學術(shù)論文創(chuàng)新點的識別與檢索入口研究
2021-12-21 13:58:19曹樹金趙浜岳文玉等
現(xiàn)代情報 2021年12期
曹樹金 趙浜 岳文玉等






DOI:10.3969 / j.issn.1008-0821.2021.12.002〔中圖分類號〕G250.2 〔文獻標識碼〕A 〔文章編號〕1008-0821 (2021) 12-0017-11
我國正在實施創(chuàng)新驅(qū)動發(fā)展戰(zhàn)略, 科技創(chuàng)新和基礎(chǔ)研究是創(chuàng)新驅(qū)動發(fā)展戰(zhàn)略的重中之重。創(chuàng)新是科學研究的核心,是學術(shù)論文的本質(zhì)要求。學術(shù)論文通常結(jié)構(gòu)嚴謹,內(nèi)容蘊藏著研究者的研究成果及科學發(fā)現(xiàn), 是科學研究工作的結(jié)晶, 理論和應(yīng)用價值豐富。蘊含創(chuàng)新內(nèi)容的學術(shù)論文是支持科技創(chuàng)新的主要情報源。
據(jù)統(tǒng)計,全球科技文獻的生產(chǎn)數(shù)量已達百萬級別, 且以每年3%左右的速度持續(xù)增長,學術(shù)文獻海量且類型多樣、分布分散。學術(shù)論文創(chuàng)新點的獲取,一方面是為了提高科研用戶的科研效率,緩解信息過載現(xiàn)象;另一方面,從宏觀角度來看, 監(jiān)測創(chuàng)新、促進創(chuàng)新是科學研究發(fā)展的本質(zhì)要求, 而創(chuàng)新本身及其表述的復雜性和多樣性又為識別創(chuàng)新要素增添了難度。
當前, 在自然語言處理和深度學習方面的研究進展為文本的多粒度挖掘和組織提供了技術(shù)支持。已有研究從事件文檔和句子級別對創(chuàng)新特征的自動識別進行了探索, 但在實際應(yīng)用的檢索系統(tǒng)中,并沒有實現(xiàn)對文獻創(chuàng)新特征的檢索功能,文獻創(chuàng)新點與創(chuàng)新要素仍有待揭示和描述。因此, 有必要對學術(shù)論文的創(chuàng)新點進行深度挖掘,提取出其中的結(jié)構(gòu)化信息, 揭示不同粒度創(chuàng)新點表述的關(guān)聯(lián)并進行存儲, 以滿足科研用戶獲取創(chuàng)新情報的需求, 提升情報服務(wù)的能力。
1相關(guān)研究
1.1學術(shù)創(chuàng)新的含義與測度
根據(jù)庫恩的范式概念, 學術(shù)創(chuàng)新可以分為兩類:一類是對已有研究進行補充和發(fā)展, 推動科學的累積式漸進; 另一類是對原有研究的顛覆, 具有革命性的創(chuàng)新意義。更進一步地, 關(guān)于學術(shù)論文的創(chuàng)新, 姜春林等認為, 學術(shù)論文的創(chuàng)新蘊含著從研究者的思想和觀點到產(chǎn)生新知識的復雜過程。學術(shù)論文中的創(chuàng)新點可以認為是研究者研究中創(chuàng)新成果的文字體現(xiàn)。論文創(chuàng)新點的表現(xiàn)形式為作者在論文中使用的“知識主張” (Knowledge Claim), 論文作者使用的“新知識主張語句” 提供具有學術(shù)價值的新知識, 可以揭示論文的創(chuàng)新點。
在學術(shù)創(chuàng)新的相關(guān)研究中, 創(chuàng)新能力、水平或程度的測量一直是研究的熱點之一。近年研究的熱點聚焦于對學術(shù)成果本身創(chuàng)新性的測量, 一些研究者使用單個特征作為論文學術(shù)創(chuàng)新性的評價指標。比如以論文作者的h 指數(shù)、論文的被引量等單個指標為主的評價方法。從內(nèi)容角度進行深層次、全面化的學術(shù)創(chuàng)新評價和揭示成為目前的主流趨勢。如一些學者以語義相似度計算為核心, 分別從篇章級和句子級構(gòu)建模型或函數(shù)測度學術(shù)成果的創(chuàng)新性。賀婉瑩通過對不同機器學習模型的性能進行評價, 得出了適合進行創(chuàng)新力評價的機器學習模型。
從以上研究可以看出, 自然語言處理、機器學習等技術(shù)的不斷發(fā)展促進了學術(shù)創(chuàng)新測度不斷向更細粒度、更精準的趨勢發(fā)展。這說明學術(shù)論文的創(chuàng)新點抽取或許可以為學術(shù)創(chuàng)新情報的挖掘提供一個新方向。
1.2學術(shù)信息的多粒度組織與檢索
