基于遷移學習和預訓練技術的推理機器閱讀理解模型
2022-01-11 09:42:14薛匯泉方建安
現代計算機 2021年32期
薛匯泉,方建安
(東華大學信息科學與技術學院,上海 201620)
0 引言
機器閱讀理解[1]是自然語言處理領域中一項重要任務,在搜索引擎、智能問答和對話系統等領域具有廣泛的應用場景,是一項評估計算機是否真正理解自然語言并具備一定的邏輯推理能力的任務。按照答案形式的不同,Chen 等[2]將機器閱讀理解分為完型填空式、多項選擇式、跨度抽取式和自由答案形式四種任務。本文關注多項選擇式機器閱讀理解[3],該任務需要在給定上下文、問題和候選答案集下,輸出正確的答案,通常需要更高級的閱讀理解技能,如邏輯推理、歸納演繹等,常用的評估指標是準確度。
目前,機器閱讀理解領域中主流的研究方法是預訓練語言模型技術[5],如BERT[6]、Ro-BERTa[7]等預訓練語言模型,其中,RoBERTa 相比于BERT,在模型參數量、訓練資源上都有一定的增強,更具魯棒性和高效性。然而,受限于數據樣本的不足,強大的預訓練語言模型在需要邏輯推理能力的多項選擇閱讀理解數據集上的表現較差。因此,考慮通過豐富預訓練語言模型能學習到的邏輯推理知識來增強模型的推理能力。選擇LogiQA[8]數據集作為目標數據集,該數據集收集自中國國家公務員考試。相較于其他閱讀理解數據集,LogiQA 不依賴于外部知識,文本短小精悍,更專注于邏輯推理。表1 是來自LogiQA 數據集的兩個典型例子,一個完整的樣本由上下文、問題、候選答案集和正確答案組成。首先,復現了LogiQA 的原始論文中發布的最佳基準模型,并在開發集中進行了細致的參數調優,也同樣實驗了不同輸入組合下,模型在開發集中的表現。接著,提出的模型經過一個答案選擇器在多個不同粒度的域外數據集上進行微調,使用滑動窗口方法可以解決緩解過長文本輸入情況下導致計算機的顯存不足問題,模型在不同窗口大小和步長值的實驗表明多次閱讀部分重疊的同一上下文的不同片段能增強模型的邏輯能力。最后,使用數據擴充技術,將經過遷移學習方法微調得到的模型在目標數據集與擴充的數據集上進行多任務學習,最終在目標數據集的開發集上取得了最佳表現。
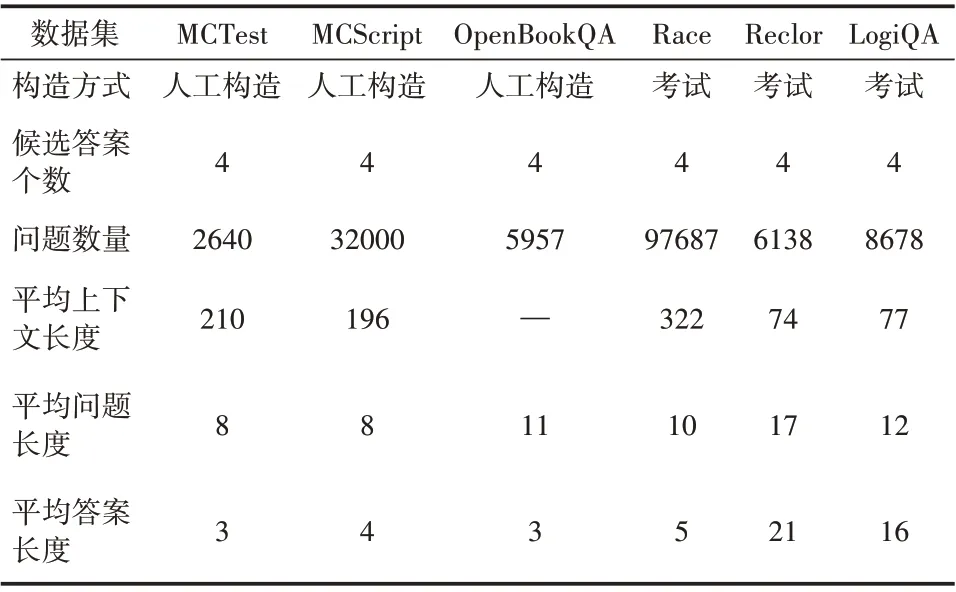
表1 數據集統計信息

表1 LogiQA數據集中的典型例子
1 相關工作
