基于RF-VR的紫丁香葉片葉綠素含量高光譜反演
2021-11-27 13:29:06肖志云王伊凝
浙江農業學報 2021年11期
關鍵詞:模型
肖志云, 王伊凝
(內蒙古工業大學 電力學院,內蒙古機電控制重點實驗室,內蒙古 呼和浩特 010051)
綠色植物的生長過程離不開光合作用,葉片葉綠素含量及其動態變化與光合作用能力密不可分,檢測葉片葉綠素含量,對植物的長勢監測和精準農業的實施具有重要意義[1-3]。目前葉綠素含量測定方法主要分兩種:化學測定法[4]需要破壞植物樣本,耗時且費力;SPAD(soil plant analysis development)葉綠素測定儀通過測量葉片對兩個波段(紅波段和近紅外波段)的吸收率,計算當前葉片中葉綠素的相對含量,但其只可實時測出局部點光譜對應的SPAD值,無法反映整張葉片各像素點的葉綠素分布差異,對儀器精度有很高的依賴性。葉綠素含量的變化會引起植物反射光譜特征的變化。高光譜技術[5]具有圖譜信息合一的優勢,既可以利用多波段光譜對葉片葉綠素含量進行定量反演,又可以利用圖像像素點分布進行葉綠素分布可視化研究,這就為利用高光譜技術獲取植物生化參數提供了理論基礎,但由于高光譜所含波段數量大,波段間相關性強導致數據中冗余信息增多,當下關鍵問題是,對高維的高光譜數據降維,達到簡化模型的目的,同時保持甚至提高模型的預測能力。
早期學者們利用相關性分析法[6-8](correlation analysis,CA)探究植物生理參數與其光譜反射率(或經不同數學變換后的光譜反射率)的關系,選取相關系數高的波段作為敏感波長。但其只考慮了單波段與植物生理參數間的相關性,未考慮各波段間的共線性,難以解決光譜數據的冗余問題,而且所選波段較集中,只考慮某一段波長范圍的重要性,未考慮到其他波段,造成光譜數據的浪費。而后學者們嘗試采用敏感變量優選方法[9]從全波段內剔除無關變量,優選出敏感變量,減少數據量從而簡化模型。常用的變量優選方法包括競爭性自適應重加權算法(competitive adaptive reweighted sampling,CARS)、無信息變量消除算法(uninformative variable elimination, UVE)、移動窗口偏最小二乘法(moving window partial least square ,MWPLS)等。