基于灰度域特征增強的行人重識別方法
2022-01-05 02:32:00龔云鵬曾智勇
計算機應用 2021年12期
龔云鵬,曾智勇,葉 鋒
(福建師范大學計算機與網絡空間安全學院,福州 350117)
(?通信作者電子郵箱zzyong@fjnu.edu.cn)
0 引言
視頻分析及圖像偵查技術在安防、智慧城市、民生服務等方面發揮了愈來愈強大的作用。行人重識別(Person Re-Identification,ReID)是對行人進行跨攝像頭檢索,從而判斷圖像或者視頻序列中是否存在特定身份行人的技術[1]。這項任務的挑戰在于不同攝像頭拍攝的圖像往往包含由視角、人體姿態、光線變化、遮擋等變化引起的顯著的類內變化,即同一行人圖像的表觀可能會發生了巨大的變化,使得行人間的類內(同一個行人)的差異可能大于類間(不同行人)差異,因此,尋找更加魯棒的特征與度量方法來有效地解決上述問題,已經成為ReID的主要目標之一。
本文提出的方法通過模擬行人樣本的顏色信息丟失并從數據增強的角度強調樣本的結構信息,促進模型學習到更穩健的特征。灰度圖像可以看作是丟失了一些顏色信息但保留了空間結構的RGB 圖像。在人類認知上,人類通過灰度圖片就可以很好地辨別不同的行人。因此,探究如何充分利用灰度信息,減少顏色信息偏差對ReID 的影響是一個重要的問題。為了探究灰度圖像在ReID 任務中的所能起到的作用,本文設計了如下的灰度貢獻率測試實驗:
通過圖像的灰度變換將可見光RGB 圖像構成的數據集A1 轉換成由灰度圖像構成的數據集A2,然后分別用A1 和A2在同一個基準模型上訓練和測試,并把模型在RGB 數據集和其對應灰度數據集上相應性能評價指標的比值當作灰度信息的貢獻率,如圖1所示。
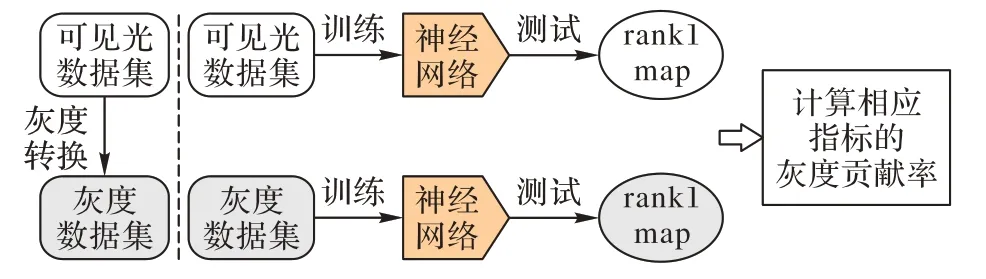
圖1 灰度貢獻率實驗示意圖Fig.1 Schematic diagram of experiment on grayscale contribution rate
表1 則展示了在ReID 三個數據集上測試得到灰度圖像在各數據集上對模型性能的貢獻度,其中:Rank-1、Rank-5、Rank-10表示按相似度排序的查詢結果中第1、5、10個返回結果的平均準確率,mAP 表示平均精度均值(mean Average Precision)。可以看出,灰度圖像對檢索精度的貢獻率占87%以上。值得一提的是,在Rank10 中,灰度圖像對檢索精度的貢獻率高達95%以上。
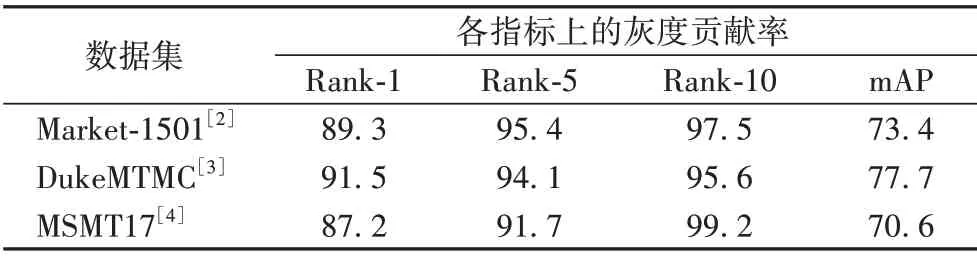
