類GAN 算法的腦部核磁共振圖像增強技術研究
2021-11-28 11:56:26李梓鷗費樹岷
軟件導刊 2021年11期
關鍵詞:模型
李梓鷗,費樹岷
(東南大學 自動化學院,江蘇 南京 210096)
0 引言
傳統的自動化技術逐漸被機器學習與深度學習等方法取代,智能檢測方法在醫學領域發揮著越來越重要的作用,在傳統的醫學影像技術中應用計算機圖像處理技術具有重大的實際意義。計算機圖像處理技術不僅能夠有效提高醫學影像的處理效率,還能夠保證醫學影像的清晰度與準確度,從而提高醫學診斷準確度,最終大大提高了現代醫療水平[1]。
然而,在利用機器學習方法與深度學習方法對傳統醫學核磁共振圖像(Magnetic Resonance Images,MRI)進行檢測與分割時,由于采樣難度大、成本高,病態樣本數量的多樣性稀缺以及病人的隱私問題而導致樣本數量不足,樣本質量不高嚴重限制了機器學習與深度學習方法應用[2-3]。因此,有效擴充數據集是支撐計算機輔助分析方法的重要基礎。
傳統的擴充方法是對圖像的基本集合變換,如水平翻轉、豎直翻轉、隨機旋轉角度、隨機水平平移、隨機豎直平移、隨機錯切變換、隨機放大、顏色變換、亮度變換、對比度變換等一系列圖像處理方法[4]。單純使用基本變換方法增加了樣本數量,但這樣指定特征的擴充方法是有限的,并且未從本質上改變圖像,僅保留了處理前的特征與所有組合。除了對圖像進行基本變換外,SMOTE 方法也是擴充數據集的一種直接方式。盡管SMOTE 方法可以擴展出與原數據集中元素不相似的圖像,但在圖像擴充問題質量上卻很難通過視覺圖靈測試。
近年來,隨著深度學習的不斷發展,通過深度神經網絡模型生成的圖像樣本應用在不斷增加[5-6]。2013 年,Die?derik 等[7]首次提出變分自動編碼器VAE 模型,采用KL 距離作為理論損失函數,利用對下界逼近的方式訓練模型。但是因為KL 散度在真實和生成分布間的不對稱性,以及訓練過程中是針對上界逼近,所以效果并不理想;2014 年,Ian 等[8]首次提出了生成對抗網絡(Generating Adversarial Networks,GAN),利用一個判別器D 作為生成器G 的損失判別函數,隱式地表示生成器G 的損失函數。但是等價的詹森香農距離(Jensen Shannon Divergence,JSD)損失函數本質上并不是連續可導函數,所以仍存在不穩定的訓練過程,即生成器G 的學習動力不足。GAN 模型廣泛應用于醫學圖像合成,主要為醫學圖像的擴充;2017 年,Zhang 等[9]設計了SCGAN,利用兩級的GAN 模型生成心臟MRI 的圖像,并將該圖像作為擴充數據集進行檢測;2018 年,Plassard等[10]利用DCGAN 生成了T1 權重下的腦部MRI圖像,并設計了去噪自動編碼器對原圖像去噪;Beers等[11]利用PGGAN對細胞瘤和視網膜圖像進行合成。近年來,基于大規模計算框架的GAN 模型[12]與醫學圖像翻譯(Translation)[13]逐漸成為熱點。