隨著知識抽取技術(shù)的不斷發(fā)展和學術(shù)論文全文本可獲得性的不斷提高, 從學術(shù)研究成果文本中獲取多粒度信息并進行關(guān)聯(lián), 從而進行知識結(jié)構(gòu)構(gòu)建, 是一種可行且有必要的手段。
現(xiàn)有研究多聚焦于細粒度信息單元的獲取與組織。在細粒度學術(shù)信息獲取研究領(lǐng)域, 知識元抽取是近年的研究重點。現(xiàn)有知識元的抽取級別分為詞級和句子級, 近年知識元抽取研究一般都以句子級為主。方法可以分為人工標注、基于規(guī)則的方法和機器學習方法。多粒度學術(shù)信息組織相對復雜, 單文檔的多粒度信息組織方面, 如李湘東等提出一種基于加權(quán)特征的LDA模型和多粒度特征選擇模型, 以抽取表意性較強的粗粒度特征; 多文檔的多粒度信息組織方面, 如肖璐從詞語、句子與文本粒度構(gòu)建領(lǐng)域知識關(guān)聯(lián)體系, 并將多個知識關(guān)聯(lián)網(wǎng)絡(luò)通過超網(wǎng)絡(luò)技術(shù)融合成全聯(lián)通的多粒度知識關(guān)聯(lián)體系。
學術(shù)信息的多粒度或細粒度檢索相關(guān)研究相對較少。如李禎靜提出一種基于資源語義空間的科技文獻細粒度語義檢索方法。王忠義等基于關(guān)聯(lián)數(shù)據(jù)提出數(shù)字圖書館多粒度集成知識服務(wù)方式, 并開發(fā)原型系統(tǒng), 進行檢索實驗和評估。
總結(jié)以上研究可以看出, 雖然多粒度學術(shù)信息組織已有較多研究, 但以標注或模型構(gòu)建的相關(guān)研究為主, 以檢索為目的或者真正實現(xiàn)檢索功能的研究不多。
1.3學術(shù)研究創(chuàng)新的識別與挖掘
學術(shù)創(chuàng)新的識別多指宏觀層面, 而挖掘則更多指微觀層面。宏觀層面的學術(shù)創(chuàng)新識別主要包括兩個研究方向: 顛覆性創(chuàng)新識別和探測與創(chuàng)新路徑識別。關(guān)于顛覆性創(chuàng)新識別,已有不少學者進行了綜述, 從對象方面一般可以分為基于專利和基于論文的顛覆性創(chuàng)新識別, 從方法上一般分為文獻計量、文本挖掘等識別方法。關(guān)于創(chuàng)新路徑的識別, 一般以3種方法為主:引文分析法、主題詞分析法、基于多元關(guān)系融合的方法。這些研究主要是從宏觀上探究學術(shù)創(chuàng)新的發(fā)展趨勢。
對于學術(shù)論文創(chuàng)新點的挖掘, 除了通過相似度, 與知識元抽取類似, 一般還分為通過規(guī)則和通過算法抽取兩種方法。如張帆等以領(lǐng)域詞表和本體中的關(guān)系為基礎(chǔ)構(gòu)建識別規(guī)則, 采用基于主題詞重疊度的算法評估創(chuàng)新點的有效性。周海晨等提出一個深度學習與規(guī)則結(jié)合的學術(shù)創(chuàng)新貢獻識別方法, 實現(xiàn)了大規(guī)模學術(shù)全文本創(chuàng)新貢獻的自動抽取。
以上研究為本文提供了重要的理論前提和方法基礎(chǔ)。但將創(chuàng)新句的抽取擴展到全文的研究較少,也沒有研究將句子級創(chuàng)新點的抽取結(jié)果應(yīng)用于檢索。因此, 本研究以情報學期刊論文為例, 從學術(shù)論文的句子級創(chuàng)新點識別出發(fā), 以創(chuàng)新對象和創(chuàng)新維度為線索, 對創(chuàng)新句、相關(guān)章節(jié)和論文本身進行多粒度關(guān)聯(lián), 并以此為數(shù)據(jù)基礎(chǔ)設(shè)計創(chuàng)新點檢索入口,探索對創(chuàng)新點進行檢索的可行性。
需要強調(diào)的是, 本研究所進行的學術(shù)論文創(chuàng)新點識別, 是完全從客觀層面對論文作者在文中表述的研究創(chuàng)新之處進行挖掘和特征分析, 不涉及研究者的主觀判斷。本研究所稱“創(chuàng)新句” 指論文作者在文中表述的,旨在提示研究創(chuàng)新之處的句子。
2研究設(shè)計與方法
2.1研究設(shè)計 本研究分兩個階段進行, 第一階段為領(lǐng)域?qū)W術(shù)論文創(chuàng)新句獲取以及創(chuàng)新要素分析; 第二階段為創(chuàng)新點檢索入口及系統(tǒng)構(gòu)建。由于近年情報學期刊論文寫作規(guī)范化程度不斷提高, 同時作者和標注人員對本領(lǐng)域相對熟悉, 因此選擇情報學研究領(lǐng)域, 研究樣本為情報學期刊論文。
