相空間重構的輕量級活動識別算法研究
2021-11-28 11:55:52和夢琪施偉斌
軟件導刊 2021年11期
和夢琪,施偉斌
(上海理工大學光電信息與計算機工程學院,上海 200093)
0 引言
隨著MEMS 技術和人工智能的快速發展,智能生活輔助系統備受關注[1-4]。人體活動識別(HAR)因其在普適計算中的卓越貢獻,已成為其中一個熱門研究領域。研究人員將該系統作為獲取信息的媒介,通過環境傳感器和可穿戴傳感器信號獲取人體行為信息,將采集的信號數據通過機器學習算法加以處理,以識別發生事件的種類。HAR 系統可在智能環境中的許多實際場景中得到應用,例如智能家庭醫療保健系統,可以連續地觀察病人,實現監控診斷和醫療輔助[5-6],尤其是將其應用于行動不便的高危老人日常行為監控,預防老人跌倒引發的意外情況[7-9]。
在過去幾十年里,研究者針對人體活動識別進行了大量研究,基本可概括為兩種識別方法:一是基于環境采集設備如麥克風及攝像機等[10-11],二是基于可穿戴傳感器設備。基于環境傳感器的人體活動識別主要關注攝像機采集的信息,因為攝像機可以容易地檢索周圍環境的圖像。但隨之也帶來了隱私相關問題,這種方案不能很好地保護與尊重監測者的隱私,并且受限于復雜環境因素如光線,視頻傳感器并不能準確地提供監測者的活動信息。于是,慣性傳感器等可穿戴傳感器因其可以克服隱私問題而在智能家居應用中得到越來越多的關注[12-14]。基于可穿戴傳感器設備的人體活動識別系統通常用于識別大范圍的日常活動,如站立、行走、上下樓梯以及奔跑等。大多數人體活動識別需提取時域、頻域以及啟發式的多維特征并將其作為訓練特征向量,Anguita 等[15]提取時域與頻域的17種特征向量,并利用定點算法降低計算成本,通過標準的SVM 分類器對其進行識別,顯著降低了計算成本;Gao 等[16]通過提出分布式人體多位置的傳感器數據采集方法,在多位置佩戴傳感器進行數據采集,提取了包括均值、標準差、過零率、均方根、譜能量、譜熵等12 種時域和頻域特征,此多傳感器系統在決策樹分類器分類算法上可得到96.4%的整體識別準確率;Hsu 等[17]提出一種可穿戴的慣性傳感器網絡及其相關活動識別算法,通過采集手腕和腳踝上的加速度計與陀螺儀數據,提出包括均值、平均絕對值、最大值、最小值、偏斜度、譜熵、頻率能量等21 種時域與頻域特征,再通過非參數加權特征提取算法和主成分分析法降低特征維數,最終在識別10 種日常家庭活動和11 種體育活動數據集上分別得到98.2%和99.5%的識別準確率。
