基于粒子群優化和長短期記憶神經網絡的氣井生產動態預測
2022-01-04 03:18:22薛亮顧少華王嘉寶劉月田涂彬
石油鉆采工藝 2021年4期
薛亮 顧少華 王嘉寶 劉月田 涂彬
1. 中國石油大學 ( 北京 ) 石油工程學院;2. 中國石油化工股份有限公司石油勘探開發研究院
0 引言
氣井生產動態分析是油藏工程研究的主要內容之一,是氣井產量規劃、開發方案編制及生產制度動態調整的重要依據,對于認識油藏、改造油藏,科學開發氣藏具有重要的指導意義。目前主要有3種產能評價方法:第1種是基于統計分析的典型曲線方法[1],例如 Arps 產量遞減分析方法,該類方法一般通過統計分析油氣井生產數據得到,簡單明了,但一般都建立在一定的假設條件上,適用條件苛刻,且不能考慮到開發后期生產情況的變化,具有一定局限性[2];第2種是基于流體滲流原理的數值解析方法,這種方法將實際油藏轉化為物理模型,再轉化為數學模型并對模型進行求解,數值解析方法一般適用于模型較為簡單的油氣藏;第3種是數值模擬方法,數值模擬方法依靠計算機的運算能力來模擬油氣藏的實際生產情況和流體滲流規律,這需要地層資料、巖石流體資料、生產動態資料等來建立地質模型、數值模型并進行歷史匹配等工作。如果想要得到一個符合實際生產情況的數值模擬結果,就需要建立一個精確的數值模型,但精確的數值模型往往是十分復雜的,建立模型耗費時間長,工作量大。
目前實際工程應用中最常使用的是油藏數值模擬方法和典型曲線方法[3-4],但復雜的氣水井產量變化以及現場生產措施的調整,使得目前的常規方法難以精準描述產量變化。近年來,機器學習理論得到了迅速發展,出現了許多種新的機器學習算法,包括BP神經網絡、循環神經網絡、支持向量機、自回歸模型等算法,并且在搜索技術、機器翻譯、自然語言處理、圖形識別等各個技術領域取得了很大的進展,也逐漸受到了石油領域的關注。機器學習方法由于其能夠很好地處理非線性問題,通過對數據進行深度學習,捕捉生產數據與產量之間的隱藏規律,能夠克服常規生產動態分析方法的缺點,依靠現場易獲得的油氣生產動態數據實現產量的準確預測,與傳統方法相比預測結果更加可靠。
