基于PSO和GA混合優(yōu)化的FCM算法
2021-12-11 07:58:14呂冰垚姜志翱寧春玉
關(guān)鍵詞:優(yōu)化實(shí)驗(yàn)
呂冰垚,姜志翱,寧春玉
(長(zhǎng)春理工大學(xué) 生命科學(xué)技術(shù)學(xué)院,長(zhǎng)春 130022)
乳腺鉬靶圖像分割方法有邊緣檢測(cè)法、區(qū)域生長(zhǎng)法及模糊聚類(lèi)算法等,其中FCM算法是一種結(jié)合無(wú)監(jiān)督聚類(lèi)和模糊集合概念的分割技術(shù)。1981年,Bezkek引入模糊加權(quán)指數(shù)m提出了標(biāo)準(zhǔn)的FCM算法[1],通過(guò)對(duì)目標(biāo)函數(shù)求解極值進(jìn)行圖像分割,原理簡(jiǎn)單易實(shí)現(xiàn)。在此之后,人們以此為基礎(chǔ)進(jìn)行了許多改進(jìn),現(xiàn)已成為圖像分割領(lǐng)域最主要的方法之一。
Zhao等人[2]提出了一種隸屬度加權(quán)的KFCM圖像分割方法,引入局部空間信息,結(jié)合像素的鄰域來(lái)增強(qiáng)算法的抗噪性。Das等人[3]將改進(jìn)的遺傳算法與FCM相結(jié)合,在彩色圖像中分割效果較好,但未涉及醫(yī)學(xué)圖像的分割。Bai等人[4]提出了一種直覺(jué)無(wú)中心的FCM聚類(lèi)(ICFFCM)算法,用直覺(jué)模糊隸屬函數(shù)來(lái)定義像素到聚類(lèi)的相似性,解決了圖像分割中的模糊性和聚類(lèi)過(guò)程中的不確定性等問(wèn)題,抗噪性好但耗時(shí)長(zhǎng)。Elazab等人[5]用高斯徑向基核函數(shù)替換了模糊聚類(lèi)中的歐氏距離,提出了自適應(yīng)正則化基于核的FCM算法,對(duì)低噪聲圖像分割的效果較好,分割噪聲比較大的圖像時(shí)容易造成圖像的缺失。