Li等[10]通過小波變換結合UVE技術簡化模型并提高了偏最小二乘回歸(PLSR) 模型預測的穩定性。趙艷茹等[11]、邵園園等[12]利用CARS方法篩選敏感波段,簡化模型后得到比全波段還要高的PLSR預測精度。結果表明,對原始光譜進行敏感波段優選既可以降低模型復雜度,又能很好地提高模型的精度和穩定性。隨機蛙跳算法(random frog,RF)通過在特征空間模擬一條平穩分布的馬爾科夫鏈來計算每個變量被選擇的概率,從而進行重要變量的篩選,被證明是一種較優的變量優選算法。如龍燕等[13]利用連續投影法(SPA)結合RF優選出最佳波段,用于建立偏最小二乘回歸模型(PLSR)預測番茄的硬度;孫紅等[14]用CA和RF算法篩選到的敏感波段建立PLSR模型,結果表明,相比于CA法,RF算法篩選的敏感波段分布范圍更廣且對馬鈴薯葉片含水率預測性能更優;孫紅等[15]基于馬鈴薯葉片成像高光譜數據,利用RF-PLSR模型反演出不同位置葉片逐像素點的葉綠素值。研究中大部分使用線性回歸(LR)、神經網絡(NN)、偏最小二乘回歸(PLSR)等算法來建立回歸模型,各模型均有其特點和優勢,因為PLSR可有效解決高光譜數據波段間的共線性和信息冗余問題[16-18],應用最為普遍。隨著機器學習方法[19]日漸成熟,被廣泛應用于高光譜反演中。金秀等[20]優選并組合了4個單模型,對集成算法進行了優化,結果顯示梯度提升樹算法(GBT)對土壤磷含量的預測精度最高。研究表明,采用機器學習算法可有效提高植物生理參數反演精度,明顯優于傳統方法,但將機器學習方法融合的建模方法并不多見,與單個機器學習建模算法相比,融合建模方法對異常值和噪聲的敏感度更低,預測穩定性能更優。
本研究利用高光譜成像技術獲取紫丁香葉片光譜信息,針對葉片葉綠素含量基于隨機蛙跳(random frog,RF)方法篩選敏感波段,建立具有低復雜度和高穩定性的投票回歸器(vote regressor,VR) 模型,并與全波段以及其他經典變量提取方法篩選出的敏感波段建立的偏最小二乘回歸(partial least squares regression,PLSR)和投票回歸(VR)模型的預測結果進行比較,同時結合偽彩色技術繪制紫丁香葉片葉綠素含量可視化分布圖,探索RF算法結合VR模型快速估測葉片葉綠素含量的可行性,以期為大面積監測紫丁香冠層葉片養分分布和生長狀況提供技術支持。
