
基于密集Inception的單圖像超分辨率重建方法
2022-01-05 02:32:28王海勇張開心管維正
計算機應用 2021年12期
王海勇,張開心,管維正
(1.南京郵電大學計算機學院,南京 210023;2.南京郵電大學物聯網學院,南京 210003)
(?通信作者電子郵箱18336921525@163.com)
0 引言
單圖像超分辨率(Super-Resolution,SR)重建是計算機視覺領域一個經典的研究方向。刑事偵查、安全監控、醫學影像等領域非常重視圖像細節,但是因為攝像設備、拍攝角度、光線等原因,導致拍攝出來的圖像分辨率過低,影響工作人員對圖像細節的判斷[1]。因此,單圖像SR重建的研究至關重要。
近幾年,隨著深度學習的發展,基于卷積神經網絡(Convolutional Neural Network,CNN)的單圖像SR研究受到廣泛關注。經研究發現,CNN越深,可以從較大的感受野中獲得越多的上下文信息,重建效果會越好;但是,隨著網絡層數加深到一定規模,單純地加深網絡會出現有關輸入或梯度信息經過多層傳播,在到達網絡末端時消失[2]。密集連接卷積網絡(Densely Connected Convolutional Networks,DenseNets)[3]通過創建每一層到所有后續層的最短路徑,有效緩解了梯度消失的問題,并且能夠加強特征傳播,鼓勵特征重用。初期,網絡結構的突破大都是純粹地增加網絡的深度或寬度,但是該方法會帶來很多問題,比如:在訓練集有限的情況下,網絡參數過多,會出現過擬合的現象;網絡過大,計算復雜度高。在這種情況下,Inception[4]結構應運而生,該架構的主要思想是在增加網絡深度和寬度的同時保持計算預算不變,提高網絡內計算資源的利用率[4]。
在以上深度模型的啟發下,本文提出了一種基于密集Inception 的單圖像超分辨率重建方法。該方法全局采用簡化后的密集網絡,每個分層的特征采用一個跳過連接,僅傳入重建層,用于特征重建,可以避免分層特征過度重用,引入冗余信息。核心模塊采用堆疊的Inception-殘差網絡(Inception-Residual Network,Inception-ResNet)[5]結構,本文簡稱為IRN,該結構通過很少的計算量,保證了模型的深度和寬度,利于圖像特征提取和重建,選用的IRN 結構相較于先前的版本,融入了殘差連接,可以顯著加快網絡的訓練速度。總的來說,本文所提出的方法參數少,模型的訓練速度快,可以在資源受限的設備上進行訓練。
1 相關工作
1.1 單圖像超分辨率重建
經典的單圖像SR重建方法包括基于插值的方法,基于重建的方法和基于學習的方法。其中,基于插值的方法雖然計算簡單,但是重建效果差。基于重建的方法存在難以處理噪聲、先驗約束不生效等問題。因此,基于學習的方法成為研究熱點。
