詞向量文本挖掘技術在建筑設施管理應用研究
2021-12-17 00:26:39蔣海剛
電腦知識與技術 2021年33期
蔣海剛

摘要:該文挖掘是自然語言處理技術(NLP)在人工智能應用領域的一個重要落地場景。文章以建筑設施運維工單短文本分類器構建為背景,分析了具有稀疏特征的短文本分類技術難點,提出了基于Word2vec算法模型構建建筑運維工單文本詞向量特征,通過有監督機器學習模型將強關聯規則加入短文本分類器訓練過程中,通過短文本詞向量特征改善,優化短文本分類準確率、召回率和 F1 值。通過驗證,建筑運維工單專業自動分類識別成功率達89%,為分析建筑運維服務訴求提供數據依據和基礎。
關鍵詞: 詞向量;短文本挖掘;非結構化數據;建筑數據管理
中圖分類號:TP311? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)33-0022-04
開放科學(資源服務)標識碼(OSID):
1引言
近年來,隨著信息技術的日新月異,尤其是人工智能技術的發展,在建筑運維領域也開始探索應用人工智能賦能建筑數字化運維服務。建筑運維工單是建筑運維過程中描述性的非結構化文本數據,其中包括對建筑維保對象故障、專業、維修記錄的描述性信息。傳統的基于結構化數據的數值分析方法較難適用于這類非結構化文本數據的分析和挖掘工作[1]。因此需要引入自然語言處理(NLP)中的文本挖掘技術,將文本數據進行結構化的向量處理,形成工單文本的詞頻、詞性、關鍵詞等特征標注信息,并對建筑運維工單文本進行語料庫構建,應用機器學習算法對文本完成預訓練結果集輸出,形成建筑維保工單文本語義的深度挖掘能力,最終輸出建筑運維工單可視化分析報告,為建筑運維服務提供主動式建筑設施維保建議,是當前建筑運維領域應用自然語言處理(NLP)技術進行建筑運維非結構化數據應用的人工智能應用場景之一[2]。
2建筑運維工單文本特征
建筑運維工單主要分為維修工單、維保工單。維修工單內容通常是用戶報修信息和維修人員維修記錄其工單文本長度統計一般都在200字符以內,具有明顯的短文本特征如圖1所示,且屬于非規范性口語化嚴重的短文本[3]。建筑運維工單文本描述通常不遵守語法規則;且工單描述信息由于字數少,本身所包含的有效信息也較少,這樣造成工單文本的統計特征非常稀疏,并且特征集的維數非常高,因而通過機器理解短文本面臨極大的技術挑戰[3]。同樣在建筑維保工單短文本挖掘過程中會遇到上述數據擾動的干擾,影響建筑運維文本語義真實意圖的理解。短文本的特征使得傳統基于詞袋模型文本挖掘方法很難對其進行有效建模。近年來基于深度學習算法的應用成熟在一定程度上提升了對于語義特征稀疏的短文本挖掘效率。
3 短文本挖掘技術研究
文本挖掘是非結構化數據處理的一個重要分支,其本質是將文本數據通過向量化方式形成結構化文本信息描述,進而提煉出有價值的知識信息。文本挖掘主要步驟包括數據收集、文本預處理、數據挖掘和可視化、搭建模型和模型評估 [4]。目前文本挖掘技術已經在關鍵詞提取、文本自動摘要、文本聚類、文本分類、文本主題模型、文本觀點抽取、情感分析等領域得到廣泛的應用。