以上方法都是對原始GAN 模型的改進,依然保留著原始GAN 中的缺陷問題,同時也缺少對GAN 缺陷的理論分析以及改進措施。本文使用K-Lipschitz 約束GAN 及其變體[14-16],并將其與圖像處理中的深度卷積模型結合并加以改進,提出一種利用少量的腦部核磁共振圖像(MRI)進行圖像增強的方式,并從理論上分析了改進的穩定性數學原理及實際意義。同時,本文也分析了當前學術界較為流行的幾種指標,指出了腦部MRI 的合成過程中常規指標IS 的不合理性,并采用FID[17]作為衡量生成數據的質量與多樣性指標,對現有的FID 指標進行改進,以此替代一般的視覺圖靈測試方法。實驗結果表明,使用含有K-Lipschitz 條件約束的GAN 模型使判別器對輸入的梯度數量級較為合理,穩定性明顯強于使用JSD 作為損失函數的GAN 模型,同時在質量和生成多樣性上也有顯著提升。
1 腦部核磁共振圖像數據集
1.1 腦部核磁共振圖像成像原理
核磁共振圖像是通過原子核在磁場內產生信號,并經過重構成像的一種醫學影像技術。核磁共振技術在醫學領域有著廣闊的應用場景,可在不進行物理解剖的條件下無損地重構出身體器官的圖像信息。核磁共振成像技術在病理分析、醫學診斷等各個醫學領域都有應用。
大腦是一個結構復雜且功能強大的器官,核磁共振圖像因其在橫截面成像方面性能優越,在腦部成像上應用最為廣泛[18]。一般對大腦掃描成像的MRI 分為橫斷面、矢狀面、冠狀面,分別對應三維空間中的3 個截面。對于一個現實中的大腦樣例,一次完整的核磁共振成像過程會在3 個截面上進行掃描,形成三組圖像,每組圖像包含了該截面與大腦相交的截面圖像。同時,核磁共振的成像機器可以選擇不同厚度和數量的切片,以滿足不同應用場景需求。除此以外,在釋放電磁波構建MRI 時,一般會采用加權的方式進行圖像處理,通過此過程對大腦中不同的結構進行劃分,這些加權方式包括T1、T2、Flair、DWI 等。
1.2 核磁共振圖像預處理
本文主要使用兩個數據集:①以自閉癥內在大腦結構研究相關的ABIDE 數據集;②阿茲海默癥(AD)與輕度認知障礙(MCI)內在大腦結構研究相關的ADNI 數據集。一張核磁共振圖像一般由一個圖像序列{ }x|i=1,…l組成,其中,參數l為切片層數,在預處理過程中,本文在ABIDE 數據集以及ADNI 數據集中選取橫斷面掃描的圖像2D 切片作為生成對象,著重選擇靠近丘腦與海馬體的切片部分進行數據增強。最終,在ABIDE 數據集上選擇106 個樣本截取切片圖像,并將圖像重新映射至[-1,1]區間內。
值得注意的是,相比于學術界中較為流行的數據集,核磁共振圖像數據集具有樣本數量少、獲得難度較大、樣本之間大體特征相似但細節特征豐富而細微的特點。
2 數據增強算法模型
目前在醫學領域最新且應用最廣泛的數據增強方式是GAN 模型(包括深度卷積化的GAN 變體),然而傳統的GAN 模型具有許多固有缺點:對抗方式訓練過程具有不穩定性以及隨著GAN 中判別器D 的收斂,生成器G 的學習動力不足等問題,這些問題都會影響傳統GAN 生成樣本的質量。本文使用Wasserstein GAN 及其改進的變體替代傳統的GAN,對于訓練的不穩定性以及學習動力不足有很大改善。
