基于注意力機制的卷積神經網絡在圖像分類中的應用
2021-12-14 08:05:56陳耀文譚曉玲
科學技術創新 2021年34期
陳耀文 譚曉玲
(重慶三峽學院,重慶 404130)
1 概述
圖像分類指的是根據某種算法判定輸入的圖像的類別,一般的圖像分類步驟包括:圖像預處理、圖像特征提取和圖像類別判定。卷積神經網絡(Convolutional neural network,CNN)模仿了生物的視知覺機制,解決了傳統人工提取特征的繁瑣工程,實現了從數據中自動地提取特征。在ImageNet 2012 競賽上,AlexNet[1]遠超傳統機器學習方法,使用8 個卷積網絡層達到了15.3%的TOP-5 圖像分類錯誤率。而隨著對CNN 在圖像分類領域研究的深入,研究者發現CNN 的特征提取能力可以隨著網絡的深度和寬度而增加。VGGNet[2]探索了更深地網絡,設計了可以重復堆疊的卷積網絡模塊,通過堆疊這些網絡模塊構建網絡,并提出多層網絡模型中特征的等級會隨著堆疊層的深度變的更加豐富。InceptionNet[3]探索的更寬的網絡,提出了分支設計,在一個網絡層使用多種卷積核提取多層次特征,使網絡具有更強的表達能力,同時多分支疊加的大通道輸出相比無分支在計算消耗上更少。ResNet[4]引入的殘差結構解決了網絡加深導致的網絡退化問題,使得深度網絡在學習不到新特征時可以通過殘差結構實現恒等映射,保證網絡性能不會變差,并且殘差結構對各層之間的微小差異更加敏感,特征學習能力更強。
然而,在實際任務中,受限于計算能力,常常無法構建足夠深和足夠寬的網絡去處理和記憶全部的信息,而需要對信息進行選擇,因此,研究者嘗試將注意力機制引入到CNN 中。注意力機制是當前深度學習領域比較流行的一個概念,其模仿人的視覺注意力模式,每次只關注與當前任務最相關的源域信息,使得信息的索取更為高效。注意力機制已在語言模型、圖像標注等諸多領域取得了突破進展,并且研究者發現將注意力機制與CNN 結合的可以讓網絡關注重要特征,提高重要特征關注點表示,并抑制不必要的特征,減弱不必要特征關注點表示,并且緩解了CNN 傳統卷積操作的局部感受野缺乏全局信息層次的理解能力,導致提取特征的特征差異性的問題,進一步提升CNN的特征提取能力[22]。
本文主要框架如下:在第二章中本文對CNN 注意力模型機制進行了介紹,并且基于典型的幾種CNN 注意力模型詳述了CNN 注意力模型的發展方向和各模型的特點;然后在第三章中本文結合第二章的分析對CNN 注意力模型存在的挑戰進行了概述;最后在第四章對本文進行了總結概括。
2 CNN 注意力模型
CNN 注意力模型是在CNN 的基礎上發展而來,如圖1 所示,CNN 主要包括輸入層,隱含層和輸出層[23]。在輸入層將圖像輸入到網絡中,然后在隱含層通過卷積操作或池化操作實現特征的傳遞,學習圖像的分布式特征表示,最后由輸出層將學習到的分布式特征表示映射到樣本標記空間完成分類輸出。隱含層中特征傳遞的載體為特征圖,在圖像分類領域中特征圖的儲存形式一般為C×H×W,也即通道數×圖像高度×圖像寬度。
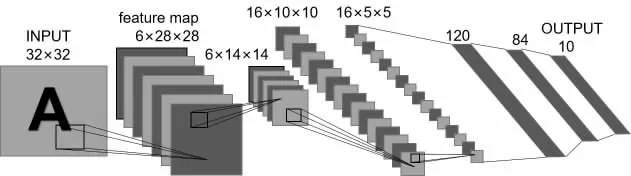
圖1 CNN 網絡
CNN 注意力模型在上圖的基礎上對特征圖進行了注意力學習,如圖2 所示,CNN 注意力模型可以分為全局上下文建模、依賴關系轉換和特征融合三個步驟。在全局上下文建模部分對信息進行壓縮;在依賴關系轉化部分,基于壓縮的信息學習注意力權重矩陣;最后在特征融合部分,權重矩陣通過與特征圖相乘或相加等方式得到具有注意力的特征圖。
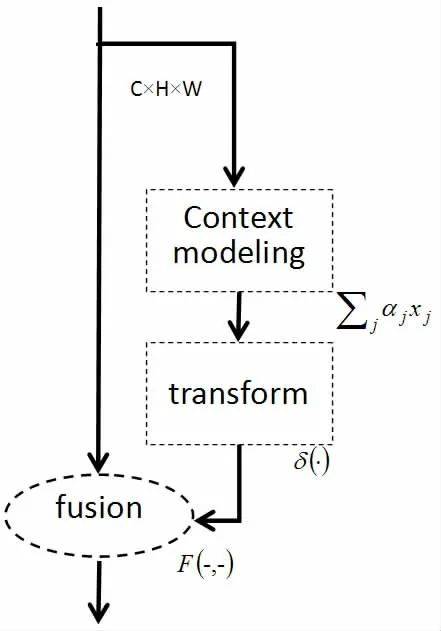
圖2 注意力模型