1 材料與方法
1.1 試驗樣本
實驗對象為紫丁香,研究區選定在內蒙古工業大學校園內(呼和浩特市),研究對象為2020年5月采集于開花期的紫丁香葉片。根據校園紫丁香樹的分布情況,同時保證實驗結果具代表性,在每棵紫丁香樹的東、西、南、北四個方位,隨機采集100個完整無損葉片樣本入袋密封并編號,后帶回實驗室低溫冷藏的同時進行實驗測定。
1.2 丁香葉片高光譜圖像信息獲取
本文采用芬蘭Specim IQ高光譜成像系統,一款帶有集成操作系統和控制裝置的手持式掃帚系統,采集丁香葉片光譜成像數據,結構如圖1所示,該系統主要由高光譜相機、可控載物臺、植物葉片樣品、2個鹵素燈電源、計算機及相應配套控制軟件組成。高光譜相機攝像頭分辨率為512×512像素,光譜范圍為400~1 000 nm,光譜分辨率為7 nm,設置載物臺和鏡頭之間的距離為20 cm,系統曝光時間為15 ms,為消除基線漂移須測量前預熱20 min,然后將已編號丁香葉片放于載物臺正對相機,最終得到一個同時包含圖譜信息的三維數據塊。
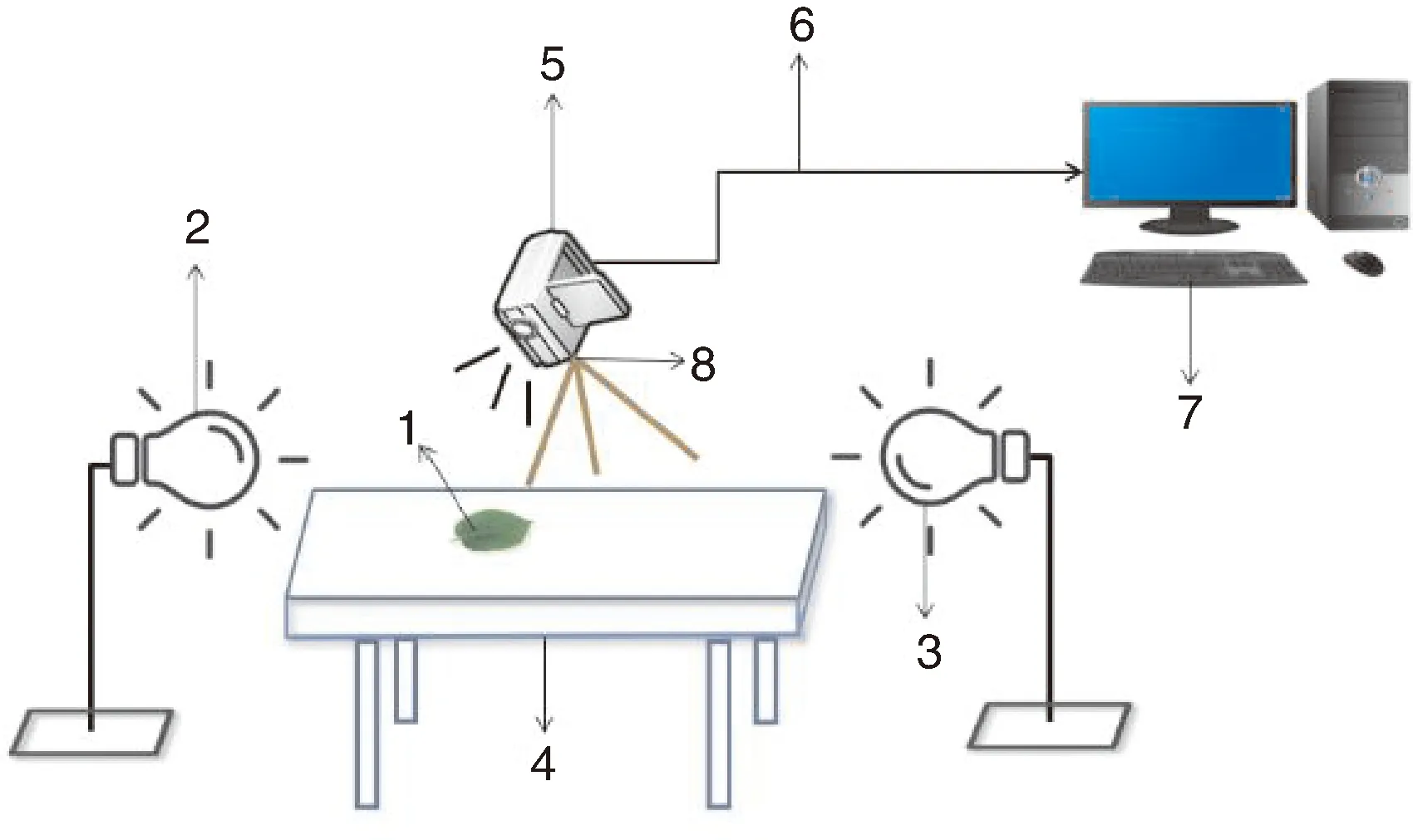
1,樣品;2、3,鹵素電源;4,可控載物臺;5,高光譜相機;6,數據傳輸線;7,計算機;8,三腳架。1, Leaf sample; 2, 3, Light source; 4, Storage platform; 5, The Specim IQ hyperspectral camera; 6, Transmission data line; 7, Computer; 8, Tripod.圖1 高光譜成像系統Fig.1 Hyperspectral imaging monitoring system
在數據采集實驗過程中,光照強度不均勻或暗電流等因素都會對實驗結果產生影響,故需要對采集好的高光譜圖像進行黑白板校正,最終得到校正后的原始光譜數據Rraw,校正公式如下:
(1)
式中:Rraw為黑白板校正后圖像數據;W為白板數據;B為黑板數據;I為原始圖像數據。
1.3 葉綠素含量測定
本文采用手持式植物參數檢測儀對劃分區域進行無損檢測,以SPAD值作為葉綠素含量參考指標[21]。測量時避開葉脈和不平整區域,每片葉片主葉脈左右各選取3個感興趣區域(ROI),并對3個感興趣區域求平均,每片葉子可得2個SPAD值,最終通過對100個丁香葉片樣本的測量,獲得200個SPAD值。在測定SPAD值過程中對測量區域用馬克筆標記測量范圍并編號,以便獲取相應位置光譜。
