基于深度學習的安全帽監管系統①
2022-01-06 08:04:56王淑琴張文聰鄭京瑞
計算機系統應用 2021年11期
鄭 曉, 王淑琴, 張文聰, 鄭京瑞, 周 游
1(天津師范大學 軟件學院, 天津 300387)
2(天津師范大學 計算機與信息工程學院, 天津 300387)
安全帽能夠有效減少頭部和頂部受到的壓力, 保護人的頭部免受侵害[1], 是不可替代的防護工具.不佩戴安全帽等不安全行為是導致工程現場事故發生的主要原因.因此, 長期以來工人不安全行為管理一直被認為是預防和控制工程現場生產事故的根本途徑[2].由于工程現場范圍較大、工作時間長, 使用人工方法對安全帽的佩戴情況進行監管, 不僅耗費大量人力物力, 而且容易出現漏檢情況.
隨著計算機視覺技術的快速發展, 基于深度學習的目標檢測算法取得了巨大的成功.基于深度學習的目標檢測算法可劃分為兩個類別, 一類是two stage檢測器, 主要包括R-CNN[3], Fast R-CNN[4], Faster R-CNN[5]等, 首先產生多個可能包含待測物體候選框(proposal),再對這些候選框進行位置的修定和目標的分類, 得到最后的檢測結果.另一類是one stage檢測器, 以YOLO系列, SSD[6], RetinaNet[7]為代表, 不產生候選框, 直接在CNN網絡中提取特征完成目標的分類與定位, 整個過程只需要一步, 檢測速度更快.2020年4月, Bochkovskiy等人[8]提出YOLOv4目標檢測算法, 在YOLOv3[9]的基礎上加入了各種可以提升精度的tricks, 速度保持不下降的情況下, 在MS COCO數據集上達到了43.5% AP,實現了精度和速度的最優平衡.
采用基于深度學習的目標檢測方法對安全帽佩戴情況進行檢測已成為趨勢.施輝等人[10]改進YOLOv3目標檢測方法, 使用圖像金字塔結構來獲取多尺度的特征圖, 進行位置和類別的預測, 從而提高安全帽的識別精度; 徐先峰等人[11]使用輕量級網絡 MobileNet替換SSD中的特征提取網絡VGG, 來提高安全帽檢測的速度, 在安全帽檢測模型上進行改進.但潘存瑞等人[12]指出: 工地現場人員組成復雜, 流動性強, 管理難度大, 僅進行安全帽佩戴檢測無法實現對違規人員的管理, 因此一些研究人員開始致力于安全帽佩戴監管系統的研究, 如樊鈺[13]設計的安全帽檢測系統可以對報警區域出現行人未佩戴安全帽進行報警, 但無法進行有效的違規圖片抓取、違規人數統計以及解決重復警告問題, 仍無法滿足當前工程現場的實際需求.
本文設計并開發了一套安全帽智能監管系統.首先根據實際應用場景對安全帽數據集進行了擴充, 對當前主流的目標檢測模型進行實驗對比, 最終選用速度和精度均具優勢的YOLOv4目標檢測模型, 使用K-means算法針對安全帽目標較小的特點對數據集進行聚類分析生成新的先驗框, 并進行訓練得到檢測模型, 提高安全帽的識別精度, 實現對監控中工人是否佩戴安全帽的精確實時檢測, 并在YOLOv4檢測模型的基礎上結合跟蹤模型DeepSORT, 為每個檢測目標標記一個唯一的ID, 有效解決違規人員重復警告和無法進行違規數據統計, 違規圖片抓取的問題; 并結合視頻推拉流,OpenCV圖像處理, ECharts數據可視化等技術, 最終制作成具有安全帽檢測、檢測視頻實時直播、違規人員實時警告、違規圖片抓取并展示、違規數據可視化監測、查看違規歷史圖片等多功能的跨平臺移動APP,可同時兼容IOS和安卓設備, 方便管理人員隨時隨地使用, 真正實現對工程現場工人不佩戴安全帽行為的有效監管.