1.1 預訓練+微調
預訓練技術的出現使得自然語言處理進入了一個新的時代,語言模型先在大規模無監督文本語料庫上進行預訓練再在目標任務上微調的方法已成為自然語言處理領域中的主流方法。Dai等[9]使用預訓練技術改進了循環神經網絡中序列學習方法,在多項文本分類任務中取得了不錯的效果;Devlin 等[6]提出的BERT 模型開創了預訓練+微調方法的先河;Khashabi 等[10]構建了一個統一的預訓練自動問答任務框架,在四種不同格式的問答任務下多個數據集上表現良好。基于預訓練語言模型BERT[6]和RoBERTa[7]重新實現了LogiQA[8]原論文中發布的基準模型以及最佳表現,并進行細致的超參數調優;提出了一個基于Ro-BERTa 語言模型的推理閱讀理解模型,該模型能在一定精度下自動輸出一批給定的邏輯推理問題的答案。
1.2 遷移學習VS多任務學習
遷移學習是指將一個或多個任務上學習到的知識或模式應用到某個與之相關的領域中,從而加快模型的訓練效率。關于遷移學習方法的研究最早可追溯到2014 年,Yosinski 等[11]研究了神經網絡中的各層特征與權重參數的可遷移性。Min等[12]通過實驗證明了遷移學習方法有助于提升語言模型在問答數據集上的表現。多任務學習則是要求模型將相互關聯的多個任務同時學好,達到舉一反三的效果。Argyriou 等[13]發布的跨多任務共享學習方法上的實驗結果表明當任務相關時,多任務學習相較于單任務學習能顯著提升模型的表現。復現了LogiQA 原始數據集中提出的遷移學習方法,通過設置不同的隨機種子,提出的模型在四個具有代表性的多項選擇式閱讀理解數據集上進行充分的預訓練,收斂后的遷移學習模型再在源數據集和目標數據集上進行多任務學習。
1.3 邏輯推理數據集
大規模閱讀理解數據集的發布在極大程度上推動了機器閱讀理解模型的不斷建立,促進了機器閱讀理解領域的進步。多項選擇式閱讀理解任務受到人類語言能力考試的啟發而發布。MCTest數據集[14]和MCScript 數據集[15]以兒童故事書為藍本,包含了大量需要使用常識知識進行推理的問題;OpenBookQA 數據集[16]探索了計算機對某一主題的深入理解;Race[17]數據收集了中國中學生英語考試的相關內容。然而,上述數據集都或多或少地依賴于外部知識和簡單的詞匯匹配。Reclor[18]數據集的來源是研究生入學考試,且專注于邏輯推理問題,在許多方面都與LogiQA 很相似。