一種基于注意力機制的細粒度圖像分類方法
2021-12-02 06:24:50鄭承宇鄧亞萍尹甜甜
云南民族大學學報(自然科學版) 2021年6期
王 婷,王 新,鄭承宇,鄧亞萍,尹甜甜
(云南民族大學 數學與計算機科學學院,云南 昆明 650500)
細粒度圖像分類(FGVC)作為當前研究的熱點,與常規的粗粒度圖像分類相比,為人們提供了更加詳細的圖像信息,并可以區分圖像中的各基本級別的類別.例如,鳥類和車輛之間存在細微的視覺差異[1-2],在區分圖像中鳥和車的同時,還能分別出鳥類和車輛的特定種類和類別.由于傳統的圖像分類方法無法產生良好的分類效果,研究人員開始將深度學習技術引入到圖像分類、識別任務中[3].
目前關于細粒度圖像分類的研究已取得一些成果.例如,Huang等[4]提出1種基于多視角融合的分類方法,其主要包括使用特征圖從圖像中挖掘出細粒度特征和分析圖像的全局特征的2個分支,最后合并2個分支;Wei等[5]提出在對物體進行檢測時引入深度卷積特征的方法,應用到細粒度圖像中,通過圖像的注釋定位目標和圖像中其他可識別的地方;Lin等[6]提出了一種包含2個VGG網絡的B-CNN網絡,將其分別用于檢測圖像的目標區域和提取目標區域的特征,最后將獲取的特征進行雙線性融合.不同而又細微的細節特征在細粒度圖像分類中起著重要作用,因此,學會區分細節的注意力機制逐漸成為最受歡迎和最有前途的研究方向,研究者們提出了各種注意力機制.例如,文獻[7]中提出了一種動態反復視覺注意計算時間的DT-RAM模型,該模型能夠參與動態測量中最具有區別的部分.Fu等[8]提出一種使用注意力網絡在不同尺度的圖像上生成區域性注意力的RA-CNN網絡,此模型主要使用多尺度網絡逐步找到主要目標,利用分類損失優化網絡,從而找出準確的區域.Heliang Zheng等[9]提出了MA-CNN模型,此模型能夠產生多個設計通道模塊,并且能夠實現單尺度一致的注意映射.Heliang Zheng等[10]提出了TASN模型,該模型以一種高分辨率的師生方式從數百個建議中學習圖像的細粒度特征,最后表現出來的分類性能優于上述模型.
上述的分類模型在細粒度圖像的分類的任務中雖已取得較好的分類效果,但是在實驗過程中缺少對模型的魯棒性和泛化能力的驗證.為了解決此問題,本文針對TASN模型進行研究,對此模型注入dropout,隨機深度2種噪聲,并在輸入實驗數據之前,利用Rand Augment的數據增強對實驗數據進行加噪,并把增強后的圖像反饋回加噪后的模型,從而來驗證模型的泛化能力和魯棒性.
1 基于注意力機制的細粒度圖像分類
1.1 注意力機制
因人類認知過程中,大腦會有選擇的關注所得信息更有價值部分,忽略低價值的信息,這樣會給識別的結果產生干擾.當計算機無法模擬人類的注意力狀態時,可能會對低價值的信息進行處理從而擾亂最終結果,也正因此,我們需要通過訓練,使計算機學會注意力機制.在經過訓練后,注意力模塊通過不同的神經網絡結構以預測主體的位置,即從輸入圖像中剪裁更精細的圖像,讓模型對精細化圖像的進行更精準的分類,從而達到提升分類的性能目的.具體的測試流程圖如圖1所示.