以往基于慣性傳感器的人體活動識別方法需要豐富的先驗知識以提取足夠的特征向量,特征向量的維數加大了計算成本。為此,本文提出一種基于相空間重構的輕量級活動識別算法,降低特征提取復雜度,并結合Xgboost 分類器進行活動識別。為驗證算法的有效性與魯棒性,選取UCI HAR 數據集與ADL 數據集進行測試。本研究的主要貢獻包括:①提出一種基于相空間重構的輕量級活動識別算法,降低特征提取步驟計算成本;②結合特征降維算法進一步降低特征維度,提高整體系統識別精度;③與Xg?boost 分類器相結合,在兩種公開數據集上得到了穩定的活動識別精度。
1 基于相空間重構的輕量級活動識別算法
1.1 基本框架
人體活動識別主要分為數據采集與預處理、特征提取與選擇、分類器訓練以及測試等階段[18]。傳統的人體活動識別方法通常需要提取活動數據的時域特征、頻域特征以及時頻特征等,這幾類特征提取方法需要實驗者具有豐富的先驗知識,并且往往需要提取多種特征才能達到較好的識別結果,較高的特征矩陣維度增加了分類器的訓練難度。為克服復雜的特征提取問題,本文提取基于相空間重構的輕量級活動識別算法,通過簡單的單軸加速度數據的相空間重構與降維,能夠有效地進行活動識別。其主要步驟包括加速度數據預處理、Z 軸加速度數據相空間重構特征提取、相空間重構特征降維以及Xgboost 分類器訓練與測試[19]。

Fig.1 Flow of lightweight activity recognition algorithm based on phase space reconstruction圖1 基于相空間重構的輕量級活動識別算法流程
1.2 數據采集與預處理
為驗證本文算法有效性,采用公開活動識別數據集ADL[20]及機器學習公開人體活動識別數據集UCI[21]。其中,數據集ADL 來自于在真實自然條件下對15 名志愿者(8個男生,7 個女生)8 種活動的數據采集,分別包括上樓梯、下樓梯、跳、躺、站、坐、跑以及行走,文中選取腰部三軸加速度計采集數據進行研究。公開人體活動識別數據集UCI采集了30 位年齡在19~48 歲志愿者的6 種活動數據,分別包括上樓梯、下樓梯、坐、站、躺以及行走。采集的數據來自于固定在腰部的智能手機,本文選取手機中加速度傳感器數據進行研究,數據集的采樣速率為50HZ,可用于表征人體日常活動頻率。為降低特征提取維度實現輕量級活動識別,選取單軸加速度數據進行活動識別,為有效識別靜態活動(躺、坐、站),繪制靜態活動三軸加速度數據。由圖2 可以看出,對于不同靜態活動類型的三軸加速度數據,z 軸的加速度數據更具區分度,因此選取z 軸加速度數據進行活動識別。將數據集采用1.5s 的滑動窗口大小進行分割,窗口重合率為50%,其中數據集的70%用作分類器訓練,30%用作分類器測試。
1.3 加速度數據相空間重構