Han等人[6]提出了獅群算法優(yōu)化的FCM圖像分割方法,算法的效果較好。徐路等人[7]首先采用最大類(lèi)間方差的方法劃分多個(gè)區(qū)間,然后以各自區(qū)域內(nèi)的像素值為依據(jù)決定聚類(lèi)中心初始值,減少了迭代次數(shù),縮短了運(yùn)行時(shí)間。
為了克服FCM算法對(duì)初始聚類(lèi)中心十分敏感,容易陷入局部最優(yōu)的問(wèn)題[8],以及僅基于GA的FCM聚類(lèi)(GA-FCM)和僅基于PSO的FCM聚類(lèi)(PSO-FCM)容易出現(xiàn)早熟的現(xiàn)象,本文將具有全局搜索能力的PSO與GA混合優(yōu)化算法與具有局部搜索能力的FCM聚類(lèi)結(jié)合起來(lái),提出了基于PSO與GA混合優(yōu)化的FCM聚類(lèi)算法,將其用于乳腺鉬靶圖像的分割,對(duì)多幅圖像進(jìn)行分割實(shí)驗(yàn),并將分割結(jié)果與FCM、GA-FCM和PSOFCM算法進(jìn)行比較。
1 基本理論
1.1 FCM算法


1.2 GA算法
GA算法是一種根據(jù)生物進(jìn)化思想產(chǎn)生的隨機(jī)搜索算法,基于選擇、交叉、變異過(guò)程產(chǎn)生高質(zhì)量的優(yōu)化解。由于其強(qiáng)大的全局搜索能力、簡(jiǎn)單的操作和較強(qiáng)的魯棒性,成為各種問(wèn)題領(lǐng)域的搜索和優(yōu)化工具。
