基于多特征的數(shù)字圖書推薦算法
2021-12-17 00:56:56李冬
智能計算機與應(yīng)用 2021年6期
李冬
(商丘職業(yè)技術(shù)學(xué)院,河南 商丘 476001)
0 引言
伴隨著信息技術(shù)的高速發(fā)展,數(shù)字媒體技術(shù)日新月異,大量的數(shù)字資源的誕生和普及,對數(shù)字資源服務(wù)也提出越來越高的要求,如何從海量的數(shù)字圖書中,根據(jù)相關(guān)的數(shù)據(jù)信息,為讀者提供高質(zhì)量、差異化、個性化的圖書推薦愈發(fā)重要。提高圖書推薦的效率和準(zhǔn)確率,提高讀者的滿意度、粘合度是各種數(shù)字圖書平臺努力的目標(biāo)和方向。
基于各種算法建立起來的數(shù)字圖書推薦系統(tǒng)是根據(jù)讀者的個人偏好,提供差異化圖書推薦的有效方法。算法是推薦系統(tǒng)高效、準(zhǔn)確運行的基礎(chǔ)和關(guān)鍵,目前推薦系統(tǒng)常用的算法有基于內(nèi)容的推薦算法、基于知識的推薦算法、基于關(guān)聯(lián)規(guī)則的推薦算法、基于協(xié)同過濾推薦算法以及基于模型的各類推薦算法[1]。以這些算法建立起來的推薦系統(tǒng)通過對用戶歷史行為數(shù)據(jù)的分析,得出用戶的真實需求,向用戶推薦相關(guān)的產(chǎn)品及信息,隨著正反饋結(jié)果的不斷提高,加強了用戶和平臺間的緊密度,實現(xiàn)用戶鏈?zhǔn)椒磻?yīng)增值,這些推薦系統(tǒng)在電子商務(wù)、音視頻推薦、新聞、圖書等很多領(lǐng)域已經(jīng)取得的廣泛的應(yīng)用,產(chǎn)生了很好的經(jīng)濟效益和社會效益。
數(shù)字圖書和普通圖書相比在數(shù)據(jù)信息和數(shù)據(jù)質(zhì)量上更加的豐富和準(zhǔn)確,讀者對數(shù)字圖書的評價可以更加的便捷、有效,數(shù)字圖書的名稱、簡介、評論、作者、出版社、出版時間、上線時間、搜索量、瀏覽頻次、頁面停留時間等因素都可能會影響讀者的興趣偏好。基于某一特征建立起來的推薦系統(tǒng),在一定程度上欠缺了對其它影響因素的考慮,在推薦的有效性上略顯不足。因此,本文提出一種融合數(shù)字圖書多項特征的推薦算法,并以此為基礎(chǔ)建立推薦模型。
1 多特征數(shù)字圖書的數(shù)據(jù)處理
通過對多個數(shù)字圖書管理系統(tǒng)中的數(shù)據(jù)研究發(fā)現(xiàn),數(shù)字圖書的數(shù)據(jù)屬性主要有名稱、簡介、評論、作者、出版社、出版時間、讀者信息、圖書評分等等。找到合適的方法,融合這些數(shù)據(jù),以此為基礎(chǔ)構(gòu)建數(shù)字圖書的推薦方法,下面介紹各種數(shù)據(jù)特征的處理和模型構(gòu)建。
1.1 數(shù)字圖書簡介信息的數(shù)據(jù)處理及特征提取