Dong 等[6]提出了基于CNN 的超分辨率(Super-Resolution CNN,SRCNN),首次將CNN 用于單圖像SR 重建。該模型雖然只有三層,但是相較于傳統的重建方法,重建效果異常顯著。Kim等[7]提出了具有20個權重層的超深CNN的圖像超分辨 率(accurate image Super-Resolution using Very Deep convolutional network,VDSR),具有非常大的感受野,同時VDSR 將多種尺度的圖像同時放入模型中進行訓練,滿足了多尺度圖像重建的需求。Dong等[8]又提出了加速的超分辨率CNN(Fast Super-Resolution CNN,FSRCNN),在網絡末端引入了一個反卷積層用于上采樣。基于學習的圖像超分辨率重建方法與傳統的方法相比具有顯著的優越性,因此,本文采用基于學習的方法進行研究。
1.2 跳過連接
隨著卷積神經網絡的加深,相應的梯度消失問題也顯現出來。為了解決這一問題,Kim等[9]提出了深度遞歸卷積網絡(Deeply-Recursive Convolutional Network,DRCN),使用遞歸神經網絡來解決SR 問題。Huang 等[3]提出了密集卷積網絡,在該網絡中所有的層通過跳過連接的方式連接起來,L層的卷積神經網絡有L(L+1)/2 個連接。Tong 等[10]使用密集跳過連接來解決圖像SR問題,表明了使用密集跳過連接的方式重建圖像的效果更好。Zhang 等[11]提出了基于殘差密集網絡的圖像超分辨率(Residual Dense Network for image superresolution,RDN),通過密集連接使得每個殘差塊都能獲得來自先前殘差塊的輸出。Tang 等[12]簡化了密集連接架構,只在重構層中重用各個特征提取層的特征,減少了冗余信息。
1.3 Inception結構
2014 年,谷歌推出了一款稱為GoogLeNet 的網絡,其核心結構是Inception-v1,該結構修改了傳統的卷積神經網絡結構,將全連接變成稀疏連接[4]。Ioffe 等[13]引入批量歸一化的思想,修改后的結構稱為Inception-v2。由于大尺寸卷積核進行卷積操作的計算量非常大,為了提高計算效率,Szegedy等[14]將Inception-v1 結構中5× 5 卷積核替換為兩層3× 3 的卷積核,通過共享相鄰切片之間的權重,減少了參數量,該結構稱為Inception-v3[14]。Szegedy 等[5]又提出了Inception-v4 和Inception-ResNet,其中Inception-v4 為先前版本的變體,Inception-ResNet 在普通的Inception 結構中引入了ResNet,極大提高了模型訓練速度。
