基于稀疏幀檢測的交通目標跟蹤①
2022-01-06 08:05:18余宵雨宋煥生梁浩翔王瀅暄
計算機系統應用 2021年11期
余宵雨, 宋煥生, 梁浩翔, 王瀅暄, 云 旭
(長安大學 信息工程學院, 西安 710064)
我國汽車保有量以及公路總里程數逐年快速遞增,為了獲取大量準確的交通信息, 將其作用于交通管理控制系統, 實現交通的快速調度, 判斷甚至預測交通事件, 提高道路運行效率、實現交通管理智能化.因此,加強交通場景視頻的分析技術和分析能力, 提高交通視頻中的信息采集能力是當前智能交通系統建設的當務之急.
對交通視頻中目標車輛進行長時間的跟蹤并對行駛軌跡進行提取分析, 就可以得到靜態和動態的道路交通信息.目前已有的目標跟蹤算法可以分為基于生成式模型方法和基于判別式模型方法[1].其中, 基于生成式模型方法[2]在當前幀對目標區域建模, 在下一幀尋找和模型相似性最強的區域作為目標預測位置, 典型代表算法有: 粒子濾波算法[3]、Meanshift算法[4]和卡爾曼濾波算法[5]等.基于判別式模型方法將目標跟蹤問題看作分類或回歸問題, 用分類器學習將目標從背景中分離, 典型代表算法有: TLD算法[6]、CN算法[7]、DSST算法[8]等.
近年來, 相關濾波算法由于其兼備速度和精度而成為目標跟蹤領域的主流研究方向之一.相關濾波算法屬于判別式模型方法, 其主要思想是在圖像中對每個感興趣目標產生高響應, 對背景則產生低響應.其中,基于最小化平方和誤差(Minimum Output Sum of Squared Error, MOSSE)算法[9]首次將相關濾波應用于目標跟蹤中, 采用灰度特征, 跟蹤速度高達615 fps.CSK[10]在MOSSE的基礎上引入了循環矩陣和核的概念, 這是核相關濾波算法(Kernel Correlation Filter,KCF)的原型, 但它用的是灰度特征, 速度達到320 fps,精度比MOSSE有很大的提升.本文所使用的KCF算法[11]通過嶺回歸計算判別函數, 引入循環移位的方法作近似密集采樣, 引入核方法并加入HOG特征[12], 在保持快速計算的情況下也提高了跟蹤效果.
隨著GPU的出現和卷積神經網絡的不斷發展與突破, 基于深度學習的目標檢測和跟蹤算法興起并蓬勃發展.在目標檢測方向, 2014年, Girshick等人首次將CNN引入到目標檢測中, 提出了R-CNN[13]的目標檢測算法.之后Girshick等人針對R-CNN中存在的問題, 先后提出了Fast R-CNN[14]、Faster R-CNN[15]和Mask R-CNN[16].為了進一步提高目標檢測的速度,2015年, Joseph等人提出了YOLO算法[17], 之后經過YOLOv2[18]、YOLOv2[19]和 YOLOv4[20]的改進, 在目標定位以及小目標的檢測上都取得了很好的檢測效果.在目標跟蹤方面, Bewley等人提出的Sort[21]以及Deep Sort算法[22]旨在提升跟蹤速度.Sort算法使用卡爾曼濾波算法對目標進行預測, 計算IoU度量目標框間的距離, 通過匈牙利算法進行最優關聯匹配.Deep Sort在Sort的基礎上進行改進, 使用Faster R-CNN檢測目標, 仍使用卡爾曼濾波預測, 在距離度量上綜合了馬氏距離和最小余弦距離.
綜上所述, 本文提出利用YOLOv4算法檢測目標車輛.然后, 根據不同的視頻場景條件和項目需求, 選擇不同的跟蹤算法預測下一幀的目標位置, 建立匹配代價表, 關聯目標車輛, 得到交通視頻場景下連續的目標車輛軌跡.最后, 提取得到的車輛軌跡, 利用提出的軌跡分布算法得到車輛分布圖和交通場景俯視圖, 對獲取交通參數提供了真實的數據基礎和更加準確直觀的參考意義.
1 多目標車輛跟蹤框架
1.1 基于YOLOv4的目標檢測
對于交通場景下的多目標跟蹤問題來說, 首先需要得到交通視頻幀中車輛目標的檢測結果, 然后再根據不同的跟蹤算法進行各個檢測框之間的對比和匹配,以此得到交通場景中車輛的跟蹤軌跡.YOLOv4算法是一個快速且高精度的檢測網絡, 因此本文采用YOLOv4算法檢測車輛目標.
YOLO算法是一種端到端的目標檢測算法, 算法的輸入是一張待檢測的圖像, 輸出是輸入圖像中待檢測目標的邊界框坐標、邊界框中包含目標的置信度及邊界框的類別概率.YOLOv4以在檢測方面更為優秀的CSPDarknet53網絡為主干網絡, 利用殘差網絡來進行深層特征的提取, 最終經過多尺寸的特征層得到待檢測目標的類別和位置.YOLOv4的整體框架和YOLOv3是一樣的, 主要是在YOLOv3的基礎上在輸入端、特征提取網絡以及預測模塊等方面進行了改進,提高了算法的檢測精度和處理效率.圖1為YOLOv4在本文實驗場景下的結果示意圖.