對于時間序列的分析和建模一般從統計學角度出發,這種方法的前提是自然界中隨機性占主導地位。隨著非線性系統理論的發展,產生了一種關于時間序列的動態系統分析方法,該方法描述了一個系統的時間演化以捕獲系統動態。相位空間表示系統隨時間演化的所有可能狀態,通過對序列的相空間重構可以從時間序列的觀測值中捕捉到系統的底層動態。相位空間重構法不僅可以重構動態系統的非線性動態方程,而且可以將時間序列的特征與該序列系統的內在機理聯系起來,從系統內部動力學系統中尋找時間序列的特征[22-23]。
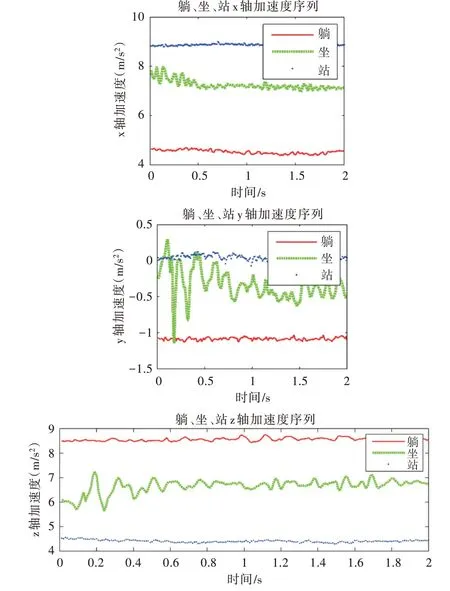
Fig.2 Acceleration data of lying down,sitting and standing(data set ADL)圖2 躺、坐、站(數據集ADL)加速度數據
相空間重構理論于1981 被提出,對于給定的時間序列x,有:

其中,n為下標索引,N為序列的長度。對該系統根據相空間重構理論進行延遲嵌入:
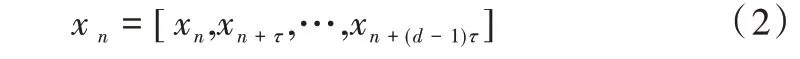
其中,τ為時間延遲,d為嵌入維數,通過時延嵌入重構系統的狀態與動態。Takens 定理證明,如果嵌入維數d≥2d'+1,d'為系統動力學維數,則重構的動力系統與原動力系統在拓撲意義上等價。
1.3.1 嵌入維數d與時間延遲τ
對于嵌入維數d與時間延遲τ的選取,主要分為兩種觀點:一種是兩個參數選取互不相關,如求取時間延遲的自相關法,求取嵌入維數的FNN(Flase Nearest Neighbors)法等;另一種認為兩個參數相關,如c-c法等。本文采用第一種方法,使用自相關法求取時間延遲,使用虛假最近鄰法求取嵌入維數。
(1)自相關系數法。自相關系數法的原理是提取序列之間的線性相關性,對于混沌序列x(1),x(2),…,x(n),其相關函數為:
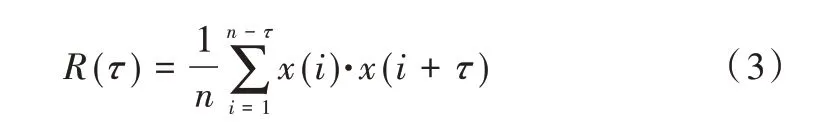
當自相關函數下降到初始值R(0) 的1-e-1時,即R(τ)=(1-e-1)R(0),所得到的時間τ為重構相空間的延遲時間。
(2)虛假最近鄰法。混沌時間序列是高維相空間混沌運動的軌跡在一維空間的投影,當高維相空間被投影后,原本不相鄰的兩個點在一維空間有可能變為相鄰的兩個點,也稱作虛假鄰點。當嵌入維數逐漸增大,混沌運動的軌跡會被打開,虛假鄰點被逐漸剔除,從而整個混沌運動軌跡得到恢復。在d維相空間中,對于每一個矢量:

都有一個歐幾里得距離的最鄰近點xk(d),(k≠i,1 ≤k≤n-(d-1)τ),二者的距離是:

當相空間維數增加,二者的距離變為Di(d+1)。
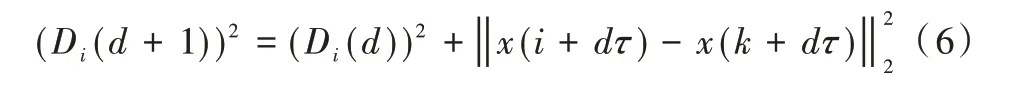
