
基于改進的傾向得分估計的無偏推薦模型
2022-01-05 02:31:32駱錦濰劉杜鋼潘微科
計算機應用 2021年12期
駱錦濰,劉杜鋼,潘微科*,明 仲
(1.大數據系統計算技術國家工程實驗室(深圳大學),廣東深圳 518060;2.人工智能與數字經濟廣東省實驗室(深圳)(深圳大學),廣東深圳 518060;3.深圳大學計算機與軟件學院,廣東深圳 518060)
(?通信作者電子郵箱panweike@szu.edu.cn)
0 引言
推薦系統作為大數據時代的產物,旨在為用戶推薦其感興趣或喜歡的物品。推薦系統所使用的數據通常來自用戶與物品的歷史交互行為,包括顯式反饋和隱式反饋兩種形式。顯式反饋通常是指能夠充分展示用戶對物品偏好程度的反饋(如評分);而隱式反饋則通常指點擊、瀏覽等不能充分表示用戶偏好的反饋[1]。相比收集過程困難的顯式反饋,隱式反饋廣泛存在于用戶與系統的行為日志中,收集成本低廉,因此基于隱式反饋的推薦算法研究更符合現實場景[2]。
另一方面,推薦系統遭受著各種偏置問題,例如曝光偏置(exposure bias)、位置偏置(position bias)和選擇偏置(selection bias)等[3]。其中,曝光偏置是指推薦系統會給予不同的物品不同的曝光概率從而導致數據的采集存在偏置。例如:某不滿足用戶偏好的物品由于得到系統高頻的曝光而被用戶點擊,進而導致系統增加推薦該物品的次數。如果不對數據偏置進行處理,推薦系統難以捕捉用戶的真實偏好,有損推薦的多樣性和公平性。相比傳統推薦模型,無偏推薦模型的關注點在于如何從有偏的歷史交互記錄中挖掘用戶無偏的真實偏好信息,因此近年來受到學術界和工業界愈來愈多的關注[4-5]。
其中,基于傾向得分估計(propensity socre estimation)的無偏推薦模型能夠有效緩解曝光偏置,但這類模型的糾偏程度和性能依賴于傾向得分估計的準確度[6]。目前關于顯式反饋數據的傾向得分估計的研究已比較充分,而對于推薦系統中更常用的隱式反饋數據傾向得分估計的研究還非常少,這將限制基于傾向得分估計的推薦模型的糾偏能力和推薦性能。對于推薦系統中隱式反饋數據中的曝光偏置,先前的方法只通過從稀疏數據中獲取物品的流行度信息來估計傾向得分,這導致傾向得分估計不夠精確,進而會對模型的性能和無偏性質帶來損害。為了克服現有方法在傾向得分估計上的不足,本文同時挖掘隱式反饋數據中用戶層面和物品層面的信息,并通過用戶流行度偏好和物品流行度配對的思想將兩者融合起來,最終得到配對傾向得分估計(Match Propensity Estimator,MPE)方法。
本文的主要工作包括:
1)提出一種同時利用物品層面與用戶層面信息的MPE方法。該方法在無輔助數據集的情況下,以用戶的流行度偏好作為切入點,融合用戶層面和物品層面的信息,實現了對傾向得分更精確的估計。
2)將所提出的MPE 方法與傳統推薦模型和前沿無偏推薦模型進行結合,并在無偏推薦領域的公開數據集上開展了一系列實驗。實驗結果表明MPE 方法能夠有效緩解隱式反饋數據中的曝光偏置,進而讓模型在各項推薦指標上優于相關工作。
3)得益于MPE 對曝光偏置問題的解決,可以使模型從有偏數據中更好地捕捉用戶無偏的真實偏好,進而提升模型在長尾物品上的推薦性能。