詞向量(Word Embedding)是為了讓計算機能夠處理的一種詞的表示。短文本分類的關鍵在于詞向量矩陣的降維處理,短文本向量表達特征有高維、稀疏等問題,通過降維處理可以減小數據維度和需要的存儲空間、節約模型訓練計算時間、去掉冗余變量、提高算法的準確度[1]。
4 文本分類方法研究
文本分類是指將文本描述歸類到已知的文本類別中,其主要包括文本預處理和分類器模型構建兩個過程,文本分類流程如圖2所示。
4.1文本向量化預處理技術
文本挖掘是自然語言處理在主要研究內容,并且是人工智能和機器學習算法的主要應用場景。近年來,文本向量化研究已備受關注,目前大致有三種常用技術路徑可供選擇:基于規則特征匹配的方法;基于傳統機器學習的方法(特征工程 + 分類算法);基于深度學習的方法(詞向量 + 神經網絡)。Word2vec是Google研究團隊里的Tomas Mikolov等人于2013年的兩篇研究論文中提出的一種使用一層神經網絡高效訓練詞向量模型的方法 [5]。Word2vec 最有價值的是讓不帶語義信息的詞帶上了語義信息,其次把詞語從 one-hot encoder 形式的表示降維到 Word2vec 形式的表示,是一種研究短文本分析的常用方法[5,6]。
4.2 文本語料庫構建技術研究
文本向量化需依次經歷分詞、詞向量化和詞向量組合的過程。目前主流的詞向量方法都存在不同的缺陷。現有的向量化方法是依賴于詞袋模型產生文本向量表達,然而短文本中有些詞與文本要義關聯度較低,但對文本用向量表示的影響較大。因此需要抽取短文本關鍵詞并以此和TF-IDF權重組合形成文本向量更能反映短文本語義的特征信息。因此本次研究的對象建筑運維工單短文本挖掘,通過構建建筑運維語料庫提升文本向量化的準確度其技術實現方式,如圖3所示。
4.3文本分類器模型構建
分類器模型構建過程即通過相應的算法,根據文本預訓練后的生成訓練結果生集,依據訓練結果進行文本分類測試驗證分類器構建的有效性。目前國內中文文本分類研究主要集中在樸素貝葉斯算法、K近鄰算法、支持向量機算法、決策樹算法等[5]。
4.4 分類器模型效果評估
用來評價文本分類器的指標非常多,在實際應用中需要根據場景來選擇甚至是設計評價分類器的指標。在本文研究中結合建筑運維工單文本的特征,采用準確率(Accuracy,簡記為A)、精確率(Precision,簡記為 P)、召回率(Recall,簡記為 R)、 F1 測量值(簡記為 F1)4項指標用于評估分類器效果[7],相關概念和指標定義如下:
TP:被模型預測為正的正樣本? TN:被模型預測為負的負樣本
FP:被模型預測為正的負樣本? FN: 被模型預測為負的正樣本
準確率(Accuracy) 公式(1)表達式為:
精確率(Precision) 公式(2):表達式為:
召回率(Recall)公式(3):表達式為:
F1 測量值(F1 Score)公式(4):表達式為:
上述分類評估指標各有優缺點。召回率主要評估分類器的查全程度,精確率主要評估的是分類器預測的準確能力。二者指標通常有沖突,需要通過F1值進行平衡[8]。建筑運維工單維修專業分類器關注的是分類的維修專業是否精確,因此在本研究中主要側重于對分類器模型的精確度的評估,通過F1分數平衡其與召回率的關系。
5 建筑運維工單文本挖掘應用實踐
5.1 工單文本預訓練