1 系統功能
系統功能模塊如圖1所示.(1)用戶管理.用戶初次使用系統時, 可以使用個人信息進行注冊, 注冊并登錄成功后方可使用該系統; 若用戶忘記密碼, 可以通過修改找回密碼繼續使用系統.(2)安全帽檢測跟蹤.對監控視頻流中的工人進行安全帽佩戴檢測和跟蹤.(3)狀態管理.用戶可以在APP端實時查看經過安全帽檢測跟蹤后的監控視頻, 若視頻中出現違規人員, 則自動進行違規圖片抓取, 并觸發彈窗警告提醒用戶, 同時可以點擊“歷史違規”按鈕, 查看歷史違規圖片, 將違規數據通過柱狀圖、折線圖等多種格式進行展示, 同時可以下載導出違規數據, 更加方便用戶監管工程現場安全帽佩戴情況.
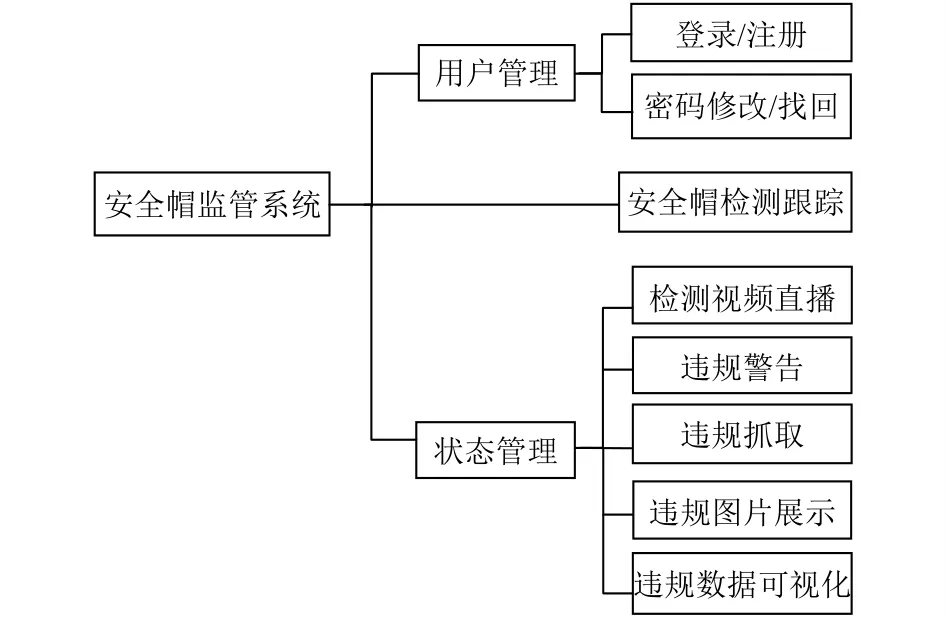
圖1 安全帽監管系統功能模塊圖
2 系統設計與實現
基于深度學習的安全帽監管系統的架構如圖2所示.通過監控攝像頭, 對工程現場監控視頻進行采集,在本地服務器對視頻進行安全帽檢測跟蹤處理, 并將處理中的視頻進行實時推流以及違規數據和圖片發送至云端, 在云端進行大數據的分析、統計和存儲, 最后在跨平臺APP終端進行展示.