目前,許多學者通過使用BP神經網絡方法實現油氣產量的預測[5-7],此外,諸多學者也采用了支持向量機(SVM)、自回歸模型(AR)和滑動平均自回歸模型(ARIMA)等算法[8-10]來預測油氣產量,且都得到了較為準確的預測結果,說明了此類基于機器學習的產量預測方法具有可行性。但應用這些方法處理數據時,都是對某個時間點產量的計算,沒有充分考慮到各時間點產量的前后關系及變化趨勢。基于油氣產量具有時間序列的關系,且近幾年發展的長短期記憶神經網絡(LSTM)可以很好地處理時間序列數據的前后關系,提出使用長短期記憶神經網絡模型對天然氣藏產量進行預測。長短期記憶神經網絡(LSTM)是基于循環神經網絡(RNN)改進而來的[11],它具有自循環的網絡結構,將上一時間步的信息傳遞至當前時間步,并通過LSTM的輸入門、輸出門和遺忘門來控制信息的輸入輸出以及哪些不重要的信息將被遺忘,以保持神經網絡在較長時間內具有對數據的記憶功能。長短期記憶神經網絡不僅可以考慮相關因素對產量的影響,還能反映出產量數據的變化趨勢,預測精度高,更適用于油氣產量時序預測。粒子群算法具有全局尋優能力強、收斂速度快的特點,使用粒子群算法對LSTM模型超參數進行優化,既能夠提高模型預測精度,也可以避免繁瑣的、專業性強的模型調參過程,便于現場工作人員使用。
1 原理與方法
1.1 循環神經網絡(RNN)
循環神經網絡(RNN)是長短期記憶神經網絡的基礎。傳統的神經網絡只能對輸入和輸出構建直接的映射關系,而循環神經網絡在每個循環神經網絡隱藏層單元中可以將上一步計算的狀態信息加入到當前時間步的運算中,使得神經網絡可以保留先前時間步的信息,即具有記憶能力。其中循環神經網絡結構如圖1所示。圖1中,xt為t時刻的輸入數據;ht為t時刻包含隱藏層狀態信息的數據;yt為t時刻的輸出數據;W、V、U分別為各層權重參數。與傳統的人工神經網絡相比,循環神經網絡在計算過程中共享相同的權重參數,極大地減少了需要學習的網絡參數。在前向傳播過程中,t時刻隱含層的狀態信息為
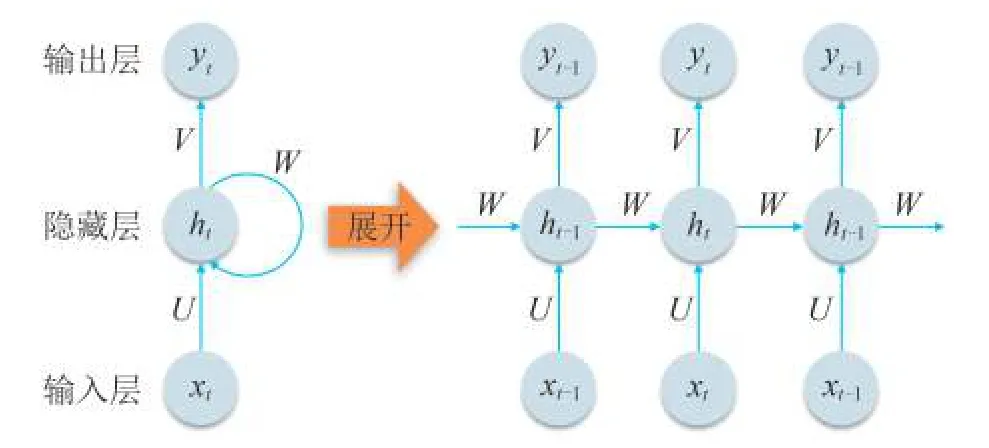
圖1 循環神經網絡結構Fig. 1 Structure of recurrent neural network
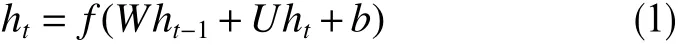

輸出層的輸出值為式中,W、V、U分別為RNN輸入層、隱藏層和輸出層的權重參數;b、c為RNN隱藏層和輸出層的偏置項;f為激活函數,一般采用tanh函數或Relu函數。
