多波束漁用聲吶波束成形算法設計與FPGA實現
2022-01-06 02:19:10王志俊李國棟
漁業現代化 2021年6期
關鍵詞:信號
程 婧,王志俊,李國棟,魏 珂
(中國水產科學研究院漁業機械儀器研究所,上海 200092)
漁用聲吶作為在漁業領域利用聲波對水下魚群進行探測的重要助魚儀器[1],近幾十年來,在海洋捕撈漁業中發揮重要作用[2]。漁用聲吶從利用聲波波束的角度可分為單波束[3]、分裂波束[4]、多波束等多種方式[5],其中多波束漁用聲吶通過多個換能器陣子協同工作,可在較短的時間內進行掃海,相較于單波束可以更加準確地探測較大范圍內的魚群距離和方位[6-7],主要在中大型圍網和拖網捕撈漁船上使用[8],提高了捕撈效率[9-11]。
波束成形作為多波束聲吶的一項核心技術,是一種抗噪聲和混響干擾的主要方法[12],其實現性能決定了聲吶探測距離和空間分辨能力[13]。相位補償的波束成形方法資源占用少且運算速度較快,在窄帶波束成形中有較多使用。相較于窄帶技術,寬帶技術由于具有更好的抗混響和距離分辨能力[14]被廣泛應用在漁業探測中[15-17],然而因其相位的實時變化,相位補償的方法將不再適用。常用的寬帶波束成形方法有時移法、頻域變換法[18]和移邊帶波束成形法(SSB)等,其中時移法主要使用延時濾波器組對寬帶信號中不同頻率的信號幅度與相位加權[19],其精度受采樣周期的制約;頻域變換法是先將寬帶信號變換到頻域,然后將多個頻率分量,對不同頻點的信號采用窄帶波束成形進行波束合成,最后再變換到時域上[20],其波束成形精度受頻點精細度的影響,精細度越高運算量越大[12];SSB算法采用下變頻的方法,將較高的載頻信號先搬移到較低頻率然后進行相位和時間補償,避免了采樣率的限制,可在較低的采樣率下達到較高精度,然而由于其相位和時間補償過程采用并行運算,參與波束成形的陣子數越多,運算量和硬件資源占用量越大[21],制約了其在漁船這類對空間和能耗要求較嚴苛的搭載儀器上的使用。
