引書的自動識別及文獻計量學分析
2021-12-28 01:26:18黃水清彭秋茹王東波
情報學報 2021年12期
黃水清 ,周 好 ,彭秋茹 ,王東波
(1. 南京農業大學信息科學技術學院,南京 210095;2. 南京農業大學領域知識關聯研究中心,南京 210095)
1 引 言
自1955 年Garfield[1]系統地提出引文分析思想以來,經過60 余年的發展,引文分析法已成為文獻計量學中系統而成熟的分析方法,并被推廣應用于知識發現領域[2]。然而,在以漢語文獻為對象的計量分析中,引文分析法多針對現代漢語文本,而對古籍文本的研究相對較少。漢語古籍文本承載著豐厚的傳統文化,是歷史和現實之間的橋梁。與現代漢語文本一樣,單篇(部、冊)的漢語古籍文本并不是孤立存在的,文本與文本之間存在著千絲萬縷的聯系。古人在撰寫著作的過程中常常旁征博引,只是形式上不符合當代學術期刊的引用規范,即古籍文本之間存在事實上的引用關系。引書就是古籍文本中旁征博引的表現形象,是古籍文本中的被引文獻,其引用形式雖不及現代文獻規范,但作用基本類似。
目前,關于引書并沒有真正的從引文分析法入手開展研究的成果,而是多采用“因書究學”的研究方法。“因書究學”著重于研究知識傳承、學術脈絡等,忽視了引書在“量”(如引文量、共引量、共現量等)方面的特征。李夢姣[3]對《文選》人工逐卷標注引書,在此基礎上總結和分析了《文選》的引書特點,并從文獻學意義上探討《文選》引書的價值。張麗[4]梳理了《分門古今類事》的引書,包括作者、內容、性質、流傳以及版本在內的各項內容,并對不同版本之間引書的異文情況以及部分引文進行了校訂,并且考察了其中所引的佚書。類似的研究還有許多,這些研究把單部古籍的引書研究得非常細致透徹;然而,知識不是孤立存在,而是共生的[5]。古籍文本之間通過引書建立起了千絲萬縷的聯系,有必要進行整體考察。馬創新等[6-7]利用XQuery(XML query)和SQL(structured query lan‐guage)查詢抽取了《十三經注疏》中的注疏文獻及上下文,統計了其中注疏的數量分布,分析了注疏的特點以及耦合和同被引現象,進而評估了注疏文獻的影響力。從數據上看,馬創新等[6-7]抽取得到的注疏文獻量大大低于本文針對對應典籍識別出的引書條目數。馬創新的研究是結合信息處理手段對古籍文本的注疏進行量化分析的有益嘗試,但總體處于初步階段,只涉及注疏這樣一種引書類型,并沒有真正把引書作為研究對象。由上述引書的研究可以看到,大多數的研究仍聚焦在微觀知識層面的引書統計、考證、歸類、辨析等,具有一定的研究深度;然而,很少有利用引文分析方法,從整體角度探尋古籍之間的聯系。前人的研究奠定了引書研究的基礎,對本文的研究具有一定的借鑒意義和價值。
數據的獲取是引文分析的第一步,也是最基礎的工作。不同于現代漢語文本中的參考文獻有統一的著錄格式,古籍文本中的引用以多種形式散布于文中。前人的研究中,獲取引書條目主要依賴于人工逐卷逐字的閱讀。然而,面對浩如煙海的古籍,純人工操作顯然單薄無力。對于大規模甚至超大規模的古籍文本語料來說,想要深度挖掘其中的相互引用關系,通過人工逐本逐卷標注顯然是不現實的。引書條目中的引書名稱,從自然語言處理的角度來看,屬于命名實體的范疇,因此,可采用命名實體自動識別技術抽取古籍文本中的引書名稱,有效地解決大規模古籍文本引書語料難以構建的問題[8]。目前,對于中文命名實體的抽取,不論是之前依賴人工標注的基于統計的機器學習方法,還是現在的從數據中自主學習的深度學習方法,國內都已經取得了較為滿意的結果,且涉及的領域較多。在針對現代文本的命名實體識別中,近兩年的研究主要集中在直接使用深度學習方法或者基于統計的機器學習和深度學習識別效果的對比。王東波等[9]對比了Bi-LSTM-CRF、CRF(conditional random field)和 Bi-LSTM (bidirectional long short-term memory)三種模型在識別數據科學招聘實體中的表現。相較于另外兩種模型,融入CRF 的Bi-LSTM 模型的準確率、召回率以及F值的均值均超過91%,能夠更有力地保證識別的效果。黃煒等[10]基于Bi-LSTM 和Bi-LSTM-CRF 模型,進行了兩組關于識別涉恐信息實體的對比實驗。從實驗結果來看,加入考慮字符之間關聯性的Bi-LSTM-CRF 模型取得的效果更優,準確率與召回率均高達90%以上。