基于多種群協同進化算法的數據并行聚類算法
2021-12-17 00:56:36孫柳
智能計算機與應用 2021年6期
孫柳
(廣東工業大學 華立學院,廣州 511325)
0 引言
隨著云存儲空間多維資源分布數據庫存儲和信息傳輸技術的發展,云存儲空間多維資源分布數據庫的數據信息維數越來越多,需要結合大數據和云信息處理技術,構建云存儲空間多維資源分布數據庫的大數據并行聚類模型,提高云存儲空間多維資源分布數據庫數據的檢測和識別能力。通過云存儲空間多維資源數據并行聚類和特征分析,構建云存儲空間多維資源數據聚類分析模型[1],提高云存儲空間多維資源分布數據庫的信息管理能力。相關的并行聚類方法研究,在云存儲和資源分布數據庫的組網設計和大數據信息管理中具有重要意義[2]。
對云存儲空間多維資源數據并行聚類是建立在對數據的候選特征分析基礎上,通過貝葉斯關聯規則分析,進行云存儲空間多維資源數據并行聚類[3]。傳統方法中,對云存儲空間多維資源數據并行聚類方法主要有:基于模糊信息檢測的云存儲空間多維資源數據并行聚類方法[4]、基于統計分析的云存儲空間多維資源數據并行聚類方法[5]、基于粗糙集特征匹配的云存儲空間多維資源數據并行聚類方法[6]等。由于傳統方法進行云存儲空間多維資源數據并行聚類存在適應度水平不高,抗干擾性不好等問題。對此,本文提出基于多種群協同進化算法的云存儲空間多維資源數據并行聚類方法。首先構建云存儲空間多維資源數據的參數采集模型,對采集的云存儲空間多維資源數據進行模糊并行特征分布式重組,提取云存儲空間多維資源數據聚類特征參數集,采用關聯粗糙集特征分析方法進行云存儲空間多維資源數據的多尺度小波結構分解,然后采用多種群協同控制的方法,建立云存儲空間多維資源數據的并行聚類模型。通過關聯協同濾波檢測方法,進行云存儲空間多維資源數據的分組特征檢測和融合聚類處理,利用差分進化方法進行云存儲空間多維資源數據的聚類中心尋優,遍歷云存儲空間多維資源數據聚類區域的候選目標集,實現對云存儲空間多維資源數據的并行關聯規則聚類和可靠性挖掘。經仿真測試分析,展示了本文方法在提高云存儲空間多維資源數據并行聚類能力方面的優越性能。
1 云存儲空間多維資源數據存儲特征分析
1.1 結構分析
為了實現基于多種群協同進化算法的云存儲空間多維資源數據并行聚類,構建云存儲空間多維資源數據的參數采集和優化存儲結構模型,采用多維特征空間融合和匹配調度的方法,進行云存儲空間多維資源數據的傳輸結構分析,通過信道轉換和均衡配置,進行云存儲空間多維資源數據融合[7],得到云存儲空間多維資源數據存儲結構模型如圖1 所示。

圖1 云存儲空間多維資源數據存儲結構模型Fig.1 Cloud storage space multi-dimensional resource data storage structure model
在云存儲空間多維資源數據存儲結構模型中,采用演化貝葉斯準參數估計方法,構造云存儲空間多維資源數據的分類存儲器,通過多維信息重組和分塊區域重構,進行云存儲空間多維資源數據的網格分塊區域調度[8]。在臨近區域中,邊緣特征融合測度作為云存儲空間多維資源數據挖掘的候選區域,遍歷這些區域獲得云存儲空間多維資源數據的聚類中心子集,在候選目標集中,得到云存儲空間多維資源數據聚類信息熵為:
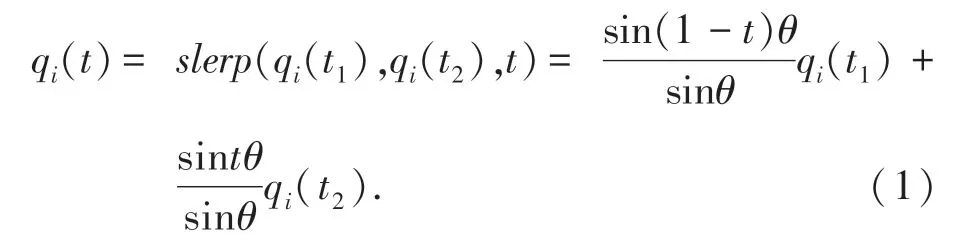
采用熵函數聚類方法,進行云存儲空間多維資源數據分布式概率密度重組,得到云存儲空間多維資源數據聚類的隨機概率密度條件p(vi |y=1)、p(vi |y=0),其滿足高斯分布:

式中,μ1、σ1和μ0、σ0分別為云存儲空間多維資源數據的目標樣本數據和標準信息差。
采用多維特征分解方法,進行云存儲空間多維資源數據信息特征重構,得到云存儲空間多維資源數據的模糊信息聚類樣本分布為:
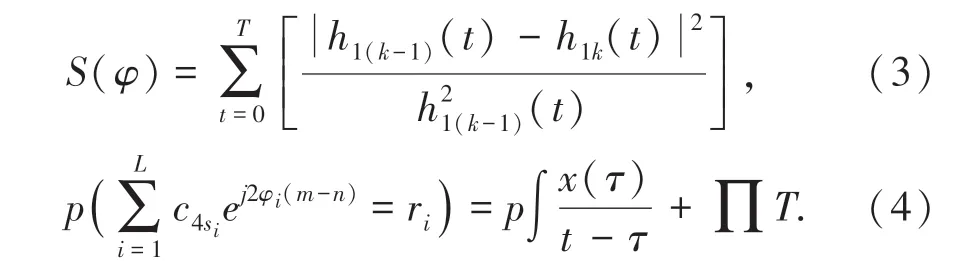
式中,α <ζ <β,l(z)為云存儲空間多維資源數據樣本位置;lt為云存儲空間多維資源數據聚類區域位置;Dα和Dζ,β分別為正樣本和負樣本。根據云存儲空間多維資源數據的結構參數分析,進行云存儲空間多維資源數據的優化聚類和挖掘[9]。
1.2 特征分析
采用關聯粗糙集特征分析方法進行云存儲空間多維資源數據的多尺度小波結構分解,結合特征收斂性控制的方法,通過云存儲空間多維資源分布數據庫多屬性樣本重組[10],得到云存儲空間多維資源數據的模糊相關系數:

結合灰度特征重組和語義分布式融合方法,得到云存儲空間多維資源數據聚類的隨機概率密度分布集。云存儲空間多維資源數據的多維概率密度函數為:
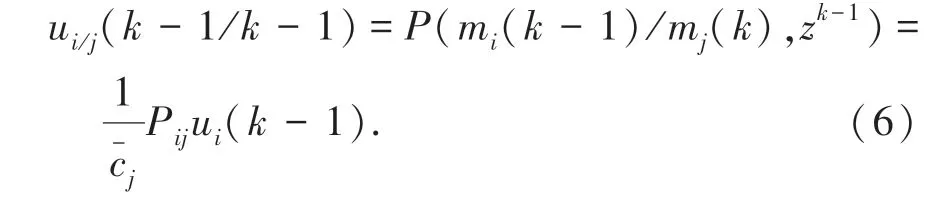
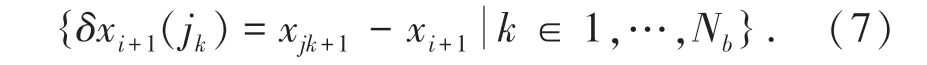
采用機器學習的分類學習方法,得到云存儲空間多維資源數據的聯合特征分布參數φ和θ。采用重采樣策略,得到云存儲空間多維資源分布數據庫的特征分配概率P(zi=j|z-i,wi)的算式為:

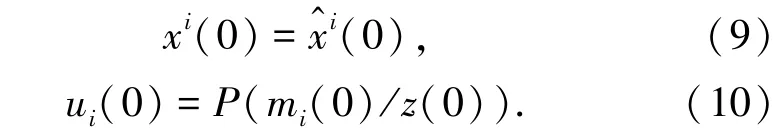
綜上分析,構建了云存儲空間的多維資源數據融合模型,結合特征檢測方法,實現數據并行聚類分析[11]。
2 云存儲空間多維資源數據聚類
2.1 云存儲空間多維資源分布數據庫多屬性數據特征融合
采用多種群協同控制的方法,建立云存儲空間多維資源數據的并行聚類模型,通過關聯協同濾波檢測方法[12],得到云存儲空間多維資源數據聚類的更新規則約束參量的解:
根據云存儲空間多維資源數據的屬性分布進行模糊聚類,得到云存儲空間多維資源數據的差分進化約束的相關性因子為:

其中,云存儲空間多維資源數據融合的特征分布矩陣為R=(rij,aij)m ×n,基于數據層面構建大數據分類模型,得到云存儲空間多維資源數據分類的聯合特征解為:
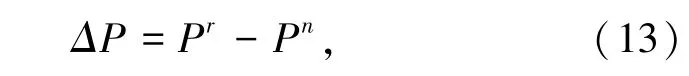
獲取原始數據集,引入云存儲空間多維資源數據的互信息熵,即:

以P為云存儲空間多維資源分布數據庫多屬性分布的概率密度為:
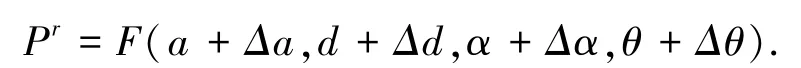
根據云存儲空間多維資源數據的融合參數應滿足:

用Ui,j(t) 表示的云存儲空間多維資源數據動態特征分布信息熵。
基于決策邊界的類樣本分析方法[13],得到共享的通道數為P,構建云存儲空間多維資源數據聚類的聯合關聯決策函數為:

其中,d(omi,rmi)表示聯合度評估系數。充分利用數據空間的類間指數分布,采用差分進化方法,基于高斯概率分布方法,云存儲空間多維資源分布數據庫多屬性特征融合輸出為Ek∈E(k=1,2,…,t)。根據類別的不同屬性,得到云存儲空間多維資源分布數據庫多屬性數據特征融合模型為Pi∈P(i=1,2,…,m)。
綜上分析,采用差分進化方法,進行云存儲空間多維資源分布數據庫多屬性參數識別和聚類[14]。
2.2 云存儲空間多維資源數據并行聚類

其中,Vi為云存儲空間多維資源數據的關聯分析度量值,使用聯合特征分布式進化方法,得到云存儲空間多維資源數據并行聚類的聯合公式為:

在非線性可分的數據集中,得到云存儲空間多維資源分布數據庫多屬性并行聚類輸出的相似度系數為:
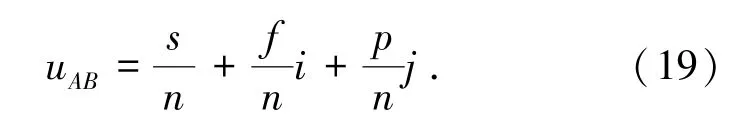
其中:p為云存儲空間多維資源數據的分布集,f為云存儲空間多維資源數據分布的聯合特征參數分布集。用4 元組(Ei,Ej,d,t) 來表示云存儲空間多維資源數據的主特征量,采用決策樹調度和多屬性差分進化方法,得到并行聚類輸出的聯合特征量:
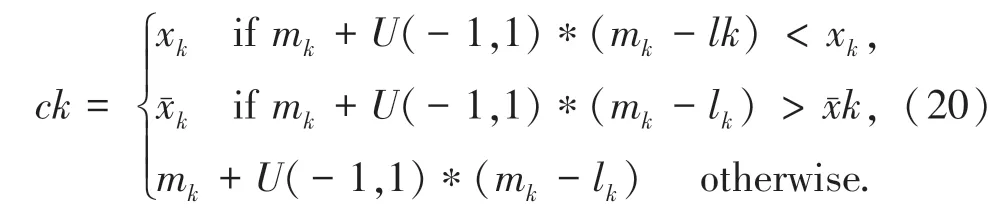
式中,m為云存儲空間多維資源數據并行聚類的進化維數,(dik)2為非線性數據集。
綜上分析,通過差分進化方法進行云存儲空間多維資源數據的聚類中心尋優,實現對云存儲空間多維資源數據的并行關聯規則聚類和可靠性挖掘。
3 仿真測試
對云存儲空間多維資源數據采集的樣本長度為1024,云存儲空間的特征分布維數為3,嵌入維數為125,數據分類的屬性為6,多種群迭代的部署為24,差分進化的迭代數為100。根據上述參數設定,得到云存儲空間多維資源數據統計特征量分布如圖2 所示。

圖2 云存儲空間多維資源數據統計特征量分布Fig.2 Distribution of statistical characteristics of multi-dimensional resource data in cloud storage space
根據圖2 大數據檢測結果,實現云存儲空間多維資源數據聚類,得到并行聚類預測值如圖3 所示。

圖3 數據并行聚類預測值Fig.3 Data parallel clustering predicted value
分析圖3 得知,本文方法進行云存儲空間多維資源數據的特征并行聚類的聚斂度水平較高,數據聚類融合性較好。測試數據分類的準確率,得到聚類誤差收斂結果如圖4 所示。

圖4 數據聚類收斂曲線Fig.4 Data clustering convergence curve
分析圖4 得知,本文方法對云存儲空間多維資源數據分類的正確率較高。在不同的數據聚類中心,測試云存儲空間多維資源數據挖掘的識別率,得到測試結果如圖5 所示。
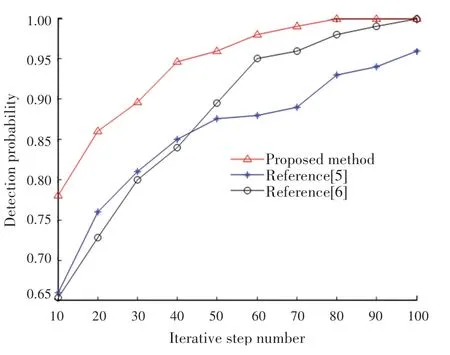
圖5 數據并行聚類的識別率Fig.5 Recognition rate of data parallel clustering
根據圖5 仿真結果得知,本文方法進行云存儲空間多維資源數據并行聚類處理,提高了數據的識別率。
4 結束語
本文提出基于多種群協同進化算法的云存儲空間多維資源數據并行聚類方法,采用多維特征空間融合和匹配調度,進行云存儲空間多維資源數據的傳輸結構分析,結合灰度特征重組和語義分布式融合方法,得到云存儲空間多維資源數據聚類的隨機概率密度分布集。基于決策邊界的多數類樣本分析方法,充分利用數據空間的類間指數分布,采用差分進化方法,遍歷云存儲空間多維資源數據聚類區域的候選目標集,實現對云存儲空間多維資源數據的并行關聯規則聚類和可靠性挖掘。研究得知,本文方法進行云存儲空間多維資源數據聚類的收斂性較好,并行關聯規則聚類性較強,提高了數據的檢測識別率。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