GA算法從隨機(jī)生成的初始種群開(kāi)始其搜索過(guò)程,初始種群中的個(gè)體被稱(chēng)為染色體。GA算法主要通過(guò)染色體交叉(概率PC)、變異(概率Pm)來(lái)實(shí)現(xiàn),為了評(píng)估染色體的適應(yīng)性,引入了適應(yīng)度函數(shù)。適應(yīng)度在遺傳算法中是用來(lái)衡量種群在進(jìn)化過(guò)程中所達(dá)到的最優(yōu)值的一個(gè)概念。在種群的迭代中依據(jù)適應(yīng)度大小選擇一定比例的個(gè)體作為后代的群體,然后繼續(xù)迭代計(jì)算直到產(chǎn)生最優(yōu)染色體。
GA算法的具體步驟如下:
(1)生成初始種群,并計(jì)算適應(yīng)度;
(2)根據(jù)適應(yīng)度進(jìn)行選擇、交叉和變異,生成新種群;
(3)計(jì)算新種群的適應(yīng)度;
(4)當(dāng)算法達(dá)到進(jìn)化的最大迭代次數(shù)或達(dá)到設(shè)定的閾值,即種群的適應(yīng)度沒(méi)有改進(jìn)時(shí),算法停止,否則跳轉(zhuǎn)到第(2)步;
(5)產(chǎn)生適應(yīng)度最好的種群。
1.3 PSO優(yōu)化算法
PSO算法是一種基于種群尋優(yōu)的搜索算法。其概念簡(jiǎn)單,易于實(shí)現(xiàn),并且具有良好的尋優(yōu)能力。
PSO算法的解對(duì)應(yīng)于所求問(wèn)題的解空間中的一個(gè)粒子。每個(gè)粒子都有對(duì)應(yīng)的速度和位置以及由目標(biāo)函數(shù)決定的適應(yīng)度值,粒子在解空間中的每次迭代都是以當(dāng)前找到的較好解為依據(jù)尋找下一個(gè)解。第i個(gè)粒子表示為Xi=(xi1,xi2,…,xid),它經(jīng)歷過(guò)的最好位置(有最好的適應(yīng)度值)記為Pi=(pi1,pi2,…,pid),也稱(chēng)為pbesti。群體所有粒子在迭代中的最好位置用符號(hào)pg表示,也稱(chēng)作gbest,粒子i的速度用Vi=(vi1,vi2,…,vid)表示。對(duì)于每一代粒子,其在第d維(1≤d≤D)的速度和位置根據(jù)如下方程變化:
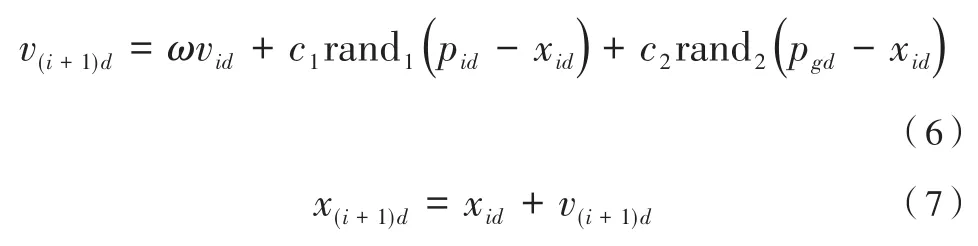
其中,ω為慣性權(quán)重,通常是從0.9線性減小到0.2;c1和c2為加速常數(shù);rand1和 rand2為兩個(gè)在[0,1]范圍內(nèi)變化的隨機(jī)函數(shù)。
PSO算法的具體步驟如下:
(1)生成初始種群,在允許范圍內(nèi)隨機(jī)產(chǎn)生初始粒子的位置和速度,每個(gè)粒子當(dāng)前的位置記為Pi,并計(jì)算適應(yīng)度,此時(shí)全局最好點(diǎn)為個(gè)體中的最好點(diǎn),記為pg;
(2)利用式(6)和式(7)更新每一個(gè)粒子的速度和位置并計(jì)算適應(yīng)度,若好于該粒子當(dāng)前的個(gè)體極值,則將Pi設(shè)置為該粒子的位置,且更新個(gè)體極值。如果所有粒子的個(gè)體極值中最好的好于當(dāng)前的全局最好點(diǎn)pg,更新全局最好點(diǎn),將該粒子的位置設(shè)置為pg;
(3)當(dāng)算法的迭代次數(shù)達(dá)到了最大次數(shù)或者滿足最小的誤差要求時(shí),停止迭代,否則跳轉(zhuǎn)到第(2)步;
(4)輸出最優(yōu)解。
2 基于PSO和GA的FCM算法
本文提出了PSO和GA混合優(yōu)化FCM的分割算法,這個(gè)算法以全局最優(yōu)個(gè)體將GA與PSO有機(jī)地聯(lián)系在一起,既有PSO算法中的“記憶”功能,保留了上一代中的最優(yōu)解,又有GA算法中交叉變異等操作算子,迭代過(guò)程中既包括了GA運(yùn)算也包括了PSO運(yùn)算,提高了算法的穩(wěn)定性。克服了僅基于單一GA或PSO優(yōu)化的FCM聚類(lèi)算法所存在的早熟問(wèn)題。