循環神經網絡的權值更新采用隨時間反向傳播(Back-propagation through time, BPTT)的方法,基于梯度下降法,沿著權值的負梯度方向不斷尋優直至收斂。在循環神經網絡中,在誤差的反向傳播計算過程中會出現早期時間步的梯度消失或者梯度爆炸現象,即循環神經網絡對較早時期的數據無法學習,導致預測誤差增大[12],使其不適用于處理長時間的序列數據。在建立氣藏產量預測模型時,輸入數據往往是數年,甚至數十年的每日生產數據,大量數據點的輸入使得循環神經網絡不適用于氣藏的產量預測問題。
1.2 長短期記憶神經網絡(LSTM)
為了解決循環神經網絡的梯度問題,有學者提出了RNN的改進結構——長短期記憶神經網絡(LSTM),它是循環神經網絡的一種變體,能夠解決RNN的梯度問題。與RNN相比,LSTM在神經網絡結構中引入了記憶單元和控制神經網絡隱藏層之間信息傳遞的控制門,其網絡結構見圖2。
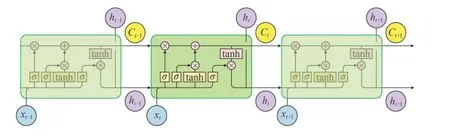
圖2 長短期記憶神經網絡結構Fig. 2 Structure of LSTM
在LSTM的神經網絡隱藏層中,加入了輸入門、輸出門和遺忘門以控制記憶單元,t時刻時,首先通過輸入門輸入數據xt和上一時間步輸出數據ht-1計算記憶單元遺忘門的值,輸出一個0~1之間的值傳遞給單元狀態信息Ct?1,確定前期單元狀態Ct?1應該丟棄哪些信息(0表示完全舍棄,1表示完全保留)
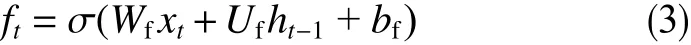
更新輸入信息it和候選單元狀態
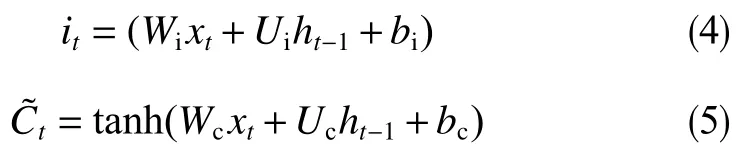
式中,ft為t時間步時的遺忘門信息;σ為sigmoid函數;it為t時間 步時 的 輸 入 信 息;Wf、Uf為LSTM遺忘門的權重參數;bf為LSTM遺忘門的偏置項;Wi、Ui為LSTM輸入門的權重參數;bi為LSTM輸入門的偏置項;Wc、Uc為LSTM單元狀態的權重參數;bc為LSTM單元狀態的偏置項;為t時間步時的候選單元狀態。
此時,根據更新得到的候選單元狀態和上一時間步的單元狀態Ct?1, 更新得到t時間步的單元狀態Ct

最后在輸出門中使用輸出門ot輸出單元狀態Ct和輸出數據ht
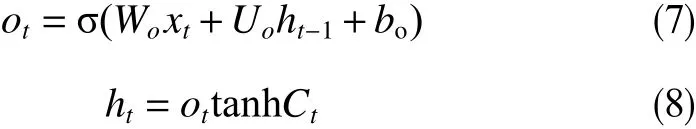
式中,Ct為t時間步時的單元狀態;Wo、Uo為LSTM輸出門的權重參數;bo為LSTM輸出門的偏置項;ot為輸出門信息; tanh為雙曲正切函數。
圖2中,σ為輸入門、輸出門和遺忘門3個門的主動函數,是變量在0~1之間的sigmoid函數。激活函數tanh是將值壓縮在?1~1之間的雙曲正切函數。利用這兩個激活函數來增強網絡的非線性