1.4 光譜預處理
卷積平滑(savitzky golay,SG)濾波算法可以減少噪聲干擾,使光譜曲線更加平滑。光譜微分技術(spectral differentiation technology)通過計算光譜的n(n取1,2,3,…)階微分值來確定光譜曲線的極值點選取光譜響應波段。應用光譜微分技術能夠消除大氣效應和植物背景的影響,將光譜曲線間的微小差異放大,可以更明顯地反映出不同葉綠素含量的植物的光譜響應差異。故在波段篩選和建模前,選用卷積平滑(SG)和二階微分處理(second derivative,SD)對原始光譜數據進行預處理[22-23],獲得SG-SD預處理后的葉片光譜反射率RSG-SD。
1.5 基于RF的特征波長提取方法
作為一種高效降維方法,隨機蛙跳[24-25](random frog,RF)算法在特征空間建立一條具有平穩分布特性的馬爾科夫鏈,計算得到一個一維概率矩陣,每個概率值代表每個波段被選擇的概率大小。相比較于經典變量優選算法,該算法具有隨機搜索的特性,能夠利用較少的變量迭代建模。RF算法主要的運算步驟包括以下4步:
(1)輸入一個初始波段子集F0,初始化時包含K個隨機波段,設定迭代次數N;
(2)在原始波段子集F0基礎上選出一個候選波段子集F*,包含K*個波段;對初始波段子集F0建立PLS模型,計算并降序排列各波段的絕對回歸系數:若K*=K,則F*=F0;若K*
(3)選擇F*替代原波段子集F0,迭代N次后完成計算;
(4)計算N次迭代后每個波段被選擇的概率值,此概率值大小被作為變量是否被選取的標準,概率值越大說明此波段越被優先篩選。
1.6 基于VR的葉綠素含量預測方法
本研究提出的投票回歸器(vote regressor,VR)[26]是一種分步非參數方法,融合了線性模型和非線性模型兩大類建模方法,與傳統回歸模型和單個機器學習算法相比,能更好地處理偏離點和噪聲,平衡它們各自的弱點。建模流程如圖2,具體運算步驟如下:
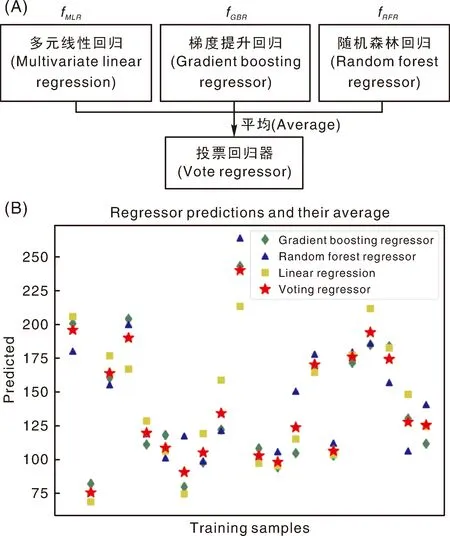
圖2 投票回歸器算法流程圖Fig.2 Voting regression algorithm flow chart