選擇MCTest、MCScript、OpenBookQA、Race作為域外數據集參與到模型第一階段的訓練過程,在此過程中,模型習得的知識能在一定程度上能提升模型的泛化能力。將LogiQA 數據集作為目標數據集,Reclor 數據集作為源數據集,與LogiQA 數據集共同參與到模型第二階段的多任務學習過程,以豐富模型所能獲取到的邏輯推理知識和經驗。
2 模型
2.1 任務定義
給定上下文C、問題Q以及候選答案集A={A1,A2,…,An},n為候選答案的個數,Ai∈A,表示第i個候選答案項,多項選擇式閱讀理解的任務旨在從候選答案集A中選擇出正確選項Ai。該任務要學習的函數或模型為F,見公式(1)。
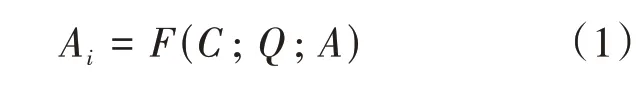
2.2 模型架構
基于RoBERTa 預訓練語言模型,提出的推理閱讀理解模型架構如圖1 所示,主要由輸入層、嵌入層、編碼層、分類層以及答案選擇層組成。模型將給定一組樣本輸入下編碼層得到的高維特征向量與分類層輸出的答案向量進行殘差連接[19]以解決訓練過程中出現的梯度消失和梯度爆炸問題;模擬人類在做邏輯推理類題目時會在做出初步推理判斷后再次比對候選答案,以給出最終的答案選擇的過程,模型在答案選擇層中融合了候選答案輸入下的編碼信息與經過分類層輸出的答案信息;使用滑動窗口方法,設置不同的窗口大小和步長值,將目標數據集中所有樣本的上下文切分成部分重疊的長度相同的不同段,與問題和候選答案一起送入到模型的輸入層當中,以解決模型不能吸收完整的樣本內容導致答案預測效果不佳的問題。
(1)輸入層。模型的輸入層通過組織樣本的表達形式以滿足模型的輸入要求。記給定上下文分詞后的單詞序列為C(c1,c2,…,cn),n為上下文長度; 給定問題分詞后的單詞序列為Q(q1,q2,…,qm),m為問題長度;給定候選答案集A(Ai∈A)中第i個答案項分詞后的單詞序列為Ai=(ai1,ai2,…,aik),長度為k。分別使用和 作為輸入的起始標志和分割標志或結束標志。給定數據集中的任一樣本,模型的輸入層包含兩個獨立的模塊。如式(2)所示,模塊一將樣本中的部分上下文、問題和一個候選答案連接成一個長句子T1,通過和標志分隔開來,其中,部分上下文取自樣本中上下文經過滑動窗口方法得到的不同塊。模塊二的輸入則僅包含候選答案信息,兩端添加起始標志和結束標志,見式(3)。