算法步驟如下:
(1)給定類(lèi)別數(shù)c,模糊指數(shù)m,群體規(guī)模N,學(xué)習(xí)因子c1和c2,交叉概率PC,變異概率Pm,慣性權(quán)重ω,閾值ε,最大迭代次數(shù)T,粒子變化范圍。
(2)初始化隨機(jī)生成N個(gè)聚類(lèi)中心,形成N個(gè)第1代粒子。每個(gè)粒子的當(dāng)前位置為其pbesti,當(dāng)前種群所有粒子中的最好位置為gbest。用式(8)計(jì)算適應(yīng)度值,此時(shí)每個(gè)粒子的最優(yōu)適應(yīng)度個(gè)體為其自身,群體中最優(yōu)適應(yīng)度個(gè)體為所有粒子中適應(yīng)度值最大的粒子。
(3)用公式(6)和公式(7)對(duì)每個(gè)粒子進(jìn)行速度和位置更新,依據(jù)交叉概率PC,變異概率Pm,進(jìn)行選擇、交叉和變異操作,產(chǎn)生下一代的粒子群。
(4)用公式(8)計(jì)算新粒子群中每個(gè)個(gè)體的適應(yīng)度值,先與個(gè)體上一代比較,若大于上一代適應(yīng)度值,則取代上一代個(gè)體成為pbesti,且適應(yīng)度值為個(gè)體最優(yōu)適應(yīng)度值,否則保持原樣。
(5)再與群體最優(yōu)個(gè)體適應(yīng)度比較,若大于群體最優(yōu)個(gè)體適應(yīng)度值,則用該個(gè)體替代全局最優(yōu)個(gè)體gbest,其適應(yīng)度值為此時(shí)群體最優(yōu)適應(yīng)度值,否則群體最優(yōu)和群體最優(yōu)適應(yīng)度值保持原樣。
