Scrapy 框架下區域人口數據爬蟲的設計與實現
2021-11-28 11:56:16姚新強
軟件導刊 2021年11期
關鍵詞:數據庫
李 通,姚新強
(1.防災科技學院 應急管理學院,河北 廊坊 065201;2.天津市地震局 震害防御中心,天津 300201)
0 引言
我國地處世界兩大地震帶——歐亞地震帶和環太平洋地震帶包圍之中,地震災害頻發。據統計,自1900 年以來,在中國爆發的7 級以上地震約占全球的35%,地震已成為我國自然災害的群災之首[1-2]。作為地震災害的主要承災體的人,因不同區域人口數量不同、不同區域人口分布情況不同,會產生不同的人口傷亡情況。因此,高精度的區域人口數據是制定區域防震減災政策的一項重要參考內容,能為震后人員傷亡數量的快速評估提供重要的科學依據[3]。城市人口規模研究較多,如婁格等[4]結合“珞珈一號”夜光數據與土地利用數據,采用多元逐步回歸模型有效實現了指定區域的常住人口估算及分布模擬;鈕心毅等[5]使用多源移動定位大數據估算結果的交叉檢驗方法對城市常住人口規模進行檢測。以上研究雖然可以獲得城市的常住人口規模,但卻無法將人口數據具體到街道或者社區級別。
目前,通過搜索引擎可以查詢到指定街道或社區的人口數據,但缺點是數據較為分散,不利于快速統一的分析。本文重點研究了如何利用Scrapy 框架設計并實現爬蟲,對指定區域人口數據進行高效、準確、完整的爬取。
1 技術介紹
1.1 Python 爬蟲及Scrapy框架
伴隨著互聯網技術的飛速發展,大數據時代已經來到。據統計,到2020 年,全世界每人每天將產生140GB 左右的數據[6]。為剔除無用數據,保存有價值的信息,網絡爬蟲應運而生。網絡爬蟲是一種按照人們定義的規則,自動抓取網址上的文字、圖片、音頻等頁面內容或者腳本的程序。目前有許多使用爬蟲案例,如百度搜索引擎,利用爬蟲技術從海量網站爬取不同信息,通過大數據分析及整理用于用戶檢索;一些搶票軟件使用爬蟲技術,通過設置爬蟲程序不斷刷新12306 網站的余票數量來發現剩余車票信息[7-8]。Scrapy 框架是基于Python 語言編寫的用來爬取網站結構性數據內容的應用框架,可用于數據挖掘、數據監測、自動化測試等。使用Twisted 異步網絡框架來處理網絡通訊,加快了爬取數據的速度,不用異步框架及各種中間件接口就可靈活完成各種需求,具有結構簡單、便于理解、高效迅速的特點[9-10]。因此,本文選擇Scrapy 框架實現地理人口數據的爬取。
Scrapy 框架由5 個部分組成[11]:
(1)Scrapy Engine(Scrapy 引擎)。主要負責其他4 個部分的中間通訊、數據傳遞等。