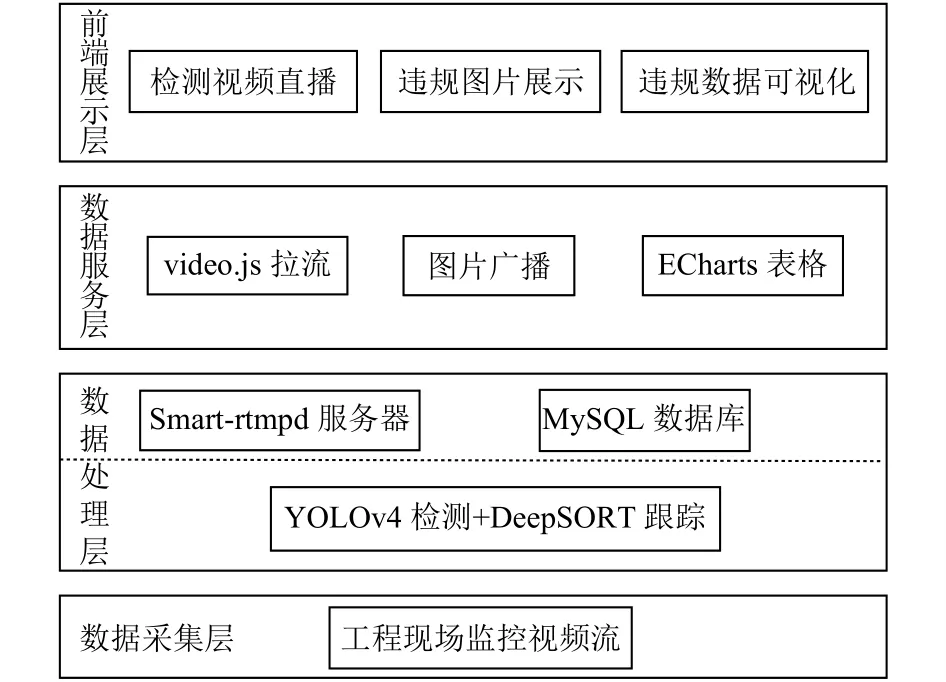
圖2 安全帽監管系統架構圖
2.1 檢測視頻直播模塊設計
借助FFmpeg和本地服務器Nginx可以將視頻數據轉換成視頻流實時上傳至云端服務器, 在客戶端進行拉流展示從而實現直播的效果, 推拉流過程如圖3所示.其中, 推流過程見圖3左側日志, 拉流過程如圖3右側視頻所示.為了在移動APP端實時展示經過安全帽檢測和跟蹤后的監控視頻, 方便管理人員實時查看工程現場的狀況.本系統在視頻推拉流的基礎上, 使用OpenCV函數將監控視頻流截取成一幀一幀的圖片放入隊列中, 調用安全帽檢測跟蹤模型, 再將檢測后的圖片以流的形式經過FFmpeg進行推流.
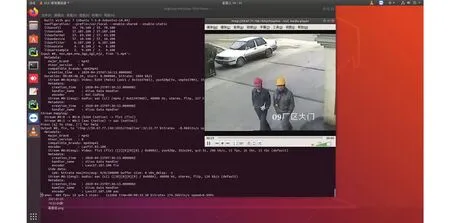
圖3 FFmpeg推流和VLC拉流過程圖
由于手機瀏覽器無Flash插件, 無法直接在移動APP上使用video.js拉取FFmpeg推送的rtmp圖片流, 本系統使用開源Smart-rtmpd服務器將rtmp協議的圖片流轉換成hls協議的m3u8格式圖片流, 最終在移動APP端成功拉流顯示, 從而實現監控視頻的邊檢測邊展示.
2.2 違規數據及圖片抓取模塊設計
對監控視頻中的安全帽進行檢測跟蹤過程中, 使用track.people_id記錄檢測結果為“person”的ID號,track.track_id為當前畫面中檢測到新目標的ID號, 如果track.track_id大于track.people_id并且當前畫面中新目標的標簽class_names[0]為“person”時, 則認為畫面出現新的未佩戴安全帽的工人, 更新記錄違規人數unsafety_count的值, 調用OpenCV函數對當前畫面進行截取, 并連接數據庫將圖片保存至數據庫的違規圖片數據表中并更新數據庫中的違規數據信息.
2.3 數據存儲模塊設計
通過編譯一組完成特定功能的SQL語句完成數據的存儲過程.本系統將數據存儲在云端MySQL數據庫中, 保證系統數據信息的安全.后端采用PHP語言進行數據存取, 完成前后端的交互.存儲數據包括移動APP的用戶信息表app_user_data, 包含用戶名和密碼,手機號以及性別等字段; 違規數據表app_illegal_data,包含未佩戴安全帽的總人數, 以及違規日期等字段; 違規圖片數據表app_illegal_image, 主要包括違規圖片的ID號, 存入時間, 名稱以及存放的路徑等字段.
2.4 違規圖片傳輸模塊設計
用戶使用移動APP時, 應用與服務器建立全雙工通道.當服務器數據庫中違規圖片數據表發生更新時,違規圖片數據表的觸發器會啟動外部PHP函數, 提取對應的圖片數據, 并使用ws.broadcast函數廣播到與服務器相連的多個用戶, 用戶端ws.onmessage函數對接收到的圖片信息進行解析顯示, 從而實現違規圖片在移動APP端的展示.
