基于稀疏卷積的前景實時雙目深度估計算法
2022-01-05 02:32:36邱哲瀚
計算機應用 2021年12期
邱哲瀚,李 揚
(廣東工業大學機電工程學院,廣州 510006)
(?通信作者電子郵箱lyang@gdut.edu.cn)
0 引言
立體匹配作為無人駕駛的核心技術之一,通過不斷提升實時性能為自動駕駛提供更穩定的主動安全措施,伴隨著深度學習的進步研究而不斷發展。立體匹配算法通過匹配雙目圖像對中的對應像素,計算每對像素的視差值生成視差圖。比起傳統的立體匹配算法,深度學習視差估計算法可以有效優化圖像深度估計中的不適定問題,能夠利用先驗知識學習估算出遮擋和弱紋理區域的深度信息。基于深度學習的雙目立體匹配網絡基本構成[1]包括:雙目圖像對、空間特征提取模塊、視差代價聚合卷(cost-volume)和視差回歸模塊。
2015年,Mayer等[2]首次提出端對端的雙目視差估計網絡DispNet,通過下采樣方式提取空間特征后構建視差代價聚合卷cost-volume,并對cost-volume 進行視差解碼,最終回歸出稠密的視差估計圖。網絡DispNet采用端對端的結構,可以直接從雙目圖像中獲取視差估計圖,算法的總體性能高。為了進一步提高預測精度,不同于Mayer 等采用二維卷積視差回歸模塊,Chang 等[3]提出的PSMNet(Pyramid Stereo Matching Network)將下采樣的空間特征通過偏移、堆疊形成帶有視差通道的4 維cost-volume,并引入三維卷積層[4]進行視差回歸,顯著提升了視差估計的準確性,但同時也增加了運算資源占用。這是由于卷積層維度從二維到三維的增加,導致了網絡參數量大幅增長,算法的實時性能隨之也大幅下降。為此,本文方法在構建4 維cost-volume 時,采用稀疏卷積代替稠密卷積,通過只對前景進行特征提取的方式減小輸入參數量的初始規模,達到緩解卷積層維度增加帶來的參數量增長問題。
針對如何提高算法實時性的問題,Graham[5]提出用稀疏卷積(Sparse Convolution,SC)代替稠密卷積減少運算量。稀疏性允許網絡使用運算效率更高的卷積神經網絡(Convolutional Neural Network,CNN)架構,且運行更大、稀疏的CNN 可能會提高結果的準確性。具體地,Graham[6]通過在前景區域設置活動站點(active site)稀疏化數據,使得SC 只對稀疏化的數據進行卷積操作,減少了運算量。