基于數學建模的數據流異常檢測方法
2021-12-17 01:50:20李煥云王勝杰
電腦知識與技術 2021年33期
李煥云 王勝杰


摘要:針對常規異常檢測方法聚合數據流數據時誤判率較大的問題,設計一種基于數據建模的數據流異常檢測方法。計算各個數據個體之間的歐幾里度量參數,規范化處理異常數據流數據,設定數據流中的判斷節點,利用數據建模技術判斷數據狀態,規范化處理異常數據流數據,采用臨近采樣方法在設定的數據集節點處構建一個檢測窗口,設定檢測周期后,最終實現對異常數據流的檢測。準備實驗數據集,設定各個數據集間的間隔周期,模擬數據流結構,準備兩種常規檢測方法以及設計檢測方法進行實驗,結果表明:設計的異常檢測方法誤判率數值最小。
關鍵詞:數學建模;數據流;異常檢測;誤判率
中圖分類號:TP393? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)33-0144-02
開放科學(資源服務)標識碼(OSID):
數據建模是將各類數據處理為一個抽象組織,在確定管轄范圍后,采用固定的組織形式將數據轉化為數據處理工具的過程。使用數學建模內置的二維或是三維數字關系,搭建多個邏輯關系,采用該邏輯關系表述數據結構間的關系。數據流是一組有序的數據序列,內置數據起點以及數據終點字節,在輸入流和輸出流的控制下,形成一個特定的數據處理過程[1-3]。為此,在數據建模技術的支持下,構建一種數據流異常檢測方法是很有必要的。國外在研究數據流異常檢測起步較早,在數據庫技術的支持下,率先建立了一種訪問系統,并設計得到了入侵檢測方法。國內在研究異常檢測方法起步較晚,結合人工智能技術,研究得到了多種檢測方法。
1 基于數學建模的數據流異常檢測方法
1.1 規范化處理異常數據流數據
數據流內的數據由多個屬性的數據構成,對應的數據有著不同的數據格式以及設計單位,所以在檢測異常數據流時,應規范化處理數據流中的數據[4]。在規范化處理前,計算各個數據個體之間的歐幾里度量參數,并根據該度量參數的數值,計算各個數據個體間的相似度,采用Z-score規范化處理方式處理數據流中的各項數據后,線性變換數據流中的原始數據,保持數據流中原始數據間的大小數值關系,假設屬性數值的標準差后,標定屬性一個有意義的最大值,標定為不同的維度參數后,形成多個維度數據空間。為了保證數據流的正常處理流程,消除數據信息流中的干擾,利用統計概率處理方法計算數據流中的標準信息熵,可表示為:
[h(x)=-i=1np(xi)n]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(1)
其中,[p(xi)]表示標準最大值對應的函數,[n]表示數據空間的維度數值。當計算得到信息熵的數值大于零時,則表示數據流處于一個穩定狀態。在該種穩定狀態下,將數據流空間內的節點劃分為不同處理順序的數據節點,整合為不同集合的數據組后,應用數據建模技術,判斷各個數據組中數據流的狀態。
1.2 利用數學建模判斷數據狀態
使用上述得到的數據集,在劃分數據集的數據分界處,設定不同的數據節點,以該節點作為狀態判斷點。使用該節點周圍的兩個數據組作為處理對象,采用距離計算方式,使用各個數據集中通用的屬性數據,計算通用數據間的距離,采用數據建模方法描述數據為一個狀態數據集,隨機選定一個數據點,計算該點與設定節點間的距離,當該距離數值在預先設定的參數數值之間,則表示該數值為正常狀態,當該數值在設定的參數數值之外,則表示對應處理的數據集為異常狀態[5]。
為了增強判斷數據狀態時的精準性,在預先設定參數時,應在劃分的數據集中定義一個局部異常因子,使用數據密度參數作為該局部異常因子的約束值,采用數學描述方法將給定的數據點處理為一個衡量數值,假設該衡量數值明顯不同于局部平均數值,則認定該數據集對應的數據流存在異常,異常數據狀態判斷后,針對該部分異常數據,構建檢測過程。