數(shù)字圖書簡介信息主要采用文本展示,基于卷積神經(jīng)網(wǎng)絡(luò)CNN 在文字識別中表現(xiàn)出較好的識別效果,并且對于未知樣本的類標(biāo)號也具有較好的預(yù)測性,本文采用卷積矩陣分解ConvMF 的算法,對數(shù)字圖書簡介信息進行處理,得到數(shù)字圖書預(yù)測評分矩陣P1。
忽略標(biāo)點符號、空格等無效信息,通過Word2Vec模型計算得到數(shù)字圖書簡介信息的詞向量矩陣,輸入CNN 中。每條數(shù)字圖書的最大簡介信息單詞數(shù)為max_lenth=300,超出單詞直接截斷。所有數(shù)字圖書簡介信息單詞形成序列L,基于數(shù)據(jù)庫中數(shù)據(jù)大小的考慮,選取出現(xiàn)最多的前2 000個單詞組成列表Vs,用UNK 對應(yīng)的詞向量表示僅在L 中出現(xiàn)的單詞。數(shù)字圖書簡介信息組成m × n矩陣,m為簡介信息的單詞序列,n為每個單詞向量維度;如若卷積神經(jīng)網(wǎng)絡(luò)輸出的數(shù)字圖書分類類別為未知,則視未知類別數(shù)字圖書特征向量為V1。
定義讀者數(shù)量為M,數(shù)字圖書數(shù)量為N,Ui表示讀者特征向量,Vj表示數(shù)字圖書特征向量,Rij表示讀者i對數(shù)字圖書j的評分,W為卷積神經(jīng)網(wǎng)絡(luò)中的權(quán)重向量,Wk為第k列元素,ε表示讀者整體評分矩陣R與讀者、數(shù)字圖書的特征向量內(nèi)積之差的方差,εu、εv、εw分別為讀者特征向量矩陣U、數(shù)字圖書特征矩陣V和卷積神經(jīng)網(wǎng)絡(luò)中內(nèi)部權(quán)重W的方差。結(jié)合公式(1),利用隨即梯度下降法求解U和V。
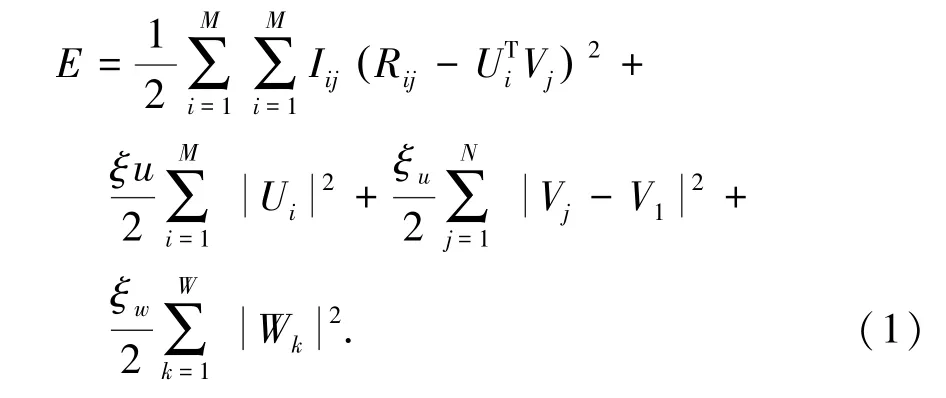
卷積矩陣分解算法中引入概率模型優(yōu)化矩陣分解,利用已知數(shù)據(jù)預(yù)測評分矩陣中的未知值,將上文得到數(shù)字圖書特征向量V1與矩陣概率分解相結(jié)合,能很好地預(yù)測讀者對數(shù)字圖書的預(yù)測評分P1,P1的取值在[0,5]之間。
1.2 數(shù)字圖書評論信息處理
讀者對數(shù)字圖書的評論會用許多帶有感情色彩的詞匯,這些詞匯也是讀者對圖書喜愛程度的表達(dá),對圖書推薦具有重要的參考價值。因此,對這些圖書評論中詞匯進行量化處理,得到讀者對數(shù)字圖書的預(yù)測評分矩陣P2。
用AFINN 情感詞典對圖書評論中的情感詞匯進行量化,每一個關(guān)鍵性詞匯對應(yīng)一個情感分值,取值范圍在[-5,5]之間,經(jīng)過處理計算可以得到每條評論的總情感分值[2]。利用Python 自然語言工具包對評論語言進行分詞,并根據(jù)Natural Language Toolkit 中的停用詞表,進行停用詞過濾,建立結(jié)構(gòu)化的評論數(shù)據(jù)[3]。