針對SC會隨著卷積層的加深無法保留數據稀疏性的問題,Graham 等[7]提出了子流形稀疏卷積(Submanifold Sparse Convolution,SSC)。SSC 只對輸入的活動站點進行卷積操作,且只對具有激活站點的輸出賦值,在保持數據原有稀疏性的同時進一步減少了運算量。為了最大限度發揮SC的優勢、克服稠密卷積參數量大的缺點,本文方法通過分割算法稀疏化輸入數據,并在特征提取主干網絡中使用SC 和SSC 完全取代稠密卷積,改善了立體匹配算法的實時性。此外,Uhrig等[8]使用SC在稀疏數據中恢復出稠密視差圖,表明SC具有從稀疏數據中提取深度信息的能力。根據該結論,本文方法使用SC 構造視差回歸模塊,通過解碼稀疏視差代價聚合卷中的深度信息,生成能夠預測稀疏前景的視差估計圖。因此配合分割算法和SC 實現對立體匹配算法的優化,能夠有效解決三維卷積解碼方式的實時性問題。
視差圖中前景的邊緣往往會有較大模糊,邊緣處視差值誤差率大。為了提升立體匹配算法的邊緣估計能力,Wang等[9]通過在視差特征中加入語義特征,提升了視差估計的邊緣效果;Fu 等[10]提出的注意力模塊起到語義上優化邊緣細節的效果。可是一般的注意力模塊只適用于稠密特征,不能兼容稀疏化特征的提取。本文方法借鑒了注意力機制的構筑方式,構造了適用于稀疏特征的空間注意力機制;同時注意力機制末端采用自適應線性疊加的方法,實現了語義特征和空間特征的疊加,形成能聚合空間、語義特征的語義注意力模塊。因此引入語義特征和注意力機制優化立體匹配算法,能夠有效地提升網絡整體的視差估計精度。
總體上,本文方法利用編碼-解碼結構的語義分割網絡LEDNet[11]作為前景分割模塊稀疏化數據,配合一般SC 和SSC逐層提取前景空間特征,大幅減小輸入數據的冗余度,提高了立體匹配算法的運算效率。充分利用LEDNet 編碼模塊的高層語義特征,通過建立語義注意力機制優化稀疏卷積層,可提升視差估計的整體邊緣效果。在數據集ApolloScape 的測試中,對比驗證了本文方法的實時性和準確性,并通過消融實驗證明了本文方法各模塊的有效性。
1 模型架構
本文針對場景目標深度估計情景下,基于稠密卷積的雙目視差估計算法所采取全局特征無差別提取的學習策略,既耗費額外計算資源,又降低網絡提取特征的效率的問題,提出了基于SC 的立體匹配網絡(SPSMNet)。模型整體架構如圖1所示,本文網絡利用編碼-解碼形式的語義分割模塊將圖像分割成形狀不規則的前景元素和背景元素,把前景元素作為掩膜稀疏化圖像并將其輸入到空間特征提取模塊;利用語義分割編碼模塊生成空間注意力機制優化空間特征的提取,同時將語義信息嵌入到空間特征中構建視差代價聚合卷;使用帶有視差通道的三維稀疏卷積模塊解碼視差代價聚合卷,最終回歸出視差估計圖。
