基于中文OCR模型的智能圖書識別系統
2021-11-28 10:51:40粟晨洪李昕昕
電腦知識與技術 2021年28期
粟晨洪 李昕昕

摘要:目前大多數圖書館的圖書管理系統仍以人工處理方式為主,為方便普通圖書用戶的使用、簡化工作流程、提高圖書管理效率,提出一種基于中文OCR模型的智能圖書識別系統,以PaddlePaddle中的OCR模型為基礎,加以網絡爬蟲技術進行智能化的圖書管理,通過理論和實踐發現,該智能化系統能滿足要求。
關鍵詞:圖像識別;OCR模型;爬蟲技術
中圖分類號:TP18? ? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)28-0020-03
開放科學(資源服務)標識碼(OSID):
隨著科技的進步,社會一步步地走向繁榮,在物質生活得到滿足的今天,文化建設越來越受到重視[1]。圖書館作為人類探索知識的補給站,肩負著知識傳承的重要責任,在城市文化建設中擔任著不可或缺的角色[2]。
大多數的圖書館的圖書管理主要以人工為主,過程冗余繁雜[3],融入一些智能化的技術既能在很大的程度上方便普通用戶進行圖書的查詢、減少查詢時間,又能實現圖書的智能識別以及圖書的即拍即查和即傳即查[4]。基于中文OCR模型的智能圖書識別系統在一定程度上能夠實現這樣的功能。
1系統簡介
1.1 系統框架
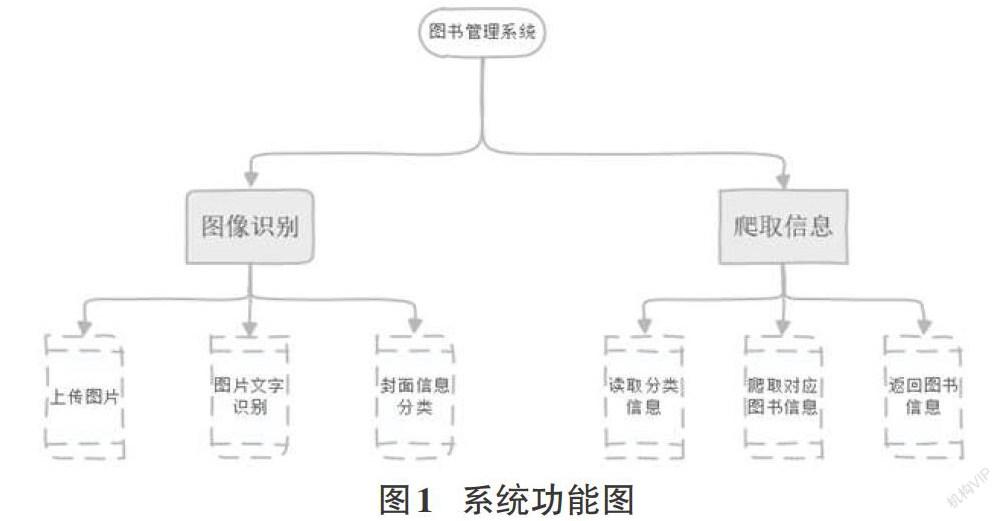
本文提出的圖書管理系統是基于中文OCR模型的智能圖書識別系統。該系統包含圖像識別和圖書信息爬取兩大功能,具體功能結構圖如圖1系統功能圖所示。
1.2 系統功能介紹
圖片的上傳:采取即時拍攝和直接輸入圖片[5]。考慮到當今信息科技的技術實力,直接輸入圖片不僅操作方便而且效果優于即時拍攝,因為伴隨著時代與技術的飛躍發展,市面上用來掃描圖片或視頻以及處理圖片效果和視頻效果的App愈漸普及且技術越來越成熟,從而讓圖片和視頻的質量得到了更大的保障,也因此提高了本次實驗識別結果的準確度。
圖片文字的識別:直接使用PaddlePaddle高度完善的中文OCR模型進行識別。
封面信息的分類:將使用模型后識別出的結果進行歸類存放,比如作者名、書籍名、出版社等書籍封面信息。
讀取分類的信息:讀取已經經過分類后的完整的模型識別結果信息。
爬取對應的圖書的信息:將讀取到的結果信息作為使用爬蟲技術爬取信息的依據,以此爬取對應的書籍在線上圖書館或線上書城以及其他購物網站中的更多詳細信息,比如書籍的簡介、書籍的線上價格等。
返回圖書的信息:將爬取到的相關圖書的所有結果信息返回客戶端,并將全部的結果輸出顯示在客戶端上。
1.3核心技術簡介
1.3.1 圖像識別模型
本文提到的基于中文OCR模型的智能圖書識別系統所用到的圖像識別模型為PaddlePaddle上已經高度完善的中文OCR模型,具體使用了模型中的“chinese_ocr_db_crnn_mobile”,該模型用于識別圖片中的漢字,其基于[chinese_text_detection_db_mobile Module]檢測得到的文本框,繼續識別文本框中的中文文字,之后對檢測文本框進行角度分類。最終識別文字算法采用CRNN(Convolutional Recurrent Neural Network)及卷積遞歸神經網絡。其是DCNN和RNN的組合,專門用于識別圖像中的序列式對象。與CTC loss配合使用,進行文字識別,可以直接從文本詞級或行級的標注中學習,不需要詳細的字符級的標注。該模型是一個超輕量級的中文OCR模型,可以支持直接預測。
1.3.2 爬蟲技術