當Di(d+1)比Di(d)大很多時,認為xk(d)是xi(d)的虛假最近鄰點。對于實際的混沌時間序列,當嵌入維數從2逐漸增加,計算虛假最近鄰點的比例,當虛假最近鄰點的比例小于5%或者不再隨著嵌入維數d的增加而減少時,認為此時的d為最佳嵌入維數。
1.3.2 Z 軸加速度數據相空間重構
將活動數據集ADL 與活動數據集UCI 的Z 軸加速度數據進行相空間重構,使用自相關系數法進行時延估算。圖3 表示各動態活動(除去躺、坐、站3 類靜態活動)時延的統計,取各活動時延統計的平均值3 作為時間延遲。
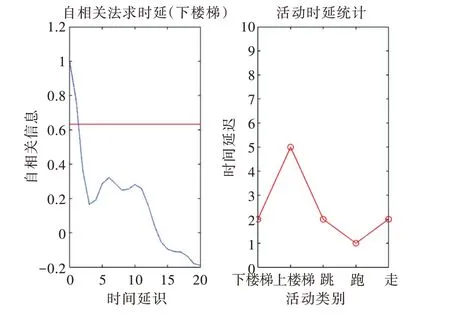
Fig.3 Time delay calculated by autocorrelation coefficient method圖3 自相關系數法計算時間延遲
將時延3 作為各類活動的時間延遲,使用虛假最近鄰法計算各活動的嵌入維數,圖4 表示5 類活動(除去躺、坐、站3 類靜態活動)嵌入維數的計算結果,綜合結果取各類活動嵌入維數的平均值為6。
對分割后的Z 軸加速度數據進行相空間重構可得特征矩陣F60×6,為降低特征矩陣維度,取特征矩陣行向量的均值作為特征向量F'60x1。

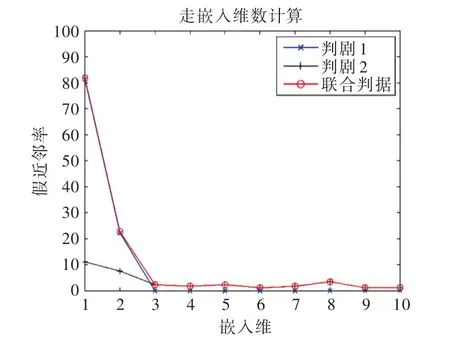
Fig.4 Calculation of embedded dimension by false nearest neighbor method圖4 虛假最近鄰法計算嵌入維數
1.4 特征矩陣降維
為降低特征向量的維度與強化特征向量的分類性能,本文采用核Fisher 判決分析進行特征向量降維,核Fisher判別分析法通過非線性映射,將原始輸入數據映射到高維空間中,在高維特征空間進行線性Fisher 判別分析,實現相對于輸入空間的非線性判決分析[24-25]。高位特征空間解決的問題為:
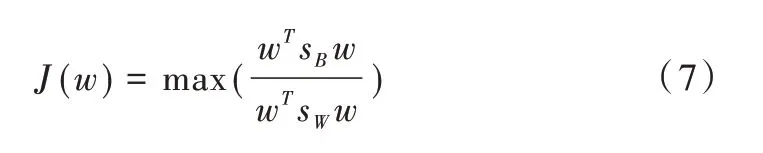
由于高維特征空間維度較高而無法直接求解問題,故高維特征空間引入核函數RBF 求解問題。
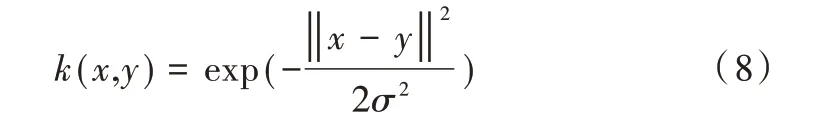
求取原特征數據在最佳投影方向上的投影為降維后的特征向量。
1.5 XGBoost 分類器
1.5.1 CART 分類樹
CART 分類器是一種廣泛流行的決策樹模型,它通常被用作梯度增強樹的基分類器。CART 分類樹算法使用基尼系數選擇最優特征,同時決定該特征的最優切分點。
假設樣本空間D,其中xi代表第i個樣本的特征向量,yi代表第i個樣本類別。

其中,xi=(xi1,xi2,…,xim),xij代表第i個樣本的第j個特征。