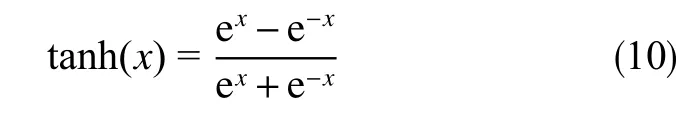
根據長短期記憶神經網絡的運算結構,采用LSTM神經網絡對時間序列數據進行學習并捕獲、提取數據特征,可以得到更加精準的預測模型。
1.3 粒子群優化算法(PSO)
構建基于長短期記憶神經網絡的產量預測模型時,模型超參數對產量預測的準確性有很大的影響,超參數影響著產量預測模型準確性和模型訓練時的收斂速度,需要避免模型訓練時陷入局部最優解。粒子群優化算法具有良好的自我學習能力,對最優參數的全局搜索能力很強,因此在建立預測模型時,使用粒子群算法對長短期記憶神經網絡算法模型的超參數進行優選。
粒子群算法是由Kennedy和Eberhart提出的啟發式優化算法,該算法通過模仿鳥群的覓食過程尋找最優解。在粒子群優化過程中,通過個體極值和群體極值更新粒子本身的位置和速度,粒子位置記為,個體極值即為單個粒子在自身移動軌跡中誤差最小時所處位置,記為,群體極值即為所有粒子在移動軌跡中誤差最小時某一個粒子的所處位置,記為g*。迭代更新粒子自身的更新速度和更新位置
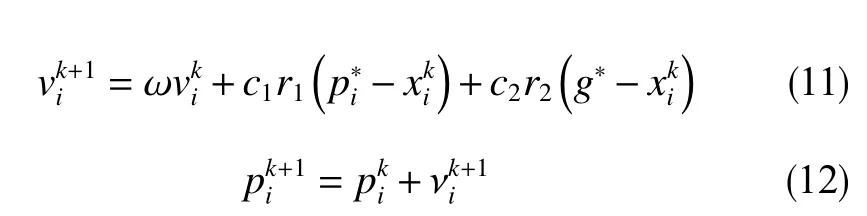
通過迭代更新粒子位置,直到達到最小誤差標準或達到粒子更新的最大迭代次數為止。
2 建立生產動態分析模型
在氣藏開采中,隨著地層壓力的不斷下降,氣藏物性和驅動能量逐漸發生變化,從而使得氣井開發方式也隨之改變,因此,根據氣井生產階段分別設計氣井穩產期生產動態預測模型和氣井遞減期生產動態預測模型,采用python進行代碼編寫。根據氣井油壓自動識別氣井生產階段,并應用相應的生產動態預測模型。
根據國內氣井實際生產情況,氣井在穩產期時一般采用配產降壓方式進行開發,因此選擇天然氣累計產量的時間序列數據為LSTM神經網絡的輸入數據,預測未來井底壓力隨天然氣累計產量的變化規律;氣井在遞減期時一般采取定壓降產方式進行開發,氣井日產量的主控因素是自身的遞減趨勢,因此以氣井日產量的時間序列數據預測未來氣井日產量數據。
2.1 數據預處理
氣井生產過程中往往會由于各種因素而使得氣井的產量、壓力等動態參數數值產生震蕩波動,所以需要對原始數據進行處理以去除數據的噪音影響。
首先采用Savitzky-Golay濾波器對數據進行處理,Savitzky-Golay濾波器(通常簡稱為S-G濾波器)最初由Savitzky和Golay于1964年提出,之后被廣泛運用于數據流平滑除噪,是一種在時域內基于多項式最小二乘法擬合的濾波方法。這種濾波器的最大特點在于濾除噪聲的同時可以確保信號的形狀、寬度不變。