本研究根據現有硬件的資源和運算能力[22-23],提出一種基于分布式的全方位漁用聲吶多波束掃海方式,并對SSB算法進行改進,采用串行處理代替原有算法的大量并行運算,并結合FPGA的特性[24-25]采用時分復用設計,實現了在未降低算法性能的同時,大量節省片上資源,并提高了信號處理速度。
1 圓柱陣多波束漁用聲吶全向掃海方式
多波束探魚儀工作時,采用旋轉定向掃描發射,即在某一時刻一個扇區內同時發射多個波束,然后在下一時刻水平旋轉至下一扇區繼續發射多個波束,以便保證各個方位都可以被波束覆蓋到。對于多波束探魚儀的接收部分采用多個陣子同步接收,并對回波進行信號處理。
接收波束成形中的關鍵環節是對各個陣子接收相位延時進行精準的控制與計算[26-27],使得回波波束的聚焦點小,指向性好從而獲得更加清晰的圖像。
由于圓柱陣換能器的陣子較多,單板無法對信號進行處理,因此為了提高波束成形的運算速度,采用分布式跨板間計算。所用換能器基陣采用8塊多通道接收機構成,每塊多通道接收機由32個陣子組成,共計256個陣子組成所需圓柱陣。
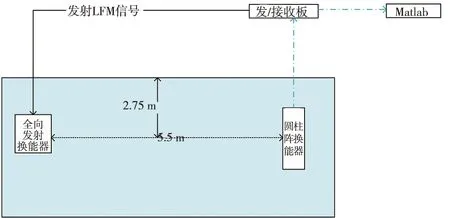
如圖1、2所示為每塊多通道接收機中的陣子排列方式:水平方向上共4列換能器,每列由8個陣子組成,相鄰兩列陣子與坐標系中心連線的夾角為11.25°,每個多通道接收機可以分別與其左側和右側的多通道接收機組成對應虛擬扇區。該探魚儀在垂直方向上兩個陣子之間的間距為0.042 m,單個陣子的半徑為0.185 m,指向性開角約為78°,圓柱陣周長為1.18 m。每個扇區可以完成20個波束,從-21.375°至21.375°,波束間隔為2.25°。單個多通道接收機參與40個波束,前20個波束與其右側的多通道接收機一起完成,后20個波束與其左側多通道接收機一起完成。

圖1 扇區劃分Fig.1 Sector division
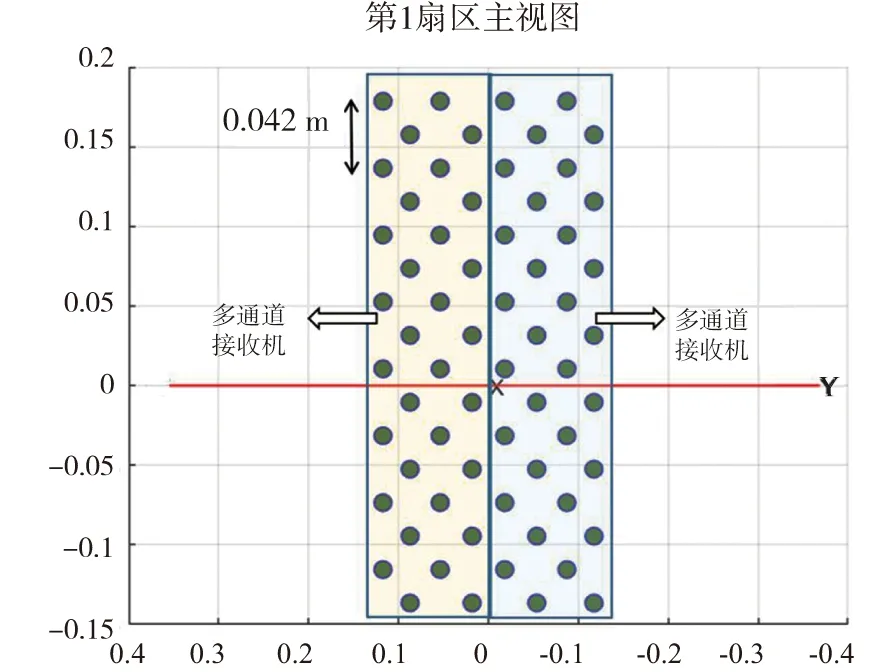