一棵回歸樹可將樣本空間劃分為K 個空間,每個空間對應一個輸出值ck,因此回歸樹模型可以表示為:
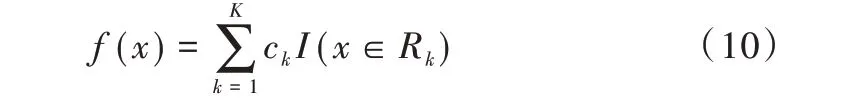
當x∈Rk時,I(x∈Rk)=1,反之I(x∈Rk)=0。
當選擇特征j作為分割變量,分割點為s,則分割后兩部分表示為:

為了尋找j與s,需要滿足式(4)的要求:
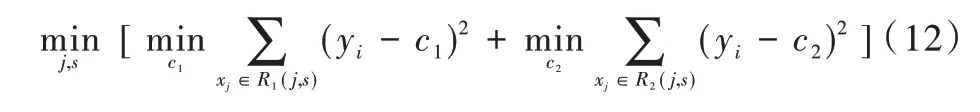
其中,c1為空間R1的樣本輸出均值,c2為空間R2的樣本輸出均值。
遍歷樣本所有輸入變量,找到最優的分割變量j,根據變量(j,s)將輸入空間分成兩個區域,然后對每個區域重復分割過程,直到滿足停止條件。
1.5.2 XGBoost 原理
基于決策樹的增強方法稱為增強樹,XGBoost 模型是一種有效的CART 樹模型增強方法[26]。對于給定的數據集D,增強樹模型使用k個樹模型函數之和預測輸出。
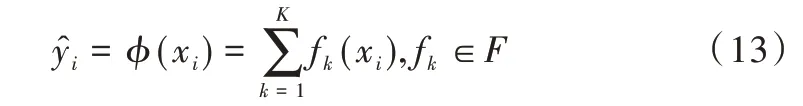
其中,F={f(x)=wq(x)}(q:Rm→T,w∈RT)代表回歸樹空間;q代表將樣本映射到相應葉索引的每棵樹的結構;T是樹上葉子的數量;每一個fk對應一個獨立的樹結構q(x)與葉權重w。與決策樹不同,每個回歸樹在每個葉子上都包含一個連續的分數,用wi表示第i個葉子上的分數。
傳統增強樹模型學習目標函數為obj。

obj的前半部分為衡量預測值與標簽值yi之間誤差的可微分凸損失函數l,后半部分為衡量模型復雜性函數Ω。正則化項有助于平滑最終學習權重,以避免過度擬合。Xgboost 算法的目標是比RGF 算法更簡單,更易于并行化。
Xgboost 算法使用加法訓練方法更新預測函數,更新判決條件為優化目標函數的程度。如式(7)所示,初始化預測初值為,預測函數更新過程為:
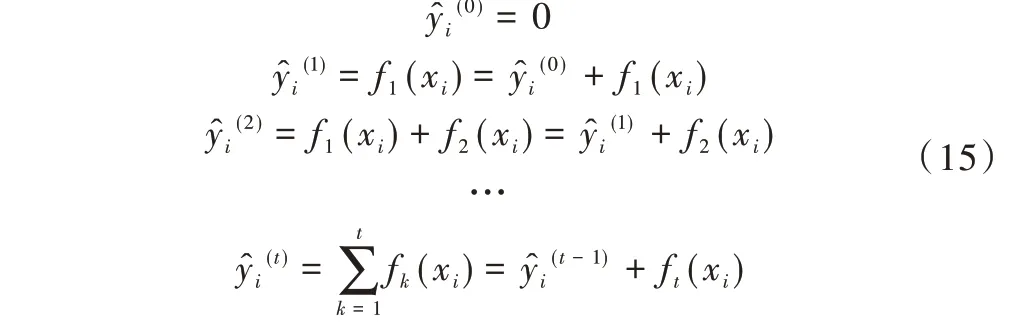
定義第t輪的預測函數為,其目標函數為obj(t)。
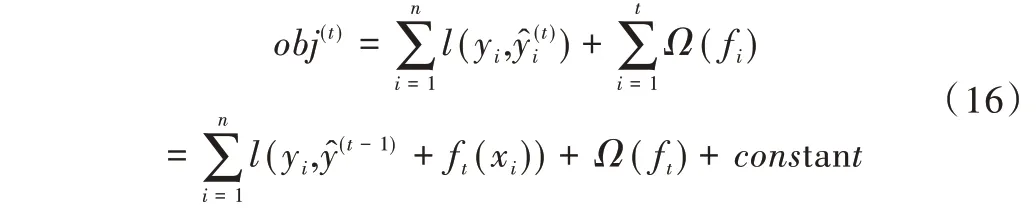
當損失函數為平方損失函數時,有:

對目標函數進行泰勒級數展開可得:
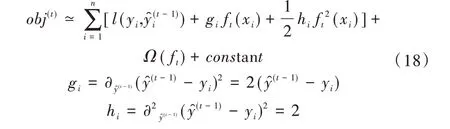
去除常數項,目標函數為:
使用葉子的分數向量定義樹函數,通過葉中的分數向量定義樹,并使用葉索引映射函數將實例映射到葉。
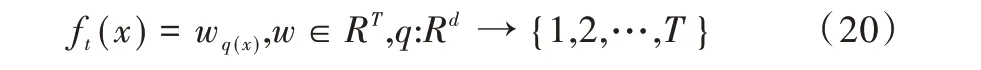
定義復雜性衡量函數為:

其中,函數前半部分代表葉子個數,后半部分代表葉子分數的L2 正則化。
