基于多參數靈敏度分析與遺傳優化的鐵水質量無模型自適應控制
2022-01-09 10:22:54溫亮周平
自動化學報 2021年11期
溫亮 周平
高爐是鋼鐵制造最主要的大型冶金反應器之一.如圖1 所示,整個高爐煉鐵系統分為高爐本體、給料系統、熱風系統、煤粉噴吹系統、高爐煤氣處理系統及出鐵系統等幾個子系統.高爐煉鐵是一個持續不中斷的過程,在整個流程中,鐵礦石、焦炭、溶劑按一定比例和布料制度分批次逐層從高爐頂部經由旋轉溜槽裝載到爐喉中.同時,煤粉由噴槍噴入高爐風口,冷空氣、氧氣在熱風爐中加熱到約1200°C 左右后經由風口鼓入高爐爐腹部分.上部調劑加入的焦炭在風口前經過燃燒產生大量高溫煤氣,煤氣不斷向上運動,與下降的爐料相遇,發生一系列復雜的物理化學反應,將鐵從鐵礦石中還原出來.上升的高爐煤氣最終從爐頂回收,經過重力除塵、余壓發電等環節回收再利用.下降的爐料經過加熱、還原、熔化等物理化學變化,最終生成液態的生鐵和爐渣,并且分別從鐵口和渣口排出[1?4].
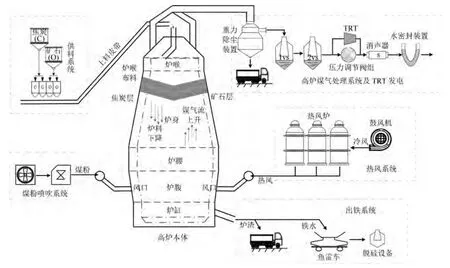
圖1 高爐工藝流程示意圖Fig.1 Diagram of BF ironmaking process
高爐煉鐵生產的主要目的是持續、穩定、高效、低能耗地生產鐵水,為后續轉爐煉鋼等下游工序提供優質鐵水.因此,對整個高爐煉鐵過程的優化控制通常可以等價于對高爐生產最終產品— 鐵水質量的控制.目前,鐵水質量的好壞通常由兩大參數來表征,分別為鐵水溫度(Molten iron temperature,MIT)和鐵水硅含量([Si]).其中MIT 是反映鐵水物理熱的重要指標,MIT 高有利于后續轉爐煉鋼的穩定操作和自動控制,鐵水溫度過低會影響鐵元素氧化過程和熔池的溫升速度,不利于成渣和去除雜質,容易發生噴濺.我國煉鋼規范規定轉爐煉鋼入爐鐵水的溫度應大于1250°C,并且要相對穩定.考慮到鐵水在運輸和待裝過程中損失的熱量,質量優良的鐵水溫度應控制在1480°C~1530°C 為宜.此外,[Si]是反映鐵水化學熱的重要指標.鐵水[Si] 高,渣量增加,有利于去除鐵水中的有害物質磷、硫.[Si] 高還會增加轉爐熱源,提高廢鋼比.但[Si] 過高會使生鐵變硬變脆,收得率降低且容易引起噴濺.另外,[Si]高使渣中SiO 含量過高,影響石灰的渣化速度,延長吹煉時間,同時也會加劇對爐襯的沖蝕.通常,質量合格的鐵水[Si] 應控制在0.5%~0.7%[1?5].
高爐煉鐵是一個多相、多場耦合嚴重的強非線性時變動態過程,機理不清,數學模型難以建立,或者建立的模型由于理想假設條件太多而難以實際應用[1?2].因此,傳統基于模型的控制器設計策略很難應用于高爐多元鐵水質量控制,而僅依賴于系統輸入輸出數據的數據驅動建模與控制方法就顯示了諸多優越性.到目前為止,基于數據驅動的方法針對多元鐵水質量的建模已經有了大量的研究成果,例如文獻[6] 中的多信息融合時間序列神經網絡模型,文獻[2]、[7?8] 的隨機權神經網絡模型,文獻[9?10]的支持向量機模型,文獻[1]、[11] 的子空間模型等,但是卻鮮有關于高爐煉鐵過程直接數據驅動控制的相關研究成果和文獻報道.
目前,直接數據驅動控制已受到學術界和控制工程界越來越廣泛的關注,發展了多種數據驅動控制方法和技術,例如無模型自適應控制(Model free adaptive control,MFAC)[12]、懶惰學習控制[13]、虛擬參考反饋整定(Virtual reference feedback tuning,VRFT)[14]、迭代反饋整定(Iterative feedback tuning,IFT)[15]、去偽控制(Unfalsified control,UC)[16]、基于相關性分析的控制器整定(Correlation-based controller tuning,CbT)[17]等.總的來說,這些數據驅動方法大體可分為兩類,第一類是控制器結構確定,控制器參數利用輸入輸出測量數據離線整定的數據驅動控制方法[18],比如VRFT、CbT、UC 等.高爐內部嚴酷的冶煉環境決定了基于工業高爐系統數據實驗的不可實現性,而高爐冶煉過程中復雜的動態特性又使得很難從理論上確定一個合適的控制器結構,因此,這種控制方法并不適用于高爐多元鐵水質量的控制.另一類數據驅動控制方法則假設控制器結構不確定[18],這種控制方法的一個典型代表就是MFAC.該方法由北京交通大學的侯忠生教授在文獻[19] 中針對單輸入單輸出離散時間非線性系統首次提出,其后在文獻[20] 中拓展到了多輸入多輸出動態系統.該方法針對離散時間非線性系統使用了一種新的動態線性化方法及一個稱為偽雅可比矩陣的新概念,在閉環系統的每個動態工作點處建立一個等價的動態線性化數據模型,然后基于此等價的虛擬數據模型設計控制器[21].因此,鑒于高爐冶煉系統機理模型難以建立,可將MFAC 方法作為該研究領域的一條新的思路.
綜上,本文針對復雜高爐煉鐵過程多元鐵水質量難以采用常規方法進行控制的難題,綜合采用基于緊格式動態線性化(CFDL) 的無模型自適應控制方法(CFDL-MFAC)、遞推子空間模型辨識方法、多參數靈敏度分析技術以及遺傳算法優化技術,研究高爐煉鐵過程多元鐵水質量的無模型自適應控制問題.首先,針對高爐鐵水質量參數控制系統建立CFDL-MFAC 控制器.然后,為了對控制器的諸多關鍵參數進行優化和整定,基于實際高爐工業數據建立多元鐵水質量的遞推子空間動態模型,并用建立好的CFDL-MFAC 控制器和多元鐵水質量遞推子空間動態模型進行蒙特卡羅(Monte Carlo) 模擬實驗.根據實驗結果,集成采用多參數靈敏度分析(Multi-parameter sensitivity analysis,MPSA) 和參數遺傳優化(Genetic algorithm,GA) 技術離線整定控制器參數.最后,基于實際工業現場運行數據進行工業實驗和比較分析.
1 控制策略
高爐冶煉過程為連續的強非線性時變動態過程,高爐內部伴有高溫、粉塵、強噪聲等常規檢測設備所懼怕的問題,因此反應狀態不清,機理研究難以進行.其狀態信息主要來源于豐富的外圍檢測設備及黑箱狀態下各項操作參數設定對應的鐵水質量參數化驗記錄.這些數量龐大的歷史數據被業內人士認為應當包含著一些尚未發現的高爐知識,有必要進行深入研究與挖掘.由此,本文以高爐歷史數據為出發點,提出如圖2 所示整體采用CFDL-MFAC 數據驅動在線控制與控制器參數MPSA-GA 離線整定的控制策略.