圖2 第一扇區Fig.2 First sector
2 波束成形算法改進
2.1 傳統移邊帶波束成形算法
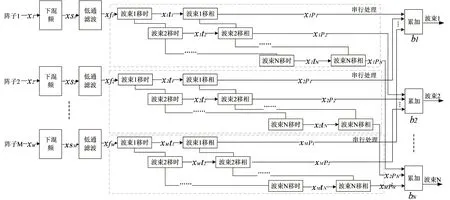
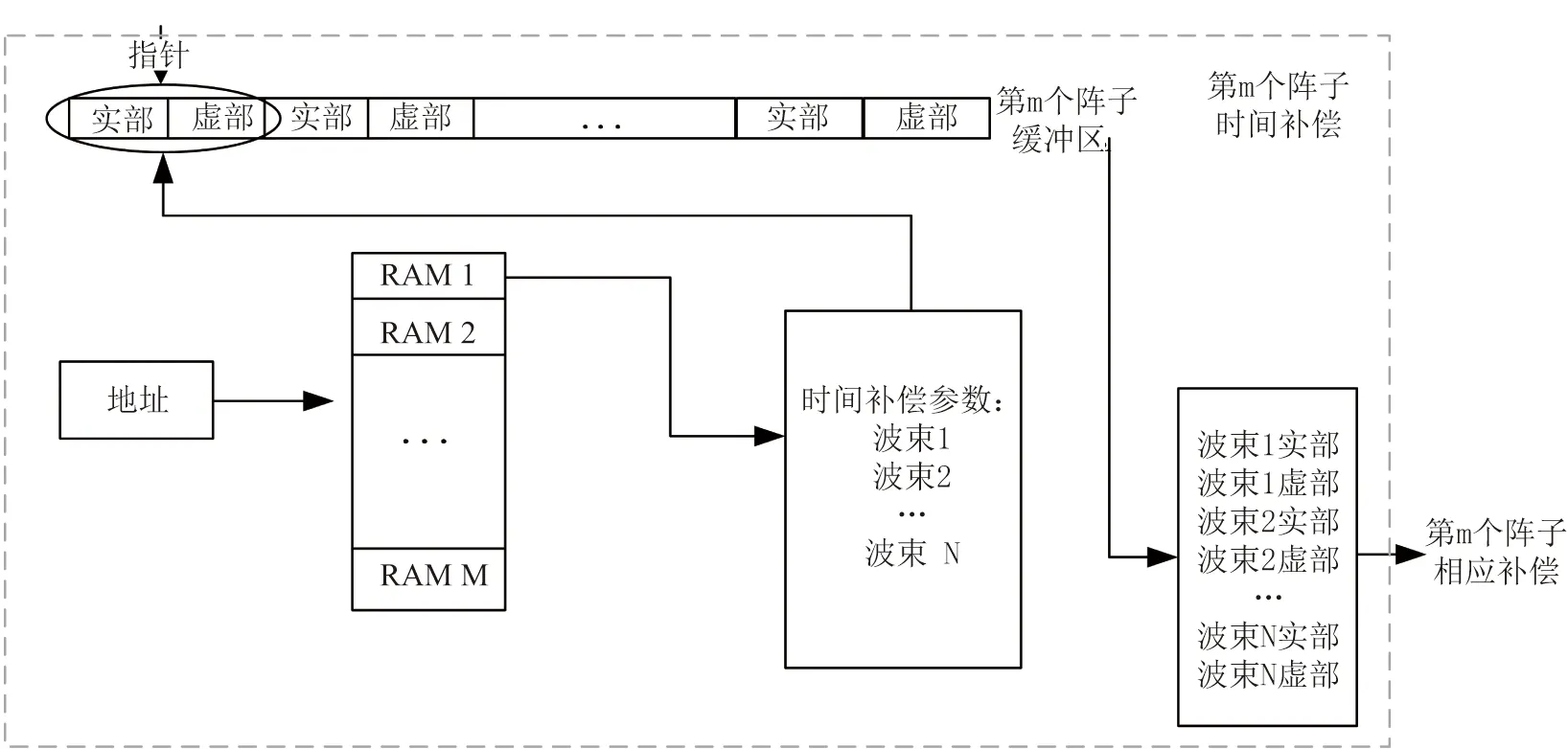
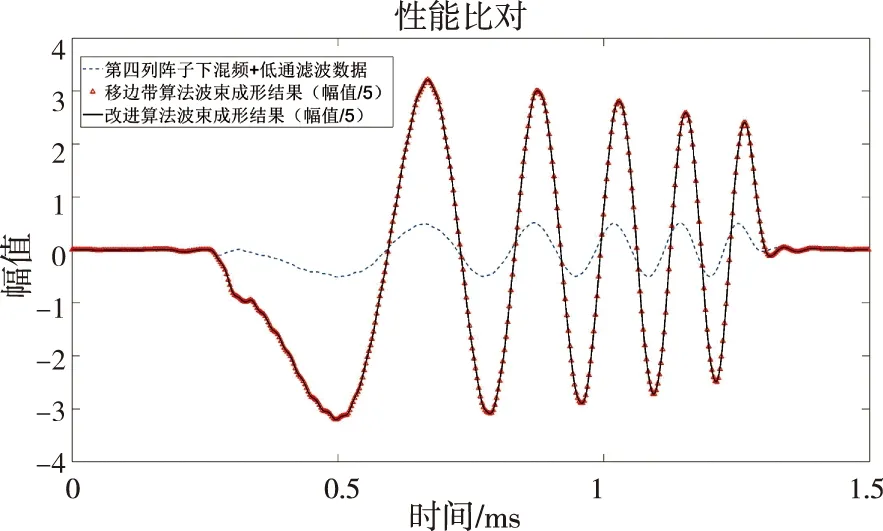
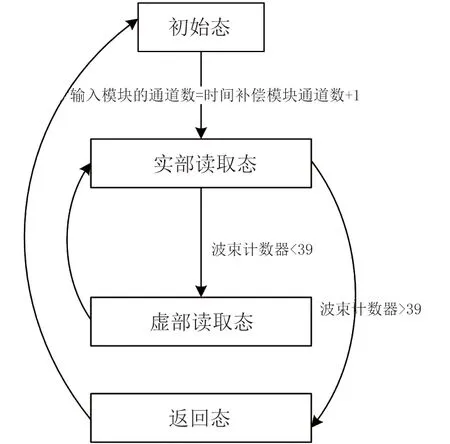
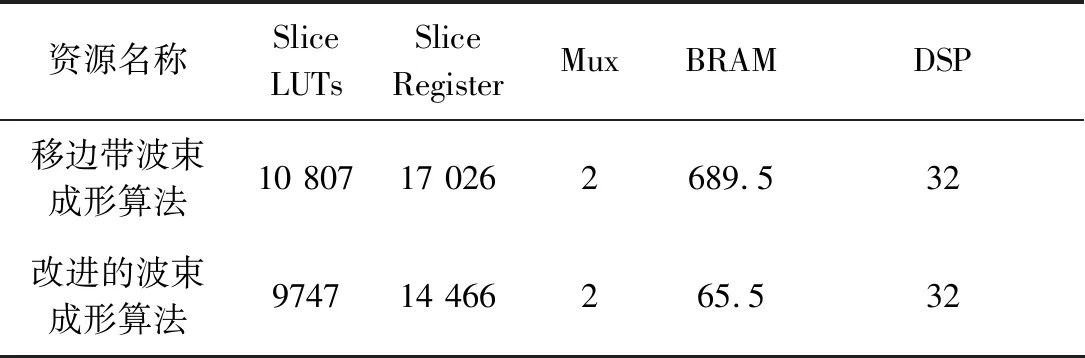
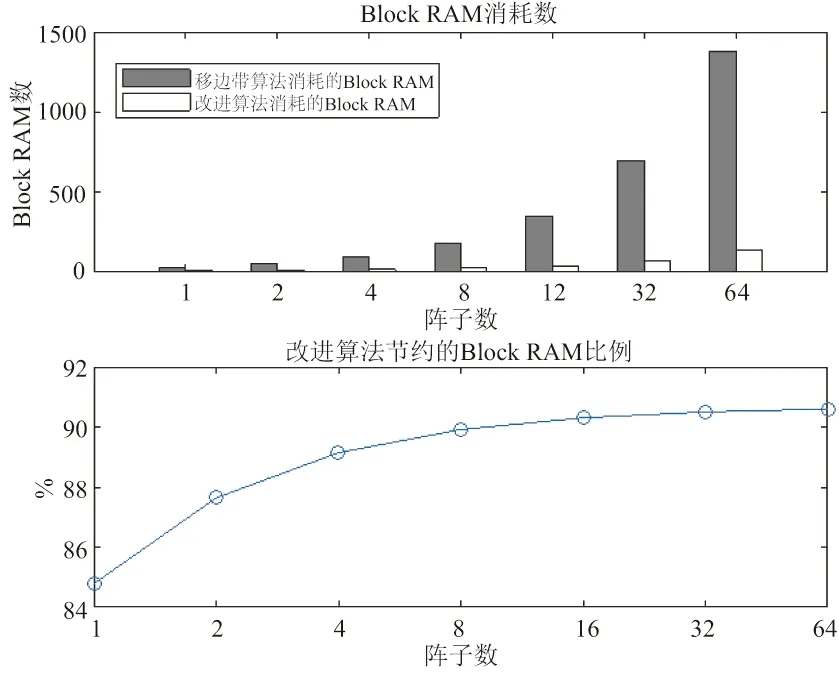
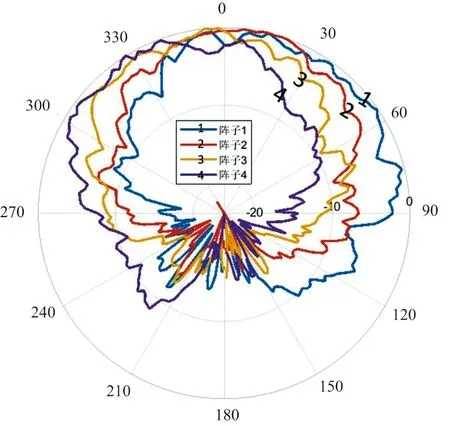
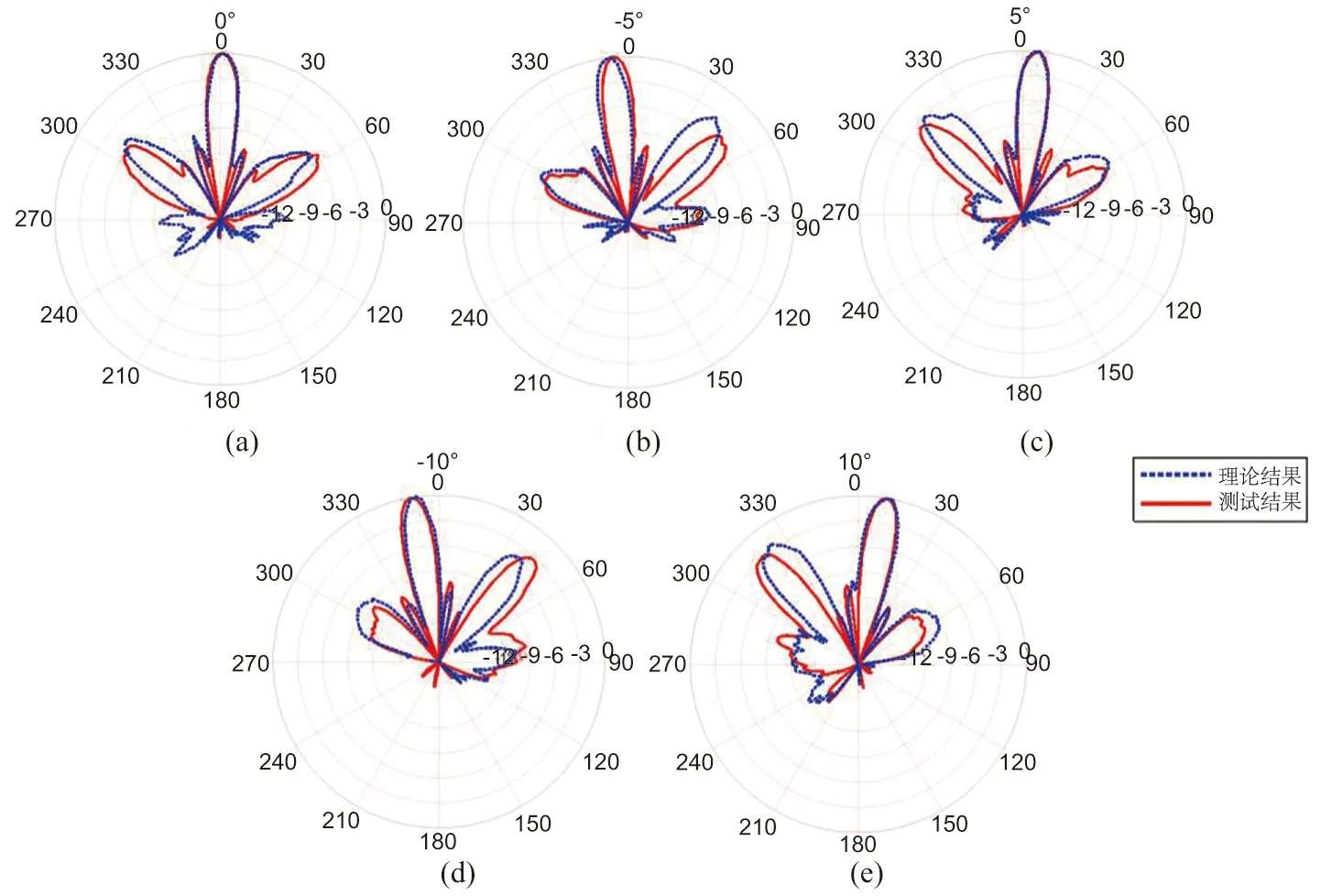
移邊帶波束形成算法原理如圖3所示,具體為將接收到的信號移動f1至中頻f0-f1,信號被調制為exp(-iω1t)的限制條件為:0 波束成形的輸入信號形式見(1): xm(t)=x(t-τm)exp[iω0(t-τm)] (1) 式中:xm為陣子m接收到的回波信號(m=1,2,3,...,M);τm為陣子m相對于坐標原點的時延值,s;ω0為基帶信號的中心角頻率,rad/s。經過下混頻模塊,可得到信號的實部與虛部分別為: xsmr(t)=xm(t)×2cos(ω1t) (2) xsmi(t)=xm(t)×2sin(ω1t) (3) 式中:xsmr與xsmi分別為經過下混頻模塊后的實部與虛部信號;ω1為載波信號的角頻率,rad/s。當下混頻后的信號經過低通濾波器,可將(ω0+ω1)過濾掉,僅保留(ω0-ω1),此時對應的信號表達式為: xfmr(t)=x(t-τm)[cos(ω0-ω1)t-ω0τm)+jsin(ω0-ω1)t-ω0τm)] (4) xfmi(t)=x(t-τm)[sin(ω0-ω1)t-ω0τm)-jcos(ω0-ω1)t-ω0τm)] (5) 式中:xfmr與xfmi分別對應經過低通濾波的實部與虛部信號。