為防止維數繁多而引起的過擬合,選用三軸加速度ax,ay,az和三軸角速度wx,wy,wz為最終構建數據集所需的數據信息。考慮到人體完成一個動作為一個連續的過程,而單條數據難以對一個活動進行描述,即其決定性有限,因此在特征提取時以連續40條數據為一個整體,類似于加窗處理方式,相鄰的整體以50%進行重疊。
為更好地輸入到神經網絡進行訓練,文中將預先人工對數據特征進行提取,選用平均值、標準差、偏度、峰度四個統計量來對上一節中的數據進行特征提取:
2.2 數據分布
經過無效數據的剔除、加窗和特征提取的處理過程后,構建的數據集每個動作的占比如表1所示。

表1 動作占比
每個動作的占比基本上在25%左右,數據集安全,可供神經網絡訓練使用。
2.3 標準預設
文中坐姿矯正使用的是監督學習的方法,需要對坐姿的端正與否制定較為科學合理的標準。事先采集多個不同體型的人正坐的數據,并提煉出2.1.2中所列舉的四個統計量分別求平均值,得到各項數據的平均水平作為端正坐姿的標準。表2是文中綜合考量不同體型的人所得到的較為均衡的數據標準,在訓練過程中近似符合該標準特征的動作視為正坐,即判斷為正確坐姿。
3 模型訓練
3.1 算法選擇
關于姿態識別,已存在很多分類算法。文獻[9]采用支持向量機(support vector machine,SVM)進行分類,但特征過于單一。文獻[10]將集成學習的相關理論基礎與隨機森林(random forest,RF)算法原理有機整合,平均識別精度為86.4%。文獻[11]提出的改進K-近鄰算法(K-nearest neighbors,KNN),更適合進行人體異常情況下行為的識別。此外還有Emerging Pattern(EP)模式匹配算法[12]、決策樹算法(decision tree,DT)[13]、樸素貝葉斯(navie Bayes,NB)[14]、基于隱形馬爾可夫鏈(hidden Markov model,HMM)的GMM-HMM模型[15]。

表2 標準預設
文獻[16]對K-近鄰算法、隨機森林算法和卷積神經網絡(CNN)算法進行評估,結果為CNN算法模型可以實現更為精確的姿態識別。而文中所進行的坐姿姿態識別涉及到坐姿的變換幅度小,更需要高精確度的模型辨識,而數據訓練集和標簽的構建更表明需要一種監督式學習算法,因而選用CNN算法模型為實現坐姿姿態識別的基礎模型。
3.2 模型搭建
3.2.1 算法設計
模型的基為:一維卷積神經網絡層、用于防止過擬合的輟學層、用于提取特征的池化層、用于連接輸出層的展平層、輸出最后分類結果的輸出層。
文中使用Tensorflow框架,結合第三方庫搭建神經網絡模型,Tensorflow2.0提供網絡層的定義和連接。以一層一維卷積層(Conv1D)進行特征學習。一維卷積層的輸入為文中每一條數據的72×1的矩陣形式。
經過卷積層的輸出為:
4.2 品種選擇 臨沭地瓜種植主要以鮮食品種為主,種植面積最大的品種為蘇薯8號(俗稱小花葉);其他品種有來福一號、紅香蕉、小黃瓤、濟薯26、煙薯25等。
Convi=f(
(1)
其中,i= 1,…,n- l + 1,f函數為激活函數;filter為卷積核;l為卷積核的長度;bias為偏置項;尖括號為求內積。
為了降低CNN極快的學習速度,設計輟學層(Dropout)隨機剔除網絡中的神經元來減慢學習過程以控制過擬合風險,原理見圖3。