Li 等[15]提出了基于多尺度殘差網絡的圖像SR(Multi-Scale Residual Network for image super-resolution,MSRN),該方法主要由多尺度殘差塊(Multi-Scale Residual Block,MSRB)構成,該結構采用3× 3 和5× 5 兩種卷積核交叉串聯的方式從各個尺度提取圖像特征,保證提取特征的多樣性。Qin 等[16]提出了一種基于多分辨率空域殘差密集網絡的圖像超分辨率重建方法,有效解決了先前方法重建的圖像存在紋理區域過度平滑的問題。
2 本文方法
2.1 網絡結構
本文所提出的基于密集Inception的單圖像超分辨率重建方法的模型結構如圖1所示。
本文模型主要由兩部分組成:特征提取模塊和特征重建模塊。用于訓練的單個低分辨率(Low Resolution,LR)圖像表示為ILR∈RW×H×C,重建的高分辨率(High Resolution,HR)圖像表示為ISR∈RWr×Hr×C,其中,W和H表示LR 圖像的寬度和高度,r表示放大系數,C表示色彩空間的通道數。模型的輸入輸出原理表示為:


其中:FFE(?)表示特征提取模塊的映射函數;FFR(?)表示特征重建模塊的映射函數;HFE表示特征提取模塊的輸出,同時作為特征重建模塊的輸入。
2.1.1 特征提取模塊
本文所提出的特征提取模塊由低層特征提取模塊、高層特征提取模塊和一個特征融合層組成。其中,低層特征提取模塊由一個卷積核大小為3× 3的卷積層構成;高層特征提取模塊由若干個堆疊的IRN 組成;在整個模塊外圍構建了簡化后的密集跳過連接,僅融合低層特征模塊的輸出與高層特征模塊各個子模塊的輸出,作為特征融合層的輸入。
特征提取模塊在圖像超分辨率重建模型中起著重要作用,提取的特征越多,重建效果越好。先前的圖像超分辨率重建模型通常僅使用特征提取模塊最終輸出的特征來重建圖像,而忽略了在特征傳遞過程中各個特征提取層的多樣特征。因此,本文所提出的模型使用簡化后的密集網絡融合各個特征提取層的特征,從而獲得更多上下文信息,可以為重建模塊提供豐富的信息。
通常情況下,提高深度神經網絡性能的最直接方法是增加模型的大小,包括增加模型的深度和寬度,這是一種簡單安全的訓練高質量模型的方法,特別是考慮到大量標記的訓練數據的可用性。然而,這種簡單的解決方案有兩個主要問題:1)較大的網絡尺度通常意味著提取更多的參數,這使得在訓練集數量有限的情況下,容易出現過度擬合,在訓練集很大的情況下,運算量又非常巨大;2)統一增加網絡大小會導致計算資源的顯著增加。例如,在深度卷積神經網絡中,如果連接兩個卷積層,則任何一個卷積層卷積核數量的增加都會導致計算量成倍的增加,如果無效地使用增加的容量則浪費了大量計算資源。由于在實驗中計算預算總是有限的,因此計算資源的有效分配也優于沒有限制地增加網絡大小[4]。解決這兩個問題的根本方法是將卷積層之間的完全連接轉變成稀疏連接。