定義葉子節點j中的樣本集為Ij={i|q(xi)=j},將樹函數與復雜性衡量函數代入目標函數中得:
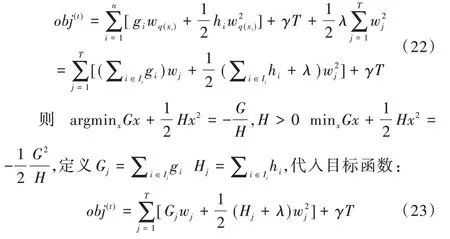
假設樹的結構固定,則每個葉子的最優權值與目標函數obj為:
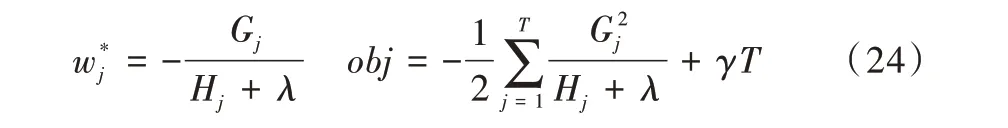
為得到最優樹的結構,將樹的葉子分裂后的增益函數定義為:
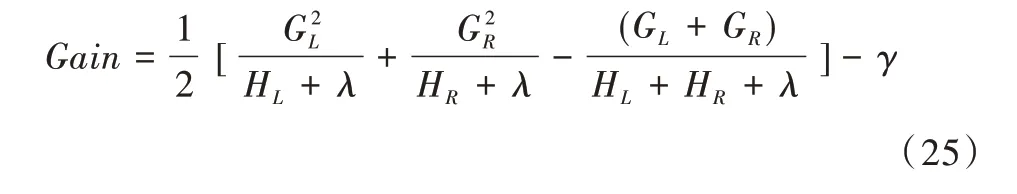
當得到負增益或者得到最大樹的深度,則停止分裂葉子。
Xgboost 算法可防止過擬合、支持并行化并提升分類器訓練速度,適合輕量級活動識別算法,極大提升了分類器的有效性與分類速度。
2 實驗結果及分析
2.1 實驗設置
實驗中分別將ADL 數據集與UCI 活動識別數據集劃分為70%的訓練數據集和30%的測試數據集,基于兩類數據集進行以下實驗以驗證算法有效性:①將所有實驗者活動數據混合,并劃分為訓練數據集與測試數據集以驗證算法有效性;②剔除一位實驗者活動數據,將其作為測試數據集,其余實驗者活動數據為訓練數據集以驗證算法有效性;③比較不同分類器算法的性能與本文Xgboost算法作比較。
2.2 評價指標
本文采用下列指標進行評估,正確率為分類正確的樣本數占樣本總數的比例,查準率P 為TP/(TP+FP),查全率R為TP/(TP+FN)。F1 度量為2 *P *R/(P+R)。
Table 1 Classification result confusion matrix表1 分類結果混淆矩陣
2.3 結果及分析
2.3.1 實驗者數據混合驗證
將ADL 活動數據集與UCI 活動識別數據集所有實驗者的活動采集數據進行訓練數據集與測試數據集劃分,根據混淆矩陣以及正確率、查準率、查全率和F1 值驗證算法有效性。
表2 體現了ADL 活動數據集在實驗者活動數據混合情況下訓練分類器的測試性能,相空間重構特征提取算法在ADL 活動數據集的測試數據集上得到了94.96%的正確率。其中,下樓梯、上樓梯、躺、行走4 類活動能夠很好地被識別,F1 值分別為1.00、0.99、1.00、0.99,并且從圖5 的混淆矩陣可以看出該4 類活動的正確率為100%、98%、100%、100%。從混淆矩陣中可以看出,跑與跳兩類活動的識別結果最差,分別為88%與85%,其中跳與跑易相互混淆,分析其原因為在相空間重構后,由于相空間重構提取特征后仍為原始時間序列數據,而其跳與跑在原始時間序列數據幅值范圍十分相似,固其二者容易混淆。
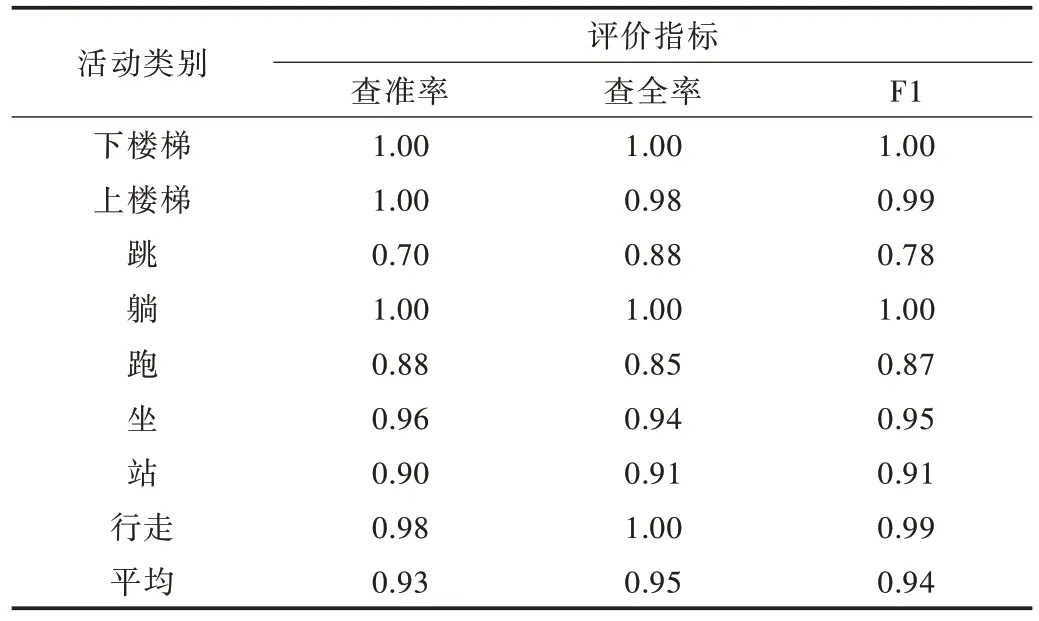