AFINN 情感取值介于[-5,5]之間,因此可以將正向積極的評論取值為(0,5],負(fù)向消極的評論取值為(0,-5],中性評價取值為0,利用公式(2)計算得出總的情感分值。
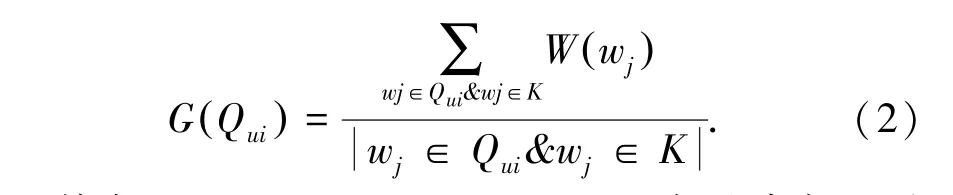
其中,Qui=(w1,w2,…,wj),Qui表示讀者u對數(shù)字圖書i的結(jié)構(gòu)化評論;wj是第j個單詞或詞匯;W(wj) 是每個單詞或詞匯的情感分值;K為AFINN中的詞匯。
利用公式(3)對G(Qui) 所得結(jié)果進行泛化處理,使其結(jié)果取值在[0,5]之間,x∈[-5,5],y∈[0,5],得到讀者評論的圖書預(yù)測評分矩陣P2。
半個多世紀(jì)以來,超高速碰撞不僅在極端條件下的物性與高壓狀態(tài)方程、高溫高壓高應(yīng)變率下材料動態(tài)響應(yīng)特性、材料科學(xué)、生命起源、行星與地球物理等基礎(chǔ)學(xué)科研究中發(fā)揮了重要作用,而且推動了常規(guī)武器與核武器武器物理、慣性約束聚變(ICF)、核反應(yīng)堆安全防護設(shè)計、航天器空間碎片防護、反彈道導(dǎo)彈、輕質(zhì)裝甲設(shè)計、飛機和車輛受撞擊時乘員與貨物的安全防護等工程應(yīng)用研究的快速發(fā)展。本文在概要介紹超高速碰撞現(xiàn)象及其關(guān)鍵科學(xué)問題的基礎(chǔ)上,評述了超高速碰撞應(yīng)用于航天器空間碎片防護、小行星撞擊地球防御研究的若干近期進展, 展望了研究發(fā)展趨勢。
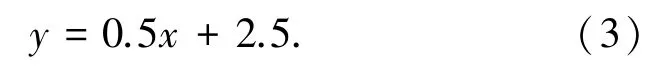
1.3 對圖書作者和出版社進行數(shù)據(jù)建模
作者、出版社對于數(shù)字圖書的評分也有著較高的影響力,因此將其作為影響圖書最終預(yù)測評分的影響因子,賦予一定的權(quán)重。
最近鄰方法KNN 可以對一個不知類別的樣本找出最相似的近鄰用戶進行分類,采用此方法求出近鄰讀者對作者ds所有數(shù)字圖書的評分均值,以及近鄰讀者對出版社eo所有數(shù)字圖書的評分均值,利用公式(4)計算出其均值,作為作者、出版社共同影響下,讀者對數(shù)字圖書i綜合評分為P(i)dseo,表示作者為ds,出版社為eo,讀者對圖書i的綜合評分。
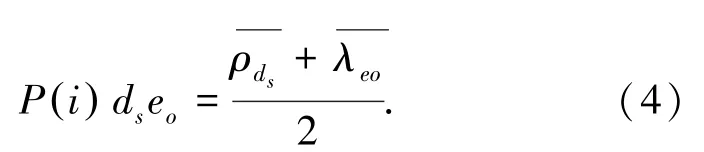
根據(jù)P(i)dseo得出的結(jié)果,利用公式(5)可以構(gòu)建讀者u對圖書i的評分預(yù)測矩陣P3,P′(ui)為讀者u對圖書i的評分。
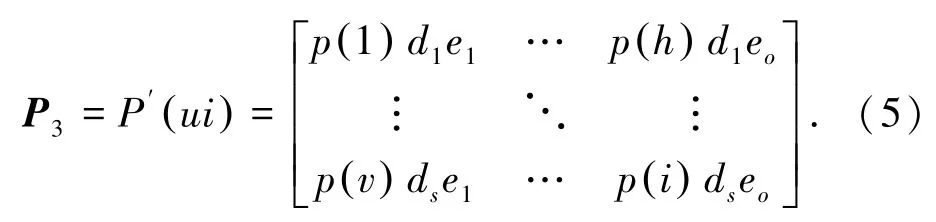
1.4 讀者-圖書評分?jǐn)?shù)據(jù)的處理
基于讀者、圖書、圖書評分矩陣,通過協(xié)同過濾技術(shù)進行圖書推薦已相對成熟,無需對數(shù)據(jù)再進行特別的處理。根據(jù)數(shù)據(jù)源D=(U,I,R),結(jié)合協(xié)同過濾算法,利用余弦相似度計算,可以得到目標(biāo)讀者對圖書的預(yù)測評分矩陣P4,其中U={User1,User2,…,Useri}為讀者樣本集合,I={Item1,Item2,…,Itemj}為數(shù)字圖書樣本集合,R為i × j階矩陣,是已有讀者對各數(shù)字圖書的實際評分矩陣。
