
基于深度學習的汽車車牌識別算法研究
2021-11-23 08:12:38高昕葳
機電工程技術 2021年10期
關鍵詞:模型
高昕葳
(甘肅林業職業技術學院機電工程學院,甘肅天水 741020)
0 引言
車牌作為汽車外在顯著身份信息之一,可以通過車牌獲得車輛的行駛路徑、類型、司機等信息。車牌識別應用范圍較廣,在智慧停車、高速公路車輛監測、城市限號等方面廣泛使用。然而目前所采用的車牌識別算法對車牌圖片要求較高,不能應用于復雜光線、多尺度、高識別率、速度快的識別的要求。車牌識別包含車牌提取、字符分割、字符識別三部分。傳統方法實現車牌定位主要依靠人工設計的特征:基于形態學特征的定位法[1-2],基于色彩圖像的定位法[3],基于神經網絡的定位法[4-5],基于紋理特征的定位方法[6]等。傳統的車牌識別算法對車牌圖片要求比較高,而影響車牌圖片質量的因素較多,如光線、車牌與圖像采集設備的距離和角度等。目前的分割算法有基于模板的字符分割算法[7]、聚類算法字符分割[8]等。字符識別作為車牌識別中最重要的環節,其準確率直接影響車牌的準確識別。使用機器學習算法識別字符[9],但是識別時間和識別率還有很大的提升空間。隨著深度學習的出現,特征提取不需要依靠人為設定特征,字符識別準確率和速度有了大幅度提升。因此,本文使用基于深度學習Faster-RCNN[10]與VGG16(Visual Geometry Group Network)模型相結合的車牌識別算法,對汽車車牌進行提取、分割和車號識別。
1 基于Faster-RCNN與VGG16的車牌識別
基于深度學習的目標檢測算法,按照原理可以將深度學習的目標檢測算法分為One-stage和Two-stage兩類,本文所用的是屬于Two-stage的Faster-RCNN模型。Faster-RCNN是一種應用于目標檢測和識別的卷積神經網絡,由Fast-RCNN改進而來,實現了端對端的檢測。使用該模型進行目標檢測任務能夠實現檢測對象的精確定位,預測圖片中的物體種類,克服多角度、多尺度、多類別、多場景的識別缺點,Fast-RCNN流程如圖1所示。

圖1 Fast-RCNN流程
2 車牌定位
本文使用Faster-RCNN模型對車牌進行提取。Faster-RCNN網絡模型首先使用基礎特征提取網絡提取被檢測圖像的特征向量。特征提取網絡包含13個卷積層和5個池化,特征向量被RPN(Region Proposal Networks)網絡和全連接網絡共享。RPN網絡用于生成目標的建議區域(region proposals),網絡結構包含一個3×3的卷積層和兩個1×1的卷積網絡,其網絡結構如圖2所示。通過Softmax激活函數,利用Bounding box regression修正anchor框獲得目標準確位置。Roi(region of interest)池化層用來得到對應的分類,也得到了概率向量接受特征提取網絡輸出的特征權值綜合proposals,經過一個全連接層和一個Softmax層,得到了概率向量,判定目標類別。

圖2 RPN網絡
3 字符分割
我國車牌類型多,種類復雜。以普通車車牌為例,小型車的藍底白字、中大型車的黃底黑字等。根據GA36-2007標準可以得知,車牌由1個文字加6個字符組成,其中第一個文字為車牌所在省份的簡稱,共31種,其余的字符為字母(去除I、O)和數字組成。首先對Faster-RCNN網絡提取的車牌進行圖像預處理。圖像預處理包括圖像灰度圖處理、濾波去噪、圖像增強、灰度圖二值化等。
3.1 圖像灰度化
車牌圖像以紅綠藍三通道分量來儲存圖片,圖像灰度化的過程是將彩色圖像的3個通道轉換為只有1個灰度通道的圖片。常用的圖像灰度化法有平均值法、最大值法、加權平均值法等。因車牌種類多,本文通過圖3所示的實驗結果對比,選用加權平均值灰度化方法,有較好的魯棒性。