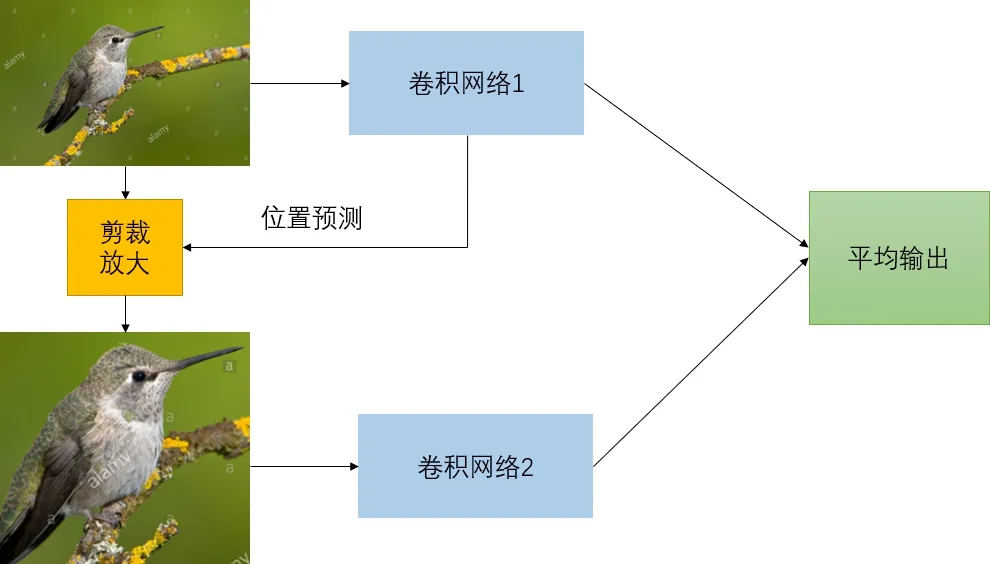
圖1 注意力機制測試流程圖
1.2 三線性注意力抽樣網絡
三線性注意力抽樣網絡(TASN)是以注意力機制為基礎,基準網絡為Resnet-18的抽樣網絡,其主要功能是以一種高效的方式,從多個注釋的特征中學習圖像細粒度特征.網絡的具體結構如圖2所示.
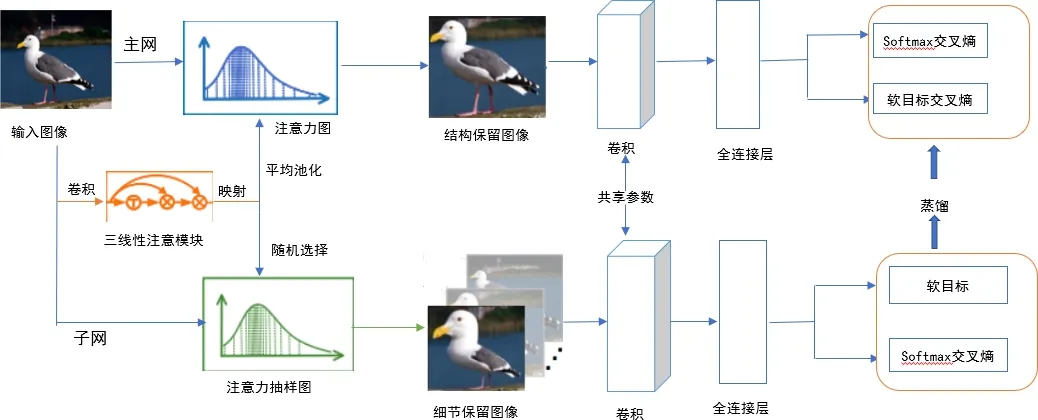
圖2 三線性注意力抽樣網絡結構
該網絡主要有3大模塊,即注意力模塊、注意力采樣器模塊及蒸餾器模塊.其中三線性注意力模塊主要以特征映射作為輸入.為了提取圖像中更多的細節特征,三線性注意力模塊通過三線性積生成注意力映射,使特征通道與其關系矩陣相結合,然后將每個通道的特征圖轉化成一個注意力.注意力采樣器以注意力圖作為輸入圖像,最后將從保留細節的圖像中學習到的細粒度特征利用蒸餾器提取到主網中.主網只要以結構保留圖像作為輸入,通過部分網的指導細化圖像特定的部分.三線性注意模塊首先將c×h×w維的特征圖轉化為c×hw維的矩陣.三線性函數如下公式(1)所示:
Mb(X):=(XXT)X.
(1)
其中:X∈Rc×hw,XXT是一個雙線性的特征,表示的是通道之間的空間關系.為提高三線性注意力的有效性,對輸入的圖像做歸一化處理,歸一化的公式可表示為
M(X):=N(N(X)XT)X.