S-G濾波器基本公式為
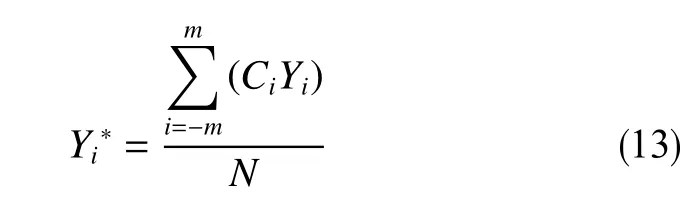
式中,Yi、分別為原始數據、平滑后數值;Ci為SG多項式擬合系數;N為濾波器長度,取值2m+1。
將需要預測的目標參數和其他相關參數的生產歷史數據進行歸一化處理。歸一化是一種無量綱處理手段,使物理系統數值的絕對值變成某種相對值關系。歸一化是簡化計算、縮小量值的有效辦法,其實質是一種線性變換。線性變換有很多良好的性質,這些性質決定了對數據轉換后不會造成“失效”,反而能提高數據在模型中的預測效果。
歸一化的作用有以下幾點:(1)把數據映射到0~1范圍之內處理,可以使數據處理更加便捷快速;(2)把有量綱表達式變成無量綱表達式,便于不同單位或量級的指標能夠進行比較和加權計算;(3)避免太大的數在計算中引發數值問題。
歸一化的計算公式如下

式中,xnew為歸一化后的數值;xold為原始數值;xmin為數據最小值;xmax為數據最大值。
將歸一化的生產數據轉化為序列數據,也就是將生產數據轉化為多個短時間序列的歷史生產數據和對應的已知目標值,每一個短時間序列數據即一個樣本,每個樣本內包含的時間步的數量即時間窗口的長度,最后轉換為三維矩陣(樣本數×時間窗口×特征數量)作為長短期記憶深度神經網絡模型的輸入參數,并利用長短期記憶深度神經網絡算法計算得到需要預測的生產動態數據。
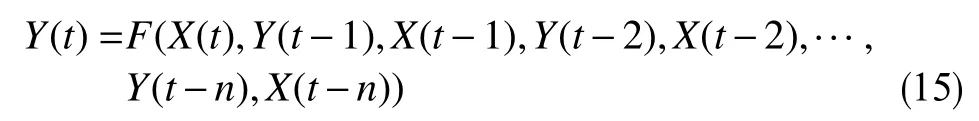
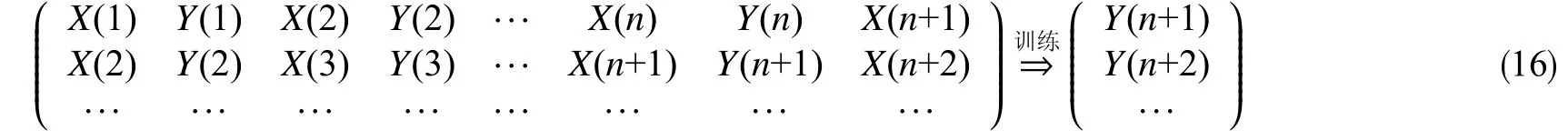
式中,Y(t)為第t個時間步需要預測的生產動態數據;X(t)為第t個時間步的生產控制參數;n為時間窗口長度,即每個樣本包含的時間步數量。
2.2 長短期記憶神經網絡模型的訓練和優化
將預處理好的數據分為兩部分,前70%的數據用作訓練集,對模型進行訓練;之后10%的數據用作測試集,在測試集上對模型進行測試,驗證模型的效果并根據測試結果優化模型;最后20%的數據作為模型預測集。在完成模型訓練后,根據模型訓練集上的擬合效果和模型在測試集上的預測誤差,使用粒子群算法優化時間窗口長度和長短期記憶網絡層的神經元數量,最后將訓練并優化好的模型應用在預測集,對未來生產動態進行預測。