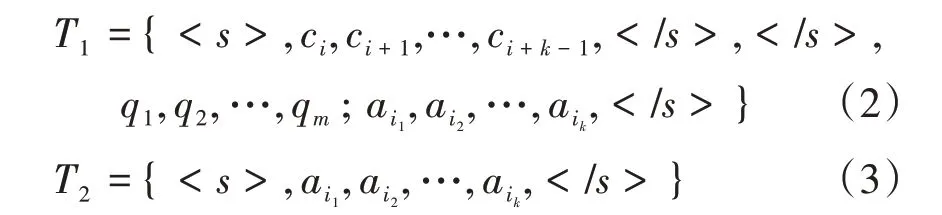
(2)嵌入層。嵌入層的作用是將自然語言轉換為模型可以理解的詞嵌入向量以便進行后續的編碼,使用RoBERTa 語言模型中的分詞器將輸入層中的每一個單詞都映射到一個高維空間當中,以獲得該單詞唯一的向量表示。圖2 展示了輸入層文本T1經由嵌入層得到的最終特征向量EA={E1,E2,…,EL}。其中,EA∈RL×d,L表示向量的長度,該向量由對應的詞嵌入向量、句子嵌入向量以及位置嵌入向量的級聯組成。同理可得輸入層文本T2經由嵌入層得到的最終特征向量EB。
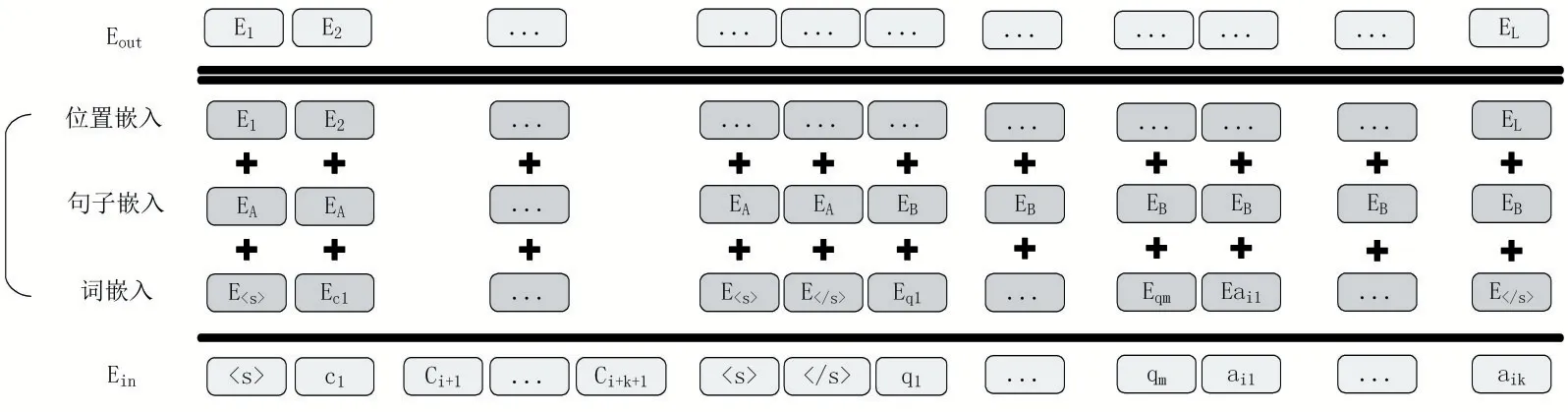
圖2 T1輸入下嵌入層的最終向量表示
(3)編碼層。編碼層利用RoBERTa-large 模型中的Transformer 結構[20],對經嵌入層得到的嵌入向量E={}E1,E2,…,EL進行深層次編碼,且只使用該Transformer 結構的編碼器模塊。該編碼器模塊由N個相同的編碼器組成,每個編碼器都由一個多頭自注意力機制和一個全連接前向反饋神經網絡組成,除最后一個編碼器外,每個編碼器的輸出作為下一個編碼器的輸入。RoBERTalarge模型共有24層Transformer編碼器,每個編碼器輸出對應著嵌入層輸入向量的不同特征表達,且各個編碼器的周圍都有一個“殘差連接”[19]以及一個“層歸一化”機制[21]。如式(4)和式(5),將各個編碼器輸出向量的加權求和作為編碼層的輸出。其中,En∈Rd為編碼層的最終輸出,El∈Rd(l= 2,3,…,N)為每個編碼器的輸出向量,E1為第一個編碼器的初始輸入向量,該輸入向量來自于嵌入層的輸出。d表示向量的維度大小,l為當前編碼器的序號,N為編碼器的數量,Wl∈Rd為當前編碼器的權重參數。RELU 表示激活函數,計算公式見式(6)。LayerNorm[21]和Multihead[5]分別表示“層歸一化”和“多頭自注意力機制”。


(5)答案選擇層。如公式(8),答案選擇層將分類層輸出的答案概率向量與編碼層的輸出向量進行殘差連接,再經過Softmax“歸一化”函數后輸出給定樣本的正確答案Answer。W1和W2是權重參數,W1,W2∈Rd+1,d表示向量的維度,“⊕”表示殘差連接。模型訓練時的損失函數如式(9),N表示候選答案集的大小,模型的訓練目標就是最小化損失函數Loss的值。