圖1 YOLOv4檢測結果
1.2 基于檢測結果的軌跡關聯策略
對于基于視頻的多目標跟蹤問題來說, 在得到交通視頻幀中車輛目標的檢測結果之后, 需要進一步根據不同的跟蹤算法進行當前幀各個檢測框和已有軌跡之間的匹配, 來得到交通場景中車輛的完整跟蹤軌跡.多目標車輛跟蹤主體框架如圖2所示, 具體流程如下:
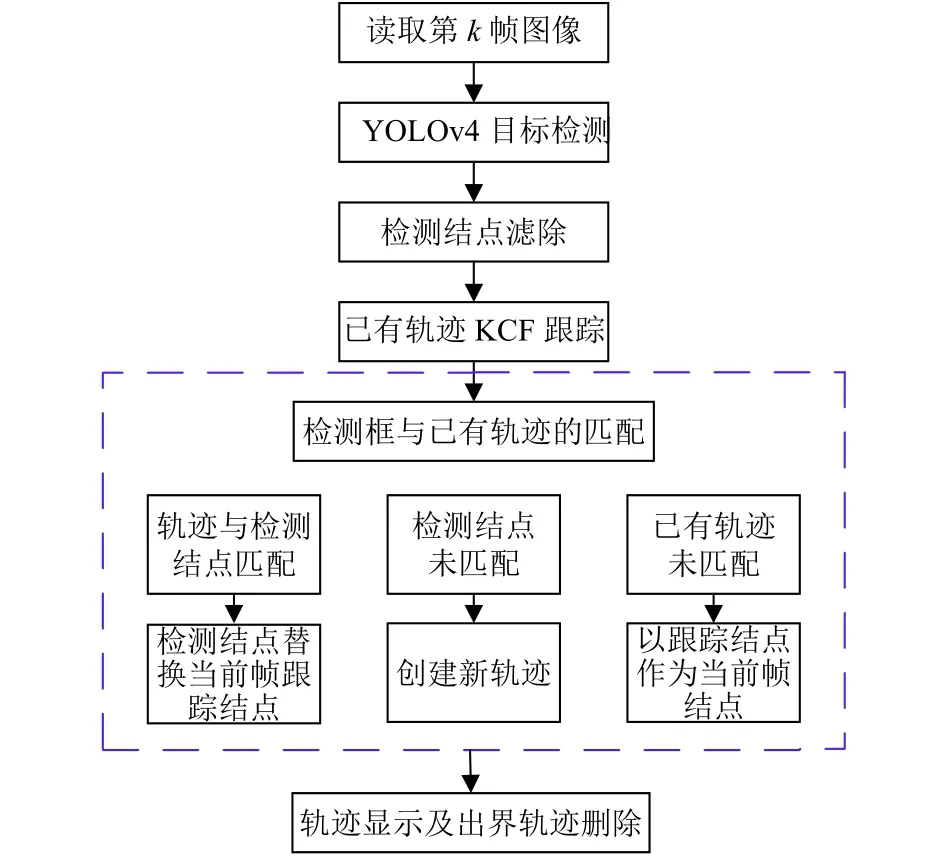
圖2 多目標車輛跟蹤主體框架
(1)使用YOLOv4目標檢測算法, 我們可以得到輸入的每一幀圖像的車輛目標檢測結點集合DecN={DecNi},i=1,2,···,p, 然后根據DecN的重疊率進行檢測結點的濾除, 也就是說認為重疊率大于0.7的檢測結點是同一個目標, 本文只保留其置信度最高的一個結點.將YOLOv4目標檢測網絡輸出的DecN進行濾除之后的檢測結點集合設置為DecN={DecNi},i=1,2,···,q,q≤p.
(2)在第一幀時, 將步驟(1)預處理后的每個檢測框都初始化成一條軌跡; 在其后一幀時, 則對已存在的歷史軌跡都用KCF算法進行預測, 得到車輛目標在當前幀的預測結點.
(3)假設當前在第k幀, 則現在有當前幀的檢測結點集合DecN={DecNi},i=1,2,···,q和已有軌跡集合Tr={Trj},j=1,2,···,w, 對于其中的每一條軌跡Trj={},t=s,s+1,···,k,s表示此條軌跡在第s幀首次出現,表示軌跡j在第t幀的軌跡結點,表示歷史軌跡j進行KCF預測后的預測結點.本文多目標跟蹤框架的核心步驟就是利用預測結點將檢測框與已有軌跡匹配起來.
按式(1)計算q個當前幀檢測結點和w個已有軌跡最后一個結點(也就是k-1幀的結點)的交并比Cij, 以此獲得一個當前幀k的匹配代價表C=(Cij)q×w.