設置粒子群算法的適應度函數為預測值與實際值的均方根誤差,將搜索維度設置為4,4個維度分別為時間窗口長度、第1層長短期記憶網絡層的神經元數量、第2層長短期記憶網絡層的神經元數量和長短期記憶神經網絡模型的迭代次數,根據粒子群計算公式不斷迭代尋優,可以使該點所對應的損失函數不斷變小,在粒子群的搜索空間內損失函數達到最小值,這樣便同時得到了最優長短期記憶深度學習模型超參數,其所對應的LSTM神經網絡,即為訓練得到的最優生產動態分析模型。
2.3 長短期記憶神經網絡模型的循環預測
生產動態分析模型是利用歷史生產動態來預測未來某個或某段時期的氣層壓力或日產油數據。預測時由于t時間步后面的日產油量未知,因此,后面每預測一個時間步,需要將該時間步的預測值Y(t)更新加入到下一個時間步的預測模型輸入數據,使用預測值Y(t)去預測下一時刻的值Y(t+1),實現對后續產量的預測。
2.4 模型評估標準
為了驗證模型的可靠性,使用平均絕對百分比誤差e1、 平均絕對誤差e2和 均方根誤差e3評價模型。平均絕對百分比誤差以百分比的方式表示誤差,平均絕對誤差則給出預測值與實際值的平均差值,均方根誤差表示誤差結果的穩定性,均方根誤差越小表示模型性能越好,其計算方法如下。
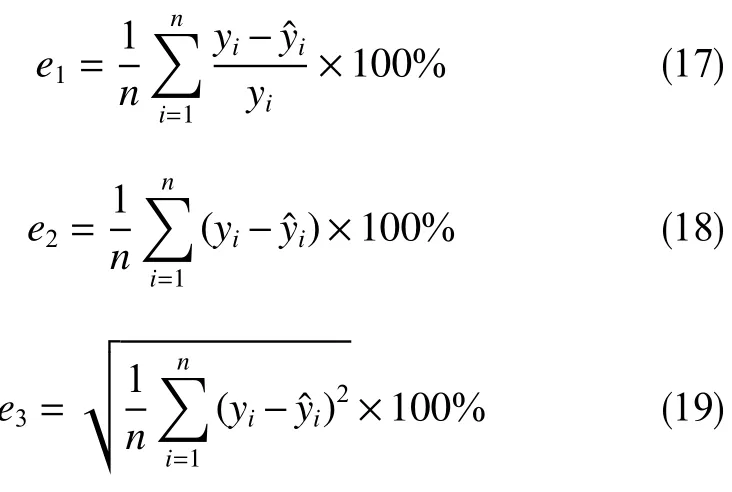
式 中,yi,y?i分別為第i個實際值和預測值。
3 應用實例
3.1 1號井生產動態分析
1號井目前油壓12 MPa,處于穩產期,氣井采用配產降壓的方式開發,因此采用穩產期產量預測模型,通過預測未來井底壓力隨天然氣累計產量的變化規律來指導未來生產措施調整。采用2010年3月24日—2020年3月31日未關井有效數據輸入模型,其中2018年2月10日—5月30日數據作為訓練集和測試集,2018年5月31日—2020年3月31日數據作為預測集進行未來生產動態預測。
采用未經粒子群優化時的模型預測效果和經過粒子群優化時的模型預測效果如圖3所示,虛線左側為訓練段和測試段,虛線右側為預測段。
從圖3(a)中可看出,采用未經粒子群優化時的模型在預測段擬合效果不佳,預測值普遍低于實際值,模型在預測段的預測誤差隨著累計產量的增加慢慢擴大,預測效果較差。模型超參數未經粒子群優化時,超參數主要依靠經驗選擇,而依靠經驗選擇的超參數很難直接適用于模型,往往需要繁瑣的調參過程。經過粒子群優化后,選擇時間窗口大小為10個時間步,第1層LSTM神經網絡神經元數量為11,第2層LSTM神經網絡神經元數量為10,LSTM模型迭代次數為83。從圖3(b)中可看出經過粒子群優化的模型預測效果良好。
