油氣勘探大數據分析在中亞盆地優選中的創新應用
2021-12-16 05:43:18張科張義娜
石油與天然氣地質 2021年6期
張科,張義娜
油氣勘探大數據分析在中亞盆地優選中的創新應用
張科,張義娜
(中國海洋石油國際有限公司,北京 100027)
隨著數字化時代的到來,石油公司開始重視基礎資料的獲取及整合,不斷加大油氣大數據的分析應用力度,以期從大數據中尋找“大油氣”。然而,以傳統數據統計分析方法研究海量數據的時效性很差,而且有效分析方法和關鍵評價指標缺乏,嚴重制約了油氣勘探行業大數據的深度應用。中亞油氣資源豐富,是中國石油公司實施“一帶一路”國家能源合作戰略的重點地區和現實之選。在戰略選區盆地篩查階段,研究范圍大、周期短、井震資料匱乏,難以開展有效的石油地質分析,無法形成宏觀認識指導決策。為此,引入大數據思維,開展大數據分析,深度挖掘、二次開發數據庫,整合海量多源異構數據,創建中亞戰略選區知識庫,為勘探大數據分析奠定資料基礎;創新油氣勘探數據挖掘技術和大數據分析方法,創建“三位一體”KPI綜合打分模式,優選多個有利勘探潛力盆地,有效指導中亞戰略選區。研究提供了新的思路和對策,從油公司的角度闡述了開展勘探大數據分析的必要性和可行性,具有較好的應用價值和推廣意義。
多學科整合;關鍵參數指標;數據可視化;KPI打分;大數據融合;勘探大數據分析;盆地優選;中亞
中亞地處亞歐大陸腹地,油氣資源豐富、勘探潛力大,是中國油氣資源進口的重要來源之一。在當前“一帶一路”國家能源合作戰略良好態勢下,中國油氣公司進入時機較好,參與機會較多[1-3]。
2000年以來,國際油價跌宕起伏,全球7個大區油氣年均發現儲量約320×108bbl,中亞地區除了在第一個五年的低油價時期有巨量發現之外,在接下來的3個五年中即便處于國際油價上漲周期,新增鉆井工作量和儲量發現也都較少,油氣勘探幾乎處于停滯狀態,錯過了全球油氣勘探快速發展的重要機遇(圖1)。當下國際油價處于快速反彈復蘇期,全球油氣勘探活動隨之加快,同時,中國對外油氣依存度逐年增加,研究中亞油氣資源潛力與進入機會,制定相應獲取策略對中國油氣公司具有重要的指導意義。厘清該區是否仍有較大勘探潛力、是否仍有勘探機會以及機會在哪里,是中亞戰略選區研究的首要目的。從資料調研來看,中亞含油氣盆地多、勘探區塊多、油氣田多、鉆井多,勘探潛力較大。然而,在戰略選區研究階段,缺乏井震數據,無法開展系統有效的石油地質條件分析,只能借助于大型商業數據庫及公開資料,如何有效整合各類資源、快速優選重點盆地、聚焦潛力區帶,是研究的重點和難點[4]。

圖1 2000年以來全球勘探歷年新增儲量與國際油價變化
近年來,隨著數字化時代到來,大數據分析技術日臻成熟。據《2019年中國大數據產業發展白皮書》統計,互聯網、金融、電商和交通領域等行業是大數據應用熱點[5]。目前,大數據在石油能源行業主要應用于生產設備的全時段監控、預測性維護和地震數據等龐大數據的自動化批量處理[6-8]。
大數據的核心是統計學,是一門探究相關性及因果關系和邏輯關系的學科,其相關性的本質使大數據分析應用于油氣勘探海量數據挖掘及分析成為現實。目前,石油企業逐漸從撒網式試用轉變為聚焦突破關鍵技術點,并落腳在設備預測性維護、地震數據和地質油藏數據的快速處理,鉆井過程的智能導向等[9-13]。那么,對油氣勘探行業,如何引入數據挖掘和大數據分析等新技術,深度挖掘基礎數據所蘊含的地質價值,為勘探研究提供數據支持和理論支撐;如何從海量屬性中尋找能夠評價勘探潛力、預測發展趨勢的關鍵屬性,從混沌中探索規律,從規律中尋找方向,并指導勘探研究,是大數據分析在油氣勘探應用領域較好的切入點和契合點[14-18]。
1 研究思路及對策
目前,大數據分析應用于油氣勘探規律的探索尚無成例可循,近年來,筆者在中亞、印尼、英國北海和大西洋兩岸重點盆地等全球多個靶區開展了多盆地排序、多區塊優選、新機會評價等探索性研究,并結合國內外最新研究進展,提出一套研究思路及對策。