注意力機制決定了權重矩陣的學習,可分為軟性注意力(Soft Attention)、硬性注意力(Hard Attention)和自注意力(Self Attention):軟性注意力機制是指在選擇信息的時候,不是從N個信息中只選擇1 個,而是對每個分配0-1 之間的權重,計算N個輸入信息的加權平均,再輸入到神經網絡中計算。相對的,硬性注意力就是指從N 個信息中選擇1 個或幾個信息,對每個信息權重分配為0 或1,相比軟性注意力速度更快,但是會損失一部分信息。自注意力機制是基于輸入項自身進行區域權重學習,進行權重分配,減少了對外部信息的依賴,更擅長捕捉數據或特征的內部相關性,所以大部分CNN 注意力模型都引入了自注意力機制。
2.1 不同作用域的注意力模型
按注意力作用在特征圖上的維度可以分為:通道域注意力、空間域注意力、卷積域注意力和混合域注意力。前兩種CNN 注意力模型主要關注了特征圖上的某一個維度,學習這一維度上的元素之間的關系。通道域注意力模型捕獲了通道間的不同特征表示之間的關系,學習了通道上的注意力權重,然后依據注意力權重判斷通道上特征的重要程度,從而關注更具代表性的特征,提高網絡分類性能。Momenta 等人[5]提出的壓縮激活網絡(Squeeze-and-Excitation Networks,SENet),通過向CNN 基礎網絡中加入一個SE 模塊,利用CNN 中的通道依賴性建模通道間的相互依賴關系,自適應的校準通道的特征響應。如圖3 中的SE模塊結構,輸入的特征圖C×H×W 經過一個全局平均池化和兩層全連接(Full Connect,FC)后,再由sigmoid 激活函數[24]激活,輸出一個1×1×C 范圍在[0,1]的通道權重,最后與特征圖相乘實現增強重要特征,削弱不重要的特征,使特征提取具有更強的指向性。與通道域注意力模型相似,空間域注意力模型學習了特征圖空間像素之間的關系,區別在于通道域注意力模型更關注特征的不同表示,而空間域注意力模型更關注空間像素之間的長距離依賴,強化空間上的關鍵信息。如Non-local[6]通過對通道域進行壓縮獲取特征圖的空間特征,然后對空間特征進行Softmax 歸一化得到空間域權重,最后與原特征圖相乘得到具有空間域注意力的特征圖。空間轉換網絡(spatial transformer network,STN)[7]引入空間注意力,基于圖像信息去學習一個空間變換矩陣,經過空間變換后生成的圖像局部重要信息可以更好地被卷積框提取出來,從而使網絡更關注這個圖像局部信息。空間轉換機制設計了定位網絡、網格生成器和采樣器三個部分。定位網絡將圖片信息轉換為空間轉換參數,網格生成器根據空間轉換參數學習構建一個采樣網格,最后由采樣器基于特征圖和采樣網格生成新特征圖。
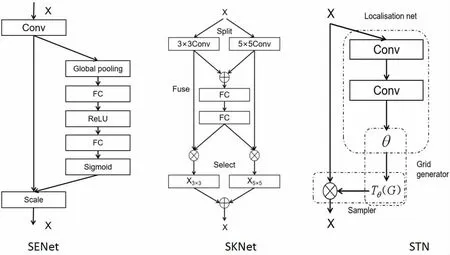
圖3 不同作用域的注意力模型
與通道域、空間域注意力模型不同,卷積域注意力模型不對特征圖直接分配權重,而是對卷積核的元素分配權重,并以此來表示核范圍內的區域重要性。卷積核選擇網絡(Selective Kernel Networks,SKNet)[8]提出了一種機制,即卷積核的重要性,它說明了不同的圖像能夠得到具有不同重要性的卷積核。SKNet 對不同圖像使用的卷積核權重不同,即一種針對不同尺度的圖像動態生成卷積核。網絡主要由Split、Fuse、Select 三部分組成。Split 部分是特征圖經過不同大小的卷積核部分進行卷積的過程,也就是待選擇的卷積核,fuse 部分計算每個卷積核的權重,Select 部分是根據不同權重的卷積核計算后得到的新的特征圖的過程。
上述注意力模型只關注了一個維度的注意力,而混合域注意力模型結合多個維度的注意力,對特征進行重標定,進一步強化關鍵特征。如圖4,卷積塊注意模塊(Convolutional Block Attention Module,CBAM)[9]將通道注意力模塊和空間注意力模塊串行連接,同時對網絡進行打分,得到經過雙重注意力調整的特征圖,這迫使網絡關注更重要的區域特征信息。而瓶頸注意力模塊(Bottleneck Attention Module,BAM)[10]則將通道注意力和空間注意力并行連接,然后用特征圖相加的方式使網絡具有兩個維度的注意力。
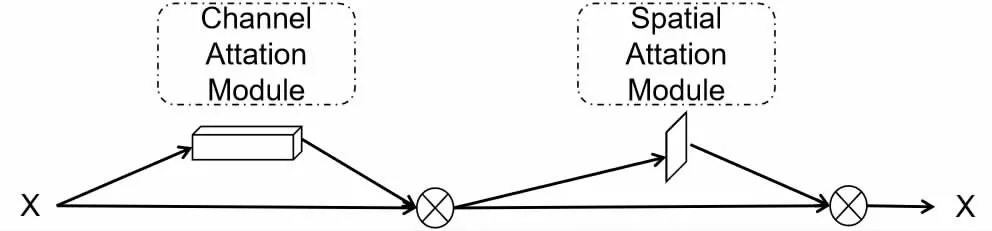