2.1 傳統GAN 模型
2.1.1 深度卷積結構的GAN 模型
傳統的GAN 模型采用兩個子神經網絡作為GAN 的基本結構,分別是生成器G 與判別器D。在常規模式下,生成器G 與判別器D 使用一般的前向神經網絡進行建模。而本文對于生成器G 采用了深度解卷積層進行建模,對于判別器D 采用卷積層進行建模,以滿足模型生成圖像的要求。卷積與解卷積相比于一般全連接神經元建模方式有兩個特點,分別是部分連接與參數共享。部分連接指前一層的卷積層只有一個相鄰的子空間生成下一層的一個結點,參數共享指同一層產生不同位置的部分連接,享有共同的參數。部分連接所反映的思想是:對于一張圖像,其中幾個相鄰的像素點組合成的一幅子圖像就可以具有一定的特征屬性,不必如全連接型的神經網絡一樣將所有結點都與下一層相連。而參數共享所反映的思想是:對于同一層次的多個部分連接都采用相同的參數進行特征提取,這意味著同一層次不同位置上的卷積層都可以利用相同的特征提取器進行特征提取。部分連接與參數共享的優勢在于利用圖像局部相關的特性大大減少了參數的數量及模型的空間復雜度,同時加快了模型的訓練速度。GAN 網絡框架結構如圖1 所示,其中表示嵌入空間的隨機變量,表示真實樣本,表示生成樣本,表示標簽。

Fig.1 GAN network framework structure圖1 GAN 網絡框架結構
傳統GAN 充分利用了對抗思想,引入二分類判別器D來判斷生成器G 生成的樣本與真實樣本差別,其損失函數如下:

其中,生成器G 的輸入為隨機噪聲信號,輸出為與訓練圖像等尺寸的同類圖像,而判別器D 則使用了一般的二分類網絡,對真實圖像和生成圖像進行分類,使用神經網絡進行判別。將式(1)優化到最優后即得到JSD。
整個優化過程屬于min-max 優化,在不斷優化生成器G 與判別器D 的過程中使G 與D 呈對抗態勢。對于難以分開的復雜的兩類樣本,判別器D 的辨別能力在優化過程中不斷加強,同時生成器G 生成樣本的能力也越來越強,不斷給生成器輸送與正樣本(即訓練樣本)形態類似的正樣本,并且在生成器G 更新的過程中,其生成的樣本越來越復雜且難以分開,這些與訓練樣本形態相似的樣本被稱為對抗樣本,其優化公式如下:

2.1.2 GAN 模型訓練過程
如圖2 所示,GAN 的訓練過程包含對生成器G 與判別器D 的異步更新,圖2 簡要說明了當下GAN 訓練過程的基本框架,在不同K-Lipschitz 限制下,對于流程圖的各個環節均有一些修改。

Fig.2 GAN-like network training process structure圖2 類GAN 網絡訓練過程結構
其中,K 值表示每次更新生成器G 時判別器D 更新的次數。在訓練過程中,首先采樣隨機噪聲用于生成負樣本,采樣真實樣本;之后對判別器D 訓練K 次,將兩類樣本通過二分類器分割。在此過程中,分類器效果越好,生成器的學習動力越不足,后面將具體說明。在對判別器D 進行K 次更新后,再反向更新一次生成器G,反向更新在損失函數上表現為損失增大,即判別器D 不再能很好地區分生成樣本與真實樣本。當生成器G 收斂時,且判別器D 具有足夠的復雜程度,則判別器D 的分類邊界B在輸入上所反映的流形就是真實樣本在樣本空間中反映出的流形。所以本質上說,優化過程是生成分布Pg跟隨分類邊界B不斷逼近真實分布Pr的過程。