將低通濾波后的信號經過相位補償后輸出信號見公式(6)。 xmpn(t)=xfmr(t)×cos(ω0τm)-xfmi(t)×sin(ω0τm)=x(t-τm)exp[i(ω0-ω1)t] (6) 式中:xmPn為陣子m的波束n相移之后的信號(m=1,2,3,...,M,n=1,2,3,...,N)。 (7) 式中:bn為累加過后的第n個波束(n=1,2,3,...,N);m為對應的陣子數(m=1,2,3,...,M)。 全方位圓柱陣多波束漁用聲吶算法是在SSB算法的基礎上進行改進,主要調整了模塊的順序,采用時分復用的技術,將傳統的并行結構進行了串行處理,且采用分布式多板同步的方式進行波束累加(圖4)。 圖4 算法改進原理框圖Fig.4 Diagram of the improved algorithm 移時模塊的串行處理如圖5所示,每個陣子對應的存儲器分別存儲N個波束的補償參數,將低通濾波的輸出依次寫入對應的緩沖區,同時額外存在一個指針,根據傳入的補償參數在此指針位置上進行對應地址的讀取,最后依次串行輸出N個波束的實部和虛部至對應陣子的相位補償模塊進行下一級的運算。與圖3相比,模塊數量由原來的M×N個變為現在的與陣子數M保持一致,減少了FPGA存儲器的資源同時提高了后續在FPGA中信號處理的運算速度。 圖5 改進算法的串行處理原理Fig.5 Principal of the improved algorithm with serial processing 基于Matlab軟件對以上兩種算法進行仿真研究與對比。仿真時接收信號為線性調頻(LFM)脈沖信號[28],工作頻率為20 kHz~ 30 kHz[29],帶寬Bw為10 kHz,中心頻率f0為25 kHz,脈寬T為1 ms,基波頻率f1為 20 kHz。