2.5 違規數據可視化模塊設計
用戶查看違規數據時, 移動APP發送Ajax請求,服務器接收到Ajax請求后, 服務器啟動PHP函數讀取數據庫中的違規數據, 并將數據以JSON格式發送給用戶, 用戶端解析接收到的JSON串, 使用ECharts內部函數將數據添加到對應的ECharts表格函數中生成表格, 并以多種圖形形式展示違規數據分別如圖4和圖5所示, 從而實現違規數據可視化, 使用戶更加方便的分析工程現場近期未佩戴安全帽的數據.
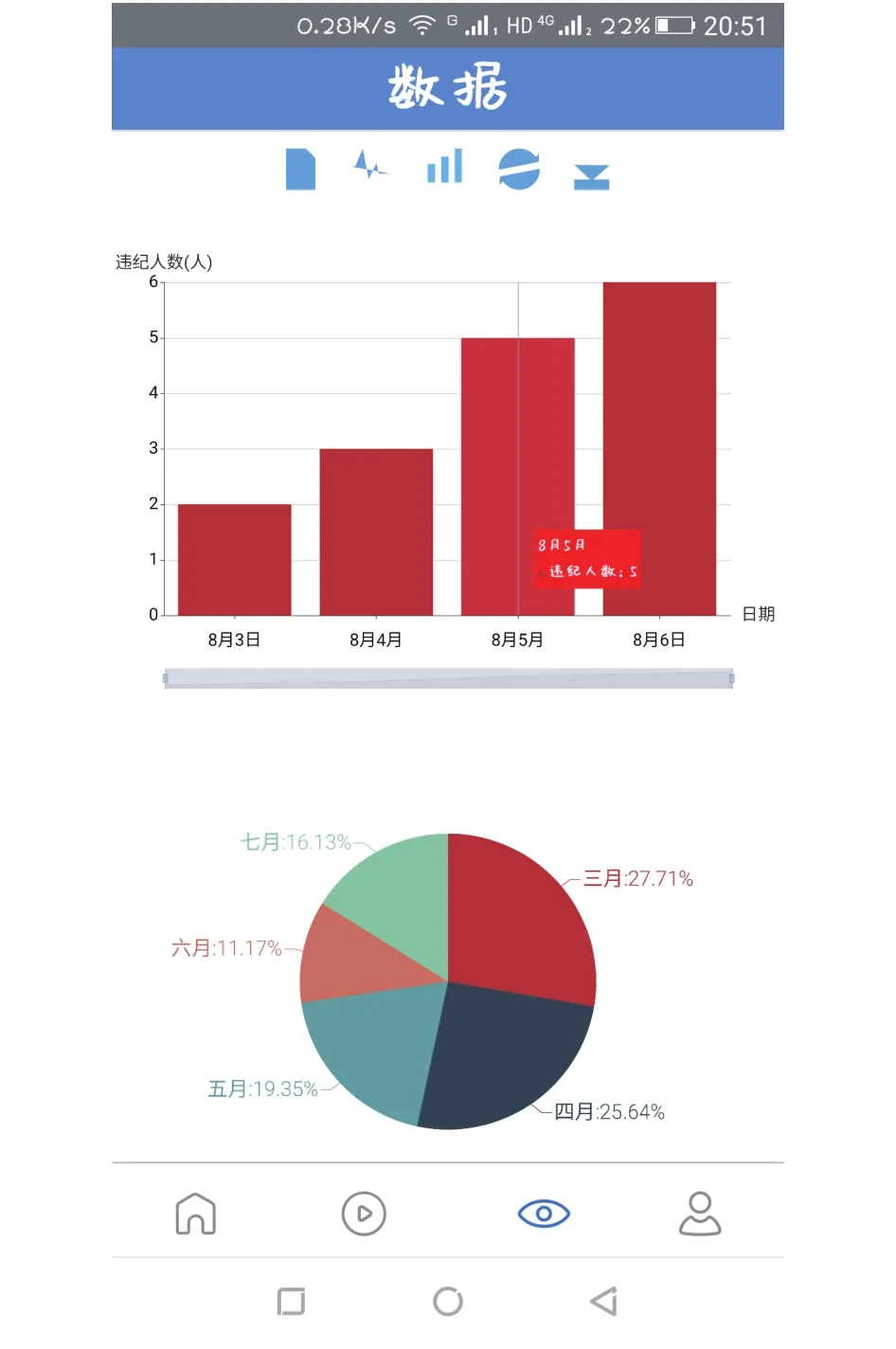
圖4 柱狀圖數據展示
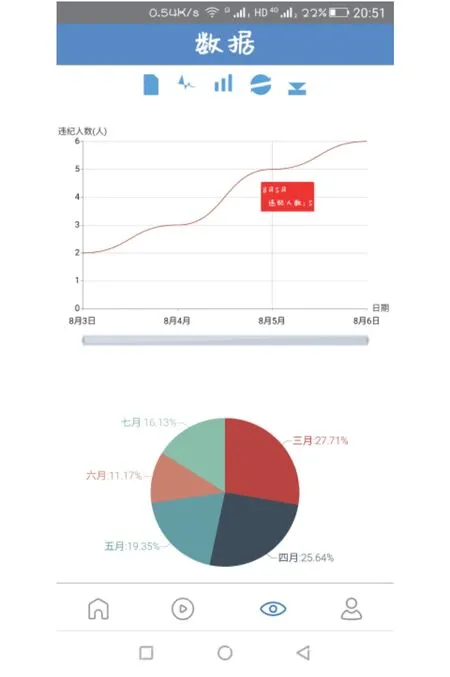
圖5 折線圖數據展示
3 安全帽檢測跟蹤算法
3.1 YOLOv4網絡結構
如圖6所示, YOLOv4使用的主干提取網絡CSPDarknet53是在Darknet53 (YOLOv3主干網絡)的基礎上使用CSPnet結構[14]產生的, 在降低計算復雜度的同時還可以保證準確率.同時為了更好地提取融合特征, YOLOv4引入SPP (空間金字塔池化層)結構和PAN (路徑聚合網絡)結構.其中在SPP模塊中, 使用1×1, 5×5, 9×9, 13×13 的池化核進行最大池化, 使得空間尺寸大小得以保留, 然后將不同尺度的特征圖進行連接作為輸出, 可以更有效的增加主干特征的接收范圍, 顯著的分離上下文特征.PAN結構則借鑒了應用于圖像分割領域的PANet[15], 可以自底向上傳達強定位特征, 進一步提高特征提取的能力.