2.1.3 傳統GAN 模型限制
傳統GAN 在學術界存在兩個最大問題是梯度彌散以及模式坍塌,這兩個問題直接影響了傳統GAN 在訓練以及生成新樣本時的質量與多樣性。
梯度彌散問題主要指生成器G 在更新過程中,梯度計算必須經過判別器D 而導致的學習動力不足問題。傳統GAN 的訓練過程是先對判別器進行若干次優化,再對生成器G 進行優化。
定義1 定義緊致測度空間X及其上分布Pr與Pg,嵌入空間Z,二分類離散概率空間Y。映射Gθ:Z→X,映射Dw:X→Y。給定樣本集Strain={(x(i),y(i))}i=1,2…m,其中x(i) ∈X,y(i) ∈Y。Dw在樣本集Strain下的極 大似 然估計(MLE)為Dw_opt。
定理1 若Dw_opt對其輸入可導,且supp(Pr)?supp(Pg)=?,則?loss(Dw_opt()) →0。其中supp(Pr)?supp(Pg),loss(?)為負對數極大似然函數。
推論 當Dw=Dw_opt時,Dw等價為JSD,定理1 說明JSD對Gθ輸出的梯度為0,梯度信息基本不能傳播到Gθ。
如定理1,傳統GAN 將最優的判別器Dw_opt引入損失函數后,在更新生成器G 時梯度為0。所以針對傳統GAN 的訓練過程,每一步對判別器D 的更新都不能達到最優,否則會出現梯度為0 的情況,這是優化變得不穩定的根本原因。從JSD 的角度來看該問題,即JSD 的導數為0,不適合作為損失函數利用梯度進行啟發式搜索優化。
模式坍塌問題主要是GAN 模型生成的樣本不具有多樣性。模式崩塌解決方法是采用改變訓練批次的數量來權衡訓練速度與樣本多樣性的平衡問題。此外,模式崩塌還與隨機輸入維數關系極大。
2.2 K-Lipschitz 條件下改進的GAN 模型
2.2.1 基于Wasserstein 距離的GAN 模型
Wasserstein GAN 使用Wasserstein 距離代替普通GAN中的JSD,Wasserstein 距離定義如下:
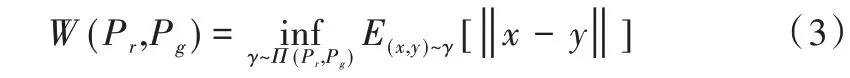
其中,Pr與Pg代表真實樣本和生成樣本的分布,Π(Pr,Pg)代表兩個為邊緣分布的所有聯合分布組成的集合。
在兩個分布Pr與Pg的聯合分布中,選擇一個特定的聯合分布,在連續的樣本空間中,這個聯合分布可以表征出一種將Pr的概率函數變換成Pg的由微分過程和積分過程的可逆泛函映射,記作:F:Pr→Pg。對于離散的樣本空間可以理解為將Pr(或Pg)中的概率值拆分并變換到Pg(或Pr)的過程。可證明每一個聯合分布有且僅有一種分解Pg并將其組合為Pr的方式。
