基于改進GoogLeNet網絡的時空雙流乒乓球動作識別
2021-12-17 00:50:31張傲于洪霞
電腦知識與技術 2021年33期
張傲 于洪霞


摘要:針對乒乓球運動視頻中人體動作具有連續性,需要有效地提取時間維度上的運動信息,提出了基于改進的GoogLeNet作為基礎網絡框架,搭建了時空雙流卷積神經網絡進行乒乓球動作識別。對GoogLeNet網絡進行內部參數優化和網絡結構改進。該方法以RGB圖像作為空間網絡的輸入,光流圖作為時間網絡輸入,選擇加權的特征融合方式在分類層進行時空特征融合。在UCF101中的乒乓球動作視頻以及自制數據集上進行實驗,通過實驗表明,本文提出的乒乓球動作識別方法最終識別準確率可以達到98.88%,該方法提高模型的訓練速度同時提高了模型的識別能力的。
關鍵詞:人體動作識別;GoogleNet網絡;雙流網絡
中圖分類號:TP311? ? 文獻標識碼:A
文章編號:1009-3044(2021)33-0078-03
開放科學(資源服務)標識碼(OSID):
1 引言
隨著深度學習技術的日益成熟,基于深度學習的人體動作識別廣泛受到國內外研究學者的關注。運動類視頻中的技術動作檢測是計算機視覺領域在體育方面的重要應用,其中乒乓球運動其技術特點鮮明,對于單個人體動作技術識別分類具有顯著優勢。通過運動視頻中對雙方運動員動作技術的識別分類,對運動員技術分析和戰術安排有著重要作用。因此基于深度學習的乒乓球人體動作識別有著重要研究意義和應用價值。
乒乓球運動的動作識別其本質屬于人體動作識別分類范疇。卷積神經網絡被引入到視頻領域進行動作識別。2014年,Karenx[1]等人首次提出了基于雙流神經網絡的人體動作識別方法,在ImageNet來進行預訓練,利用RGB單幀和光流圖訓練雙流網絡,最后融合進行動作識別。2016年Wang等人[2]在經典雙流網絡的基礎上,提出了時間段網絡(TSN),結合稀疏時間采樣策略與視頻監督方法。2014年ILSVRC挑戰賽冠軍GoogLeNet網絡被提出,其在傳統深度卷積神經網絡的基礎上加入多個inception網絡模型的結構。
對視頻中的人體動作進行識別一直是計算機視覺領域中具有挑戰性的研究,人體動作識別除了需要提取圖像中外觀場景等空間信息外,有效地提取時間維度上的運動信息也很重要。因此本文結合雙流思想,構建了基于雙流New GoogLeNet卷積神經網絡的乒乓球動作識別算法,并采用加權融合的策略將空間流提取的場景特征和時間流提取的運動特征進行特征融合[3],從而提高了模型的泛化能力和乒乓球動作識別的準確率。
2 時空雙流卷積網絡模型構建
雙流New GoogleNet網絡的結構可以分為空間流和時間流這兩種通道。雙流卷積神經網絡比傳統卷積神經網絡優勢在于,其對視頻數據中時間信息特征的捕捉更加清晰且高效。對于單幀RGB的空間信息一般主要表達出的特征為事物的坐標位置以及固定場景,而對于時間信息中,在多個光流幀的連續運動形式下可以傳遞出更多的目標連續動作信息。空間流和時間流兩個通道都應用同一網絡對特征圖像進行訓練,隨后通過時空特征融合實現動作識別。
2.1 GqoogLeNet網絡
GoogLeNet是由Christian Szegedy于2014年提出的深度學習網絡結構。GoogleNet不同于之前的網絡AlexNet[4]、VGG16[5](通過增大網絡的深度來獲得更好的訓練效果),而GoogLeNet不但加深網絡深度同時還拓寬了網絡的寬度。Inception作為GoogLeNet網絡中最核心的結構,在Inception中將單一卷積核改變為卷積核配合池化層并用的模式,其中的卷積核為三組并行卷積核(1*1,3*3,5*5),池化層為單個池化層。且每路在卷積操作之前或者池化操作之后都緊跟著一個1*1的卷積操作。可以在相同的尺寸的感受視野中疊加更多的卷積,能夠提取更豐富的特征,1*1的卷積還能達到降維的效果,降低了計算的復雜度,提升了網絡的性能。因此本文針對乒乓球動作識別選取GoogLeNet網絡作為基礎網絡進行改進。