(1)多元線性回歸(multivariate linear regression,MLR)通過最小化誤差平方尋找最佳擬合函數預測葉綠素含量fMLR。
(2)利用梯度提升回歸(gradient boosting regression,GBR),通過串行地生成多個弱學習器,來擬合各分類器先前累加模型的損失函數的負梯度,使加上該弱學習器后的累積模型損失往負梯度的方向減少來預測葉綠素含量fGBT。
(3)利用隨機森林回歸[27](random forest regressor,RFR)模型,以決策樹為基學習器構建Bagging,在生成樹的時候, 每個樹的每個節點都是隨機生成的,每個節點的拆分變量由少量隨機選擇的變量生成,形成多個決策樹,對結果取平均可得葉綠素含量的預測值fRFR。
(4)計算并返回三者的平均預測值,最終模型對葉綠素含量預測結果如式(2):
(2)
建立定量分析模型后,需選擇有效評估模型預測能力的指標,本研究選用決定系數R2進行模型的評估,R2值在0和1之間,值越接近1,表明預測精度越高。本文數據處理與建模在Matlab2016和Python3.7軟件中完成。
2 結果與分析
2.1 丁香葉片光譜曲線分析
本文利用ENVI5.3提取丁香葉片編號區域的平均光譜值。Rraw曲線走勢總體符合綠色植物葉片的光譜響應特性(圖3-A),主要特征包括在可見光的綠波段對葉綠素的強反射現象導致出現“波峰”現象,由于可見光紅波段對葉綠素的強吸收現象導致出現“波谷”現象,且在近紅外區(750~800 nm)光譜反射率急劇上升后不再變化,形成近紅外強反射平臺。從圖3-B中可以看出,Rraw經SG-SD預處理后,由葉綠素含量差異導致的光譜曲線的等級差異得到有效消除,光譜曲線的微小細節特征被放大了。
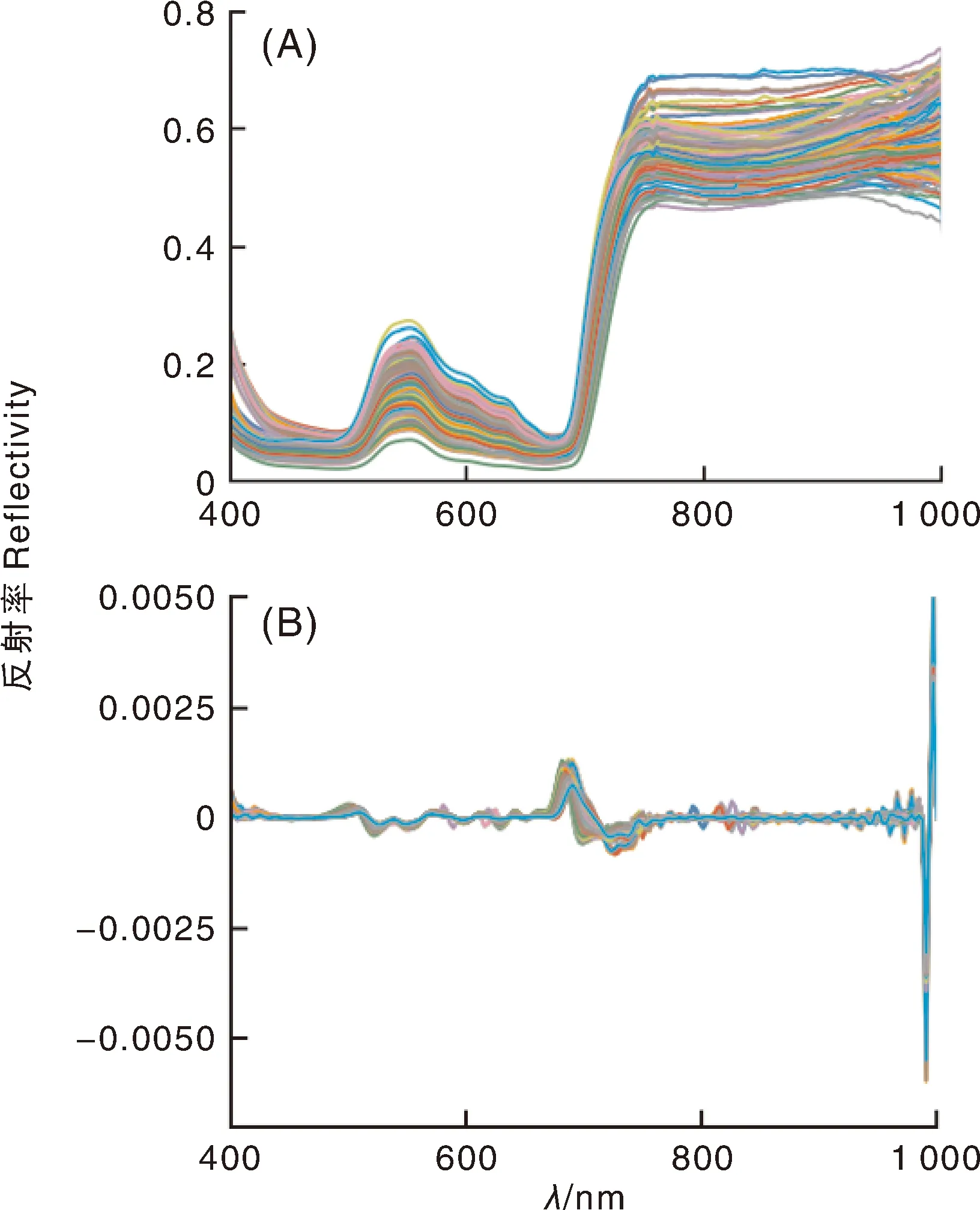
圖3 紫丁香葉片樣本原始光譜曲線Rraw(A)和預處理后光譜曲線RSG-SD(B)Fig.3 original spectral curve Rraw (A) and pretreated spectral curve RSG-SD (B) of syringa oblata leaves
2.2 丁香葉片SPAD值統計