表1 不同數據集上在各評價指標上的灰度貢獻率 單位:%Tab.1 Grayscale contribution rate on each evaluation index on different datasets unit:%
圖2直觀地展示了利用灰度進行數據增強(圖2(a))和利用生成對抗網絡(Generative Adversarial Network,GAN)進行數據增強(圖2(b))這兩種數據增強方式的對比。如圖2(a)中第一行彩色圖像和第二行灰度圖像所示(第一列圖像給出來正常情況下的對比,其余列為具有顏色偏差的情況下的對比),各數據集中普遍存在著行人對比度低的著裝、暗色系和灰色系著裝、行人的移動而引起的圖像模糊或分辨率低、光線變化等引起的顏色偏差等問題,這些因素使得圖片本身會更接近于灰度圖片。由于顏色偏差問題客觀存在且不可避免,即使顏色偏差不是趨向于介于黑白的灰度形式而是看起來整體圖像偏向于某一色調,總體情形也是相似的,因為這種情況下模型在判別過程中所依賴的顏色信息都已經不再可靠,而圖像結構信息就顯得尤為重要。這也直觀地揭示了為什么在評價指標Rank-10 上灰度圖像對檢索精度的貢獻率能夠高達95%以上。這些證據表明灰度圖像的空間結構信息在ReID檢索任務中具有很大的潛力。
如圖2(b)所示,Zheng 等[5]提出的DGNet 利用GAN 為圖像上的每一個行人換上其他行人的衣著,生成了更多樣化的數據來降低顏色變化對模型的影響,有效提升了模型的泛化能力。該結果表明,通過減少模型訓練過程中對顏色信息的過度擬合,可以有效提高模型的泛化能力。實際上,本文提出的局部灰度轉換(Local Grayscale Transformation,LGT)方法通過隨機將RGB 圖像中的某些區域轉換為灰度也可以達到相同的目的。

圖2 兩種數據增強方式對比Fig.2 Comparison of two data augmentation approaches
基于對灰度貢獻率的探索,本文提出了一種有效的數據增強方法來模擬行人圖像顏色信息的丟失來提高特征的魯棒性,所提方法包括全局灰度轉換(Global Grayscale Transformation,GGT)、局部灰度轉換(LGT)以及這兩者的組合。該方法有以下的優點:
1)它是一種輕量級方法,可以在不改變學習策略的情況下與各種卷積神經網絡模型相結合;
2)它是現有數據增強的一種補充方法,當組合其他方法使用時,本文方法可以進一步提高模型識別精度。
本文的主要工作如下:
1)針對ReID 提出了一種有效的數據增強方法,充分利用灰度圖像的結構信息和RGB 圖像的顏色信息,兩者的互相補充有效解決了ReID 訓練過程中顏色偏差所帶來的不良影響,提升了現有模型的性能上限。