在對古代漢語文本的命名實體識別中,基于CRF 模型在過去的研究中已經取得了較好的效果,例如,李娜[11]在對方志類古籍別名的自動抽取實驗中,CRF 模型的精確率達到了93.52%。基于深度學習的模型,在古漢語中也有初步嘗試。高甦等[12]采用Bi-LSTM-CRF 對《黃帝內經》中的5 種實體進行識別,在對各個模型識別性能比對的過程中,F值最高的是Bi-LSTM-CRF 模型,比CRF 模型的F值上升了接近10%。上述分別基于CRF、Bi-LSTM、Bi-LSTM-CRF 模型在不同領域進行的各項實體抽取研究均取得了良好的識別效果,為本文利用這三種模型進行引書條目的自動識別研究奠定了基礎,也是本文選擇這三種模型進行實驗的原因。
在古籍文本的引書語料構建完成后,即可借助引文分析法對古籍文本的引書開展量化研究。相較于文獻學、訓詁學等單純的“因書究學”引書研究方法,引文分析法能夠把隱藏在古籍文本中的引用關系量化,并揭示文本與文本之間的隱性關聯。同時,隨著對引文研究的深入,這些研究成果逐步形成了體系。除了引文分析法之外,還有引文內容分析、引用行為分析等。其中,在引用行為的研究中,又可細分為引用動機、引用功能和引用偏好等研究。引用行為,實際上屬于信息行為的一種。關于引用行為的研究,一直存在兩個互相競爭的理論,一個是規范理論(normative theory),另一個是社會構建論(social constructivist view)。前者主張引用是為了認同前人的工作,是一種知識的傳承[13];后者則主張引用僅是一種為了說服讀者、增強其觀點可信度的工具[14]。目前,學術界對引用行為的實證研究主要根植于這兩種不同的研究方法。其研究對象仍以期刊論文為主,關于中文圖書類的引用行為研究較少,尤其是對古代漢語典籍的相關研究比較缺乏。在以現代漢語圖書為研究對象的關于引用行為的研究中,主要通過兩種方法開展研究。一是利用具體的引文內容特征,通過研究引文內容的位置、引用次數、引文的上下文等來揭示引用行為。例如,章成志等[15]對39 本學術專著人工構建引用語料庫,并分別從引用位置、引用次數以及引文上下文特征3 個層面分析學術專著的引用行為。二是通過訪談法或問卷調查法直接解讀作者的引用行為[16]。由于現代圖書和古代圖書的相似性,現代中文類圖書的研究方法對古籍的研究有可借鑒之處。但由于本文的側重點在于引書的文獻計量學分析,尚未涉及對引書具體引用內容的分析,因此,關于引用行為的研究只是從通過可量化的引用指標和相關背景知識方面進行初探。
本文把引書當作一種特殊形式的引用文獻,將引文分析法應用于引書研究。首先,利用古文信息處理技術從古籍文本中獲取與引書有關的數據。把引書名稱當作命名實體,在人工標注訓練語料的基礎上,通過機器學習等方法,自動識別出古籍文本中的引書條目。然后,對引書做量化分析,計算引書的各項引文計量指標,展示古籍文本之間可量化的引證關系,并依據各項引文計量指標探析影響古人引用動機及引用偏好的因素,分析古人的引用行為,以期為引書的相關研究帶來新的啟示。
2 實體界定與模型介紹
2.1 語料簡介與實體界定
本文選取阮元主持重刻的《十三經注疏》中的《論語注疏》《毛詩正義》《春秋左傳正義》三部古籍的數字化文本為語料,所有的數據處理和研究都是在此語料上進行和完成。《十三經》作為儒家的經典,歷朝歷代研究解讀的不計其數,在所有解讀《十三經》的典籍之中,以清朝著名學者阮元主持校刻的《十三經注疏》 流傳最為廣泛[17]。其中,《論語注疏》《毛詩正義》《春秋左傳正義》的引書條目不僅數量眾多,而且引用內容廣泛,引書類型豐富,對經典文獻的引用也較多。同時,《論語》《詩經》《左傳》三部儒家經典著作分別為語錄體典籍、詩歌類典籍、史書類典籍,體裁不同且各具代表性。因此,本文把這三部經典著作作為研究對象是極為合適的。
與現代文獻中的引文不同,古籍文本中的引書不但沒有引用標志,也沒有統一的著錄格式,更沒用統一的列舉位置。劉姝[18]把古籍文本的引書分為明引和隱引兩種類型。明引明確標明了引用(引書的書名、作者),而隱引則與施引文獻的文字連為一體,較難分辨出引用的跡象。由于隱引較難識別,本文只統計明引形式的引書條目,即直接標明了引書的引用類型。
2.2 模型選擇與簡介