Inception 結構的主要思想是將各個卷積層以串聯并聯的方式相結合,使得在每個卷積層中增加卷積核的數量而不會引入過多的計算量,因此本文提出的模型選擇該結構作為主要的特征提取模塊[4]。由于該結構現行的版本很多,本文僅選擇IRN 進行疊加,其結構如圖2 所示,該結構與先前各版本相比融入了殘差結構,可以顯著加快模型的訓練速度。
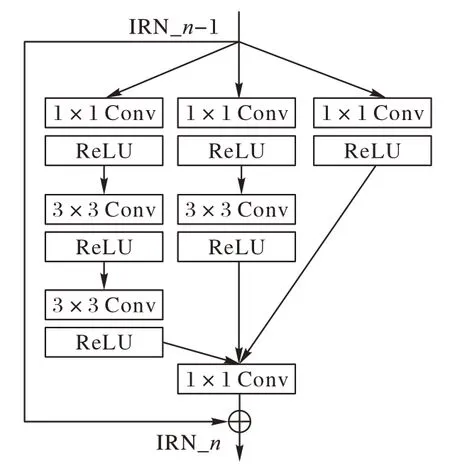
圖2 IRN結構Fig.2 Structure of IRN
具體地,整個特征提取模塊的輸入輸出原理表示為:

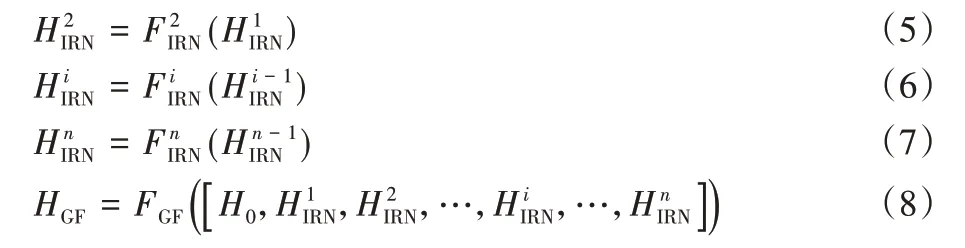
其中:H0表示低層特征提取模塊的輸出同時作為高層特征提取模塊的輸入;分別表示第1、2、i和n個IRN 的輸出;FLF(·)表示低層特征提取模塊的映射函數,表示各個IRN 映射函數;表示串聯結構;HGF表示特征融合層的輸出;FGF(·)表示融合層的映射函數。
構成高層特征提取模塊的IRN 主結構由1× 1 和3× 3 兩種卷積層組成,寬度上采用多通道串聯的結構,全局采用殘差連接,第i個IRN的輸入輸出原理可以表示為:
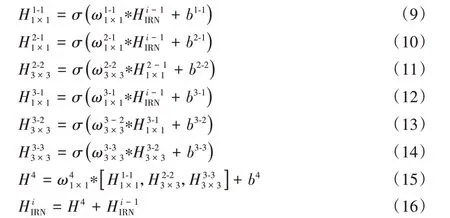
2.1.2 特征重建模塊
大多數模型的特征重建模塊選用反卷積層將圖像恢復到原始尺寸,與插值方法相比,減少了計算量。但是對于不同尺度的模型,需要設置不同數量和尺寸的反卷積層,以2 × 2 反卷積層為基準,逐漸將圖片恢復到原始尺寸大小。放大因子越大,需要堆疊的2 × 2 反卷積層越多,會增加訓練的不確定性;并且,該方法不適用于奇數放大因子。因此,重建模塊由一個卷積層、一個Pixel Shuffle 層和一個特征重建層組成,重建模塊的輸入是由特征融合層的輸出得到。
該模塊的輸入輸出原理表示為:

其中:HCN表示卷積層的輸出;FCN(·)表示卷積層的映射函數;HPX表示Pixel Shuffle 層的輸出;FPX(·)表示Pixel Shuffle 層的映射函數;ISR為重建的SR 圖像;FRC(·)表示重建層的映射函數。
2.2 損失函數
大多數通用的損失函數包括兩種:一種是L1_Loss,也稱為最小絕對值偏差(Least Absolute Deviation,LAD),實現原理是把目標值與估計值的絕對插值總和最小化;另一種是L2_Loss,也稱為最小平方誤差(Least Square Error,LSE),原理是把目標值與估計值的插值平方和最小化。為了便于和先前的工作比較,選擇常用的L1_Loss。假設訓練集表示為,包括N個LR 圖像和對應的HR 圖像,以LR 圖像作為輸入,輸出重建的SR 圖像,最終目標是最小化兩者之間的差距。L1_Loss的原理表示為:
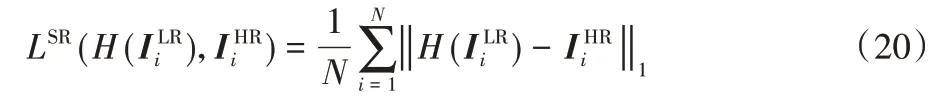
3 實驗與結果分析
3.1 訓練和測試數據集
為了將本文方法和現有的方法進行比較,本文的訓練集采用DIV2K 數據集[17],其中包括800 張訓練圖像、100 張驗證圖像和100 張測試圖像,不同于以往的291 幅圖像,該數據集每一張圖像都是分辨率為2 048× 1080 的高清圖像,對圖像重建的效果要求更高。本文選用前800 張圖像作為訓練集,訓練集采用縮放、旋轉、翻轉三種方式進行擴充。
測試集選擇通用的基準數據集:Set5[18]、Set14[19]、Urban100[20],這些數據集包含各種類型的圖像,滿足在各種場景的圖像中驗證本文的模型。測試集的圖像均通過Matlab代碼使用雙三次插值下采樣進行處理,得到LR 圖像,下采樣尺度包括×2、×3、×4。為了便于與先前方法比較,僅在基于YCbCr色彩空間中的亮度通道Y進行測試。
3.2 實驗參數
模型的高層特征提取模塊中,IRN 的個數設置為8。為了避免在訓練過程中出現尺寸不匹配的情況,在代碼上使用零填充的方法,保證在特征傳遞過程中圖像大小保持一致。實驗環境在基于Ubuntu 系統的遠程服務器上進行,配置兩臺英偉達GPU,使用python進行編程,版本為3.6.9,深度學習框架采用pytorch,版本為1.0.0,對應的torchvision 版本為0.2.0,CUDA版本為11.0。
訓練的batch_size設置為16,圖像分多個批次進行反向迭代訓練,總共訓練1 000 個epoch。訓練下采樣倍數為×2 的模型時,patch_size 設置為96;訓練下采樣倍數為×3 的模型時,patch_size 設置為144;訓練下采樣倍數為×4 的模型時,patch_size 設置為192。低層特征提取模塊的卷積核大小設置為3× 3。特征提取模塊和特征融合層的所有卷積層的輸出均設置為64 個特征圖,即64 個通道。初始學習率設置為1E-4,每200 個epoch 后,將學習率降至原來的一半。使用自適應矩估計(ADaptive Moment Estimation,ADAM)優化器[21]訓練模型,參數設置為β1=0.9,β2=0.999,?=10-8。