2)通過大量實驗和分析驗證了本文方法能有效提升ReID 性能。本文方法可以為ReID 未來的研究提供一個有效增長的方向,并在多個基準和具有代表性的數據集上驗證了所提方法的有效性。
1 相關工作
自深度學習被引入到ReID 領域后,短短幾年間就取得了快速的發展,先后公開的數據集很快就被不斷提出的模型和方法逼近識別精度的上限。諸如的隨機裁剪、隨機翻轉等眾所周知的簡單數據增強技巧在分類、檢測和ReID 領域發揮了重要作用。利用GAN[6]來增加訓練數據也是ReID 研究的一個活躍領域[3,7-8],該類方法能增加訓練數據的多樣性,從而在一定程度上提升模型的泛化能力。此外,最近的研究提出了一些有針對性的方法來從不同的角度幫助模型提高泛化能力。隨機擦除[9]在訓練過程中模擬真實場景中頻繁遇到的遮擋問題,在一定程度上有效解決了識別任務面臨遮擋問題時泛化能力不足的缺陷,成為公認有效的方法。Fan 等[10]發現學習率對ReID 模型的性能有很大的影響,為了取得更好的性能它采用了一種預熱策略來引導網絡盡可能跳出局部最優解。Zhong 等[11]提出的k倒數編碼來對檢索得到的結果進行重新排序以提升模型精度,這一技巧被稱之為re-Rank,同樣是一種公認提升模型性能的方法。Circle Loss[12]從統一的相似度配對優化角度出發,統一了分類學習和樣本對學習兩種基本學習范式下的損失函數,在Market-1501數據集上取得了CVPR2020的最高識別精度。IANet(Interaction-and-Aggregation Network)[13]針對ReID 圖像空間位置不匹配的問題,通過設計空間交互聚合模塊和通道交互聚合模塊實現自適應地確定感受野和增強特征表示,以克服卷積神經網絡難以應對建模人體姿態和尺度的巨大變化這一固有局限。AdaptiveReID[14]通過將可訓練的標量變量作為正則化因子來實現正則化因子的反向傳播進行自適應更新。據我們所知,該方法在MSMT17數據集上取得了目前的最高識別精度。此外,還有其他一些方法[15-19]從空間通道相關性、局部信息匹配、注意力方面來改善模型性能,雖然以上這些方法各不相同,但它們分別從不同的角度和環節提高了ReID 模型的泛化能力。這激勵我們打開思維,從更多的角度尋找方法來解決問題。
2 全局灰度轉換與局部灰度轉換
由于灰度圖像的結構信息對ReID 模型性能有很大影響,為了充分利用灰度結構信息并降低ReID 模型對顏色信息的過度擬合,本文提出了隨機灰度轉換,它包括全局灰度轉換(GGT)、局部灰度轉換(LGT)以及這兩者的組合。通過在訓練數據中以一定的概率將輸入圖像進行隨機灰度轉換讓模型更充分地挖掘灰度信息的潛力以增強模型的泛化能力。本文方法的框架如圖3所示。