在1995 年MUC-6 會議上,命名實體作為一個明確的概念被正式提出[19],對命名實體識別(named entity recognition,NER)的研究從對象到方法都在不斷地推陳出新。從早期的簡單統計模型到現在的基于機器學習的方法,命名實體識別的性能在不斷地提升。CRF 模型是無向圖模型下的一種馬爾科夫網絡,因其是在某種特定條件下的馬爾科夫隨機場,所以稱之為條件隨機場。與最大熵模型和隱馬爾科夫模型相比,條件隨機場模型作為通過自定義特征模板能同時利用實體左右兩邊的邊界特征,而且還可以重疊多重特征,利用內外部多重信息,采用豐富特征集的辦法來提高識別精準度。在引書條目實體的識別過程中,也需要考慮實體左右邊界特征的影響,因此,本文選取了在以往實體識別任務中表現一貫良好的CRF 模型來完成識別實驗。
近年來,隨著神經網絡的發展,需要大量人工標注的傳統機器學習方法逐漸被效率更高的深度學習模型所替代或部分替代。循環神經網絡(recur‐rent neural network,RNN)在每個隱藏層之間建立起關聯,能夠有效地捕捉上下文信息,并且尤其擅長序列標記任務,但實際上RNN 在長期依賴關系的學習中表現并不良好。在RNN 的基礎上,能夠記憶更長數據序列的長短時記憶網絡(long shortterm memory,LSTM)、雙向長短時記憶網絡(Bi-LSTM) 應運而生。LSTM 單元主要由存儲單元、輸入門、輸出門以及遺忘門構成。通過模型的訓練對各個門或者單元的參數進行控制及更新,最終使LSTM 單元能夠高效地利用長距離的歷史信息。相比于LSTM 只能利用上文信息,Bi-LSTM 能夠同時利用文本的上下文信息,擁有前向層和反向層兩個不同方向的并行層,可儲存來自兩個方向的未來的上下文信息,能讓文本特征信息有充分表達,更有助于命名實體的有效識別。由于識別效果良好且效率高,因此大量研究選擇了Bi-LSTM 模型。本文的研究是以字為單位進行的引書條目實體識別,在模型訓練過程中,需要考慮前后字之間的聯系和相互作用,因此,本文選擇此模型來處理實體識別任務。
盡管Bi-LSTM 模型識別命名實體的效果較好,但當輸出標簽之間存在較強的依賴關系時,其性能會受到一定程度的影響。Huang 等[20]提出了Bi-LSTM結合CRF 層的Bi-LSTM-CRF 模型。Bi-LSTM-CRF模型結合了Bi-LSTM 模型和CRF 模型的特性,在考慮實體上下文特征的同時,也能兼顧輸出獨立標簽之間前后的依賴關系,強依賴的問題得到了較大改善。該模型應用于命名實體識別任務后,能夠提升命名實體識別的性能。Bi-LSTM-CRF 模型的整體框架如圖1 所示。該模型主要包括輸入層、Embed‐ding 層、Bi-LSTM 中間層、CRF 層、輸出層等。在將單個字序列標注以后,作為模型的輸入,中間通過正反兩個方向的LSTM 網絡層對其建模,再利用CRF 層對其前后關系建模,最后輸出對應的標簽序列。
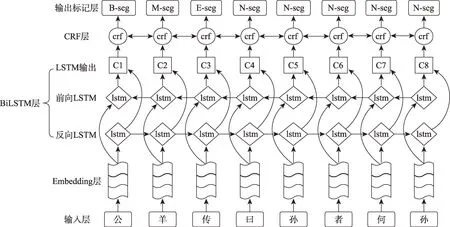
圖1 LSTM-CRF模型的主要結構
為了客觀檢驗CRF 模型、Bi-LSTM 模型以及Bi-LSTM-CRF 模型在引書條目實體識別過程中的實際效果,本文以《論語注疏》《毛詩正義》《春秋左傳正義》 為研究對象,分別采用CRF 模型、Bi-LSTM 模型、Bi-LSTM-CRF 模型識別和抽取引書條目,并對比實體識別效果,從中篩選最適用的引書實體識別技術方案。
3 實體識別實驗
3.1 語料的預處理
文本中的實體,是以詞語或短語的形式對世間萬物的指稱,包括命名性指稱、名詞性指稱和代詞性指稱[21]。命名性指稱是指通過名字表示實體,如人名、地名等。名詞性指稱是指通過名詞或者名詞性短語表示實體,如職稱、職位等。代詞性指稱是指通過代詞來指代實體,如“你”“我”“他”。本文研究的命名實體集為《論語注疏》《毛詩正義》《春秋左傳正義》三部典籍中的引書,屬于名詞性指稱的一種。為了構建實驗語料,首先采用人工方式對《論語注疏》《毛詩正義》《春秋左傳正義》中明引條目進行標注,并規定標記符號為“ 【】 ”。具體標注后的樣例如下:
○正義曰:夫人孫意,傳文不明,故云魯人責之。蓋責其訴公於齊侯,而使公見殺,故慚懼而出奔也。【《公羊傳》】曰:“孫者何?孫猶孫也。內諱奔,謂之孫。”【《穀梁傳》】曰:“孫之為言猶孫也,諱奔也。”杜用彼為說。昔帝堯孫位以讓虞舜,故假彼美事而為之名,猶孫讓而去。
