基于生成對抗網絡的單圖像超分辨率重建
2021-11-26 07:48:58朱海琦李定文
吉林大學學報(理學版) 2021年6期
朱海琦, 李 宏, 李定文, 李 富
(1. 東北石油大學 電氣信息工程學院, 黑龍江 大慶 163318; 2. 大慶鉆探工程公司 鉆井一公司, 黑龍江 大慶 163458)
圖像超分辨率是指從一張低分辨率圖像或圖像序列重建出含有更多高頻信息和紋理細節的高分辨率圖像, 在人臉識別[1]、視頻監控[2]、衛星遙感[3]和醫學成像[4]等領域應用廣泛. 傳統的圖像超分辨重建方法主要有3類: 基于插值的[5]、基于重建的[6]和基于學習的[7-8]方法. 但上述方法重建出的圖像存在邊緣模糊、丟失高頻信息或只能處理結構簡單的圖像等問題. 由于神經網絡具有較強的擬合建模能力, 可在數據驅動下充分提取圖像的本質特征, 所以基于深度學習的超分辨率重建方法能得到更好的圖像視覺效果. Dong等[9]將卷積神經網絡(convolutional neural network, CNN)應用于圖像超分辨率, 提出了一種基于CNN的超分辨率重建算法(super resolution convolutional neural network, SRCNN), 該方法使用3層卷積神經網絡學習低分辨率圖像和高分辨率圖像之間的映射, 其重建效果好于其他傳統算法; Shi等[10]采用亞像素卷積層上采樣, 提出了一種亞像素卷積神經網絡(efficient sub-pixel convolutional neural network, ESPCN)方法, 提高了圖像的重建質量; He等[11]設計了一種殘差網絡(residual network, ResNet)解決網絡結構較深時無法訓練的問題; 在此基礎上, Kim等[12]提出了一種基于深度卷積神經網絡的超分辨率算法(very deep convolutional networks, VDSR), 擴大了圖像的感受野; Lai等[13]提出了基于Laplace金字塔網絡的超分辨率重建算法(deep Laplacian pyramid networks for fast and accurate super-resolution, LapSRN), 通過級聯方式逐步上采樣, 很好地實現了圖像中紋理細節的重建; Tong等[14]設計了一種基于密集跳躍連接網絡的超分辨率重建算法(super-resolution using dense skip connections, SRDenseNet), 有效提高了圖像重建質量; Li等[15]提出了一種反饋網絡實現超分辨率重建(feedback network for image super-resoluition, SRFBN), 提高早期重建能力以恢復出高質量的重建圖像; Ledig等[16]將生成對抗網絡(generative adversarial networks, GAN)應用于圖像超分辨率, 提出了一種基于生成對抗網絡的超分辨率重建算法(super-resolution generative adversarial networks, SRGAN), 利用感知損失驅動重建出逼真的高分辨率圖像.
受文獻[16-19]的啟發, 本文設計一種新的生成對抗網絡結構, 將GCNet模塊和像素注意力機制相結合, 形成通道和像素的雙重注意力機制模塊(channel and pixel attention mechanism), 簡稱為CP模塊. 首先, 在生成器網絡中采用WDSR-B殘差塊代替傳統的殘差塊充分提取圖像的淺層特征信息; 然后, 在每個WDSR-B殘差塊后加入一個CP模塊學習不同特征通道的重要程度, 抑制不重要的特征并學習圖像中的高頻信息; 最后, 在鑒別器的淺層和深層也分別加入一個CP模塊, 并用譜歸一化[20](spectral normalization, SN)代替批標準化(batch normalization, BN)減小計算開銷、穩定訓練.
1 預備知識
1.1 生成對抗網絡
生成對抗網絡[21]結構包括生成器網絡和判別器網絡, 兩個網絡通過相互對抗的方式進行學習, 最終達到Nash均衡, 其模型結構如圖1所示. 隨機噪聲z輸入生成器G得到假數據樣本G(z), 生成器的目的是學習真實數據樣本的分布, 并盡可能生成與真實樣本高度相似的數據樣本. 判別器D是一個二分類器, 輸入由生成器生成的假樣本G(z)和真實樣本數據x兩部分組成, 輸出是一個概率值, 表示生成器生成的假數據樣本被認為是真實數據的概率, 若輸入來自真實樣本, 則為1, 否則為0. 與此同時, 判別器會將輸出反饋給生成器, 用于指導生成器的訓練. 通過這種方式不斷地對抗訓練, 理想情況下達到判別器D無法判斷輸入數據來自真實樣本還是由生成器生成的假樣本, 即D每次輸出為1/2時為模型最優. GAN的目標函數為