圖4 CBAM
2.2 CNN 注意力模型的發展
雖然只需要在CNN 上添加一個注意力模塊就可以使CNN具有注意力,但是在許多大型CNN 上添加注意力模塊,特別是混合域注意力模塊,仍然會產生大量的計算消耗。針對這個問題,許多研究人員提出了改進方法使網絡在學習注意力的同時具有更少的計算消耗。

此外,許多研究也致力于增強注意力對全局信息的表征能力。GCNET[16]結合了non-local 和SENet,使用簡化的non-local 進行上下文建模后,利用兩個1×1 卷積學習通道上的信息對通道維添加注意力。全局二階池卷積網絡(Global Second-Order Pooling Convolutional Networks,GSoP-Net)[17]提出二維平均池化代替SENet 中的全局平局池化,并引入協方差矩陣表現通道維注意力。雙重注意力網絡(Double Attention Networks,A2net)[18]提出了一種用于收集和分布長距離特征的二階注意力,對全局關鍵特征進行收集再基于另一種注意力機制自適應地將特征分配到對應位置。自校正卷積網絡(Self-calibrated Convolutions Networks,SCNet)[19]提出一種自校正卷積,采用由一個卷積核變換的低維嵌入來校準另一部分中卷積核的卷積變換,自適應地在每個空間位置周圍建立了遠程空間和通道間依賴關系。有效通道注意力網絡(Efficient Channel Attention Networks,ECANet)[20]針對降維操作會削弱通道注意力學習能力的問題,提出了不降維的局部跨信道交互策略。
3 CNN 注意力模型存在的挑戰
注意力模型的出現使得CNN 在包括圖像分類等領域的性能表現進一步提升,并且它有助于克服CNN 中的一些問題,如數據集中類內差距大、類間差距小或者全局空間上局部特征聯系不強導致的分類困難。然而,雖然現在CNN 注意力模型在許多任務上都取得了很好的效果,但是CNN 注意力模型的研究仍然存在一些不足。
首先,目前CNN 注意力模型的研究已經拓展到包括通道、空間、卷積等多個維度,混合注意力也有很好的性能提升,然而在實際問題中,對每個維度都增加注意力來提升網絡性能在計算消耗的約束下是難以實現的,同時,對某些數據集增加多一維注意力并不能明顯提升分類準確率,有時還會導致過擬合現象。因此,如何針對數據集設計注意力機制是一個具有現實意義的問題,可以結合網絡結構搜索的方法,在網絡計算消耗約束下搜索最適合數據集的注意力機制和添加的注意力模塊的數量,自適應的構建注意力模型。
其次,隨著時代發展,三維視頻流的處理(如手勢識別)有了很大的需求,然而目前大部分的注意力網絡研究都是針對二維圖像設計,如何在時間域引入注意力機制,讓網絡更加關注視頻流關鍵幀,和時間域注意力如何與空間域和通道域注意力建立顯性聯系,使網絡具有更強的視頻流處理能力是一個值得探索的問題。
最后,相較于SENet、Non-local 等通過全局池化獲取全局信息的方法,TAM、CGC[21]等方法通過旋轉、局部池化減少了暴力壓縮產生的信息損失,然而這類避免信息損失的方法還有一定的提升空間,需要更加精細的注意力。
4 結論與展望
注意力機制是強化CNN 圖像分類特征提取能力的重要方式之一,并為CNN 圖像分類提供了一定的可解釋性。本文主要介紹了CNN 注意力模型的主要機制和發展過程,并基于現有的CNN 注意力模型分析了CNN 注意力模型存在的不足和可能的研究方向。希望本文可以為未來的CNN 注意力模型研究提供一定的參考。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中國衛生(2015年9期)2015-11-10 03:11:12
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
河南科技(2014年23期)2014-02-27 14:19:15
