基于深度視頻分析的面癱分級方法
2021-12-23 12:24:44段群郭新明黃素萍謝飛
微型電腦應用 2021年12期
段群, 郭新明, 黃素萍, 謝飛
(1.咸陽師范學院 計算機學院,陜西 咸陽 712000;2.西北工業大學 計算機學院,陜西 西安 710129;3.西安電子科技大學 前沿交叉研究院,陜西 西安 710068)
0 引言
面癱是以面部表情肌群運動功能障礙為主要特征的一種疾病,面癱病癥的診斷目前主要還是依靠醫生通過“望聞問切”的診斷方法來對病人的病情進行診斷并評估面癱病癥的嚴重程度。隨著計算機視覺技術的發展,相關學者開始探索能否利用計算機視覺的相關方法來協助、甚至代替醫生“望”診的工作。此外,利用計算機視覺技術進行診斷還能夠較大程度上避免醫生在診斷時受主觀因素的影響。
關于面癱的自動分級與評價,國內外學者已進行了許多該方面的研究。王倩倩等[1]基于AAM關鍵點定位的算法提出了一種面神經運動功能評價方法,徐峰等[2-4]主要提出了人臉微表情的識別方法,此方法不能直接應用于面癱病癥診斷過程中的等級評估。現有的研究成果基本都集中在面癱檢測和面部不對稱性評價的相關研究。大部分的研究缺乏對這種面部不對稱性評價進行進一步量化和分級評估,而且沒有建立一套完整的評價準則,不能切實地應用于臨床。
針對此問題,本研究引入深度學習在視頻處理與分析中的相關理論和方法,探索設計能夠學習更本質、更有效的人臉運動特征信息的深層非線性網絡結構。
1 面癱患者面部圖像和視頻數據的采集及標注
針對面癱病癥嚴重程度的自動評估的相關研究,由于研究對象涉及個人隱私問題,目前國際上還沒有公開的數據集。為此,與陜西省中醫醫院針灸醫療科室合作,協調患者關于面部數據隱私的相關問題,制定相應的數據采集標準與規范,進行數據采集。主要包括如下。
1)圖像和視頻拍攝要求
關于拍攝設備:手機即可,拍攝圖像或者視頻中人臉區域的分辨率在200×200像素以上即可。
關于數據的存儲格式:每個病人樣例的數據放置在同一個文件夾下,文件夾中包含無面部動作的照片以及7種面部動作(微笑、抬眉、皺眉、閉眼、聳鼻、示齒、鼓腮)的照片和短視頻,每種面部動作的數據用其動作名稱作為短視頻和照片的文件名。此外,還應適當考慮數據的多樣性,即人員的胖瘦、不同的年齡階段、性別等因素。
對于相應視頻數據的獲取方式:每個動作讓志愿者做2次,第一次拍該動作短視頻;第二次拍對應的靜態圖像。然后對每個樣例(“樣例”指的是某個病人/正常人的一次測試。對于正常人,只需測試一次,而對于病人,可測試2到3次,記錄康復過程中的不同階段。)進行標注(無面部動作以及7個動作中每個動作是否屬于面癱癥狀;以及此面癱癥狀的嚴重程度應該屬于的級別)。
2)數據標注的要求