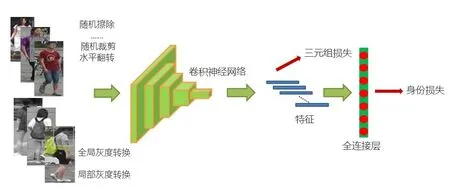
圖3 本文方法框架Fig.3 Framework of the proposed method
2.1 全局灰度轉換
全局灰度轉換在數據加載過程中隨機抽取K個身份,對每個身份抽取m個RGB 樣本圖像來組成一個訓練批組。用集合表示為表示訓練批組的第i個樣本圖像,yi表示樣本圖像的類別標簽。然后以一定的概率隨機將整個批組的訓練圖像進行全局灰度轉換,最后再輸入到模型中進行訓練。對于每個RGB 樣本圖像的灰度轉換可以由如下公式實現:

其中:t(?)是全局灰度圖像轉換函數,通過在原始的可見光RGB 圖像的R、G、B通道上應用灰度變換函數執行逐像素累加計算實現。轉換后的圖像標簽和原來保持一致。用xg表示轉換后得到的灰度樣本圖像,則有如下公式:

2.2 局部灰度轉換
局部灰度轉換在訓練中同樣按一定概率進行。對于原始的RGB 圖像I,假設隨機灰度轉換的概率為p,則保持不變的概率為1-p。該方法在圖像中隨機選擇一個矩形區域,并用其對應的灰度圖像中相同的矩形區域的像素進行替換。其中Sl和Sh為最小和最大的矩形區域的面積比例,通過Sg=Rand(Sl,Sh)×S得到限定在最小和最大比例之間的隨機矩形區域的面積大小Sg。rg是一個系數,用來將得到的隨機矩形寬、高的具體數值以確定矩形的形狀,它被限定在(r1,r2)區間。根據經驗,本文以Sl=0.03,Sh=0.4,r1=0.3,r2=1/r1作為基礎設置。(xg,yg)為隨機得到的該矩形的左上角坐標,如果這個坐標會導致隨機生成的矩形超出圖片范圍,則重新確定矩形的面積、形狀和位置坐標,直到找到了一個符合要求的矩形。最后對原始RGB 圖像中的目標區域使用灰度像素進行替換,由此產生了不同灰度替換區域的訓練圖像。如圖4所示,這個過程中訓練圖像的整體結構沒有遭到破壞,方框指出了灰度轉換的部分。該方法實現了數據的多樣化,并保留了RGB 圖像的空間結構信息。根據上述過程,本文建立局部灰度轉換算法如下:

圖4 局部灰度轉換示意圖Fig.4 Schematic diagram of local grayscale transformation
輸入 RGB 圖像I,圖像的寬W和高H,圖像的面積S,局部灰度轉換概率pr,灰度轉換面積比例范圍(Sl,Sh),形狀比例區間(r1,r2)。
輸出 局部灰度轉換圖像I*。
1)由Rand(r1,r2)得到一個屬于(0,1)區間的隨機數p1,若p1>pr則直接返回原圖像。
2)while True
2.1)通過計算Rand(Sl,Sh)×S得到目標矩形區域的面積大小Sg。