1 相關工作
1.1 傳統推薦模型
在推薦系統算法的研究中,基于協同過濾的算法被廣泛接受和應用[7]。協同過濾的思想是通過尋找和利用不同用戶之間或(和)不同物品之間的相似性來協同地預測用戶對物品的喜好程度。在協同過濾的研究中,因為其簡單且高效的特點,潛在因素模型(latent factor model)一直是推薦系統算法研究的熱點[8]。潛在特征模型通過訓練學習用戶和物品的潛在特征向量,并利用這些潛在特征向量來計算用戶偏好,進而實現推薦。
基于隱式反饋的推薦算法面臨著兩大難題,即正未標記問題(positive-unlabeled problem)和非隨機缺失(Missing-Not-At-Random,MNAR)問題。正未標記問題是指推薦系統所收集的隱式反饋只包括正反饋(如點擊、收藏、購買),而未觀測樣本可能包含負反饋和潛在的正反饋[9]。這意味著一個物品沒有得到點擊可能是由于用戶不喜歡,也可能是因為用戶沒有觀測到該物品而無法點擊。非隨機缺失問題則是由于數據偏置所導致的[10-11],例如,推薦系統通常會傾向于推薦熱門的物品,這會導致在長尾物品上的數據缺失程度比熱門物品上的嚴重得多。如果推薦模型不對數據偏置進行處理,將使得原本的流行物品獲得更多的曝光機會,而長尾物品則難以被用戶所觀測到,即馬太效應。
隱式反饋通常對應于top-K排序問題,而成對偏好假設更為接近排序問題的設定,因此有學者提出了基于成對損失函數的貝葉斯個性化排序(Bayesian Personalized Ranking,BPR)模型[12],其核心思想為:相比未點擊的物品,用戶可能更喜歡點擊的物品,模型通過極大似然估計來最大化正負樣本(即點擊與未點擊樣本)之間的差異。BPR 模型在排序任務上能取得較好的效果,且先前的工作通常都將其作為一個重要的基線模型。
作為另外一個重要的分支,權重矩陣分解(Weighted Matrix Factorization,WMF)[13]基于一個啟發式的想法:在隱式反饋的設定下,由于正未標記問題的存在,無法將未觀測樣本完全置信地作為負樣本。因此,相比未觀測樣本,應給予正樣本更高的權重。在后續的工作中,有學者認為WMF對未觀測樣本賦予一樣的權重是不合理的,并首次提出了基于物品流行度來為未觀測樣本進行加權的快速矩陣分解(Fast Matrix Factorization,FMF)方法[14]。FMF 同樣基于一個啟發式的想法:用戶沒有點擊一個流行物品則表示該用戶很可能不喜歡該物品。
在傳統推薦模型的研究中,先前的工作主要基于啟發式的想法來設計新的模型,以便更好地符合隱式反饋的設定;另一方面,數據偏置的問題沒有得到充分的重視和研究。
1.2 無偏推薦模型
在現有文獻中,無偏推薦算法的研究方向主要分為以下兩種:1)利用少量無偏權威數據(gold-standard data)的方法;2)基于逆傾向得分(Inverse Propensity Score,IPS)的方法。