(1)
其中V(D,G)表示GAN待優化的損失函數,Pdate(x)表示真實數據分布,Pz(z)表示隨機噪聲分布.
1.2 WDSR-B殘差塊
由于目前的網絡結構在提取特征過程中存在丟失淺層信息的問題, 即使后來通過在低層和深層網絡之間引入密集連接或跳躍連接解決了該問題, 但結構相對復雜, 所以Yu等[17]提出了一種使通道數先變多后變少的WDSR殘差塊, 其原理是在激活函數前的特征圖通道數越多, 低層特征信息越容易傳遞到深層網絡, 從而提高網絡性能. WDSR-B殘差塊的結構如圖2所示. 由圖2可見, 對于輸入特征x, 首先通過1×1卷積核將特征圖通道數擴大r倍, 然后通過ReLU激活函數進行非線性映射, 并引入線性低秩卷積(linear low-rank convolution)將一個大卷積核分成兩個低秩卷積核, 1×1卷積用于減小特征通道數, 3×3卷積用于進行空間特征提取, 最后將提取結果加上原來的特征輸入得到WDSR-B殘差塊的最終輸出.

圖1 生成對抗網絡模型Fig.1 Model of generative adversarial network

圖2 WDSR-B殘差塊結構Fig.2 WDSR-B residual block structure
1.3 GCNet模塊
生成對抗網絡大多數通過卷積操作學習圖像特征, 但卷積操作只適合在局部鄰域內建立像素關系, 當學習遠距離范圍特征信息時效率較低, 無法捕捉特征通道之間的依賴關系, 所以Cao等[18]結合NLNet[22]和SENet[23]的特點提出了一種既能利用全局上下文信息建模, 又輕量的結構, 稱其為GC模塊, 其結構如圖3所示.