2.1.1領(lǐng)域?qū)W術(shù)論文創(chuàng)新句獲取以及創(chuàng)新要素分析
本階段引入多層次研究設(shè)計, 解決“學術(shù)論文的創(chuàng)新點與創(chuàng)新要素如何獲取?”這個問題。
在第一層次首先進行數(shù)據(jù)準備,包括樣本數(shù)據(jù)獲取、文本預(yù)處理和數(shù)據(jù)集標注。分別采集中英文各兩種情報學期刊論文, 對論文文本按照一定的規(guī)則進行預(yù)處理,參考前序研究總結(jié)的創(chuàng)新引導詞集,進行數(shù)據(jù)集劃分和標注, 訓練Bert語言模型進行創(chuàng)新句抽取; 第二層次是對創(chuàng)新句的進一步處理, 分析創(chuàng)新要素, 選擇依存句法分析方法獲取創(chuàng)新對象和創(chuàng)新維度。
2.1.2創(chuàng)新點檢索入口及系統(tǒng)構(gòu)建 本階段通過構(gòu)建創(chuàng)新點檢索系統(tǒng), 提供創(chuàng)新點檢索入口, 解決“如何實現(xiàn)多粒度關(guān)聯(lián)的創(chuàng)新點檢索?” 的問題。基于上一階段分析結(jié)果, 以創(chuàng)新對象和維度為線索進行創(chuàng)新點多粒度關(guān)聯(lián)。具體來說, 提出關(guān)聯(lián)章節(jié)的具體獲取步驟, 將細粒度的創(chuàng)新句與中粒度的創(chuàng)新章節(jié)和粗粒度的論文本身進行關(guān)聯(lián), 實現(xiàn)學術(shù)論文創(chuàng)新內(nèi)容的多粒度組織。構(gòu)建創(chuàng)新點檢索的原型系統(tǒng), 選擇Python 作為后端開發(fā)語言, 采用Django 作為Web框架, MySQL 作為系統(tǒng)數(shù)據(jù)庫, 索引和檢索模塊由Faiss搭配Numpy實現(xiàn)。以識別部分進行的創(chuàng)新點多粒度關(guān)聯(lián)為數(shù)據(jù)基礎(chǔ),輔以學術(shù)論文其他一些元數(shù)據(jù)導入數(shù)據(jù)庫。
以“創(chuàng)新對象” 與“創(chuàng)新維度” 作為關(guān)鍵檢索字段并在此基礎(chǔ)上建立索引和查詢, 設(shè)計前端界面并進行實驗, 對檢索功能模塊和效果進行展示。
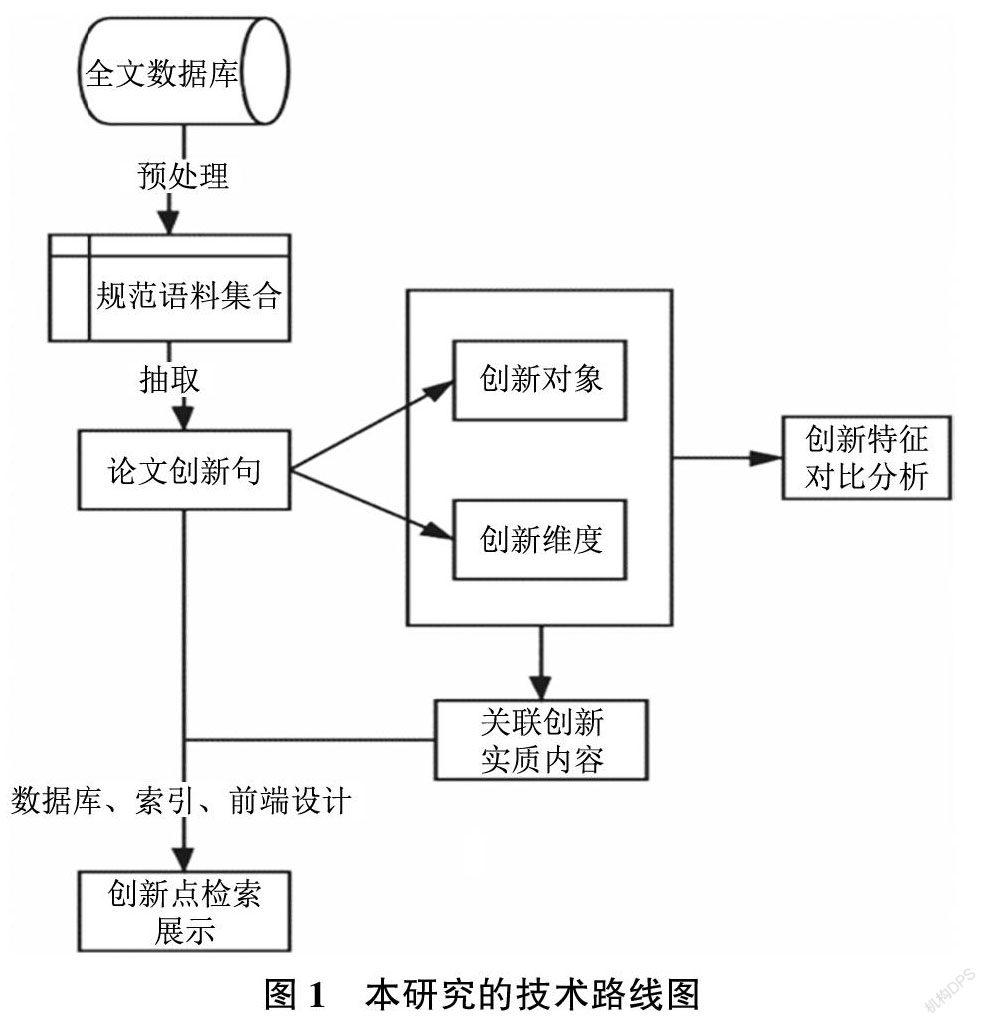
本研究的技術(shù)路線如圖1 所示。
2.2 Bert 語言模型
Bidirectional Encoder Representations from Trans?formers(Bert) 是由Devlin J等與其谷歌同事于2018年在論文中提出的一種基于神經(jīng)網(wǎng)絡(luò)的機器學習技術(shù), 來源于谷歌對Transformer 的研究成果。
Transformer 使用了注意力機制, 將序列中的任意兩個位置之間的距離縮小為一個常量, 其次是避
免使用RNN 的順序結(jié)構(gòu), 并行性更佳。因此,Bert 模型可以考慮到完整的上下文, 從而捕捉更豐富的文本語義信息。
2.3依存句法分析
現(xiàn)代依存句法理論由法國語言學家LucienTesniere 提出, 依存句法分析的主要目的是通過描述詞之間的依存關(guān)系來揭示句子的語義結(jié)構(gòu)。
Stanford CoreNLP基于標注算法先進、加工程度較深的賓州樹庫(Penn Treebank)作為分析器的訓練數(shù)據(jù), 面向英文、中文、德文等多語種提供句法分析功能。其優(yōu)點一是支持語言的廣泛性; 二是所用PCFG算法準確率高。除此之外, 其配套工具齊全, 有使用最大熵模型的詞性標注工具, 基于概率解析器提供完整的語法解析的解析工具、實體識別等功能, 能夠滿足實驗需求。
2.4 Faiss 相似性搜索庫
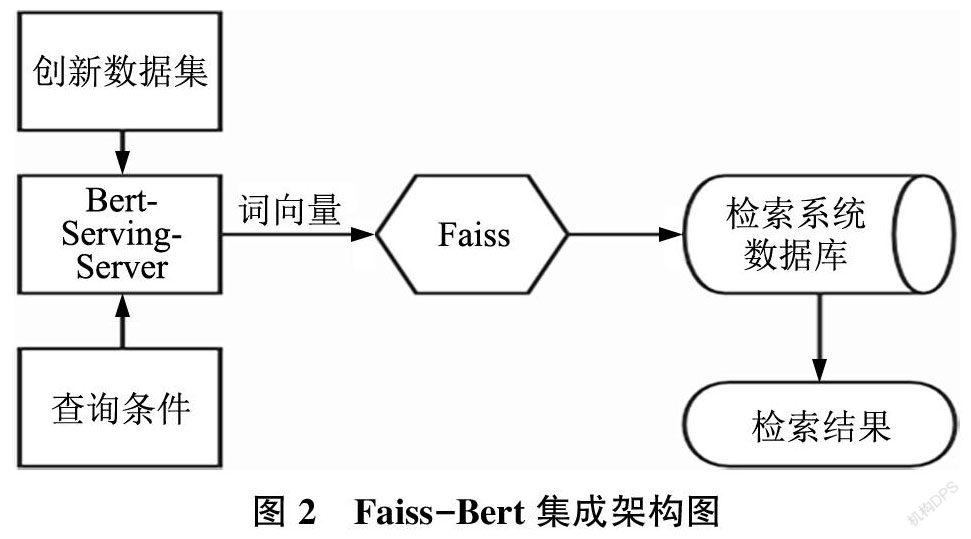