本研究以某建筑運維公司2020年1月-2020年12月期間產生的工單文本為文本預訓練數據集,從工單內容出發進行中文分詞、詞向量計算以及TF-IDF(詞頻-逆向文件頻率)統計,工單訓練數據集記錄數為19,029條。本次研究使用中文分詞工具是Jieba分詞,使用Python 3.8編寫工單預訓練腳本文件。通過完善和加入用戶自定義專業詞庫和停用詞庫來優化中文分詞結果,最終分詞得到 49,760個建筑維保詞匯,將分詞結果去除停用詞處理后,再進行特征降維處理,結合建筑運維專業特征從詞性、詞頻、權重以及詞義與詞頻關系等多維度進行特征信息選擇[7],所形成的建筑運維專業特征語料分布,如圖4所示。
5.2? 建筑維修專業分類器模型構建
5.2.1 訓練集數據選取
在建筑運維服務項目中,用戶通過工單反映出的建筑設施問題多種多樣,為統一、準確、詳細地反映用戶的建筑運行訴求,本研究以某建筑機電運維項目在建筑運維服務過程中產生的“熱點詞匯”為文本研究對象,如“脫落”“漏水”“空調”“照明”等,如圖5所示。隨機從工單中篩選出含“熱點詞”樣本工單作為工單專業分類的訓練集。
5.2.2 分類器模型確定
通過Python腳本調用文本挖掘算法庫構建4個備選分類器模型,并對比分析不同分類器的分類效果,對比結果如圖6所示:
由圖7的可知,從箱體圖上可以看出Sklearn Linear SVC (線性支持向量機)的準確率評估值達到90% 以上命中率,基于模型有效性評估結果,對比研究認為Linear SVC使用One-vs-rest來生成分類器,通過構造N個分類器,可以獲取的建筑工單文本的比較重要的向量化特征[5,9]。因此,綜合平衡后確定Linear SVC分類模型作為建筑運維工單專業分類器模型選擇。
5.3 建筑運維專業分類評估及結果
從分類結果中隨機抽選 12,500張工單進行效果評估,評估結果如表1所示。
從表1的分類結果分析,模型查全率(Recall)達到50%,錯誤率33%。
從分類器評估結果分析該工單分類訓練集識別出正確工單專業分類的概率僅為67%。因此對建筑工單專業分類模型進行調優。模型調優主要從三個方面進行改進:
1) 完善建筑運維專業詞庫和停用詞庫使中文分詞結果更精準;
2) 根據工單詞頻統計選擇更精準的特征詞強化工單分類訓練;
3) 調整Linear SVC模型參數,增加訓練迭代次數優化分類器預測效果。
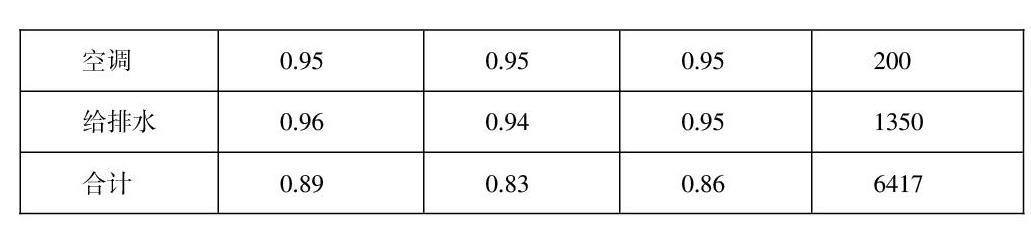
分類器模型調整后,結果評估見表2。
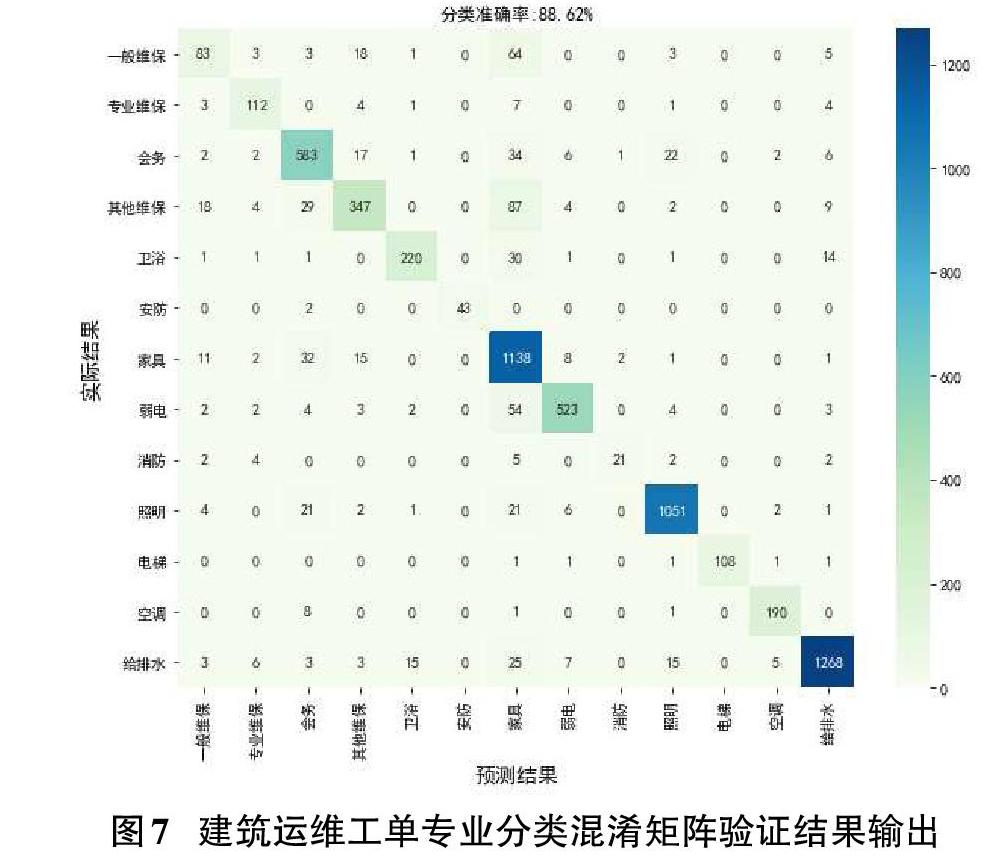
由表2可知,經過模型優化后,準確率和查準率分別提高至 89%、83%,在業務可接受范圍內。通過驗證對比認為,調整后的分類器模型對全量工單專業分類測試結果為正確率為88.62%,共準確識別出工單維修專業16,935張,工單專業類型識別情況如圖7所示。
5.4 建筑運維工單專業自動分類器應用展望