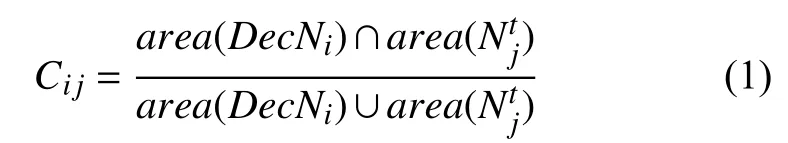
其中,area(·)表示結點的面積.
如果Cij為 行列最大值, 則說明此檢測結點DecNi和已有軌跡Trj的最后一個結點匹配成功.然后在軌跡Trj中刪除最后一個結點,再將檢測結點DecNi添加進去.如果檢測結點DecNi沒有匹配到已有軌跡, 則認為這是一個新出現的目標車輛, 將其初始化成一條新的軌跡Trn={Nj}, 并將Trn加入到軌跡集合Tr中.如果軌跡Trj沒有匹配到檢測結點, 則認為檢測框丟失, 此時將預測結點當做此幀的軌跡結點.在一條軌跡連續25幀的軌跡結點都是經KCF預測得來的情況下,認為此目標車輛已經離開相機視野, 對其軌跡進行刪除操作.
車輛軌跡在視頻幀中的顯示, 僅是對軌跡結點目標框的下底邊中點進行連線操作.
1.3 軌跡預測方法
在1.2節中, 我們以KCF算法為例, 在本文提出的基于檢測結果的軌跡關聯策略中對視頻幀已存在的歷史軌跡都進行預測, 得到車輛目標在當前幀的預測結點, 使用預測結點來關聯歷史軌跡集合和每一幀的檢測結果, 最終達到目標車輛跟蹤的目的.KCF是在2014年提出來的一種鑒別式跟蹤方法, 其利用脊回歸訓練一個回歸器.在新一幀圖像中, 以上一幀圖像的目標位置進行循環移位采樣, 然后利用此回歸器可以得到樣本塊的響應值, 響應值的峰值點所在位置就是目標在新一幀圖像的位置.并將此位置采樣結果作為訓練樣本再去進一步更新回歸器.KCF無論是在跟蹤速度還是在跟蹤效果上的效果都相當不錯, 因此被廣泛應用于實際場景中.
在實驗過程中我們發現, 用KCF跟蹤算法做歷史軌跡的預測其實還存在一定的問題, 比如計算量大, 對高速運動的目標以及遮擋情況嚴重的目標會比較敏感.而高速公路交通場景中, 道路大多為直線型, 其目標車輛的運動也是基本保持勻速狀態的.因此, 我們使用基于稀疏幀檢測的多目標跟蹤方法, 對歷史軌跡集合進行預測, 糾正1.2節中的跟蹤方法.如圖3所示, 可以根據不同的場景以及項目需求, 具體選擇不同的軌跡預測方法.
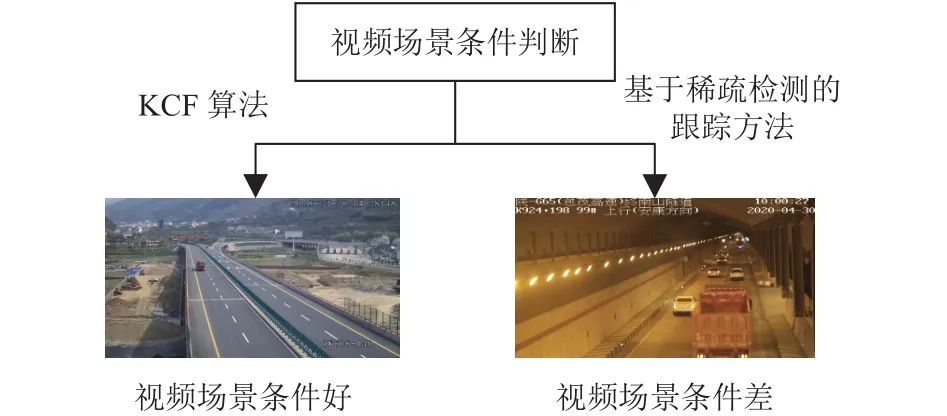
圖3 軌跡預測方法
例如在視頻整體條件比較好(天氣、光照條件等)、遮擋情況不嚴重以及目標運動速度不快的情況下選擇傳統跟蹤方法(KCF算法); 在視頻整體情況比較差、遮擋情況嚴重以及目標運動速度快的情況下選擇本文提出的基于稀疏幀檢測的跟蹤方法.
基于稀疏幀檢測的跟蹤方法流程如圖4所示, 圖4僅使用前幾幀為例來說明具體原理, 后續幀的操作以此類推.
基于稀疏幀檢測的跟蹤方法具體過程如下:
(1)在對視頻幀使用YOLOv4目標檢測算法之后,得到此幀圖像的車輛目標檢測結點集合, 如同1.2的步驟(2), 對檢測結點進行預處理.基于稀疏幀檢測的跟蹤方法本質上是做兩次檢測計算速度, 然后根據速度跳k幀進行跟蹤.本節以跳20幀進行舉例, 因此本算法首先需要用當前幀號對24進行取余, 只選擇余數為1和5的視頻幀進行目標檢測操作.