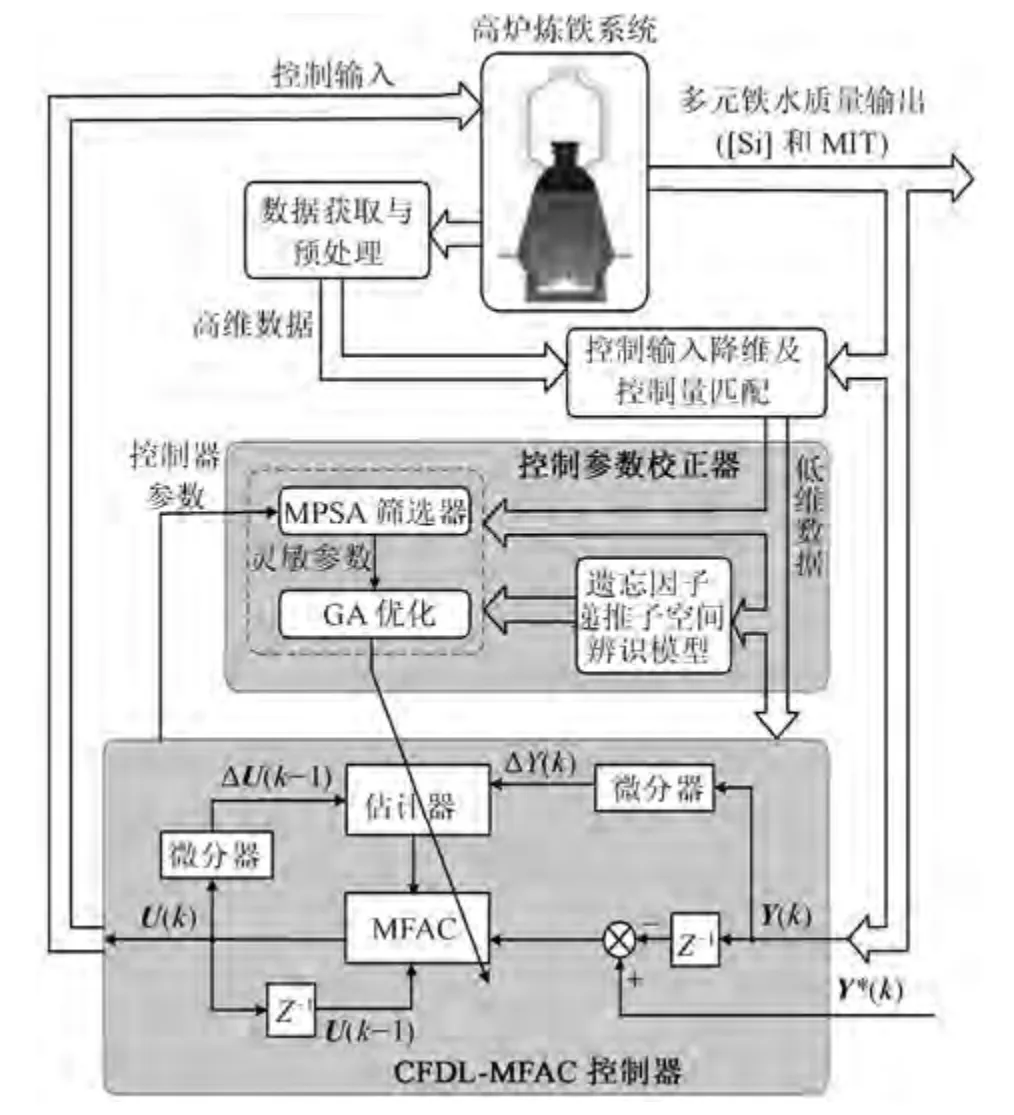
圖2 CFDL-MFAC 控制策略Fig.2 Control strategy of CFDL-MFAC
1) 首先,采用典型相關性分析(Canonical correlation analysis,CCA)、相關性分析(Correlation analysis,CA)、MPSA 相結合的方法從所有高爐主體參數中選出對MIQ (Molten iron quality) 參數影響最大的可控變量作為建模與控制的輸入變量,并采用灰色關聯分析的方法對控制量與鐵水質量指標之間的主要對應關系進行匹配;
2) 采用基于遺忘因子的遞推子空間辨識方法建立鐵水質量參數動態模型,并依據此模型建立參數整定所需的優化模型;
3) 依據基于緊格式動態線性化的無模型自適應控制(Compact form dynamic linearization-Model free adaptive control,CFDL-MFAC) 方法建立多元鐵水質量的數據驅動控制器,并用此數據驅動控制器來控制建立的遞推子空間數據模型,從而進行針對控制參數的Monte Carlo 實驗;
4) 針對高爐煉鐵過程鐵水[Si] 與MIT 的控制難題,所提數據驅動控制根據Monte Carlo 實驗結果,采用MPSA 方法分析各個控制器參數的靈敏度,選出靈敏參數;
5) 以遞推子空間數據模型為指標,依據遺傳算法的思想整定靈敏參數,以此提高控制器的控制性能;
6) 用參數整定后的CFDL-MFAC 控制器在線控制高爐多元鐵水質量,以此適應高爐煉鐵過程的慢時變特性,使高爐順行,鐵水輸出質量穩定.
2 控制算法
由圖2 可知,CFDL-MFAC 控制器和控制參數整定模塊為本文所提控制策略中最主要的兩個部分,因此本節將圍繞這兩部分進行展開.第2.1 節將依據高爐煉鐵系統的具體特性給出CFDL-MFAC 控制器的設計過程,第2.2 節將依據第2.1 節中給出的CFDL-MFAC 控制算法設計相應的參數整定算法.
2.1 CFDL-MFAC 數據驅動控制算法
采用如下多輸入多輸出(Multiple input multiple output,MIMO) 離散時間非線性方程來描述高爐鐵水生產過程:
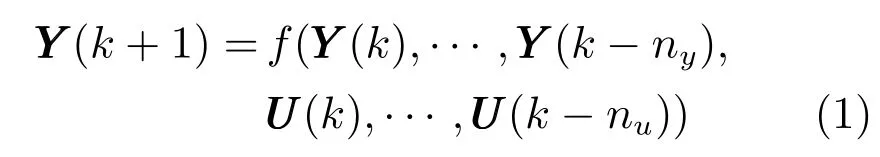
式中:UUU(k)∈Rm,YYY(k)∈Rn分別表示k時刻系統的m維控制輸入和n維多元鐵水質量輸出;nu,ny為表征系統階次的未知正整數;f(·) 為未知非線性映射函數.在這里,n維多元鐵水質量輸出指[Si]和MIT 兩個鐵水質量指標,m維控制輸入指從高爐主體參數中選出的對多元鐵水質量輸出影響最大的幾個控制輸入變量,將在第3 節數據實驗時具體給出.
針對上述系統的無模型自適應控制器設計過程如下:
1) 緊格式動態線性化:為了便于鐵水質量數據驅動自適應控制律的設計,在每個動態運行工作點建立一個等價線性化動態模型.根據文獻[21] 提出的無模型自適應控制(MFAC) 理論,此等價線性化模型的建立需要系統滿足如下兩條假設條件.
假設1[21].系統對應的非線性映射函數f(·) 對系統控制量在系統輸入階次nu范圍內各個時刻的分量UUU(k),···,UUU(k ?nu) 存在連續偏導數.
假設2[21].系統滿足廣義Lipschitz 條件,即在任意兩個時刻k1,k2(k1,k2≥0 且k1k2),當UUU(k1)/UUU(k2) 時,系統輸入與系統輸出之間滿足
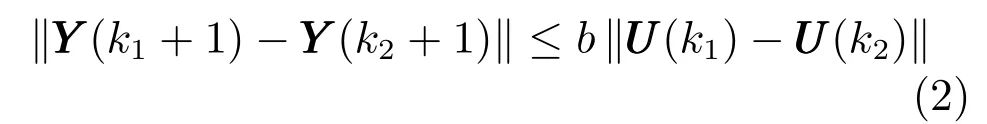
式中,b>0 是一個常數.