對標注了引書條目的語料依次進行文本格式轉換、合并以及數據預處理等工作,再去掉標點;然后,選用5-tag 作為標記集拆分成字,形成訓練語料 。 5-tag 標 記 集 采 用 {B-seg, M-seg, E-seg, S-seg,N-seg}標注方式,即B-seg 表示實體的開始,M-seg 表示實體的中間部分,E-seg 表示實體的結尾,S-seg 表示單字實體,非實體用N-seg 表示。具體樣例如表1 所示。
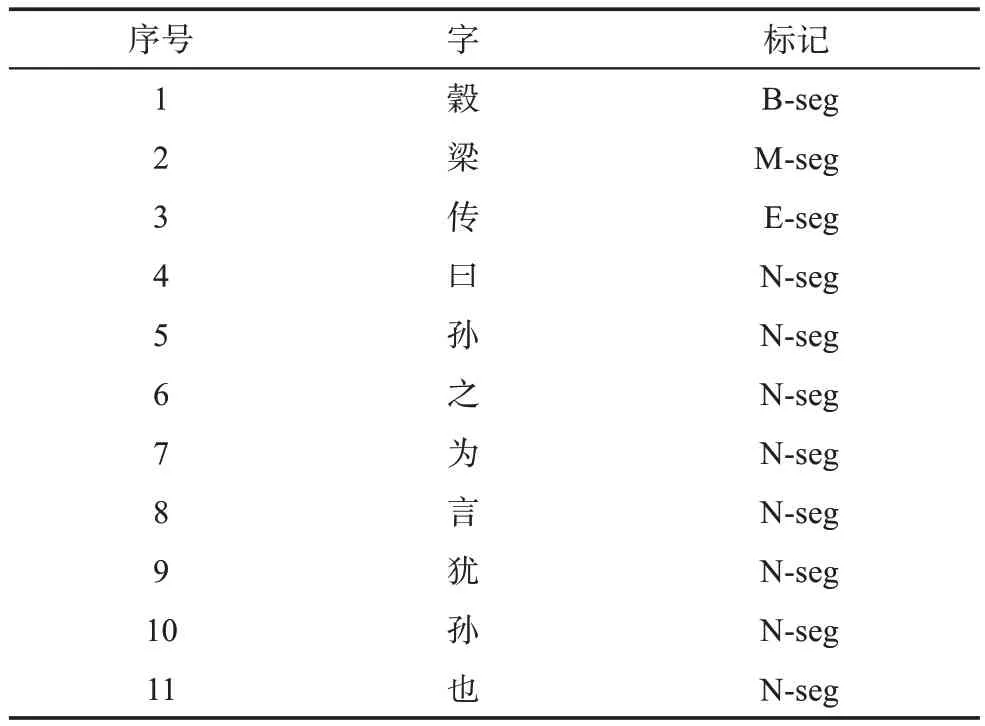
表1 訓練文本樣例
3.2 抽取性能評價指標及參數設置
引書實體名的自動識別模型選用準確率P(pre‐cision)、召回率R(recall)和調和平均數F(F-mea‐sure)作為測評指標。具體計算方法為
準確率(P)=識別正確的實體數/機器識別出的實體數×100%
召回率(R)=識別正確的實體數/人工標注的實體數×100%
調和平均值(F)=(2×P×R)/(P+R)×100%
在實驗過程中,分別選用了CRF、Bi-LSTM 和Bi-LSTM-CRF 三種訓練模型,三者的區別在于部分參數有所不同。其中,Bi-LSTM 和Bi-LSTM-CRF 兩者的參數相近,后者僅在前者基礎上加入了一層CRF模型。在模型中,具體參數值的設置為:dropout_rate=1,learning_rate:=0.001;一次訓練所選取的樣本數batch_size=32;迭代次數epoch_num 設置為200 輪;梯度閾值Clip=5;采用Adam 梯度下降算法。
3.3 實驗結果及分析
本文分別采用CRF、Bi-LSTM、Bi-LSTM-CRF三種模型對《論語注疏》《毛詩正義》《春秋左傳正義》的引書條目進行實體名識別。為了防止實驗結果出現偶然性,在實驗中,將語料按照9∶1 的比例分為測試語料和訓練語料,使用十折交叉驗證的方法來測試所構建模型的性能,以期從中獲得最科學合理的自動抽取模型。測試結果如表2~表4 所示。
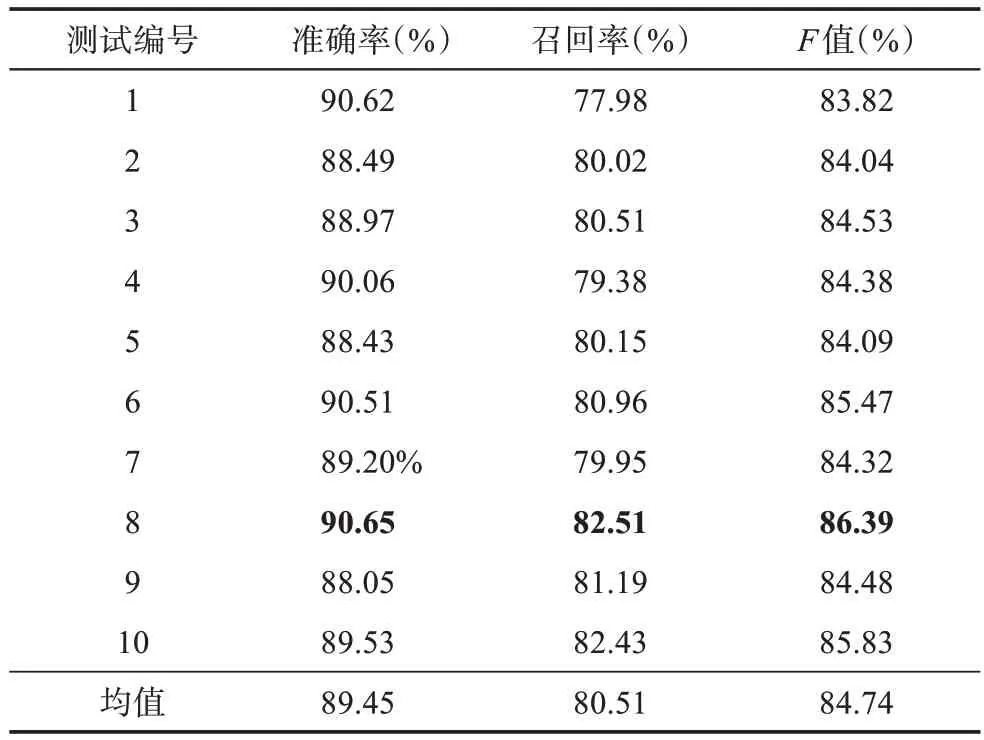
表2 基于CRF模型的引書條目實體識別性能
對比表2~表4 可以看出,Bi-LSTM-CRF、Bi-LSTM 模型的性能基本相同,而CRF 模型則存在明顯差距。具體而言,兩種深度學習模型的引書識別性能表現優異,無論是Bi-LSTM-CRF 模型還是Bi-LSTM 模型,各組實驗的識別準確率、召回率和F值均超過了94%。與CRF 模型相比,基于Bi-LSTM所構建的模型在準確率上平均提高了5.43%,在召回率上平均提高了13.93%,F值提高了9.92%。相較于 Bi-LSTM 模型,Bi-LSTM-CRF 模型全部 10 組實驗的均值有小幅度上升,其中準確率提升了0.07%,召回率基本持平,F值提升了0.03%,但最優模型的F值反而下降了0.01%。可以認為,在深度學習模型中加入CRF 層對引書的實體識別并無實質影響,Bi-LSTM-CRF 模型與Bi-LSTM 模型的F值百分比小數點后兩位的差異是語料或統計誤差,實際上兩個模型的性能差不多。將CRF 加入Bi-LSTM模型,目的是改善標簽之間強依賴關系對實體識別的可能影響,當引書實體名的各字符之間關聯性不強時,引入CRF 層的意義就不大了。
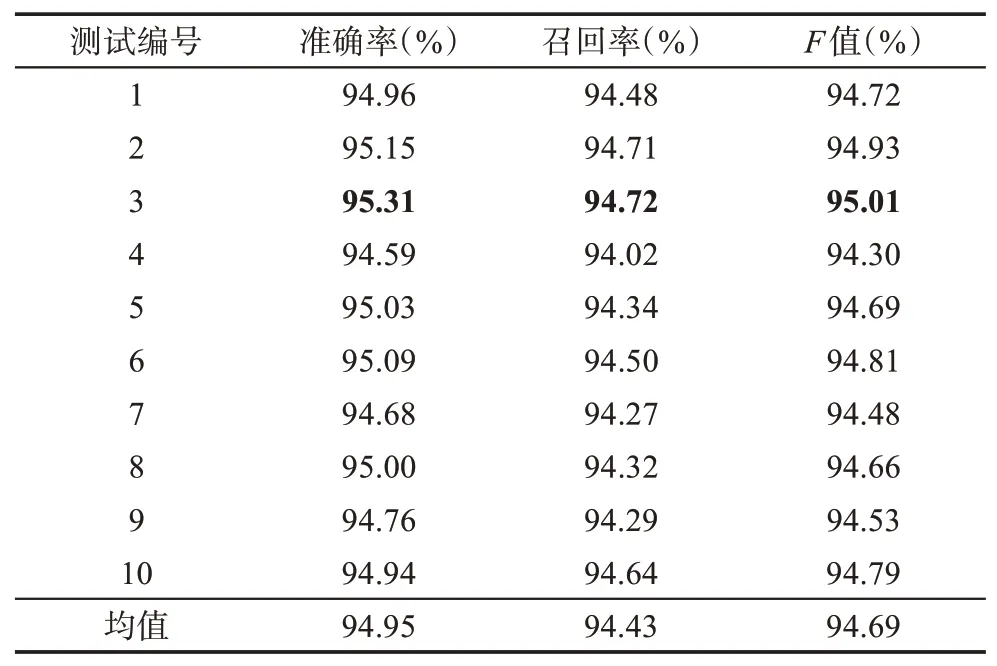
表4 基于Bi-LSTM-CRF模型的引書條目實體識別性能
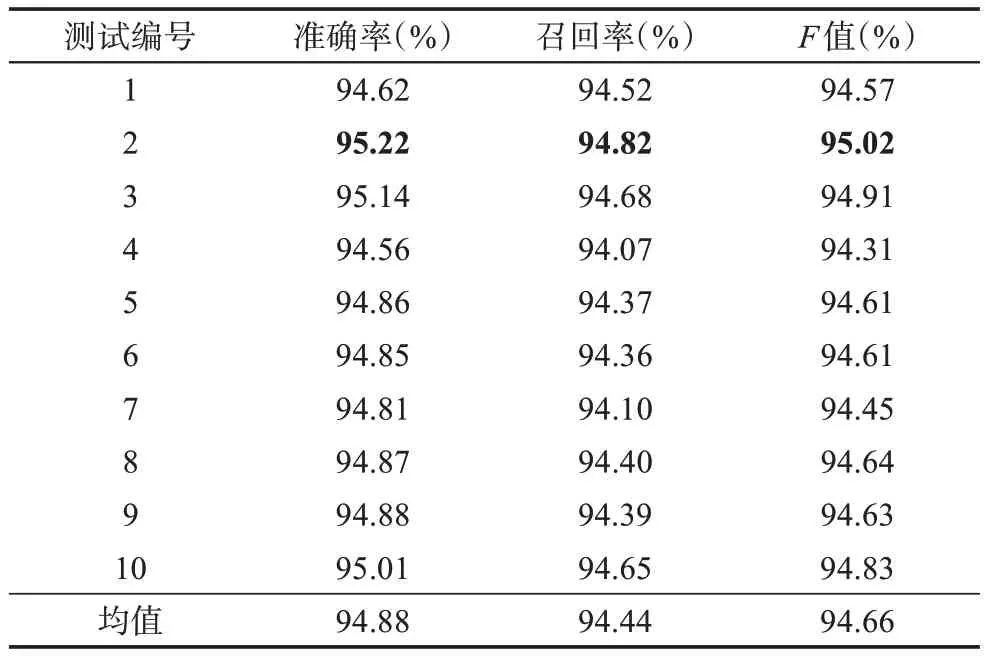
表3 基于Bi-LSTM模型的引書條目實體識別性能
以上數據說明,在引書的實體名識別方面,深度學習模型的性能比傳統機器學習的性能要優越很多,在Bi-LSTM-CRF 和Bi-LSTM 兩種深度學習模型中,融入CRF 的模型有時能提高序列化模型的性能,但總體性能無明顯差異。總之,在無任何人為特征添加的情況下,僅基于“字”這一基本構成元素,Bi-LSTM-CRF、Bi-LSTM 兩種實體識別模型均可選擇。綜合實驗結果與技術先進性兩方面考慮,Bi-LSTM-CRF 模型可作為首選。
4 古籍引文分析
4.1 引書總體情況
對識別出的引書條目進行匯總,計算得出三部典籍總計發生了12369 次引用行為,統計結果如表5 所示。從統計數據來看,引用的總次數越多,引書的種類就越豐富;反之,引用的總次數越少,引書的種類也越少。同時,數據也顯示,古籍文本本身的篇幅長短會影響引書的規模和種類。此外,體裁和內容上的不同也會影響引書類型。

