云存儲網絡映射密文搜索的惡意域名檢測仿真
2021-12-10 09:07:18陳曉飛
計算機仿真 2021年11期
陳曉飛,姚 翔,賈 勇
(1.新疆工程學院信息工程學院,新疆烏魯木齊830023;2.新疆師范大學化學化工學院,新疆烏魯木齊830054)
1 引言
“惡意域名”是指傳播蠕蟲、病毒、木馬,或從事釣魚欺詐等違法活動的網站域名。有些網站的惡意域名可能會出現在郵件,短信或者廣告中,通過讓人迷惑的文字和圖片來吸引用戶點擊。如果用戶設備訪問這些惡意域名,則可能導致木馬植入、病毒感染或泄露個人信息等風險。由于安全設備和安全軟件只能保護自己免受外部威脅,所以如果內部設備受到感染,所有內部設備都會直接暴露給攻擊者。如不及時處理,將會造成嚴重后果。
基于目前存在的問題,已有許多學者進行了關于惡意域名檢測方法的研究,彭成維[1]等人研究了一種基于域名請求伴隨關系的惡意域名檢測方法,該方法主要通過挖掘域名請求之間潛在的時空伴隨關系進行惡意域名檢;臧小東[2]等人研究了基于AGD的惡意域名檢測方法,該方法通過聚類關聯,提取每一個聚類集合中算法生成域名,以對惡意域名進行檢測。
上述方法雖然具有一定的惡意域名檢測效果,但是存在檢測準確性低的問題,為此設計一個云存儲網絡映射密文搜索的惡意域名檢測方法,以解決目前惡意域名檢測上存在的問題。
2 云存儲網絡映射密文搜索的惡意域名檢測方法設計
2.1 獲取基礎數據
在對云存儲網絡映射密文搜索的惡意域名檢測前,獲取基礎數據[3]。全局歷史數據獲取內容如下所示:

表1 全局歷史數據獲取
然后對原始流量數據包進行過濾篩選,預處理過程如圖1所示。

圖1 預處理模塊處理流程
2.2 數據特征提取
在上述基礎數據獲取的基礎上,對數據特征進行提取。特征量的提取就是把無法識別的原始數據轉化成可以識別的特征量,其是惡意域名[4]檢測中非常重要的一步,主要內容如下所示。
2.2.1 時間特征提取
在時間特征提取上,為分析域名狀態隨時間的變化情況,將某一時間段設置為觀叉窗口,是指數據分析前后的一段時間,每個域名都會在觀察窗口中選擇數據。每一字段的數據可以按照時間順序形成一個觀測序列[5]。將觀測序列分成固定的時間段(小時),對同一域名在固定的時間段內的狀態變化進行統計[6]。并提取了3個特征:
第一個特征是活躍期。在觀察窗口中,域名第一次查詢到最后一次查詢的時間間隔稱為活動時間,它反映了域名在觀察窗口中的活躍時間的長短;
另一個特征是平均每日訪問量,能夠反映域名的“自由”狀態[7](即域名沒有被查詢到)或已被訪問過(即熱門域名);
最后一個特征是其日常行為具有相似性,一天中對域名的查詢量隨時間而變化,這種特點能夠反映出域名是否每天都有類似的時序[8]。
基于上述分析,以天為單位,將觀測窗口中時間序列設置為每天00:00開始,23:59結束。當一個域名被查詢了n天時,其計算表達式為

(1)
式中,di,j代表第i天和第j天之間的歐式距離。
在此基礎上對時間序列進行標準化處理,得到時間序列的均值與方差,表達式為

(2)
式中,std(T)代表時間序列T的標準差,mean(T)代表時間序列T的均值。
2.2.2 響應報文特征提取
在此基礎上,對響應報文特征提取[9],預先解析的IP地址集的分散程度[10]。其表達式為

(3)

基于上述過程完成對網絡中數據特征的提取,為惡意域名檢測仿真提供基礎。
2.2.3 域名的特征提取
相對于良性域名,惡意域名的字符串組成一般比較雜亂,常常包含數字和特殊符號“-”和“_”,并會出現間隔,惡意域名字符串通常不匹配良性域名。主要提取內容如表2所示。

表2 詞匯特征
在此基礎上,主要分析子域名中制度的平均隨機程度,其表達式為

(4)
式中,S代表子域名集合,p(i,x)代表字符x在第i個子域在子域名S中占得比例。
依據上述過程完成特征數據的提取。
2.3 惡意域名檢測實現
依據上述特征提取結果,采用隨機森林方法[11]獲取惡意停靠域名,以實現對惡意域名的檢測[12]。具體過程如下所示:
Step1:在對停靠域名處理過程中,對全部域名進行過濾處理,其過濾函數為