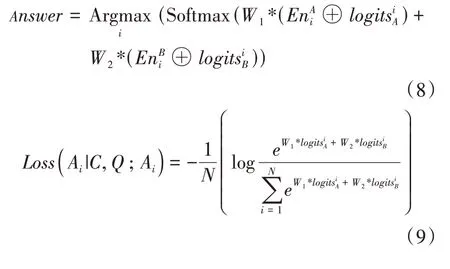
3 實驗及分析
3.1 實驗數據
提出的模型首先在MCTest、MCScript、Open-BookQA 和Race 上進行充分的微調,再在目標數據集LogiQA 和源數據集Reclor 上進行多任務學習。數據集的統計信息見表2,由于OpenBookQA數據集只有問題和候選答案項,故該數據集下的平均上下文長度置空。LogiQA 數據集共包含8678個問題。
模型的表現使用準確度作為評估指標,計算公式見公式(9),N+和N分別表示模型預測正確的題目數量和總的題目數量。
3.2 實驗細節
模型訓練時,先固定好一個隨機種子,再對多種不同的超參數組合進行了多次實驗,并記錄下在目標數據集的開發集上的表現,最佳表現對應的超參數組合見表3,其中,max_grad_norm 用來約束參數的梯度值,防止訓練過程中出現梯度爆炸問題。max_input_size 規定了模型所能接收的最大輸入文本長度,超過該長度的文本內容會被截斷。使用的實驗平臺是Windows 10 家庭中文版,處理器型號為Intel(R)Core(TM)i7-9700K CPU @ 3.60 GHz 3.60 GHz,顯卡為NVIDIA Ge-Force RTX 3060,顯存容量為12 GB,深度學習框架選擇Pytorch 1.8。
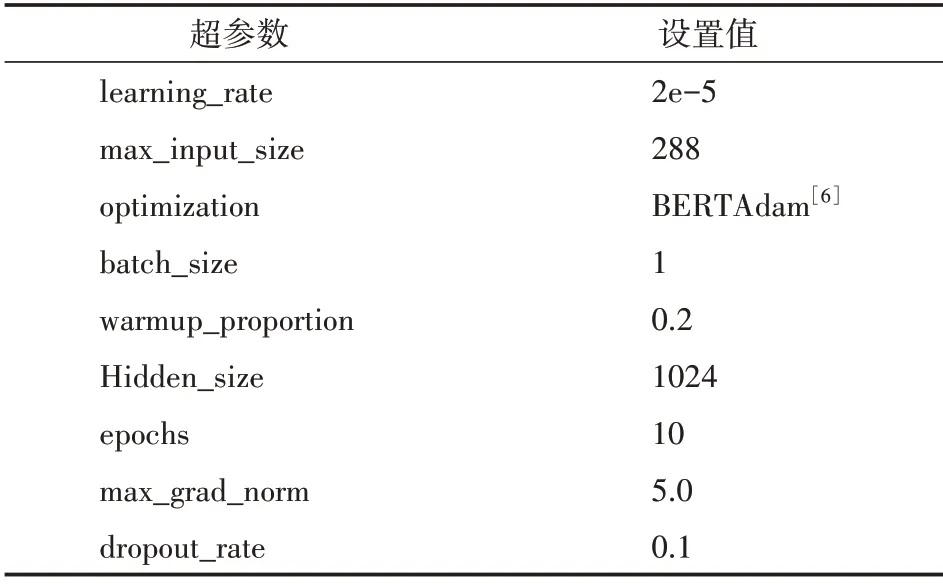
表3 超參數設置
3.3 實驗結果及分析
基于BERT 和RoBERTa 預訓練語言模型重新實現了LogiQA 數據集原始論文中使用的預訓練方法。實驗結果如表4 所示,表頭中的開發集上的準確度選項計算公式見公式(9)。經過細致的參數調優,重新實現的方法相比于原論文發布的基于預訓練技術的最佳表現,在目標數據集LogiQA的開發集上的準確度分別提高了約4%和5%,且RoBERTa 模型相比于BERT 模型在開發集上的推理效果更佳,準確度達到了40%,后續的實驗均基于RoBERTa模型。

表4 LogiQA原論文發布的最佳表現與本文復現后的表現