醫生的標注判斷必須要明確,不能模糊。如果對于同樣一個表情,有的醫生認為是中度,有的認為是重度,當這種情況常常發生時,會嚴重影響計算機作出有效的模型!在對面部動作進行標注時,需要根據不同的面部動作所關注的不同的區域分別予以標注。例如聳鼻時,主要標注聳鼻運動時面部的異常程度,可對相應關注的區域進行標記,標簽主要分為:正常=0,輕度=1,中度=2和重度=3這4個標準。其他面部動作的數據標注與之類似。
2 基于多重卷積神經網絡的面癱視頻劃分
針對利用計算機視覺技術進行面癱病癥診斷的任務場景,設計一種可以同時提取面癱患者面部動作的空間特征與時域特征的深層神經網絡模型,以完成在面癱診斷時對面部動作開始與結束狀態的識別,實現對面癱診斷視頻按面部動作類型進行的劃分。該網絡結構的關鍵在于卷積層的設計,由于任務場景中,視頻幀之間的差異,主要在于面部皮膚運動的變化,相對于圖像整體來說變化微小,空間特征之間的差異信息難以提取。具有高分辨率的視頻幀序列帶來的卷積層的參數太多,計算復雜度太高。而傳統CNN一般每層僅包含一個局部感受野較大的卷積核,或者局部感受野較小的卷積核。然而,大尺寸的卷積核,參數規模大,計算成本高,特征表達能力有限,獲取了整體運動信息,但忽略了面部變化的細節。而小卷積核只能提取面部運動過程中的細節特征,卻無法提取面部整體特征。
針對這些問題,將大的卷積核分解為若干個小型卷積核疊加。使用多個較小的卷積核的卷積層代替一個卷積核較大的卷積層,使得網絡的層次更深,不僅可以減少參數,并且進行了更多的非線性映射,可以增加網絡的擬合表達能力。不僅可以提取面部運動的整體運動信息,并且也可以提取過程中的細節特征。由此設計了多重卷積神經網絡結構:包含4組卷積層,3個全連接層,一個softmax層,描述網絡的整體結構如圖1所示。

圖1 多重卷積神經網絡框架及設置
首先將序列視頻幀經過多重卷積神經網絡的一系列處理得到的特征向量。然后,將特征序列帶入LSTM中,進而對面癱診斷動作的開始和結束狀態進行準確識別。在整個過程中,視頻幀序列的長度T的選擇直接影響了動作狀態識別的準確率。序列長度足夠短,運算速度快,但是面部動作變化細微,需要足夠長的序列,獲取充足的信息才能進行有效動作識別。完整的算法框架如圖2所示。

圖2 基于多重卷積神經網絡模型的面癱動作開始與結束狀態識別框架
3 基于特征點矢量與紋理形變參數相結合的面癱等級評估
基本思想是融合人臉圖像的結構特征與紋理信息,然后利用LSTM神經網絡進行面癱等級評估。特征參數主要分為兩部分:特征點矢量和紋理特征變化信息。在獲取特征點矢量與特征塊之前,首先利用主動外觀模型(Active Appear-ance Model, AAM)對人臉進行特征點進行定位。如圖3所示。

(a)面癱患者面部圖像
1)基于特征點矢量的特征提取