上述假設僅是對于一般非線性系統的典型約束,由于多元鐵水質量控制系統亦滿足能量守恒,有界輸入定會產生有界輸出.具體來說,[Si] 存在一個確定的上界100%和下界0%,在煤粉、焦炭及熱風的供應量范圍內,MIT 也不會無限升高,所以,在任意兩個時刻,一定能夠通過計算獲得[Si]、MIT 變化量與高爐本體主要控制參數變化量之間的有界系數,因此可認為高爐系統滿足假設1 和假設2,由此可給出如下引理.
引理1[20].任意時刻k,若有‖ΔU(k)‖=‖UUU(k)?UUU(k ?1)‖/=0,則一定能夠找到一個時變參數矩陣Φc(k)∈Rn×m,使得系統(1) 可轉化為如下緊格式動態線性化(CFDL) 模型:
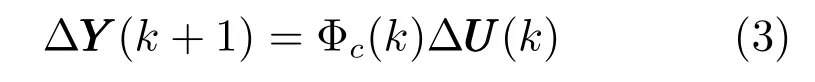
且對任意時刻,Φc(k) 是有界的,稱Φc(k) 為偽雅可比矩陣(Pseudo Jacobian matrix,PJM).
2) 控制量求解:取準則函數如下:
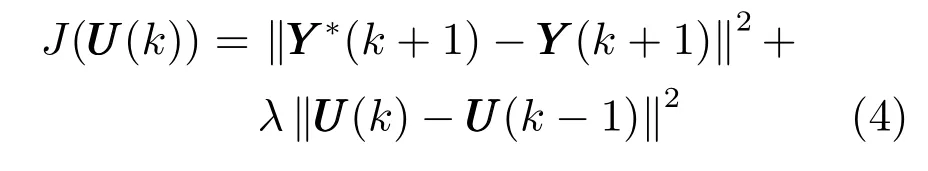
式中,第1 項的引入是為了使多元鐵水質量輸出能夠跟蹤設定的參考軌跡,其中YYY ?(k+1) 是k+1 時刻期望輸出值;第2 項的引入是考慮到高爐本體控制參數噴煤量、富氧流量等的變化均需要過渡時間,不能突變,過大的控制量變化難以短時間實現,為此弱化控制增量,減輕執行機構負擔;λ >0 是控制增量懲罰項的權重因子.
將式(3) 代入式(4),并對UUU(k) 求偏導,令其為零,得
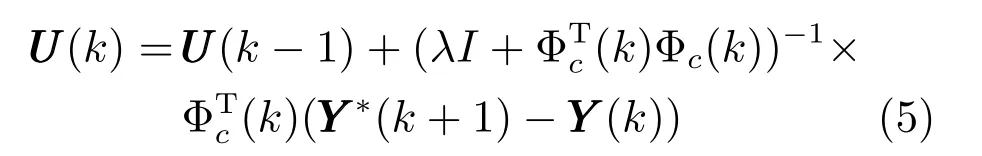
由于算法(5)中包含矩陣求逆運算,當系統輸入輸出維數很大時,求逆運算非常耗時,不利于實際應用,將式(6) 替代式(5) 從而避免矩陣求逆運算.
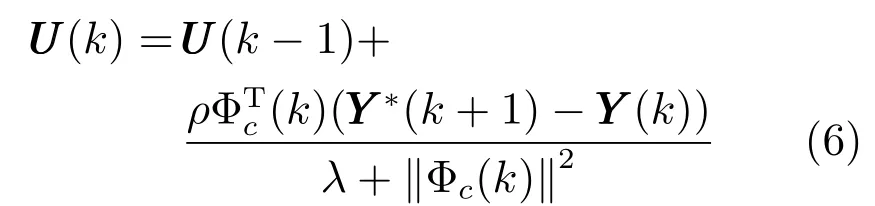
式中,ρ ∈(0,1] 是為了使控制算法更具一般性而加入的步長因子.
3) 偽雅可比矩陣估計算法:由于多元鐵水質量控制系統模型未知,因此,式(6) 中偽雅可比矩陣Φc(k) 無法得知,需要對其進行在線估計.考慮如下估計準則函數:
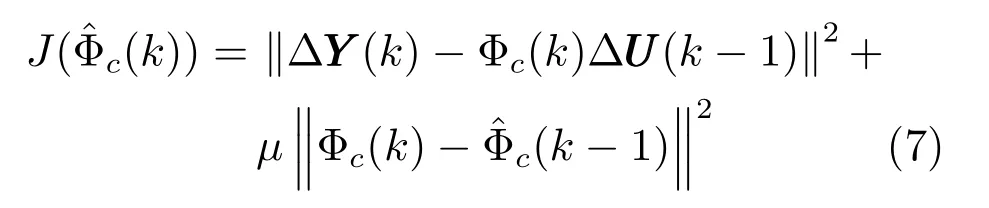
式中,μ>0 是權重因子:為Φc(k ?1) 的估計值.極小化準則函數,可得PJM 的估計算法如式(8) 所示.同樣,為避免矩陣求逆運算,將上式替換為如式(9) 所示形式.
式中,η ∈(0,2] 為引入的步長因子,作用與式(7) 中的ρ相同.
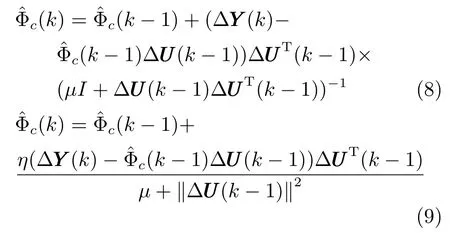
4) 算法重置機制:由于高爐多元鐵水質量參數每次出鐵僅能獲得一組數據,因此采樣間隔時間較長,參數時變程度較大.為了使PJM 估計算法能夠更好地對時變參數進行跟蹤,引入如下算法重置機制:

上述中,式(6)、(9)、(10) 即為CFDL-MFAC控制器的基本結構框架,該控制器結構框架的確定完全依據基于緊格式動態線性化的多輸入多輸出無模型自適應控制方法,因此文獻[20] 中給出的穩定性數學證明在本文中依然成立.
2.2 基于多參數靈敏度分析和遺傳優化(MPSAGA)的(CFDL-MFAC)參數整定方法
由上述第2.1 節可知,CFDL-MFAC 控制器有7 個固定的控制參數(λ,μ,ρ,η,α,b1,b2) 和m×n個偽雅可比矩陣初值.若假定控制器輸入輸出維度均為2 維(即m=n=2),則CFDL-MFAC 控制器將包含4 個偽雅可比矩陣初值(φ11,φ12,φ21,φ22),共11 個可調變量.這些控制參數及偽雅可比矩陣初值會嚴重限制控制器的控制性能.同時,由于MFAC方法在高爐多元鐵水質量控制中沒有實際應用,缺乏相應的經驗取值,其他系統應用中采用的參數在高爐系統中并不適用,因此需要引入優化算法來對控制器參數進行整定.但由于參數較多,全部優化相當于在一個11 維的參數空間中尋找一個全局最優解,時間成本較大,且通過實驗發現部分參數的取值對控制結果的影響較小甚至可以忽略不計,因此考慮對各個參數進行靈敏度分析.
常用于參數靈敏度分析的方法有直接求導法、因子擾動法等.直接求導法的思路是根據靈敏度的含義,直接對系統參數進行求導[22?23],這種方法適用于能寫出明確表達式的系統,對高爐鐵水質量控制系統并不適用.因子擾動法[24]的思路是指變化一個參數的數值,其他參數保持不變,以輸出變量與輸入變量的比值為指標,單獨分析每個參數的靈敏度,然后綜合所有分析結果.顯然,這種方法忽略了參數之間的相關性,只是一種局部的分析方法.本文采用多參數靈敏度分析方法[25]來分析參數的靈敏度,多參數靈敏度分析基于Monte Carlo 實驗進行.Monte Carlo 實驗是以概率統計理論為基礎,依據大數定律(樣本均值替代總體均值),利用電子計算機數字模擬技術,解決一些很難直接用數學運算求解或用其他方法不能解決的復雜問題的一種近似計算方法[26].Monte Carlo 實驗同時變化所有參數的取值,多次運行控制器,相比于因子擾動法中只改變單個參數的取值,能夠更真實、全面地模擬實際物理過程,包含了參數之間的相關性.多參數靈敏度分析綜合考慮多次運行結果,同時給出所有參數的靈敏度,靈敏度不是由輸出變化值與參數變化值的比值來描述,而是依據定義的目標函數,將多次運行結果按給定指標進行分類,分別繪制累計頻率曲線,依據統計學的原理來判斷[27].