(2)對第1幀(當前幀號對24取余為1)和第5幀(當前幀號對24取余為5)的檢測結點集做預處理后,如1.2的步驟(3), 對這兩幀的檢測結點集合利用交并比得到一個匹配代價表.將匹配上的結點初始化成軌跡集合tracks_old, 也就是說沒有匹配上的結點就認為目標丟失.并且根據匹配成功的兩幀檢測結點的世界坐標計算每一條軌跡的真實速度v_oldi,i代表tracks_old中第i條軌跡.
(3)具體方法實現如同步驟(2), 但此時操作的是第25幀(當前幀號對24取余為1)和第29幀(當前幀號對24取余為5), 并且此時將匹配上的結點初始化成軌跡集合tracks_new, 根據匹配成功的兩幀檢測結點的世界坐標計算每一條軌跡的真實速度v_newj,j代表tracks_new中第j條軌跡.
(4)此時得到的是tracks_old的每一條軌跡在第5幀的速度v_oldi和tracks_new的每一條軌跡在第29幀的速度v_newj.然后根據軌跡在第5幀結點(tracks_old的每條軌跡末結點)和第29幀結點(tracks_new的每條軌跡末結點)的世界坐標以及速度, 將第5幀軌跡結點的坐標正向推12幀得到(x1i,y1i), 也就是得到其在第17幀的世界坐標, 如圖4中黑色圓點; 將第29幀軌跡結點的坐標反向推12幀得到 (x2j,y2j), 同樣也是得到在第17幀的世界坐標, 如圖4中白色圓點.在理想情況下(x1i,y1i)和(x2j,y2j)是完全相等的.
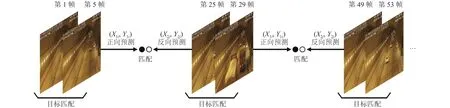
圖4 基于稀疏幀檢測的跟蹤方法流程
(5)計算 (x1i,y1i)和(x2j,y2j)的歐氏距離dij, 建立匹配代價表, 歐氏距離定義如式(2).
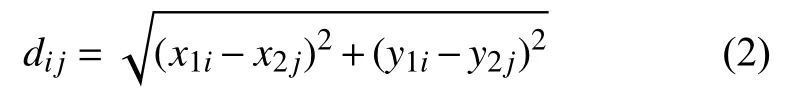
如果dij為行列最小值則說明tracks_old的第i條軌跡和tracks_new的第j條軌跡已匹配, 此時將tracks_new的第j條軌跡結點加入tracks_old的第i條軌跡結點集(也就是軌跡連接).如果tracks_old的某條軌跡未匹配上tracks_new的軌跡, 則認為此目標已出相機視野, 刪除其軌跡.如果tracks_new的某條軌跡未匹配上tracks_old的軌跡, 則認為是新出現的車輛目標,將其軌跡也加入到tracks_old中.
(6)此時我們有tracks_old (保存的是第29幀圖像中的目標軌跡)和第29幀目標的速度, 因此清空tracks_new.再對第49幀(當前幀號對24取余為1)和第53幀(當前幀號對24取余為5)進行檢測框匹配,匹配上的結點將其初始化成軌跡集合tracks_new.繼而使用tracks_new各條軌跡的速度和末結點世界坐標進行反向預測, tracks_old各條軌跡進行前向預測, 如步驟(4); 再如步驟(5), 建立匹配代價表, 進行軌跡連接,出界軌跡進行刪除, 新出現的目標軌跡加入進tracks_old; 最后清空tracks_new.此后滿足步驟(1)中取余條件的各幀也依次進行操作.
基于稀疏幀檢測的跟蹤方法在計算目標的真實速度時所用到的世界坐標, 是相機標定的結果, 由于相機標定并非本文的重點, 因此本文不多加贅述.車輛軌跡的顯示也如1.2節所述, 僅對每條軌跡的結點集合連線即可.
2 交通場景下的多目標跟蹤軌跡分布
在傳統的智能交通系統中, 對視頻幀中的車輛進行檢測和跟蹤之后, 具體檢測框及車輛目標的軌跡顯示都在當前視頻圖像中.但是為了更加直觀的顯示出以車輛為主的交通數據和交通信息, 全面提升交通管理部門的實時監測、整體協調、全面布局能力, 可建立起車輛分布圖以及交通場景俯視圖, 從而為交通部門以及交通運輸業提供一種更智能更直觀的方案.
本節基于單相機的檢測跟蹤系統, 通過視頻監控系統中車輛軌跡的提取, 提出了一種軌跡分布算法, 建立了車輛分布圖及交通場景俯視圖.主體框架如圖5所示.