以一塊多通道接收機M=32為例,當期望指向性角度為水平方向0°垂直方向90°時,兩種算法的仿真結果如圖6所示,其中上三角對應SSB算法,實線為本研究提出的改進算法,虛線為經過低通濾波后輸入補償模塊的波形。 圖6 算法性能比對Fig.6 Comparison of algorithm performances 為了更加直觀地進行比較,圖6將兩算法的仿真輸出幅值同時縮小5倍。兩種算法的32路陣子累加結果進行對比可得對應的波形、幅值、以及頻率一致且結果完全重合,與單列陣子經過低通濾波后輸出的波形相比,幅值明顯提高。幅值的增加體現了波束成形空間濾波器的性質,完全重合的結果表明改進算法與傳統算法的性能一致。 3.1.1 下混頻及低通濾波模塊 該模塊主要由FPGA的直接數字頻率合成(DDS)IP核、乘法器以及91階低通濾波器[30]組成。實現過程中系統時鐘為200 MHz,采樣時鐘為1 MHz。由于下混頻包括實部和虛部,因此一個扇區中的32個陣子,在一個采樣時鐘內將產生64組數據,為節省資源采用64路時分復用。 一個采樣周期內,32路各傳輸一個數字信號,先后與DDS產生的余弦值和正弦值經過乘法器相乘,最后經低通濾波器向時間補償模塊輸入一組數據。下一個采樣周期時,32路將各傳輸另一個數字信號值,并按照上述過程向下一級輸出另一組數據,以此類推。 3.1.2 時間補償模塊 時間補償模塊狀態機如圖7所示,分為初始態、實部讀取態、虛部讀取態、以及返回態。初始態主要判斷上一模塊輸出通道數的高五位與時間補償模塊的對應通道數是否相等。當兩者相等且控制信號處在高位時,時移緩沖區的地址寫入當前指針值,同時時移緩沖區依次寫入上一模塊輸出數據的實部和虛部。虛部寫入完畢后轉至實部讀取態,當波束計數器小于39 時,狀態機跳轉至虛部讀取態進行地址運算,否則狀態跳轉至返回態而后回到初始態進行下一個采樣時鐘的時移計算。 圖7 時間補償狀態機Fig.7 State machine of time compensation 3.1.3 相位補償模塊 由相位補償模塊的計算公式可得,算法實現時需要對輸入本模塊的實部乘上對應的正余弦值。