利用少量無偏權威數據的方法旨在利用由均勻策略收集得到的小規模的無偏數據集去幫助在大規模的有偏數據集上構建無偏的推薦算法[15]。均勻策略是指不使用部署的推薦策略進行物品的推送,而是隨機地從候選集中選擇物品,且對它們進行隨機排序以進行展示。均勻策略盡可能地屏蔽了系統層面上偏置的來源,這意味著在均勻策略下收集到的觀測數據可以被認為是一個權威的無偏數據。文獻[15]中,作者分別對有偏數據和無偏數據進行建模,并且利用一個參數對齊項來將無偏知識進行遷移。隨后,有研究人員提出了一個基于無偏數據和知識蒸餾的反事實推薦框架[16],其中無偏數據分別在四個不同的蒸餾模塊中被更充分地利用。但是這個方向的一個難處在于無偏數據的收集需要高昂的代價,尤其當其在真實產品的線上流量中部署時。
基于IPS 的方法旨在利用傾向得分來將有偏數據分布平衡為無偏數據分布,從而解決偏置問題。傾向得分(propensity score)的概念于1983 年首次提出[17]。文獻[6]中,作者首次將IPS 應用在推薦算法中,提出了矩陣分解的IPS 版本MF-IPS,同時也提出了顯式反饋設定下的傾向得分估計方法(naive Bayes 等)。文獻[18]中,字節跳動公司在搜索系統領域首次提出了基于成對損失函數的無偏置排序算法,緩解了在搜索系統領域中位置偏置的問題。由于IPS 具有簡潔、可離線計算和高效的特點,當前大部分旨在解決偏置問題的工作都遵循這個思路。
除了上述兩個方向,有研究者嘗試在評分預測問題上同時使用無偏數據和傾向得分來緩解數據偏置[19]。
文獻[20]的作者將IPS 框架首次應用到基于隱式反饋的推薦算法中,提出了相關性矩陣分解(Relevance Matrix Factorization,RMF)模型,并從理論上證明了該模型具有無偏的性質。
2 推薦模型
本章將給出符號描述與相關定義,并介紹本文所使用的傳統推薦模型FMF和前沿的無偏推薦模型RMF。
2.1 符號系統描述
假設有用戶全集U={1,2,…,n}和物品集合I={1,2,…,m};Yu,i∈{0,1}則表示用戶u對物品i的點擊反饋,包括點擊(1)和未點擊(0);D為訓練數據,其中包括觀測到的點擊樣本和隨機采樣的未觀測樣本。在本文中,推薦系統的目標是根據D中不同用戶的歷史交互記錄,挖掘用戶的真實偏好,并最終給用戶生成先前未交互過且符合用戶偏好的物品列表。
本文所涉及的模型均屬于潛在特征模型,該類模型將反饋矩陣分解或映射為潛在特征空間中的用戶特征矩陣和物品特征矩陣。通過優化預設的損失函數獲得最佳的用戶特征向量和物品特征向量后,便可以通過向量的內積來計算用戶在原有隱式反饋矩陣中的缺失值。最終按照預測值進行降序排序后,選擇前K個物品推薦給用戶。
2.2 快速矩陣分解模型
快速矩陣分解(FMF)模型[14]的損失函數為:
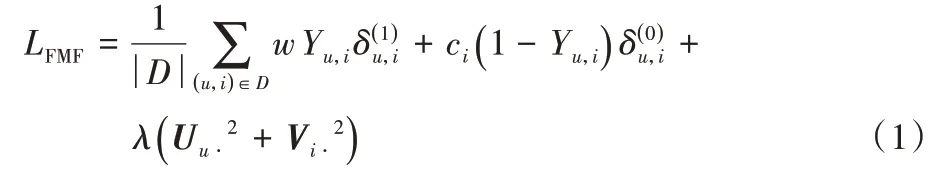
其中:w≥1 是一個超參數,表示點擊數據相比未點擊數據的置信度,在沒有先驗知識的情況下,該方法對所有點擊數據設置相同的權重;ci為物品i的流行度;Uu?和Vi?則表示用戶u和物品i的潛在特征向量;λ為正則化項上的參數,用于防止模型過擬合;分別表示一個樣本(u,i)的正損失函數(標簽為1)和負損失函數(標簽為0),其中損失函數可以是交叉熵或平方損失等。為了公平起見,在本文的所有實驗中都采用平方損失(square loss):


2.3 相關性矩陣分解模型
