文本風格轉換模型的平衡性改進方法研究
2021-12-03 05:11:02劉延飛何玉杰
兵器裝備工程學報 2021年11期
劉延飛,李 慧,何玉杰
(火箭軍工程大學 電子信息技術教研室, 西安 710025)
1 引言
文本風格轉換屬于一種特殊的自然語言生成技術,是指在保留原句內容的同時,重新措辭生成包含特定風格屬性(詞匯、句法等)的文本。不同場景下不同人群的表達方式不同,例如小說和科學論文、語言在個性年齡方面具有顯著差異[1]等,使得信息交換中存在一定領域性的表述門檻和理解偏差。文本風格轉換通過將語句轉換成目標風格,能更好促進信息的接收,對于科學論文成功、信息的廣泛傳播、維護社交媒體的良好交流氛圍、減輕現有自然語言技術中存在的偏差、語言風格控制生成技術等有重要意義[2-5],近年在文本領域的研究已經成為熱點,引起學者們關注和研究。
根據研究數據是否為內容一致而風格不同的平行數據,文本風格轉換主要有監督的傳統方法和無監督的深度學習方法。有監督的傳統方法主要針對在平行數據下實現,基本以單語機器翻譯為思路,將不同風格視為不同語言,形同釋義。例如,文獻[6]基于短語的機器翻譯完成現代語言-莎士比亞文本風格轉換。Mizukami[7]等利用統計機器翻譯模型,結合語言模型實現說話人的個性翻譯,但規則復雜且內容保留程度較低。然而,由于內容一致而風格不同的平行數據難以獲取,該領域當前工作主要集中實現無監督的文本風格轉換。主要有以下3種實現思路:隱式分離風格和內容[8-11],用對抗網絡或回譯等方法對語句潛在表示強制分離內容和風格,存在訓練困難、風格和內容難以平衡等問題;顯式分離風格和內容[12-14],對包含風格屬性強的短語進行刪除替換,模型簡單,但難以識別并轉換隱式風格;不分離風格和內容[15-22],對特征高度糾纏的潛在空間信息進行處理,較好地平衡風格和內容表示,值得進一步探索。
綜上考慮,本文對文獻[18]的文本屬性可控轉換模型CTAT進行深入研究。該模型不分離內容和風格,對語句的潛在表示添加風格擾動,較為簡單直觀地實現文本風格轉換,具有良好性能。然而,該模型存在性能不穩定的問題,特別是較大程度風格轉換時易添加復雜信息,使得生成語句較為混亂。針對此不足,本文在算法上進行了改進,對風格干擾添加顯著性操作,增大優化梯度方差,局部加強風格干擾效果,以加強內容保留約束。同時,在結構上,受文獻[23]的啟發,修改解碼器模型對干擾前后的潛在表示進行漸進式融合,實現進一步的內容保留約束,從而在風格和內容上產生更好的平衡。為此,創新性地漸進式融合思想應用于文本風格轉換,用多頭注意力代替卷積,融合不同層次的語句信息。通過顯著性風格干擾和漸進式風格融合實現轉換句的內容與風格平衡表示,在Yelp數據集上驗證了提出的方法的有效性,提出的方法有效提高內容保留度和流暢度,實現較好的綜合性能。
2 Balance-CTAT模型
CTAT模型通過自編碼器重建語句,并且利用對抗樣例生成技術,以此實現無監督文本風格轉換。模型由3部分組成,分別是編碼器、解碼器和風格分類器,如圖1所示。編碼器和解碼器都是由2層具有4頭注意力的Transformer堆疊而成,編碼器將原句編碼為潛在表示,解碼器對其解碼輸出語句;風格分類器由兩個全連接層和一個sigmoid層組成,判斷潛在表示的標簽。訓練階段的目標是盡量減小將自編碼器重建損失和分類器損失,使得模型具有基本的生成能力和風格判斷能力。
風格轉換任務主要是利用快速梯度迭代算法(fast gradient iterative modification,FGIM)實現,通過對抗樣例生成技術對潛在表示進行風格干擾,使之能欺騙分類器達到其擁有目標風格的目的。具體實現中,風格分類器C根據原句潛在表示z預測標簽s,并計算其與目標標簽s′的損失L得到風格優化梯度,以風格干擾系數λ調整轉換程度,生成具有目標風格屬性的z′:
z′=z-λ▽zL(C(z),s′)
(1)
然而,CTAT模型存在性能不穩定的問題,特別是較大程度風格轉換時易添加復雜信息,使得生成語句較為混亂。針對CTAT模型存在的不足,本文在傳統的CTAT模型上進行改進,構造了Balance-CTAT模型,如圖2所示。對比圖1和圖2,提出的模型做了兩方面的改進,在算法上對風格遷移算法進行顯著性優化,在結構上,修改Transformer[24]解碼器各層注意力頭數進行不同層次的信息融合。