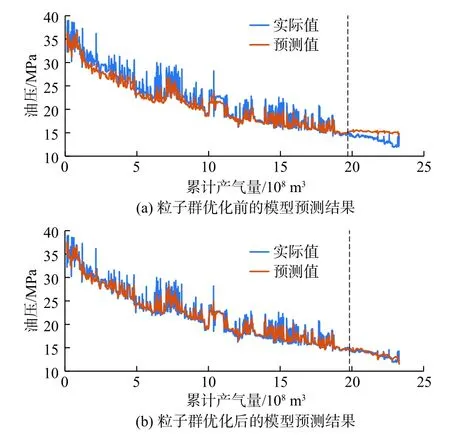
圖3 粒子群優化前后的1號井模型預測結果對比Fig. 3 Comparison of prediction result of No.1 well model before and after particle swarm optimization
對模型在預測集上的預測結果進行了進一步分析。圖4為2種預測模型預測值偏離實際值的分布情況,可以看出,經過粒子群優化后的模型預測值更加接近斜率為1的直線,說明預測值更加接近實際值,而未經過粒子群優化后的模型預測值更加偏離實際值,預測效果較差。
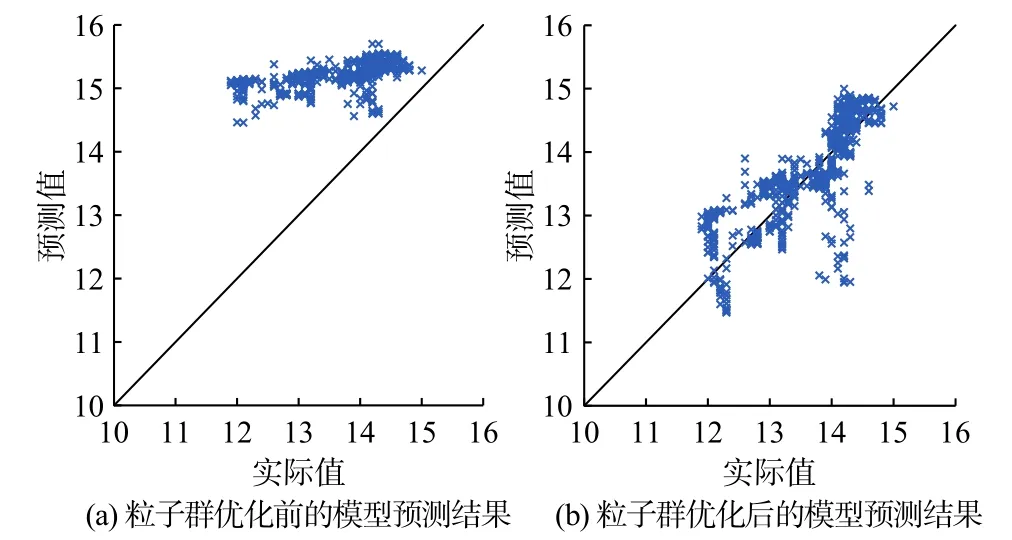
圖4 模型預測值和實際值的偏離情況Fig. 4 Deviation of model prediction from actual value
可以觀察到計算模型在預測集上的預測結果與實際值的均方根誤差、平均絕對誤差和平均絕對百分比誤差在粒子群優化后都發生下降,均方根誤差從1.72256降至0.52508,平均絕對誤差從1.56841降至0.38646,平均絕對百分比誤差從11.857%降至2.911%。研究認為,經過粒子群優化的LSTM模型預測效果更好,且能很好地預測未來生產動態。
3.2 2號井生產動態分析
2號井目前油壓8.3 MPa,處于遞減期,氣井采用定壓降產的方式開發,因此采用遞減期產量預測模型,預測未來日產氣量隨生產時間的變化規律,以指導未來生產措施調整。采用2017年8月31日—2019年5月12日中的未關井的有效數據作為輸入數據,其中2017年8月31日—2018年10月18日的數據作為訓練集和測試集,訓練并優化模型,2018年10月19日—2019年5月12日的數據作為預測集對氣井未來生產動態進行預測。
采用未經粒子群優化的模型預測效果和經過粒子群優化的模型預測效果如圖5所示,虛線左側為訓練段和測試段,虛線右側為預測段。
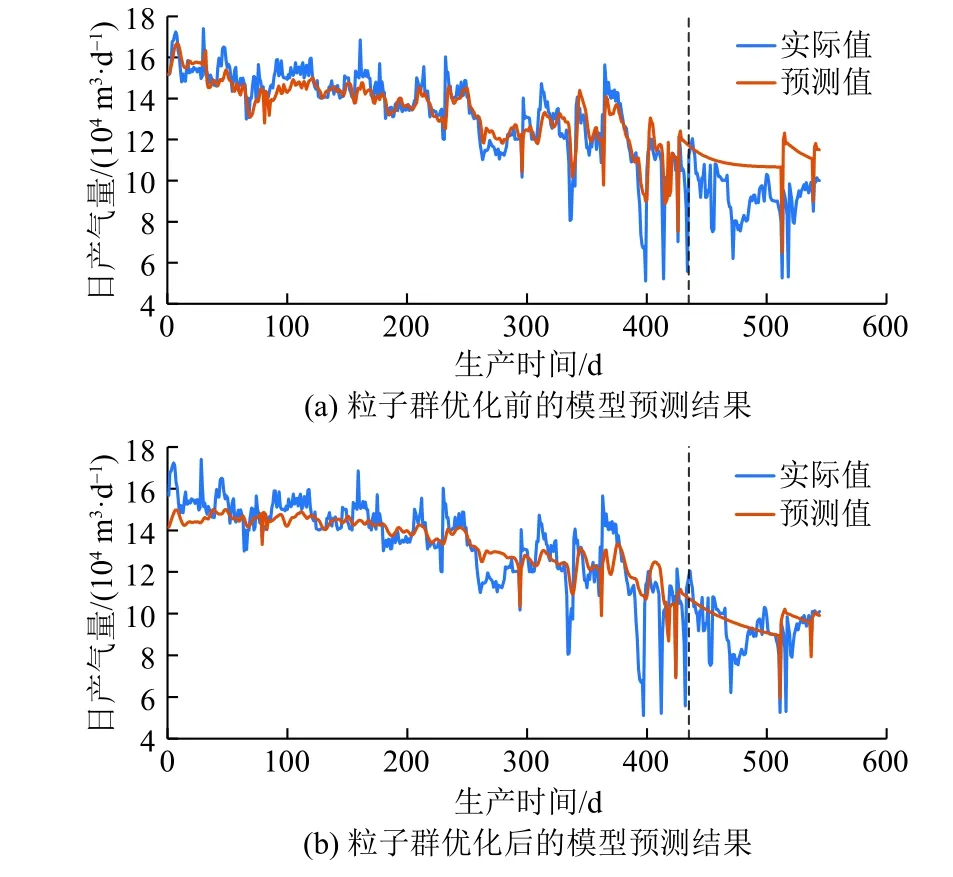
圖5 粒子群優化前后的2號井模型預測結果對比Fig. 5 Comparison of prediction result of No.2 well model before and after particle swarm optimization