本節基于MPSA 和GA 技術,提出一種CFDLMFAC 數據驅動控制器參數整定方法.首先采用遞推子空間辨識方法建立高爐多元鐵水質量局部動態模型,然后依據此模型建立離線參數優化模型,采用MPSA 技術通過該模型來對CFDL-MFAC 控制器的參數及偽雅可比矩陣初值的相對重要性做出統計評價,然后基于遺傳優化技術設計適用于高爐鐵水質量控制系統的優化流程,以該流程來對MPSA 分析后靈敏度高、對控制器性能影響較大的參數及初值進行整定,其余參數及初值在其限定范圍內選取適當的值.
2.2.1 多元鐵水質量動態模型的建立
采用MPSA 方法分析參數靈敏度和遺傳參數優化均需要進行大量試驗獲取測試性輸入輸出數據,包括隨機產生控制變量加載在高爐煉鐵系統,以獲取相應的鐵水質量指標輸出.由于高爐操作存在的危險性,這些試驗操作無法在真實高爐系統上來完成.為此,本文結合文獻[28] 中的基于遺忘因子的遞推子空間辨識方法建立高爐多元鐵水質量系統的動態模型,該動態模型是由高爐離線輸入輸出數據推導出的一系列子空間模型參數組.
對于式(1) 表述的高爐煉鐵系統,假設在k時刻,多元鐵水質量輸出可由過去時刻的系統輸入輸出信息和當前時刻控制量輸入推算出來,其關系為
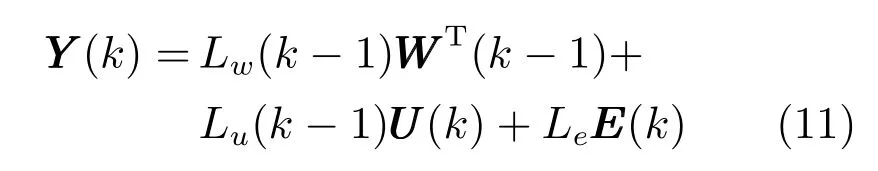
式 中,WWW(k ?1)=[YYY(k ?1)T,UUUT(k ?1)],Lw、Lu、Le分別為狀態子空間矩陣、確定輸入的子空間矩陣和隨機輸入的子空間矩陣,EEE(k) 為零均值白噪聲向量.則當k →∞時,當前時刻輸出預測為
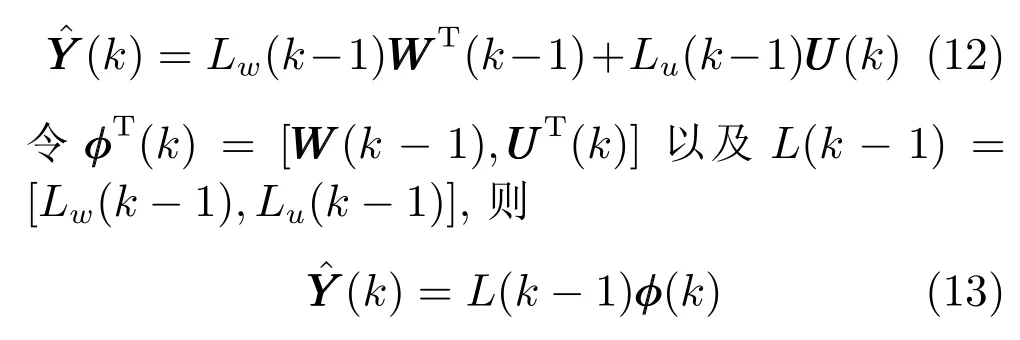
系數矩陣參數集L={L(1),L(2),···,L(k),···,L(Z)},k=1,···,Z即為所需求解的多元鐵水質量動態模型,其中Z為動態模型采樣時間長度.每一組參數L(k) 可以通過求解如下最小二乘問題來獲得:
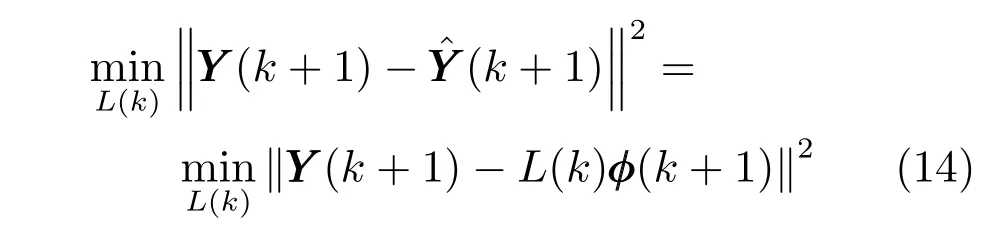
引入遞推最小二乘法來求解上述問題,遞推方法如式(15)~(17):
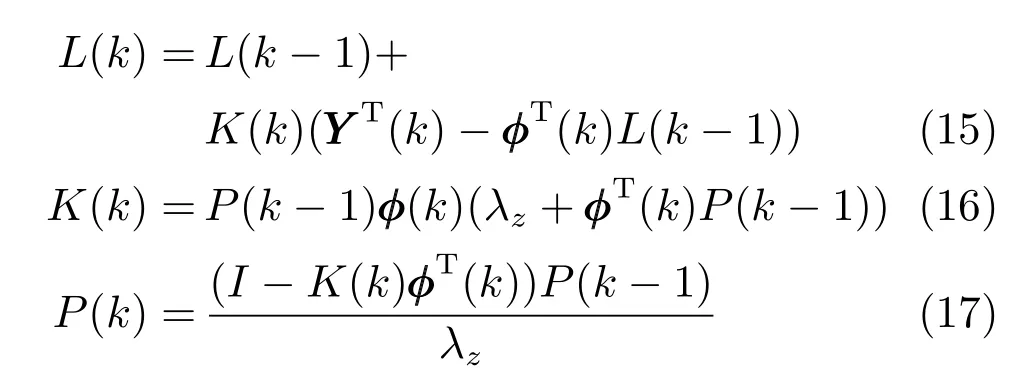
式中,K(k) 是增益矩陣,P(k) 是協方差矩陣,λz為遺忘因子.
2.2.2 CFDL-MFAC 參數優化問題描述
控制器參數整定的主要目的是獲取一組較優的控制器參數以提高控制器性能.若以控制器控制前述的多元鐵水質量動態模型跟蹤輸出參考曲線T個采樣周期的累計均方誤差為控制器性能衡量指標,則CFDL-MFAC 控制器參數優化問題可用如式(18) 所示優化模型來描述:
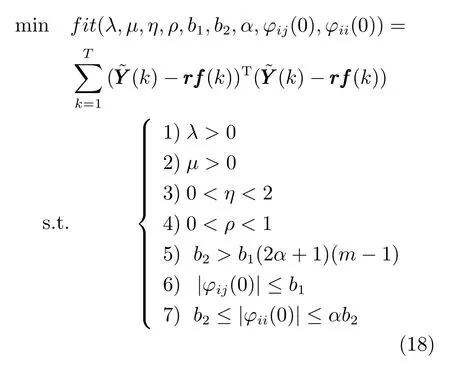
式中,i=1,···,m,j=1,···,n,j/=i;約束5)~7) 的引入是為了保證偽雅可比矩陣初值滿足嚴格對角占優條件;為在k時刻控制器輸出控制量UUU(k) 作用下多元鐵水質量動態模型的輸出向量,可由式(13) 計算得到;rf為輸出參考曲線,因為真實高爐系統的鐵水質量輸出期望值的變化通常為階躍變化,因此將其定義為一個多次跳變的分段函數,以此使優化后的參數對系統設定值跳變具有較好的適應性.