2.2)由Rand(r1,r2)獲得(r1,r2)區間范圍內的一個隨機數rg,并通過計算Sqrt(Sg×rg)和Sqrt(Sg/rg)得到目標矩形區域的寬Wg和高Hg。
2.3)分別由Rand(0,W)和Rand(0,H)隨機得到目標矩形的左上角坐標(xg,yg)。
2.4)如果由目標的左上角坐標(xg,yg)和其寬Wg高Hg構造出來的矩形區域在圖像范圍內,則將可見光圖像上的目標區域替換為灰度;否則重新生成目標區域的寬高和其左上角坐標。
2.5)返回局部灰度轉換圖像。
2.3 損失函數


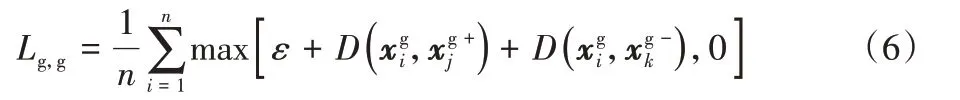
除此之外,xv和xg使用一個共享身份分類器φ進行訓練。使用分類器φ識別,對其身份標簽yi的預測概率表示為。身份損失表示如下:
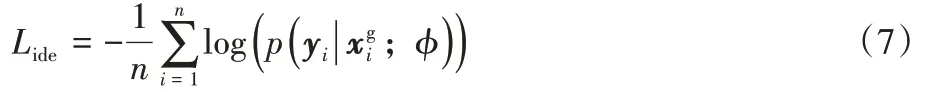
綜上所述,進行隨機灰度轉換時總體損失表示如下:

3 實驗比較與分析
本文在三個基準模型上進行實驗來驗證所提方法的有效性,它們分別是ReID Baseline[20]、Strong Baseline[21](SB)和FastReID[22](FR)。ReID Baseline 和Strong Baseline都基于ResNet-50[23]骨干網絡實現,FastReID 基于IBN-ResNet101[24]骨干網絡實現。
3.1 數據集和評價指標
本文在ReID 的三個具有代表性的數據集上進行對比實驗,它們分別是MTMC17、DukeMTMC和Market-1501數據集。
MSMT17數據集是2018年提出的更接近真實場景的大型數據集,總共包含4 101 個獨立人物,涵蓋了多場景多時段。該數據集共包含15 個攝像頭,其中包含12 個戶外攝像頭和3個室內攝像頭。在一個月里選擇了具有不同天氣條件的4 天進行數據采集,每天采集3 h,涵蓋了早上、中午、下午三個時間段。
DukeMTMC 數據集是一個大規模標記的多目標多攝像機行人跟蹤數據集,于2017 年提出。它提供了一個由8 個同步攝像機記錄的新型大型高清視頻數據集,具有7 000多個單攝像機軌跡和超過2 700多個獨立人物。
Market-1501 數據集于2015 年構建并公開。它包括由6個攝像頭(其中5 個高清攝像頭和1 個低清攝像頭)拍攝到的1 501個行人。
以上數據集是目前開源ReID 數據集中最大的3 個數據集,它們總體包含了多季節、多時段、高清與低清攝像頭,具有豐富的場景和背景以及復雜的光照變化,因此也是最具代表性的。