為了加快模型的訓練,提高圖形處理器(Graphics Processing Unit,GPU)的內存占用率,充分利用GPU 內存,Pytorch 框架的Dataloader 模塊里面的參數num_workers 設置為8,分配多個子線程訓練模型,pin_memory 設置為True,節省了將數據從中央處理器(Central Processing Unit,CPU)傳入隨機存取存儲器(Random Access Memory,RAM),再傳輸到GPU 的時間,直接映射數據到GPU 的專用內存,減少數據傳輸時間,可以避免CPU 被瘋狂占用而GPU 空閑,提高了GPU利用率。
3.3 性能評價指標
本文主要選用峰值信噪比(Peak Signal-to Noise-Ratio,PSNR)和結構相似性(Structural SIMilarity,SSIM)作為重建圖像質量的評價指標。PSNR的計算式為:

其中:MAX表示圖像點顏色的最大數值;L1 表示損失函數。兩幅圖像間的PSNR 值(單位dB)越高,則重建圖像相對于HR圖像失真越少。
SSIM 計算式基于樣本x和y之間的三個比較衡量:亮度、對比度和結構。SSIM的計算式表示為:
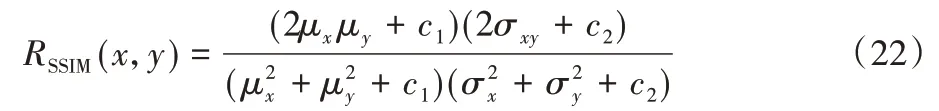
其中:μx為x的均值,μy為y的均值;為x的方差,為y的方差,σxy為x和y的協方差;c1=(k1L)2,c2=(k2L)2為兩個常數,L為像素值的范圍2B-1(B是比特深度,一般取值為8),k1=0.01,k2=0.03為默認值。
每次計算時都從圖像上取一個N×N的窗口,然后不斷滑動窗口進行計算,最后取平均值作為全局的SSIM。
3.4 結果分析
3.4.1 重建性能對比
圖3給出了本文方法在放大倍數為2、3、4時,模型的損失變化情況,橫坐標為epoch,縱坐標為loss。可以看出,本文方法可以使loss 迅速收斂至很小值,且運行穩定,可以較好地優化模型參數,使重建性能更佳。
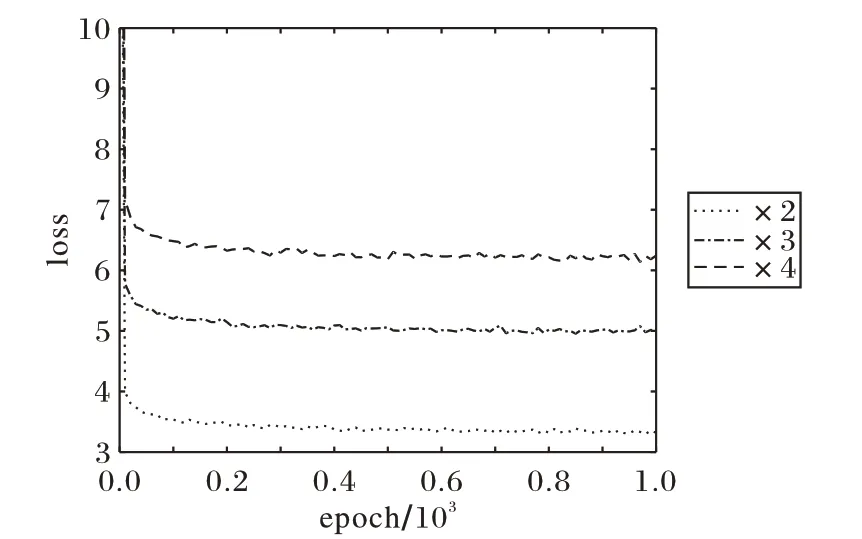
圖3 本文方法的損失收斂曲線Fig.3 Loss convergence curve of proposed method
為了驗證本文方法在重建性能上的優越性,將本文方法與SRCNN[6]、高效亞像素CNN(Efficient Sub-pixel CNN,ESPCN)[22]、FSRCNN[8]、VDSR[7]、DRCN[9]、深度拉普拉斯金字塔超分辨率重建網絡(fast and accurate image Super-Resolution with deep Laplacian pyramid Network,LapSRN)[23]、深度遞歸殘差網絡(Deep Recursive Residual Network,DRRN)[24]、用于圖像恢復的持久性存儲網絡(persistent Memory Network for image restoration,MemNet)[25]和MSRN[15]方法進行比較,這些方法的實驗結果均通過原文公開的實驗數據獲取。針對插值處理過的×2、×3、×4 的LR 圖像,采用本文所提出的模型進行重建,得到對應的SR 圖像,再通過Matlab 代碼,得到SR 圖像的PSNR值和SSIM值。