相關性矩陣分解(RMF)從理想損失函數出發,通過IPS框架得到RMF模型[20]的損失函數如下:
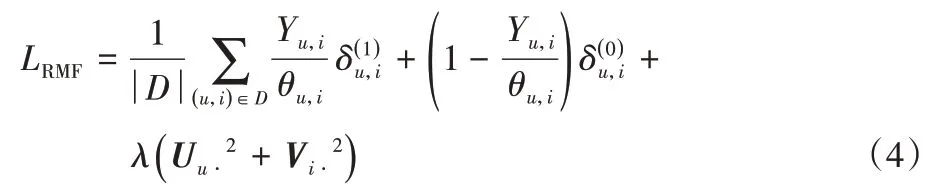
其中:θu,i為IPS 框架下的傾向得分,在RMF 模型中也可以解釋為樣本(u,i)的曝光概率。RMF 采用潛在特征模型,預測規則同式(3)。本文略去RMF 的具體推導過程,但從其損失函數可以看出在正樣本部分(點擊數據),RMF 給每個樣本(u,i)賦予一個個性化的權重,代表不同曝光概率的正樣本相關性不同,即RMF 通過逆傾向得分在一定程度上恢復由曝光偏置導致的分布漂移。在已知真實的傾向得分的理想情況下,RMF可以有效緩解曝光偏置。
3 傾向得分估計
與傳統推薦算法相比,基于IPS 的推薦模型能較好地解決數據的偏置問題,但是其性能嚴重依賴于傾向得分估計的準確性,即傾向得分的估計準確性直接影響IPS 模型的糾偏能力,只有在已知真實的傾向得分的理想情況下,IPS 模型才能被認為具有真正的無偏性質。然而在現實中,只能通過傾向得分估計方法對傾向得分進行估計,其中傾向得分估計值越準確,則IPS 模型越接近于無偏模型,從而具有更好的性能。對于推薦系統中常見的隱式反饋數據,現有工作在傾向得分估計的準確性上亟待改進。本章將首先分析現有傾向得分估計方法的缺陷,隨后,提出一個新的配對傾向得分估計(MPE)方法來克服這些缺陷,從而進一步提升基于IPS 的推薦模型的性能。
3.1 流行度傾向得分估計方法
在RMF[20]中,作者采用流行度敏感(popularity-aware)的傾向得分估計方法,即通過計算物品流行度來估計曝光率。其估計方法如下所示:其中:τ≤1 為平滑項,U為用戶全集,I為物品全集。式(5)旨在通過計算物品i的相對點擊概率來估計物品流行度,從而確定傾向得分的具體數值。

流行度傾向得分估計方法可以解釋為對于所有用戶,推薦系統都“一視同仁”地按照物品的流行度高低進行推薦。這與推薦系統旨在實現個性化推薦的目標不一致。換言之,推薦系統應該學習不同用戶的不同偏好,從而對不同的用戶采用不同的推薦策略。另一方面,只考慮物品層面的信息來估計傾向得分可能是不充分和不準確的。正如前面所述,傾向得分的估計精度會直接影響模型的糾偏能力并最終影響推薦效果,因此有必要引入更多信息來提升傾向得分估計的準確性。
傳統的推薦模型FMF 雖然沒有使用IPS 框架,但其在未觀測數據部分的加權處理在一定程度上也可以被解釋為傾向得分。為了實驗的統一,本文同樣采用式(5)來計算FMF 模型在損失函數式(1)中的ci,即物品i的流行度。
3.2 配對傾向得分估計方法
在沒有輔助數據集的情況下,估計傾向得分的難點在于如何從稀疏的隱式反饋數據中挖掘用戶層面的信息和物品層面的流行度信息,并將它們進行結合,以更好地建模歷史推薦系統的曝光率。
在流行度偏置的研究中,研究人員已經觀察到不同用戶對待“流行物品”的態度是不一樣的。文獻[21]的作者將用戶劃分為熱門導向型(blockbusters-focused)、追求多樣型(diverse)和獵奇型(niche),通過實證研究驗證了不同用戶對流行度的偏好程度是不同的。基于這個結論,本文創新性地以用戶的“流行度偏好”作為切入點來挖掘用戶層面的信息,進而提出MPE方法:
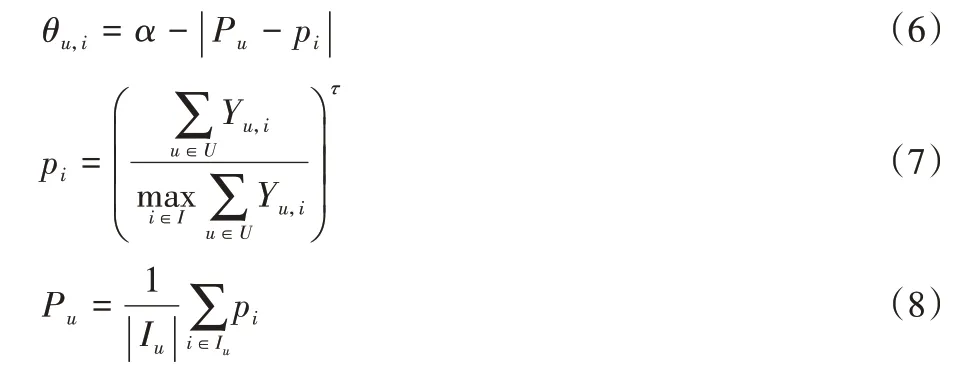
其中:pi表示物品i的流行度,由式(7)計算;Pu表示從歷史數據中估計的用戶u的“流行度偏好”,數值越高表示該用戶的流行度偏好程度越高。本文首先提取用戶u的歷史點擊物品集合Iu,然后計算所有物品流行度pi的均值,如式(8)所示;α∈(0,1]為閾值參數,代表樣本(u,i)在推薦系統中能獲得的最大曝光率。MPE方法的思想是歷史推薦系統可以捕捉到用戶個性化的“流行度偏好”,當物品i的流行度與用戶u的“流行度偏好”越匹配時,樣本(u,i)在歷史推薦系統中就會獲得越高的曝光率。注意,當兩者完全匹配(|Pu-pi|=0)時,曝光率θu,i為閾值α。
進一步可以發現,式(5)的流行度傾向得分估計方法實際上是本文MPE 方法的一個特例,即當α=1,Pu=1 時,θu,i=1-||1-pi=pi,MPE 退化為流行度傾向得分估計方法。從這個視角可以看出,流行度傾向得分實際上是將所有用戶看作極端的熱門導向型用戶,而這顯然是對用戶群體做出的一個過于簡化的假設。挖掘并結合用戶流行度偏好信息的MPE方法可以很好地解決這個問題。
為了驗證本文MPE 方法的有效性,本文分別將MPE 與原始的FMF 模型[14]和RMF 模型[20]進行結合,并將它們稱作FMF-MPE 模型和RMF-MPE 模型,其中RMF-MPE 模型的訓練算法如下:
算法1 RMF-MPE模型訓練算法。
輸入 觀測數據點擊矩陣Y∈{0,1}n×m,學習率μ,潛在特征維度d,正則化參數λ,傾向得分的最小閾值M,迭代次數T;
輸出 訓練好的模型參數:用戶潛在特征矩陣U∈Rn×d,物品潛在特征矩陣V∈Rm×d。

RMF-MPE模型的算法流程主要分為兩部分:
1)傾向得分的估計。輸入觀測數據點擊矩陣Y∈{0,1}n×m,通過MPE 估計每個(u,i)樣本的傾向得分并保存。值得注意的是,本文通過預先設置的閾值M來限制傾向得分的最小值(算法1第3)步)。先前的研究已經表明這種處理有助于減少IPS模型的方差[20]。
2)模型的損失函數的優化。在每一次迭代中,根據模型具體的損失函數求取梯度,然后通過梯度下降的方式來更新模型參數,即用戶潛在特征矩陣U∈Rn×d和物品潛在特征矩陣V∈Rm×d。
4 實驗與結果
4.1 數據集
本文采用在現有工作中最常用的Yahoo!R3數據集作為實驗數據集。需要說明的是,本文僅選用Yahoo!R3 數據集作為實驗數據集是因為它是目前僅有的一個較大的,且提供在均勻策略下收集到的測試集的公開的推薦系統數據集。Yahoo!R3 數據集是雅虎公司在音樂服務推薦中收集的顯式反饋評分數據。Yahoo!R3 數據包括15 400 位用戶和1 000首歌曲。訓練集中有超過300 000 條在正常交互場景下收集的用戶對音樂的評分記錄,其中每個用戶至少有10 條評分記錄。Yahoo!R3 數據集還提供了一個使用均勻策略收集到的測試集:系統為5 400 位用戶中的每個用戶隨機選取10 首音樂作品,并要求該用戶對這些音樂作品給予反饋。因此,Yahoo!R3 的測試集可以被認為是完全隨機缺失的(missing at complete random),即具有無偏性質。