(6)迭代次數(shù)T=T+1。
(7)當(dāng)算法達(dá)到進(jìn)化的最大迭代次數(shù)或設(shè)定的閾值ε,即種群的適應(yīng)度沒(méi)有改進(jìn)時(shí),算法停止,否則,跳轉(zhuǎn)到第(3)步。
(8)產(chǎn)生適應(yīng)度最好的種群,即適應(yīng)度最好的初始聚類(lèi)中心。
(9)在FCM中輸入產(chǎn)生的初始聚類(lèi)中心進(jìn)行圖像分割。
(10)輸出分割結(jié)果。
算法流程如圖1所示。
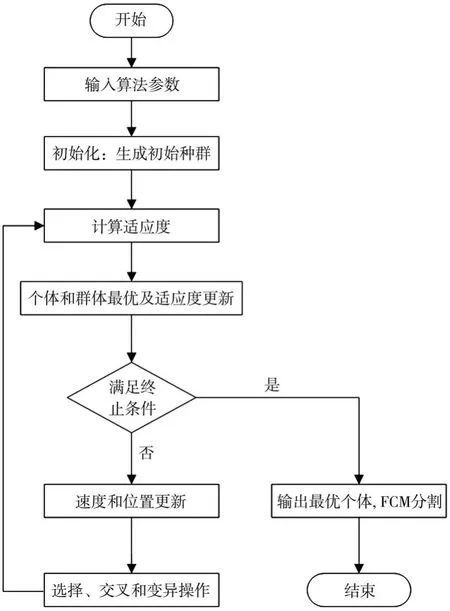
圖1 優(yōu)化FCM算法流程圖
對(duì)于FCM算法來(lái)說(shuō),不同的聚類(lèi)中心產(chǎn)生的分割效果是不同的,其目標(biāo)函數(shù)式(3)越小分割效果越好,而在混合優(yōu)化算法中不同聚類(lèi)中心的適應(yīng)度越大越好,因此可使用式(3)的倒數(shù)來(lái)評(píng)價(jià)每個(gè)粒子的適應(yīng)度,定義如下的適應(yīng)度函數(shù):

其中,k為常數(shù);J(U,V)為FCM的目標(biāo)函數(shù)。J(U,V)越小就代表聚類(lèi)效果越好,則粒子適應(yīng)度f(wàn)(xi)就越高。
3 實(shí)驗(yàn)結(jié)果分析與討論
為了驗(yàn)證本文提出的改進(jìn)算法的性能,進(jìn)行了MATLAB仿真實(shí)驗(yàn),選用大量的DDSM數(shù)據(jù)庫(kù)中的乳腺鉬靶圖像進(jìn)行實(shí)驗(yàn),選取了其中四幅圖像進(jìn)行說(shuō)明和驗(yàn)證。