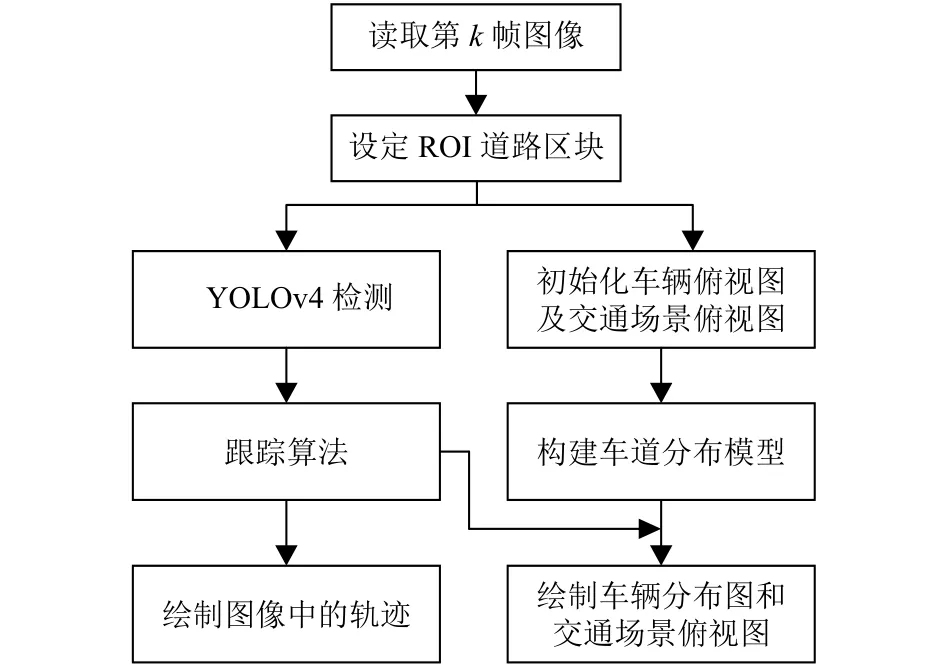
圖5 軌跡分布算法主體框架
交通場景下的目標軌跡分布算法具體步驟如下:
(1)假設當前視頻在第k幀, 雖然對當前幀整幅圖像進行目標檢測, 但軌跡分布算法只需對感興趣區域ROI (Region Of Interest)內的目標車輛進行跟蹤.因此,首先要在圖像中進行道路塊的設定, 也就是需要沿著道路邊緣用鼠標點擊選擇4個點, 得到感興趣區域ROI, 如圖6中道路邊緣的4個綠色圓點.
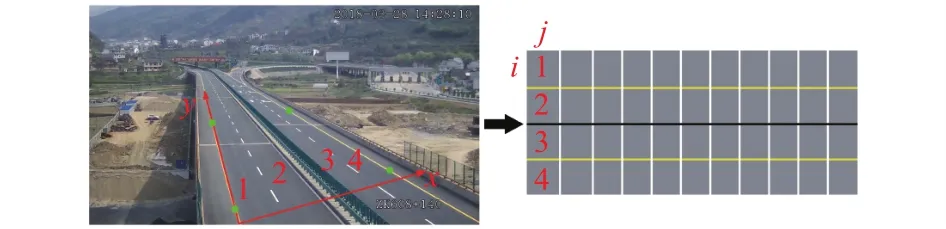
圖6 車輛分布圖模型
(2)在獲取ROI道路區塊后, 在進行檢測跟蹤的同時, 初始化車輛分布圖及交通場景俯視圖.首先清空之前幀的分布圖和俯視圖, 再根據ROI道路塊的大小, 重新設定車輛分布圖和交通場景俯視圖大小.
(3)構建車道分布模型.車輛分布圖以圖6為例,黑色實線表示中央隔離帶; 黃色實線表示車道虛線; 白色實線表示垂直于道路方向的分割線, 把道路分割成15 m寬的道路塊.假設ROI區塊長度為150 m, 則車輛分布圖有15列道路塊.交通場景俯視圖以圖7為例,兩條黑色實線表示中央隔離帶區域, 黃色實線表示車道虛線.圖6和圖7中均用1、2、3、4代表一一對應的車道一、車道二、車道三、車道四, 也就是說, 無論視頻場景以及相機架設位置如何變化, 視頻圖像中ROI道路區塊的左下角點始終對應車輛分布圖和交通場景俯視圖的左上角點.
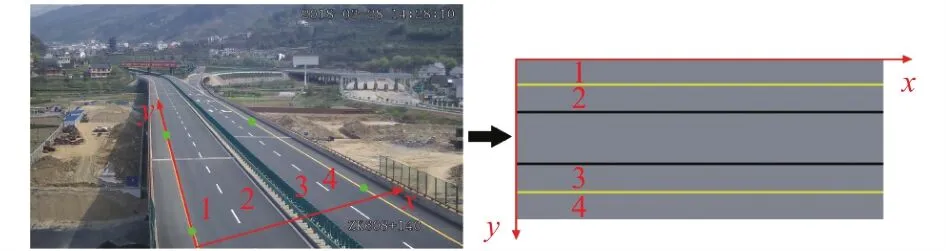
圖7 交通場景俯視圖模型
(4)如圖4所示, 此時第k幀圖像的目標檢測和ROI內目標跟蹤也已完成.得到當前幀在ROI道路區塊內所有目標車輛的跟蹤軌跡集, 此時用每條軌跡末結點的位置, 也就是當前幀檢測結點的位置繪制車輛分布圖; 用軌跡結點集繪制交通場景俯視圖.