數據基礎是通過整合主要商業數據庫而創建的基于GIS的全球油氣勘探數據庫,包含了從宏觀的國家、盆地、區塊到微觀的油氣田、探井等不同級別研究對象的屬性信息。每類研究單元分別有20 ~ 60種屬性,比如,研究區共有探井近5 000口,每口井有62個屬性,包含國家、盆地、油氣田、儲層和作業公司等文本屬性,以及鉆井日期、時長、費用和發現儲量等度量屬性,共計近百萬條屬性。
針對海量基礎屬性,此次研究創新性提出了目標驅動勘探大數據分析“三步走”的思路和對策(圖2)。第一步,多角度解析海量屬性,結合靶區特點,從盆地、區塊、作業公司到油氣田和探井等不同級別進行統計,多形式、多維度呈現油氣勘探現狀,全面描述、摸清家底;第二步,多屬性融合分析要素,將不同級別、不同類型的屬性轉換到以盆地為單元進行分析,交會衍生新屬性;第三步,多參數評價優選關鍵參數指標(KPI,Key Parameter Indicator),對不同種類的參數進行評價,優選滿足戰略選區盆地初篩階段的KPI參數[19-22]。

圖2 油氣勘探大數據分析研究流程
2 數據挖掘HEAD流程
在對目前行業通用數據挖掘技術進行研究的基礎上,結合油氣勘探行業特點,創建了油氣勘探大數據挖掘HEAD(Hydrocarbon Exploration Assisting Data?mining)流程,為大數據分析奠定資料和方法基礎。
HEAD流程將數據挖掘技術定義為對海量數據的采樣,數據特征的探索、關聯、建模和評估,深入挖掘油氣勘探信息所蘊藏的模式和關系。主要包含以下5個環節:①數據采樣,GIS平臺強大的數據處理能力能夠快速實現海量數據采樣,在分析海量數據之后才能發現其蘊含的模式和趨勢,理想的采樣結果包含了用于數據特征探索的完整和全面的數據集;②數據探索,多維度展示預期關系、未預料的趨勢以及各種異常,以期獲得對數據的全面理解和確定有關聯的方向;③關聯性分析,全方位開展多參數相關性分析,探索隱藏的關系,產生有建模價值的假設;④模型建立,對數據進行建模,以搜索能可靠預測所需結果的數據組合;⑤預測評估,比較不同模型,根據統計學原理對模型進行區分和分級,以確定概率分布的可信度。
HEAD流程具備多次迭代、自適應功能,是不斷調整的自循環深度學習過程。該流程有機融合了油氣勘探認識論和辯證法思想,從數據采樣、探索到統計,是從未知探索規律到已知的歸納過程;從數據統計、異常修正到預測評估是對潛力和風險進行辯證分析過程。因此,該流程可探索數據特征、明確分布規律,深入挖掘油氣勘探信息所隱藏的模式和關系。
3 多角度解析勘探目標屬性特征
在GIS數據庫中,不同的研究對象包含多種不同的類型屬性。盆地有已發現可采儲量、剩余可采儲量、待發現資源量、歷年產量、勘探程度(地震、探井數量)、烴源巖(時代、巖性、指標)和儲層(時代、巖性、物性)等共約30種屬性。區塊有不同公司持有數量、歷年授予區塊數量、授標簽字費及發現儲量等共約51種屬性。油氣田有已發現可采儲量、剩余可采儲量、儲集層深度和儲集層層系發現儲量、原油API及儲層物性等共約44種屬性;探井有探井數量、鉆探成效及鉆探費用等共約62種屬性[23-25]。
通過對不同級別勘探目標的海量屬性轉換到盆地級別進行統計,運用多種形式的圖表進行可視化呈現,對油氣勘探現狀進行快速梳理,整體分析、總結規律。
3.1 中亞各盆地已發現油氣分布規律
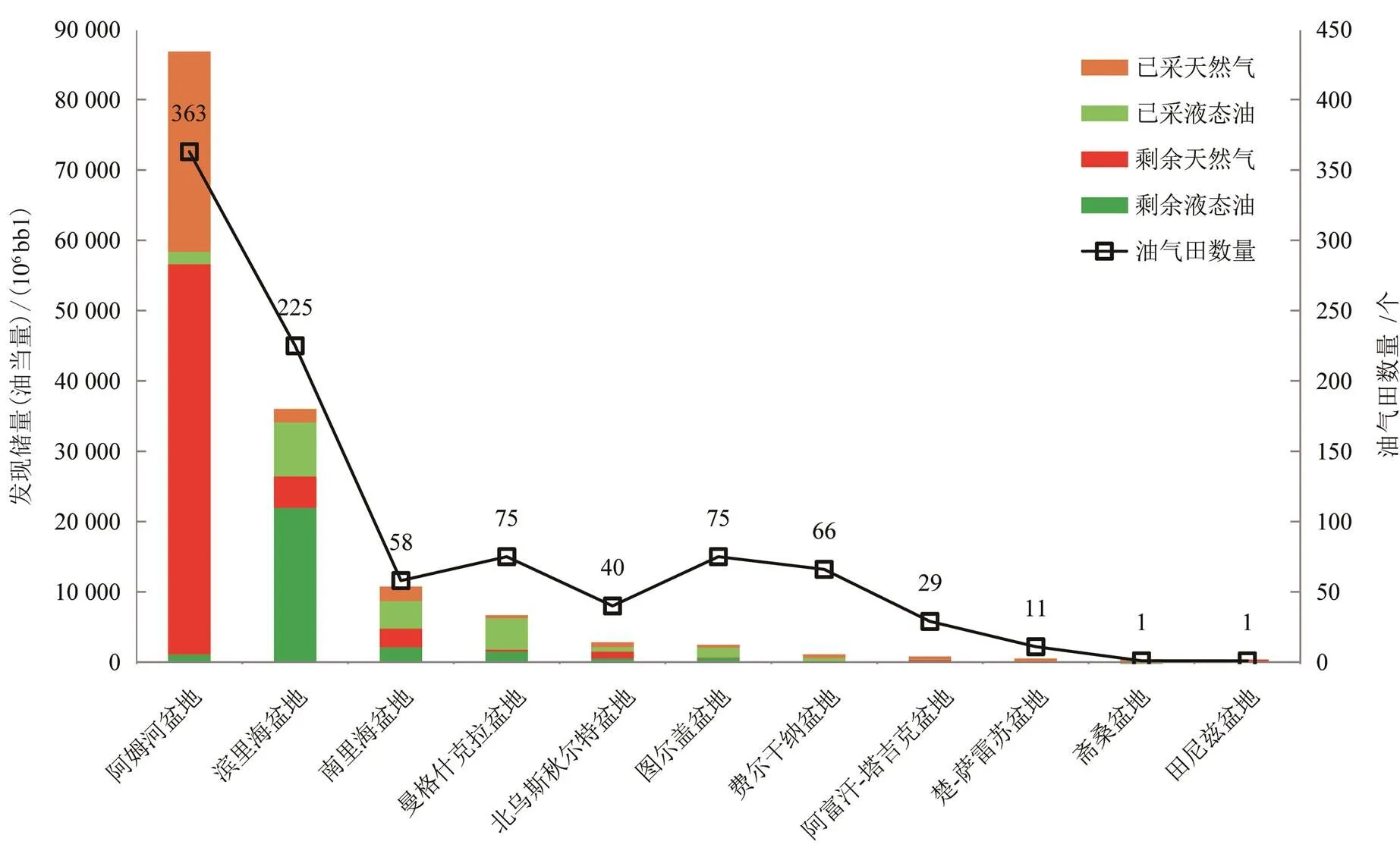
圖3 中亞含油氣盆地已發現油氣可采儲量柱狀圖
中亞沉積盆地有裂谷、前陸和克拉通盆地3類,均有不同程度的油氣發現(圖3),總量較大,11個盆地共發現可采儲量146 200×106bbl油當量(氣多油少,液態油47 800×106bbl,天然氣521×1012ft3),剩余可采儲量規模較大(92 400×106bbl油當量);其次,各盆地間可采油氣富集差異大,阿姆河盆地發現可采儲量最大,占總發現可采儲量的近60 %(約8 700×106bbl油當量),獨占鰲頭,濱里海和南里海盆地次之。