將本文算法與FCM、GAFCM、PSO-FCM三種算法進(jìn)行比較,實(shí)驗(yàn)參數(shù)的設(shè)置如下:種群規(guī)模30,聚類(lèi)數(shù)目為4、迭代次數(shù)為 50、收斂精度為 10(-5)、模糊加權(quán)指數(shù)m=2、交叉概率PC=0.7、變異概率Pm=0.3、c1=c2=1.49。
圖2到圖5分別為四組乳腺鉬靶圖像分割實(shí)驗(yàn)的結(jié)果,在每組實(shí)驗(yàn)結(jié)果中有(a)原始圖像、(b)FCM 分割結(jié)果、(c)GA-FCM 分割結(jié)果、(d)PSO-FCM分割結(jié)果、(e)本文算法分割結(jié)果五張圖片。
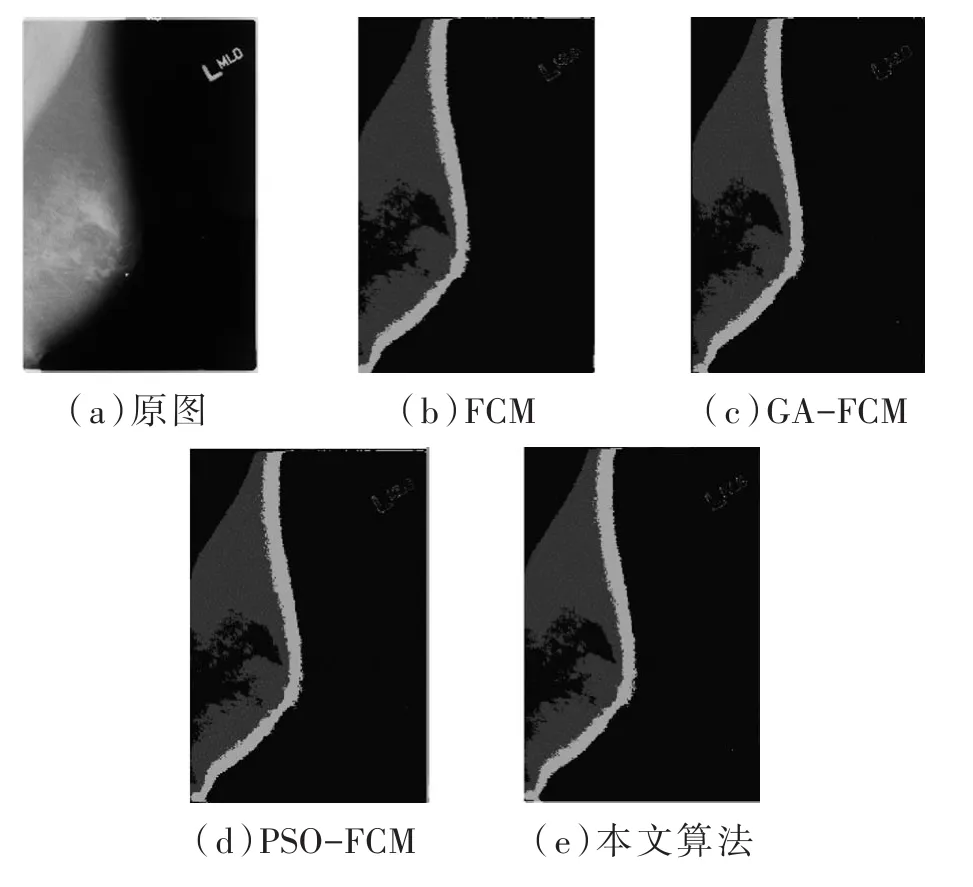
圖2 第一組惡性腫塊圖像分割實(shí)驗(yàn)
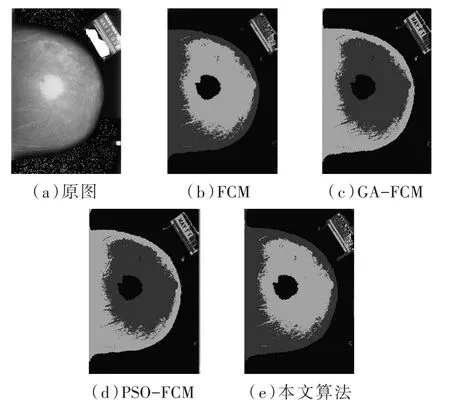
圖3 第二組惡性腫塊圖像分割實(shí)驗(yàn)
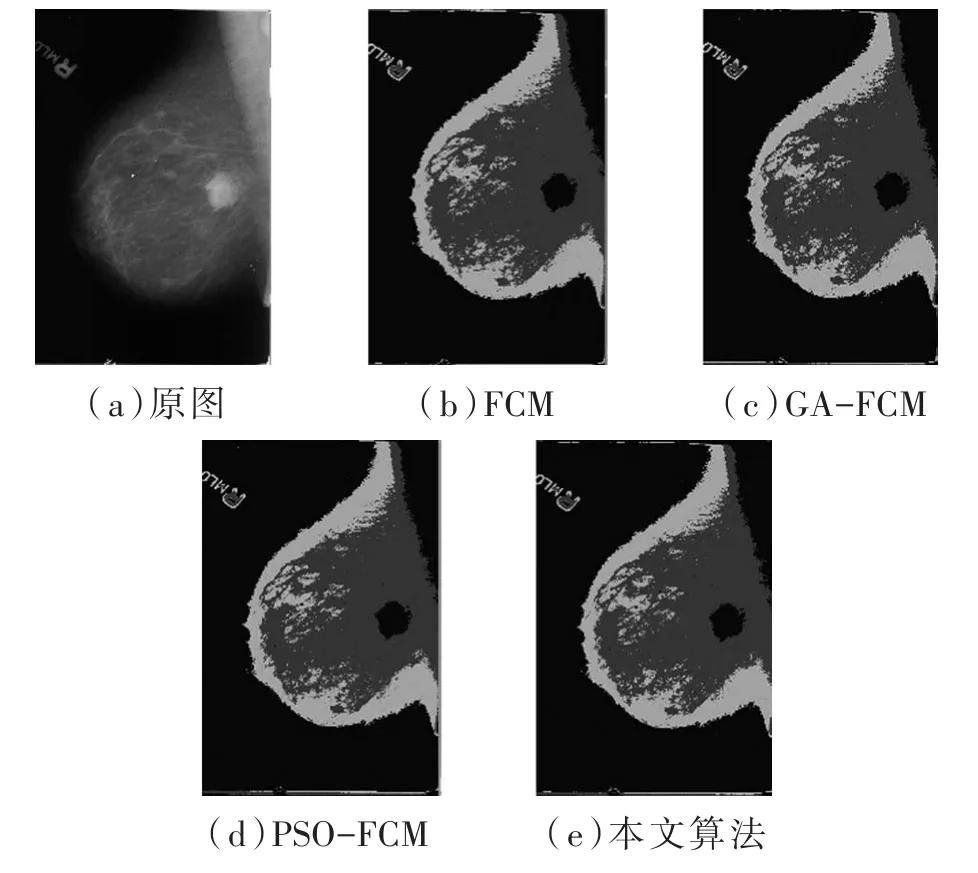
圖4 第三組惡性腫塊圖像分割實(shí)驗(yàn)
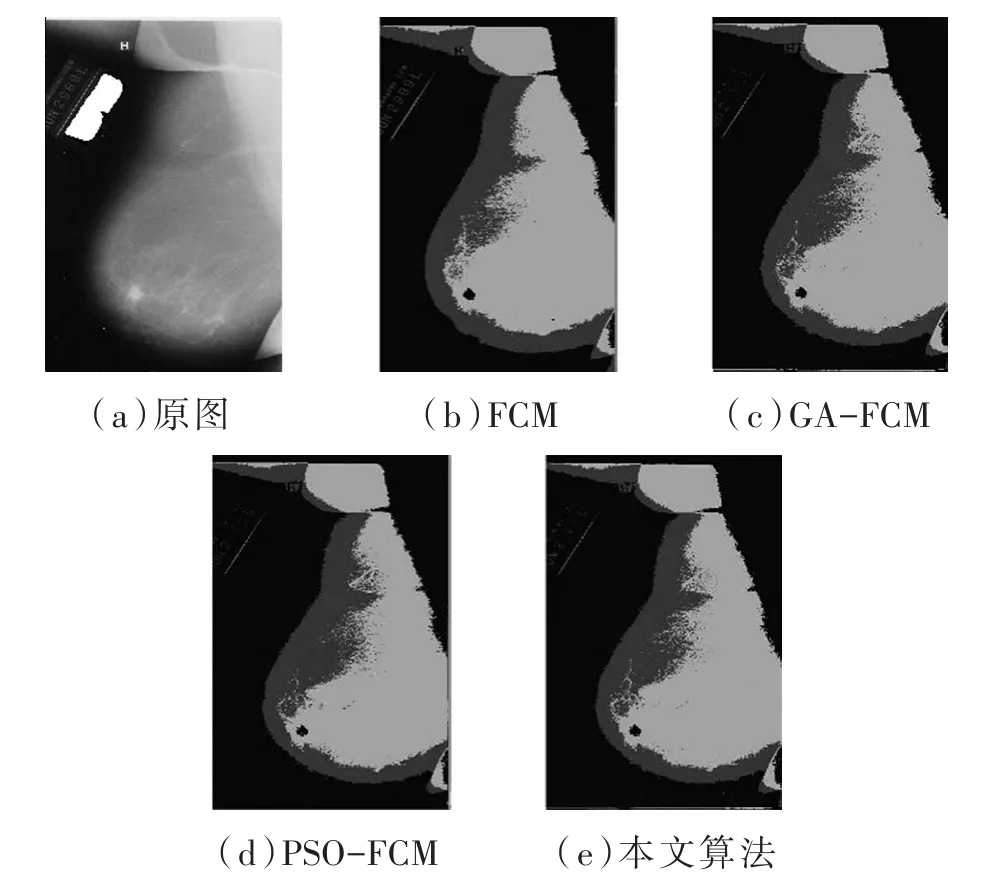
圖5 第四組惡性腫塊圖像分割實(shí)驗(yàn)
為了獲取一個(gè)定量的實(shí)驗(yàn)結(jié)果比較,引入有效性評(píng)價(jià)函數(shù)。其中最具代表性的是緊致性分割系數(shù)Vpc和分離性分割熵Vpe,它們分別定義如下[10]:
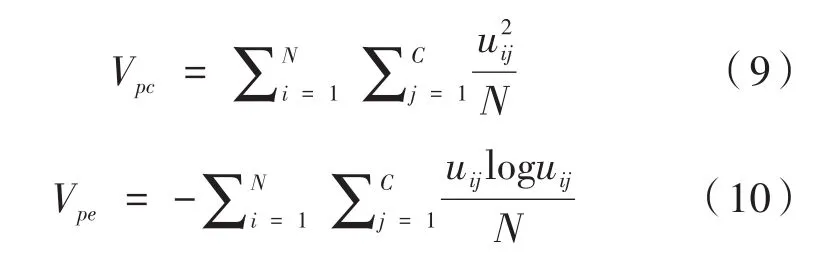
在FCM的分割結(jié)果中,會(huì)得到最終的隸屬度矩陣,并以此為標(biāo)準(zhǔn)按照隸屬度最大原則將像素劃分到應(yīng)屬于的類(lèi)。隸屬度矩陣的模糊性越小,即每個(gè)像素的最大隸屬度越接近于1,說(shuō)明像素屬于這一類(lèi)的概率越大,分割效果也就越好,像素更有可能被正確歸類(lèi)。反映到Vpc和Vpe的計(jì)算中時(shí),也就是Vpc越大,分割效果越好;同時(shí)Vpe越小,分割效果越好。