ReID 最主要的兩個性能指標是首選準確率(Rank-1)和平均準確率(mAP)。其中Rank-1 表示每個查詢圖片對應的第一(最相似)返回結果的平均準確率;mAP 表示返回查詢結果的平均精度均值,查詢中正確的結果越靠前得分就越高。
3.2 超參數設置
訓練過程中有兩個超參數需要確定,其中一個是全局灰度轉換概率pg。取超參數pg分別為0.01、0.03、0.05、0.07、0.1、0.2、0.3、…、1,使用ReID Baseline 基準在Market-1501 數據集上進行實驗,對每個參數取值進行3 次獨立重復實驗取平均值得到的最終結果如圖5。從圖5 中可以看出,當pg=0.05時,模型的性能在評價指標Rank-1和mAP上都一致地取得了最大值,最佳結果在Rank-1 和mAP 上比基準提高了0.7個百分點和1.9 個百分點;在同樣使用reRank(表示對檢索結果使用了重排序技術)的條件,此時Rank-1 和mAP 比基準提高了1.5 個百分點和1.7 個百分點。當pg>0.2 時,模型性能會受到負面影響。
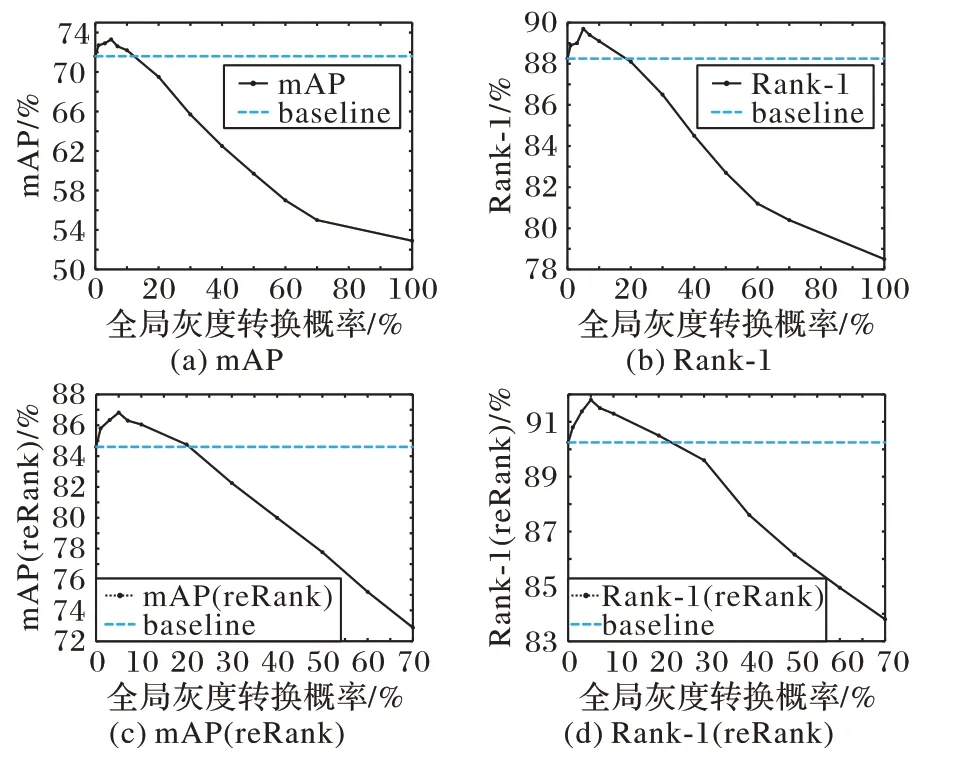
圖5 全局灰度轉換中不同超參數下的模型性能Fig.5 Model performance in global grayscale transformation under different hyper-parameters
另一個需要確定的超參數是局部灰度轉換概率pl,在Market-1501 數據集上進行實驗得到的最終結果如圖6 所示。從圖6中可以看出,當pl=0.4和pl=0.7時模型可以取得較好的性能,而當pl=0.4 時模型的綜合性能最好,最佳結果在Rank-1 和mAP 上比基準提高了1.2 個百分點和3.3 個百分點;在同樣使用reRank 的條件下,此時Rank-1 和mAP 比基準提高了1.5 個百分點和2.1 個百分點。不論pl取何值都不會對模型的性能帶來負面的影響。
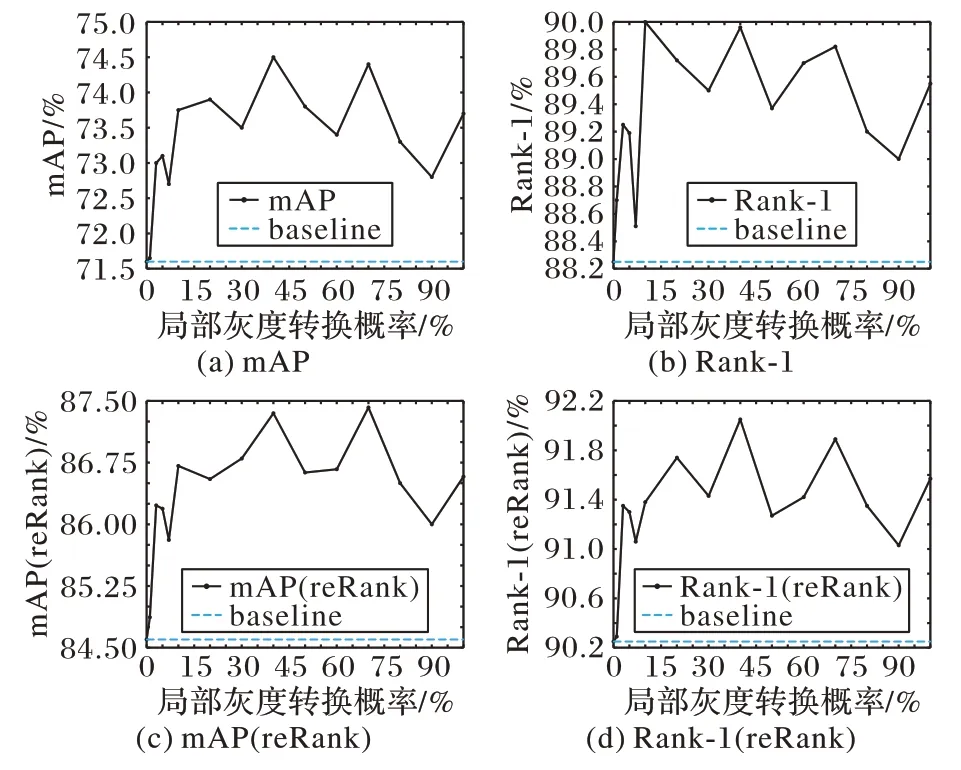
圖6 局部灰度轉換中不同超參數下的模型性能Fig.6 Model performance in local grayscale transformation under different hyper-parameters
3.3 性能比較
局部灰度轉換與全局灰度轉換的最佳結果相比,精度在Rank-1 和mAP 上分別提高了0.5 個百分點和1.4 個百分點;在同樣使用reRank 的條件,mAP 提高了0.4 個百分點。這表明局部灰度替換在不使用reRank時優勢更明顯。然而圖6也表明局部灰度替換所帶來的性能提升不夠穩定,具有比較明顯的波動變化,而全局灰度轉換所帶來的性能提升比較穩定。因此本文通過結合兩者來提升性能表現的穩定性。