3.2 各盆地歷年授標區塊變化規律
歷史數據統計來看,11個盆地平均每年授標區塊約19個,隨著國際油價起伏,勘探熱點變化較大(圖4),不同勘探程度盆地的授標數量與油價呈較好的相關性,低油價時,勘探以成熟盆地為重點,因為此類盆地勘探風險較低;反之,高油價時,則轉向低勘探程度盆地,因為此類盆地進入成本較低。濱里海盆地在低油價的20世紀90年代為勘探重點;隨著國際油價升高,2004年開始多個盆地均有區塊授予,尤其是2008—2014年,油價高企之時,勘探程度較低的費爾干納盆地(Fergana)和田尼茲盆地(Teniz)也有不同數量的區塊授予;在2015年國際油價下跌之后,熱點又回到濱里海盆地開展老區挖潛;近兩年,油價回升,則又轉向新區,而且授標區塊逐步穩定在40個左右,表明該區油氣勘探正在回升,趨于常態化。
3.3 各盆地油氣田儲量分布規律
從歷年發現油氣田儲量、儲量規模及分布概率等多個角度分析可知,不乏世界級巨型氣田(South Lolotan氣田,36 000×106bbl油當量,2005年發現),但大多數油氣田規模較小,小于50×106bbl油當量的油氣田有711個(圖5),概率分析可知該區發現油氣田的規模概率50為10×106bbl油當量。

圖4 中亞各盆地歷年授標區塊與國際油價變化趨勢

圖5 中亞各盆地已發現油氣田儲量規模分布柱狀圖
3.4 各盆地勘探程度規律
通過對各盆地2D地震和探井總數量的統計,勘探程度如下:①整體勘探程度不高,2D地震密度為(15 ~ 233)×10-3km/ km2,探井密度平均在(2 ~ 10)×10-3口/ km2;②盆地之間差異大,海、陸之間差異大。整體來看,濱里海和南里海盆地勘探程度較高,田尼茲和齋桑盆地(Zaysan)勘探程度最低。
具體而言,該區共有初探井(NFW)約5 000口,1950年以來,年均探井51口,平均探井成功率為33 %。2014年以來,受到國際油價下降影響,油公司減少勘探投入,鉆井數量下降,但成功率有所提高(40 % ~ 70 %)。

圖6 中亞地區累積發現可采儲量及單井平均累積發現可采儲量隨探井數量變化趨勢
從儲量累積發現及單井累積平均發現儲量變化趨勢(圖6)可以將中亞地區油氣勘探分為3個階段:第一階段為初步探索期(1900—1960年),新探區石油地質條件不清楚,勘探規律不明,油氣勘探偶然性強,儲量會有跳躍式遞增現象,同時,單井累積平均發現儲量變化幅度很大,有大發現時會突然增高,發現少則會降低;第二階段為穩定發展期(1961—1979年),隨著勘探研究持續深入,油氣分布規律逐漸明確,中小規模油氣田持續發現,探井平均勘探成效持續變好;第三階段為停滯期(1980年以后),隨著重點盆地勘探程度提高,已知勘探領域及其油氣藏類型基本探明,儲量增長放緩,探井成效逐步降低。綜上分析可以看出,該區需要尋找新的勘探領域以實現勘探的新突破。
4 多屬性融合優選以盆地為單元的關鍵屬性
多屬性融合是將從盆地到探井不同尺度研究單元的多項屬性轉換到以盆地為單元進行分析,不但能夠深度探索物理屬性蘊含的地質價值,而且通過數理轉換,還能夠衍生出新的具有更加直觀、更加綜合指示意義的物理屬性[26]。
4.1 各盆地發現儲量與探井數量融合
通過中亞盆地群已鉆探井與已發現儲量(圖7)交會分析可以將8個盆地分為好、中、差3類含油氣盆地,南里海(South Caspian)、阿姆河(Amu-Darya)、濱里海(Precaspian)和曼格什克拉(Mangyshlak - Ustyurt)等4個盆地不但總發現儲量較高,而且平均單井發現儲量也高(>35×106bbl油當量),屬于Ⅰ類富含油氣盆地;北烏斯秋爾特(North Ustyurt)和南圖爾蓋盆地(Turgay)總發現儲量和平均單井發現儲量較高[(20 ~ 35)×106bbl油當量)],屬于Ⅱ類中等含油氣盆地;其余平均單井發現儲量較小(<20×106bbl油當量)則屬于Ⅲ類較差含油氣盆地。