圖3 GCNet模塊Fig.3 GCNet block
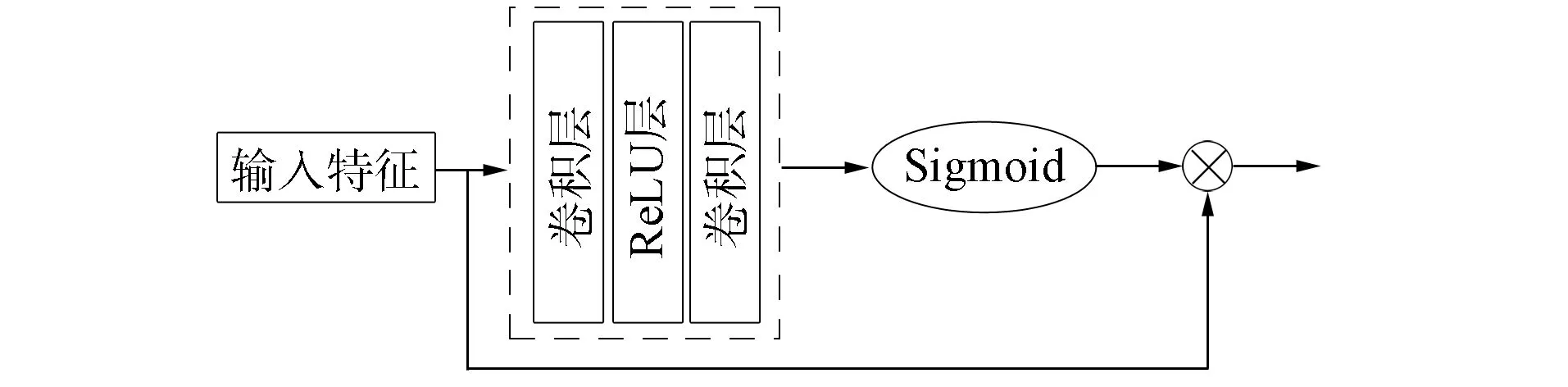
圖4 像素注意力機制模塊Fig.4 Pixel attention mechanism block
1.4 像素注意力機制
傳統卷積神經網絡對像素特征的處理是平等的, 但圖像特征中的高頻信息分布并不均勻, 低頻信息和高頻信息的像素權重明顯不同, 所以Qin等[19]采用了一種像素注意力機制關注高頻信息, 其結構如圖4所示.
2 本文方法
本文在SRGAN網絡的基礎上, 首先用WDSR-B殘差塊代替SRGAN網絡中使用的傳統殘差塊, 然后充分結合了GCNet模塊和像素注意力機制兩者的優勢, 提出既關注特征通道的相關性又可以捕獲圖像高頻信息的CP模塊, 并受文獻[18]啟發在每個WDSR-B殘差塊后加一個CP模塊, 此外, 在鑒別器中的淺層和深層分別引入一個CP模塊, 并且去除了不利于圖像超分辨率重建和大量增加網絡參數量的批歸一化層, 在生成器和鑒別器分別采用權值歸一化(weight normalization, WN)和譜歸一化加速模型收斂和穩定訓練, 最后在損失函數中添加整體變分(TV)正則項約束噪聲.
2.1 生成器網絡
設計生成器網絡時, 先使用一個9×9的卷積層對輸入低分辨率圖像進行特征提取, 然后通過16個WDSR-B殘差塊和CP模塊, 每個WDSR-B殘差塊包含兩個1×1卷積層和一個3×3卷積層, 并使用ReLU作為激活函數, 本文在殘差塊中選擇r=4, 即特征通道數在ReLU激活函數前先擴大4倍, 然后通過兩次卷積將通道數變回原來的通道數量(通道數先減小為擴大后的0.8倍, 然后再減小到原來的通道數量). 在CP模塊中所有的卷積層均為1×1卷積, 在通道注意力階段的全局信息上下文建模后, 對特征通道數進行一個先縮小16倍再擴大16倍的變化, 在像素注意力階段先通過一個1×1卷積將輸入通道數縮小8倍, 然后經過ReLU激活函數后再用一個1×1卷積將通道數擴大到原來的通道數. 特別地, 在WDSR-B殘差塊和CP模塊階段輸入通道數均為64, 然后通過跳躍連接的方式進行特征融合, 生成器中的歸一化層采用權值歸一化, 最后通過亞像素卷積層進行圖像上采樣到相應放大因子的高分辨率圖像大小, 整體過程如圖5所示. 圖5中的k,n,s分別表示卷積核大小、通道數和卷積步長.

圖5 生成器網絡結構Fig.5 Generator network structure
2.2 判別器網絡
設計判別器網絡時, 采用1組卷積層+Leaky ReLU激活函數形式和7組卷積層+譜歸一化+Leaky ReLU激活函數形式, 每個卷積層的卷積核大小均為3, 通道數依次為64,64,128,128,256,256,512,512, 在第1個和8個卷積層后分別加入一個CP模塊, 每個CP模塊的輸入通道數分別為64和512, 然后通過全連接層+Sigmoid將圖像數據維度鋪平對圖像分類判斷真假, 判別器的結構如圖6所示.

圖6 判別器網絡結構Fig.6 Discriminator network structure
2.3 損失函數
本文方法的損失函數由均方誤差(mean square rrror, MSE)損失、對抗損失和TV損失的加權和組成. MSE損失衡量了生成圖像和真實圖像的像素級差異, 更符合人的視覺感知; 對抗損失體現了網絡生成器和判別器互相博弈的過程, 有利于恢復圖像的高頻信息; TV正則項有利于保持生成圖像的平滑性, 減少噪聲. MSE損失、對抗損失和TV損失數學表達式分別為

L=LMSE+Ladv+LTV.
(5)
3 實 驗
為驗證本文算法的超分辨率重建性能, 本文在VOC2012數據集上進行訓練, 其中包括16 700張訓練圖像, 425張驗證圖像. 實驗在放大因子為2倍和4倍的條件下, 使用的測試集為Set5,Set14,BSD100和Urban100; 在放大因子為8倍的實驗中使用的測試集為SunHays80. 實驗在Intel(R) Xeon(R) Gold 5218處理器, NVIDIA Tesla P100 16 GB顯卡, Pytorch環境下進行.
3.1 參數設置
由于受實驗設備條件限制, 在實驗過程中訓練集的圖像被裁剪為88×88, batch_size=64, 實驗迭代次數為100次, 生成器和判別器使用Adam算法進行優化, 初始學習率設為10-4, 后20次迭代學習率調整為10-5, 本文涉及的超參數分別為α=10-3,β=2×10-8.
3.2 結果與分析
先將本文算法在數據集Set5,Set14,BSD100和Urban100上進行放大2倍和4倍的測試, 在數據集SunHays80上進行放大8倍測試, 再將重建效果與傳統的雙三次插值法(Bicubic)[24]、ESPCN算法[10]、SRCNN算法[9]和SRGAN算法[16]進行主觀和客觀的對比. 為使測試結果更公平, 所有方法均使用VOC2012數據集進行訓練; 由于測試平臺配置和所用框架不同, 對比算法測試結果可能與原文獻不一致.