(5)
式中,ε(ci)代表函數過濾值,ω代表過濾系數。
Step2:依據上述過濾函數的計算,獲得待分類的域名數據。采用隨機森林算法對惡意域名與正常域名[13]進行分類,分類過程如圖2所示。

圖2 惡意域名與正常域名分類過程
具體內容如下,假設待訓練的樣本集為E,其表達式為

(6)
式中,Gini(E)代表樣本集的基尼系數度量值,pl代表樣本集隸屬類別于l的樣本數量。
Step3:通過關鍵字的數字值來確定關鍵字落在哪個分區上[14],然后通過數字范圍來確定數據庫中哪些記錄可能滿足搜索條件,從而獲得基礎數據。
在此基礎上,計算數據屬性的最優分裂點[15],并生成對應的決策樹,計算公式為

(7)
式中,κ(F)代表對應的分類樹,Nf代表決策樹生成參數。
Step4:惡意域名檢測,一般情況下,正常域名不會與多個域名共享相同的IP地址,而惡意域名則有所不同,很多域名經常會共享同一個 IP地址。對于whois信息的完整性,一般情況下正常域名是全面描述的,惡意域名基本上不會填寫whois信息。利用同一 IP的 IP域數之和與其自身whois信息完整性的比值作為特征,可以區分正常域和惡意域。根據以上的分析,進行分類,表達式為

(8)

與此同時,正常域名和惡意域名的 IP地址隨時間的增長而變化,而正常域名的 IP地址變化不大,惡意域名的 IP地址變化不大。隨著時間的推移,正常域名的這種特征值逐漸減小,惡意域名的特征值逐漸增大并趨于1,設置該特征的表達式為

(9)
式中,IPchT代表域名的變化速度,IPchN代表域名的變化時間。
依據上述過程,完成惡意域名的分類。
Step4:在此基礎上,對分類結果進行測試,測試函數如下所示
ι(U)=testκ(F)*f
(10)
式中,ι(U)代表測試函數值。
通過上述計算完成該算法的計算,獲得惡意域名,以此完成云存儲網絡映射密文搜索的惡意域名檢測。
3 實驗分析
3.1 實驗環境
為驗證此次研究方法的有效性,進行此次實驗,本實驗的實驗環境如下:
1)虛擬機:10.0.0 VMware工作站;
2)OS:Ubuntu14.0464位;
3)編譯程序、Eclipse3.8;
4)網絡仿真:Mininet2.2。
通過Mininet 虛擬網絡平臺和 Floodlight 控制器搭建的實驗環境來驗證惡意域名檢測方法的有效性該試驗的具體部署和配置如下:
1)將64位 Ubuntu14.04 LTS安裝到64位win7操作系統的 VMware虛擬機上,創建兩個網卡,其中一個連接外部網絡,另一個則作為空閑資源備用。
2)在 Ubuntu系統中,使用 Python調用 Mininet庫來創建虛擬網絡拓撲結構。
3)在 DNS重定向服務器上作為 DNS解析器運行 Python程序,以向發送 DNS查詢包的主機返回 DNS響應包。
3.2 實驗數據來源以及實驗對比指標
從網絡安全聯盟和PhishTank等網站獲取已知惡意域名,鑒于惡意域名的持續時間較長,選取500個具有以上特征的惡意域名作為黑名單。將 Alexa排名較高的域名用作普通域名是合理的,因為 Alexa是基于三個月積累的域名訪問信息的,將該數據用作白名單是合理的。白名單是以 Alexa排名的1162個域名為標準構建的,使用 dig,nslookup,whois,bgp表示每個域名的網絡屬性特征。為節省實驗時間,對實驗數據預處理,其表達式如下所示

(11)
式中,x*代表歸一化的數據,x代表當前原始數據,xmin代表當前數據屬性中最小數據值,xmax代表當前屬性中最大數據值。
經歸一化處理后的數據進行整理,共整理出1050條數據,將其分為50、100、150、200、250、300條數據,共進行6次進行實驗。
實驗主要將文獻[1]中的基于域名請求伴隨關系的惡意域名檢測方法、文獻[2]中的基于AGD的惡意域名檢測方法與此次研究的方法對比,對比三種方法的準確率、召回率與檢測時間。
準確率用以下公式進行計算:

(12)
式中,TP樣本分類準確率,FP代表將負樣本分類到正樣本的參數。
召回率的計算方法如下所示
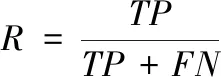
(13)
式中,FN代表假負類,將正樣本分類錯誤的參數。
3.3 檢測準確率對比
分別采用此次研究的檢測方法與文獻[1]方法、文獻[2]方法對惡意域名檢測準確率進行分析,得到對比結果如圖3所示。
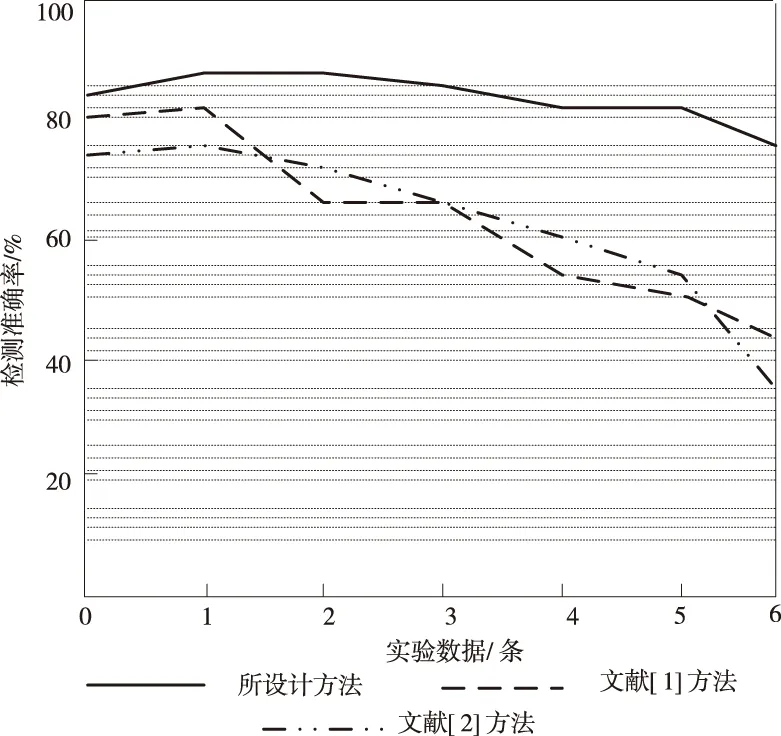
圖3 檢測準確率對比
分析圖3可知,此次研究的云存儲網絡映射密文搜索的惡意域名檢測方法與文獻方法的檢測準確率均隨著檢測數據量的增加而降低。經過對比可知,此次研究得檢測方法的準確率雖然有下降的趨勢,但是變化較小。而文獻方法的檢測準確率下降較快,沒有此次研究的檢測方法的檢測效果好。
3.4 召回率對比
圖4為三種方法的召回率對比結果。

圖4 召回率對比
通過圖4可知,此次研究的云存儲網絡映射密文搜索的惡意域名檢測方法的召回率效果均保持在較好的水平,受到數據多少的影響較小。而兩種文獻方法的召回率受到數據多少影響較大,隨著數據量的增多,召回率下降速度也變快。由此可見,設計方法的召回率更高,檢測精確度較好。
3.5 檢測時間對比
分析三種方法對惡意域名的檢測耗時,得到對比結果如圖5所示。

圖5 檢測時間對比
通過圖5可知,文獻[1]、文獻[2]檢測方法的檢測時間在數據量多與少的情況下,都較此次研究檢測方法的檢測時間長。
綜上所述,此次研究的檢測方法有效提高了檢測準確性與召回率,并減少了檢測時間,較傳統方法的應用效果更好。原因是,此次研究的檢測方法預先對數據進行了采集與預處理,并采用隨機森林算法對惡意域名進行了檢測,從而獲得了較好的檢測效果,具備一定的實際應用意義。
4 結束語
為了提升網站抵御病毒攻擊的能力,設計了一個云存儲網絡映射密文搜索的惡意域名檢測方法,通過實驗驗證得出,所提方法不僅提高了檢測的準確性以及召回率,還減少了檢測時間。通過惡意域名檢測,可以發現網絡上的惡意域以及與這些域通信的客戶端主機。研究結果可以幫助安全團隊理解當前網絡中的安全威脅,并采取有針對性的措施,應對主機可能感染的惡意軟件。通過對惡意域名的關聯分析,進一步發現僵尸網絡信息和攻擊者信息,這對于保護網絡安全具有很好的參考價值。
但是,由于研究時間的限制,試驗拓撲過程過于簡單,不具備復雜的網絡環境和真實的通信流。外來可以建立一個復雜的網絡拓撲,引入一些實際的網絡流量來驗證系統的性能和防御效果。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
電子制作(2019年15期)2019-08-27 01:12:00
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