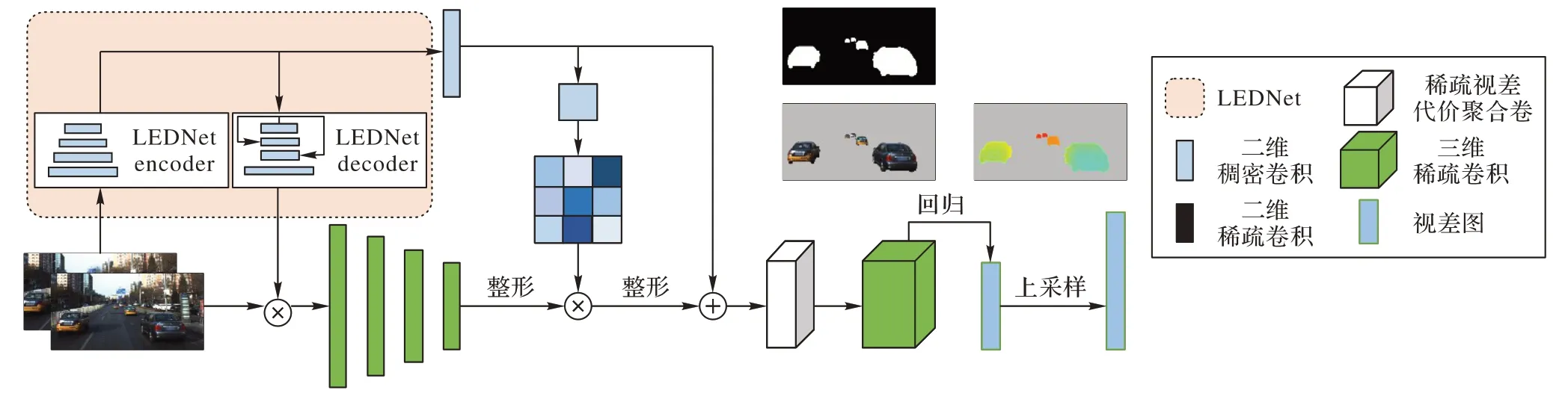
圖1 SPSMNet模型架構Fig.1 SPSMNet model architecture
1.1 語義分割模塊
在立體匹配網絡SPSMNet 中,語義分割模塊需要為網絡提供前景分割功能和提取語義信息,以供后續空間特征提取模塊和語義注意力模塊的使用,符合條件的語義分割模塊的結構將會是編碼-解碼形式;同時,語義分割模塊作為前置模塊,必須兼有精度高和處理快的特點。LEDNet作為輕量級語義分割網絡且具備編碼-解碼形式的結構,在數據集ApolloScape 的平均精確度(Average Precision,AP)達到0.91,因此很適合作為語義分割模塊。
前景分割功能是稀疏化輸入的雙目圖像的過程。利用網絡LEDNet語義分割出的前景掩膜,可以獲得輸入圖像的前景區域。對輸入圖像的前景區域設置活動站點標識,使得后續的空間特征提取模塊能夠識別需要處理的區域,從而只對輸入圖像的前景部分進行卷積操作,實現了輸入圖像稀疏化的功能。語義信息的獲取得益于LEDNet 的構成形式。LEDNet采用多次下采樣構造語義編碼模塊,使得豐富的語義信息緊湊地匯集在編碼模塊的最后一層特征圖。由此,后續的語義注意力模塊能夠簡單方便地獲取和使用語義信息。
1.2 空間特征提取模塊
基于稠密卷積的立體匹配算法,需要通過學習全局特征以區別多種類多目標邊界處的邊緣細節、估算各物體內部視差。不同于一般的稠密卷積,SC 可以有選擇性地學習前景空間特征,網絡的計算資源被更多地分配在優化目標視差的任務上,這使得采用稀疏卷積CNN 架構的立體匹配算法具有良好的準確性和實時性。利用稀疏卷積能夠高效提取稀疏特征的特點,使用SC和SSC構建4層下采樣的空間特征提取模塊,模塊架構如圖2所示。
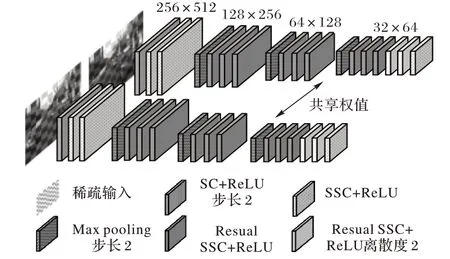
圖2 空間特征提取模塊Fig.2 Spatial feature extraction module
采用步長為2 的SC 和最大池化函數實現逐層下采樣,以保留顯著的空間特征、降低特征維度和增大卷積核的感受野;直連或殘差連接的SSC 保證了前景特征的稀疏性,同時加強了網絡訓練的魯棒性;模塊尾端采用離散度為2 的SSC 拓寬卷積核的感受野。卷積層的輸入均采用批歸一化處理,并使用ReLU 非線性函數激活網絡節點,左右圖像特征提取的卷積層共享權重。