在結合使用全局灰度轉換與局部灰度轉換時,由于全局灰度替換的性能表現比較穩定,并且在pg=0.05 時取得最佳性能,因此本文實驗固定全局灰度替換的超參數值為pg=0.05,再確定局部灰度替換的超參數。使用ReID Baseline 基準在Market-1501 數據集上進行兩者的結合實驗,結果如圖7所示。從圖7 可以看出,兩者結合使用后模型性能的提升表現更為穩定且波動更小,并且在局部灰度轉換的超參數取值pl=0.4時,模型的綜合性能表現最佳。因此本文在接下來的實驗中設置超參數為pg=0.05,pl=0.4。
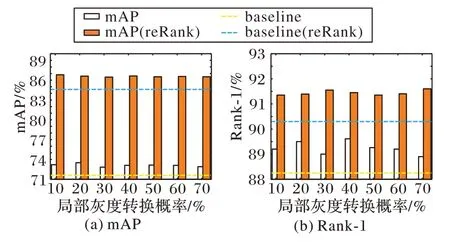
圖7 全局灰度轉換與局部灰度轉換結合的模型性能Fig.7 Model performance with combining global grayscale transformation with local grayscale transformation
本文方法與先進方法在三個數據集上的性能比較如表2~4 所示,其中:+GGT 表示使用全局灰度轉換,+LGT 表示使用局部灰度轉換,+GGT&LGT 表示上述兩者的結合使用;+reRank 表示對檢索結果使用了重排序技術;括號內數值表示相對于原始基準所提升的性能,如表2 的SB+GCT(94.6%)與SB(94.5%)相比,Rank-1提升了0.1個百分點。
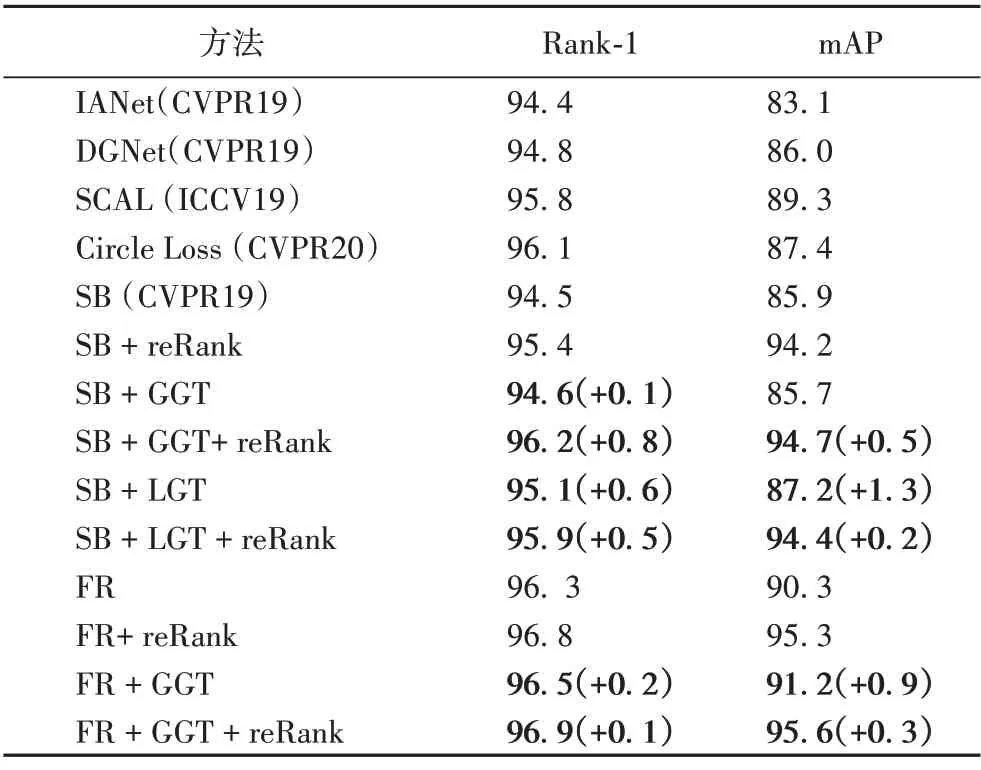
表2 Market-1501數據集上不同方法的性能比較 單位:%Tab.2 Performance comparison of different methods on Market-1501 dataset unit:%
Strong Baseline 和FastReID 這兩個基準訓練時默認使用了隨機翻轉、隨機裁剪、隨機擦除等數據增強方法,本文方法在使用它們的基礎上能進一步提升模型精度,這表明本文的方法可以與其他數據增強方法結合,并且它們是互補的。據筆者所知,FastReID 上應用本文方法在MTMC17 數據集上取得了目前的最高檢索精度。
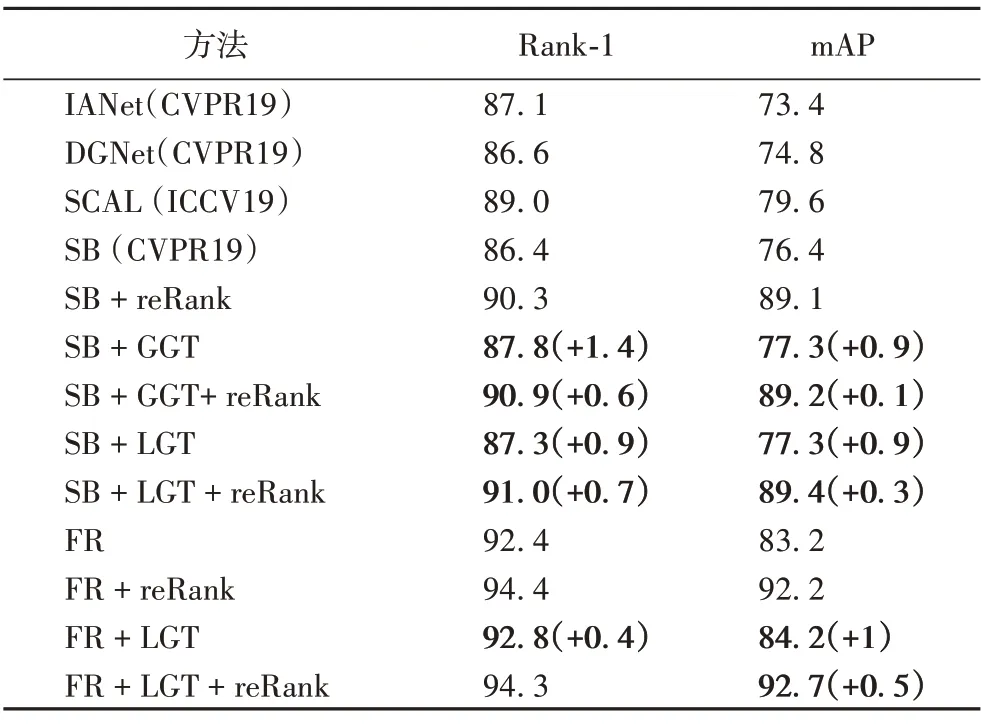
表3 DukeMTMC數據集上不同方法的性能比較 單位:%Tab.3 Performance comparison of different methods on DukeMTMC dataset unit:%