圖4 給出了本文方法在測試數據集上生成的部分SR 圖像與其他方法重建圖像的細節對比,能夠觀察到,本文方法重建圖像的細節恢復得最好。其中,SRCNN 等方法重建的嬰兒睫毛和蝴蝶翅膀細節非常模糊且失真嚴重,小鳥嘴巴邊緣和辣椒輪廓存在偽影,而本文方法得到的嬰兒睫毛根根分明,蝴蝶翅膀細節完整,小鳥嘴巴和辣椒邊緣輪廓清晰,線條明朗,高頻細節得到恢復,更接近原始HR圖像。
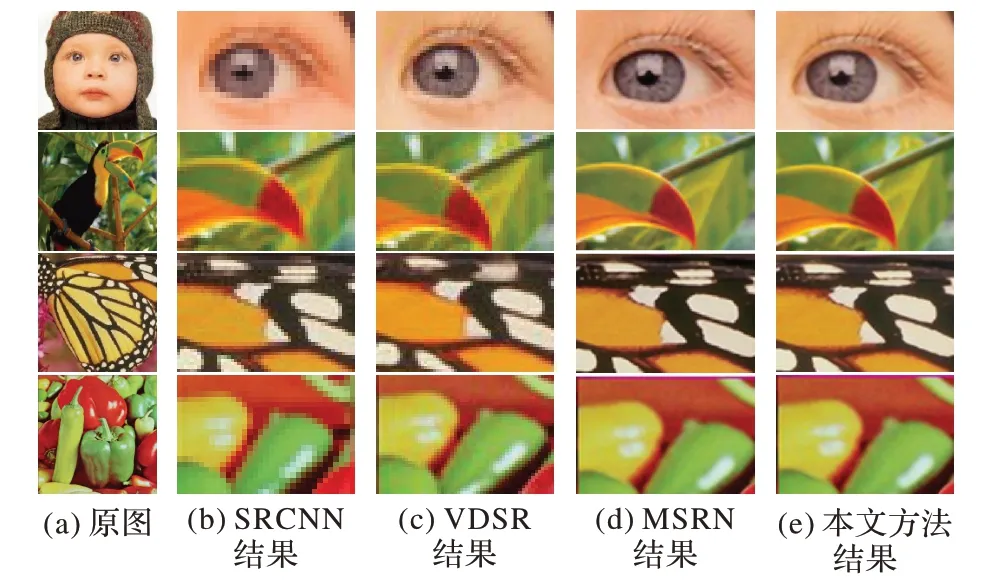
圖4 不同方法重建的SR圖像局部細節對比Fig.4 Local detail comparison of SR images reconstructed by different methods
表1~3 分別給出了在測試集中,本文方法與其他方法在放大倍數為2、3和4時的PSNR值和SSIM值的比較,加粗顯示的數據代表所有方法中最優的。可以看出,與SRCNN 等方法相比,本文方法得到的PSNR值和SSIM值均有顯著提升,主要是由于本文方法采用一種稀疏連接的方法,可以在增加模型深度和寬度時,保證參數量盡可能少地增加,同時使重建性能得到提升;與同樣采用稀疏連接方法的MSRN 相比,互有優劣,主要是由于MSRN 采用5× 5 和3× 3 兩種卷積交叉串聯的方式,本文方法采用1× 1 和3× 3 兩種卷積直接連接的方法,使得MSRN 的參數量遠遠多于本文方法,從而導致其部分性能優于本文方法。其中,放大倍數為4 時,針對數據集Set5,相較于VDSR,本文方法的SSIM 高了0.013 6,相較于MSRN,其SSIM 高了0.002 9。具體的參數對性能的影響在3.4.2節進行了詳細的分析對比。
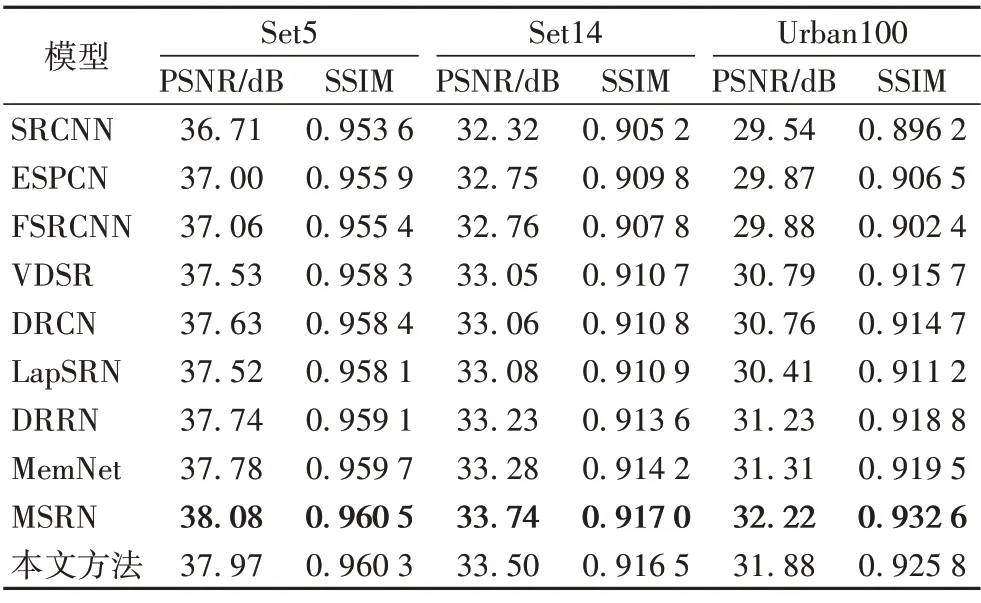
表1 本文方法與其他方法在放大倍數為2時的PSNR/SSIM對比Tab.1 Comparison of PSNR/SSIM between proposed method and other methods at 2 magnification
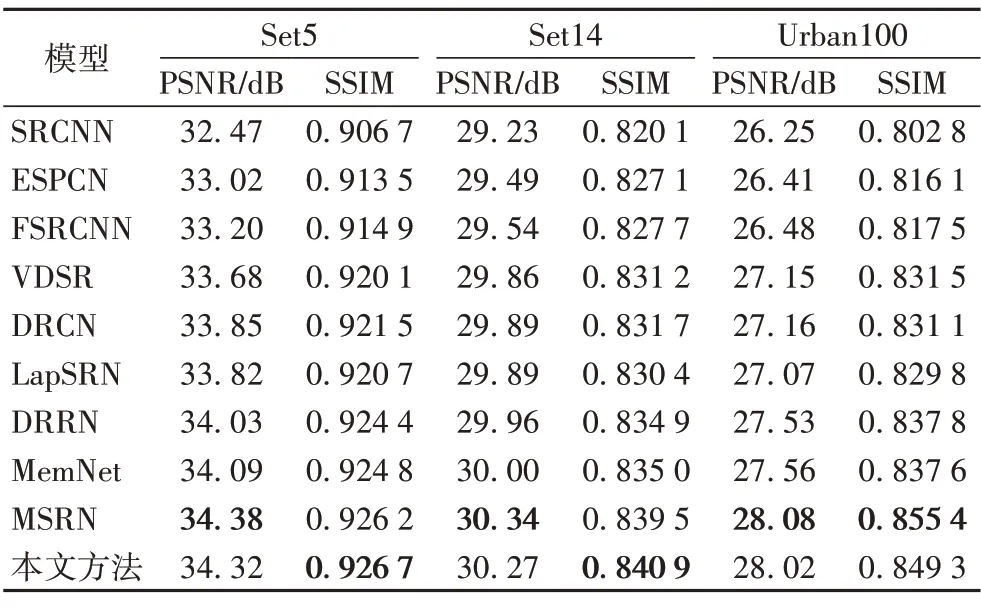
表2 本文方法與其他方法在放大倍數為3時的PSNR/SSIM對比Tab.2 Comparison of PSNR/SSIM between proposed method and other methods at 3 magnification