Table 2 ADL dataset mixed recognition results of experimenter activity data表2 ADL 數據集實驗者活動數據混合識別結果
表3 體現了UCI 活動數據集在實驗者活動數據混合情況下訓練分類器后的測試性能,相空間重構特征提取算法在UCI 活動數據集的測試數據集上得到了92.66%的正確率。同樣對于下樓梯、上樓梯、躺、行走4 類識別結果較好,其F1 值分別為0.98、0.98、0.92、1.00,正確率分別為96%、100%、95%、100%。同時,從混淆矩陣可以看出,坐與站兩類活動識別結果較差,僅有84%與82%的正確率,且二者容易相互混淆。
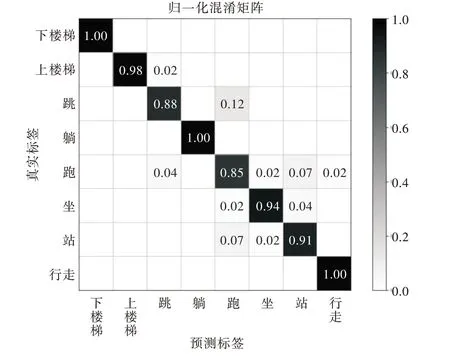
Fig.5 Confounding matrix of mixed identification of active data of ADL active dataset圖5 ADL 活動數據集實驗者活動數據混合識別混淆矩陣

Table 3 UCI activity dataset experimenter activity data mixed identificution results表3 UCI 活動數據集實驗者活動數據混合識別結果
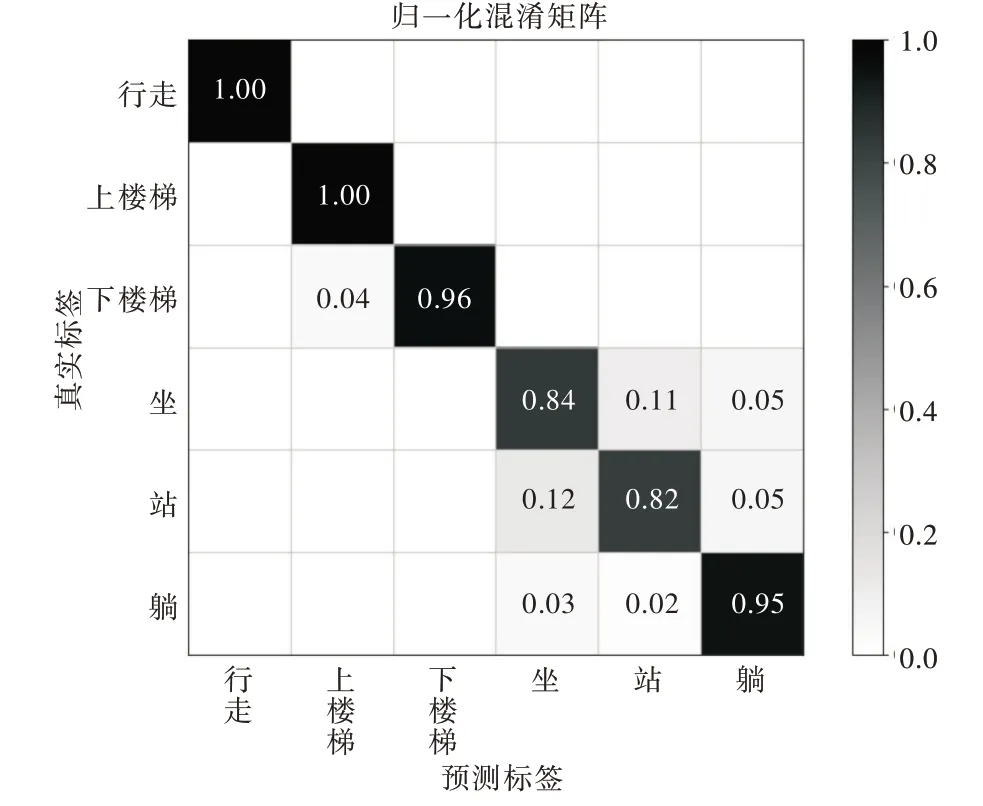
Fig.6 Confounding matrix of mixed identification of active data of UCI active dataset experimenter圖6 UCI 活動數據集實驗者活動數據混合識別混淆矩陣
2.3.2 實驗者數據獨立驗證
為驗證算法泛化能力,將ADL 活動數據集與UCI 活動數據集中的一位實驗者采集的活動數據提取出作為測試數據,其余實驗者采集數據作為訓練數據,根據混淆矩陣以及正確率、查準率、查全率和F1 值驗證算法泛化能力。
表4 體現了ADL 活動數據集實驗者數據獨立下本文算法的識別性能,可以看出在測試數據不參與訓練分類器情況下,在ADL 活動數據集仍能達到平均查準率、查全率、F1值的3 個性能指標為0.92、0.91、0.91,下樓梯、上樓梯、躺、跑、行走幾類活動仍可達到90%以上的正確率,并且整體可達到91.16%的正確率。表5 體現了UCI 活動數據集獨立實驗者數據的識別結果,可看出下樓梯、上樓梯、行走3 類活動的查準率、查全率、F1 值3 個指標接近1.00,且從其混淆矩陣中可以看出3 類活動具有100%的正確率,總體正確率達93.08%。

Table 4 ADL dataset independent recognition results of experimenter data表4 ADL 數據集實驗者數據獨立識別結果