個體之間存在很大差異,在臉型和器官形狀上表現尤為突出。面部各器官的不同導致個體在做同一個面部動作時都具有很大的差異。人在做微笑的面部動作時不同個體嘴巴變化的程度都不一樣。因此,在基于結構特征的面癱識別研究中,應考慮個體差異對識別結果的影響。利用AAM 算法對人臉共計68 個特征點進行定位,如圖4所示。將選取的特征點記為pi(i=1,2,…,68)。在人臉關鍵點中,當面部進行不同的面部動作時。多數關鍵點都會發生位置變化,但是鼻梁上的3個關鍵點幾乎不變,我們稱此3個關鍵點為主關鍵點,如圖4中紅色標記的關鍵點。因此,我們定義面部各特征點與鼻梁3個主關鍵點之間兩兩構成的矢量為特征點矢量,那么每個關鍵點在每張靜態幀中都有3個特征矢量,構成自身的特征信息。基于特征點矢量,計算特征點之間的歐氏距離,那么每個關鍵點在每張靜態幀中都有3個特征矢量的歐式距離。整個面部共有68-3=65個關鍵點的歐式距離向量,共65×3維。定義矢量距離特征向量為Df(f=1,2,…),f為視頻幀序號。

圖4 面部特征點運動矢量分析
然后基于視頻信息,每兩個連續幀之間特征矢量的距離會發生變化,我們計算連續兩幀之間的距離變化參數Pn,n-1=Dn-Dn-1,2≤n≤N,N為整個視頻的幀數。隨著視頻的持續,可以得到一個N×195的距離矩陣P。
2)紋理形變參數
人在做某些面部動作時,總會伴隨著面部紋理的變化,從而使原本平滑的皮膚表面變得復雜。如何利用面部紋理的變化進行面癱等級的評估是我們關注的研究點。例如微笑主要是嘴和面頰的運動,并產生紋理變化,如圖5所示。2個特征塊記為Mn-1和Mn,其中下標代表幀序號。然后計算特征塊的紋理特征,例如LBP特征。患者做面部動作時,相應的肌肉均在運動,導致相應區域的紋理發生變化,我們計算Qn,n-1=LBPn/LBPn-1,2≤n≤N,N為整個視頻的幀數。隨著視頻的持續,可以得到N個紋理差異矩陣Q。
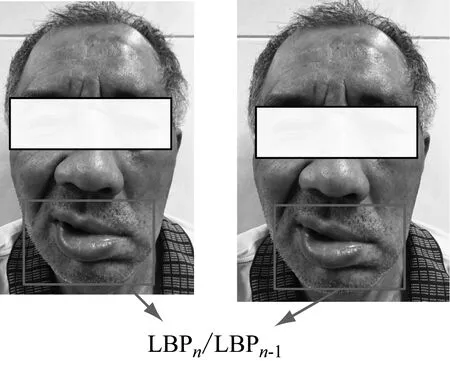
圖5 紋理變化參數的提取
最后,對P和Q進行歸一化,獲得最后的特征向量,并將其作為LSTM的特征輸入,最后得到面癱等級的評估結果。
4 基于多源視頻信息融合的多通道神經網絡的面癱分級
在本研究的任務場景中,視頻幀之間的差異,主要在于人臉皮膚運動的微小變化,特別是輕微面癱患者的面部動作與正常人面部運動之間的差異,以及患者在恢復過程中面部狀態之間的差異非常微小,運動細節差異特征難以準確提取。為此,結合可見光和深度視頻兩種類型的視頻數據,提出融合多特征的多任務深度神經網絡模型,由2個通道時域卷積神經網絡組成。