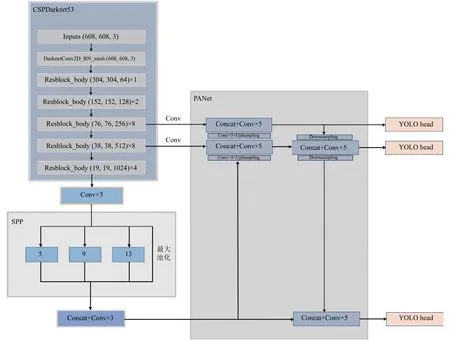
圖6 YOLOv4網絡結構
3.2 數據集的制作和劃分
針對開源安全帽數據集[16]缺乏實際應用場景數據這一問題, 在原數據集的基礎上進行擴充.采集了多個工程現場的監控視頻, 并將視頻中符合場景需要的圖片進行裁剪和截取, 然后使用labelImg進行數據標注如圖7所示.最終選取8805張圖片作為數據集, 并隨機選取其中7924張作為訓練數據集, 881張作為測試數據集.
圖7 安全帽數據集標注
3.3 先驗框的生成
在安全帽數據集上使用K-means算法進行聚類分析, 生成新的先驗框.YOLOv4模型使用的9個先驗框是在VOC數據集上計算得出的, 目標大小差距很大,而安全帽數據集以小目標為主, 原先驗框的尺寸和數據集中目標的尺寸差異較大, 會導致檢測模型的精度不高, 因此使用K-means算法對數據集進行聚類分析,得到9個新的先驗框分別為(7, 15), (9, 19), (11,23),(14, 29), (20, 36), (28, 49), (41, 70), (64, 110), (120, 207).并分別使用原先驗框和新先驗框對YOLOv4檢測模型進行訓練, 對比檢測效果如圖8所示, 檢測圖片中的藍色框為數據集的標注框, 紅色框和綠色框為模型的檢測結果, 其中綠色框為正確檢測的目標框, 反之紅色框則為錯誤檢測的目標框.檢測結果表明, 在安全帽數據集上使用K-means算法進行聚類分析生成新的先驗框, 并進行訓練得到的YOLOv4檢測模型對安全帽的檢測更加精準.