表5 引用概況
《論語》全書20 篇492 章,累計1.1 萬余字,而《論語注疏》的篇幅總計達到23.6 萬余字。《左傳》全書約19.6 萬余字,《春秋左傳正義》汲取各家之營養,全文共計200 多萬字。《詩經》收錄詩歌305篇,共3.9 萬余字,在孔穎達旁征博引之下,《毛詩正義》成為了一部將近800 萬字的鴻篇巨著。在內容體裁上,《論語》是一部記錄孔子一行人言語形為的語錄體著作,是儒家思想最初階段最重要的源泉。孔子學識淵博,《論語》一書的內容幾乎無所不包,涉及社會、政治、經濟、文化等各個方面。因此,詮釋《論語》必然要具備廣博的學識。由于《論語》的文體主要是語錄和對話的形式,而《論語注疏》中的引書更多的是對其中的對話背景信息進行補充,其次才是解釋某一詞語在特定情境下的含義。《詩經》內容豐富,用詞考究,反映了包括政治、祭祀、天文、地理、動植物等在內的社會生活的方方面面。為了更好地服務于科舉考試,孔穎達熔鑄百家之長,尤其注重“禮教”和“訓詁”,對《詩經》的內容進行了盡可能細致入微的呈現,使得《毛詩正義》成為《五經正義》中最具價值的一部著作。《左傳》與《公羊傳》和《谷梁傳》一起為解釋《春秋》而著,是一部編年體史學著作。與《公羊傳》和《谷梁傳》重解經不同,《左傳》重記事,以故事的形式講述了《春秋》涉及的史實;而《春秋左傳正義》則從政治角度通過大量引用歷史類文獻,對某些歷史人物和事件其進行詮釋和辨正。
4.2 引書分布特征分析
4.2.1 引書的分布特點與核心古籍
古籍文本的引書呈現二八律,即引書分布不均勻,小部分的引書承擔了大部分的被引量。在三部古籍中,引用次數排前10 位的引書在總引用次數中占比較大,均超過了70%,《毛詩正義》更是達到了79%(表6)。另外,統計數據顯示,《論語注疏》中引用總次數的一半來自6%的引書,而20%的引書被引次數之和占總被引用總數的81%;《毛詩正義》中引用總次數的一半來自2%的引書,9%的引書被引次數之和占總被引用次數的81%;《春秋左傳正義》中引用總次數的一半來自3%的引書,8%的引書被引次數之和占總被引用次數的80%。并且,三部典籍中單種引書被引次數占比極高的引書多有重復。以上數據說明,古籍中也存在“核心”文獻,處在核心區的古籍相較于非核心區的古籍更具影響力。
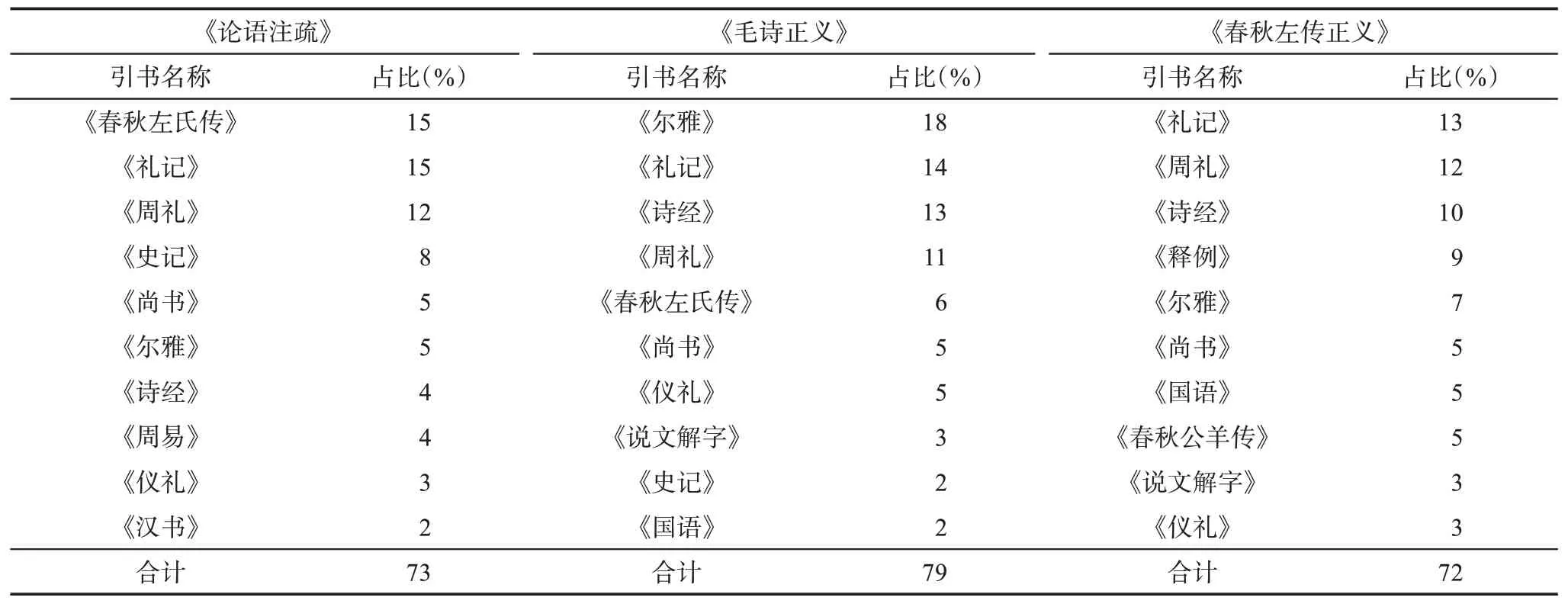
表6 引用次數前10位的引書占比
4.2.2 引書中各類別文獻引用情況
按照經史子集四部分類法,《論語注疏》《毛詩正義》《春秋左傳正義》三部典籍中的引書均以經部文獻最多,其次是史部文獻,然后才是子部和集部文獻。屬于經部的引書在《論語注疏》中占比達75%,在《毛詩正義》中占比達88%,在《春秋左傳正義》中占比達80%。分析三部典籍的原文發現,部分對史部、子部、集部的引用也是出于解經釋經的目的。這些數據充分證明了《論語注疏》《毛詩正義》《春秋左傳正義》的絕對經學屬性。出現這種情況,主要有三方面原因。第一,參與編撰三部典籍的皆為當時的博學大儒,主持編撰的兩人均是著名的經學家。孔穎達為孔子的第三十二代孫,師從大儒劉焯,家學淵源又勤奮好學,經學功底深厚。邢昺為北宋經學家,對儒學有極大的造詣,其經學思想上承孔穎達,曾被選為太宗諸子講群經。因此,相較于其他類型的文獻,他們對于經部文獻更為熟悉。第二,唐宋的統治者都把儒家思想作為主導思想,儒學盛行。第三,與注疏的特點有關。“以經釋經”是訓詁學的傳統體例,上述三者的引書數量分布恰好體現了“以釋經義”為核心的基本原則,全面體現了注疏的重點和方法。
為了更直觀地顯示出《論語注疏》《毛詩正義》《春秋左傳正義》三部注疏文獻中引書的引用情況,本文特繪制引書詞云圖,如圖2 所示。通過詞云圖,可以清楚地看到三部注疏文獻總引書量較大,具體引書情況各不相同,但高被引引書有所重合。

圖2 《論語注疏》《毛詩正義》《春秋左傳正義》引書詞云圖
4.3 引書引文耦合分析
引文耦合[22-23]是指兩篇或多篇文獻具有共同的引用文獻,耦合強度反映了文獻與文獻之間關聯關系的強弱。典籍之間同樣存在大量的共同引書現象,因此也可以使用引文耦合方法來探究。通過對《論語注疏》《毛詩正義》《春秋左傳正義》共同引書的計算,得到三部典籍的耦合強度矩陣,如表7所示。
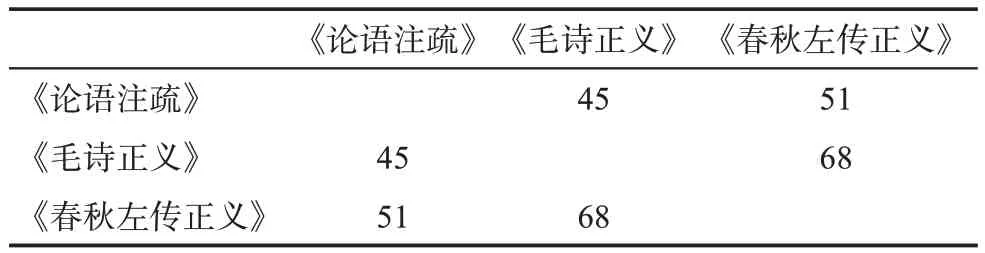