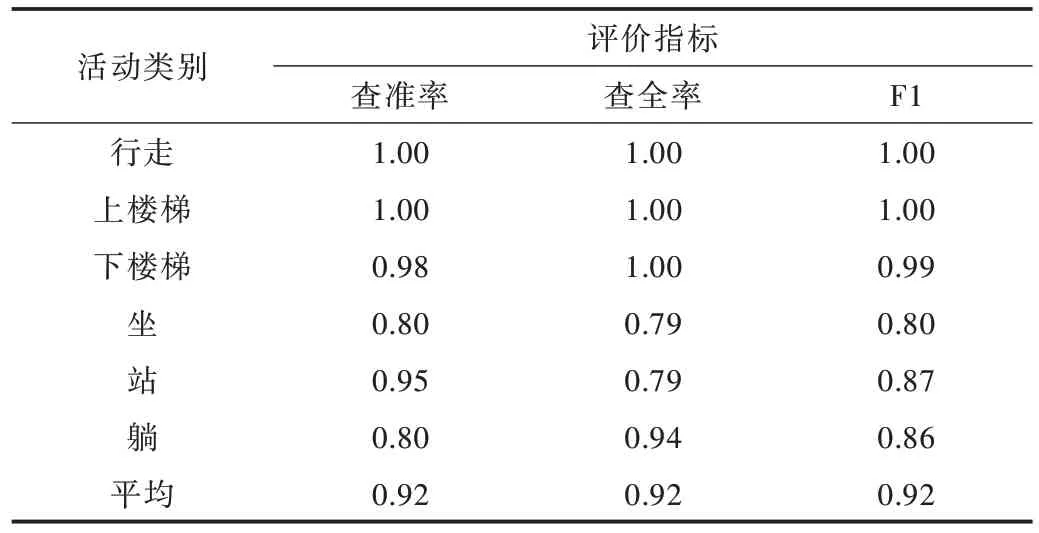
Table 5 UCL activity dataset independent recognition results of experimenter data表5 UCI 活動數據集實驗者數據獨立識別結果
2.3.3 分類算法比較
對常用分類算法在相同特征集下的性能進行比較,選擇常用分類算法KNN、SVM、BP 神經網絡與本文算法Xg?boost 進行分類性能比較如表6 所示。其中,KNN、SVM、BP神經網絡正確率達90%、90%、81%,F1 值達0.89、0.91、0.75,而本文使用算法Xgboost 達到了94%的正確率,F1 值為0.94,性能優于上述3 種分類算法。Xgboost 作為傳統分類樹算法的增強算法,分類性能優于傳統分類算法,適合用于具有相似特征的活動識別任務。
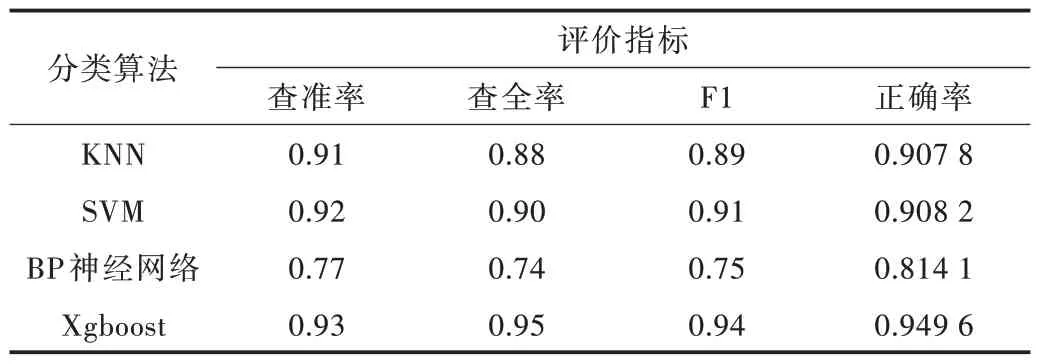
Table 6 Comparison of classification algorithms表6 分類算法比較
3 結語
本文提出了一種基于可穿戴傳感器的輕量級活動識別算法,該算法由相空間重構特征提取和核Fisher 判別分析特征降維方法以及Xgboost 識別器組成,分別用于HCI HAR 和ADL 公開活動數據集。該活動識別算法由運動信號采集、信號預處理、相空間重構特征提取、核Fisher 判別分析特征降維和Xgboost 識別器組成,從放置于腰部的單加速度計傳感器提取相空間重構后的共60 維時域特征用于人物日常活動識別。此外,通過核Fisher 判別分析特征降維方法將60 維特征進一步縮減,以減少計算成本并提高日常活動識別準確率。通過對UCI HAR 和ADL 公開活動數據集的6 類和8 類日常活動數據進行驗證,可以分別獲得93%和94%的整體識別率。基于上述實驗結果,本文提出的基于相空間重構的輕量級活動識別算法的有效性與魯棒性得到了驗證。接下來的研究將擴展到更多種類的活動識別以及進一步提升整體系統識別精度上。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
少先隊活動(2021年1期)2021-03-29 05:26:36
快樂語文(2020年30期)2021-01-14 01:05:38
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
海峽姐妹(2018年3期)2018-05-09 08:20:40
