基于LSTM-GRU的污水水質預測模型研究
2022-01-05 08:24:44鄒可可李中原穆小玲李鐵生于福榮
能源與環保 2021年12期
鄒可可,李中原,穆小玲,李鐵生,于福榮
(1.河南省平頂山水文水資源勘測局,河南 平頂山 467000; 2.河南省水文水資源局,河南 鄭州 450003;3.河南省鄭州水文水資源勘測局,河南 鄭州 450006; 4.鄭州大學 化學與分子工程學院,河南 鄭州 450052;5.華北水利水電大學,河南 鄭州 450046)
水質是由水資源內所含物理、化學和生物等多種參數共同定義而成[1]。在用于飲用水、農業、娛樂和工業用水等各種預期用途之前,確定水資源質量至關重要。一般情況下,污水水質預測模型可分為機理式[2]水質預測模型和非機理式[3]水質預測模型。機理式水質預測模型復雜,且普適性較弱,目前國內外普遍采用非機理式水質預測模型,預測水質的長期和短期變化趨勢。常用的方法有時間序列預測法、人工神經網絡預測法、回歸分析預測法、熵值法等。梁中耀等[4]利用時間序列預測法對滇池外海的水質指標的時間序列數據進行遞歸迭代,并對水質趨勢的時、空變化特征進行識別和判定。然而該方法屬于無原因變量的統計預測模型,其特點是數學理論基礎完善,實踐難度較大,誤差較大。袁宏林等[5]運用Levenberg-Marguardt優化算法對學習樣本進行訓練,建立以上游斷面水質監測數據預測下游水質變化的反向傳播(Back Propagation,BP)神經網絡水質預測模型。該方法建立的預測模型的預測精度可以達到令人滿意的程度,但從預測模型中尚不清楚水質變化趨勢的具體原因和內在聯系,從而影響了模型的預測精度。笪英云等[6]提出了一種基于關聯向量機回歸的水質時間序列預測模型,該方法通過對大量數據樣本進行相關分析,得出相關性,并建立回歸方程,在考慮預測誤差的基礎上確定未來水質預測值,然而模型復雜,對數據和樣本的分布要求較高。陳昭[7]應用熵值法改進集對分析模糊評價方法,實現河流水質狀況等級評價。然而該方法容易受到數據不穩定性的影響,從而產生較大的預測誤差。
由于水質參數是一個動態的時間序列,因此更適合使用遞歸神經網絡[8-9](RNN)。另外,水質參數的預測過程是漸進的,即當前水質參數與歷史水質參數相關聯。這就要求RNN能夠動態地記憶歷史水質參數信息,并在學習新信息的同時保留歷史水質參數信息。為此,本文引入了一種改進的長—短記憶網絡結構(LSTM-GRU)來增加RNN的隱層,從而高效學習歷史水質參數信息,使得預測結果更加精確。
1 神經網絡模型
1.1 RNN神經網絡模型
遞歸神經網絡(RNN)通常用于機器視覺和自然語言處理,它具有特征學習能力,能夠從輸入數據中提取高級特征。一維CNN(1D RNN)可用于時間序列數據處理,二維CNN(2D RNN)可用于圖像識別等視覺處理。
1D-RNN的結構如圖1所示,它由輸入層、卷積層、池化層、全連接層和輸出層組成。卷積層通過不同大小的卷積核提取特征,池化層通過壓縮數據來降低信息的維數。為了有效地提取和保留數據特征,卷積層和池層交替出現。全連通層將從不同空間提取的分布特征展平,實現回歸或分類。RNN注重局部特征提取,通過參數共享減少權值,大大減少了網絡的計算參數。