通過上述簡單分析,可將Wasserstein 距離用以下方式解釋:尋找一種泛函映射方式(一個Pr與Pg的聯合分布),使得兩個邊緣分布Pr與Pg以最簡單的形式相互轉化。要盡量使得下確界達到,就要盡可能地使由X 與Y 中有相同取值的樣本對應的概率密度進行直接轉化。當兩個分布相等時,其下確界取得的聯合分布恰好在X 與Y 相同的位置其概率才不為0(其他位置概率為0),此時計算出的距離恰好為0,即最簡轉化形式。如果在最簡形式的轉化過程中,兩個樣本空間X 與Y 的非同值對應的概率密度發生轉化,則被定義為Wasserstein 距離。
盡管式(3)具有很好的數學特性,但是在聯合分布集{Fi} 中尋找出一個特定的聯合分布在數值計算過程中仍有一定困難,根據文獻[14]中的K-R 定理將式(3)等價為式(4):
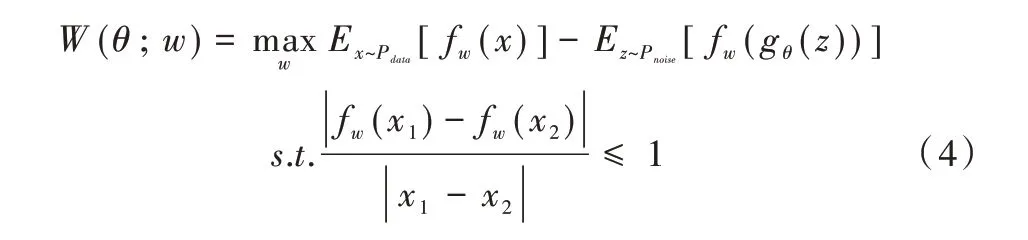
該式的約束條件即為1-Lipschitz 條件。將損失函數擴大K 倍后,可以將約束進一步改為滿足K-Lipschitz 條件,即可使上式成立。值得一提的是,fw是Dw去除最后一層激活函數的非線性函數,當Dw=Dw_opt時,fw=fw_opt。由定理1及其推論可知,正是因為傳統GAN 中最后一層激活函數是在分類器的背景下定義的,所以其梯度接近彌散的問題很難解決。如果隱層的激活函數也使用sigmoid 則彌散問題會嚴重一些,但隱層可以使用relu、elu 等抗彌散的激活函數代替,并且可以使用批歸一化的方式對數據分布進行重新規劃,而輸出層則卻不行,但使用Wasserstein 距離后就不存在隱層激活問題。
K-Lipschitz 條件沿用了部分導數定義,反映了一個函數在其定義域內的平均變化率。對整個判別器進行KLipschitz 約束后,相當于對判別器D 的復雜度進行了約束。在Wasserstein GAN 中采用權重限幅(weight clipping)的方式讓判別器D 保持K-Lipschitz 條件,每次更新將權重限制在[-c,c]范圍內,其中c 為限幅幅度,利用限幅來控制整個判別器的輸出,限制其從輸入到輸出滿足K-Lipschitz條件。
2.2.2 K-Lipschitz 條件下WGAN優勢
傳統GAN 最大的缺陷在于當真實樣本和生成樣本在樣本空間中的支撐集沒有交集,而且判別器D 達到最優分類界限時,生成器G 的學習動力不足,即:
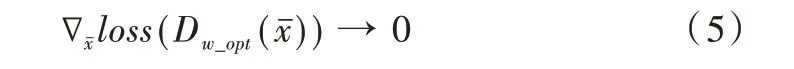
由文獻[15]中的命題一可知,當1-Lipschitz 條件成立時可以得到以下結論:
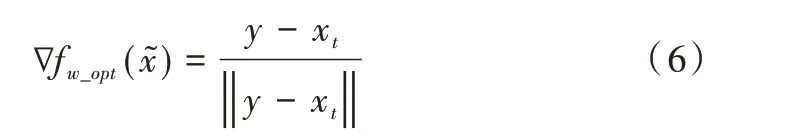
其中,來源于=εx+(1-ε)表示在真實樣本x和生成樣本連線區域。因為損失函數形式改為了Wasser?stein 距離形式,所以式(6)基本等于損失對輸入的梯度,即與傳統GAN 所得結果不同,滿足K-Lipschitz 條件的WGAN其損失對輸入的梯度向量等于單位向量。
3 判別指標