2.2 GoogLeNet網絡結構改進
本文對GoogLeNet網絡從Inception模塊內部優化、批量歸一化算法選擇、激活函數的選擇、引入Dropout以及在分類層中選擇改進后的AM-softmax分類器等方面進行內部參數優化和網絡結構改進。其中對于網絡中Inception模塊的結構改進最為重要。
GoogLeNet網絡結構分別在淺層中加入Inception3模塊,中層Inception4模塊,以及深層Inception5模塊,其中原始網絡結構中對于該模塊結構進行統一設定相同結構。由于加入的Inception模塊擁有著較大的卷積核,導致參數過大。因此本文將原有傳統的淺層的Inception3模塊進行了適當的結構優化。將淺層的Inception3刪除5*5的卷積核,增加3*3卷積核的通道數,同時將3*3改成3*1和1*3,使計算速度更快速。
在改進了淺層的Inception3模塊之后,中層的Inception4模塊進行更大的結構改進,由于中層模塊對于特征提取相對于淺層更加重要,因此要保留完整的卷積操作使特征提取更加顯著的同時加快計算速度。先將原有傳統的中層Inception4模塊結構中5*5大小的卷積核進行改進。將兩個3*3大小的卷積核依次連接所組成的新的卷積層小網絡取代原有的大卷積核結構。同樣對中層Inception 4模塊結構中兩個離輸出圖形更近的3*3大小的卷積核使用3*1和1*3兩種卷積核串行來代替。隨后將模塊中的濾波器組進行擴展,使得網絡結構更寬而不是更深,這樣減少維度,使神經網絡的性能會更好,較適合于乒乓球運動人體細微動作幅度這樣的高維特征。因此在計算速度更快的同時,調整以后模型的準確率相比之前更高。
對于深層的Inception5結構,本文保留該模型的原來結構,因為在網絡的深層中卷積核的空間集中性會下降,相對較大的卷積核提取的特征較為抽象,因此適合應用于網絡的深層。
2.3參數選擇及優化
(1)選擇CN批歸一化。改進后的Inception網絡結構在每個卷積操作之后將統一進行CN批歸一化,CN歸一化方法可以更好的避免梯度消失等問題。相對于原有的BN歸一化的泛化性會更加的強。
(2)選擇激活函數。在淺層網絡中選擇Leaky-Relu激活函數,中層后選擇ELU激活函數,從而以結合優秀的激活函數來達到更高準確率的目的。
(3)引入Dropout層并選擇最優比例。通過最大值池化操作后依次進入改進的兩個淺層Inception3模塊,結構優化后的5個中層Inception4模塊,以及兩個擁有較大卷積核的高層Inception5模塊,隨后進行了全局的平均池化,在全連接層引入Dropout層選擇最優的Dropout比例為0.5。
(4)通過AM-Softmax分類器對特征圖像進行分類輸出。由于該分類器對于不同動作特征的類間距更大,類內距更小,因此選擇基于Softmax進行算法改進的AM-Softmax分類器運用于乒乓球動作識別,使局部動作分類效果更佳顯著顯。
以上對于GoogLeNet網絡進行改進后的New GoogLeNet網絡相對于原有的基礎網絡的性能更加優化。
2.4時空特征融合設計
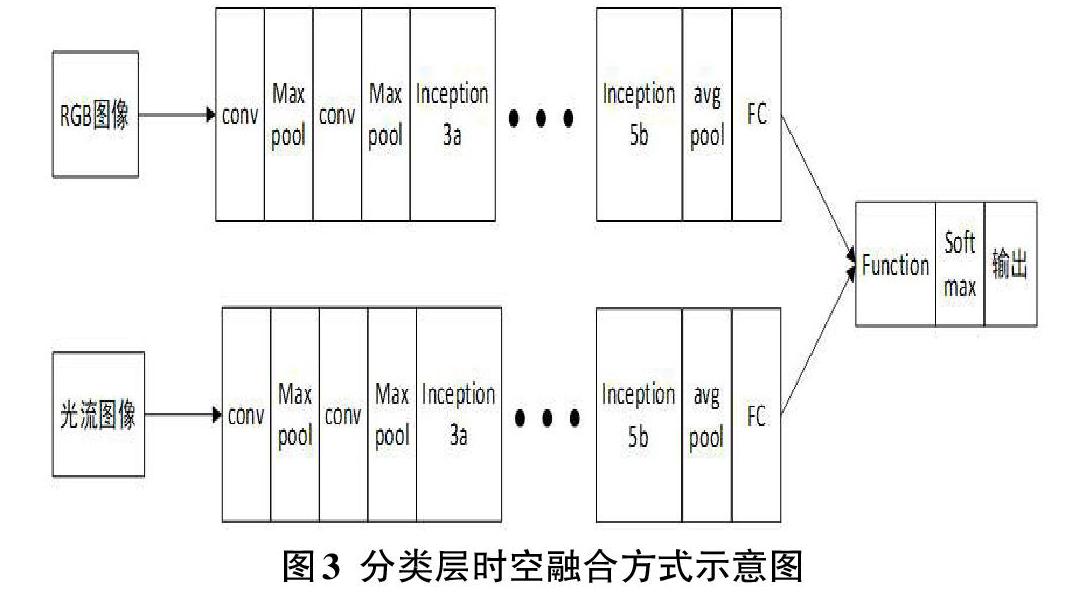