圖2 Balance-CTAT模型的組成示意圖Fig.2 Balance-CTAT model
在算法上,利用快速梯度優化算法FGIM進行顯著性優化,結合注意力機制,增大梯度值方差,局部化風格干擾影響。快速梯度迭代優化算法FGIM是CTAT模型中實現風格轉換的核心算法。該算法受對抗樣本生成工作[25-26]啟發,用對抗性擾動全局化編輯原句的潛在表示來改變分類器預測結果,使之擁有目標風格特性,從而達到風格轉換的目的。而語句的潛在表示中特征高度糾纏,全局化編輯會一定程度上影響句子的其他屬性(語序、詞匯等)。因此,本文對該算法進行顯著性優化,增大梯度值方差,局部化風格干擾影響。
設n維的句子潛在表示zn通過分類器計算得到風格優化梯度gn,梯度保留系數為μ,顯著性權重為wn。將梯度取絕對值,其中前「μn?個最大值乘以顯著性梯度wn,并將剩余的n-「μn?個梯度值置為零,以此實現顯著性梯度的局部性優化。其中,顯著性權重wn=[w1,w2,…,wn]中第k項的計算公式如下:
(2)

原梯度優化值與顯著化后的梯度優化值如圖3所示。圖中為了便于描述,將句中每個token視為不同梯度項。以句子“the food was great.”為例,梯度維數為5,梯度保留系數為0.6。原梯度值越高則顯著性權重越大,顯著化梯度值后越突出,并且將最小的兩個梯度值置為零。

圖3 原梯度優化值與顯著性梯度優化值直方圖
同時,本文固定FGIM算法的風格干擾系數并舍棄迭代過程。該算法十分依賴于分類器性能,通過有效計算預測標簽和目標標簽之間的損失得到優化梯度,實現風格轉換。而當分類器性能足夠好時,潛在表示第一次梯度優化后往往已被分類器判定為目標風格,這使得后續迭代梯度基本為零。本文認為迭代并不能提供更好效果,因此舍棄。顯著性快速梯度優化算法的偽代碼如下:
算法1 顯著性快速梯度優化算法
輸入:原句n維潛在表示z;預訓練好分類器C;風格干擾系數λ;梯度保留系數μ;目標風格標簽s′;
輸出:梯度優化后的潛在表示z′;
1: 計算顯著性權重w=1+softmax(|▽zL(C(z),s′)|);
2: 計算顯著性優化梯度
g=[g1,g2,…,gn]=λw▽zL(C(z),s′);
3: foriin int((1-μ)n);
4: min{|g1|,|g2|,…,|gn|}=0;
5:i=i+1;
6: end for;
7:z′=z-g;
8: returnz′;
潛在空間的特征高度糾纏,風格干擾的優化梯度過大時易帶來內容的改變,需要進行一定的內容約束。受文獻[23]工作啟發,本文對解碼器的結構進行修改。解碼器通過漸進式的語句融合,整合原句的簡單層次信息和風格干擾后的復雜層次信息,在確保風格轉換精度的同時有效提高內容保留度。
文獻[23]提出的StyleGAN模型以漸進式的方式從低像素到高像素逐步生成圖像信息。低像素上主要影響粗粒度特征,例如臉型、發型、眼鏡等;高像素上主要影響細粒度特征,例如發色、膚色等。通過affjne變換和卷積在不同像素進行影響,從而有效控制圖像屬性。模型漸進式生成器結構如圖4所示。

圖4 StyleGan漸進式生成器結構框圖Fig.4 Architecture of StyleGan generator
本文結合Transformer的多頭注意力機制特性,即不同頭注意力關注不同的空間層次信息,模仿StyleGAN模型的生成器結構將解碼器改為單頭注意力Transformer層和4頭注意力Transformer層的堆疊。解碼器結構如圖5所示。在單頭注意力Transformer層上,對原句潛在表示進行內容級別的低層信息提取;在4頭注意力Transformer層上,對風格干擾后潛在表示進行多層次信息提取。以漸進式風格融合的方式,在低層次加強內容約束,并且在高層次保留了風格干擾效果,實現較好的內容與風格平衡的文本風格轉換。
圖5中,以“the salad was fresh.”為例進行積極-消極的情緒風格轉換。在顯著化風格干擾算法后,對具有目標風格的潛在表示z′解碼對應得到生成句“the food was terrible.”,損失了部分主語信息。因此,我們在第一層Transformer中輸入原潛在表示z,獲取簡單語義信息,同時在第二層Transformer中獲取具有目標風格的復雜語義信息。通過這種漸進式的解碼提高對原句內容的保留程度,輸出性能更好的風格轉換句“the salad was terrible.”。