圖3 Dropout層工作原理
常用的池化層Pooling有最大池化層和平均池化層,而文中選擇的最大池化層MaxPooling1D能減少卷積層參數誤差造成估計均值的偏移:
Pooli=max([Conv(i-1)P+1,…,ConviP])
(2)
其中,i=1,…,n/p;p為池化窗口的大小;max為取最大值函數;Conv為輸入的卷積層。
經過展平層Flatten的過渡,最后連接輸出層輸出分類結果。
目前常用的神經網絡激活函數有多種,文中卷積層使用ReLU函數加快訓練速度,該函數收斂速度快,能克服“梯度消失”問題。Softmax適用于多分類,按最大概率輸出預測值,因此輸出層使用Softmax分類器輸出分類結果。
鑒于多分類問題,損失函數選用交叉熵函數,優化器選用Adam。
3.2.2 超參數評估
為了更好地進行超參數評估,文中將神經網絡的epochs值設置為5,batch_size值設置為32。其余參數組合有多種,文中對4個超參數從模型準確率和擬合情況進行超參數評估,表3為控制單一變量進行調整,重復10次實驗得到的平均準確率和標準差,圖4~圖7為不同參數下loss的變化。
在選定模型時,準確率為第一考慮要素,使準確率提高以達到實驗目的;標準差一項能說明重復10次實驗所求準確率的波動程度,該值越大說明模型準確率越不穩定;準確率過高也有可能是模型的過擬合導致的后果,因此loss值的變化情況也應被考慮在內。
濾波器個數(filters):單層卷積層所擁有的濾波器個數。
卷積核大小(kernel_size):即濾波器形狀。
輟學率(Dropout):剔除網絡神經元的數量占比。
池化窗口大小(pool_size):池化矩陣大小。
filters個數的多少反映卷積層整體學習速度的快慢,filters越多,卷積速度越快。當filters過低時,模型欠擬合,平均準確率低且不穩定;當filters值大于2時,模型準確率較高,標準差小。但filters過高時,loss函數波動程度大,學習速度過快導致模型過擬合現象出現。因此選擇filters為2符合文中要求。
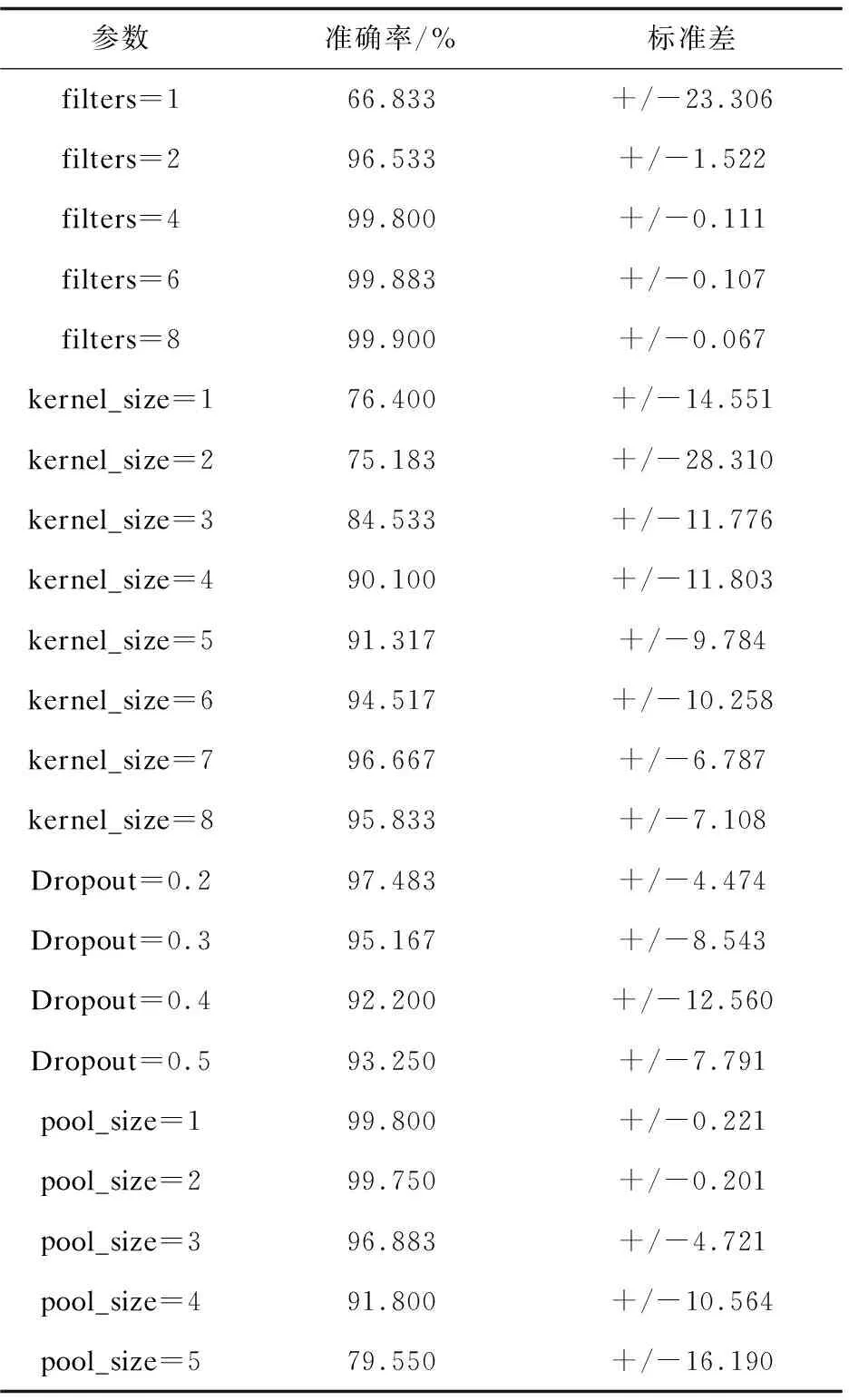
表3 調整不同參數得到的實驗結果
kernel_size的大小反映卷積層單次卷積學習速度的快慢,kernel_size越大,單次卷積速度越快。kernel_size為7的時候,準確率較高,loss函數波動程度小,無明顯反彈跡象,減輕了網絡過擬合,因此kernel_size取7適合。
增添Dropout層是為過擬合現象出現的解決方案之一,從表3中可以看出剔除20%的神經元是最合適的,損失值反彈的程度沒有其他情況下的高。