1)要繪制車輛分布圖, 首先計算當前每條軌跡末結點距ROI左下角點x軸方向的真實世界距離ΔX, 及距ROI左下角點y軸方向的真實世界距離ΔY.如圖6所示,i為垂直于道路方向的索引,j為沿車道方向的索引, 車輛分布圖左上角道路塊的i和j都為0.i等于ΔX除以單個道路塊真實高度(垂直于道路方向, 根據道路實際情況制定),j等于ΔY除以單個道路塊真實寬度(沿道路方向的15 m);i、j從0開始, 所以向下取整.此時, 車輛分布圖中索引為i、j的道路塊為此幀的車輛位置.
2)繪制交通場景俯視圖, 只需計算出每條軌跡結點在俯視圖圖像坐標系的坐標, 然后進行連線顯示即可.假設當前幀第i條軌跡的第k個結點的圖像坐標為(xik,yik).以圖7為例, 需計算此節點距ROI左下角點的y軸方向的真實世界距離ΔY, 以及此結點距ROI左下角點x軸方向的真實世界距離ΔX.
由于原圖像也就是ROI使用的是相機坐標系, 相機架設位置即原點位置, 則圖7中道路左下角即為坐標系原點.交通場景俯視圖使用圖像坐標系, 圖像左上角為原點位置.所以如式(3)所示, 需計算出ROI區塊的比例系數rateX、rateY(單位: 像素/米).
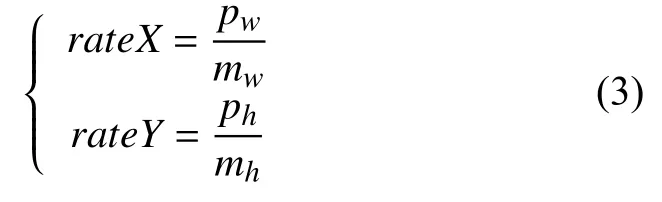
其中,pw、ph表示ROI道路塊的像素寬度和高度;mw、mh表示ROI道路塊的真實世界寬度和高度.
如圖7所示, 圖像坐標系中, 沿道路方向的是x軸;相機坐標系中, 沿道路方向的是y軸.所以結點的圖像坐標xik等于 ΔY和rateY的乘積,yik等 于 ΔX和rateX的乘積.
3 實驗結果分析
3.1 實驗數據設置
本實驗的硬件支持是Intel(R) Core(TM) i7-8700型號的CPU和NVIDIA GTX2080Ti顯卡支持的計算機.本文的車輛目標檢測跟蹤算法及分布算法都使用C++編寫, 運行于Qt 5.10.1平臺, 輔助環境為CUDA v10.0, OpenCV 3.4.0和YOLOv4動態鏈接庫.
本文測試視頻為隧道和高速公路部分路段監控視頻, 充分考慮了視頻場景條件優秀及一般的交通情況,視頻幀率均為25 fps, 每段視頻時長均為30 min.具體實驗場景信息見表1.

表1 實驗測試場景
3.2 目標跟蹤及軌跡分布結果
本文使用YOLOv4目標檢測算法, 檢測3種目標車輛類型, 分別為小車(car)、卡車(truck)和客車(bus), 使用LabelImage完成數據集的標注.如1.3節圖3所示, 對不同的場景, 具體選擇不同的軌跡預測方法.本節設置場景1為高速公路場景(白天), 視頻光線明亮、相機視角高且車輛目標較少、并無明顯遮擋,因此選擇KCF跟蹤算法.場景2為隧道場景, 隧道場景光線較暗、遮擋情況較為嚴重、相機視角低導致車輛目標移動速度也很快, 因此選擇基于稀疏幀檢測的跟蹤方法.車輛目標跟蹤結果、車輛分布圖和交通場景俯視圖結果均如圖8所示.