1.3 語義注意力模塊
SC 能夠很好地通過稀疏前景估算出前景內部視差,但由于稀疏化的數據損失部分邊緣信息,生成的前景視差圖邊緣不清晰。為了補償丟失的邊緣信息,利用LEDNet解碼模塊最后一層的特征圖構建語義注意力模塊,模塊架構如圖3所示。
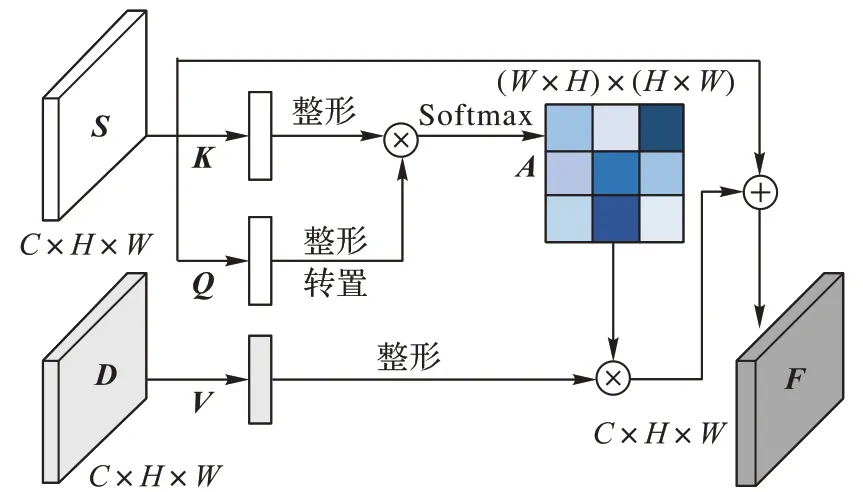
圖3 語義注意力模塊Fig.3 Semantic attention module
取LEDNet 編碼模塊的最后一層特征圖(segment feature map)記為S∈RC×H×W,特征圖S經過核心數為1 的稠密卷積后生成{Q,K}∈R1×H×W。把{Q,K}統一整形成R1×N的結構(其中N=H×W),將矩陣Q轉置后與K做矩陣乘積,并應用softmax 函數生成注意力圖A∈RN×N。其中aij是注意力圖A的元素,i,j為元素坐標,則由{Q,K}生成注意力圖A的計算方法如下所示:

取空間特征提取模塊的最后一層特征圖(disparity feature map)記為D∈RC×H×W,特征圖D經過卷積核1× 1 的卷積后整形成RC×N結構(其中N=H×W)。將經過卷積并整形后的特征圖D與注意力圖A做矩陣乘積,結果加上語義特征圖S,之后整形生成聚合特征F∈RC×H×W。其中:fijk是聚合特征F的元素,i、j、k為元素坐標,a、d、s分別是注意力圖A、經過1× 1 卷積的空間特征圖D、語義特征圖S的元素,β為自適應參數。則聚合特征F的計算方法如下所示:
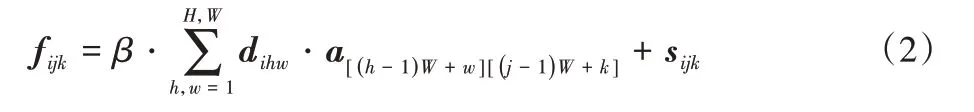
1.4 稀疏視差代價聚合卷
對于一組雙目圖像輸入,在經過語義注意力模塊之后,將會得到同時聚合了空間特征和語義特征的左、右兩個位置的聚合特征。為了維持特征的稀疏性,由語義注意力模塊得到的聚合特征是稀疏的;聚合特征所具有的活動站點標識,其標識的狀態與空間特征提取模塊最后一層的特征圖相一致。視差代價聚合卷是對左、右聚合特征的結合構造,其組織也應該是稀疏的。稀疏視差代價聚合卷的構造方式與PSMNet[3]類似,都是結合左右圖中每個視差值對應的特征圖,但只對具有活動站點標識的特征做出響應,并輸出維持著原有稀疏性的4維代價聚合卷(特征×視差×高×寬)。