從圖5可以看出,應用未經粒子群優化時的模型在訓練集擬合效果較好,但在預測段預測效果較差,說明模型的泛化能力較弱,而采用經過粒子群優化的模型預測值更貼合實際值。經過粒子群優化后,優化的時間窗大小為4個時間步,第1層LSTM神經網絡神經元數量為6,第2層LSTM神經網絡神經元數量為3,LSTM模型迭代次數為272次。可以發現優化的參數值除迭代次數外都相對較小,且從圖5中可以看到模型的預測值在訓練集和測試集上的極值點表現較差,分析數據后得出結論,由于2號井已進入見水期,氣井見水后產量波動較大,使模型很難預測到精確的產氣量,而粒子群優化后選擇的較小的超參數,降低了模型的復雜程度,可以使預測模型具有更好的泛化能力,從而使預測效果在整體上表現更加良好。
計算在預測集上實際值與預測值的均方根誤差、平均絕對誤差和平均絕對百分比誤差后發現,由于2號井見水后產量波動較大,數據的不穩定程度大幅度增加,導致誤差增大,但在粒子群優化后,均方根誤差從2.12160降至1.14898,平均絕對誤差從1.76625降至0.77692,平均絕對百分比誤差從21.153%降至9.425%。分析兩種條件下在預測段的誤差大小,可以明顯觀察到經過粒子群優化后的LSTM模型預測效果更好,且能夠很好地預測未來生產動態。
4 結論
(1)將機器學習中的長短期記憶神經網絡應用到生產動態分析中,并采用粒子群算法優化神經網絡,實現了對氣井生產動態的準確預測。
(2)使用粒子群優化算法對建立的長短期記憶神經網絡模型進行優化,實現了神經網絡超參數的自動優化,避免了常規神經網絡繁瑣的調參過程,大幅度簡化了預測模型的優化過程,操作簡單,便于實現自動化和現場人員使用。
(3)實例應用說明,建立的產量預測模型可以精準地預測未來生產動態變化,平均絕對百分比誤差小于10%,預測精度符合現場要求。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
礦山安全信息(2022年40期)2022-04-07 02:16:52
當代水產(2021年10期)2021-12-05 16:31:48
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
今日農業(2020年20期)2020-11-26 06:09:10
聚氯乙烯(2018年9期)2018-02-18 01:11:34
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