圖8 使用原、新先驗框訓練模型后檢測效果對比
3.4 檢測模型實驗結果對比
為了進一步驗證在YOLOv4模型使用K-means算法生成的新先驗框的有效性, 檢測訓練模型的性能,在相同的實驗環境下分別使用YOLOv3、SSD、Faster R-CNN對數據集進行訓練, 再使用得到的訓練模型進行測試, 實驗結果如圖9所示.使用經過K-means算法聚類分析得到的新先驗框進行訓練的YOLOv4檢測模型比使用原先驗框進行訓練的YOLOv4模型MAP(AP表示單個檢測類別的平均精度, MAP則是多個類別AP的平均值, 即檢測的準確率)提高0.81%, 且高于YOLOv3的85.08%, SSD的77.11%, 以及Faster RCNN的88.66%, FPS (每秒能檢測的幀數, 即模型的檢測速度)高達24, 性能最優, 完全滿足工業需求.
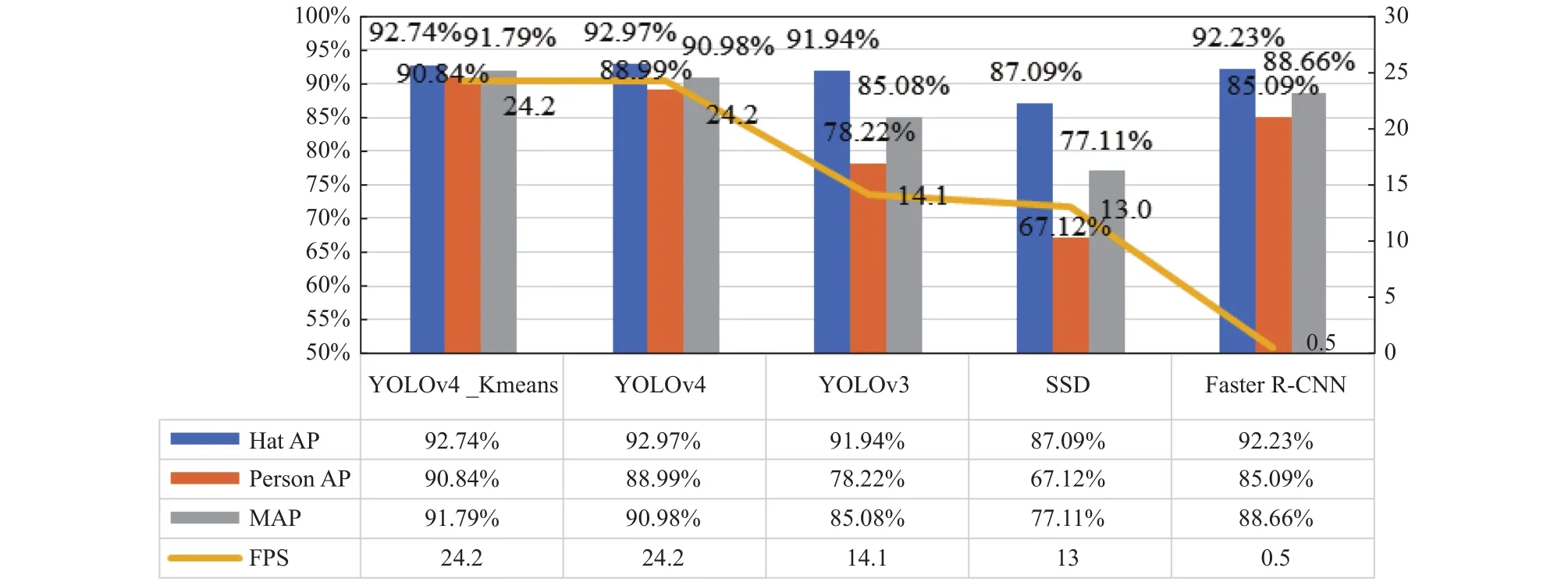
圖9 各模型實驗結果對比
3.5 DeepSORT目標跟蹤算法原理
目標跟蹤SORT算法[17]使用卡爾曼濾波算法預測當前位置, 使用匈牙利算法進行逐幀關聯, 在高幀速率下能夠取得良好的性能, 但是對于物體遮擋情況幾乎沒有處理, 容易導致ID切換.相比于SORT, DeepSORT算法[18]使用了更加可靠的度量來代替關聯度量, 還加入了級聯匹配以解決目標較長時間被遮擋的情況.因此本文采用DeepSORT算法對檢測目標進行跟蹤, 為每個人標記一個唯一的ID, 以避免重復警告, 并能實現對違規人員的正確統計.