圖3 常用的灰度化方法
3.2 濾波去噪
車牌圖像信息在采集中容易產生噪聲,常用的圖像濾波算法有高斯濾波、雙邊濾波、均值濾波等方法。雖然這些方法可以較好地去除噪聲,但是使車牌字符圖像邊緣變得模糊。而雙邊濾波很好地保持輪廓的邊緣特征的同時能消除噪聲。圖4所示為采用不同方法去噪的結果對比,本文采用雙邊濾波進行對車牌的去噪處理。

圖4 常用的濾波方法
3.3 圖像增強
圖像增強主要解決圖像的灰度級范圍較小造成灰度對比度較低的問題,目的是增強圖像的灰度對比度,使得圖像中的細節對比更加分明。幾種常用的方法有線性變換、分段線性變換、直方圖正規化、局部自適應直方圖均衡化等。本文采用了一種伽馬變換算法來增強車牌圖像的對比度,效果較好,有助于后續的處理。
3.4 圖像二值化
二值化主要為了減小計算量,其原理為:設定一個值T為閾值,將二值化圖像的像素灰度值與T比較,小于T,該像素值點設成0,即白色,否則該像素點值為255,即黑色。整個圖像呈現出黑白兩種效果。其中閾值的選取是二值化效果的關鍵,Otsu法統計整個圖像的直方圖來實現全局閾值T的自動選取,該算法簡單、穩定,是常用的一種方法,本文使用Otsu法對圖像增強后的車牌圖像進行了二值化處理,其過程如圖5所示。

圖5 圖像二值化過程
3.5 字符分割
本文采用基于垂直投影的字符分割算法,其原理是對預處理后的車牌圖像進從左到右進行掃描,統計車牌字符的每列像素點個數,可以得到一幅垂直投影圖像,根據車牌字符像素統計特點:波谷就是字符投影,波峰是字符間隙投影,選取所有波峰的中心位置,把車牌圖像分割成單個獨立的字符圖像,該方法簡單、速度快、效率高,分割效果如圖6所示。

圖6 字符分割
4 字符識別
傳統的車牌字符識別的方法是模板匹配和傳統BP(Back Propagation Neural Network)神經網絡等方法。卷積神經網絡可以對復雜的圖像自動提取特征和分類,受外界環境干擾較小,其魯棒性和自適應性比較好,因此本文采用了基于卷積神經網絡的VGG16網絡模型進行車牌字符識別。其模型包含了13個卷積層、5個池化層、3全連接層,模型如圖7所示。在模型中加入Dropout層,直接作用是按比例減少中間特征數量,從而減少冗余權值,增加每層各個特征之間的正交性,提升模型泛化能力。本文以CCPD數據集為基準,對字符分割后的字符圖片進行統計、分類,制作字符識別的數據集。數據集包含的種類有31種文字,去除I、O的剩余24個字母,10個數字,其識別車牌問題轉換為65種字符分類問題。數據集包含漢字圖片3 100張,字母圖片2 400張,數字圖片1 000張。在Keras平臺中運用深度學習理論搭建VGG16神經網絡模型進行訓練。將分割的二值化圖片長寬統一為224的圖片送入輸入層,損失函數使用relu,優化器選擇adam,epoch為200,進行訓練識別。圖8(a)所示為訓練精度與迭代次數關系,由圖可知在迭代到第100次時,準確率達到99.2%;圖8(b)所示為損失率與迭代次數關系,由圖可知,在迭代到100次左右時,損失率降到最低并趨于穩定,在迭代到200次時,其識別準確率為99.2%。
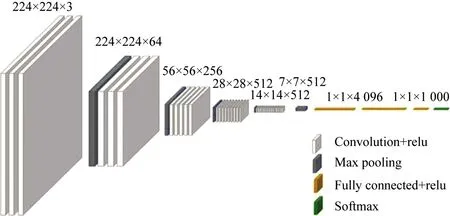
圖7 VGG16結構

圖8 識別訓練
5 結束語
本文使用Faster-RCNN和VGG16模型對車牌進行定位和識別。通過Faster-RCNN對車牌定位,使用VGG16模型進行識別,在車牌數據集進行訓練和測試,實驗結果表明本文使用的方法能夠有效地提取車牌圖像并且識別車牌號,檢測正確率高達99.2%。相比傳統的車牌識別算法,雖然模型訓練時間較長,但可以得到更高的準確率和更高的識別效率。由于樣本圖片數量有限,車牌圖片質量影響因素較多,若添加更多的樣本,使其數據更加豐富,模型的識別準確率會相應提高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