通過整體分析可以得出,相較于其他方法,本文方法不管在主觀視覺還是客觀評價上,重建效果均有顯著的提升。
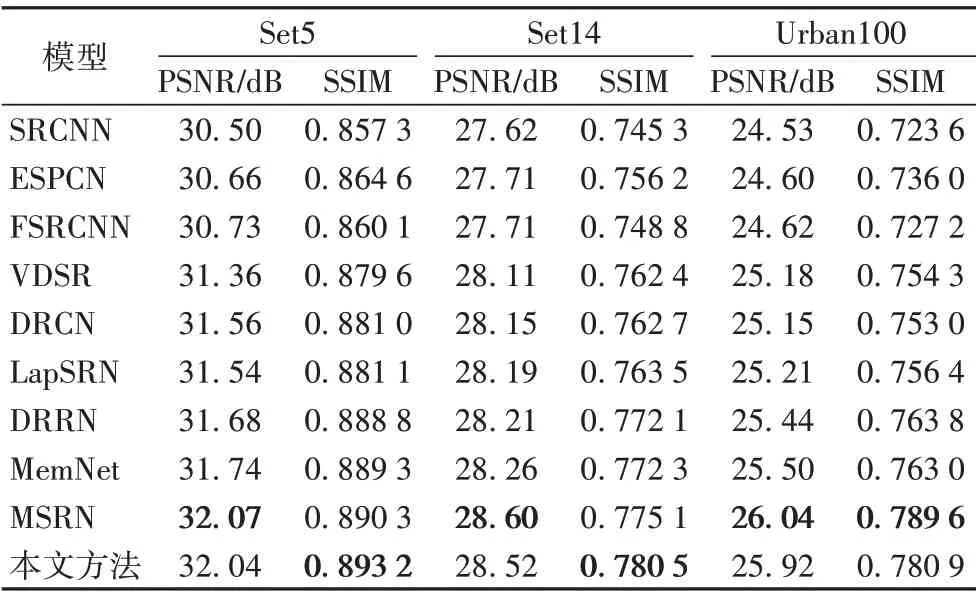
表3 本文方法與其他方法在放大倍數為4時的PSNR/SSIM對比Tab.3 Comparison of PSNR/SSIM between proposed method and other methods at 4 magnification
3.4.2 參數量、平均訓練時間和SSIM的對比
為了驗證本文方法在參數規模和訓練時間上的優越性,將其與SRCNN、ESPCN、FSRCNN、VDSR、DRCN、LapSRN、DRRN、MemNet和MSRN方法進行了比較,如表4所示。
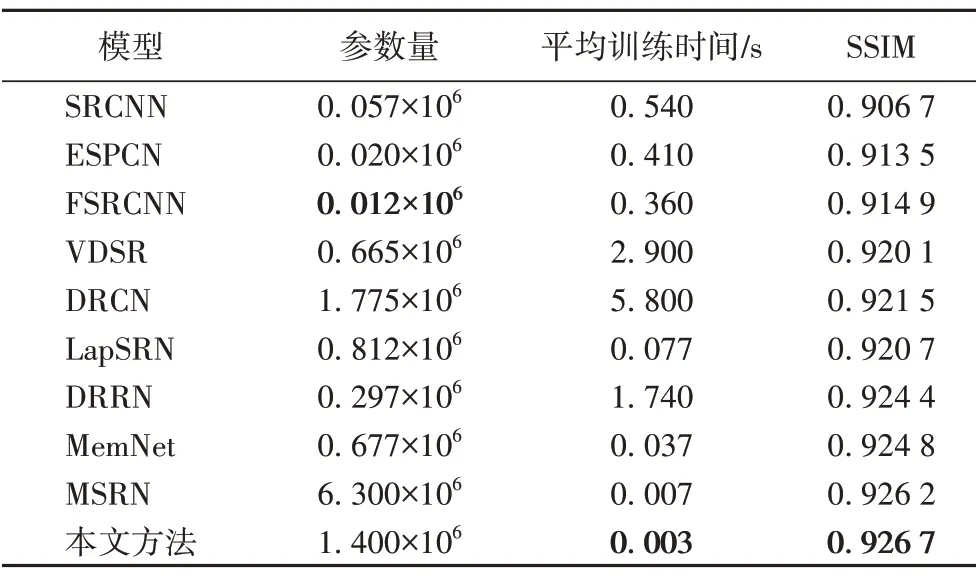
表4 不同方法在參數量、平均訓練時間以及SSIM上的對比Tab.4 Comparison of parameters,average training time and SSIM of different methods
從表4中可以看出,本文方法的平均訓練時間最短,SSIM值最高。本文方法的參數量與MSRN 和DRCN 相比,分別減少了78%和21%,SSIM 分別提升了0.000 5 和0.005 2,主要是因為本文方法采用IRN 結構組建模型,該結構采用稀疏連接的方法。在同樣深度和寬度的情況下,與直接連接3× 3卷積核的結構相比,IRN 可以節省60%的參數量;與采用MSRB作為主要結構的MSRN 相比,單個IRN 的參數量比MSRB 減少68%。與SRCNN、ESPCN、FSRCNN 等方法相比,本文方法雖然參數量略微增加,但重建性能得到大幅提升,主要是因為參數量過少會對重建性能的提升略有影響。
總體來說,本文方法在減少參數量、縮短訓練時間,以及提升重建效果上,均有顯著的提升。同時,文獻[4]證明了模型對資源的占用與參數量呈正相關,而本文方法擁有更少的參數可以證明本文所提出的模型對實驗設備資源的占用少,能夠適應設備資源受限的情況。
4 結語
本文提出了一種基于密集Inception的單圖像超分辨率重建方法。該方法全局融合了簡化的密集網絡,將每一個分層特征提取模塊的輸出用于重建,核心模塊引入了Inception-ResNet 結構,將其應用在圖像超分辨率重建領域。實驗結果表明,本文方法具有較好的重建效果,并且使用了更少的參數,極大提升了模型的訓練速度。但是,由于該方法著重縮減模型參數,對圖像的重建性能稍有影響,下一步將研究在模型參數盡可能少的情況下,提升重建性能。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
