
基于GMM的聽覺場景識別算法研究
2021-12-22 00:13:21劉明曾偉浩
科技信息·學術版 2021年2期
劉明 曾偉浩
摘要:佩戴助聽器的聽力患者像正常人一樣生活在安靜的臥室、嘈雜的道路或音樂會等各種環境中。有些助聽器算法只適用于一個場景,但在另一個場景可能沒有效果,甚至帶來更糟糕的結果。有些助聽器需要患者根據不同的環境手動調整一些參數,通過音量調節開關來控制輸出音量,以適應當前的環境,獲得更好的聲音。而且,一次設置后,佩戴后不可能一直手動調整,手動選擇功能對于老年人、兒童或殘疾人等弱勢群體非常不方便。如果助聽器使用算法自動識別場景,自動設置參數以適應當前環境,并自動增益輸出音量,而不是人工操作的繁瑣部分,將大大提高助聽器的智能化程度。
關鍵詞:助聽器 ?自動識別場景 ?自動增益
一、引言
聽佩戴數字助聽器的聽障患者通常處于各種聽力環境中,如言語、噪音或音樂等[1]。為了獲得最佳的聽覺體驗,在早期的數字助聽器中,數字助聽器廠商會將適合各種場景的程序預刻錄到芯片中,通過撥動開關選擇相應的程序,即不同的頻率響應或其他處理選項,如麥克風陣列語音增強、噪聲抑制、寬動態壓縮和回聲消除等[2]。用戶需要確定他們所處的環境,并手動切換開關來選擇與場景相對應的節目。然而,對于聽障患者來說,識別當前環境并選擇與場景相對應的節目是一項非常困難的任務。即使對于一個聽力健康的人來說,也不清楚選擇哪個節目來匹配當前的場景。最大的問題是,老年人是數字助聽器的主要用戶,讓他們根據不同的應用場景進行功能切換是非常困難的。
二、聽覺場景分析算法概述
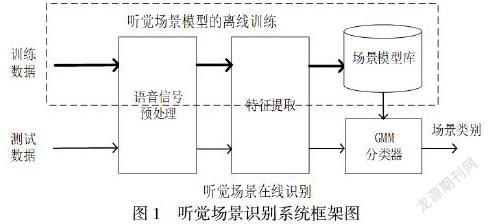
根據數字助聽器的語音信號整體的處理流程可知,聽覺場景分析算法屬于事先準備好的,也就是說經過算法訓練好的模型。算法流程分為三部分,分別是特征提取、模式分類器和參數控制。第一步,數字助聽器通過特征提取將接收到語音信號轉換成特征向量。這一步是識別算法中非常關鍵的階段,因為選擇的特征向量包含有可以區分不同類型的環境的信息,選擇合適的特征向量將會影響到整個算法的識別率[3]。第二步是模式分類器根據特征向量判決輸入的語音信號是屬于哪個場景模型。第三步根據第二步判斷出的場景,配置其他算法的一些參數以適應當前場景。聽覺場景分析的整體結構如圖1所示:
圖1 ?聽覺場景識別系統框架圖
在本文中,考慮到數字助聽器芯片的功耗和計算能力,特征提取采用12維MFCC 梅爾倒譜系數和12維一階二階MFCC 梅爾倒譜系數,分類器采用改進的GMM模型[4]。實驗中,分別比較了改進的GMM算法和改進的GMM算法的識別率,比較了不同維數的特征參數和不同高斯混合數的識別率,最后選擇了最佳參數并應用于數字助聽器系統中。
三、實驗方法
日常生活中,聽覺場景的種類數目眾多,找出典型的聽覺場景是該算法的第一步。因此,為了驗證聽覺場景識別算法的準確性,采用文獻提到的方法從在線聲音庫的網站freesound.org收集到7類音頻數據,分別是嘈雜的語音、展館上的語音、餐廳中的語音、街道上的語音、列車中的語音、純凈的語音和音樂音頻。其中前五種屬于帶噪語音[5]。每個種類總共有300段音頻,其中225段作為訓練數據,75段作為測試數據,每段音頻時間是2s,采樣率為16KHZ,精度為16位。由于語音信號具有短時平穩特性,因此在實驗時可以對每短時音頻信號進行分幀、加窗(漢明窗),每幀音頻信號幀長20 ms,采樣數為320,幀移設置為15 ms,采樣數為240,FFT長度為256。本文首先從GMM高斯核數方面來比較傳統GMM算法和本文提出的改進的GMM算法的整體識別率。特征參數先固定選用12維的MFCC系數。高斯混合數分別取2,4,8,16和32。
四、結論
基于GMM模型的聽覺場景識別算法分為訓練和識別兩部分。訓練部分首先對語音信號進行采樣和量化,然后從語音信號中提取36維特征參數,如MFCC、一階MFCC和二階MFCC。首先,通過GMM訓練算法訓練每個聽覺場景的特定模型參數,最后通過GMM識別算法識別聽覺場景。聽覺場景識別算法是現代數字助聽器的一項高級功能,它極大地提高了現代數字助聽器的智能性,解決了許多聽力受損患者的不便問題。
參考文獻
[1]曹旭來.數字助聽器中響度補償算法的研究[D].南京郵電大學,2014.
[2]雍雅琴.數字助聽器中主要語音信號處理方法研究[D].北京協和醫學院,2013.
[3]魏政,尹雪飛,陳克安.可實現聽覺場景匹配的智能數字助聽器算法[J].聲學技術,2012,31(5):511-516.
[4]何鑫,高勇.一種語音增強中新的噪聲預估計算法[J].通信技術,2018,51(10):2320-2324.
[5]Dillon H.Hearing Aids[M].Thieme,2001.
基金項目:
1:深圳市科技計劃項目(項目編號:JCYJ20180307123857045)
2:廣東省教育廳科技項目(項目編號:2019GKQNCX122)
3:校級科研項目(項目編號:SZIIT2019KJ026)