Facebook AI Similarity Search(Faiss)是FacebookAI團隊開發(fā)的, 提供高效相似度搜索和稠密矢量聚類的近似近鄰搜索庫。Faiss 的核心是索引(In?dex)概念, 它封裝了一組包含多種搜索任意大小的向量集, 以及用于算法評估和參數(shù)調(diào)整的代碼庫,并且可以選擇是否進行預(yù)處理以高效地檢索向量。可以預(yù)先通過Bert 模型將非結(jié)構(gòu)化數(shù)據(jù)提取為特征向量, 同時利用開源的Bert-Serving-Server 啟動一個Bert 向量服務(wù), 便捷地調(diào)用訓練好的詞向量以及句向量, 然后通過Faiss 對這些特征向量進行計算, 實現(xiàn)對非結(jié)構(gòu)化數(shù)據(jù)的分析與檢索。本文使用的Faiss 和Bert 的集成架構(gòu)如圖2所示。
3創(chuàng)新點識別實驗
3.1數(shù)據(jù)來源與文本預(yù)處理
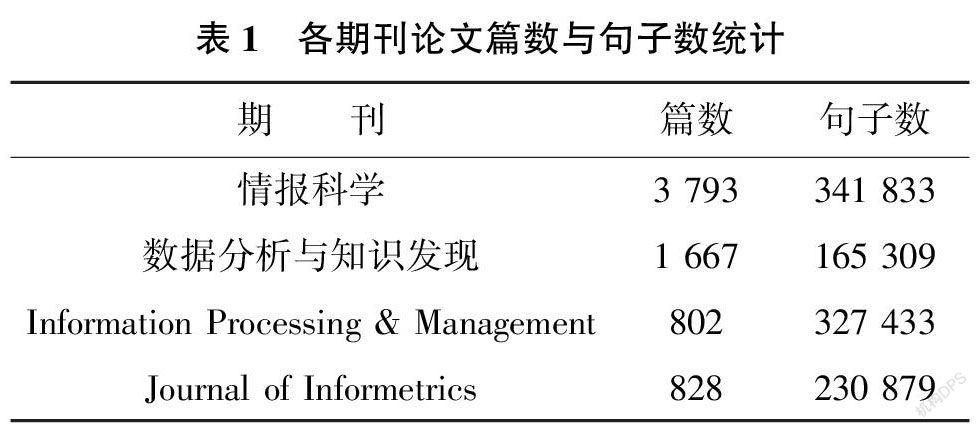
在樣本的選取過程中, 主要選擇高質(zhì)量期刊,輔以論文易獲取性和期刊影響力作為考量。經(jīng)過篩選和分析, 中文情報學期刊論文以2009—2019 年《情報科學》和《數(shù)據(jù)分析與知識發(fā)現(xiàn)》(原《現(xiàn)代圖書情報技術(shù)》)為數(shù)據(jù)來源, 英文情報學期刊論文選取“Information Processing & Management” 和“Journal of Informetrics” 兩期刊2009—2019 年的論文作為數(shù)據(jù)來源。選擇2009—2019 年發(fā)表的論文主要有兩個原因, 一是截止時間較新, 能有效反映近年的創(chuàng)新情況; 二是時間區(qū)間較長, 獲取到的論文數(shù)量多, 有利于時間角度的比較分析。研究所用到的中文期刊論文從CNKI 獲取, 英文期刊論文從ScienceDirect 全文數(shù)據(jù)庫獲取。
獲取的原始論文文本是非結(jié)構(gòu)化的, 它包含了對本任務(wù)來說不必要的標記、圖表等, 需要進行預(yù)處理以適用于模型。處理順序與規(guī)則如下所示: 1)初步去除“本刊訊”、會議預(yù)告、征稿通知、“Editorial Board” 等非學術(shù)論文。
2)用Pdfminer 庫進行PDF—純文本轉(zhuǎn)換。
3)分句,同時對文內(nèi)不必要的部分進行剔除處理, 如分類號、參考文獻、作者貢獻說明、作者信息、關(guān)鍵詞等, 保留摘要與全文內(nèi)容。
最終用于實驗的論文數(shù)以及分句后的句子數(shù)統(tǒng)計結(jié)果如表1 所示。
3.2創(chuàng)新點抽取
創(chuàng)新點的抽取分為不同粒度。與更粗粒度(如章節(jié)) 相比, 句子級抽取技術(shù)得到了更迅速的發(fā)展, 句子級別的自然語言處理技術(shù)也有更好的研究基礎(chǔ); 另一方面, 本研究的出發(fā)點之一是解決科研用戶信息超載的問題, 用戶需要的是粒度更細的創(chuàng)新點, 語詞不能清晰完整地描述一項創(chuàng)新, 能夠完整描述創(chuàng)新點的最小單元是句子。因此, 本研究選擇能夠揭示更完整語義且粒度較細的句子級別進行創(chuàng)新點抽取, 一個創(chuàng)新句對應(yīng)一個創(chuàng)新點。
研究采用隨機抽樣的方式, 從上述分句結(jié)果集中, 抽取中文和英文總數(shù)分別為9328和11272句的兩個數(shù)據(jù)集作為訓練樣本數(shù)據(jù)。
實驗共招募3名碩士研究生進行創(chuàng)新點的人工標注。本文使用的創(chuàng)新句判別標準分為兩類:
一是論文作者明確表達的創(chuàng)新點, 對學術(shù)論文創(chuàng)新的界定按創(chuàng)新程度粗略分為兩子類, 即對已有成果的改進和與已有研究成果完全不同的“全新” 。前者包括但不限于對問題/ 方法/ 理論/ 結(jié)論的優(yōu)化、修正、補充, 通常附有改進點或改進效果的說明, 如表2 例句。這一大類一般有明顯的創(chuàng)新引導詞(組), 如各種比較級句式、“首次提出” “改進” “Novel”等。后者包括: ①提出新理論; ②界定新概念; ③首創(chuàng)新的方法; ④針對特定問題提出不同的解決方案; ⑤構(gòu)建新的系統(tǒng)、框架、模型等; ⑥屬于新的學科交叉點或首次引入其他學科的理論、模型、方法; ⑦在理論空白點上得出新結(jié)論等。如表2例句, 即為針對特定問題提出一套不同的解決方案。