圖7 中亞各盆地發現儲量與探井數量交會圖
4.2 各盆地油氣田平均儲量與儲量豐度交會
盆地儲量豐度是每千平方公里發現油氣儲量,能夠直接反映盆地石油地質條件,交會分析認為盆地油氣田平均儲量與儲量豐度呈較好的對數正相關(圖8)。阿姆河、濱里海和南里海等3個盆地具有明顯的高儲量豐度和大規模油氣田,勘探成效好。
4.3 盆地勘探趨勢融合
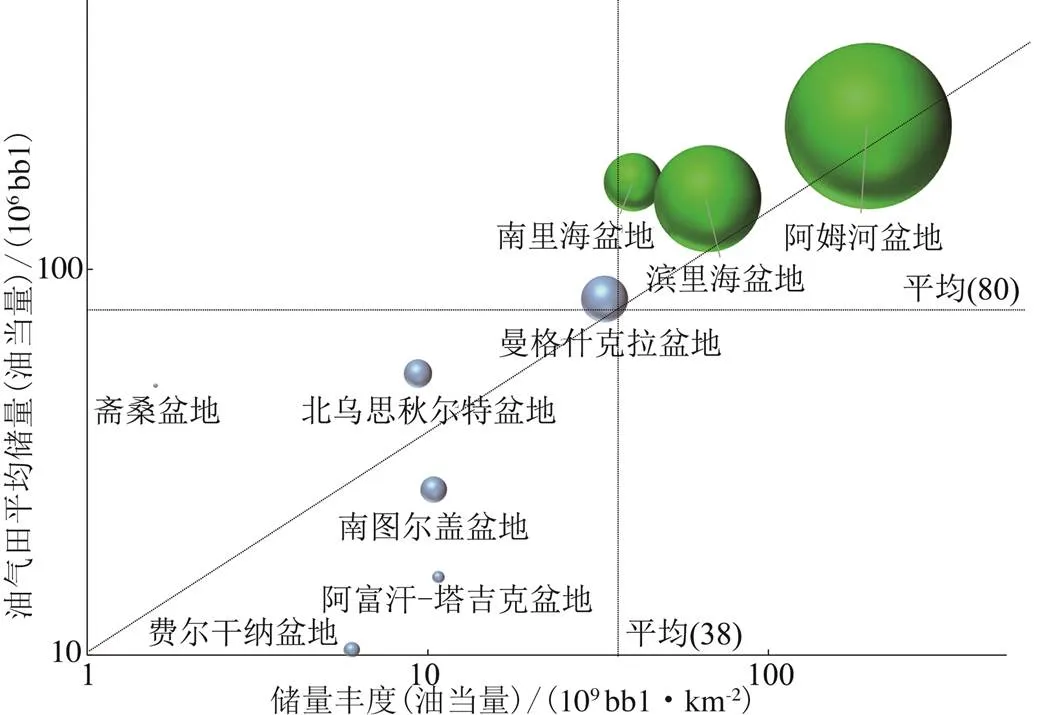
圖8 中亞各盆地油氣田儲量均值與儲量豐度交會圖
勘探趨勢表示隨著鉆探工作量的增加,新發現油氣的概率和規模變化,指示不同勘探階段的鉆探成效。以南里海盆地油氣勘探趨勢為例進行分析(圖9),可以將南里海盆地油氣勘探劃分為初步探索和穩定發展兩個階段。第一階段在2002年之前,油氣勘探規律不清楚,鉆探發現偶然性強,單井平均儲量跳躍大,新增儲量少,為初步探索期;第二階段在2002年以后,在勘探發現層系及圈閉類型等方面逐漸明確,逐步探索不同領域,累積發現儲量有3次較大的遞增,單井儲量基本平穩,為穩定發展階段。可以看出,該盆地目前仍處于上升勘探態勢,勘探潛力較大。

圖9 南里海盆地油氣勘探發現趨勢
4.4 盆地勘探潛力預測
運用規模序列法,通過以濱里海盆地已發現油氣田(235個)為樣本進行級別劃分和分布規律分析[27-29],預測該盆地待發現油氣田約568個,待發現資源量10 037×106bbl油當量,仍有較大勘探潛力,待發現油氣田以中小型為主(圖10)。
5 多參數評價優選KPI
通過單屬性分析和多屬性融合,深入解析了中亞各盆地的油氣發現、區塊熱點、勘探程度、勘探趨勢、財稅條款和石油地質條件等10余項參數。對上述參數進行相關分析,剔除類型相似和相關性較好的參數之后,綜合評價優選出石油地質條件、勘探程度和商業價值3大類共12項KPI參數,作為評價盆地勘探潛力的打分參數[30-36](表1)。
通過對11個盆地12項KPI參數排序,可以看出,每個盆地均有不同的優勢參數,難以從整體上進行評價、排序。
6 “三位一體”綜合打分定量評價勘探潛力
運用隨機森林算法和多元回歸法優選了3大類共12項KPI參數,通過對標國際大型石油公司,結合研究現狀創建了含油氣盆地評價“三位一體”KPI綜合打分排序模式[37-40]。

圖10 中亞濱里海盆地預測待發現資源量分布
“三位一體”模式中的“三位”指石油地質條件、勘探程度和商業價值等能夠反映勘探潛力的3個不同維度,“一體”指盆地綜合勘探潛力。

表1 中亞主要含油氣盆地KPI排序
評分原則是每個盆地總分為100,總權重為1,包含3個大類,石油地質條件是最重要的物質基礎,決定油氣勘探的價值所在,賦值為50 %;勘探程度是總結勘探歷史并預測未來潛力,決定油氣公司勘探信心的強弱,賦值25 %;商業價值隨著國際政治經濟形勢的變化而波動,決定油氣公司與資源國的價值共識,賦值25 %。每項大類權重定為1,所包含的不同KPI賦予從20 %到35 %的不同權重,最終進行加權求和作為盆地總分。
“三位一體”綜合打分模式,是在對海量屬性逐步深入分析的基礎上,根據含油氣盆地客觀情況(石油地質條件),隨著研究深入、工作量增加(勘探程度)以及資源國政策調整所獲得的投資回報(商業價值)為整體進行相對動態的、貫穿從盆地研究到投資全生態鏈的綜合評價體系來預測、打分及排序。
“三位一體”評價模式結合了常用評價體系中專家打分的優點,避免了雷同屬性多次賦值,兼顧地下和地面因素,能夠因地制宜根據靶區級別和規模靈活選取KPI參數,在缺乏一手井-震資料、難以深入開展地質研究取得認識之前,可以做有效賦值、快速排隊,為決策層提供意見和建議。