(2)
其中:N(.)表示對矩陣的第二階進行softmax函數歸一化,N(X)表示空間歸一化,N(N(X)XT)X表示關系歸一化,它在每一個關系向量上進行.注意力采樣器在對圖像進行細粒度提取的過程中,對不同的注意力圖統一抽樣處理,統一抽樣公式為:
IS=S(I,A(M)),Id=S(I,R(M)).
(3)
其中:M為注意力圖,S(.)表示非均勻采樣函數,A(.)表示平均池化通道,R(.)表示從輸入中隨機選擇通道.最后將結構保留圖像和細節保留圖像送到相同CNN中,以此獲得全連接的輸出.將全連接輸入記為Zs和Zd,采用softmax函數將其轉換為概率向量qs和qd,如下所示:
(4)
其中T為參數,在知識蒸餾中,T的值通常會設置比較大.主網軟目標交叉熵為:
(5)
最后三線性注意力抽樣網絡的損失函數如下所示:
L(IS)=Lcls(qs,y)+λLsoft(qs,qd) .
(6)
1.3 Resnet網絡
Resnet最初由何凱明團隊提出,開啟了人們學習殘差網絡的熱潮,解決了在淺層次的網絡結構中建立深層網絡不僅不能取得較高的準確率,反而引起了網絡性能下降的問題.作為基于注意力機制的三線性注意力抽樣網絡的基準網絡,其原理是在輸入和輸出之間增加了一種短鏈接,迫使網絡適應殘差映射.于之前的網絡結構相比,此方法更加容易訓練.設所有的映射為H(X),殘差連接讓堆疊的非線性層來擬合另一個映射:
F(X)=H(X)-X.
(7)
原來的映射為:
H(X)=F(X)+X.
(8)
參差網的基本結構圖如圖3所示;
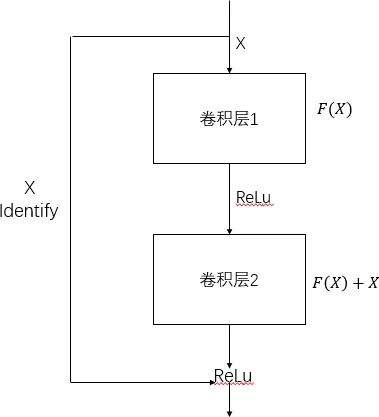
圖3 殘差模塊的基本結構
殘差網結構具體形式如圖4所示:
xl+1=xl+F(xl,Wl).
(9)
通過遞歸,可以得到任意深層單元L特征的表示:
(10)
2 基于改進的注意力機制的細粒度圖像分類方法
2.1 模型框架
三線性注意力抽樣網絡在細粒度圖像分類中已取得較好的分類效果,但模型的魯棒性和泛化能力在訓練的過程沒有得到很好的體現.為了進一步提高三線性注意力抽樣網絡模型的魯棒性及泛化能力,提出一種改進的三線性注意力抽樣網絡.該模型在原始三線性注意力抽樣網絡基礎上引入一種新穎的圖像增強方法,并引入隨機深度和Dropout層添加噪聲,進而完成細粒度圖像分類.改進的模型框架如圖4所示.