(2)Scheduler(調度器)。負責接受引擎發送過來的Request 請求,并按照一定的方式進行整理排列、入隊,當引擎需要時交還給引擎。
(3)Downloader(下載器)。負責下載Scrapy Engine 發送的所有Requests 請求,并將其獲取到的Responses 交還給Scrapy Engine,由引擎交給Spider 來處理。
(4)Spider(爬蟲)。負責處理所有Responses,從中分析提取數據,獲取Item 字段需要的數據,并將需要跟進的URL 提交給引擎,再次進入Scheduler。
(5)Item Pipeline(實體管道)。負責處理Spider 中獲取到的Item,并進行后期分析、過濾、存儲處理等。
Scrapy 架構及數據流向如圖1 所示。
1.2 XPath
XPath 即XML 路徑語言(XML Path Language),最初是用來搜尋XML 文檔用的,但也適用于HTML 文檔搜索。XPath 功能十分強大,可用于字符串、數值、時間的匹配以及節點、序列的處理等,并且提供超過100 多個內建函數,涵蓋了平時搜尋指定文檔的常用方法,使用起來方便快捷。由于要爬取的網站采用HTML 代碼編寫,所以在爬取結構性數據時選擇XPath 方法進行定位和選擇[12]。
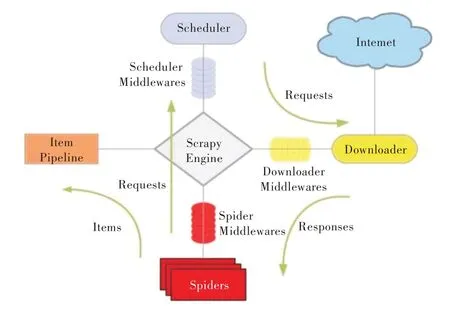
Fig.1 Scrapy architecture diagrams and data flow圖1 Scrapy 架構及數據流向
1.3 正則表達式
正則表達式即Regular Expression,給計算機操作和檢驗抽取字符串數據提供了一種工具,通過普通字符、元字符和限定符構成一組文字模式對字符串進行匹配、檢索、替換等,幾乎在所有語言中都能使用[13]。本文通過分析目標網址中要爬取的數據可知,在對北京市最小一級的人口分布區域——社區的爬取過程中,需要使用正則表達式來查找社區的具體人數。
2 爬蟲過程設計
2.1 網頁結構分析
本文將目標網址(http://www.tcmap.com.cn/beijing/)數據分為三層,分別為北京市區人口數據、區下面不同街道的人口數據、街道下面不同社區的人口數據,呈現出一種典型的樹狀結構分布。北京市區人口數據在目標網址的第一層頁面上呈現出有規律的分布,如圖2 圓形框標注區域所示;第二層頁面中的各個區下面不同街道的人口數據在列表中呈現出有規律的分布,如圖3 圓形框標注區域所示,這兩項人口數據均可通過XPath 的方式獲得。第三層頁面中各個街道下面不同社區的人口數據則是隱藏在社區介紹的字符串中,需要使用正則表達式方法檢索其中的人口數據,如圖4 圓形框標注區域所示。