通過打分將中亞11個主要盆地劃分為3類:分值高于80分的濱里海、阿姆河、南里海和曼格什拉克共4個盆地屬于第一類,潛力較好;分值介于75分到79分的北烏斯秋爾特、阿富汗-塔吉克、費爾干納和圖爾蓋等4個盆地屬第二類,潛力中等;其余4個盆地屬于第三類,潛力較小[32-35]。
7 結論及建議
此次中亞含油氣盆地戰略選區研究中,運用大數據分析思維,通過HEAD挖掘流程和“三步走”策略,逐步優選KPI參數,聚焦研究目標;創建“三位一體”評分方法,多要素兼顧,分層次賦值,階梯式排序,定量化評價,實現了定量化高效評價和可視化快速決策,探索了一套大數據分析打分體系,將新技術應用于傳統油氣勘探領域。
大數據分析有效解決了戰略選區中一手基礎資料缺乏,研究時間緊張以及地質規律認識不清等制約盆地評價的問題,通過對油氣田及探井分析,能夠全面摸清規律,從宏觀上指導研究,在中亞多盆地優選和印尼多個新機會快速排序應用實踐中取得了較好的效果。
油氣勘探大數據最直接的體現是鉆井和地震,相比于地震資料所反映的間接信息,鉆井資料能夠更加真實揭示地下油氣賦存情況,包含巖性、流體和物性(孔、滲),同時也蘊含著作業成本及商業價值信息。因此,深度挖掘、分析以鉆井、油氣田為代表的油氣勘探大數據能為石油公司的宏觀戰略規劃及決策提供最直觀、最有價值的依據[41-44]。另一方面,研究靶區勘探潛力最現實的體現是油氣公司的關注度,隨著企業對“大數據”的認識和應用逐步深入,對數據及數據價值的理解和把握也將更加具體,基礎資料的利用率也將不斷提高,油氣勘探研究的效率也將不斷提高、勘探研究也將持續聚焦。隨著油公司和互聯網公司(Amazon和Google等)合作的增多,此類新技術與石油能源傳統行業跨界聯姻將帶來的巨大潛在價值也值得業界期待[45-46]。
[1] 郭菊娥,王樹斌,夏兵.“絲綢之路經濟帶”能源合作現狀及路徑研究[J]. 經濟縱橫,2015,(3):88-92.
Guo Jue,Wang Shubin,Xia Bing. Current situation and path of energy cooperation in the Silk Road Economic Belt[J]. Longitudinal and horizontal economy,2015,(3): 88-92.
[2] 朱偉林,王志欣,李進波,等.中亞-里海含油氣盆地[M].北京:科學出版社,2016:10-102.
Zhu Weilin,Wang Zhixin,Li Jinbo,et al. Central Asia-Caspian Basin[M]. Beijing: Science Press,2016:10-102.
[3] 王素華,錢祥麟. 中亞與中國西北盆地構造演化及含油氣性[J]. 石油與天然氣地質,1999,20(4):321-325.
Wang Suhua,Qian Xianglin. Tectonic evolution and oil and gas potential of basins in Central Asia and Northwestern China[J].Oil & Gas Geology,1999,20(4):321-325.
[4] 賽迪.2019中國大數據產業發展白皮書[OL].[2019-03-07]. http://www.100ec.cn/detail--6498821.html.
Saidi. White paper on the development of Chinas big data industry in 2019[OL].[2019-03-07].http://www.100ec.cn/detail--6498821.html.
[5] 張科,張義娜. 油氣勘探大數據分析預測西非北段重點盆地勘探潛力[C]//2019年油氣地球物理學術年會論文集.南京:中國地球物理學會,2019:205-209.