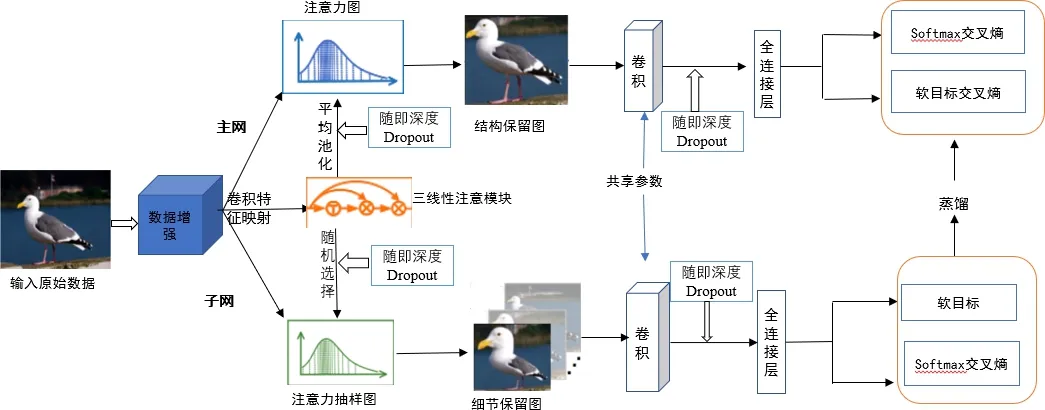
圖4 基于注意力的三線性注意力抽樣網絡
基于改進的注意力機制的細粒度圖像分類方法的主要步驟為:
1) 在原始輸入圖像中進行數據增強處理(數據增強的方式主要有旋轉、翻轉、變形、縮放以及擴充等);
2) 以三線性注意力模塊作為輸入的特征映射,將增強后的圖像轉化為注意力圖,此步驟會提取出圖像中的成百上千個細節特征,在平均池化的過程中,對其注入隨機深度和Dropout;
3) 采樣器將注意力圖作為輸入,并隨機選擇圖像生成細節保留的圖像和結構保留的圖像;
4) 將部分網中學習到的細粒度特征通過蒸餾器提取到主網中,蒸餾器是通過權重共享和特征保留來實現其操作,在主網和部分網中的卷積到全連接層也注入了隨機深度和Dropout.通過以上4個步驟以完成細粒度圖像分類任務;
2.2 圖像增強(AUG)
本文提出一種改進的三線性注意力抽樣網絡,為增加網絡的泛化能力,在將原始圖像輸入網絡之前,對輸入圖像進行歸一化操作,其計算公式如式(11)所示.
(11)
原始數據標準化處理后得到注意力圖像Ak,再對圖像進行圖像增強操作,進一步提高網絡的泛化能力,數據增強的主要過程如圖5所示.
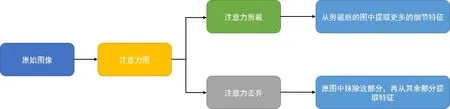
圖5 圖像增強過程
其中圖像中局部區域Ck和Dk的計算公式分別如式(12)、式(13)所示.
(12)
其中,θc∈[0,1].
(13)
其中,θd∈[0,1]
2.3 隨機深度網絡(SD)
為了提升收斂性,將隨機深度網絡引入到三線注意力機制網絡.隨機深度網絡主要是指在Restnet訓練時優化算法的速度和性能,原始Resnet結構和具有隨機深度的Resnet結構分別如式(14)和(15)所示:
Hl=ReLU(fl(Hl-1)+id(Hl-1)).
(14)
Hl=ReLU(blfl(Hl-1)+id(Hl-1)).
(15)
其中:f代表殘差部分,id代表恒等映射.然后將兩部分進行求和,再經過激活最后輸出.隨機深度網絡就是在訓練時加入一個隨機變量b,然后將f乘以b.
2.4 Dropout層
Dropout層是指在訓練深度學習網絡的過程中根據一定的概率對神經網絡單元進行丟棄,但是在網絡訓練時,總會遇到諸如過擬合和費時等問題,Dropout的功能主要是減少實驗過程中過擬合的發生,整個Dropout過程相當于平均許多不同的神經網絡取.一些互為“反向”的擬合會相互抵消,以減少整體過擬合,并且在一定程度上降低神經元之間復雜的共適應關系和正則化的影響.采用Dropout網絡計算公式如下(16)至(19)所示:
(16)
(17)
(18)
(19)
其中:Bernoulli函數是生成概率向量r,即隨機生成0、1向量;*是元素級乘法,對任意層l,r(l)是獨立Bernoulli隨機變量,每個變量的概率p為1.此操作等效于對大型網絡的子網絡進行采樣,并且在反向傳播的情況下,它是當前子網絡的反向傳播.
3 實驗數據與結果分析
3.1 實驗數據
選取了3個公開的細粒度圖像分類數據庫,分別是CUB-200-2011數據庫[11]、Stanford cars數據庫[12]以及iNaturalist-217數據庫[13]進行實驗.其中CUB-200-2011由加州理工學院創建,具有200種鳥類,共拍攝了 11 788 張圖片,其中訓練集中有共 5 799 張圖片,測試集中有 5 999 張圖片.Stanford cars數據庫由斯坦福大學團隊創建的有關汽車模型的細粒度圖像數據集,它總共包含196種常見的車型,共有 16 185 張圖片,訓練集中有 8 144 張圖片,測試集中 8 041 張圖片.iNaturalist-2017數據庫共有 675 170 張圖,其中訓練集有 579 184 張,測試集有 675 170 張圖像.數據集的統計信息如表1所示.