由式(18) 可知,該參數優化問題為一個含有非線性不等式約束的混合約束優化問題,為了便于優化算法的設計計算,采用懲罰法來松弛式中的各項約束.當參數集不滿足任意一項約束時,為目標函數值加上高額懲罰,使該參數集無法成為最優參數集,由此將原混合約束優化問題轉化為如下無約束優化問題:
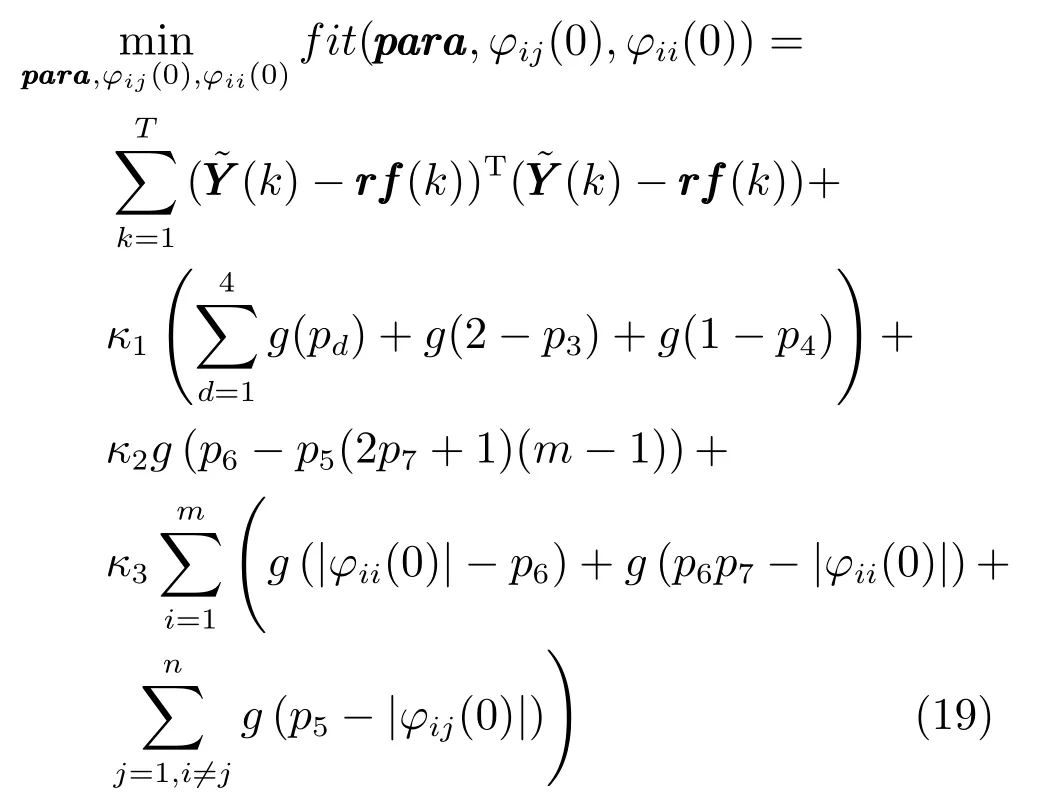
式中:para=[p1,···,p7]=[λ,μ,η,ρ,b1,b2,α]為控制參數向量;κ1,κ2和κ3分別為對應約束1)、4)、5)、6) 和7) 的懲罰因子,一般選取為一個相對正常適應度值較大的數值;g(·) 為如式(20) 的分段函數.
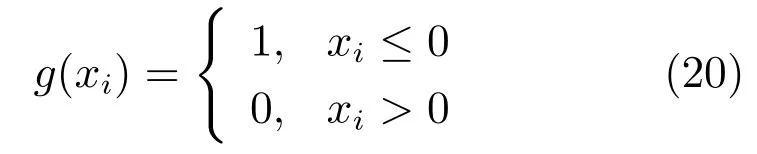
2.2.3 基 于 MPSA 與 改 進 GA 的 CFDLMFAC 數據驅動控制器參數整定
針對式(19) 的無約束優化問題,結合改進的遺傳算法及多參數靈敏度分析[23]技術,提出CFDLMFAC 數據驅動控制器的參數整定方法,如下所示:
1)基于Monte Carlo 實驗的控制器多參數靈敏度分析:根據高爐過程實驗經驗,在滿足式(19) 的約束條件下設置每個控制參數的取值范圍.在每個參數限定的取值范圍內,生成N個服從均勻分布的獨立隨機數,構成N組隨機分布的參數集.應用生成的N個參數集,分別運行控制器,根據下式計算損失函數值:
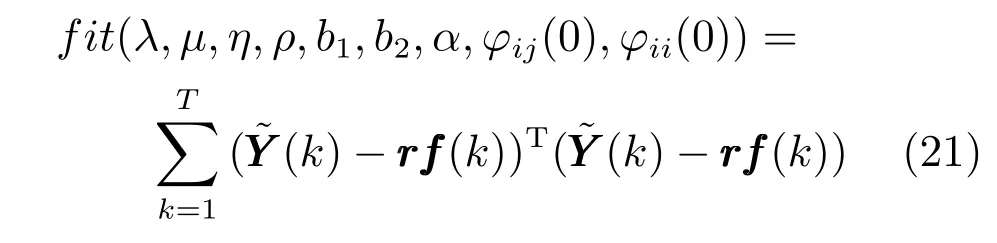
依據損失函數值的大小,將N個參數集分為兩組,分別為損失函數值“可接受的” 參數集和損失函數值“不可接受的” 參數集;分類準則依據制定的“主觀指標”,即將N個損失函數值按大小排序,選取后50%分位點處的損失函數值作為“主觀指標”,如果損失函數值大于“主觀指標”,那么該參數組被分類為“不可接受的” 參數組;反之,如果損失函數值小于“主觀指標”,那么對應的參數組被分類為“可接受的” 參數組.
對每個參數,比較“可接受” 的參數集和“不可接受” 的參數集兩組中參數值的分布情況.如果兩組分布形式相同,則表明該參數不靈敏;反之,則表明該參數較靈敏.若一組參數中不同數值的個數為Nv,則其中第j(1≤j ≤Nv) 個參數值對應的累計頻率Cfj的計算方法如式(22) 所示
式中vi為第i個數值出現的頻次.
對每個參數,繪制累計頻率曲線,并根據式(23)計算累計頻率曲線的分離程度(Degree of separation,DS):
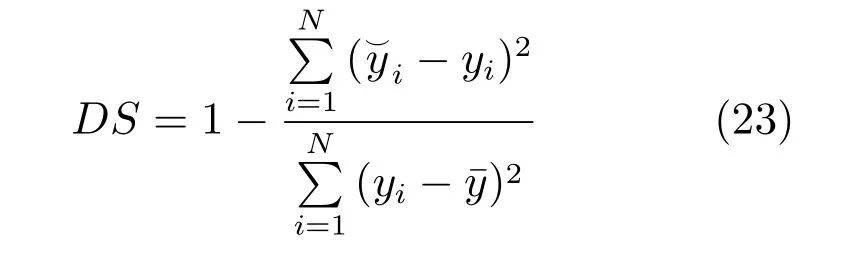
式中,和yi分別是相應參數“可接受” 和“不可接受” 參數組對應累計頻率數值,是相應參數“可接受” 參數組對應累計頻率數值的平均值.DS 的取值范圍介于0 和1 之間.參數越靈敏,DS 越接近于1,參數越不靈敏,DS 越接近于0.
根據計算的分離程度數值,篩選出累計頻率曲線分離程度較大的s個靈敏參數x1,···,xs.另外,為每個判定為不靈敏的參數在其約束范圍內取定一個合理的值,一般取為取值范圍的中位數或0.