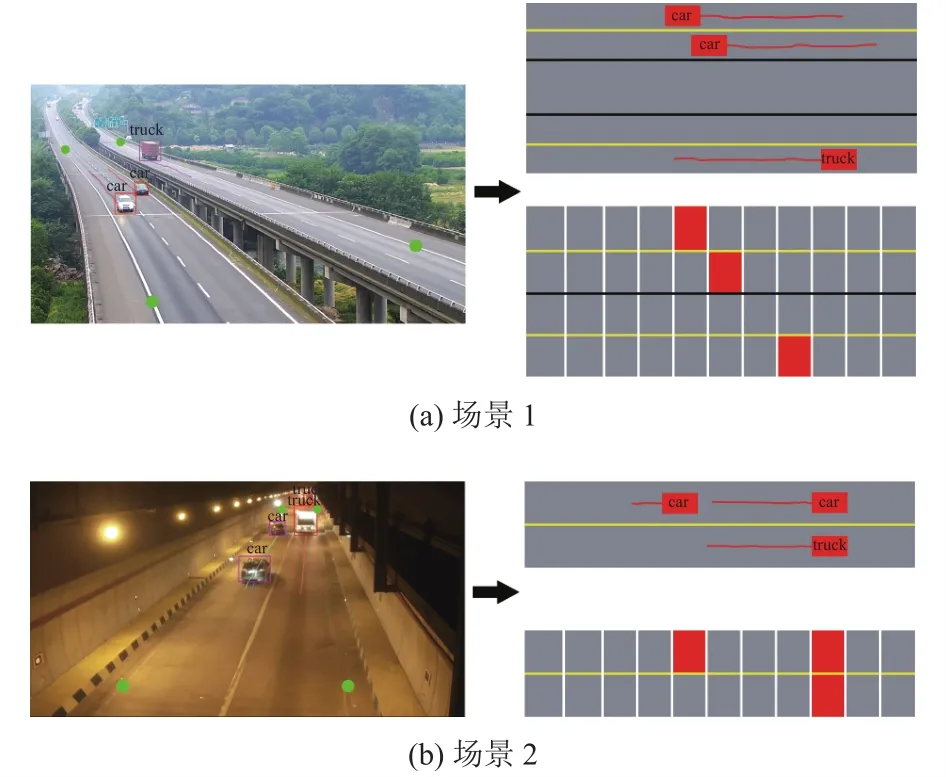
圖8 交通場景目標跟蹤及軌跡分布結果
需注意, 對于不同場景中道路的實際情況, 軌跡分布算法如第2節所示不變, 僅是在構建車道分布模型時根據實際道路情況設置車道線即可.圖像中的綠色圓點表示感興趣區域ROI, 僅對ROI道路區塊內的車輛目標做軌跡跟蹤以及軌跡分布處理.
3.3 跟蹤算法對比
為進一步評價算法的性能, 本實驗使用本文所提出的基于稀疏幀檢測的跟蹤方法和1.2節中結合軌跡關聯策略的KCF跟蹤方法在各種條件視頻場景中進行測試, 并與常用的Sort和Deep Sort兩種算法進行對比實驗.結果如表2、表3、表4所示, 其中表2為各跟蹤算法在場景條件優秀情況下的測試結果, 表3及表4為各跟蹤算法在場景條件一般情況下的測試結果.
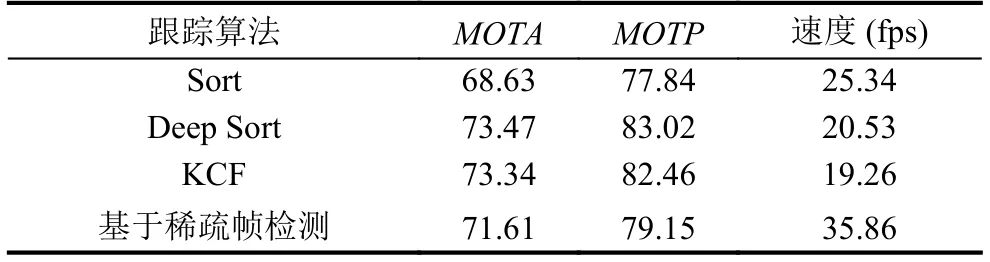
表2 高速公路(白天)場景中各算法測試結果
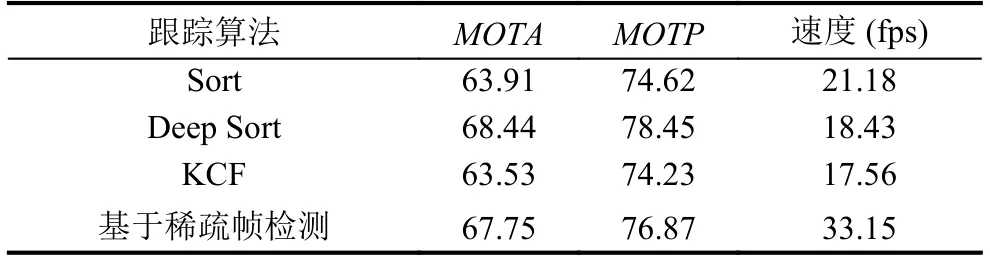
表3 隧道場景中各算法測試結果
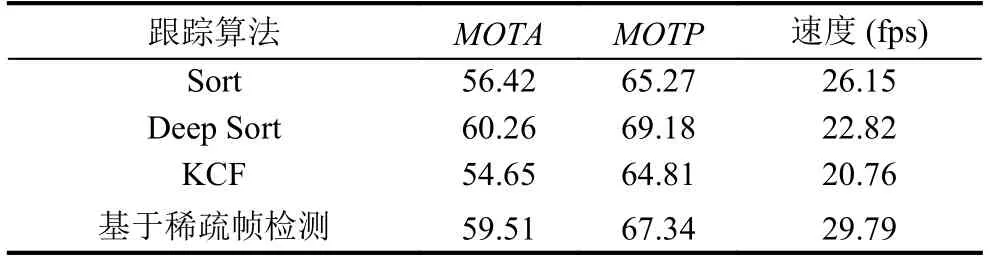
表4 高速公路(夜晚)場景中各算法測試結果
本文使用常見的多目標跟蹤準確度(Multi-Object Tracking Accuracy,MOTA)與多目標跟蹤精確度(Multi-Object Tracking Precision,MOTP)來對各不同跟蹤算法進行評價.定義如下:
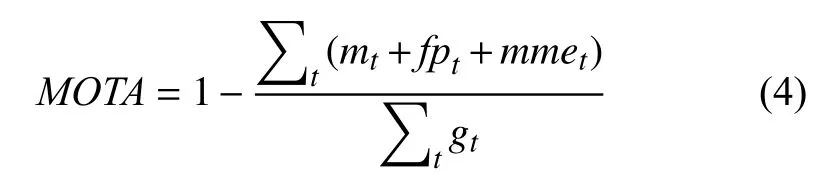
其中,mt,fpt,mmet分別表示在視頻第t幀圖像時漏檢、誤檢以及錯誤關聯匹配的目標數量,gt表示在第t幀圖像真實標注的目標數量.