200條樣本SPAD值的分布范圍在18.3~44.3,平均值為32.4,其中SPAD值主要集中在22.9~41.3,采用SPXY(sample set partitioning based on joint X-Y distance)算法將200個樣本中160個樣本劃分為建模集,其余40個劃分為驗證集,它是基于統計學角度的一種樣本集劃分方法,綜合考慮光譜和化學性質的差異來選擇建模集,劃分結果如表1所示。

表1 樣本SPAD值統計與劃分
2.3 特征波長篩選
2.3.1 CA、CARS、MA-UVE、MWPLS算法特征變量篩選
全波段光譜數據量大且波譜間信息重疊現象嚴重,需要進行敏感波段優選以簡化模型提升模型效率。本研究利用隨機蛙跳算法(RF)和相關系數法(CA)、自適應重加權算法(CARS)、無信息變量消除算法(UVE)、移動窗口偏最小二乘法(MWPLS)進行敏感波段的篩選,而后對其篩選結果進行建模,并對比和分析其建模精度。圖3為CA、CARS、UVE、MWPLS算法從SG-SD光譜數據中提取的特征波長在一條原始光譜曲線上的分布。
基于CA算法從RSG-SD中提取出相關系數絕對值大于閾值0.8的31個波段(圖4-A),CA算法的優點是計算簡單,計算公式直觀且比較容易理解,但其選擇的特征波長較集中,所選敏感波段集中在485~710 nm,如果只考慮此段波長范圍的重要性,難以解決光譜數據的冗余問題,未考慮到其他波段,造成光譜數據的浪費。
基于CARS算法從RSG-SD中共選擇29個波段(圖4-B),所選敏感波段集中在420~690 nm、800~920 nm,CARS算法選擇的敏感波段不穩定,而且存在大量冗余信息,這些無用信息會影響重要變量的優選。
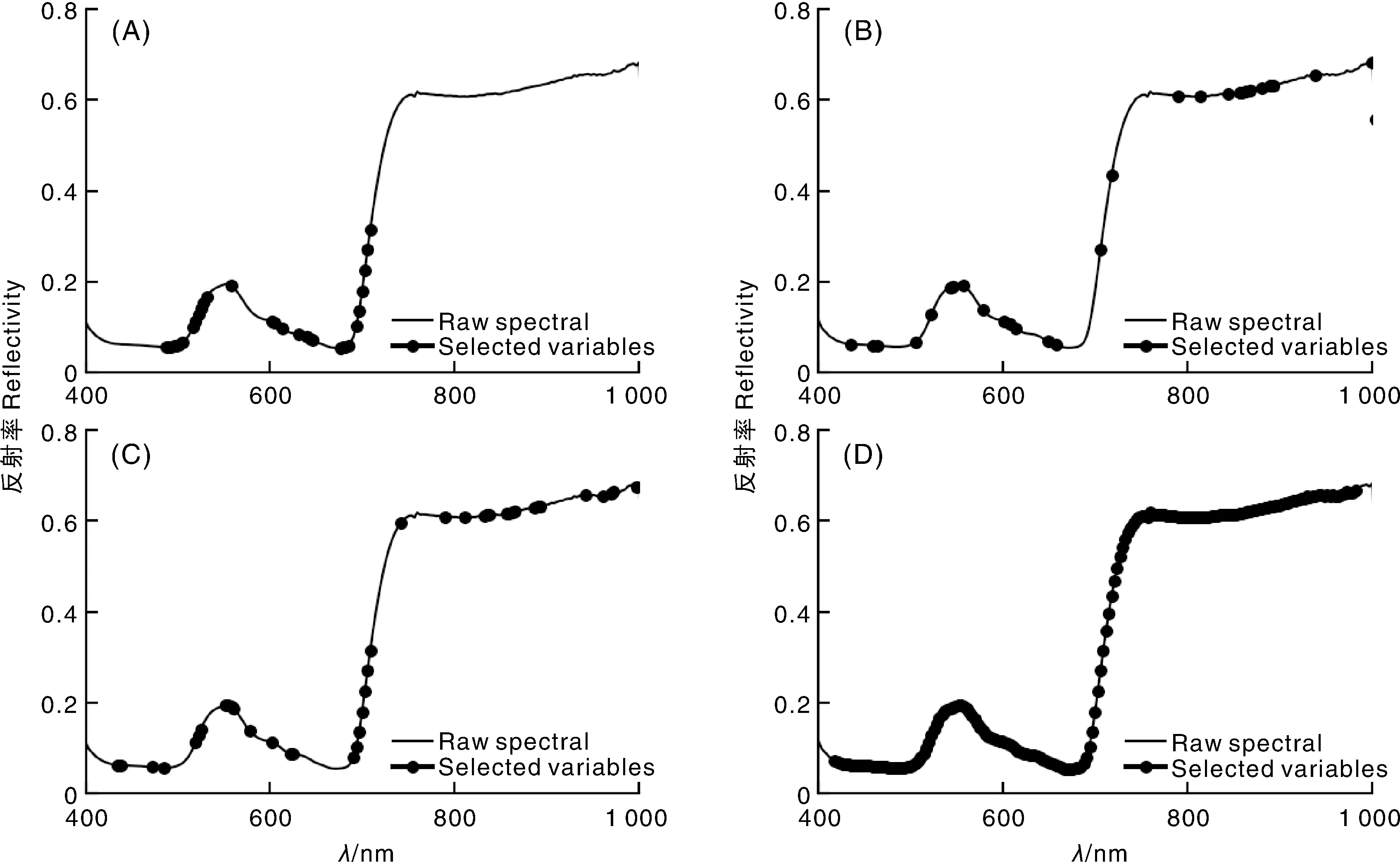
圖4 CA(A)、CARS(B)、UVE(C)和MWPLS(D)算法篩選變量分布圖Fig.4 Distribution map of variables selected by CA(A), CARS(B), UVE(C) and MWPLS(D) method
基于UVE算法從RSG-SD中篩選敏感波段,通過交叉驗證,RSG-SD的變量個數為40個(圖4-C)時,模型精度達到最高,所選敏感波段集中在420~620 nm、700~750 nm、800~1000 nm。UVE可以盡可能消除無用波段,但其并未確定對紫丁香葉綠素敏感性強的波段,計算量大,耗時長,且篩選出的變量建模精度相對較低。