目前在學術界中,常用的判別指標包括了Inception 得分(Inception Score,IS)以及Frechet Inception 距離(Frechet Inception Distance,FID)等[19],其中IS 與FID 兩個判別方式是使用最廣的判別指標。本文將先分析這兩個指標在ABIDE 數據集與ADNI 數據集上的合理性,給出舍棄IS 的原因,最終選擇FID 作為衡量指標。
3.1 IS 簡介及其在MRI 數據集上的不合理性說明
Inception 得分是一種衡量圖像質量與多樣性的一種方式,文獻[15]對于生成器生成圖像的質量和多樣性可以直接使用規模龐大的判別網絡進行判斷,所以IS 是一種網絡的判斷方法。將ILSVRC 競賽中的Inception-V3 模型作為判別基準[20],其公式如下:
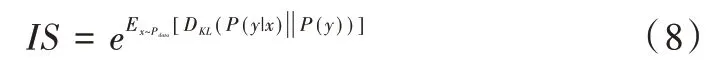
式(8)中最關鍵的兩個部分就是KL 距離,以及對先驗概率P(y)與經過判別器D 后得到的后驗概率P(y|x)之間的關系。從本質上說,IS 是最大化兩個熵值的差:

其中,H(y|x)表示在輸入圖像下其類別的熵值,是對后驗概率P(y|x)的混亂程度的一種描述。當判別器D 能確定某張圖像x(i)屬于哪一類時,H(y|x)的值會較低,也即圖像x(i)在該類上的質量較好。同理,H(y)表示在所有的生成圖像中標簽的混亂程度。混亂程度越大,生成圖像的多樣性越好。當先驗概率P(y)呈平均分布時其熵值達到最大,所以最終將兩個熵相減并反推以上證明,就得到Inception 的分值。值得一提的是,KL 距離在信息學上可以衡量兩個隨機分布的差異性(或者稱為距離),但因其不對稱性[10]以及當后一個概率的支撐集和整個概率空間的差集測度不為0時,在KL 距離無窮大的情況下,KL 距離會被其他距離所替代。
從上面的分析可以看出,若GAN 需要生成的樣本都是屬于Inception-V3 類別的樣本,那么當上式給入樣本集時,Inception-V3 能正確地給出統計概率(y|x)并判斷圖像樣本的類別。在對類別進行統計時也能正確地給出每一類樣本被生成的統計概率(y),這樣最終得到的IS 指標還是比較有效的。然而,腦部核磁共振的切片圖像屬于單一有標簽類別,并且不屬于Inception-V3 中分類的任何一類,所以使用常規的IS 是沒有內在意義的。我們更應該注重的是對于具有不同細節的同一個有標簽類別的指標建模,以及圖像中的某個局部圖像是否為有標簽類別的特征。
3.2 FID 簡介
除了上述IS 劣勢外,其未與圖像空間的概率分布產生關聯,僅僅與分類空間產生關系,但FID 則很好地解決了這個問題。
FID 定義如下:
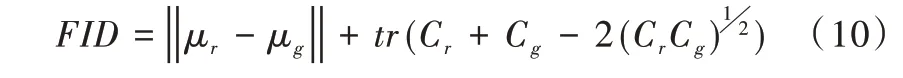
其中,μr與μg為真實特征和生成特征的均值,Cr與Cg則是真實特征和生成特征的協方差矩陣。