表7 引書引文耦合矩陣
耦合強度用施引文獻共同引用的參考文獻來衡量,共同引用的參考文獻越多,耦合強度也越大,表示兩者關系越近。在三部典籍中,單從共同引用的引書量來看,《春秋左傳正義》和《毛詩正義》的耦合強度最高,三部典籍之間的平均耦合強度為54.67。但由于三部典籍的引書基數的大小不一,因此,僅考慮數量的耦合強度存在一定的偏差。加入對引書基數的考慮后可以看出,在三者之間,《論語注疏》與《春秋左傳正義》的關系比《論語注疏》與《毛詩正義》之間的關系要更近,《毛詩正義》和《春秋左傳正義》之間的關系又比兩者分別與《論語注疏》的關系要近。從成書時間線來看,《詩經》成書于春秋中期,《左傳》成書于春秋末期,《論語》成書于戰國初期。一般來說,同時代背景的典籍可能在各方面有更多的共同點。在補充、解釋典籍時,時間相近的典籍由于社會環境等的相似,引用的書目也會更趨于一致。從注疏風格來看,《毛詩正義》和《春秋左傳正義》同屬唐疏,而《論語注疏》屬宋疏。同一時代的注疏風格較為相近,而且前兩者的注疏人相同,因此,前兩者之間的關系更為親密。從典籍自身特點來看,《毛詩正義》《春秋左傳正義》《論語注疏》三者都廣泛征引了經史子集各個門類的著作,但前兩者在篇幅上遠勝于后者,因此前兩者之間的耦合強度會更大。再看《論語》《詩經》《左傳》三部原著本身,《左傳》用敘事散文的形式記載了具體的史實,《詩經》用詩歌的形式反映了社會風貌,而《論語》則主要以對話的形式體現孔子的思想。就內容和形式來說,孔子及其弟子的言行勢必要從具體的事件當中發生,詩歌的編排也要出于一定的現實事件,那么《論語》和《詩經》分別與《左傳》在內容上存在關聯也是合理的,因此,《論語注疏》和《春秋左傳正義》以及《毛詩正義》和《春秋左傳正義》在撰述時必然有可能大量借鑒相同的資料。
為了能更清晰地展現三部典籍之間的關聯,本文選取了引用次數前30 位的引書,繪制了三部典籍的引用關系網絡圖,如圖3 所示。
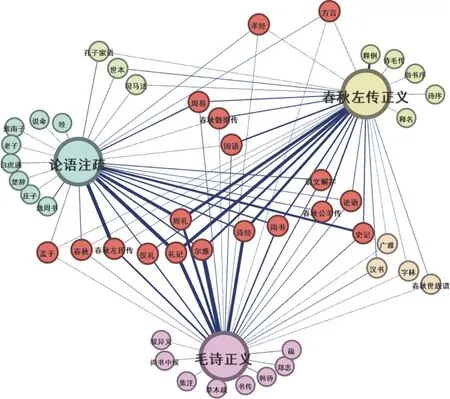
圖3 引用關系網絡圖
三部典籍的引書數據還有一個有趣的現象。《論語注疏》對《論語》以及《春秋左傳正義》對《左傳》的引用比例較低,而《毛詩正義》引用《詩經》的比例達到了13%。王力先生曾說,“孔穎達作疏的長處在于五經融會貫通,特別善于以本書證本書”[24]。《毛詩正義》正體現了這一點。不同于三傳之間互為補充的《春秋三傳》,作為中國古代詩歌開端的《詩經》是獨立存在的一部詩歌總集,在內容上并沒有其他同時代的作品與其互為補充。在注釋《詩經》時,《毛詩正義》通過“以詩釋詩”來達到闡明主旨、解釋詞義、融會貫通的作用。在《毛詩正義》對《詩經》本身的這些引證中,既有對內容的背景補充,也有對內容情感的闡釋說明等。由此可見,《詩經》的前后內容之間是具有一定關聯性的,前文與后文相互呼應。
4.4 引書文獻影響力分析
4.4.1 同被引矩陣
引書被引頻次越高,說明該書參考價值越大。三部典籍有很多共同的引書,而且這些共同的引書在總引用次數中占比很大。本文選取被引次數合計大致占到總被引次數90%的引書,作為全部引書的典型代表,對其做同被引分析。基于同被引數據,生成同被引矩陣,如表8 所示。同被引矩陣是表示兩篇文獻之間相似度程度的矩陣[25],即兩者的數字越大,表明兩者的關系越近。
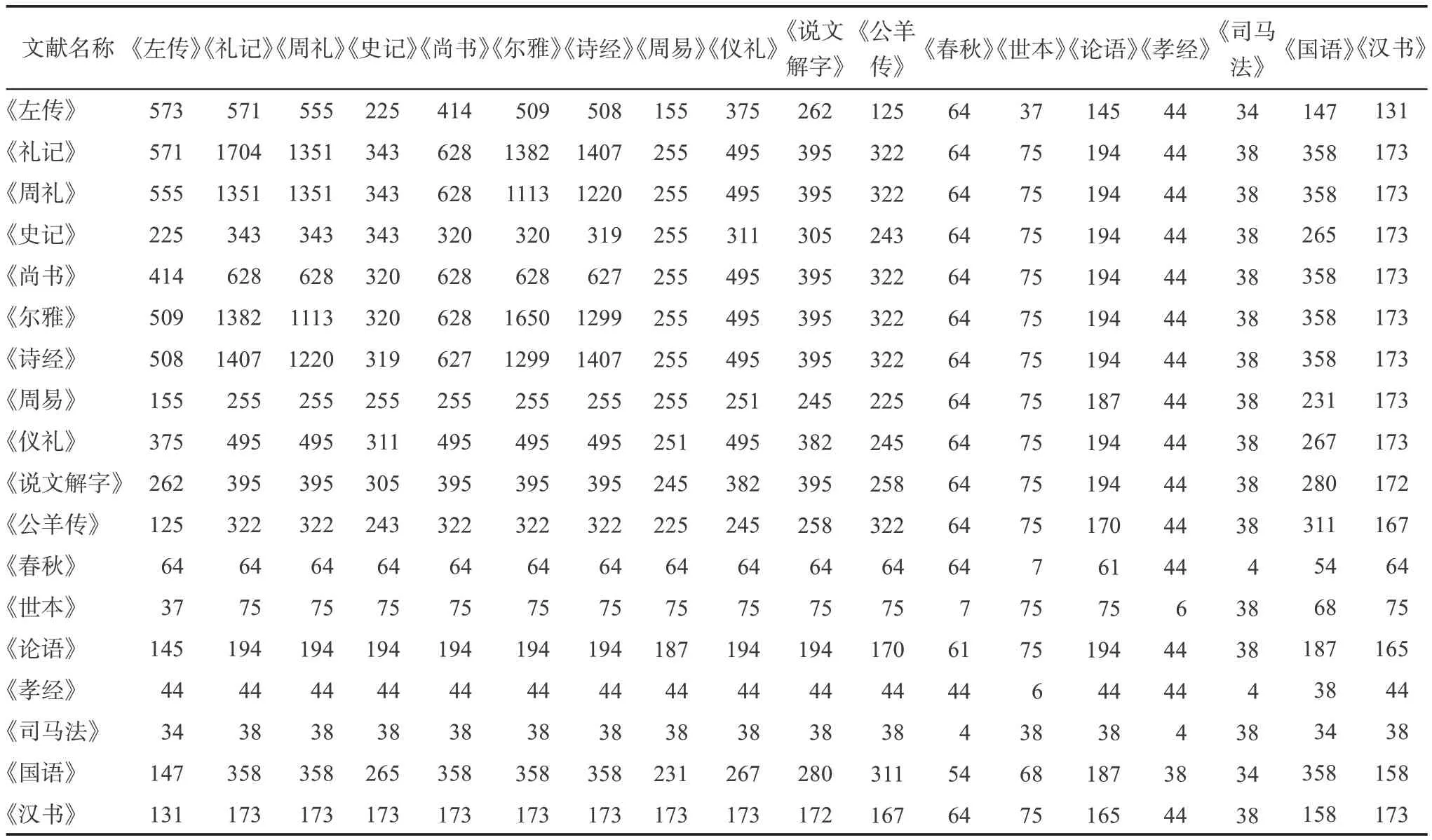
表8 引書同被引矩陣
在所得到的18×18 矩陣中,同被引次數的范圍為4~1407,最大同被引次數1407 由引書《禮記》與《詩經》所形成。同被引次數在1000 以上的還有:《禮記》與《爾雅》,《禮記》與《周禮》,《詩經》與《爾雅》,《周禮》與《爾雅》,《詩經》與《周禮》。從上述數據可以看出,高同被引對幾乎都是“三禮”《詩經》《爾雅》三者之間的組合。另外,根據同被引矩陣計算出引書的平均同被引次數如表9 所示。其中,《禮記》的平均同被引次數最大,為476.18;而《孝經》的平均同被引次數最低,為39.06。
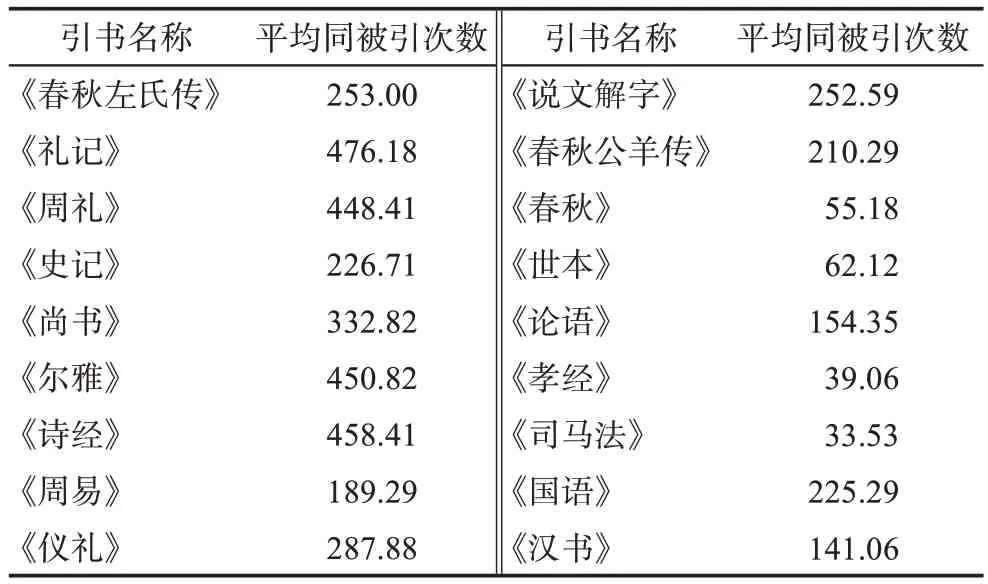
表9 引書平均同被引