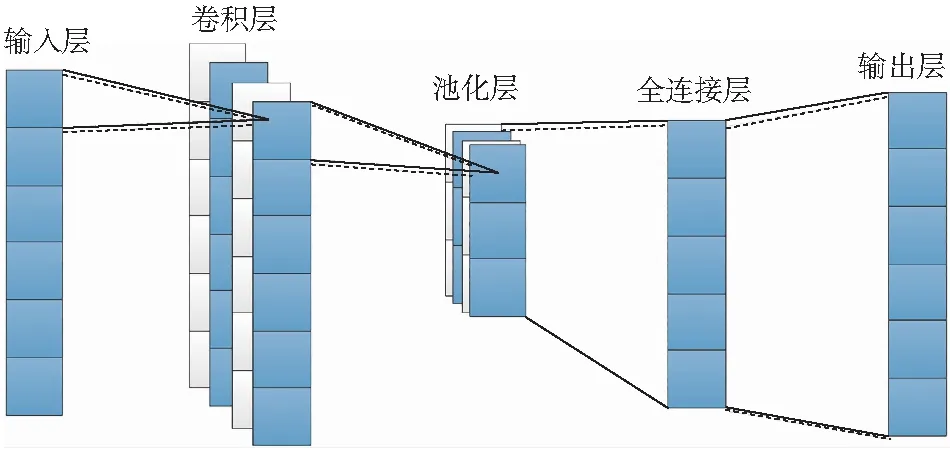
圖1 1D-RNN的結構Fig.1 1D-RNN structure
1.2 GRU和LSTM
門控遞歸單元(GRU)和長短時記憶(LSTM)可以看作是遞歸神經網絡(RNN)的變種,常用于處理序列問題。它們可以解決傳統RNN中的長時記憶和反向傳播算法中的梯度爆炸問題。
GRU和LSTM采用門結構代替標準RNN結構中的隱藏單元,可以選擇性地記憶重要信息而忘記不重要信息。與LSTM相比,GRU用更新門zt和復位門rt代替LSTM的輸入門、遺忘門和輸出門。在GRU的預測精度不低于LSTM的預測精度的前提下,可以減少訓練參數,以獲得更快的收斂速度。傳統RNN和GRU的結構如圖2所示。

圖2 RNN和GRU網絡結構Fig.2 RNN and GRU network structure
復位門rt確定新輸入與先前存儲器的組合,并且更新門zt定義保存到當前時間步長的先前存儲器的數量。zt值越大,從前一時刻到當前時刻的狀態信息就越多。rt值越小,先前時刻的狀態信息被遺忘得越多。
因此,GRU的工作原理可以概括如下:①根據當前時刻的輸入狀態信息xt和前一時刻存儲的隱藏層信息hi-1來計算zt和rt。②使用復位門來確定存儲在節點hi-1中新信息的數量。③通過更新門計算當前時刻的隱藏層輸出。GRU的計算過程如下:
(1)

2 網絡模型設計
2.1 模型框架
LSTM-GRU預測模型的總體框架如圖3所示,包括5個功能模塊:輸入層、隱藏層、輸出層、網絡訓練和網絡預測。輸入層負責對原始河流水質參數內容進行初步處理,以滿足網絡輸入要求。隱藏層使用LSTM-GRU單元構建的網絡,輸出層提供預測結果。網絡訓練采用隨機梯度下降法(SGD)作為優化器,網絡預測采用迭代法。

圖3 預測模型的總體框架Fig.3 Overall framework of forecasting model
2.2 模型訓練參數設置
采用程序自尋優法確定最優參數,需要調整的主要參數是存儲單元數、模型結構和訓練集的時間窗口大小。每例均監測100次錯誤率,該模型的效果波動很小,各參數的誤差率小于5%。當LSTM-GRU模型層數設為3層、訓練集時間窗為460、隱層存儲單元數為20時,效果較好。將每個時間點的數據輸入LSTM-GRU網絡,預測下一個時間點高錳酸鉀指數(COD含量)。然后,將下一個時間點的真實COD含量作為已知的輸入網絡繼續預測,并進行在線滾動。由于模型穩定性高,采用自動優化的方法建立模型無需人工調試。
3 仿真與分析
3.1 數據預處理
河流水質指標包括總磷(P)、總氮(N)、溶解氧(BOD)、氨氮(NH4-NO3)和高錳酸鉀指數(COD),河流水質參數預測的目的是判斷采集水樣的污染等級,為污染防治和水源保護提供依據。由于在水質預測中COD與水污染直接相關,因此選取COD作為反映河流水質參數評價的綜合指標。為了防止由于不同自變量幅值的巨大差異而引起奇異解,對測量數據進行歸一化處理,將輸入變量線性變換成[-1,1],使數據適應sigmoid和tanh激活函數。數據規范化使用以下函數:
(2)