二是論文作者對創(chuàng)新點的隱含表達, 如表2 例句就屬于一種典型的語義預(yù)設(shè), 因為預(yù)設(shè)了“本文研究的路由排隊策略” 存在的前提而得以成立。此外, 對于在綜述等處提及的其他論文的創(chuàng)新點予以剔除, 如例句和例句。標注后得到中文情報學論文創(chuàng)新句占數(shù)據(jù)集總句數(shù)的9.5%, 英文情報學論文創(chuàng)新句占數(shù)據(jù)集總句數(shù)的4.3%。以此作為創(chuàng)新點識別模型構(gòu)建與抽取的基礎(chǔ)。
類別的標注示例如表2所示。
本實驗均基于Python 編程語言, 使用GoogleColab 作為實驗的開發(fā)環(huán)境, 使用的深度學習框架為Tensorflow, 中文語料調(diào)用由Google已完成預(yù)訓練的Bert-base-Chinese 12層模型, 英文語料調(diào)用Bert-base-uncased 12層模型。
加入分類訓練樣本對模型進行微調(diào)后將模型用于完成創(chuàng)新句抽取任務(wù)。在訓練超參數(shù)設(shè)定上, 經(jīng)過多輪迭代調(diào)優(yōu)后, batch_size 設(shè)定為32, 英文讀取序列最大長度為128, 中文讀取字符最大長度為256。迭代Epoch 次數(shù)為4 0, 學習率指數(shù)為2e-5。
在模型訓練過程中將上文構(gòu)建的人工標注數(shù)據(jù)集隨機分為訓練集和測試集, 選取分層十折交叉驗證的方式, 每輪選取9 份作為訓練集, 剩余1份作為測試集。對每輪生成的模型分別計算精度(Accu?racy)、查準率(Precision)、查全率(Recall)與調(diào)和平均數(shù)(F1), 測評模型識別效果, 得出最佳模型的評價指標, 如表3所示。
從表3 可以看到, 兩模型的查全率和F1 值都不太高, 分析認為類別不平衡是一個重要原因。針對這個問題, 本實驗分別進行了上采樣和下采樣的嘗試, 在測試集上的指標結(jié)果有明顯提高, 但預(yù)測結(jié)果明顯較差。因此, 為保證訓練集、測試集、預(yù)測集的類別同分布, 實驗最終沒有采用上采樣或下采樣的方法, 而是保持原數(shù)據(jù)分布情況進行訓練和預(yù)測。
3.3創(chuàng)新點抽取結(jié)果
中文情報學論文總句集為507142句,加上標注的創(chuàng)新句共抽取到9 699個創(chuàng)新句, 平均每篇1.8句左右, 基本符合一般論文寫作情況。其中2 323篇不存在創(chuàng)新句, 約占總數(shù)的42 5%。由于在抽取過程中以查準率為主要指標, 同時以現(xiàn)在的標準對較早論文的創(chuàng)新句進行抽取也可能產(chǎn)生錯漏, 因此不存在創(chuàng)新句的論文篇數(shù)較多。創(chuàng)新句的平均長度約為94個字。
英文情報學論文總句集為558 312句, 加上標注的創(chuàng)新句共抽取到14689個創(chuàng)新句, 平均每篇9句左右。其中322篇不存在創(chuàng)新句, 約占總數(shù)的19.8%。創(chuàng)新句的平均單詞數(shù)約為31個。
3.4創(chuàng)新對象和創(chuàng)新維度的獲取
創(chuàng)新對象和創(chuàng)新維度往往構(gòu)成一項創(chuàng)新的主要內(nèi)容。創(chuàng)新對象是創(chuàng)新的客體, 回答的是“對什么進行創(chuàng)新” 的問題。創(chuàng)新維度可以理解為創(chuàng)新句所論述的創(chuàng)新對象的某個方面, 一般反映創(chuàng)新對象的領(lǐng)域特征。一個創(chuàng)新對象可對應(yīng)一個或多個創(chuàng)新維度, 一篇論文的若干個創(chuàng)新句可以反映不同的創(chuàng)新維度。
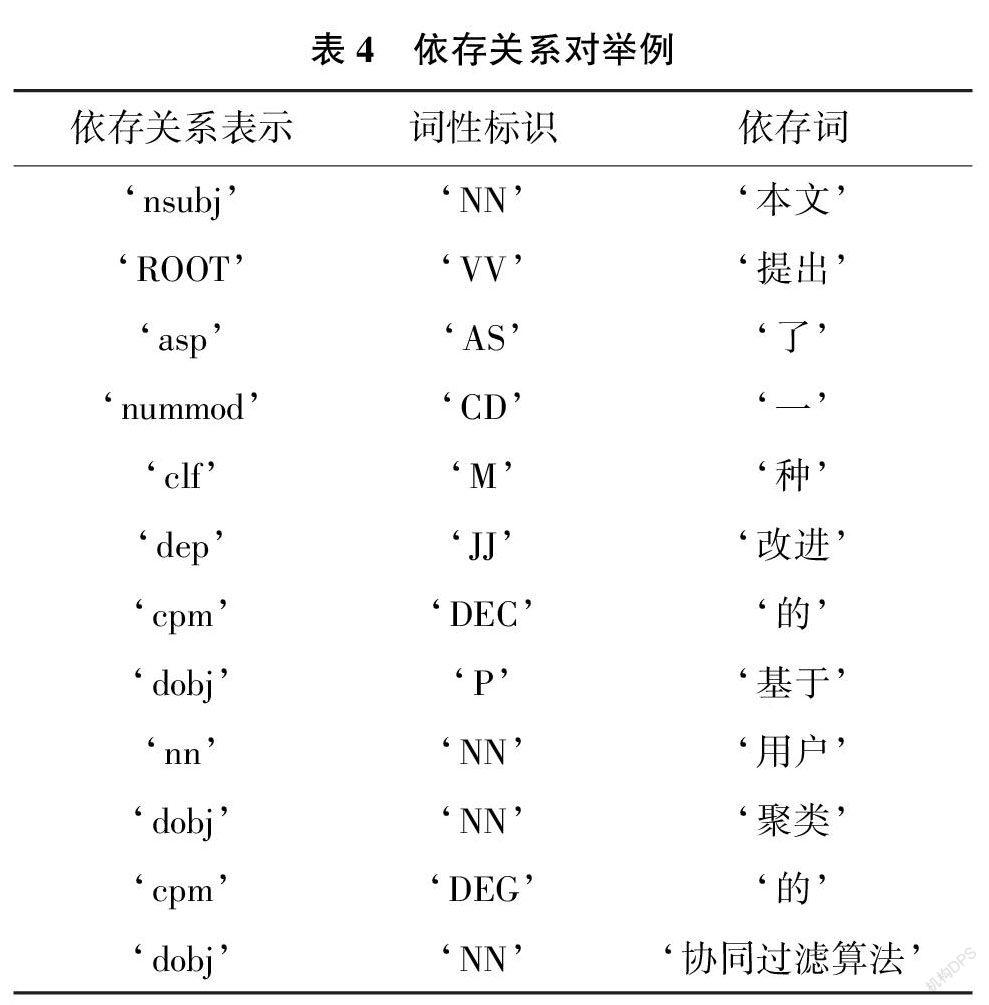
通過對創(chuàng)新句進行依存句法分析, 并構(gòu)建規(guī)則抽取創(chuàng)新對象和創(chuàng)新維度。如對于一個句子, “本文提出了一種改進的基于用戶聚類的協(xié)同過濾算法”。用Stanford CoreNLP 進行語法解析和依存句法分析的結(jié)果如表4所示。