(1) 狀態估計
DeepSORT使用一個8 維參數 (u,v,r,h,x˙,y˙,r˙,h˙)來描述目標在某時刻的運動狀態, 前4個參數分別表示目標檢測框的中心點坐標、長寬比、高度, 后4個參數為對應在圖像坐標系上的相對速度, 并使用具有等速運動和線性觀測模型的標準卡爾曼濾波器預測更新運動狀態(u,v,r,h).
DeepSORT使用卡爾曼濾波器預測框和目標檢測框之間的馬氏距離來描述運動信息的關聯程度.計算公式為:
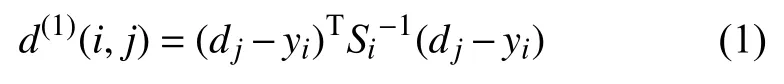
其中,dj表示第j個目標檢測框,yi表示第i個跟蹤器,Si表示檢測框位置和跟蹤器預測位置之間的協方差, 如果計算得到的馬氏距離小于閥值, 則表示運動信息關聯成功.
如果僅使用運動信息進行關聯匹配, 當運動的不確定性較高時容易導致ID切換, 因此DeepSORT引入余弦距離對外觀信息的關聯程度進行度量.計算公式如下:
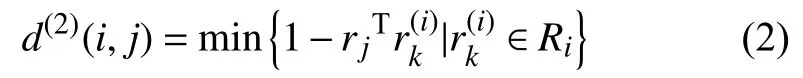
其中,ri為每個目標檢測框dj的特征向量,表示余弦相似度, 1-余弦相似度表示余弦距離.
DeepSORT使用運動信息和外觀信息兩種度量的加權作為最終度量, 計算公式為:
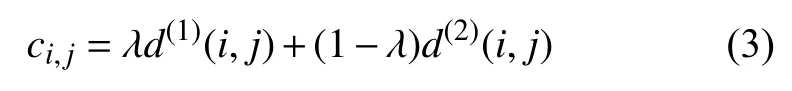
其中, λ是一個超參數, 默認為0.只有同時滿足兩個度量閾值條件時, 才認為第j個目標檢測和第i個目標跟蹤之間實現了正確的關聯.
(2) 級聯匹配
如果一個目標被長時間遮擋, 就會大大增加卡爾曼濾波器預測的不確定性.因此為了讓目標優先匹配消失時間較短的跟蹤器, 首先為每個檢測器分配一個設有time_since_update 參數的跟蹤器, 如果跟蹤器順利完成匹配和更新, 則重置參數為0, 否則對參數進行更新+1.級聯匹配就是根據這個參數進行匹配, 參數小、消失時間較短的跟蹤器優先匹配, 從而讓當前目標匹配上距離當前時刻較近的跟蹤器.級聯匹配能夠保證較近出現的目標具有較大的優先權, 從而有效解決目標被長時間遮擋的情況.
3.6 檢測跟蹤算法處理流程
在YOLOv4目標檢測算法的基礎上, 結合跟蹤算法DeepSORT, 最終實現安全帽的自動檢測跟蹤, 其算法的處理流程如圖10所示, 首先獲取監控視頻流的輸入, 對跟蹤器參數進行初始化; 然后調用YOLOv4算法對當前幀進行安全帽檢測并利用NMS (非極大值抑制)算法對檢測框進行篩選, 以及使用卡爾曼濾波器對上一幀圖片中的目標進行預測, 然而檢測出的目標并不能與上一幀的目標對應起來, 因此需要融合運動信息和外觀信息使用級聯匹配策略進行數據關聯, 并對未匹配的檢測, 未確認狀態和未匹配的跟蹤器進行IOU匹配, 利用最后的匹配結果對跟蹤器和特征集等進行更新, 繼續使用新的跟蹤器對視頻流進行預測, 同時將當前跟蹤結果進行輸出.