以建筑運維質量評估可視化分析為例,在原始報告中對于工單專業的分類是以建筑系統分類為依據,例如電氣、暖通、給排水、弱電等,但實際運行環境中存在著“工單是屬于某建筑系統但維修專業是歸屬于其他專業的情況”。而用戶表達的建筑問題會被忽略或者隱藏在系統分類標簽下得不到反映。同時,在分配工單任務時,受到人員直覺經驗、業務環境因素和固有的系統分類方法影響,使得維修專業分類結果偏離工單所需反映的問題實際。經工單專業分類器自動分類后,用戶表達的訴求和反映的問題可直接以工單維修專業維度進行分類統計并進行可視化報告呈現,如圖8所示。通過試點項目驗證,通過維修專業分類可視化呈現,試點項目主動發現和洞悉了建筑物維修重點專業,通過文本數據可視化提升了建筑物運維服務質量和效率。
6 結束語
本文研究在當前建筑運維工單統計分析不充分,主動式建筑運維服務能力待提升的背景下,提出基于詞向量Word2vec的文本挖掘技術,對建筑運維服務過程中形成的報障工單進行短文本分析應用研究,形成面向建筑運維短文本挖掘實驗性研究結果。通過研究驗證認為:基于工單專業分類器的算法實現可以成為工單自動化派單功能實現的基礎。驗證結果表明:工單專業識別準確率達到89%。原型系統驗證了從工單語義描述出發,準確地將隱藏在海量工單中的關鍵信息進行數據特征描述和呈現,降低人為介入工單專業標識的技術可行性。此外,從分類后的工單中還能進一步提煉出建筑運維服務中相關事件的關聯影響程度,通過工單溯源分析出建筑運維服務活動中存在的問題,為建筑運維服務質量的改進提供數據依據。
參考文獻:
[1] 王煜,鄧暉,李曉瑤,等.自然語言處理技術在建筑工程中的應用研究綜述[J].圖學學報,2020,41(4):501-511.
[2] 王煙.自然語言處理技術在建筑使用后評價中的應用[J].南方建筑,2019(1):82-87.
[3] 章昉,顏華駒,劉明君,等.基于詞項關聯的短文本分類研究[J].集成技術,2015,4(3):69-78.
[4] 李顥,張吉皓.基于文本挖掘技術的客服投訴工單自動分類探討[J].移動通信,2017,41(23):66-72.
[5] 蘇玉龍,張著洪.基于關鍵詞的文本向量化與分類算法研究[J].貴州大學學報(自然科學版),2018,35(3):101-105.
[6] 余傳明,李浩男,安璐.基于多任務深度學習的文本情感原因分析[J].廣西師范大學學報(自然科學版),2019,37(1):50-61.
[7] Minaee S,Kalchbrenner N,Cambria E,et al.Deep learning—based text classification[J].ACM Computing Surveys,2021,54(3):1-40.
[8] 鄒云峰,何維民,趙洪瑩,等.文本挖掘技術在電力工單數據分析中的應用[J].現代電子技術,2016,39(17):149-152.
[9] Tang D Y,Wei F R,Yang N,et al.Learning sentiment-specific word embedding for twitter sentiment classification[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers).Baltimore,Maryland.Stroudsburg,PA,USA:Association for Computational Linguistics,2014:1555-1565.
【通聯編輯:聞翔軍】