2 融合多特征數(shù)字圖書數(shù)據(jù)的模型構(gòu)建
根據(jù)多特征數(shù)字圖書的數(shù)據(jù)處理,重點研究了圖書簡介信息、圖書評論、圖書作者和出版社以及圖書的評分等影響因子,以此為基礎(chǔ)分別構(gòu)建了讀者對數(shù)字圖書的預(yù)測評分矩陣P1、P2、P3、P4,將每個影響因子賦予一定的權(quán)重,利用公式(6)融合計算,作為最終預(yù)測評分Pui。
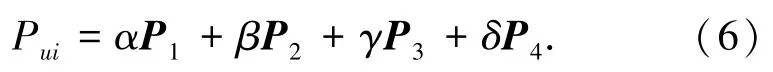
其中,α、β、γ、δ為不同預(yù)測評分矩陣相應(yīng)的權(quán)重,并且α+β+γ+δ=1,通過問卷調(diào)查的方式獲取圖書簡介信息、圖書評論、圖書作者和出版社以及圖書的評分等因素對讀者選擇圖書的直觀影響程度,根據(jù)問卷結(jié)果,設(shè)定α、β、γ、δ的初始值,不斷調(diào)整權(quán)重,對不同的權(quán)重組合進行比較,取最小的MAE值所對應(yīng)的α、β、γ、δ值作為公式中的權(quán)重值。
Pui為讀者u對圖書i綜合多特征的預(yù)測評分,根據(jù)前文所述,P1為讀者u根據(jù)圖書簡介信息對圖書i的預(yù)測評分;P2為讀者u根據(jù)圖書評論對圖書i的預(yù)測評分;P3為讀者u根據(jù)圖書作者和出版社對圖書i的預(yù)測評分;P4為讀者u根據(jù)圖書的評分對圖書i的預(yù)測評分,P1,P2,P3,P4∈[0,5]。根據(jù)已經(jīng)確定的α、β、γ、δ權(quán)重值分別賦予P1、P2、P3、P4,αP1+βP2+γP3+δP4所得結(jié)果即為Pui,得到目標(biāo)讀者對未選擇圖書的綜合預(yù)測評分后,根據(jù)評分由高到底排序,將評分最高的前k個圖書推薦給該讀者。
3 實驗分析
3.1 實驗數(shù)據(jù)
3.2 評價指標(biāo)
平均絕對偏差MAE(Mean Absolute Error)體現(xiàn)預(yù)測評分與真實評分之間的偏差平均值,計算公式如式(7)所示:
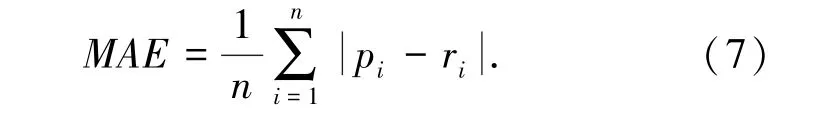
其中,n為讀者數(shù)量;Pi為預(yù)測讀者評分集合{p1,p2,…,pN};ri為實際讀者評分集合{r1,r2,…,rN};計算出的MAE值越小,誤差越小,推薦效果越好。
3.3 實驗結(jié)果及分析
首先進行權(quán)重調(diào)整實驗,獲得最佳的權(quán)重組合對數(shù)字圖書的評分矩陣P1、P2、P3、P4權(quán)重賦值,然后驗證融合多特征數(shù)字圖書推薦性能。
3.3.1 權(quán)重調(diào)整實驗