其中“提出” 即為本句核心詞, 以“dobj”依存標識引導的關(guān)系為“‘提出’ ‘基于’ ‘用戶’‘聚類’ ‘的’ ‘協(xié)同過濾算法’”, 其中“基于用戶聚類的協(xié)同過濾算法” 構(gòu)成本句的一個直接賓語, 因此抽取“協(xié)同過濾算法” 作為創(chuàng)新對象;同時“用戶” “聚類” 構(gòu)成一個復合名詞, 因此得到創(chuàng)新維度為“用戶聚類”。依存句法分析后結(jié)果如圖3 所示。
4創(chuàng)新點檢索入口實驗
4.1以創(chuàng)新對象和創(chuàng)新維度為線索的多粒度關(guān)聯(lián)
作為構(gòu)建創(chuàng)新點檢索入口的數(shù)據(jù)基礎(chǔ), 多粒度關(guān)聯(lián)的主要任務(wù)是實現(xiàn)創(chuàng)新句與相應(yīng)章節(jié)的關(guān)聯(lián)。需要強調(diào)的是, 這里“相應(yīng)章節(jié)” 并不是創(chuàng)新句所在章節(jié), 而是描述創(chuàng)新點的具體內(nèi)容的章節(jié)。仍以3.4節(jié)所舉“本文提出了一種改進的基于用戶聚類的協(xié)同過濾算法” 為例, 所要定位到的章節(jié)并非這一句子所在的原文引言部分, 而是原文第四節(jié)“改進的基于用戶聚類的協(xié)同過濾方法”。根據(jù)對知識多粒度的劃分, 介于粗粒與細粒之間的中粒可以有很多個。在創(chuàng)新對象和維度優(yōu)先級的問題上, 對象作為創(chuàng)新動作的直接客體, 能夠更好地表現(xiàn)創(chuàng)新內(nèi)容的本質(zhì), 因此創(chuàng)新對象的匹配優(yōu)先級高于維度。具體定位步驟如下:
1)對論文文本進行章節(jié)識別和層級分割, 提取各級標題;
2)由最深層標題開始, 以某一創(chuàng)新句的對象詞進行精確匹配, 匹配到即跳轉(zhuǎn)至第6步;
3)若未匹配到, 則以創(chuàng)新句的維度詞(組)重復上一步, 匹配到即跳轉(zhuǎn)至第6步;
4)若仍未匹配到, 則對維度詞組進行分詞,以分詞后的各維度詞倒序分別重復第2步,匹配到即跳轉(zhuǎn)至第6步;
5)若無法進一步分詞或仍未匹配到, 將創(chuàng)新對象/維度詞(組)的匹配范圍擴大至全文,統(tǒng)計各小節(jié)(即最深層標題下)出現(xiàn)的次數(shù)(不包括文獻綜述/ 相關(guān)工作/ 相關(guān)研究部分), 返回頻率最高的小節(jié);
6)若某一步匹配到兩個或以上數(shù)量的小節(jié),則將創(chuàng)新對象和維度詞(組)進行AND 連接在匹配結(jié)果中進一步檢索,返回更精確匹配到的小節(jié); 若仍存在多個, 則返回更高級別的標題, 同級別情況下全部返回; 若不存在則以跳轉(zhuǎn)上一步匹配到的小節(jié)為準,此時若存在多個則返回多個, 若為父子關(guān)系則返回父標題;
7)回到全文定位匹配到的標題, 返回標題及標題下的內(nèi)容;
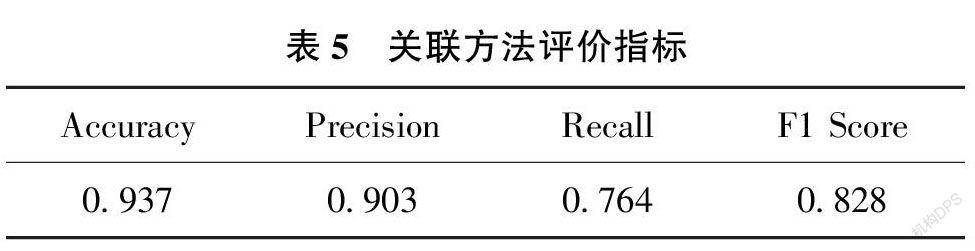
8)將返回內(nèi)容與創(chuàng)新句關(guān)聯(lián)。隨機抽取中文情報學22 篇文獻的111個創(chuàng)新句進行人工標注, 與依據(jù)上述方法進行定位的結(jié)果進行對比, 得到評價指標如表5 所示, 可以認為上述方法具有一定的合理性和可行性。
最終經(jīng)過分析整理得到創(chuàng)新句與創(chuàng)新章節(jié)段落的對應(yīng)關(guān)系, 部分結(jié)果如表6 所示。
4.2創(chuàng)新點檢索系統(tǒng)架構(gòu)設(shè)計
本文通過構(gòu)建創(chuàng)新點檢索系統(tǒng)提供創(chuàng)新點檢索入口, 探索對創(chuàng)新點進行細粒度檢索。如圖4 所示, 創(chuàng)新點檢索系統(tǒng)主要包括3個部分, 即數(shù)據(jù)存儲、索引與檢索模塊和前端展示模塊。所用數(shù)據(jù)來自采用3.4節(jié)方法獲取的創(chuàng)新對象、維度及4.1節(jié)關(guān)聯(lián)的創(chuàng)新句、相關(guān)章節(jié)和論文3種粒度的數(shù)據(jù),輔以論文的其他元數(shù)據(jù),包括作者、發(fā)表時間、中圖分類號等, 所有數(shù)據(jù)保存至MySQL 數(shù)據(jù)庫。