2) 基于大規模變異與精英局部搜索的靈敏度參數遺傳優化:以全部靈敏參數x1,···,xs作為問題變量進行參數染色體的編碼,鑒于經MPSA篩選后的靈敏參數數量較少,計算壓力較輕,可以選擇精度更高,能使遺傳算法收斂速度更快的實數編碼方式來對問題變量進行編碼[29?30].因此,每條染色體由s個浮點數作為基因串聯組成,用ccc=[x1,···,xs] 表示,種群為r條染色體構成的基因組Popu=
基因重組與基因變異:采用單點交叉方式對基因進行重組,交叉方式為從父代基因種群中無放回地隨機抽取一對染色體,以一定概率gj決定是否對該對染色體進行重組,或結果判定為真,則隨機產生一個截斷的位置loc ∈[1,s],將該對染色體從s處截斷,交換[loc,s] 部分的基因,從而產生一對子代染色體,重復該項操作直至父代種群中所有個體均被遍歷為止.該項操作可以等價為將父代種群兩兩配對進行交配,因此要求父代種群規模r為一個偶數;對基因重組后產生的每個子代以一個很小的概率gb判定是否進行變異操作,若判定結果為真,則隨機選取該染色體的某一位基因xb進行變異,變異算子采用[31] 中的實值變異算子,變異運算如式(24) 所示:
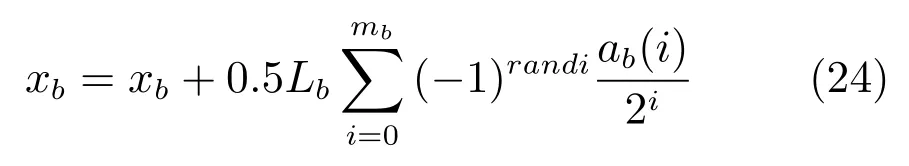
式中,Lb為對應xb靈敏參數的取值范圍;randi為隨機產生的任意正整數;mb為變異算子二進制意義下的精度,且ab(i) 以1/mb的概率取值為1,否則取值為0.
大規模變異:考慮到該參數優化問題是一個局部最優解較多的問題,為了增強算法的搜索能力,提出大規模變異的遺傳操作,對種群最優個體適應度進行監控,若30 代種群最優適應度沒有較為明顯的改進,且未達到系統控制精度要求,則將父代和進行基因重組與變異后的子代集中到一起,以一個較大的概率值gs對新種群中的每個個體判定是否變異,若某個染色體對應的判定結果為真,則在1 至s范圍內隨機產生若干個地址,對每個地址對應的基因進行變異操作.可見,由于變異概率很大,該項遺傳操作在一定程度上退化為了隨機搜索,在很大程度上脫離了父代基因的束縛,提高了搜索能力.大規模變異算法偽代碼如下所示,該算法時間復雜度為O(r+ra).

精英局部搜索:考慮到最優個體附近必存在局部最優解,為了提高算法搜索到局部最優解的速度,提出了精英局部搜索操作,即對適應度值最小的染色體的每一個基因以變異算子絕對值的幅度進行加減操作生成2s個子代并入種群.精英局部搜索算法的偽代碼如下所示,該算法時間復雜度為O(s).

子代篩選:對產生的各個子代染色體進行反歸一化并用式(21) 計算適應度值,與父代放在一起進行比較,篩選出新一代種群.同樣考慮到該優化問題易陷入局部優解,子代的篩選機制可以采用Metropolis 準則[32],但所有子代種群個體均用Metropolis 準則篩選會嚴重降低計算效率,為此,取一個折中方案,僅子代中的半數個體采用Metropolis 準則篩選.具體篩選機制為,直接將種群所有個體中適應度值最小的r/2 個個體選出歸入新一代種群,再從剩余的個體中每次無放回地隨機抽取兩個個體,對其利用Metropolis 準則判別選擇哪個個體進入新一代,直至選夠r/2 個個體為止.子代篩選算法的偽代碼如下所示,該算法時間復雜度為O(rn×T).

重復上述操作直至算法收斂或控制精度滿足要求抑或是達到最大迭代次數ge.所提控制器參數整定算法的偽代碼如下所示.由于進化過程中臨時種群的染色體個數rn要遠小于最大遺傳代數及Monte Carlo 實驗次數,并且因為提前終止條件的存在,一般不會達到最大遺傳代數,因此該算法時間復雜度主要取決于Monte Carlo 實驗次數設定值.當設定的Monte Carlo 實驗次數遠大于遺傳算法最大遺傳代數時,該算法的時間復雜度為O(N ×T),而較為一般的情況下,該算法的時間復雜度介于O((N+rn)×T) 與O((N+ge×rn)×T) 之間,僅在第一輪遺傳即滿足控制精度要求的條件下算法時間復雜度為O((N+rn)×T).


3 工業數據試驗
基于柳鋼2#高爐現場數據庫收集到的2015 年5 月1 日到2015 年5 月23 日共552 組高爐實際生產數據進行工業數據試驗.本節內容安排如下:第3.1 節給出CFDL-MFAC 數據驅動控制器維度的確定方法及結果;第3.2 節為所提數據驅動控制器參數優化整定的過程及結果;第3.3 節給出采用參數整定后的控制器進行設定值跟蹤數據試驗及抗干擾控制數據試驗的鐵水質量控制結果.
3.1 CFDL-MFAC 數據驅動控制器維度確定及控制量匹配
對于CFDL-MFAC 方法,因為控制目標變量確定為多元鐵水質量指標中的[Si] 和MIT,因此控制器輸出維度確定為2 維,只需要確定控制器的輸入維度.
基于高爐現場可用傳感器,對高爐鐵水質量參數有影響的可測變量包括:熱風溫度、熱風壓力、壓差、富氧率、富氧流量、透氣性、爐腹煤氣指數、鼓風動能、鼓風濕度、冷風流量、頂壓風量比、送風比、阻力系數、設定噴煤量、理論燃燒溫度、標準風速、實際風速、頂壓.這些變量部分之間存在較強相關性,信息冗余較為嚴重,而且如果全部選為控制器輸入,控制器維度過高,計算量大,不適用于在線控制,為此引入文獻[28] 中基于典型相關性分析(CCA)與相關性分析(CA) 相結合的數據降維方法對控制變量進行初步篩選,并依據MPSA 結果與控制實驗結果對控制變量進行二次篩選,具體流程如下:
a) 對從高爐歷史生產數據運用CCA 的方法計算出高爐主體參數與鐵水質量參數之間的全部典型變量以及對應的典型相關系數;
b) 對各典型變量的典型相關系數進行顯著性檢驗,舍棄掉相關程度不顯著的典型變量;
c) 比較剩余鐵水質量參數的典型變量與各個高爐主體參數之間的系數,保留絕對值較大的幾個對應的高爐本體參數;
d) 對步驟c) 中保留下來的高爐本體參數進行相關性分析,在相關性達到80%以上的變量中,選取可控的參數變量予以保留;
e) 將步驟d) 中保留下來的可控變量全部用作控制變量,用MPSA 分析控制器偽雅可比矩陣初值的靈敏度,若某個控制變量對應所有鐵水質量輸出的偽雅可比矩陣初值均不靈敏,則分別進行保留該控制變量和去除該控制變量的設定值跟蹤在線控制實驗,比較兩組實驗的跟蹤效果及累計跟蹤均方根誤差,若去除控制變量后的跟蹤效果與保留變量下的跟蹤效果相近且累積跟蹤均方根誤差沒有明顯增大,則認為該控制變量對控制器的貢獻度較小,刪除該控制變量.
經過步驟a)~d) 的篩選,4 個可控變量被予以保留,分別為冷風流量、壓差、富氧流量和設定噴煤量.其中冷風流量、富氧流量在步驟e) 的分析中發現其在控制器中對應的偽雅可比矩陣初值經靈敏度分析均不靈敏,且對控制效果影響較小,因此舍棄掉這兩個變量.為此,最終控制輸入選取為壓差和設定噴煤量,控制器輸入維度m確定為2.