本文提到的基于中文OCR模型的智能圖書識別系統所用到的爬蟲技術的核心部分主要利用了requests庫、xpath庫、re庫等數據挖掘中爬蟲相關的技術模塊,其中的requests庫用于模擬瀏覽器的發送請求從而獲取到服務器返回的數據,re庫主要應用在字符串的匹配中,配合xpath庫可用來查找和解析通過requests請求后所得到的返回值并提取出其中需要被使用的數據,完成前面的兩步操作后再將最終的數據結果保存到csv或txt等固定格式的文件中。
2 設計思路及實現
2.1 系統流程
本文所提到的基于中文OCR模型的智能圖書識別系統主要是利用圖像的文字識別技術將上傳的圖片中的文字進行較為精準的識別,然后通過數據處理的方式對獲取到的文字數據以“書名”“作者”“出版社”等固定格式進行分類與統計,最后以分類并統計好的結果作為數據基礎,利用大數據的信息爬取技術獲取到參與了文字識別過程后的圖書的相關簡介與價格等信息,最后以csv格式或txt格式等固定格式進行數據的存儲。其總體流程如圖2系統流程圖所示。
2.2 實現步驟
2.2.1定義待預測數據
本文所提出的基于中文OCR模型的智能圖書識別系統所需要的預測數據predict_data的內容主要為待預測的書籍的封面的圖片、背面的圖片、封面與背面的連接處的圖片,以此方式制作的預測數據集能夠在一定程度上提高識別結果信息的準確度與準確性。
2.2.2圖書信息識別
本文所提到的基于中文OCR模型的智能圖書識別系統進行圖書信息識別的主要流程為:利用im_rec對定義完成的預測數據進行圖像的文字識別,利用recognize_text()函數進行模型調參,利用本文所提到的中文OCR模型chinese_ocr_db_crnn_mobile提取圖片中的文字并形成字典,對存放文字信息結果的字典進行篩選處理,提取得到分別包含書籍名字、作者等信息的列表,對列表再做處理得到最終的更為準確的圖片信息。經過多次模擬實驗訓練,取得recognize_text()函數最終最優參數,設置為:box_thresh=0.5,text_thresh=0.2.在上述參數設置下的模型預測準確率可高達0.99877。部分源碼如下所示:
#處理圖片識別結果
positionX = []#存放識別到的每個紅框的橫坐標
res = [] #存放處理好的結果
infos = 0
count = 0
count_list = []#存放內容為字典類型,key為圖片序號,value為識別到的紅框數
dict_list = []#存放臨時字典
n = 1
for result in results:#results為中文OCR模型識別后的結果
data = result['data']
save_path = result['save_path']
for info in data:
count += 1
print(info['text_box_position'])
print(info['text'])
#根據檢測到的紅框的大小判斷書名
#大小的判斷基于紅框左右定點之間的距離
for i in info['text_box_position']:
positionX.append(i[0])
max = positionX[0]#最大橫坐標
min = positionX[0]#最小橫坐標
for i in range(len(positionX)):
if(positionX[i]>=max):
max = positionX[i]
if(positionX[i]<=min):
min = positionX[i]