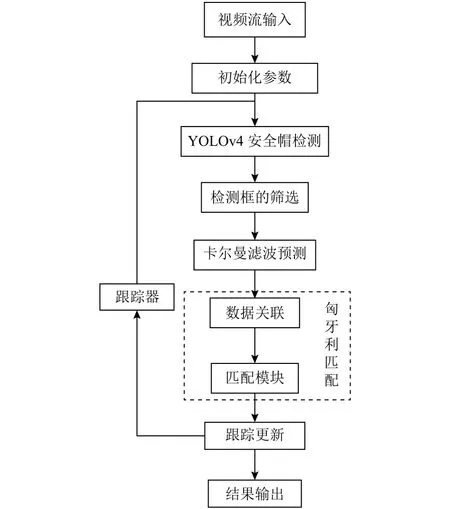
圖10 安全帽檢測跟蹤算法處理流程
3.7 實驗結果
使用上述安全帽檢測跟蹤算法對視頻處理的效果如圖11所示, 左上角顯示當前檢測幀率FPS、當前畫面中目標的個數Current Object Counter和檢測到目標的總個數Total Object Counter.

圖11 安全帽檢測和跟蹤后的處理效果
4 系統部分界面展示
視頻界面如圖12所示, 可以實時展示經過安全帽檢測和跟蹤后的監控視頻, 并且視頻下方可以實時展示抓取的違規圖片, 方便管理人員查看.點擊“查看歷史”按鈕進入違規歷史圖片如圖13所示, 查看歷史違規人員圖片.檢測視頻也可橫屏放大觀看, 當畫面中出現未佩戴安全帽的人員時, 就會觸發警告框進行警告提醒, 如圖14所示.

圖12 檢測視頻直播界面

圖13 違規歷史圖片界面
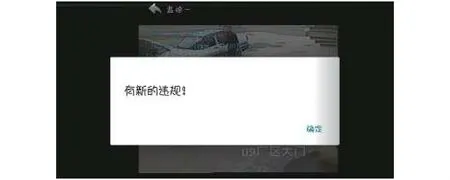
圖14 違規警告界面
5 系統測試
系統測試環境如下:
硬件環境: Windows 10專業版操作系統, 16 GB內存, 1T硬盤, i5處理器, Android 7.0手機, IOS 13手機.
軟件環境: HbuilderX編譯器, 夜神模擬器.
使用HbuilderX編譯器打包安卓和IOS應用安裝包, 并分別安裝在Android 7.0和IOS 13設備上進行測試.在聯網環境下對軟件進行測試, 初次打開應用耗時1-3 s.注冊登錄后各功能使用正常.可實時查看檢測視頻直播畫面并接收實時違規警告, 點擊按鈕可查看違規歷史圖片, 進入違規數據界面可刷新違規數據、查看可視化表格以及導出違規數據.經測試, 系統運行良好, 魯棒性強, 各項功能均符合設計要求.
6 結語
本文介紹了基于深度學習的安全帽智能監管系統,該安全帽監管系統可以準確快速地完成監控視頻中安全帽的檢測和跟蹤, 若有未佩戴安全帽的違規人員出現, 在移動APP端可以實時發送警告信息提醒管理人員, 使管理人員可以盡快對未佩戴安全帽的人員做出提醒和處理, 以有效減少安全事故的發生; 并對違規人員進行有效的圖片抓取, 相對于存儲監控視頻, 只存儲違規圖片, 可以大大節省存儲空間, 并可以作為后期管理人員處理未佩戴安全帽人員的有效證據; 實現違規數據的可視化展示, 可以幫助管理人員了分析工程現場違規數據的變化情況, 為管理人員做出響應的安全決策提供有效依據, 能夠真正實現工程現場的智慧化管理, 具有重要的推廣意義.并希望該系統能進一步推廣至更多工程現場, 協助管理人員保障工人的人身安全, 將發生悲劇的概率降低至零點.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