為節省片上資源,只將0°~90°精度為0.1°的900個正弦值sin(2πf0τ)存入只讀存儲器(rom)中,根據正余弦轉化公式,實時計算出相對應的余弦值。最后通過乘法器和加法器按照公式(6)計算出相位補償模塊的輸出值。 相位補償模塊的狀態機見圖8。初始態時上一模塊的有效值輸出,對應的控制信號置于高位,狀態機跳轉至下一狀態。相位補償余弦態和正弦態分別利用乘法器完成輸入數據的虛部與正弦相乘、實部與余弦相乘,同時在余弦態中,完成上一組輸入數據正余弦相乘后的相加,且在正弦態中,當波束計數器大于39時狀態跳轉至返回態。 圖8 相位補償狀態機Fig.8 State machine of phase compensation 若使用傳統移邊帶算法進行FPGA的實現,由于其并行的結構特點,需要例化32個存儲器分別計算并輸出對應通道的相位補償數據,每個通道輸出40個波形數據。然后將每個采樣時鐘對應的移項后的數據存入緩沖區,根據時間補償參數進行地址運算,此時每個通道將產生40個時間補償模塊,需例化40個存儲器。每一個時間補償模塊消耗0.5個塊隨機存儲器(BRAM),故參數補償部分需要消耗0.5×40×32=640個BRAM。 若使用改進算法進行FPGA的實現,由于采用了時分復用的串行結構,經過下混頻模塊后的數據先進行時移計算,每個通道對應一個時間補償模塊,每個時間補償模塊串行輸出對應的40組移時數據。隨后進行移項時只需要實時計算出當前的相位補償值并串行輸出給下一級,不需要占用額外的存儲器。此時每路陣子只對應一個時間補償模塊和一個相位補償模塊,且一塊多通道接收機在進行補償計算時只消耗32×0.5=16個BRAM,相較于傳統算法而言改進算法節省了更多的BRAM。 