為了保證偽雅可比矩陣矩陣為嚴格對角占優矩陣,需要保證第一個控制量u1與第1 個鐵水質量參數[Si] 的相關性、第二個控制量u2與第2 個鐵水質量參數MIT 的相關性要強于u1與MIT、u2與[Si]之間的相關性.為此,采用灰色關聯分析方法[33]分析了輸入輸出之間的關聯度,結果如表1 所示.
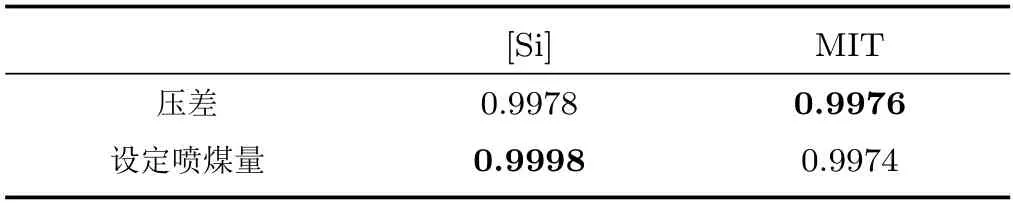
表1 輸入輸出灰色關聯系數Table 1 Grey correlation coefficients between input and output
由表1 容易看出壓差與MIT 的關聯性相對更高,設定噴煤量與[Si] 的關聯性相對更高,為此將設定噴煤量作為u1,將壓差作為u2.
3.2 控制器參數靈敏度分析及靈敏參數遺傳優化整定
高爐煉鐵過程鐵水質量CFDL-MFAC 數據驅動控制器需要進行靈敏度分析的控制參數及參數含義如表2 中第1 列、第2 列所示,其設定取值范圍如第3、4 列所示:
Monte Carlo 模擬運行次數設定為N=5000,各參數的累計頻率曲線對比如表2 中第7 列所示,其中“虛線” 累計頻率分布曲線代表“不可接受”的情況,“實線” 累計頻率分布曲線表示“可接受”的情況,兩條曲線的分離程度越大,表示該參數的靈敏度越大.用式(23)計算“可接受”情形的累計頻率曲線與“不可接受” 情形的累計頻率曲線的分離程度DS,如表2 第5 列所示.可以看出,λ,μ,η,α,b1,b2的DS 值均大于0.9,非常不靈敏,因此舍棄掉,只優化相對靈敏的參數ρ和4 個偽雅可比矩陣初值φ11,φ12,φ21,φ22.

表2 CFDL-MFAC 參數表Table 2 Parameters of CFDL-MFAC
采用所提改進遺傳算法進行靈敏參數優化時,懲罰因子κ1,κ2,κ3均設定為20,參數優化設定及收斂過程分別如表3 和圖3 所示,最終控制器參數設置如表2 中第6 列所示.為了使圖像較為清晰,在圖3 中僅繪至改進遺傳算法的收斂代數,基礎遺傳操作是指交叉變異操作,改進遺傳算法在基礎遺傳算法的基礎上增加了大規模變異操作和精英局部搜索操作,改進后的算法在進化了157 代后收斂至1.4877 并退出循環,而基礎遺傳算法在達到最大遺傳代數時仍未收斂,適應度值為1.6249,將改進算法157 代中每一代最優個體的來源通過四種不同的符號標記了出來,并對四種來源進行統計分析,繪制了如圖4 所示的餅狀圖,其中69 次迭代的最優個體來源于父代成員是由于在此次進化中三種遺傳操作均為找到更優的個體.由圖4 可以看出,新引入的大規模變異及精英局部搜索操作為算法收斂過程中提供了很大占比的最優個體,加快了算法的收斂過程,提高了算法的搜索能力,因此該兩項遺傳操作的提出具有一定的理論意義及應用價值.
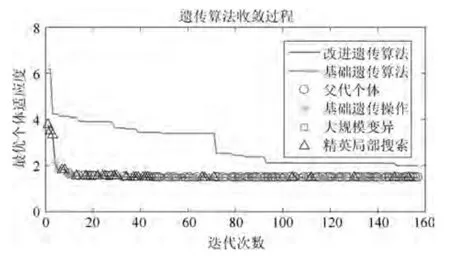
圖3 遺傳算法最優個體收斂過程Fig.3 Optimal individual convergence process of GA
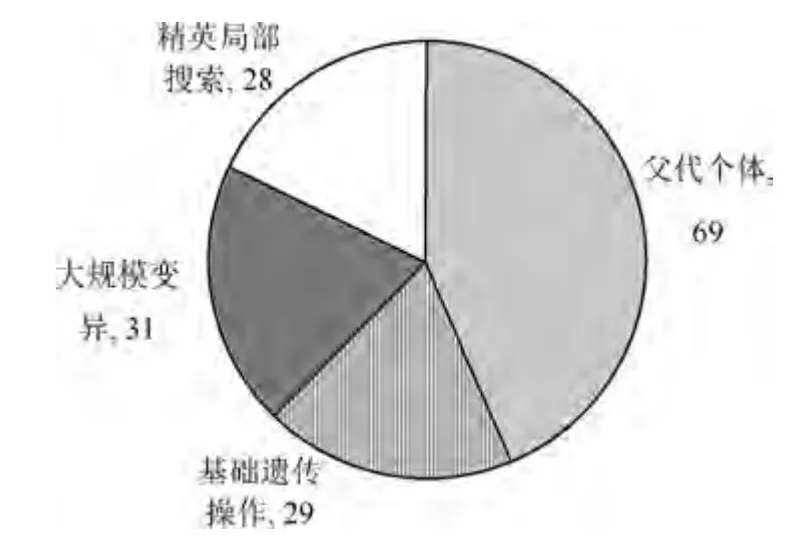
圖4 最優個體來源統計圖Fig.4 Optimal individual source statistics

表3 GA 參數設定Table 3 Set value of GA parameters
3.3 在線控制實驗
CFDL-MFAC 數據驅動控制器參數優化整定后,進行兩組多元鐵水質量參數的在線控制實驗,一組為方波擾動下的設定值跟蹤實驗,另一組為正弦擾動下的設定值跟蹤實驗.為了更加直觀地展示所提控制策略的控制效果,兩組實驗均與文獻[28] 中所提基于遞推子空間辨識的數據驅動預測控制(Data-driven predictive control based on recursive subspace identification,RSMI-DPC) 方法進行對比.結合本文第3.2 節中所提的基于遺忘因子的多元鐵水質量遞推子空間動態模型建立方法,利用柳鋼2# 高爐實際運行數據來建立高爐鐵水質量輸出系統作為被控對象,選取任意三個時刻的動態模型參數如下:
觀察上述3 組參數可以發現,參數隨著時間的推移在緩慢變化,能夠較為充分地反映出高爐系統的慢時變動態特性.
為了模擬真實高爐系統,在動態模型預測出的高爐輸出信號上人為加入均值為0,方差為0.02 的偽隨機數來模擬傳感器信號采集混入的高斯白噪聲.本文測試了控制系統對階躍信號的跟蹤能力,設定鐵水硅含量y1初始設定值為0.45,鐵水溫度y2初始設定值為1490°C;在k=60 時刻給予y1設定值+0.2%的階躍跳變信號;在k=90 時刻給予y2設定值+30°C 的階躍跳變信號.分別針對方波擾動和正弦擾動進行抗干擾性能測試,在跟蹤上述階躍信號的基礎上分別加入幅值為0.07%、頻率為0.01的方波負載擾動和幅值為7°C、角頻率為0.01π的正弦負載擾動,觀察控制器能否保持穩定并平穩地由一個動態工作點過渡到另一個動態工作點,兩組測試結果及偽雅可比矩陣變化曲線分別如圖5 和圖6 所示.由于過程擾動一般與輸出量數值幅度不相同,為了能夠較為清晰地反映出過程外部擾動下設定值跟蹤曲線的變化趨勢,將外部擾動曲線的數值加上歷史數據均值,即[Si] 含量擾動曲線數值加上0.53%,MIT 擾動曲線數值加上1510°C,并與設定值跟蹤曲線繪制在同一張圖上.