在最大可預測視差值設定為D的情況下,由于聚合特征的寬高尺寸是目標視差圖的1/8,前景視差估計將會產生D/8個視差值選項,即4維代價聚合卷的視差通道數目。4維代價聚合卷的第d個視差通道即視差值為d時,左、右聚合特征的結合方式為:左聚合特征保持不變,右聚合特征在寬通道上整體右移d個單位,之后在特征通道上對左右特征進行拼接形成視差特征,最后將視差特征在寬通道上由于右移產生的無效左區間的數值置0;同時,移位操作會同步移動活動站點,置0 操作會取消活動站點,拼接操作也會拼接活動站點,這使得稀疏特征能夠被正確表示。最后將D/8 個視差特征在視差通道上進行堆疊,形成帶有視差通道的稀疏4維代價聚合卷。
聚合卷內不同視差通道的左、右聚合特征,在拼接成視差特征之前,其活動站點需要進行平移和移除操作。根據雙目圖像左右位置的不同,從屬于代價聚合卷內不同視差通道的活動站點a'left,a'right的激活情況如下所示,其中c、h、w是不同視差通道特征圖的特征、高、寬通道,d為通道視差值,ε為單位階躍函數,a是視差聚合前活動站點的激活情況:
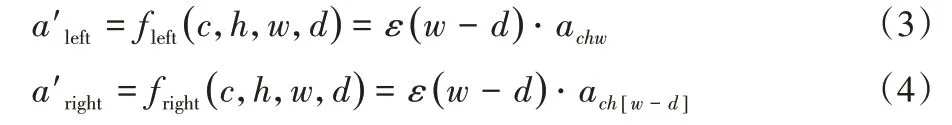
在稀疏代價聚合卷的視差通道內,經過平移置零操作后的左、右聚合特征拼接成視差特征的活動站點激活方式如圖4 所示,對于視差通道的視差特征,圖(a)左聚合特征和圖(b)右聚合特征的活動站點標識fleft、fright會合并到圖(c)代價聚合層的視差特征中,從而保持了原有特征的稀疏性。
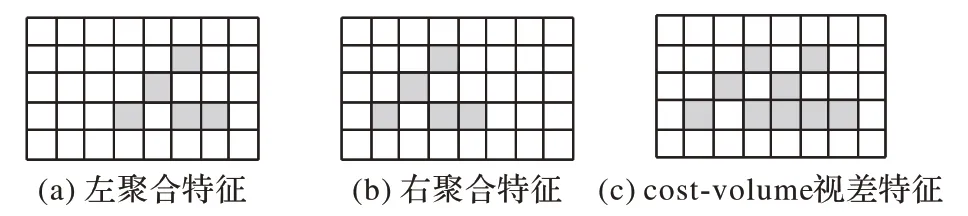
圖4 視差通道激活方式Fig.4 Disparity channel activation mode
1.5 視差回歸模塊
為了適配稀疏的視差代價聚合卷,利用SC 和SSC 構建三維卷積模塊對稀疏特征代價卷進行解碼。模塊架構如圖5 所示,模塊采用殘差連接的方式,SC 與SSC 交替聯結。卷積層的輸入均采用批歸一化處理,每個卷積層后面使用ReLU 非線性函數激活網絡節點。
在模塊末端的稀疏卷積層,通過連接SC+dense 層將稀疏的解碼圖轉化為稠密的解碼圖C∈RD×32×64,使用雙線性插值對解碼圖進行8 倍上采樣得到C'∈RD×256×512,最后利用以下計算方法回歸出最終的視差估計圖,其中d為視差值:

1.6 損失函數
實現前景視差估計任務的監督學習,具體做法是通過分割算法有選擇性地選取視差真值圖的前景區域,只對視差估計圖的前景區域使用平滑L1[12]損失作為網絡的損失函數。對于視差估計圖與視差真值圖D,圖上對應的每個視差值與di,其整體損失函數可以表示為:

2 實驗與結果
2.1 實驗數據集