改進算法主要優化了實現過程中的資源消耗量,將通過FPGA實現的兩種算法的資源消耗量進行對比,由表1可得,查找表(LUTs)、寄存器(Register)的資源消耗變化不大,然而相較于傳統算法,改進算法的BRAM消耗量大幅度減小,且隨著陣子數量的增加,節約的BRAM數量顯著增加,當陣子數為64時節約了近90.6%的BRAM見圖9。 表1 兩種算法32路陣子的資源消耗對比Tab.1 Comparison of the resource consumption of the two algorithms for 32 arrays 圖9 BRAM消耗對比Fig.9 Consumption comparison of BRAM 為了進一步檢驗改進算法的波束成形性能,在消聲水池中進行了相關試驗。綜合考慮水池的測試條件,選取圓柱陣的相鄰同層的4個陣子,進行波束成形測試。同時為方便觀察接收波束成形的效果,采用收發分離的測試方案來搭建測試平臺如圖10所示,全向發射的換能器和圓柱陣換能器置于消聲水池中,入水深度均為2.7 m,兩者距離為5.5 m。全向發射的換能器作為LFM信號發射端,連續發射脈沖為1 ms的LFM信號,由圓柱陣換能器接收回波信號。 圖10 測試平臺Fig.10 Test system 為了測試單個陣子的性能,首先對4個陣子的指向性進行了測試,其指向性見圖11,可得試驗使用的換能器陣子1開角為82°,陣子2開角為86°,陣子3開角為90°,陣子4開角為78°,且相鄰兩陣子間夾角約為22°。 圖11 陣子指向性Fig.11 Arrays directivity 根據上文掃海方式,主要對-10°、-5°、0°、5°、10°幾個特殊的角度進行測試。將四陣子各自對應的指向性作為加擋函數并帶入指向性函數[8]即可得到理論結果。最后將測試時采集到的數據與理論結果進行對比,并分析誤差。 測試結果見圖12,虛線為理論值,實線為實際測量值。當期望指向性為0°時,測量結果與理論結果的主瓣幾乎重合,兩者指向性均為0°;當期望指向性為5°和-5°時,測試結果的指向性分別為5°和-6°,理論結果的指向性分別為5°和-5°;當期望指向性為10°和-10°時,測試結果的指向性分別為10°、-9°,理論結果的指向性分別為10°、-10.5°。 