本文對于視頻中乒乓球運動的動作識別所選擇的時空融合策略進行設計,選取在分類層的融合方式進行特征融合。雙流網絡分類層的融合方式是在經過全連接層之后在后期的分類層中進行特征融合。前期過程應用改進NewGoogLeNet神經網絡對單幀RGB圖像和堆疊的光流圖像進行處理,雙流網絡分別提取運動視頻中的空間特征和時間特征,并且兩個網絡間進行權值共享,在NewGoogLeNet網絡中經過卷積、池化、全連接層等操作后,在分類層將兩流的特征進行融合。該方法在兩個網絡間加入權值參數共享的方式可以增強兩種不同特征在參數學習時的相互聯系,同時也降低訓練成本。在網絡的后期進行融合主要原因是考慮RGB圖像和光流圖像間的獨立性,對于時空雙流的各自特點分別進行更明確的提取。
本文采用加權融合法在分類層進行特征融合。對于加權融合方法,可以表示為將空間特征和時間特征定義不同權重分配后進行相加和。對于特征融合使用加權融合方法將時間流網絡和空間流網絡進行融合,加權融合權重比例為時間:空間=6:4,融合時機選擇在分類層進行融合。
3實驗設計與結果對比分析
3.1乒乓球數據集建立
本文的實驗數據集為UCF101公開數據集以及自制乒乓球數據集。UCF101數據集中乒乓球運動類視頻有143個,自制數據集為109個,所有視頻內容包括大量的乒乓球持拍對打,視頻中角度多樣,光照信息場景信息變化多樣,視頻的像素較低,且視頻長度較短。根據本文對于乒乓球技術特點的分析要求,將短視頻劃分為四個類別:(1)正手攻球(2)反手攻球(3)正手搓球(4)反手搓球。本文所用的UCF101數據集以及自制乒乓球數據集分別將視頻數據格式通過分幀處理成RGB格式,以及通過Lucas-Kanade算法進行光流圖像處理。
3.2實驗步驟
本文實驗仿真部分在tensoflow平臺上進行實驗驗證,網絡的訓練實驗在UCF101數據集及自制數據集上進行,空間流網絡的輸入為T=5幀的RGB圖像。時間流網絡的輸入為連續疊加L=10的光流圖像。在網絡訓練中迭代批量大小每次為100個,動量設置0.9。本次實驗總共進行了60輪epoch,網絡迭代到18000次時,網絡停止訓練。
3.3實驗結果對比
綜上所述,使用加權融合方法按權重比例時間:空間=6:4將時間流網絡的運動特征和空間流網絡的場景特征在后期AM-Softmax分類層時進行融合后,此時特征融合雙流New GoogLeNet卷積神經網絡的乒乓球動作識別的平均準確率達到了98.88%,損失函數值為0.4523。識別率高于其他網絡模型。
4 結論
本文提出的時空特征融合的雙流New Googlenet卷積神經網絡的乒乓球人體技術動作識別有效地加快了模型的訓練速度,提高了模型的識別能力以及泛化能力。
參考文獻:
[1] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]//Advances in neural information processing systems,2014:568-576.
[2] Wang L, Xiong Y, Wang Z, et al. Temporal segment networks: Towards good practices for deep action recognition[C]//European Conference on Computer Vision,2016:20-36.
[3] 王嬋娟.利用特征融合的行為識別方法研究[D].贛州:江西理工大學,2018.
[4] You Y,Zhang Z,Hsieh C J et al.100-epoch ImageNet Training with AlexNet in 24 Minutes[J].Journal of Jinggangshan University,2016,33(6):1020-1026.
[5] Simonyan K,Zisserman A.Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science,2014,36(1):231-235.
【通聯編輯:梁書】
\