除此之外,Strong Baseline 和FastReID 這兩個基準默認使用Circle Loss 作為損失函數來進行模型訓練,這表明本文的方法可以與該損失函數結合,并且它們是互補的。另外Strong Baseline 的報告表明,Circle Loss 的使用幫助模型性能在Rank-1和mAP 指標上分別提升0.4個百分點和0.2個百分點。從表2 可以看出本文所提出的局部灰度轉換(LGT)所帶來的性能提升更大。
從表2到表4還可以看出,FastReID 明顯優于當前的先進方法,本文方法可以在其基礎上幫助模型顯著提升性能,這驗證了本文方法的有效性和通用性。
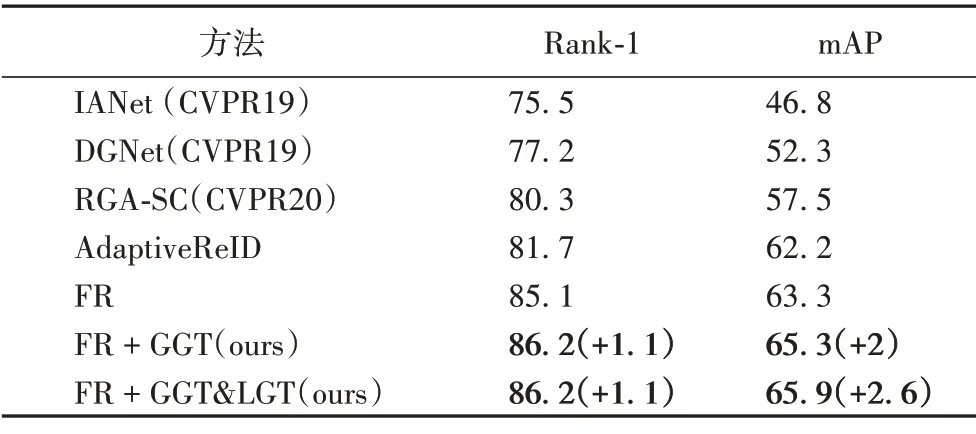
表4 MSMT17數據集上不同方法的性能比較 單位:%Tab.4 Performance comparison of different methods on MSMT17 dataset unit:%
3.4 跨域實驗
一種方法的跨域性能表現可以檢驗該方法是否切實提高了模型所提取特征的魯棒性。為了進一步探究本文方法在跨域實驗中的表現,使用全局灰度轉換在Strong Baseline 上進行以下跨域實驗,結果如表5所示。
在表5 中,本文使用Market-1501 數據集和DukeMTMC 數據集進行跨域性能評估。其中:+REA 表示在模型訓練中使用了隨機擦除的技巧,-REA 表示關閉它;M→D 表示在Market-1501 上訓練模型然后在DukeMTMC 上評估模型;D→M 同理。實驗結果表明,隨機擦除雖能顯著提高ReID 模型的性能,但會造成模型在跨域測試時性能顯著下降,而本文所提的全局灰度轉換(GGT)能顯著提高REID 模型的跨域性能,這表明本文方法有助于增強特征的魯棒性。
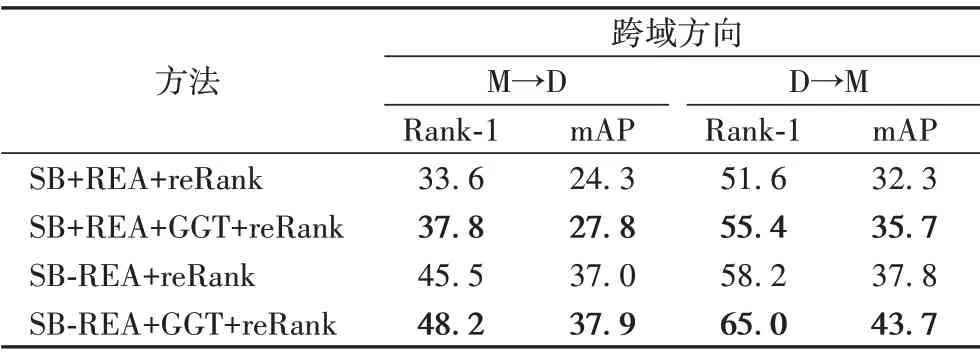
表5 全局灰度轉換與隨機擦除的跨域性能比較 單位:%Tab.5 Cross-domain performance comparison of global grayscale transformation with random erasing unit:%
4 結語
本文提出了一種簡單有效的行人重識別數據增強方法,該方法既不需要像GAN 那樣進行大規模訓練也不會引入噪聲。通過樣本圖像的隨機灰度轉換可以增加訓練樣本的數量和多樣性,并讓圖像的結構信息和顏色信息在模型訓練中相互擬合,從而減少顏色偏差對ReID 的不利影響。本文通過在多個數據集和測試基準上進行實驗,驗證了所提方法的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