從平均同被引次數的高低來看,排名前4 位的引書分別是《禮記》《詩經》《周禮》《爾雅》。綜合來看,禮制類古籍在對這三部典籍來說都具有較大的影響力。本文所選取的三部典籍均為欽定的官修經書,本意就是為統治者鞏固統治、教化天下所著,而能反映儒家禮樂文化的“三禮”,恰恰是維護封建等級制度的手段。再者,典籍的內容或多或少能反映當時的社會背景。春秋戰國時期,各國紛爭不斷,兼并戰爭四起,勢必會出現較多破壞禮法的事件。而“《禮》以節人”,孔子也要求統治者“克己復禮”。由此可見,三部典籍引用較多的“三禮”來做補充解釋也不無道理。又有言說“禮”是詩教的根本,《詩經》在相當程度上也能體現周代的禮樂文化。先秦諸子在說理論證時,也多引用《詩經》中的句子以增強說服力。而小學類引書的作用是解釋經傳的字義,研習經典,在于理解其中的奧義,而以解釋字詞為主的小學類書籍無疑是理解經典意義的“橋梁”。
4.4.2 同被引引書的聚類
利用SPSS Statistics 軟件中聚類分析的分層聚類法,將上述引書同被引矩陣導入SPSS 中,聚類方法選擇組間連接,度量標準選擇Pearson 相關性,標準化選擇Z得分,由此得到聚類譜系圖,如圖4所示。18 種引書被分成了3 大類、6 小類。
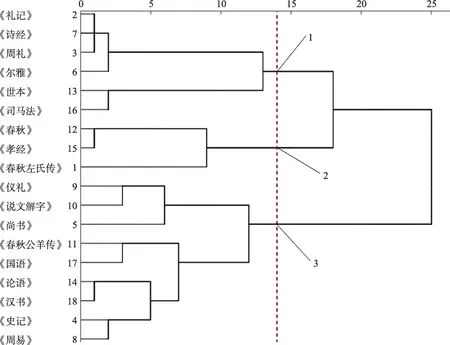
圖4 引書聚類譜系圖
區別于一般性的古籍分類目錄,圖4 的各類目融入了典籍影響力因素。圖4 從上至下6 小類引書的平均同被引分別為458、48、47、253、290、190。由于樣本量過小,帶來了圖4 中個別類目的區分度較小的問題,但總體上圖4 的各類目之間的界限還是比較清晰的。
通過計算譜系圖4 小類中各類典籍的平均同被引次數,按數值高低排序得到圖5。從圖5 中可得知,從左至右,六類典籍的影響力逐漸減弱。可以看出,排在前面的典籍為“三禮”、《詩經》和小學類典籍《爾雅》《說文解字》,此三類典籍的重要性已在前文講述過,在此不再贅述。之后為《尚書》《左傳》《公羊傳》《國語》《漢書》《史記》等,它們的共同之處在于同為史書,都是歷史事件的匯編,保存著重要的史料。排在最后的《春秋》和《孝經》也是存在共性的,其中,《春秋》雖為第一部編年體史書,但記事語言極為簡練,一字褒貶、數字成言,其后出現的“春秋三傳”都是對其進行補充和解釋的書籍。《孝經》為古代論述孝道的著作,南宋以后才被列為十三經之一。而其本身僅二卷十八章,是十三經中篇幅最短的一部。兩者篇幅都較短,且內容上與別的典籍具有重復性,在歷史上的影響力也可作等量齊觀。由此可見,與傳統分類目錄相比,融入影響力的分類方法可以方便地識別出影響力類似的典籍,當研究具體問題時更有針對性。
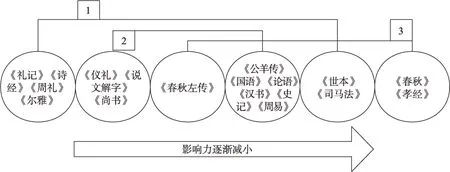
圖5 引書影響力大小
5 古人引用行為探析
包括引書在內的引文,是引用行為的外化形式,受到施引者的引用動機、引用偏好等影響。而引用行為則是學者在學術行為中借鑒他人的研究成果以表達自己思想的行為,是信息交流行為的一種[26]。信息交流行為又隸屬于信息行為。引用行為功能多種多樣,形式也復雜多變。但是,作為信息行為的一種,引用行為存在共性,比如遵循價值決定規律、穆爾斯定律等。以下將通過所得到的多維度引書計量指標,從成書目的和成書背景兩個角度,具體探討學者特征、組織環境等對引用行為的影響。
5.1 成書目的
《論語注疏》《春秋左傳正義》《毛詩正義》三部典籍皆與科舉制度有著千絲萬縷的聯系。自隋代有科舉之事起,科舉考試既是統治者選拔人才的有效途徑,也是統治者實現其政治目的的有力手段。自漢代以來,在經學領域存在諸多流派,發展到唐朝初期,儒學仍然存在南北殊途、各類注釋書籍紛紜甚至混亂的局面,朝廷為了統一政權的需要,勢必要先統一思想。因此,朝廷急需一個統一的人才選舉規范,便組織人員給科舉考試編寫教科書之舉。唐朝的科舉,分設進士科和明經科,其中,明經科的主要考察《五經》的經義。《五經》包括《周易》《尚書》《詩經》《禮記》和《春秋左傳》,是儒學思想的重要載體。因此,孔穎達等奉詔主持編撰了《五經正義》,本文所選取的《毛詩正義》《春秋左傳正義》正屬于其范疇。唐朝滅亡以后,在歷經了五代十國的分裂而建立起來的北宋王朝深知文化教育對于國家長治久安的重要性,于是統治者確立了“尊孔崇儒”的基本國策。作為儒家思想最原始載體的《論語》,地位空前提升,再次引起了極大的重視。于是,邢昺等奉宋真宗之詔,修改舊疏,成新疏《論語注疏》。