圖4 不同filters下loss值的變化

圖5 不同kernel_size下loss值的變化

圖6 不同Dropout率下loss值的變化

圖7 不同pool_size下loss值的變化
文中模型使用的是最大池化層,即取窗口數據中的最大值來代替窗口數據,pool_size值越大,池化層窗口越大,縮放比例越大。若縮放比例過大,很多特征將被忽略,影響準確率。文中模型的pool_size取3時,準確率較高,多次實驗結果穩定,并且損失值下降快速。
綜上考慮,最終模型的卷積層利用2個卷積核,每個卷積核的大小為7,Dropout率為0.2,池化層池化窗口大小為3。
3.3 多傳感器對比單個傳感器的優勢
為體現本方案所使用的多個傳感器相較于單個傳感器的優越性,分別在腰部、背部、頸部使用單個傳感器選取相同的數據,并采用相同方法對正坐、前傾、左傾、右傾四個動作進行識別。
在做四個動作時,腰部和背部的活動幅度小,而頸部的活動幅度大。如表4所示,在三個不同位置使用單個傳感器的總體準確率不高,置于腰部和背部的傳感器對正坐和前傾這兩個動作難以區分,而頸部的傳感器對左傾和右傾兩個動作識別的準確率可以達到90%以上,而像正坐和前傾那樣的動作細節的識別區分難以實現。但通過腰部、背部、頸部三點傳感器的聯合識別可使準確率到92%以上。

表4 位于不同部位的傳感器對坐姿
4 結束語
文中提出了一種基于多加速度傳感器的坐姿識別解決方案,在人體不同部位采集三軸加速度和三軸角速度的數據信息,并人工加以提取特征構建訓練集和標簽,輸入到搭建的卷積神經網絡模型中,最終得出識別準確率和識別結果。
該研究方案所使用的傳感器靈活、精度高、成本低,采用多個傳感器可從多維度采集一個動作的各項信息,提高了動作識別的辨識度,能更好地區分相似度高的動作。該研究方案可應用于監測不良坐姿,改善青少年坐姿不正的壞習慣,從而預防近視、勁椎病等問題的惡化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