Zhang ke,Zhang Yina. Prediction of exploration potential of key basins by big oil & gas data analysis in NW Africa[C]//Proceedings of the academic annual meeting of oil and gas geophysics in 2019.Nanjing:Chinese Geopgysical Society,2019:205-209.
[6] 王喜雙,趙邦六,董世泰,等.油氣工業地震勘探大數據面臨的挑戰及對策[J].中國石油勘探,2014,19(4):43-47.
Wang Xishuang,Zhao Bangliu,Dong Shitai,et al. Challenges and strategies for large seismic exploration data of oil and gas industry[J].China Petroleum Exploration,2014,19(4):43-47.
[7] Feblowitz J.The big deal about big data in upstream oil and gas[J]. Paper & Presentation,2012,10(10):55-64.
[8] 李軍.致密油藏儲量升級潛力不確定性評價方法及應用[J].石油與天然氣地質,2021,42(3):755-764.
Li Jun. Non-deterministic method for tight oil reserves upgrade potential assessment and its application[J].Oil & Gas Geology,2021,42(3):755-764.
[9] 李文魁.淺析大數據在地質礦產中的應用[J].世界有色金屬,2017,(3):52-53.
Li Wenkui. Analysis of the application of big data in geology and mineral resources[J]. World Nonferrous Metals,2017,(3): 52-53.
[10] Seshadri M. Big data Science challenging the oil industry[J].CTO Global Services,2013,11(3):5-12.
[11]吳沖龍,劉剛,張夏林,等.地質科學大數據及其利用的若干問題探討[J].科學通報,2016,61(16):1797-1807.
Wu Chonglong,Liu Gang,Zhang Xialin,et al. Discussion on geological science big data and its applications[J].Scientific Bulletin,2016,61 (16): 1797-1807.
[12]崔海福,何貞銘,王寧.大數據在石油行業中的應用[J].石油化工自動化,2016,52(2):43-45.
Cui Haifu,He Zhenming,Wang Ning. Application of big data in petroleum industry[J]. Automation in Petro-chemical Industry,2016,52 (2): 43-45.
[13] Keith R.Holdaway. Harness oil and gas big data with analytics[M]. Hoboken: Wiley,2014.
[14]王登紅,劉新星,劉麗君.地質大數據的特點及其在成礦規律、成礦系列研究中的應用[J].礦床地質,2015,34(6):1143-2154.
Wang Denghong,Liu Xinxing ,Liu Lijun. Characteristics of big geodata and its application to study of minerogenetic regularity and minerogenetic series[J]. Mineral Deposit,2015,34 (6): 1143-2154.
[15]李朝奎,嚴雯英,肖克炎,等.地質大數據分析與應用模式研究[J].地質學刊,2015,39(3):352-357.
Li Chaokui,Yan Wenying,Shock Yan,et al. Analysis and application mode of geological big data[J]. Journal of Geology,2015,39 (3): 352-357.
[16]何登發,李德生,童曉光,等.中國沉積盆地油氣立體綜合勘探論[J].石油與天然氣地質,2021,42(2):265-284.
He Dengfa,Li Desheng,Tong Xiaoguang,et al. Integrated 3D hydrocarbon exploration in sedimentary basins of China[J].Oil & Gas Geology,2021,42(2):265-284.
[17]鄭嘯,李景朝,王翔,等.大數據背景下的國家地質信息服務系統建設[J].地質通報,2015,34(7):1316-1323.
Zheng Xiao,Li Jingchao,Wang Xiang,et al. Construction of national geological information service system in the age of big data[J]. Geological Bulletin of China,2015,34 (7): 1316-1323.
[18]金宗澤. 油氣勘探開發大數據分析模式的研究[D].大慶:東北石油大學,2015.
Jin Zongze. Research on exploration and production big data analysis model[D]. Daqing:Northeast Petroleum University,2015.
[19] Shastri,Nimmagadda,Torsten,et al. On big data-guided upstream business research and its knowledge management[J]. Journal of Business Research,2018,89(8):143-158.
[20]武明輝,金曉輝,徐旭輝,等.油氣區塊勘探程度劃分方法研究[J].西安石油大學學報(自然科學版),2015,30(4):18-23.
Wu Minghui,Jin Xiaohui,Xu Xuhui,et al. Research of division method for exploration degree of oil and gas blocks[J]. Journal of Xi'an shiyou University (Natural Science Edition),2015,30 (4): 18-23.
[21]基思.霍爾韋德.油氣大數據分析利用[M].北京:石油工業出版社,2017:6-152.
Keith Holward. Analysis and utilization of big oil and gas data[M]. Beijing: Petroleum Industry Press,2017:6-152.
[22]田納新,殷進垠,陶崇智,等.中東-中亞地區重點盆地油氣地質特征及資源評價[J]. 石油與天然氣地質,2017,38(3):582-591.
Tian Naxin,Yin Jinyuan,Tao Chongzhi,et al. Petroleum geology and resources assessment of majors basins in Middle East and Central Asia[J].Oil & Gas Geology,2017,38(3): 582-591.
[23]陳翔,馬迅飛,王學軍,等. 大數據分析技術及其在地震資料處理中的應用與效果[J]. 信息系統工程,2018,(11):98-100.
Chen Xiang,Ma Xunfei,Wang Xuejun ,et al. Large data analysis technology and its application and effect in seismic data processing[J]. Information System Engineering,2018,(11): 98-100.