不同于傳統的卷積神經網絡,該網絡是在時間維度上有2個相互關聯的通道構成,利用了多任務訓練的方法把2種數據源聯合起來,用于提取視頻中面部動作的運動特征。網絡框架圖如圖6所示。該網絡主體部分由2個通道組成,其中,通道一是對可見光時序RGB圖像提取面部運動狀態特征的卷積神經網絡,輸入是原始視頻數據的序列幀;通道二主要關注深度視頻中面部運動特征的提取,網絡輸入為深度視頻序列幀中面部運動差異信息。2個通道之間通過交叉鏈接層對各通道進行正則化,使得各通道間參數協調優化。
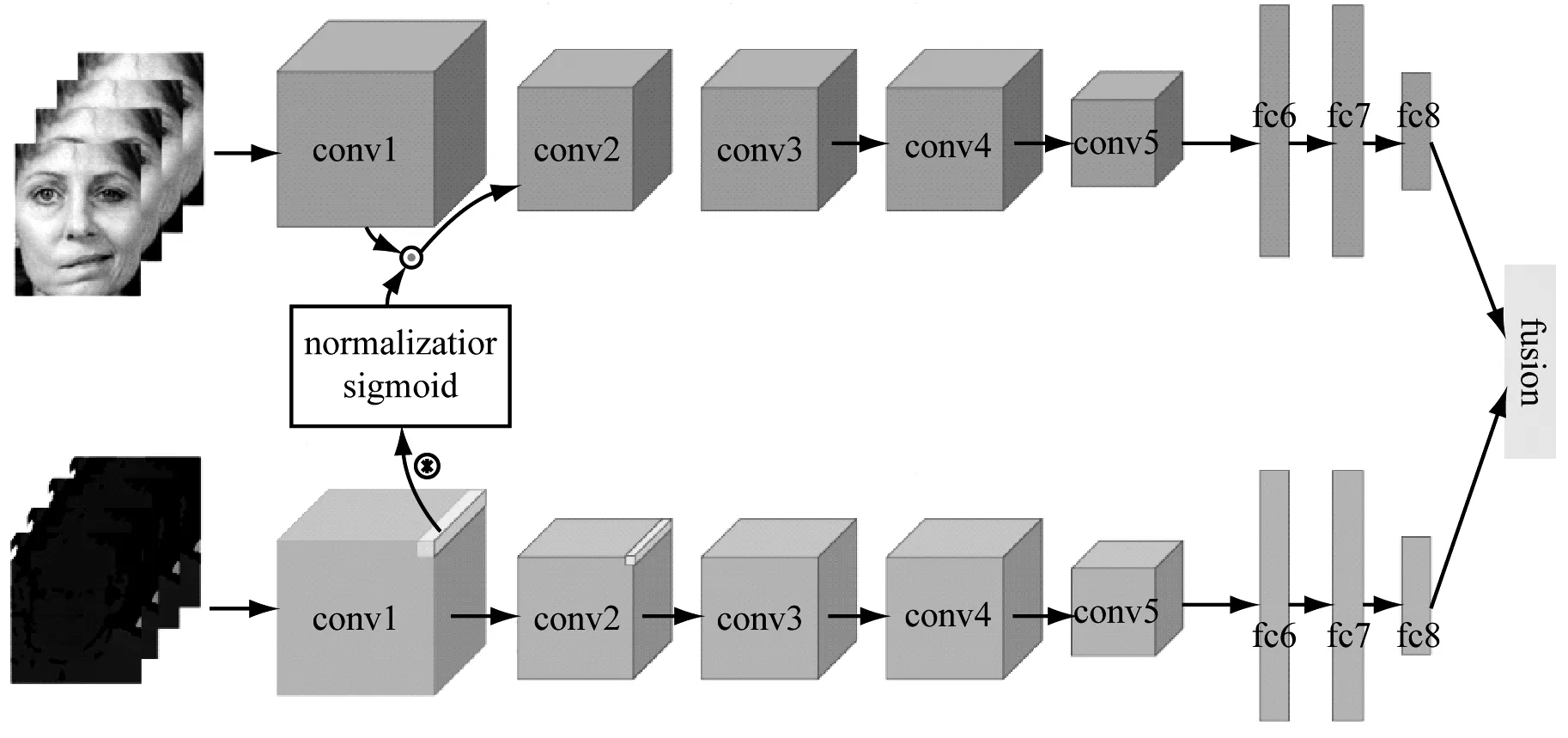
圖6 多源視頻融合的多通道神經網絡框架圖
由于網絡模型中各通道的網絡架構和數據類型不同,學習的特性具有有利于處理運動數據流中細微差別的特性。為對網絡關注機制進行建模,需要對網路模型中的各通道間建立正則化約束,一般在整個網的前一到兩層的范圍內。建立該正則化約束包括以下3個步驟:減小流特征張量x_flowl的維度、均方差歸一化和注意力預測。
令x_rgbl∈iCl×Tl×Hl×Wl,x_flowl∈iCl×Tl×Hl×Wl分別為空間和時間上的l∈{0,1,…,L}層的特征映射,Cl,Tl,Hl,Wl表示特征圖的通道數,時間長度,高度和寬度。使用一個3維卷積層將特征張量x_flowl的維度減少到x_linkl,如式(1)。
x_linkl=W3D_link?x_flowl
(1)
然后,用x_linkl中的所有空間時間特征的均值μ和方差σ對特征張量x_linkl進行歸一化,如式(2)。
(2)
(3)
最后,每個通道都會有一個輸出層,需要通過利用一種方法將2個輸出層進行融合,并利用融合后特征進行面癱識別及分級評估。在此,可以通過提供兩個輸出層相當于正則化的過程,訓練一個以這些輸出作為特征的SVM。
5 總結
在利用面癱患者的面部動作視頻進行面癱分級評估的應用背景下,本研究試圖利用高清可見光和深度攝像機全面記錄面癱患者在做相關面部動作時的視頻信息。針對利用計算機視覺技術進行面癱等級自動評估過程中存在的對相鄰等級準確評估難度大的挑戰,建立面癱患者面部動作視頻數據庫,為基于計算機視覺技術的面癱等級自動評估研究提供可靠的數據支持;融合人臉關鍵點的運動矢量特征和紋理變化特征參數,以解決不同患者在做相同面部動作時的個體差異問題;利用深度卷積神經網絡提取面癱圖像的空域特征信息,利用時間遞歸神經網絡提取面部動作的運動信息,充分利用面癱視頻中所包含的上下文信息和運動特征信息,以更準確地實現面癱患者病癥嚴重程度的自動評估。本研究為面癱病癥的臨床診斷、病情嚴重程度的自動評估提供先進的理論、方法和技術支持,并為其他類似病癥的診斷、醫療智能化奠定基礎。
猜你喜歡
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
中國衛生(2014年2期)2014-11-12 13:00:16