圖7 不同方法在Set5測試集中圖像“baby”重建效果對比Fig.7 Comparison of reconstruction effects of image “baby” in Set5 test set by different methods

圖8 不同方法在Set14測試集中圖像“butterfly”重建效果對比Fig.8 Comparison of reconstruction effects of image “butterfly” in Set14 test set by different methods

圖9 不同方法在Set14測試集中圖像“Lenna”重建效果對比Fig.9 Comparison of reconstruction effects of image “Lenna” in Set14 test set by different methods
在主觀視覺上, 不同算法放大4倍的重建效果分別如圖7~圖9所示. 由圖7可見, 在嬰兒的局部眼睛放大圖中, Bicubic算法重建的圖像最模糊, ESPCN和SRCNN算法重建的圖像比Bicubic算法重建的圖像更清晰, 但出現了偽影, SRGAN算法和本文算法重建圖像的效果相似且好于前3種算法, 但本文算法重建的圖像眼睛含有更多的細節信息, 睫毛和人眼輪廓更清晰. 由圖8和圖9可見, 在翅膀和頭發的放大圖中, 本文算法重建的圖像與其他算法重建的圖像相比紋理細節更豐富, 恢復了更好的邊緣信息. 因此, 本文算法重建的圖像取得了最好的視覺效果, 原因是本文方法通過引入WDSR-B殘差塊和CP模塊提高了淺層特征利用率, 并學習到了特征通道的相關性和圖像高頻信息, 從而可以成功地捕捉到圖像的幾何特征和細節紋理信息.
本文采用的客觀評價指標為峰值信噪比(peak signal to noise ratio, PSNR)和結構相似性(structural similarity index measure, SSIM). PSNR反應了真實圖像和重建圖像對應點的像素差異, 其值越大表示圖像失真越小, 重建質量越好; SSIM表示真實圖像和重建圖像的相似程度, 其值越接近1表示重建效果越好. 在放大因子為2,4,8的條件下, 不同算法在基準數據集的測試結果列于表1.

表1 不同方法的客觀指標對比結果
由表1可見, 本文算法除在放大因子為2和測試集為BSD100的情形下PSNR值略低于SRGAN算法外, 其他情況均取得了最優的結果. 在放大因子為4的情形下, 本文算法在Set5,Set14,BSD100和Urban100測試集上的PSNR值相比SRGAN算法分別提高0.63,0.40,0.31,0.48 dB, SSIM值分別提高了0.021 9,0.020 3,0.016 9,0.023 7; 在放大因子為8的情形下, 本文算法在SunHays80測試集上的PSNR值和SSIM值相比SRGAN算法分別提高了0.37和0.015 3, 表明了本文算法在超分辨率重建上的有效性.
綜上所述, 針對在圖像超分辨率重建過程中淺層特征信息利用不充分、難以學習各特征通道的重要程度和丟失高頻信息的問題, 本文結合SRGAN網絡的優點提出了一種新的生成對抗網絡用于圖像超分辨率. 該網絡在生成器中引入WDSR-B殘差塊和CP模塊, 并使用權值歸一化代替批歸一化, 在判別器網絡的淺層和深層分別加入一個CP模塊, 并使用譜歸一化代替批歸一化, 最后在損失函數中加入TV正則項. 與其他經典算法進行實驗對比的結果表明: 本文方法在主觀上重建出了較好的視覺效果, 重建了逼真的細節紋理信息和幾何特征; 在客觀評價指標上, 本文方法取得了較高的PSNR和SSIM值, 從而驗證了本文方法在超分辨率重建上的有效性.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