[24]姜福杰,龐雄奇,姜振學,等.應用油藏規模序列法預測東營凹陷剩余資源量[J].西南石油大學學報,2008,2(30):54-62.
Jiang Fujie,Pang Xiongqi,Jiang Zhenxue,et al. The principle and apply of predicting hydrocarbon resource by reservoir size sequence[J]. Journal of Southwest petroleum university,2008,2(30):54-62.
[25]楊克明. 川西坳陷油氣資源現狀及勘探潛力[J]. 石油與天然氣地質,2003,12(4):322-326.
Yang Keming. Status of oil &gas resources and prospecting potential in western in Sichuan depression[J]. Oil & Gas Geology,2003,12(4):322-326.
[26]張中華,周繼濤.油氣藏最小商業儲量規模計算方法[J].石油與天然氣地質,2015,2(1):148-153.
Zhang Zhonghua,Zhou Jitao. Calculation of the minimum commercial reserves of petroleum reservoirs[J].Oil & Gas Geology,2015,2(1):148-153.
[27]平英奇,申方樂,周南,等. 大數據技術在油氣地質勘探中的應用分析[J]. 科技資訊,2019,17(2):59-60.
Pingyingqi,Shenfangle,Zhou Nan,et al. Application analysis of big data technology in oil and gas geological exploration[J]. Science and technology information,2019,17 (2): 59-60.
[28]諶卓恒,黎茂穩,姜春慶,等.頁巖油的資源潛力及流動性評價方法——以西加拿大盆地上泥盆統Duvernay頁巖為例[J].石油與天然氣地質,2019,40(3):459-468.
Chen Zhuoheng,Li Maowen,Jiang Chunqing,et al. Shale oil resource potential and its mobility assessment: A case study of Upper Devonian Duvernay shale in Western Canada Sedimentary Basin[J].Oil & Gas Geology,2019,40(3):459-468.
[29]宋振響,陸建林,周卓明,等. 常規油氣資源評價方法研究進展與發展方向[J]. 中國石油勘探,2017,22(3):21-31.
Song Zhenxiang,Lu Jianlin,Zhou Zhuoming,et al. Research progress and future development of assessment methods for conventional hydrocarbon resources[J]. China Petroleum Exploration,2017,22 (3): 21-31.
[30]張長寶,羅東坤,魏春光.中亞阿姆河盆地天然氣成藏控制因素[J]. 石油與天然氣地質,2015,36(5):766-773.
Zhang Changbao,Luo Dongkun,Wei Chunguang. Controlling factors of natural gas accumulation in the Amu Darya Basin,Central Asia[J]. Oil & Gas Geology,2015,36 (5): 766-773.
[31]崔璀,鄭榮才,王強,等. 阿姆河盆地卡洛夫-牛津階碳酸鹽巖儲層沉積學特征[J]. 石油與天然氣地質,2017,38(4):792-804.
Cui Liang,Zheng Rongcai,Wang Qiang,et al. A sedimentology study of carbonate reservoirs in Carlov-Oxford stage,Amu Darya Basin[J]. Oil & Gas Geology,2017,38 (4): 792-804.
[32]余一欣,殷進垠,鄭俊章,等. 中亞北烏斯丘爾特盆地油氣富集規律與勘探潛力[J]. 石油與天然氣地質,2016,37(3):381-386.
Yu Yixin,Yin Jinyuan,Zheng Junzhang,et al.Hydrocarbon accumulation rules and exploration potential in the North Ustyurt Basin[J]. Oil & Gas Geology,2016,37 (3): 381-386.
[33]聶明龍,吳蕾,孫林,等. 阿姆河盆地查爾朱階地及鄰區鹽相關斷裂特征與油氣地質意義[J]. 石油與天然氣地質,2013,34(6):803-808.
Nie Minglong,Wulei,Sun Lin,et al. Salt-related fault characteristics and their petroleum geological significance of Zarzhu terrace and its adjacent areas,the Amu Darya Basin[J].Oil & Gas Geology,2013,34 (6): 803-808.
[34]李智鵬,許京國,焦濤,等. 如何運用大數據技術優化石油上游產業[J]. 石油工業計算機應用,2015(1):8-12,3.
Li Zhipeng,Xu Jingguo,Jiao Tao,et al. How to use big data technology to optimize the upstream oil industry[J]. Computer Applications of Petroleum,2015 (1): 8-12,3.
[35]林茂,塔依爾·伊布拉音,許濤,等. 大數據時代勘探云建設模式探索[J]. 計算機系統應用,2015,24(5):26-31.
Lin Mao,Tayer Ibrain,Xu Tao,et al. Exploration of cloud construction model in the era of big data[J]. Application of Computer Systems,2015,24 (5): 26-31.
[36]張進鐸,張俊,李華松,等. 大數據時代的專業型數據庫建設與應用[J]. 信息技術與信息化,2016,(6):32-37.
Zhang Jinduo,Zhang Jun,Li Huasong,et al. The construction and application of professional databases in big data era[J]. Information Technology and Informatization,2016,(6): 32-37.
[37]王晶晶,施冬,王文惠. 油氣資源數據管理及應用系統開發[J]. 中國管理信息化,2017,20(3):120-122.
Wang Jingjing,Shidong,Wang Wenhui. Oil and gas resource data management and application system development[J]. China Management Informatization,2017,20 (3): 120-122.
[38]檀朝東,項勇,趙昕銘,等. 基于大數據的油氣集輸系統生產能耗時序預測模型[J]. 石油學報,2016,37(S2):158-164.