經初步分析網頁機構可知,部分社區介紹中帶有具體的社區人數,部分社區介紹則僅僅提供了戶數,對于僅提供戶數的社區,爬蟲程序需要將提取的戶數乘以3.5 作為該社區的人數。同時,目標網址需要進行多級頁面跳轉,涉及多層URL 數據,因此需要對跳轉的URL 進行保存[14]。
2.2 網頁爬取流程
網絡爬蟲在爬取網頁時遵循爬取策略規則[15]:
(1)寬度優先搜索策略。在HTML 文檔中,將獲取的給定起始鏈接所有子節點放入待抓取URL 隊尾,對子鏈接繼續獲取其所有子節點,以達到最大寬度的搜索效果。
(2)深度優先搜索策略。在HTML 文檔中,以搜尋到葉節點為目標,即順著給定的起始鏈接一直搜尋到不能再繼續向下搜尋為止,然后再返回到上一層節點繼續向下搜尋。
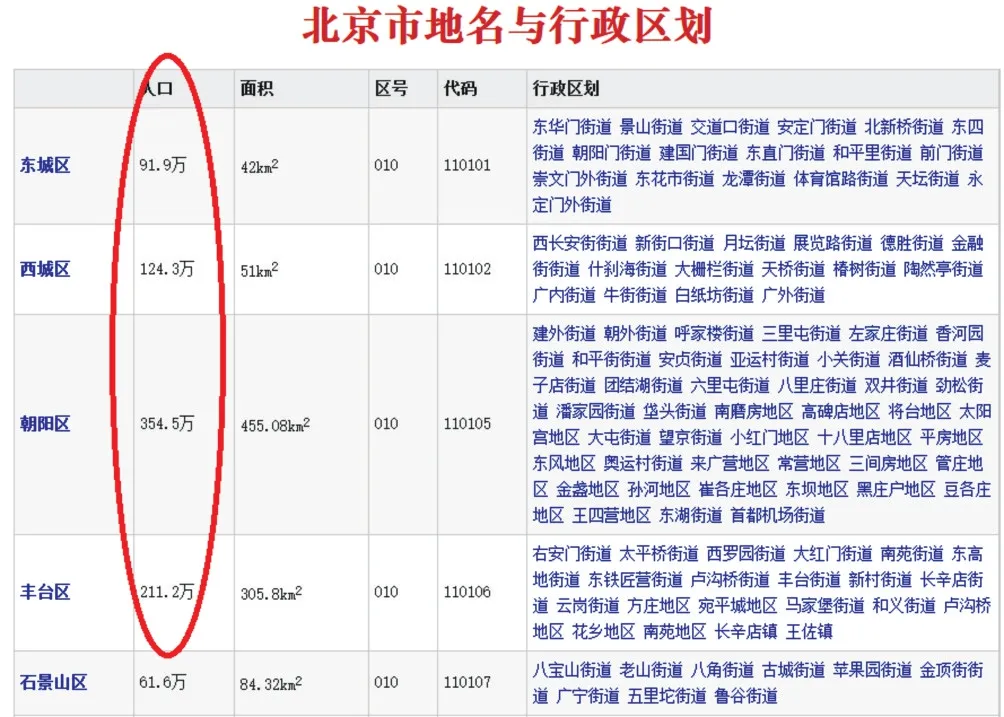
Fig.2 Population data of Beijing urban district圖2 北京市區人口數據

Fig.3 Demographic data of Donghuamen Subdistrict,Dongcheng District,Beijing圖3 北京市東城區東華門街道人口數據

Fig.4 Demographic data of Duofu Lane Community,Donghuamen Street,Dongcheng District,Beijing圖4 北京市東城區東華門街道多福巷社區人口數據
(3)IP 地址搜索策略。給定爬蟲程序一個起始的IP 地址,以遞增的方式搜尋IP 地址段后每一個地址中的文檔,完全不考慮文檔中指向其他Web 站點的文檔鏈接。
(4)大站優先搜索策略。爬蟲程序通過分析待抓取列表中URL 的域名類別進行分類統計,按照數量的大小順序進行抓取。
本文通過分析目標網址上人口數據呈樹狀結構分布的情況,選擇深度優先策略,具體的網頁爬取流程分為以下步驟[16-17]:①在Spiders 中通過繼承scrapy.Spider中的start_requests 函數,由初始URL 地址生成Request 請求發送到Scrapy Engine;②Engine 將Request 不作任何處理發送到Scheduler 中并按照一定方式排列入隊;③Scheduler 將生成的Request 請求交還給Scrapy Engine,并由Scrapy Engine 交由Downloader 進行下載并返回給Scrapy Engine 對應的Re?sponse數據;④Scrapy Engine 將Response 數據交由Spider,根據設定的解析方法爬取人口數據Item,同時將要跳轉的URL 網址以Request 方式生成;⑤將Item 及Request交由Scrapy Engine,分別發送至Item Pipeline 和Scheduler 進行持久性存儲和入隊處理;⑥當Scheduler 中不存在任何Re?quest 后爬蟲程序停止運行。