ApolloScape[13]數據集采集自真實路況場景,其中包括適用于不同訓練任務的多個子數據集,以滿足自動駕駛多種應用需求。立體匹配數據集Stereo 同時包含視差真值圖,前景標簽圖和雙目圖像對的訓練樣本共有4 158 個,以6∶2∶1 的比率將樣本劃分出訓練集、驗證集以及測試集,并對樣本進行清洗和預處理,操作過程遵循以下規則:
1)去除錯誤標注;
2)對于視差真值圖,車體小范圍遮擋區域利用鄰近的視差值替代,連續遮擋超過1/3車體的區域則直接刪除;
3)前景標簽圖對應視差真值圖的刪除區域也一并刪除。
為了適應網絡輸出尺寸,采用雙線性插值的方法縮放視差真值圖,并按照相同比例對視差值進行放縮,利用隨機裁剪的方式獲取作為訓練標簽的視差真值圖。
2.2 實驗設置
2.2.1 訓練設置
基于PyTorch[14]深度學習框架,網絡的搭載訓練和測試過程都在NVIDIA RTX2080 GPU 上運行(可以進行3 個批處理的訓練)。首先按照默認參數設置,利用前景標簽圖監督學習得到訓練好的LEDNet,將其嵌入到網絡中。將立體匹配的最大視差設置為192,梯度更新采用Adam 優化器(動量參數β1=0.9,β2=0.999),以初始學習率0.001開始訓練網絡。訓練過程每進行50 輪迭代,學習率下調到原來的1/2,直至網絡損失穩定在某一數值為止。
2.2.2 測試設置
為了對比本文方法和其他同樣在ApolloScape 數據集上進行訓練的相關工作,本文采用了常用的衡量指標評估結果。其中表示視差估計圖的預測值,di表示視差真值圖的實際值,則指標表達式如下所示:
1)平均絕對誤差(Mean Absolute Error,MAE):

2)絕對相對誤差(Absolute Relative Error,ARE):

3)N點像素誤差(NPixel Error,NPE):

2.3 實驗結果
從ApolloScape 測試集中選取了5 個圖像對,將本文方法與PSMNet[3]和GANet(Guided Aggregation Network)[15]算法進行對比實驗,實驗結果如圖6 和圖7 所示,其中前景標簽標識著輸入圖像的前景區域,視差真值的有效范圍與前景區域相對應。從圖6、7 可以看出,本文方法能夠準確預測前景的內部視差和邊緣細節,尤其是中遠距離物體的視差誤差(誤差圖前景色越暗淡誤差越小)明顯小于其他兩種算法;物體內部視差相對統一,輪廓清晰且過渡穩定,可以較好恢復重合物體的邊緣。

圖6 ApolloScape測試集的5組樣本Fig.6 Five group of samples in ApolloScape dataset
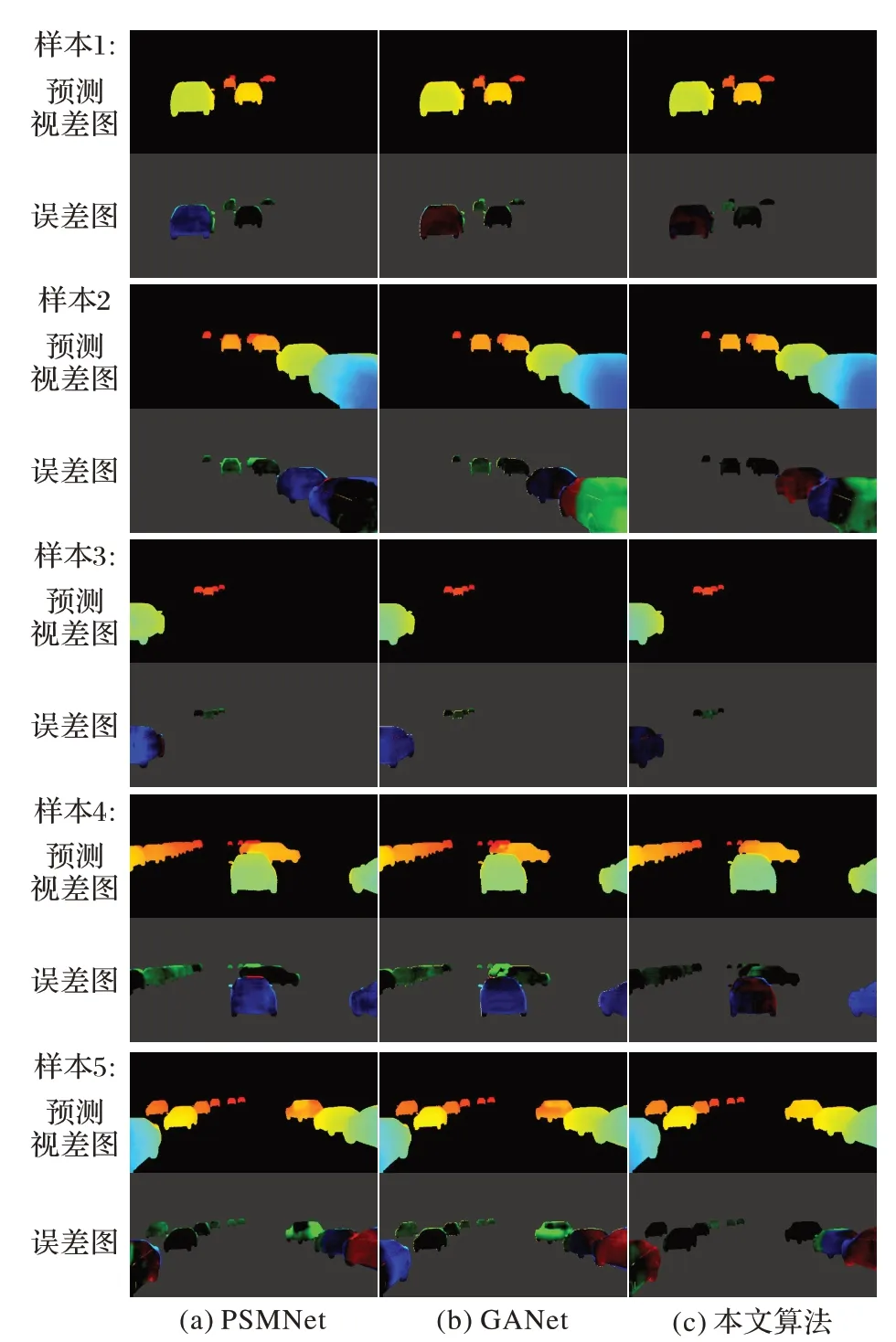