受限于機器顯存容量的不足,模型可接受最大輸入文本長度是288,考慮使用滑動窗口方法,通過選取不同的窗口大小值和步長值,對所有樣本中的上下文切分成同一長度的不同文本段,以提升模型在目標任務上的推理效果。基于Ro-BERTa 模型實驗了不同輸入組合下,模型在目標數據集的開發集中的表現,并單獨實驗了在給定上下文、問題以及候選答案集下,不同窗口大小和步長值對模型表現的提升效果,實驗結果見表5。結果表明目標數據集中上下文、問題以及候選答案項三者之間的邏輯交互與內在聯系是真實存在且至關重要的。后續的實驗將固定滑動窗口大小和步長值為288和50。
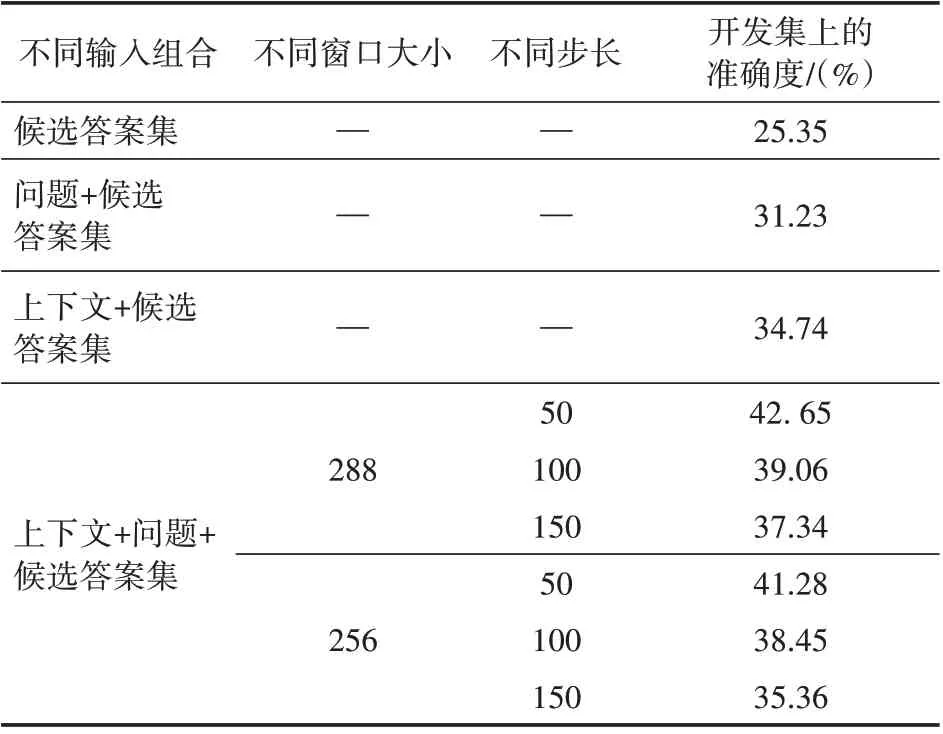
表5 不同輸入組合和窗口大小下,RoBERTa模型的表現
在復現了目標數據集原論文中使用的預訓練方法的基礎上,提出的模型在目標任務上的分解消融實驗見表6。
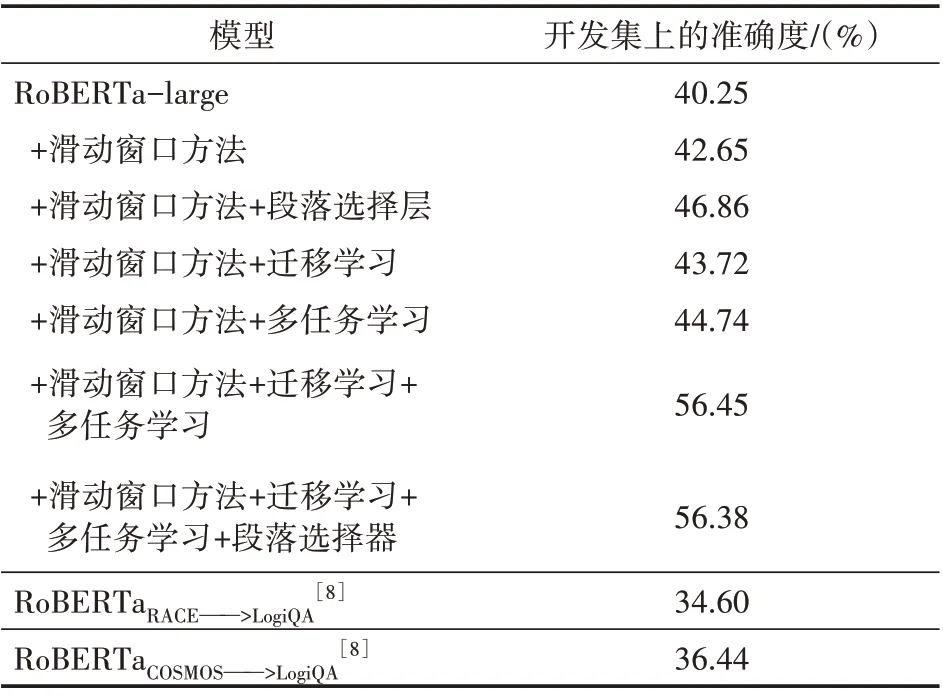
表6 模型的在目標數據集上的最終表現與分解消融實驗
表格的最后兩行取自原論文中發布的遷移學習方法的結果,RoBERTaRACE——>LogiQA和Ro-BERTaCOSMOS——>LogiQA分別表示將模型先在Race 數據集或者COSMOS 數據集[22]上進行訓練,再在目標數據集上微調,而COSMOS 是基于常識推理的多項選擇式閱讀理解數據集。段落選擇層對于模型的最終表現提升最大,提高了約7%左右,這說明引入的問題編碼信息有利于模型的最終推理;使用Reclor 作為源數據集與目標數據集LogiQA 進行多任務學習的方法的效果略高于遷移學習方法,達到了44.74%的準確度。最終模型在目標數據集的開發集上的最佳表現達到了56.38%的準確度,相比于原論文中發布的最佳表現提升了約54.72%,證明了方法的有效性。
4 結語
針對當前最新的機器閱讀理解模型在推理閱讀理解數據集上普遍表現不佳的問題,在預訓練語言模型的基礎上,提出了基于遷移學習和預訓練技術的推理閱讀理解模型,使用滑動窗口方法解決了模型無法一次性吸收過長的輸入文本的問題,段落選擇器可以幫助模型在進行答案選擇時做出正確的邏輯判斷。模型在需要邏輯推理能力的閱讀理解數據集LogiQA 上取得了當前的最佳效果,這表明模型具備了一定的邏輯推理能力。未來的研究工作將進一步考慮在模型內部研究上下文、問題與答案項之間的邏輯交互,并將交互信息編碼進模型的段落選擇層中,進一步提升模型的邏輯推理能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