爬取流程如圖5 所示。
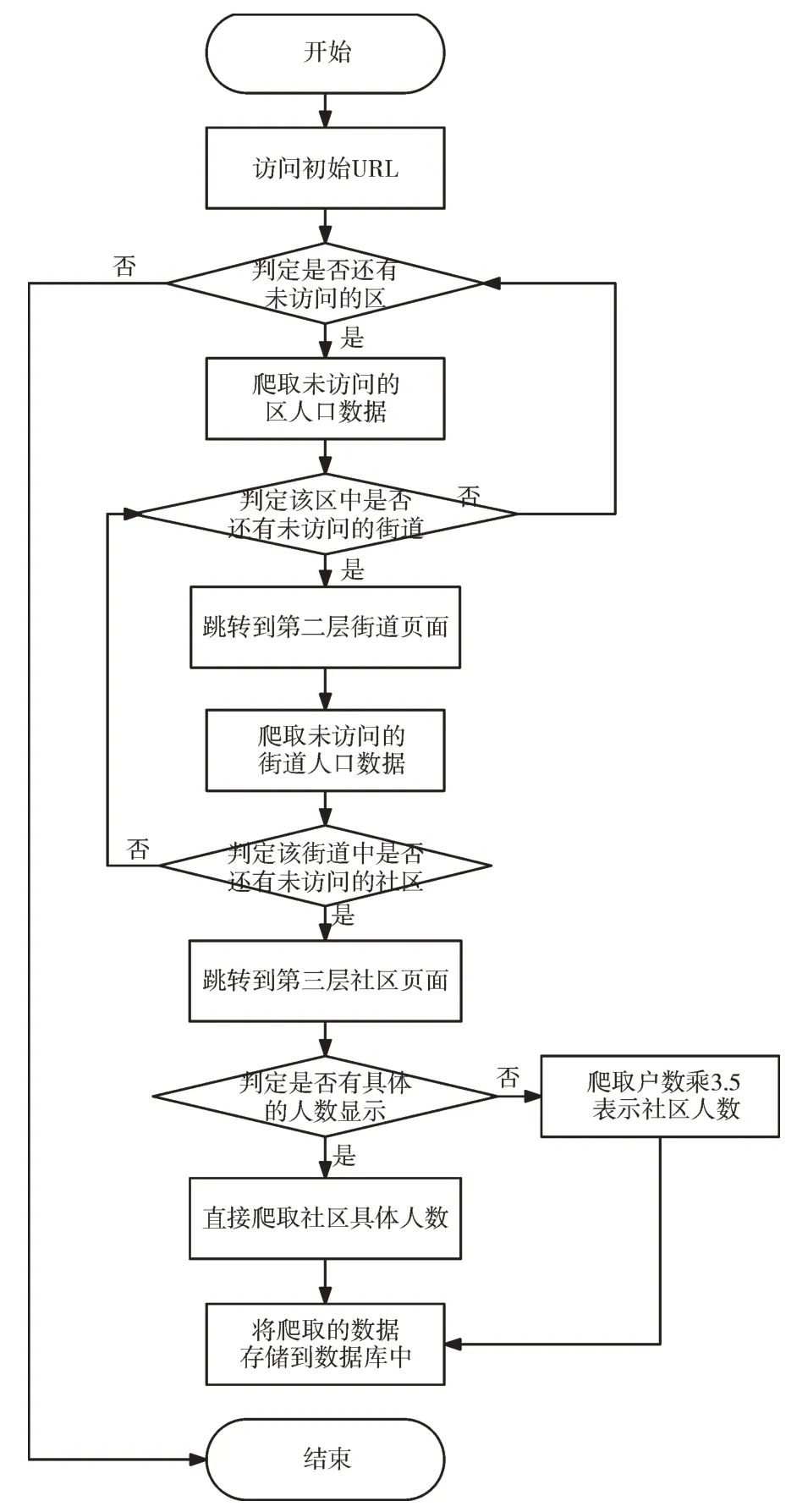
Fig.5 Flowchart of web crawling圖5 網頁爬取流程
2.3 反爬蟲機制應對措施
網絡爬蟲在爬取過程中會在短時間內向目標網址發出大量的網絡請求,占用網絡帶寬,使其他用戶訪問該網站時變得卡頓,甚至可能造成服務器崩潰。因此,許多網址都采取了反爬蟲機制,例如分析用戶請求的IP 地址在短時間內訪問的頻率、識別請求中所攜帶的User-Agent 信息及網站流量統計和日志分析等,以此判別是爬蟲訪問還是人為訪問[18-19]。為防止爬取數據時被反爬蟲限制,可以采取以下幾個方法:
(1)修改User-Agent 字段,將其偽裝成正規的瀏覽器發出的請求,防止服務器分辨出爬蟲程序。
(2)設置代理IP。若大量且快速訪問同一個域名下的網頁,會被網站識別為爬蟲程序,因此需要通過設置代理IP 或者代理服務器的方式來解除網站對于訪問頻率較高的主機限制。
(3)降低抓取速度。一個IP 地址在1s 的時間內訪問許多次,很容易被網站識別為爬蟲程序,可通過import time 引入時間模塊,設置間隔時間為2s,即在代碼中設置time.sleep(2)或在settings.py 文件中設置DOWNLOAD_DELAY=2 來降低爬取速度。
(4)禁用Cookies。有的網站為了識別用戶身份或進行session 跟蹤,在用戶終端上保存了Cookies 信息,因此可以在settings.py 文件中設置COOKIES_ENABLES=False。
3 爬蟲過程實現
3.1 Item 數據定義
在Scrapy 框架中,Item Pipeline 負責爬蟲數據的分析、過濾、存儲處理,由于本文爬取的數據是樹形結構,因此分別設置DistrictItems、StreetItems、CommunityItems 三個Item文件來保存區人口數據、街道人口數據、社區人口數據。
3.2 網頁爬取
對北京市區和街道的人口數據爬取時,根據網頁結構分析可以發現兩個網址上人口數據呈現有規律的分布,通過XPath 中following-sibling::*方法依次獲取北京市16 個區人口數據和每個區分布的所有街道的tr 標簽,提取其中的區或街道名稱以及對應的人口數據分別存入相應的Item中,并通過yield 迭代器分別回調streetparse 函數和commu?nityparse 函數[20]。部分代碼如下:


在爬取社區人口數據時,由于目標網址沒有在網頁的表格中給出人口數據,而是將其放在社區簡介的文字中,因此需要通過正則表達式來篩選匹配相應的人口數據。通過搜尋字符串中第一個以“人”為結尾的數據,若不存在,則搜尋第一個以“戶”為結尾的數據,并將得到的數據乘3.5 作為社區人口數據。部分代碼如下:

3.3 數據存儲
3.3.1 爬蟲程序測試
在Terminal 上通過scrapy crawl MySpider 指令可以運行當前代碼查看是否存在錯誤。由于Scrapy 框架采用的是Twisted 異步編程模型,所以運行結果與目標網址上的順序不一致[21]。部分運行結果如圖6 所示。
3.3.2 MySQL 數據庫存儲
在成功獲取想要爬取的人口數據后,需要對得到的數據進行持久化存儲。由于JSON 數據可讀性較差,因此本文沒有選擇將數據寫入到JSON 文件中,而是選擇存入MySQL 數據庫[22]。首先根據在Item 中定義的數據模型在數據庫中建立scrapydemodata 表,并在pipeline.py 文件中引入Python 第三方模塊pymysql,通過調用pymysql 的connect方法傳入數據庫主機名、用戶名、登陸密碼等信息獲得數據庫連接對象。在成功連接數據庫后定義process_item 方法,使用SQL 語句將爬取到的人口數據存入數據庫中,數據庫存儲的人口數據信息如圖7 所示。
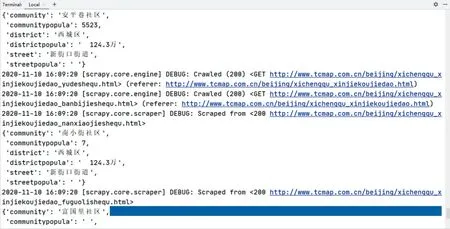
Fig.6 Operation results of the crawler圖6 爬蟲程序運行結果

Fig.7 Part of the population data in the database圖7 數據庫中部分人口數據信息
4 結語
本文設計了基于Scrapy 框架的區域人口數據爬蟲程序,實現對指定網址的人口數據爬取,以獲得市區、街道和社區三級人口數據,并通過數據庫將所得數據存入MySQL數據庫中,方便地震研究人員對數據進行查詢、統計和分析,以便估算出特定區域的人口傷亡數,為震后人員傷亡評估提供重要的科學依據。隨著爬蟲與反爬蟲技術的不斷升級,程序還有許多需要優化的環節,如網頁頁面結構更新,在數據篩選過程中解析模塊就需要重新寫入,在開發時可以擴展做成通用性爬蟲;在某些添加了滑塊驗證碼反爬蟲機制的網站上還需要對破解驗證碼進行深入研究。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