基于MWPLS 算法篩選最優波段區間,但本研究中其篩選出波段數量為190個(圖4-D),所選區間為420~980 nm,只剔除掉14個波段,未解決光譜數據冗余問題。
2.3.2 RF算法特征變量篩選
隨機蛙跳(random frog,RF)算法與PLSR方法相結合,計算PLSR模型中所有變量的回歸系數,將各變量絕對值大小作為迭代過程中每次該變量是否被選擇或者提出的依據,后基于不同的波長點具有不同的概率值進行敏感波段的選擇,運行結果如圖5-A,橫軸代表波段,縱軸代表某波段被選擇的概率值,概率值越大說明該波段越重要。設定0.3作為葉片葉綠素含量對應的篩選敏感波段的閾值,最終基于Rraw和RSG-SD分別篩選出49個和35個敏感波段,圖5-B為RF算法對RSG-SD篩選出的35個敏感波段在一條原始光譜曲線上的分布狀況,分布在420~450 nm、500~590 nm、620~650 nm、700~800 nm、850~900 nm、950~1 000 nm。RF算法既降低了波段間的多重共線性,又能更全面地提取與葉綠素含量相關的敏感波段,所選出的波段范圍更分散,跨度更廣。

圖5 RF運行結果每個波段被選擇概率(A)和波長篩選結果(B)Fig.5 Results of of RF, Probability of each wavelength selected (A) and wavelength selected results (B)
2.4 PLSR建模
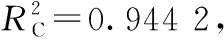

表2 不同變量篩選方法PLSR建模精度
2.5 VR建模
基于RF、CA、CARS、MWPLS和UVE算法選擇出的敏感波段和全波段(FULL),對Rraw和RSG-SD建立VR模型。表3中可看出,經SG-SD處理后的光譜數據的建模精度較原始光譜數據均有不同程度提高,但對RSG-SD建立的CA-VR、RF-VR、CARS-VR、UVE-VR、MWPLS-VR模型的精度相比于FULL-VR模型提高不多,各精度值相差微小,說明采用VR建模對于葉綠素含量預測精度的提高效果不大,但建模過程中輸入的波段數卻大大減少,表明VR模型可以更好地解決變量間復雜的非線性關系,VR模型對異常值和光譜噪聲的敏感度更低,使模型預測穩定性能更優。在建模前對原始光譜數據進行預處理和敏感變量篩選,在保證模型預測度的同時大大降低了模型的復雜度。圖7為對RSG-SD建立RF-VR模型后建模集和驗證集樣本葉綠素含量實測值和預測值的散點圖。