1.3 實現對異常數據流的檢測
基于上述處理過程,采用臨近采樣方法在設定的數據集節點處不斷采集數據,并構建一個滑動窗口,在采集的數據流處,建立一個數據密度估算數值關系,可表示為:
[f(x)=1Sct=1kxt]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (2)
其中,[Sc]表示采樣參數,[xt]表示數據密度函數,[k]表示滑動周期。在上述數值關系內,確定一個簇首數值,在密度數值返回各數據集中處理時,設定一個返回周期,按照不同的時間尺度,不斷替換密度數值中的正常數據流中的數據。
為了消除檢測過程中產生的誤判,在簇首節點處下傳一個全局分布參考數值,數據流節點結合該信息區分數據集內的有效數據,構建一個滑動區分窗口,當存在節點進入該滑動窗口時,自動觸發計算窗口處理數據集的密度,并更新為下一個檢測窗口,不斷循環處理形成一個自動處理過程。對應多個檢測狀態,定義上述檢測過程的異常概率,計算異常狀態下的數據流相關性,并將該統計特征處理為一個聯合參數,控制該聯合參數在檢測窗口中的比例,對應不同的比例數值,設定不同條件下的檢測常量,在該檢測常量的控制下,構建一個連續的數據流異常檢測過程,綜合上述處理,最終完成對基于數據建模的數據流異常檢測方法的構建。
2 對比實驗
2.1 實驗準備
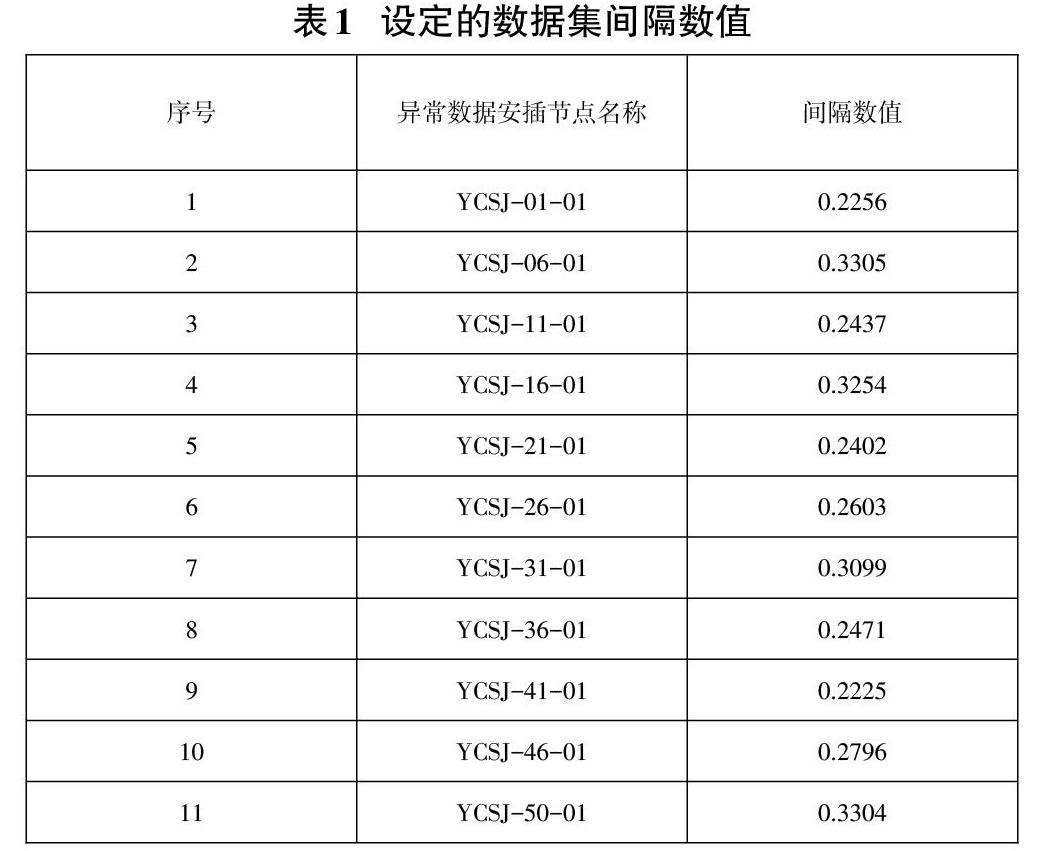
采用KDDCUP-99數據集作為處理對象,選定數據集中500個數據作為實驗對象,將正常網絡訪問數據作為數據流正常數據,將異常訪問狀態下的測試數據作為異常數據流處理對象。在實際處理過程中,將不同種異常網絡數據看作為相同異常狀態,在標記異常數據組后,選定100組測試數據作為異常數據流,將400組數據作為正常數據流。設定每組數據在檢測時的采樣節點,在每四組正常數據內安置一個異常數據,并設定數據組成數據集間隔數值,設定的間隔數值如表1所示。
在表1設定的間隔數值控制下,將上述數據形成的數據流,整合為下表所示的數據特征,并對應不同的數據特征,設定不同的轉化參數。并使用設定的屬性數據對應設定的轉換參數后,準備兩種常規異常檢測方法與設計的異常檢測方法進行測試,對比三種檢測方法的性能。
2.2 結果及分析
基于上述實驗準備,控制三種異常檢測方法從安插節點YCSJ-01-01開始檢測,并將其作為起始時間統計點,統計三種檢測方法的運行時間,運行時間結果如下表2所示。
由表2可知,與兩種常規檢測方法相比,設計的檢測方法檢測所需的時間最短,時效性最強。
在上述實驗環境下,定義檢測方法的檢測誤判率為誤檢數據占據正常數據的比例,統計不同數據周期下,三種檢測方法實際產生的檢測誤判率,實驗結果如下表3所示.
由表3可知,與兩種常規檢測方法相比,設計得到的檢測方法產生的誤判率數值最小,能夠正確檢測多種數據。
3 結束語
隨著數據處理技術的發展,數據流形式逐漸豐富,產生的異常數據流逐漸成為當下的研究熱點,在數據建模技術的支持下,構建一種異常檢測方法,能夠改善常規檢測方法存在的不足,為今后研究檢測異常數據流提供研究依據。
參考文獻:
[1] 楊杰,張東月,周麗華,等.基于網格耦合的數據流異常檢測[J].計算機工程與科學,2020,42(1):25-35.
[2] 鄧麗,劉慶連,鄔群勇,等.基于數據流時空特征的WSN異常檢測及異常類型識別[J].傳感技術學報,2019,32(9):1374-1380.
[3] 杜臻,馬立鵬,孫國梓.一種基于小波分析的網絡流量異常檢測方法[J].計算機科學,2019,46(8):178-182.
[4] 徐曉丹,姚明海,劉華文.基于稀疏表征的異常點檢測方法[J].華中科技大學學報(自然科學版),2020,48(7):20-25.
[5] 董書琴,張斌.基于深度特征學習的網絡流量異常檢測方法[J].電子與信息學報,2020,42(3):695-703.
【通聯編輯:張薇】