Tan Chaodong,Xiang Yong,Zhao Xinming,et al. Energy consumption predictionand application in oil and gas gathering and transferring system based on large data[J]. Acta Petrolei Sinica,2016,37 (S2): 158-164.
[39]凡玉梅,趙慶飛,張英利.相似油田定量篩選的方法及應用[J].油氣藏評價與開發,2021,11(5):766-771.
Fan Yumei,Zhao Qingfei,Zhang Yingli. Quantitative screening methods of similar oil fields and their application[J]. Petroleum Reservoir Evaluation and Development,2021,11(5):766-771.
[40]盧歡,牛成民,李慧勇,等.變質巖潛山油氣藏儲層特征及評價[J].斷塊油氣田,2020,27(1):28-33.
Lu Huan,Niu Chengmin,Li Huiyong,et al. Reservoir feature and evaluation of metamorphic buried-hill reservoir[J]. Fault-Block Oil & Gas Field,2020,27(1):28-33.
[41]吳鈞,于曉紅,王權,等. 松遼盆地古龍頁巖油勘探開發全息智能生態系統設計與開發[J]. 大慶石油地質與開發,2021,40(5):181-190.
Wu Jun,Yu Xiaohong,Wang Quan,et al. Design and development of holographic intelligent ecosystem for exploration and development of Gulong shale oil in Songliao Basin[J]. Petroleum Geology & Oilfield Development in Daqing,2021,40(5):181-190.
[42]姜立富,徐中波,張章,等. 基于大數據分析的海上多層油田精細開發實踐[J]. 石油地質與工程,2021,35(2):44-49.
Jiang Lifu,Xu Zhongbo,Zhang Zhang,et al.Fine development practice of offshore multi-layer oil field based on big data analysis[J]. Petroleum Geology And Engineering,2021,35(2):44-49.
[43]洪太元,程喆,許華明,等. 四川盆地大中型氣田形成的主控因素及勘探對策[J]. 石油實驗地質,2021,43(3):406-414.
Hong Taiyuan,Cheng Zhe,Xu Huaming,et al. Controlling factors and countermeasures for exploring large and medium-sized gas fields in Sichuan Basin[J]. Petroleum Geology & Experiment,2021,43(3):406-414.
[44]張科,趙汝敏,齊凱,等. 海外低勘探區預探井深度預測難點及對策[J].特種油氣藏,2014,21(2):57-60.
Zhang Ke,Zhao Rumin,Qi Kai,et al. The difficulties and countermeasures of depth prediction for exploratory well in oversea low exploration degree area[J]. Special oil and gas reservoirs,2014,21(2):57-60.
[45]田軍,王清華,楊海軍,等. 塔里木盆地油氣勘探歷程與啟示[J]. 新疆石油地質,2021,42(3):272-282.
Tian Jun,Wang Qinghua,Yang Haijun,et al. Petroleum exploration history and enlightenment in Tarim basin[J]. Xinjiang Petroleum Geology,2021,42(3):272-282.
[46]胡文革. 塔河碳酸鹽巖縫洞型油藏開發技術及攻關方向[J]. 油氣藏評價與開發,2020,10(2): 1-10.
Hu Wenge. Development technology and research direction of fractured-vuggy carbonate reservoirs in Tahe Oil field[J]. Reservoir Evaluation and Development,2020,10(2): 1-10.
Application of big data analytics to hydrocarbon exploration for favorable basin selection in Central Asia
Zhang Ke,Zhang Yina
(,100027,)
With the advent of the digital era,oil companies have invested more in obtaining and integrating basic data,and constantly improved the utilization of big data analytics,as an emerging trend,in oil and gas industries,with a view to discovering “big oil and gas”. With the use of big data,companies can capture large data in real time; in contrast,traditional statistical analysis is characterized by poor timeliness in capturing large volumes of data,as well as a lack of efficient methods for analysis and critical evaluation parameters,seriously restricting the in-depth application of the big data analytics in hydrocarbon exploration. Central Asian is a region rich in natural resources,including oil and gas,and also a key area and ideal choice for China's oil companies to implement the Belt and Road Energy Cooperation Strategy. However,it is difficult to carry out effective petroleum geological analysis at the stage of study area selection,given the large scope of researches in short time,and the lack of data in seismic interpretation and from wells,and a macro-understanding to guide decision-making cannot be reached as a result. In this regard,we firstly carry out big data analysis following deep mining into and secondary development of purchased databases,integrating massive multi-sourced heterogeneous data,creating a knowledge base for strategic area selection in Central Asia,serving to lay a data foundation for big data analysis in petroleum exploration. Secondly,methods of data mining and big data analytics are innovated for hydrocarbon exploration,and a comprehensive key parameter indicator (KPI) scoring model based on a Trinity of petroleum geological conditions,exploration maturity and commercial value,is established to select multiple petroliferous basins of great exploration potentials and effectively guide the strategic area selection in Central Asia. The study provides new ideas and solutions,and expounds the necessity and feasibility of big data analytics for petroleum exploration from the oil companies point of view. In all,it is of great significance to application and promotion.
multidisciplinary integration,key parameter indicator (KPI),data visualization,comprehensive KPI sco-ring,Big Data fusion,hydrocarbon exploration-centered Big Data Analytics,favorable basin selection,Central Asia
TE132.1
A
0253-9985(2021)06-1464-11
10.11743/ogg20210620
2020-07-24;
2021-07-13。
張科(1979—),男,高級工程師,海外含油氣盆地資源評價。E?mail:zhangke@cnooc.com.cn。
國家自然科學基金項目(92055203)。
(編輯 張玉銀)