圖7 PSMNet、GANet和本文算法對圖6的視差估計結果Fig.7 Results of disparity estimation of PSMNet,GANet and proposed algorithms to Fig.6
在視差圖生成尺度統一為256×512 的情況下,對測試集的實驗結果進行了定量可視化,并把各種方法的誤差指標進行了對比,定量結果如表1 所示。表1 中,本文方法的平均絕對誤差為1.47 像素,視差誤差率在誤差大于2、3、5 像素時分別為22.05%、11.16%、3.94%,同時運行幀率為每秒16.53幀,表現效果優于對比的其他算法,具有較高的準確度和實時性。
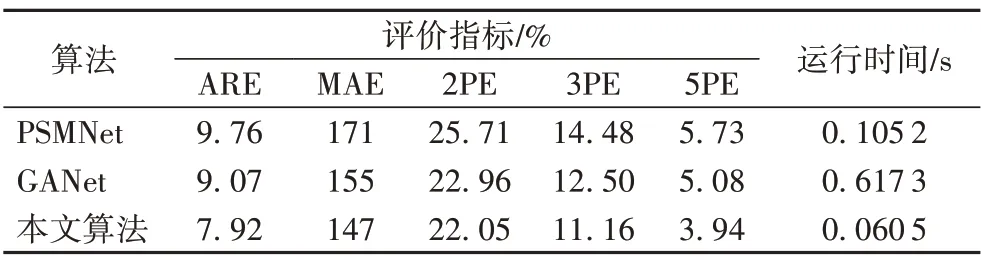
表1 ApolloScape測試集上的定量結果Tab.1 Quantitative results on ApolloScape dataset
2.4 消融實驗
為了更好地分析各個優化策略的性能,依據采取策略的不同,設置三組模型prototype1、prototype2和prototype3進行消融實驗。對比本文模型prototype3,模型prototype1 的CNN 架構為一般的稠密卷積,模型prototype2則是采用稀疏卷積但不使用語義注意力策略。在視差圖生成尺度統一為256×512 的情況下,選取了ApolloScape測試集中的2個圖像對,各個模型的樣本實驗結果如圖8 和圖9 所示。從圖8、9 可以看出,采取稀疏卷積策略可以更好地預測中遠距離前景的內部視差,語義注意力策略很好地彌補了前者策略在近景視差估計上的不足,邊緣細節也更加清晰。這得益于稀疏卷積策略能夠高效提取前景特征,同時語義注意力策略可以補充稀疏特征缺乏的高層語義信息,能指導生成更加精準的視差圖。

圖8 ApolloScape測試集的2組樣本Fig.8 Two group of samples of ApolloScape test dataset

圖9 三個模型對圖8的視差估計結果Fig.9 Results of disparity estimation of three models to Fig.8
從表2 可以更加直觀地看出,本文方法prototype3 的視差誤差率在誤差大于2、3、5 像素時分別為22.05%、11.16%、3.94%,在三組模型中具有最佳性能;只采取稀疏卷積策略的模型prototype2,表現效果優于單獨采用一般CNN架構的模型prototype1。