需要說明的是,不同于傳統推薦算法的評估,無偏置推薦算法的評估需要在具有無偏性質的測試集上才能驗證推薦模型的無偏性質與真正性能[22]。因此,本文采用Yahoo!R3 數據集而不是其他常見的推薦數據集,例如MovieLens數據集。
本文采用與文獻[20]一致的數據集處理方式:將數據集里的評分記錄數據轉化為隱式反饋數據,即將評分記錄ru,i≥4 的樣本當作點擊數據(Yu,i=1),將其他樣本作為未觀測數據(Yu,i=0)。由于Yahoo!R3已劃分好訓練集和均勻策略收集的測試集,本文在訓練集中隨機選取10%的樣本作為驗證集,并在驗證集上對模型參數進行調優。最后,在權威的隨機測試集上進行效果評估。
4.2 評估指標
本文采用三種常用的排序評估指標,分別是折損累計增益(Discounted Cumulative Gain,DCG)、召回率(Recall)和平均精確率(Mean Average Precision,MAP)。將推薦列表的長度記為K,則三個評估指標可以表示為DCG@K、Recall@K和MAP@K,用于評估推薦算法在排序前K個位置的表現。令推薦算法為用戶u產生的長度為k的推薦列表為Ire@ku,實驗測試集中用戶u喜歡的物品集合為Iteu,測試集中的用戶集合為Ute。
DCG 是評估排序任務的一個綜合性指標,計算公式如式(9),其中:l表示用戶u的推薦列表中的位置,δ(i(l)∈Iteu)表示推薦列表中第l個物品是否在測試集中用戶u的喜歡物品中。DCG越大表示算法在排序推薦中的準確性越高。
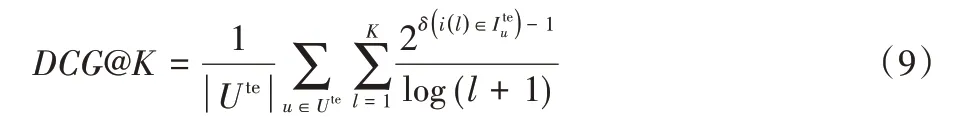
召回率計算推薦列表前K個位置包含的測試集中用戶喜歡的物品個數占測試集中用戶喜歡的物品總個數的比例,計算公式如式(10)。算法的召回率越大表示算法能夠準確地覆蓋更多的未知正樣本。
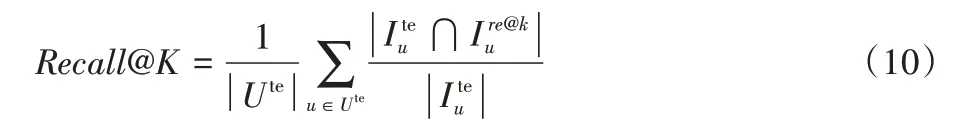
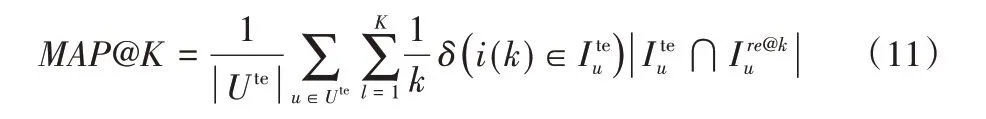
4.3 對比模型
如前所述,本文專注于解決推薦系統中隱式反饋數據的曝光偏置問題。在基于隱式反饋的傳統推薦方法中,貝葉斯個性化排序(BPR)[12]是一個有代表性的經典算法,本文將其作為一個基線模型。FMF[14]和RMF[20]是與本文方法最接近的兩個主流算法,在本文中被視為兩個重要的基線模型。其中,RMF 是前沿且具有代表性的基于隱式反饋的無偏推薦算法。因此,實驗部分包含BPR、FMF、RMF、FMF-MPE 和RMFMPE 五個推薦模型,其中FMF-MPE 和RMF-MPE 是結合本文MPE方法的模型。
4.4 參數調節
對于FMF模型和FMF-MPE模型,本文統一地設置正樣本權重為1 以確保對比的公平性。流行度傾向得分估計方法和MPE 方法中的τ值根據文獻[20]將其設置為τ=0.5,傾向得分的最小閾值統一地設置為M=0.01。MPE 方法中的α在{0.6,0.7,…,1}范圍內進行選擇。本文所有模型算法的潛在特征的特征維度d在{20,30,…,200}范圍內進行選擇,正則化參數λ在{0.000 01,0.000 1,…,0.01}范圍內選擇,迭代次數T統一設置為300。五個模型的最佳參數如下所示:
BPR:d=30,λ=0.000 1。
FMF:w=1,d=200。
FMF-MPE:w=1,d=200,λ=0.000 01,α=0.8。
RMF:d=200,λ=0.000 01。
RMF-MPE:d=200,λ=0.000 01,α=0.8。
4.5 實驗結果及分析
實驗一:物品全集上的實驗。
上述五個模型算法在Yahoo!R3數據集上的實驗結果如表1所示。

表1 五個模型在Yahoo!R3數據集上的推薦性能Tab.1 Recommendation performance of five models on Yahoo!R3 dataset
通過對表1的實驗結果進行分析,可以得出以下結論:
1)FMF 的表現與BPR 相近,總體上略微遜色于BPR。基于IPS 的RMF 模型表現顯著優于FMF 和BPR,這得益于IPS模型可以有效地緩解數據的偏置問題,從而使RMF 模型可以學習到更為無偏的潛在特征。
2)結合本文MPE方法的RMF-MPE的表現相比RMF有顯著的提升(DCG@5相比RMF提升了5.35%),是在各項評估指標中表現最佳的模型。這表明相較于流行度傾向得分估計方法,MPE能在相同的數據中挖掘出更多的有用信息,即用戶層面的流行度偏好信息,最終實現對曝光率更精確的建模。由于IPS 框架模型的效果與傾向得分估計精確度直接相關,RMF-MPE 的實驗結果驗證了本文MPE 方法實現了更加精確的傾向得分估計,進而提升了推薦模型的無偏程度和推薦性能。
3)結合本文MPE 方法的FMF-MPE 模型相比FMF 模型在所有指標上也都有顯著地提升,綜合性能接近RMF 模型。值得注意的是,FMF 不是基于IPS 框架的模型,其效果的提升也驗證了MPE 對歷史推薦系統在曝光率建模上的有效性,并且說明MPE具有較好的通用性。
實驗二:長尾物品上的實驗。
將Yahoo!R3數據集中的物品按照點擊數從大到小進行排序,并以物品排序為橫坐標,點擊次數為縱坐標進行統計,得到長尾分布如圖1所示。
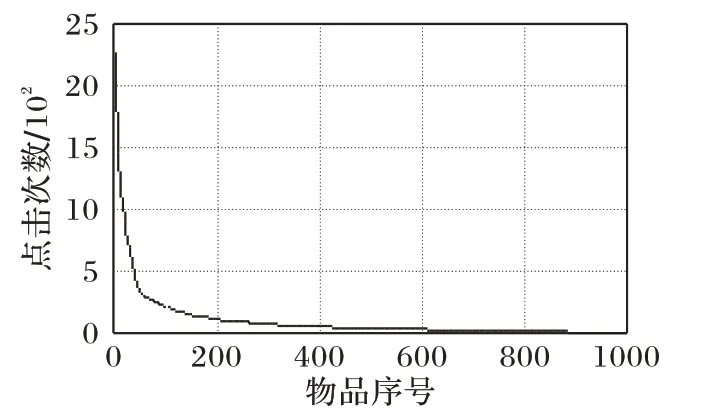
圖1 Yahoo!R3數據集中物品的點擊次數分布Fig.1 Distribution of number of clicks on items in Yahoo!R3 dataset
在推薦系統的場景下,長尾物品的有效推薦也是一個非常重要的研究問題。推薦系統往往能夠在流行度高的“短頭”(short-head)部分取得很好的推薦效果,而在“長尾”(long-tail)部分的推薦效果往往不盡人意[23-24]。處理長尾部分中零散的、個性化的需求問題能夠創造比短頭部分還要大的利潤。由于曝光偏置可能是導致長尾效應的一個重要因素,解決曝光偏置可望提升推薦模型在長尾物品上的推薦效果。
因此,本文對上述五種模型算法在長尾物品上的推薦效果進行進一步的實驗。將點擊數排名前10%的物品標記為Yahoo!R3 的短頭物品,其余為長尾物品。在保持所有實驗的模型參數、訓練過程不變的基礎上,僅在測試集中的長尾物品(點擊次數<250 的物品)子集上進行推薦效果評估。實驗結果如圖2所示。