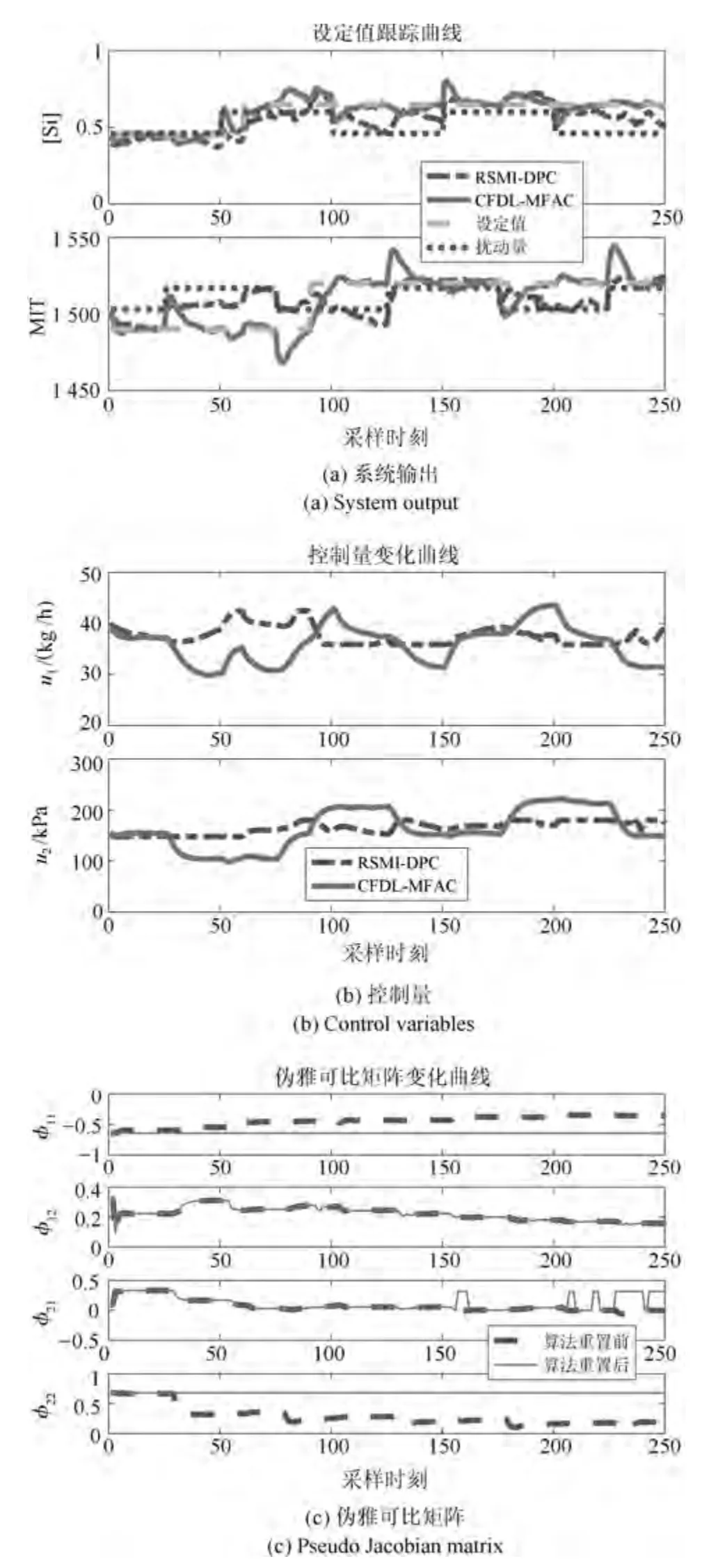
圖5 方波干擾測試Fig.5 Square wave disturbance test

圖6 正弦干擾測試Fig.6 Sinusoidal disturbance test
從圖5 和圖6 可以看出,對比文獻[28] RSMIDPC 方法控制下的鐵水質量指標在方波擾動下始終在相應設定值附近浮動,很難收斂到設定值.在正弦擾動下,RSMI-DPC 方法無法使得實際鐵水質量輸出較好地跟蹤設定值,始終存在較大的控制誤差,而所提基于MPSA 以及改進遺傳優化的CFDLMFAC 方法控制下鐵水質量指標在方波干擾切換的瞬間會有較大幅度的跟蹤誤差,但是控制誤差能夠逐漸收斂,始終跟隨設定值的變化趨勢,并且受低頻正弦擾動的影響很小,始終保持著穩定跟蹤.此外,表4 給出了兩種控制方法更新一次控制量的平均運行時間和兩類外部干擾下的鐵水質量設定值跟蹤均方根誤差(Root-mean-square error,RMSE).從表中可以看出,所提改進CFDL-MFAC 方法不僅設定跟蹤誤差要比文獻[28] 所提RSMI-DPC 方法小很多,計算速度也要快出3 個數量級.即所提方法具有快速、準確和穩定的在線控制性能.
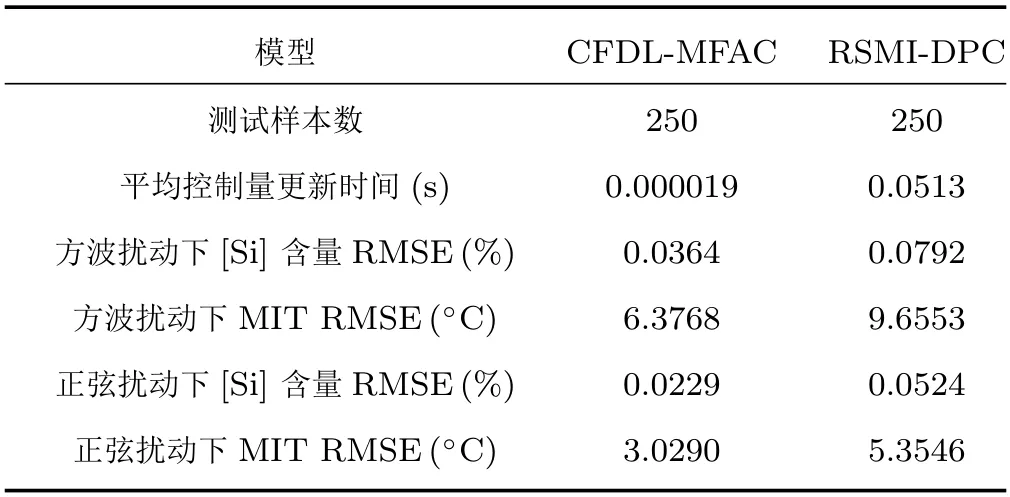
表4 控制器性能對比Table 4 Control performance comparision
4 結論
針對難以采用常規基于模型的方法進行高爐多元鐵水質量建模與控制的難題,改進和完善基于緊格式動態線性化的無模型自適應控制(CFDLMFAC) 方法,提出一種基于多參數靈敏度分析與大規模變異與精英局部搜索遺傳優化的CFDLMFAC 直接數據驅動控制方法.通過多參數靈敏度分析方法分析了CFDL -MFAC 控制器眾多關鍵參數的靈敏度,并根據遺傳算法的思想設計了靈敏參數校正算法,同時在基本遺傳算法的基礎上增加了大規模變異和精英局部搜索的遺傳操作.基于實際工業數據的實驗結果表明,所提出的改進遺傳操作提高了優化算法的搜索能力及收斂速度.用該方法整定了控制器的參數,使其適應工程實際需求,并利用實際工業高爐數據進行了數據實驗,與已有文獻的RSMI-DPC 方法進行對比.結果表明所提改進CFDL-MFAC 直接數據驅動控制方法不僅能夠達到很好鐵水質量控制性能,而且優于RSMI-DPC方法,尤其在在線控制的運算速度、抗干擾性能以及設定值跟蹤等方面,有著顯著優勢.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
汽車觀察(2016年3期)2016-02-28 13:16:26
Coco薇(2015年1期)2015-08-13 02:47:34