權(quán)重α、β、γ、δ取值組合范圍較大,通過對50位讀者直觀感受和實際經(jīng)驗進行的問卷調(diào)查顯示,數(shù)字圖書簡介信息、讀者評論、評分對其選擇圖書的影響較大,因此可以假定數(shù)字圖書簡介信息、讀者評論、評分對圖書推薦結(jié)果的影響較大,作者、出版社對圖書推薦結(jié)果的影響較小,設(shè)置初始值α=0.3,β=0.3、γ=0.3、δ=0.1,不斷調(diào)整權(quán)重進行測試。鄰居數(shù)N在10-50 之間取值,當(dāng)N取值30時,不同權(quán)重對應(yīng)的MAE值見表1。
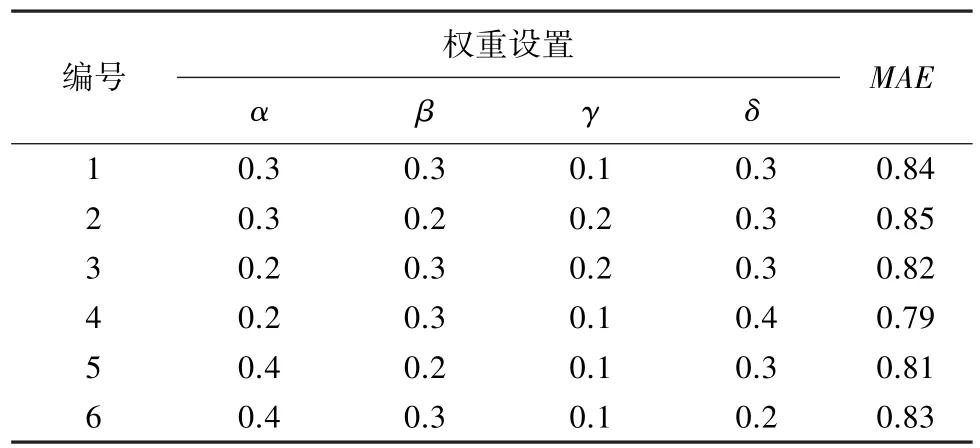
表1 N=30時不同權(quán)重對應(yīng)MAE值Tab.1 N=30,Different weights correspond to MAE values
實驗結(jié)果如圖1 所示,權(quán)重編號為4、12、19時MAE值較小,采用權(quán)重編號4 所對應(yīng)的權(quán)重,取值α=0.2、β=0.3、γ=0.1、δ=0.4 進行后續(xù)的數(shù)字圖書推薦實驗。
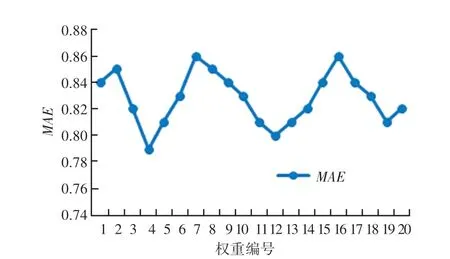
圖1 N=30時不同權(quán)重編號對應(yīng)的MAE值Fig.1 N=30,Different weights serial number correspond to MAE values
3.3.2 融合多特征數(shù)字圖書推薦性能實驗
該實驗驗證本文提出的融合多特征數(shù)字圖書推薦性能,用協(xié)同過濾算法CF 與本文提出的方法進行對比,比較平均絕對偏差MAE值。協(xié)同過濾算法CF 得到的預(yù)測評分矩陣就是目標(biāo)讀者對圖書的預(yù)測評分矩陣P4,得出的MAE值如圖2 所示。
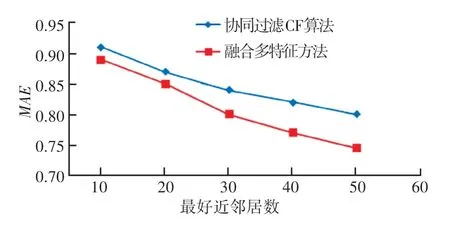
圖2 最近鄰居數(shù)變化時對應(yīng)的MAE值Fig.2 MAE values of nearest neighbors’ number changes
實驗表明,融合多特征數(shù)字圖書推薦方法與協(xié)同過濾CF 算法相比較,MAE值均最小,表明本文提出的數(shù)字圖書推薦方法的有效性,該方法在一定程度上提高了數(shù)字圖書的推薦性能,獲得了較好的推薦效果。
4 結(jié)束語
數(shù)字圖書具有多特征屬性,隨著現(xiàn)代信息技術(shù)的發(fā)展,數(shù)字圖書特征數(shù)據(jù)已經(jīng)極大的豐富,這為融合多特征數(shù)字圖書推薦奠定了基礎(chǔ)。本文通過對數(shù)字圖書特征的分析,考慮圖書簡介、讀者評論、作者、出版社、讀者評分等多種影響因素,分別對圖書評分進行預(yù)測,對預(yù)測結(jié)果加權(quán)融合,賦予一定的權(quán)重,以此提高圖書的推薦性能。通過實驗證明該方法優(yōu)于協(xié)同過濾CF 算法,具有更好的數(shù)字圖書推薦性能。