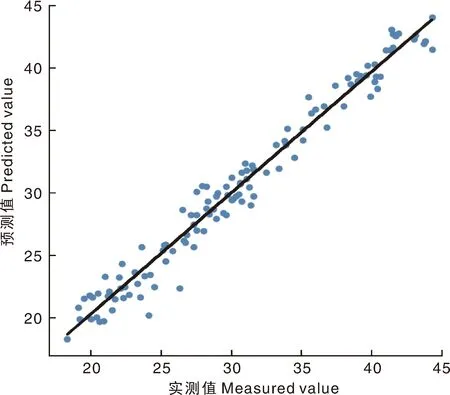
圖6 RF-PLSR模型預測值和實測值散點圖Fig.6 Scatter diagram of predicted and measured values for the RF-PLSR model

表3 不同變量篩選方法VR建模精度

圖7 RF-VR模型預測值和實測值散點圖Fig.7 Scatter plot of predicted and measured values for the RF-VR model
2.6 紫丁香葉片葉綠素含量分布反演圖
由上得, RF波段優選算法結合VR模型可有效預測紫丁香葉片上各個像素點的葉綠素含量。具體步驟如下:
(1)獲取敏感波段下的純紫丁香葉片高光譜圖像;
(2)提取圖像每個像素點的反射率;
(3)將(2)中結果代入RF-VR模型中求出各像素點SPAD值,得到灰度圖像;
(4)利用偽彩圖技術將灰度圖轉化為彩色圖,得到紫丁香葉片葉綠素分布圖(圖8)。
圖8可以直觀地看出紫丁香葉片上葉綠素的分布情況,偽彩色圖中顏色的差異和相同顏色深淺程度差異代表了紫丁香葉片中葉綠素濃度的差異。圖中,葉脈兩側葉綠素分布均勻,葉脈部分主要顯示為藍色(SPAD值為10~20),葉肉部分主要顯示為綠色(SPAD值為20~40),葉肉中的葉綠素含量較葉脈整體偏高。葉片首端顏色主要顯示紅色(SPAD值為40~50),葉片末端顯示黃色(SPAD值為30~40),首端葉綠素含量高于末端。圖中葉片外黑色區域為數據采集背景,葉片內黑色區域是由于葉片邊緣光照強度不均勻或陰影導致,故不可代表此區域SPAD值。總之,最終根據RF-VR模型比較準確地預測出了葉片葉綠素含量分布。
3 結論

綜上,利用高光譜成像技術結合光譜預處理技術和RF-VR模型能夠較好地對紫丁香葉片葉綠素含量反演和葉綠素分布可視化表達。但仍存在不足,本實驗數據僅采集于紫丁香開花期,未考慮本模型是否同樣適用于紫丁香其他時期,采樣范圍也局限于校園內。因此,今后應擴大采樣范圍和采樣時段以期提升模型精度和普適性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