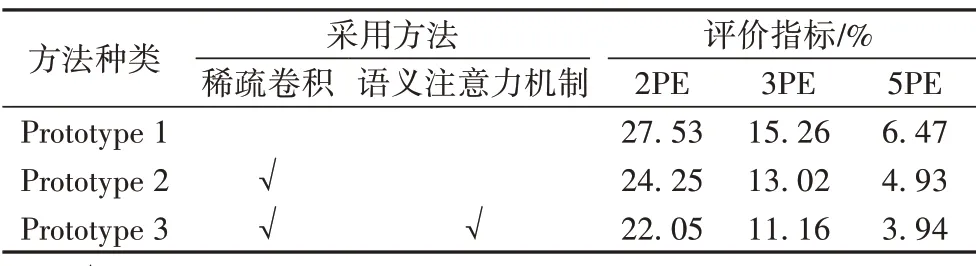
表2 消融實驗Tab.2 Ablation experiment
圖10展示了200個訓練批次下三組模型的驗證集損失曲線,從曲線走勢可以看出,采取了稀疏卷積策略的網絡比模型prototype1 收斂得更快、更平穩;額外采用了語義注意力策略的模型prototype3,其網絡收斂速度略快于prototype2。綜上所述,本文方法所采用的稀疏卷積策略和語義注意力策略,都對視差估計結果的優化具有一定的有效性。
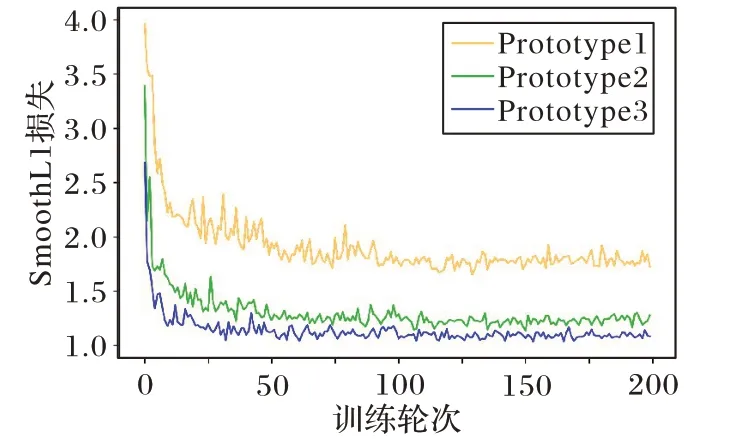
圖10 三組模型的驗證集損失曲線Fig.10 Validation dagaset loss curves for three models
3 結語
本文針對前景視差估計的特定任務下,使用稠密卷積架構將造成立體匹配算法資源占用過高、實時性能不足等問題,提出了一種基于稀疏卷積架構的實時立體匹配框架。框架采用了稀疏卷積和語義注意力策略,可以提取豐富的空間、語義聯合特征,從而穩定地獲得表面平滑,邊緣清晰的最終視差圖;采用了先提取前景后預測視差的方式,區別于直接獲取整個場景的視差圖,可以實現對前景區域更快更精準的視差估計。實驗結果表明,本文方法具有實時性和準確性的優勢,對前景遮擋表現出抗噪性和魯棒性,視差估計的效果明顯優于現有的先進方法。
稀疏卷積架構允許擴大輸入圖像的尺寸,通過更詳細的輸入信息獲得精度更高的視差圖,但是稀疏卷積提取的空間特征缺乏語義信息,這會導致高視差值區域的預測效果不如一般卷積。稀疏卷積架構依賴于分割算法,分割精度會影響到前景空間特征的提取,這意味著網絡不是端到端的結構。如何進一步豐富稀疏架構的語義特征,以及實現網絡的端到端結構,這些需要在今后的工作中逐步改善和加強。
猜你喜歡
建材發展導向(2021年6期)2021-06-09 05:57:08
現代國際關系(2021年2期)2021-04-13 01:59:16
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中國外匯(2019年11期)2019-08-27 02:06:32
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
太空探索(2016年10期)2016-07-10 12:07:01
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