result = max – min
#創建臨時字典用于存放處理過的數據
dict_res = {}.fromkeys(["info","result","text"])
dict_res["info"] = infos
dict_res["result"] = result
dict_res["text"] = info['text']
dict_list.append(dict_res)
infos += 1
positionX = []
res.append(dict_list)
infos = 0
dict_list = []
print(n,count,sep=':')
count_dic = {}.fromkeys(['圖片序號','識別到的框'])
count_dic['圖片序號'] = n
count_dic['識別到的文字'] = count
count = 0
print('-'*100)
n += 1
count_list.append(count_dic)
2.2.3圖書信息智能匹配
本文所提到的基于中文OCR模型的智能圖書識別系統所用到的智能匹配技術是根據2.1.2中識別得到的書籍的名稱、作者等圖書的封面信息,然后對相關書籍的詳細信息進行更深層次的爬取:
第一步:利用request庫發送服務器HTTP請求,其請求頭的內容包括URL、User-Agent、Headers等。
第二步:response獲取請求成功后服務器返回的數據。
第三步:先利用xpath語言對通過服務器請求成功后返回的數據結果進行查找并獲取,然后利用數據挖掘中的re庫對查找并獲取到的數據結果進行解析和處理。
第四步:將獲取并解析后的數據進行一定的分類和格式處理后得到后續實驗所需要處理和利用的信息。
第五步:將最終處理好的信息存儲并保存為csv或txt等固定格式的文件。
2.3 實驗結果
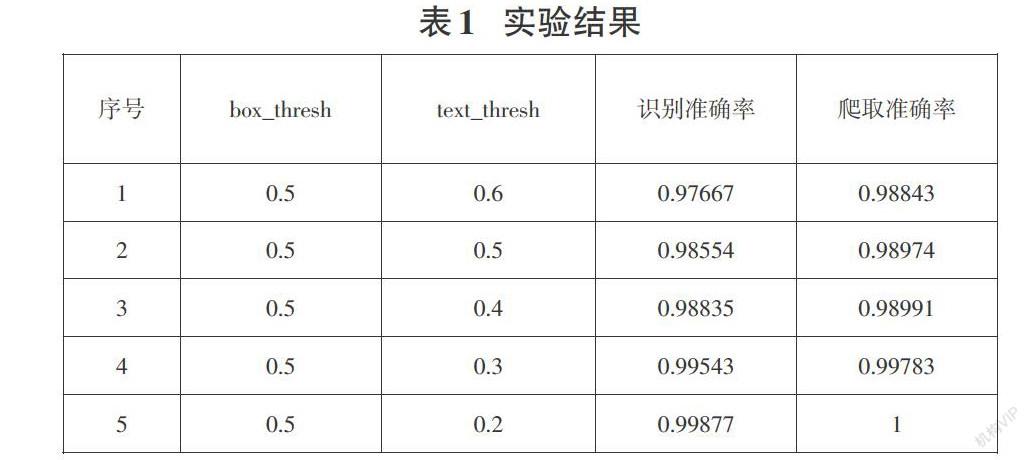
本文實驗用到的圖片數據集大小一共為265張,其中訓練集為204張,驗證集為10張,預測集為51張。在實驗的數據集下,本文的實驗結果如以下表1所示。
從表1可以得出的結果為:在圖片處于較高畫質的情況下時,當box_thresh=0.5,text_thresh不斷減小時,識別準確率與爬取準確率逐漸趨于穩定并在box_thresh= 0.5,text_thresh=0.2時達到最高。
3結束語
本文所提出的基于中文OCR模型的智能圖書識別系統采用了PaddlePaddle深度學習框架中的中文OCR文字識別模型,結合了部分網絡爬蟲技術,實現了對圖書的即拍即查、即傳即查的智能化功能,在一定程度上降低了工作人員的工作負擔,更大程度地方便了普通用戶的使用,節約了讀者用戶在書籍尋訪過程中的時間開支。但本智能系統在識別準確率和爬蟲準確率上仍然存在一定的優化空間,在后期還可以通過圖像增強、關鍵點捕捉以及優化被爬網站等方式來進行技術上的改進。
參考文獻:
[1] 王海波.圖書管理助手機器人檢測系統設計[J].現代鹽化工,2020,47(6):173-174.
[2] 劉秀峰.基于物聯網技術的圖書管理系統[J].農業網絡信息,2015(5):53-56.
[3] 黃敏杰,于國龍,黃榮翠,等.基于opencv圖像識別的圖書管理系統[J].電腦知識與技術,2019,15(17):194-195,198.
[4] 胡俊瑋.基于數據挖掘的圖書管理系統研究與設計[D].廣州:中山大學,2014.
[5] 黃佳.基于OPENCV的計算機視覺技術研究[D].上海:華東理工大學,2013.
【通聯編輯:唐一東】