表1為四組惡性腫塊圖像的四種分割算法的客觀評(píng)價(jià)指標(biāo)數(shù)據(jù)。
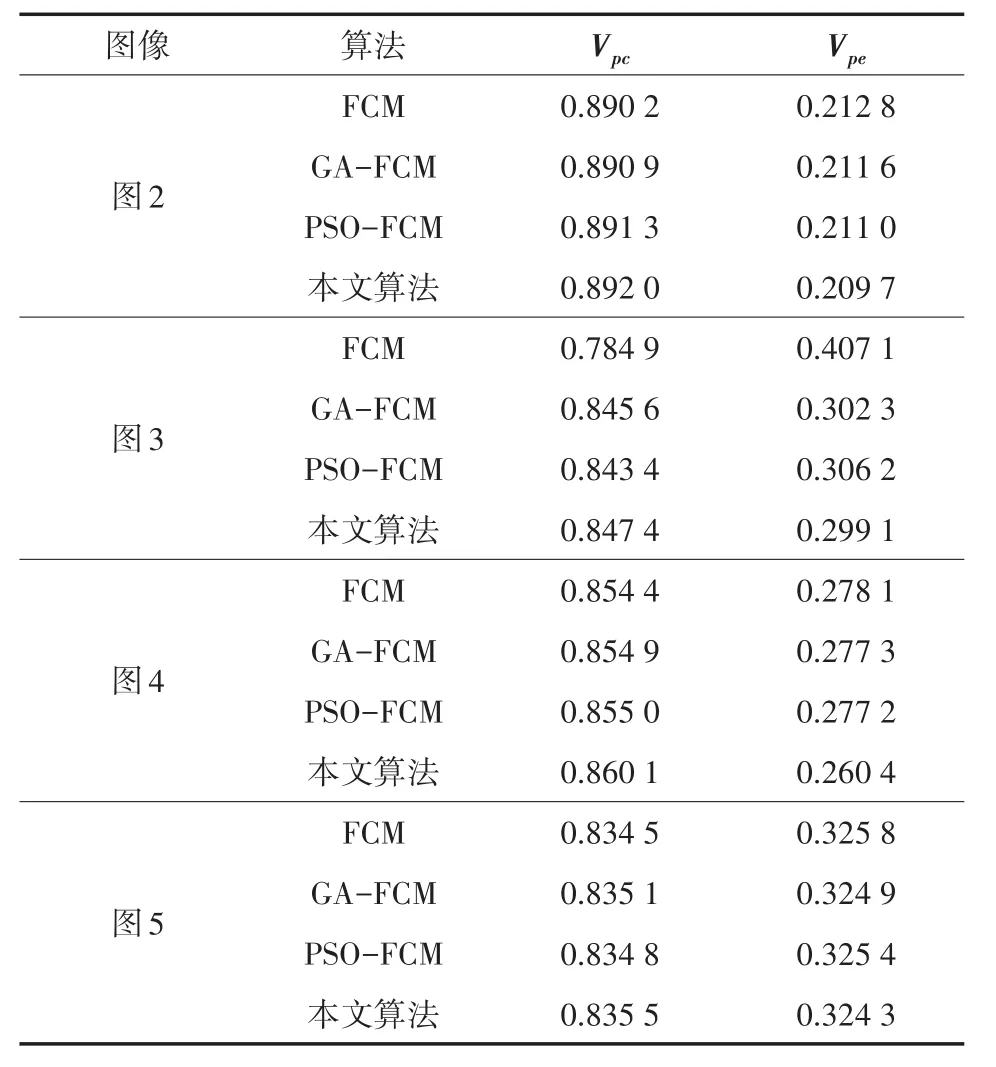
表1 聚類(lèi)分割客觀評(píng)價(jià)指標(biāo)
從表1中可以看出本文算法和其他三種算法相比,Vpc最大且Vpe最小,提高了聚類(lèi)的精度,因此在圖像聚類(lèi)分割方面有更好的表現(xiàn)能力。這是由于FCM算法在選取初始聚類(lèi)中心時(shí)是隨機(jī)選取的,容易使迭代過(guò)程陷入局部最優(yōu)解,因此把進(jìn)化尋優(yōu)算法引入到模糊聚類(lèi)分割中,可達(dá)到全局尋優(yōu)、快速收斂的效果。
4 結(jié)論
本文采用PSO和GA混合優(yōu)化FCM算法進(jìn)行全局搜索,保留了PSO和GA各自的獨(dú)立性,克服了FCM容易陷入局部極小值的問(wèn)題。對(duì)乳腺鉬靶圖像的分割實(shí)驗(yàn)結(jié)果表明,本文算法得到的隸屬度矩陣模糊性小于其他算法,能夠更準(zhǔn)確地表明像素點(diǎn)應(yīng)該屬于哪一類(lèi),分割結(jié)果的可靠性更高,取得的分割效果更精確,能夠準(zhǔn)確地分離出腫塊,為后續(xù)的醫(yī)療診斷與圖像處理提供有力的支持,提高疾病的診斷準(zhǔn)確性。
猜你喜歡
小獼猴智力畫(huà)刊(2022年9期)2022-11-04 02:31:42
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