圖5 Balance-CTAT漸進式解碼器結構框圖
3 實驗
為了檢驗提出算法的有效性,本文在一臺計算資源相對豐富的服務器上進行了驗證實驗。該服務器的硬件配置為Intel?CoreTM i7-8750HQ的CPU,GTX1060的GPU,以及 8 GB的運行內存。軟件配置為Windows 10家庭中文版操作系統,配有CUDA10.2,CUDNN 8.0.1 RC2的深度學習驅動,并使用對應的編程框架Pytorch 0.4。
為了有效對比優化效果,采用的模型參數與文獻[18]相同。在基于Transformer的自編碼器中,嵌入維度、潛在表示維度均設置為256,簇大小為128。Transformer中前饋網絡的內部維數設置為1 024。標簽平滑參數ε設置為0.1。分類器由兩個線性層搭建而成,尺寸分別為100和50。顯著性快速梯度優化算法的風格干擾系數、梯度保留系數分別為6和0.6。采用優化器Adam,初始學習率是0.001。訓練周期數為200。
這里,采用Yelp數據集來進行驗證。Yelp餐廳評論數據集,包含積極、消極和中立情感。將情感視為一種風格,作為正負情感轉換任務的語料庫。文本風格轉換領域的經典數據集,便于對比各模型性能。
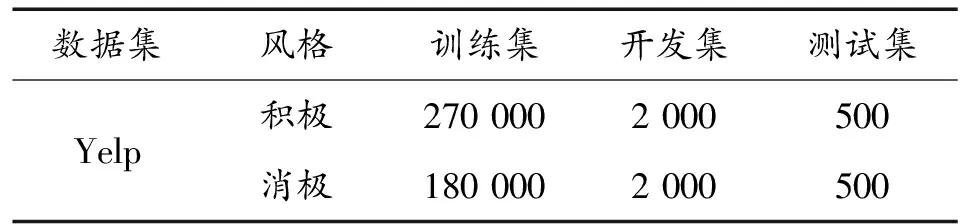
表1 Yelp數據集統計信息 /句
為了評價提出的方法的有效性,在此采用以下3個指標來評價:
1) 風格轉換精度Acc。衡量語句轉換到目標風格的準確性,數值越大性能越好。本文用訓練集數據對FastText[27]分類器進行訓練,用于測試模型生成句的風格準確性。
2) 內容保留度BLEU。衡量模型生成語句與目標句的相似性,數值越大性能越好。本文用multi-bleu計算模型生成句和人工編寫的參考句之間的相似度。
3) 幾何平均值GM。衡量模型的整體性能,用acc、bleu的幾何平均數綜合評估模型,數值越大性能越好。
同時,提出的方法還與Cross[8]、CTAT[18]、FGST[28]模型進行對比研究。實驗結果如表2所示。其中粗體表示指標相對最優值。

表2 Yelp數據集實驗結果(%)
由表2可知,相較于Cross模型,CTAT、FGST、Balance-CTAT模型的綜合性能更好,特別是在風格轉換精度上有很大提升。主要是對抗網絡強制分離風格和內容不能很好地處理復雜語義信息,而對潛在表示整體進行處理更易保留原句語義。在風格分類器性能良好的情況下,風格的表現力強,轉換的針對性也相對較強。
對比CTAT模型,FGST、Balance-CTAT模型顯著提高了內容保留度,有較好的綜合性能。兩個模型都是以可接受的程度犧牲部分風格轉換精度,提高了內容保留程度。說明語句信息高度糾纏,風格和內容作為其中的兩個特征關系緊密、難以簡單分割,仍存在對風格轉換精度和內容保留度間的取舍問題。
對比FGST模型,Balance-CTAT模型在內容保留度提升效果有限,3-gram、4-gram BLEU分數表現更好,如表3所示。FGST模型通過內容判別器預測輸出詞的字包(Bag-of-Word)特征進行內容約束,對長距離的單詞預測表現較弱。而本文模型對潛在表示整體信息進行處理,受語句長度的影響較小,在較長的句子上表現較好。

表3 FGST和Balance-CTAT模型的N-gram BLEU分數(%)
4 結論
針對傳統CTAT模型模型存在性能不穩定的問題,特別是較大程度風格轉換時易添加復雜信息,使得生成語句較為混亂,構建了Balance-CTAT模型。在提出的模型中,創新型漸進式融合思想應用于文本風格轉換,用多頭注意力代替卷積,融合不同層次的語句信息。同時,通過顯著性風格干擾和漸進式風格融合實現轉換句的內容與風格平衡表示。提出的模型與Cross、CTAT、FGST模型進行對比,并以風格轉換精度Acc、內容保留度BLEU、幾何平均值GM進行了評價。實驗結果表明:在Yelp數據集上,提出的方法具有明顯的優勢。可以有效提高內容保留度和流暢度,實現較好的綜合性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科學大眾(2022年11期)2022-06-21 09:20:52
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
臺聲(2016年2期)2016-09-16 01:06:53