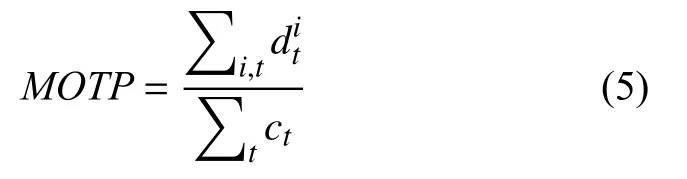
其中,表示第i個目標匹配成功時候的檢測目標框與跟蹤算法預測的目標框的交并比,ct表示在視頻第t幀圖像時成功匹配上的目標數量.
測試結果中的速度指的是檢測加跟蹤的速度, 在實驗中使用視頻總幀數除以總時間的方法計算速度.由于檢測器和跟蹤方法的影響, 若只對稀疏幀進行檢測跟蹤, 速度會大大減少.通過上述評價指標, 可以驗證反映多目標跟蹤方法的綜合性能, 并評估多目標跟蹤方法的穩定性與精度.
在表2、表3及表4中, 由于場景條件及場景復雜度的差別, 為提升跟蹤正確率, 基于稀疏幀檢測的跟蹤方法具體跳幀數量根據場景決定.高速公路(白天)視頻條件較好, 因此選擇跳20幀; 隧道視頻條件較差, 選擇跳10幀; 高速公路(夜晚)視頻光線十分差且車輛遠光燈近光燈影響較為嚴重, 但車輛目標并不密集, 因此選擇跳15幀.
由表2、表3及表4可以得出, 在不同的實驗場景條件下, 本文所提出的基于稀疏幀檢測的跟蹤方法, 與結合目標檢測的KCF+IOU改進方法、Sort和Deep Sort算法進行對比, 本文基于稀疏幀檢測的跟蹤方法以犧牲少量精確度和準確度為代價換來了更優秀的跟蹤實時性, 處理速度大幅度提升.
在本文定義的優秀的場景條件下, 基于稀疏幀檢測的跟蹤方法對比KCF算法和Deep Sort算法, 跟蹤準確度和精確度略有下降, 跟蹤速度大大提升; 本文方法對比Sort算法, 不管是在跟蹤準確度和精確度, 還是在速度方面都有一定程度的提升.在本文定義的一般的場景條件下, 用基于稀疏幀檢測的跟蹤方法對比對比KCF算法和Sort算法, 在跟蹤速度提升的同時, 準確度和精確度也有一定提升; 本文方法對比Deep Sort算法, 跟蹤準確度和精確度略有下降, 速度有明顯提升.因此, 本文在表2、表3和表4中, 將本文算法分別和上述算法進行了比較.從而可根據現實的場景條件以及實驗需求, 平衡跟蹤準確度、跟蹤精確度和速度選擇用何種跟蹤方法進行軌跡預測.
由于跟蹤準確度和精確度在一定程度上依賴于檢測精度.隧道和高速公路(夜晚)視頻由于場景條件限制, 導致車輛目標的特征并不明顯, 因此導致檢測精度有一定的下降.盡管如此, 基于稀疏幀檢測的跟蹤方法在場景條件一般的視頻仍然取得了較為不錯的跟蹤結果, 因此本文所提出的基于稀疏幀檢測的跟蹤方法可以滿足場景條件一般情況下目標車輛的檢測跟蹤, 同時速度也有很大的提升, 則進一步可以將本文算法推廣至多個相機并行處理的情況, 增強了本文算法的實用性.
4 結束語
本文提出了一種交通場景下的多目標車輛跟蹤及實時軌跡分布方法.首先, 對真實場景交通視頻使用YOLOv4目標檢測算法, 獲得車輛目標在每一幀的位置、類別以及置信度, 并對目標檢測框進行濾除.然后根據具體的視頻場景條件以及項目需求進行判斷, 選擇不同的軌跡預測方法把不同幀的檢測框關聯成連續穩定的軌跡.最后提取交通視頻中車輛目標的軌跡, 通過車輛分布圖以及交通場景俯視圖直觀清楚地將顯示出來.本文針對多種視頻場景條件進行實驗, 實驗結果表明, 本文的跟蹤算法在各種交通視頻場景條件下都具有精確的目標跟蹤正確率, 并且速度基本滿足實時處理的需要.綜上所述, 本文對實際交通場景下的車輛目標檢測跟蹤具有重要參考意義.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