為了能更詳細地解讀經典以更好的為科舉考試提供參考資料,注疏者們俯察歷史,廣泛取材,吸收經史子集各個門類的著作。從表5 可看到,注疏者們征引了大量的文獻;而從表6 來看,征引的文獻大部分為經部著作。這些數據可以證明,唐宋學術熔鑄百家,且《毛詩正義》《春秋左傳正義》《論語注疏》具有絕對的經學屬性。這也和三部典籍的本質分不開。作為官修書的經學,這些典籍屬于官方意識形態,其目的是維護統治階級的思想意識,編纂的初衷不是追求“新”思想,而是為政治服務。Garfield[27]曾列出15 種典型的引用動機,此處的引書明顯符合其中的2 種:提供背景資料;標識某想法的原始文獻。此外,“依經立義”是古代慣例[28],金克木先生曾說,“按照古代慣例,無論什么新思想都得依傍并引證古圣先賢,最好是利用古書作注”[29]。中國文化以儒學為主,而儒學的代表為經學著作,因此,古人有著引經據典的寫作習慣。在大多數情況下,把經典著作搬出來引用,能使自己的主張更具說服力,增強權威性。在這個意義上,古人的引用動機更符合社會構建論的主張。
5.2 成書背景
與對任何事物的研究一樣,對古籍的注釋也受到社會環境和研究者主觀因素的制約。一定的學術文化總是依托于特定的社會政治背景之中。在封建社會,儒學一直都是社會的正統思想。自漢武帝提出“罷黜百家,獨尊儒術”,儒家的正統地位已基本確立,同時期國家實力也有了顯著提升。東漢末年至魏晉南北朝時期,儒學受到挑戰,地位不保,相繼了出現了多起滅國現象。后來的統治者從中吸取了經驗教訓,自唐朝開始,統治者極力提升儒學在國家各個層面的地位,以求興邦安國。本文所研究的三本古籍,均為王朝建朝初期為解決儒學內部“章句繁雜”所著,編撰的并非一家之言,而是幾個時代的注家共同的成果。《毛詩正義》在編撰過程中,以成書于漢代的《毛傳》和《鄭箋》為基礎,或在其注解的基礎上加以闡明,或對兩者的不同進行辨正,或提出一些新的看法。《春秋左傳正義》以杜預《左傳注》為底本,在綜合劉炫等義疏的基礎上,搜集大量《公羊傳》《谷梁傳》、“三禮”以及《爾雅》等資料,對《春秋左傳》進行了翔實的注解。《論語注疏》的成書主要經歷了如下幾個階段:①何宴融合了東漢和魏晉南北朝時期的注釋,形成了《論語集解》;②皇侃對《論語集解》進行疏解,加工整理成《論語義疏》,極具玄學色彩;③北宋邢昺等奉詔重新為《論語》作疏,刪除《論語義疏》中的涉玄之語,增加對《論語》內容的解釋,形成《論語注疏》。
除了成書的社會環境類似以外,為首的兩位注疏人也在不同時期分別經歷過政權由分散走向統一。孔穎達,公元574 年生于北朝,貞觀年間奉唐太宗詔完成《毛詩正義》和《春秋左傳正義》疏解。同樣由亂世入統一王朝的邢昺出生于公元932年的后唐。宋真宗咸平二年(公元999 年),68 歲的邢昺奉詔改舊疏,并于公元1001 年編成。兩人不僅在人生經歷上有共同點,思想上更是一脈相承。邢昺的《論語注疏》秉承孔穎達《五經正義》的注疏原則,注釋翔實。從上述引書的分布特征來看,三部典籍的引書都是經部文獻居多,平均占到了總引用文獻的81%以上。上述學者均為儒家學者、經學大師,其自身的學術主張本就為儒學,在知識結構方面經部文獻是其本源,多引經部文獻符合所謂的行為習慣。由于施引者的學術背景,再加上儒學在中國封建社會中正統地位,經部文獻無論是從施引者對其的熟悉度,還是保存的完整性和傳播的廣泛性來看,都比其他類型的文獻更具有易獲取性,正是“省力法則”的體現,也符合所謂的穆爾斯定律。而實際引用結果也證明了這一點。
6 結 語
本文將古籍文本中的引書看作被引文獻,在解決引書條目自動識別問題的基礎上,利用引文分析法研究引書分布規律,進而探討了古籍文本之間的關聯和影響力,并從不同的角度探析了古人引用行為,構建了古籍文本引書計量學研究的初步框架,為引書的研究提供了新視角。
本文在三個方面存在局限。首先,在數據處理上,對訓練集的人工標引可能存在誤差,特別是未對隱引進行標注;其次,在引文指標方面,僅關注了量化指標,沒有對引用做深入的文本內容分析;最后,本文的研究對象僅為《十三經注疏》中的三部典籍的引書,得出的結論具有一定的片面性。
在未來的研究中,可擴大研究對象,增加樣本典籍的數量,使數據更充實,以期得出更具普遍性的研究結論。同時,在研究內容方面可以考慮對引用內容進行挖掘,更加深入地研究古籍文本中的引用行為,為引書研究提供更有價值的視角。另外,也可以考慮在數據樣本覆蓋面足夠大以后,構建一個全面的古籍文本引文數據庫,相當于構建中華古籍的SCI。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