索引與查詢模塊是整個系統(tǒng)的核心, 主要負責完成特征提取、建立索引、排序等任務(wù)。Faiss通過Bert模型將非結(jié)構(gòu)化數(shù)據(jù)提取為特征向量,對這些特征向量進行計算并建立索引, 索引庫會存儲相應(yīng)的索引信息。
前端展示模塊是系統(tǒng)與用戶交互的界面,向用戶展示搜索界面及最終的創(chuàng)新點檢索結(jié)果。通過基于Django框架搭建的后臺,索引與檢索模塊的檢索組件會根據(jù)查詢語句進行檢索排序, 然后將結(jié)果返回給頁面展示模塊。
4.3索引與檢索模塊的設(shè)計與實現(xiàn)
索引與檢索模塊是通過為稠密向量提供高效相似度搜索和聚類的Faiss 構(gòu)建。Faiss 提供了多種索引方法,且便于開發(fā)者根據(jù)需要選擇最恰當?shù)乃饕愋停?本文預(yù)選方案為基礎(chǔ)的IndexFlatL2, 這是一種簡單的檢索L2 距離的索引, 可以精確遍歷計算索引向量,不需要做訓練操作。
利用Bert-serving-server 啟動Bert 向量服務(wù),調(diào)用微調(diào)好的Bert 模型中的詞向量以及句向量,然后通過Faiss 對這些特征向量進行計算,構(gòu)建索引。
當索引就緒后, 一系列Search-time 的參數(shù)可供開發(fā)者在精確度和搜索時間之間進行權(quán)衡、優(yōu)化。同時,F(xiàn)aiss配有自動調(diào)參機制, 能掃描參數(shù)空間, 提供最佳操作點(Operating Points)。
4.4數(shù)據(jù)庫設(shè)計
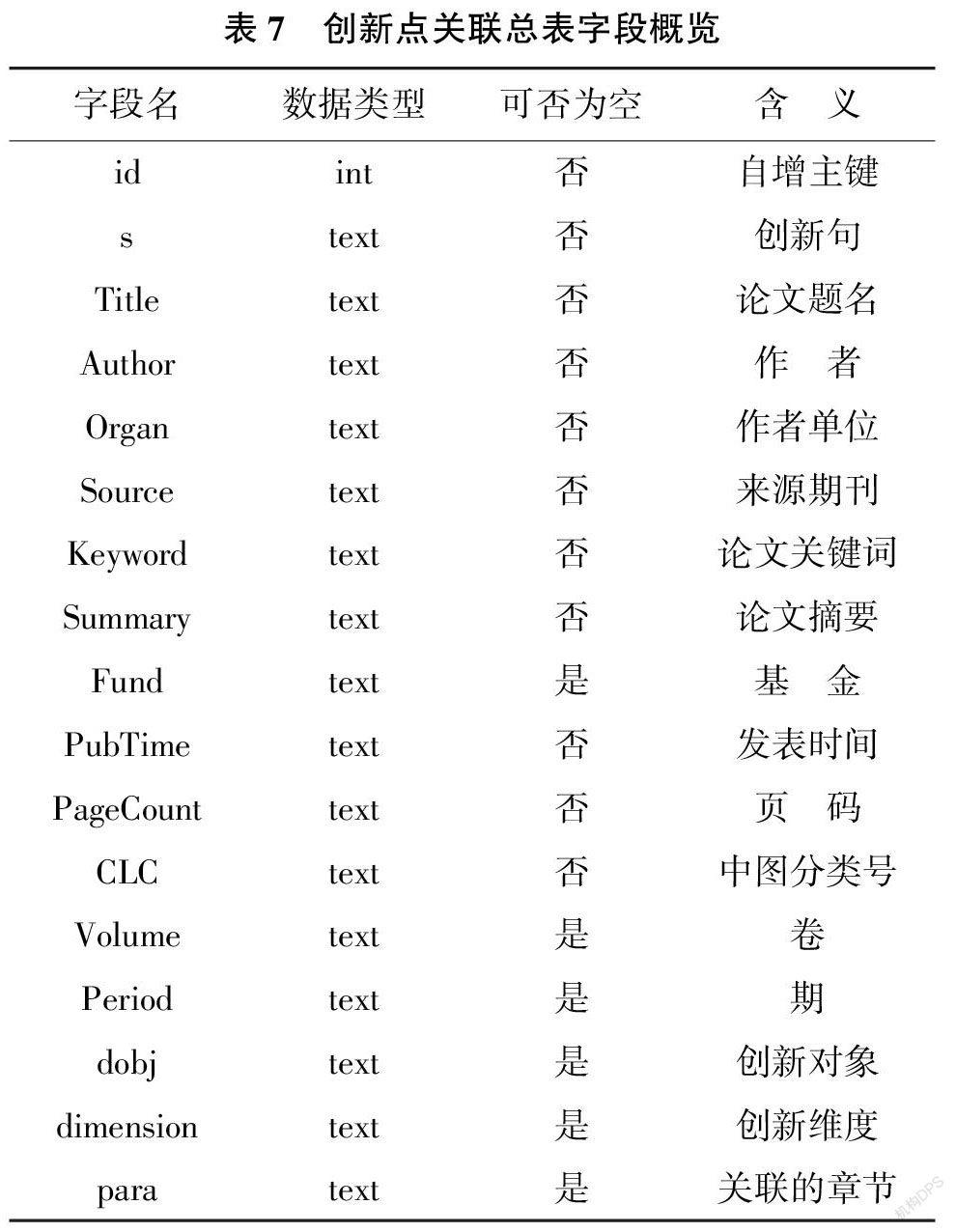
本研究采用的數(shù)據(jù)庫為MySQL。在Django 框架中可以動態(tài)加載實際所需管理的內(nèi)容, 以本系統(tǒng)中的創(chuàng)新點關(guān)聯(lián)總表為例, 生成的創(chuàng)新點關(guān)聯(lián)總表結(jié)構(gòu)如表7 所示。
4.5前端展示模塊設(shè)計與實現(xiàn)
在數(shù)據(jù)庫和索引與檢索模塊搭建好后, 還需要借助Web框架,將檢索結(jié)果以恰當?shù)姆绞椒答伣o用戶。
在Django 中為搜索引擎配置環(huán)境, 利用Djan?go 以及Numpy 實現(xiàn)Faiss 完整的接口支持。采用HTML+CSS+JS 技術(shù)實現(xiàn)系統(tǒng)前端的設(shè)計, Python作為后端開發(fā)語言實現(xiàn)系統(tǒng)業(yè)務(wù)層需求。項目在集成開發(fā)環(huán)境Spyder 下進行。
用戶可以像使用一般的學術(shù)搜索引擎那樣, 在搜索框輸入查詢條件, 然后點擊“檢索” 按鈕查看檢索結(jié)果。
檢索入口所支持的字段類型越多越有針對性,越有利于檢索效率的提高。在考慮平衡性的情況下, 在入口的可選字段,設(shè)置了針對創(chuàng)新句與創(chuàng)新章節(jié)的“創(chuàng)新對象” “創(chuàng)新維度” 關(guān)鍵檢索字段, 以及“作者”“發(fā)表時間”“刊物”等作為可選檢索字段。針對創(chuàng)新句與創(chuàng)新章節(jié)的“創(chuàng)新對象” “創(chuàng)新維度” 是加工程度較深的字段, 也是本研究的核心內(nèi)容。
輸入查詢語句既支持單個檢索詞, 也支持短語檢索,系統(tǒng)則將調(diào)用分詞模塊對查詢語句進行分詞與語義分析,例如:針對創(chuàng)新句輸入“協(xié)同過濾算法” 作為“創(chuàng)新對象”的檢索詞, 得到檢索結(jié)果如圖6所示。
由圖6 可以看到, 在檢索結(jié)果的展示界面主要由創(chuàng)新句、創(chuàng)新對象、創(chuàng)新維度、題名、作者、來源刊物及發(fā)表時間等幾部分構(gòu)成。
類似的, 針對創(chuàng)新句輸入“協(xié)同過濾算法”作為“創(chuàng)新維度” 的檢索詞, 得到檢索結(jié)果如圖7所示。
為了節(jié)省界面空間將創(chuàng)新句等較長字段做了壓縮處理,鼠標移至創(chuàng)新句可完整顯示; 同時通過點擊右側(cè)的“詳細” 按鈕, 可在詳情頁面獲取更多信息, 如創(chuàng)新句的關(guān)聯(lián)章節(jié), 以及論文相關(guān)的其他元數(shù)據(jù),輔助用戶進行決策和判斷, 創(chuàng)新句詳情頁如圖8所示。