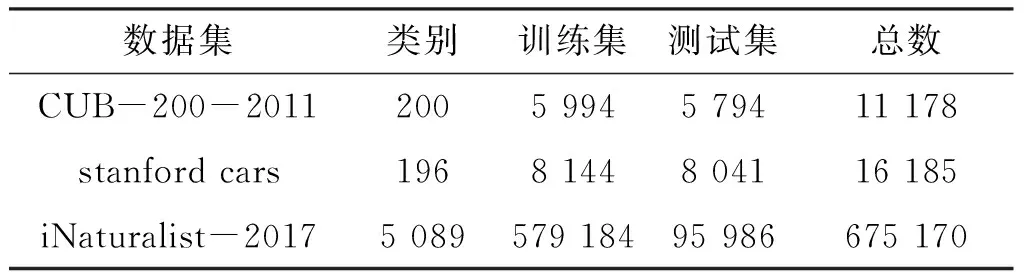
表1 數據集信息統計表
3.2 實驗平臺及實驗參數
本實驗采用的實驗平臺與配置如表2所示,實驗具體參數如表3所示.

表2 實驗平臺與環境

表3 實驗參數
3.3 實驗結果分析
將本文方法與當前的細粒度圖像分類模型進行比較,對比結果于表4~表6所示.在文中,將公式(20)定義的精度作為評估指標,Pi代表正確分類為類別i的物種的數量,numi代表第i類圖像的數量,N代表所有圖像類別的數量.

表4 數據集CUB-200-2011的細粒度分類結果對比

表5 數據集stanford cars的細粒度分類結果對比

表6 數據集iNaturalist-2017的細粒度分類結果對比
(20)
為進一步增強結果的可靠性,實驗過程未采用額外的數據集,也未進行人工標注以及層次標簽.由表4可見,對于數據集CUB-200-2011,文中方法相較于RA-CNN準確率提高了2.7%,相較于MA-CNN準確率提高了2%,相較于三線注意力抽樣網絡的準確率提高了0.1%.
由表6可見,對于數據集iNaturalist-2017,本文方法的準確率比RA-CNN提高了2.9%,比MA-CNN提高了2.5%,比三線注意力抽樣網絡提高了0.5%.
由此可見,通過數據增強增加噪聲以及提高模型魯棒性的方式,可有效提高細粒度分類準確度.
3.4 消融實驗
討論各種噪聲的作用情況,研究噪聲在具有同一數量的數據和不同狀態下的模型的分類準確度.分別采用TASN、TASN+Aug、TASN+SD、TASN+Dropout及TASN+Aug+SD+Dropout等不同模型訓練圖像數據,實驗使用的數據集均為CUB-200-2011.實驗結果如表7所示.
由表7可見,噪聲如隨機深度、dropout和數據增強等在訓練模型TASN網絡的過程中發揮了重要作用.其中,分別在TASN中增加數據增強、隨機深度及Dropout,其準確率相較于TASN模型增加0.04%~0.05%,但三者之間的準確率相差不大,分別為87.93%、87.94%、87.93%;在同時對TASN模型加入數據增強、隨機深度、Dropout后,其準確率相較于TASN增加0.13%,相較于只增加數據增強、隨機深度或Dropout,準確率提高了0.08%~0.09%.由此可見,采取多種方式增加噪聲,可明顯增加結果的準確度.
4 結語
隨著對計算機視覺中應用的不斷研究,細粒度圖像分類被越來越的人關注.文中基于注意力機制條件,對三線性注意力抽樣網絡提出改進,使網絡具有更加顯著的魯棒性和泛化能力,從而減少了外界環境改變對分類結果的影響.具體方法是通過在網絡中注入隨機深度、Dropout兩個噪聲,且在實驗之前,采用數據增強對原始圖像進行預處理.本文所提出的改進網絡表現出較強的容錯率,減少了外界環境的改變對分類結果造成的影響,提高分類準確度的效果.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