IS 未將原數據集引入計算,為解決該問題提出了FID,其原理是將實際圖像和生成圖像利用Inception 特征提取器進行特征提取,之后將提取后的特征看作特征空間的高斯分布,通過考量兩個高斯分布均值和協方差矩陣的差值范數,從而得出兩個圖像空間之間的距離。距離越近,兩個分布越相似,生成的質量也就越高,但同時多樣性也隨之變差;距離越遠,生成的質量則越低。對于腦部MR圖像這類特征細小的樣本,以高斯分布對其進行建模的方式十分適用于該問題,將IS 對通過神經網絡所得的類別分布直接改為原始圖像在像素空間中的分布,很大程度上提高了FID 在該問題上的可解釋性與合理性。
3.3 基于FID 的新型指標計算方式
本文將經過Inception 特征提取器的FID 絕對值作為衡量指標改為基于樣本集的相對指標,相對指標綜合考量了生成圖像的質量與圖像多樣性要求。之前的研究普遍認為FID 值越小越好,然而在實踐中如果對數據集的圖像進行簡單的圖像變換(例如翻轉、平移、錯切等)后,計算其與原集合的FID 值會產生一個十分小的值。此時,盡管整個數據集與原圖有差異,但是其FID 值依舊很低,在細節模式上變化很小,但新樣本是與數據集相似的冗余樣本,而非具有多樣性的樣本。
針對以上問題,本文提出類間FID 與類內FID 概念,并說明其原理。
FIDinter成為類間是指訓練集與生成圖像集之間的FID值,也就是常用的FID 方式。FIDintra也稱為類內FID,指某類集合中樣本間固有的FID 值,反映了一類樣本集中固有的多樣性。根據兩種集合,還可以把類內FID 分為樣本集類內與生成集類內,樣本集類內又被稱為FIDanchor。FIDinter的計算方式與傳統FID使用方式一致,而FIDintra則是將某類集合隨機分為兩半,將這兩半集合作為不同分布進行統計。將新的FID 指標定義為:
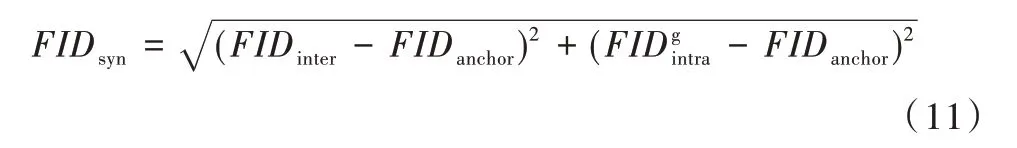
其中,式(11)的優勢在于FID 值不是越小越好(將生成集作為訓練集時,FID 為0,但圖像冗余度過高,樣本多樣性不夠好),而是越接近FIDanchor越好(因為類別具有層級性,某一大類中樣本依舊有小類,即某些細節特征的變化是多樣性的根本,保證類內的多樣性即保證FID 值不應太小)。式(11)的第一項反映了整體生成集的質量和多樣性是否與訓練集一致,第二項則反映了生成集內部有無模式坍塌現象。
4 實驗結果與分析
基于ABIDE 腦部核磁共振數據集中的數據,本文使用訓練過程更為穩定的Wasserstein GAN 代替了傳統的GAN,同時利用傳統的圖像增強方式對原數據集進行擴充,在傳統指標FIDinter與本文提出的FIDsyn指標上進行對比分析,實驗環境為Python+Tensorflow 框架。
實驗流程如下:首先,從ABIDE 數據集中逐一選擇出清晰而合適的橫斷面掃描圖像的三維采樣數據集。通過觀察與對比,將接近丘腦部分的截面圖像提取出并進行歸一化處理,在圖像尺寸方面,將其統一成128*128 大小的灰度圖像;在圖像像素強度方面,將其統一在[-1,1]區間內;之后,將圖像通過圖2 的流程進行訓練,采樣得到新生成的核磁共振圖像。與此同時,利用挖除、添加噪聲、對比度變化等方式,對數據集進行傳統的數據增強;最后,計算FIDinter與FIDsyn指標,值得一提的是,FIDinter指標需要對一個樣本進行不同方式的分割,計算其均值減少偶然誤差。圖3 給出了兩組圖像的對比。