圖12 實測與理論在不同角度的指向性對比Fig.12 Comparison of directivity between test and theory at different angles 根據測量結果可得,當期望指向性角為±5°時,理論和實測的指向性角度大約偏差1°左右,可能是由于測量時伺服機精度不夠造成誤差。當期望指向性為10°時,旁瓣值高,造成的原因可能是此時的聲程差較大,帶來的測量誤差較大,即當指向性角越向正向偏離0°,聲程差越大,對應旁瓣越高。同時本試驗所用換能器采用了束控,這也是導致旁瓣較高的原因之一[31]。實測的波束圖相較于理論仿真[12]的偏差在合理范圍中,進一步證明改進算法與傳統移邊帶[21]算法在性能上的一致。 基于傳統的移邊帶波束成形算法原理,改進算法對傳統移邊帶算法的時間補償和相位補償模塊進行了順序的調整與改進,將原有資源占用量較大的并行處理優化為串行運算,并結合FPGA的特點利用時分復用的方法降低資源的消耗量,在保留原有算法精度的前提下提高了硬件處理速度,同時節省了硬件的成本。本研究主要考慮了硬件處理方面的資源消耗與波束成形性能之間的關系,要更加直觀地觀察回波是否擊中目標物體,還需要通過上位機的界面顯示來實現,然而由于網口傳輸的數據量有限,因此今后還應對波束成形過程中各個模塊的數據進行相應的截位,并對采集到的數據進行分析,以實現在波束成形性能不變的同時,傳輸更多的數據,從而獲得更加清晰的圖像。 □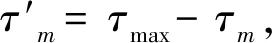
2.2 算法改進
2.3 兩種算法仿真比較
3 改進算法的FPGA實現
3.1 模塊設計與實現

3.2 資源消耗對比
4 試驗測試
5 結論
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