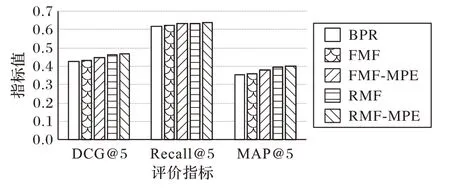
圖2 五個模型在Yahoo!R3數據集中長尾物品上的推薦效果Fig.2 Recommendation performance of five models on long-tail items in Yahoo!R3 dataset
通過對圖2的實驗結果進行分析,可以得出以下結論:
1)從DCG 和MAP評估指標來看,五個模型在長尾物品上的實驗結果相比在物品全集上的實驗結果有較大的差距,而在召回率上呈現出不一樣的趨勢。這可能是因為在將測試集縮小為原來的長尾物品子集后,長尾物品實驗中的待召回物品數目減少而導致召回率提升(評估指標的局限性)。五個模型在長尾部分的推薦效果表現均遜色于它們在物品全集上的表現,這驗證了推薦系統中長尾難題的存在,也符合經驗上的認知。
2)BPR、FMF、FMF-MPE、RMF和RMF-MPE在長尾物品上的推薦性能依次提升,且FMF 在長尾物品上的表現優于BPR(物品全集上呈現相反的趨勢)。可以看出,基于IPS 的RMF和RMF-MPE相比傳統推薦模型,在長尾物品推薦上的性能有顯著的提升,這得益于傾向得分對數據偏置問題的有效解決。從式(4)可以看到,RMF 為觀測數據中的長尾物品樣本(即曝光率小的點擊樣本)賦予了更高的權重。這表示在訓練過程中模型根據傾向得分適應性地提高了長尾物品的權重,即系統更加信任從這些長尾物品樣本中所學習到的個性化偏好信息,這也是符合直覺的一個結果。
3)我們認為RMF-MPE 相比RMF 在長尾物品上的提升來自MPE 對傾向得分估計精度的提高,使得模型捕捉到用戶更具適應性的無偏偏好。RMF 與RMF-MPE 都是基于逆傾向得分的模型,因此整體來說都會提升長尾物品在損失函數中的權重(長尾物品的曝光率低);而MPE 根據用戶的流行度偏好將用戶分類,融合用戶側和物品側的信息來估計傾向得分,使得同一物品對不同用戶有不同的傾向得分值,這在一定程度上增強了模型的表達能力,從而提升長尾物品上的性能。這說明數據糾偏對于提升長尾物品上的推薦性能是至關重要的,也值得今后在這方向上進行更深入的研究。
5 結語
本文針對現有的基于隱式反饋的無偏推薦算法在傾向得分估計上的缺陷,在分析先前工作不足的基礎上,引入用戶的流行度偏好,并通過配對用戶流行度偏好和物品流行度,提出了配對傾向得分估計(MPE)方法,并在公開數據集上通過實驗驗證了MPE 的有效性和通用性。在未來希望能夠進一步研究以下幾點:1)由于推薦系統的迭代,不同時間點的傾向得分是變化的,在未來的研究中可以探討如何有效地利用時序信息;2)基于隱式反饋的傾向得分的估計精度還有進一步提升的空間,我們將研究如何構建更加通用和更加精確的傾向得分估計方法;3)無偏置推薦算法在評估時受限于無偏置測試集的收集,在未來的研究中可以探討傳統推薦算法的評估和無偏置推薦算法的評估的互補性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
意林原創版(2016年10期)2016-11-25 10:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