圖3 中左側為經過預處理后的ABIDE圖像數據,右側則是經過WGAN 模型生成的腦部核磁共振圖像數據。通過視覺圖靈測試(Visual Turing Test,VTT),可以觀測出,盡管有細微的差異,但生成圖像在質量上基本與訓練集差別不大。同時,生成圖像的多樣性也較好,生成與數據集重復與冗余的圖像較少。這兩點充分證明了WGAN 在逼近某個分布時,相較于傳統方式具有更好的生成能力。
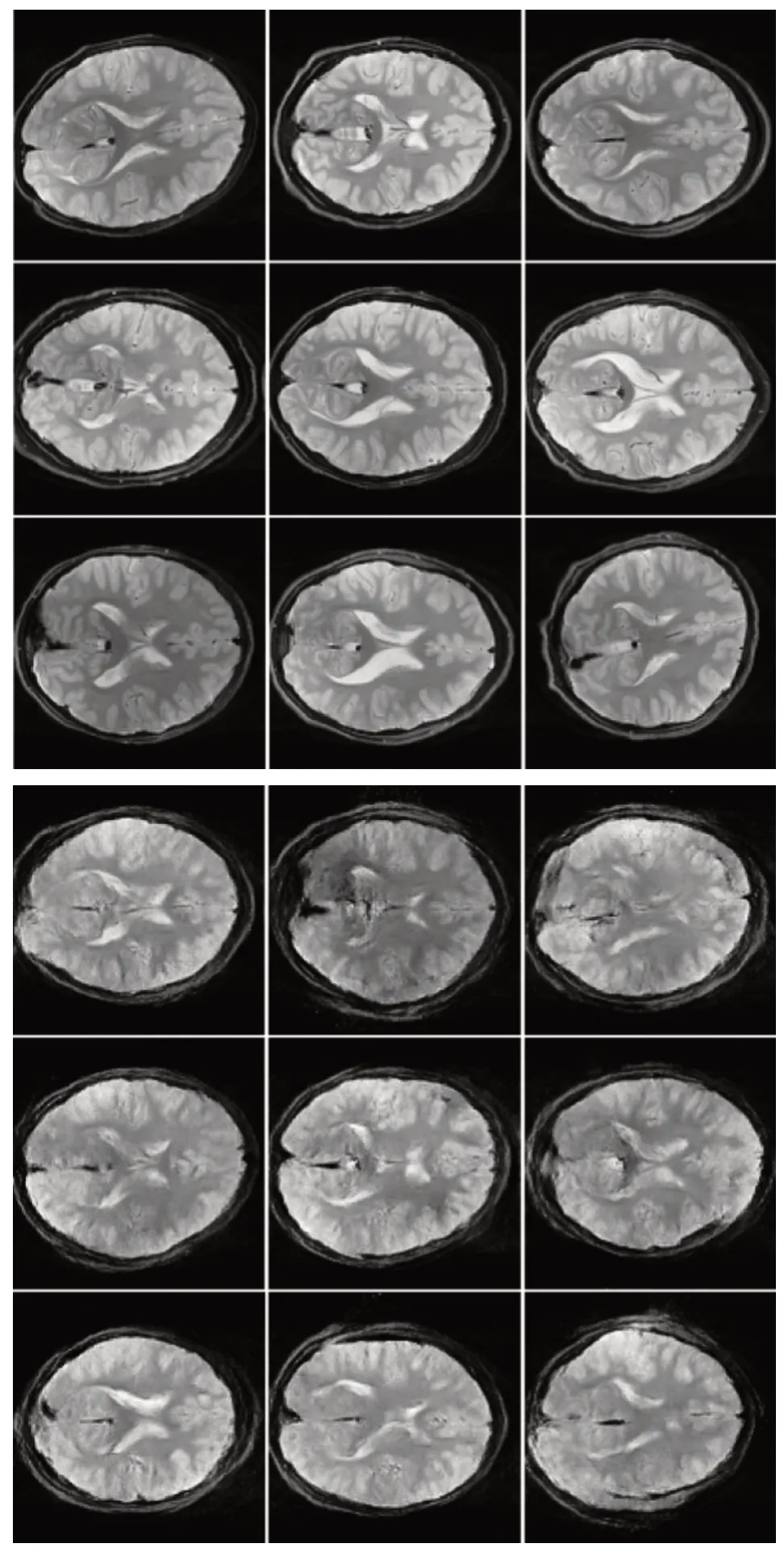
Fig.3 Partial MRI real images(left)vs.generated images(right)圖3 部分核磁共振數據集圖像(左)與生成圖像(右)
表1 反映了在不同圖像集下其與ABIDE 數據集的FID指標關系,可以看到質量低的數據集(如隨機噪聲)的FIDinter值(傳統FID)很高,質量高的數據集(如原數據集(整))的值接近0,但后者忽略了生成新樣本的多樣性問題。FIDsyn則很好地反映出了質量與多樣性之間的關系。在SMOTE 算法上實驗得到的圖像經過VTT 的效果很好,但是FIDinter的指標很大,這是由于其超越了數據集進行了擴充。由表1 可知,WGAN 方法生成的樣本相比傳統方法更好,在傳統FIDinter指標上達到了1.29,在FIDsyn指標上則達到了0.07,相較于傳統的增強方法有明顯提高。

Table 1 Comparison of FID metrics for ABIDE dataset generation results表1 ABIDE 數據集生成結果FID 指標比較
5 結語
改進的GAN 模型及其變體中,使用Wasserstein-1 距離代替了JSD 作為生成網絡G 的損失函數,同時將Wasser?stein-1 距離表達成可以優化的函數式,增加了K-Lipschitz條件對GAN 的限制,使得GAN 訓練過程中,在反向傳播后,對于判別器D 的支撐集(WGAN-GP)以及支撐集以外的區域(SNGAN)有著優良的梯度特性,從而很好地避免了因為網絡層數過深以及不合適的非線性激活函數所導致的學習動力不足之類的訓練穩定性問題。后續工作應該著重于對Lipschitz 條件深入理論分析與實際改進。
模式坍塌是GAN 最常見的問題之一,在本文之外對類GAN 網絡產生模式坍塌的原因做了一些簡單實驗,經過VTT 發現,生成器G 的隨機噪聲輸入維數越小,生成器生成的模式相似圖像就越多。深入探究類GAN 網絡模式坍塌的具體原因也是未來的工作之一。
同時,對于新的FID 指標,還需要在更多的數據集以及更大規模的真實樣本集上實驗,并對比更多數據擴充方法(尤其是SMOTE 算法)驗證其優缺點,從理論上說明不同的數據集上FIDsyn的第一項與第二項收斂的依據。如何提高整個指標的敏感度也是進一步改進FID 指標重要的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