5結(jié)論與展望
5.1主要研究結(jié)論
從論文中識別和組織創(chuàng)新內(nèi)容并將其用于學術(shù)檢索系統(tǒng), 提供創(chuàng)新點檢索入口, 對于科學研究的創(chuàng)新與發(fā)展具有重要意義。研究得出以下結(jié)論:
1)Bert模型可以用于句子級創(chuàng)新點抽取任務(wù),即使是在類別非常不平衡(創(chuàng)新句與非創(chuàng)新句)的數(shù)據(jù)集上也有不錯的表現(xiàn), 可以成功抽取出情報學研究論文中的創(chuàng)新句; 在創(chuàng)新句關(guān)聯(lián)創(chuàng)新章節(jié)這一類問答任務(wù)上也有良好的效果。
2)以中文情報學論文為例提出以創(chuàng)新對象和創(chuàng)新維度為線索的多粒度創(chuàng)新內(nèi)容關(guān)聯(lián)方法, 并證明了其有效性和可行性。以關(guān)聯(lián)后的多粒度數(shù)據(jù)為基礎(chǔ)設(shè)計創(chuàng)新點檢索入口, 不僅便于用戶高效檢索論文的創(chuàng)新點, 及時發(fā)掘科研新方向, 還可以通過創(chuàng)新內(nèi)容的分解與重組進行細粒度、多維度的論文創(chuàng)新點分析, 以響應(yīng)更多樣的用戶需求。同時也利于促進創(chuàng)新點檢索系統(tǒng)、創(chuàng)新點知識圖譜等應(yīng)用的落地, 成為現(xiàn)有創(chuàng)新性評價體系的補充。
3)本研究的嘗試表明, 通過深度學習和句法分析對論文創(chuàng)新點進行分析具有一定的可行性和價值。這表現(xiàn)為不僅可以借助這種方法對論文創(chuàng)新性進行更細粒度的分析, 進而對整個領(lǐng)域的研究創(chuàng)新進展有所把握, 實現(xiàn)監(jiān)測的目的, 從而促進科學研究創(chuàng)新。將論文中的創(chuàng)新內(nèi)容進行多粒度關(guān)聯(lián)并用于檢索, 同樣具有可行性和巨大潛力, 可以為科研用戶提供有力支持。
5.2研究局限及未來工作展望
本研究對學術(shù)論文創(chuàng)新點的識別與檢索進行探究, 但信息組織和檢索是復雜的系統(tǒng)工程, 由于理論水平和時間的限制, 本研究也存在一定的局限性: ①研究只選取了國內(nèi)外各兩種情報學期刊的論文, 樣本的覆蓋面還不夠全面; ②Stanford CoreN?LP處理中文分詞不夠準確,導致句法分析存在不準確的情況,一定程度上影響了創(chuàng)新對象和創(chuàng)新維度的獲取; ③定位創(chuàng)新章節(jié)關(guān)聯(lián)時,由于所依據(jù)的文本是經(jīng)過預(yù)處理的, 純文本中圖表都被清除,公式也有缺失或亂碼的情況, 因此在檢索系統(tǒng)中展示信息的還原性和完整性有待提高。
針對以上提到的研究局限性, 提出后續(xù)的研究工作展望: ①擴大樣本選取的學科和期刊范圍, 檢驗方法的普適性, 助力更廣范圍的創(chuàng)新點組織和檢索; ②進一步完善創(chuàng)新句和相關(guān)章節(jié)的關(guān)聯(lián)方法,提高檢準率和檢全率; ③考慮更廣范圍的多粒度創(chuàng)新內(nèi)容關(guān)聯(lián), 打破篇章限制, 將不同論文的創(chuàng)新句、創(chuàng)新章節(jié)以某種機制進行關(guān)聯(lián), 形成知識圖譜, 實現(xiàn)更強大的情報發(fā)現(xiàn)功能; ④將創(chuàng)新點組織和檢索的整套流程集成到統(tǒng)一的系統(tǒng), 或?qū)?chuàng)新內(nèi)容的多粒度關(guān)聯(lián)嵌入到已有學術(shù)信息檢索系統(tǒng), 并證明其可行性和有效性。
(責任編輯: 郭沫含)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
當代陜西(2021年17期)2021-11-06 03:21:36
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設(shè)計與研究(2019年4期)2019-05-21 07:21:24
學苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