式中,xmin、xmax分別為測得的最小值和最大值;ymin、ymax分別為歸一化處理后最小值和最大值,通常取0.01和0.99。
實測指標值對應的水質分級等級見表1。
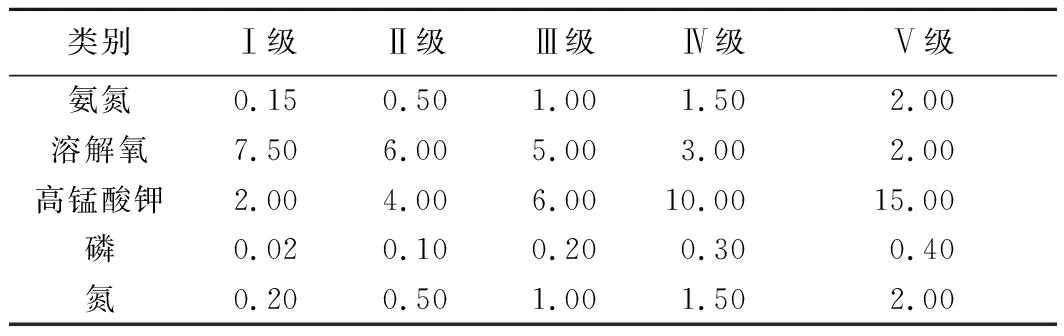
表1 地表水環境質量標準Tab.1 Environmental quality standard of surface water mg/L
選擇LSTM模型和GRU模型作為河流水質參數的對比預測模型,以重慶市某河流COD含量日監測數據中的460組實測數據作為LSTM模型、GRU模型和LSTM-GRU模型的訓練數據集,將其中25組實測數據作為上述3種模型的測試數據集。
3.2 評價指標的選取
為了保證誤差測量結果的有效性,采用均方根誤差(RMSE)和平均絕對百分比誤差(MAPE)作為預測精度的評價標準,RMSE和MAPE值越小,預測結果越準確。計算公式如下:
(3)
(4)
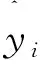
3.3 性能評估
采用LSTM模型、GRU模型和LSTM-GRU模型的指標預測值與真實值對比結果如圖4所示。對3個模型的RMSE和MAPE值分別進行了分析,結果見表2。
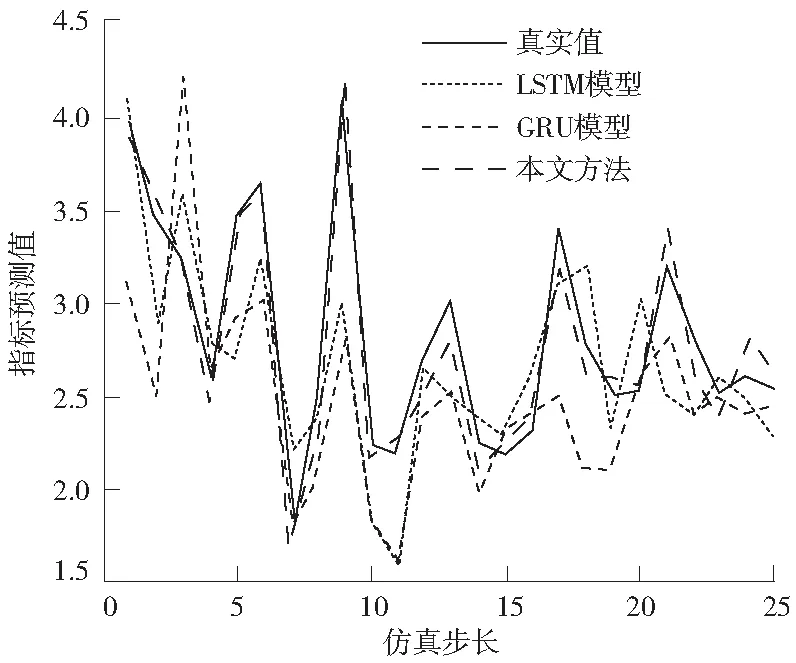
圖4 不同方法預測與真實值對比結果Fig.4 Comparison results between predicted and real values by different methods

表2 不同模型預測結果的性能指標Tab.2 Performance index of prediction results of different models
從圖4可以看出,用LSTM模型和GRU模型預測COD含量偏差值較大,預測效果不理想。采用LSTM-GRU模型預測COD含量,預測值與真實值變化趨勢基本一致,數據跟蹤效果較好,預測精度高,在污水處理預測上比使用單個預測模型的預測精度高、效果好。
由表2可以看出,與LSTM模型和GRU模型相比,LSTM-GRU模型的預測評價指標值均小于傳統水質模型,說明就河流水質參數預測而言,與傳統的水質參數預測模型相比,LSTM-GRU模型的泛化能力更強,預測精度更高。
4 結論
水資源質量檢測對于飲用水、農業、娛樂和工業用水等水資源的管理及保護具有重要作用。然而水質參數的預測過程是一個漸進過程,需要同時考慮當前水質參數與歷史水質參數相關性。為此,本文對遞歸神經網絡中LSTM和GRU模型進行了研究,該技術提高了水質檢測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代水產(2019年1期)2019-05-16 02:42:04
當代水產(2019年3期)2019-05-14 05:42:48
電子制作(2018年14期)2018-08-21 01:38:16
光學精密工程(2016年6期)2016-11-07 09:07:19
水利規劃與設計(2016年7期)2016-02-28 15:06:27
核科學與工程(2015年4期)2015-09-26 11:59:03
