遺傳算法的神經網絡在醬油分類建模中的應用
2022-01-12 02:34:56蔡炳育楊帆
中國調味品 2022年1期
蔡炳育,楊帆
(1.蘇州工業園區服務外包職業學院,江蘇 蘇州 215123;2.貴州財經大學,貴陽 550025)
醬油是日常生活中的必需品,醬油風味物質是影響醬油品質的關鍵性因素[1]。醬油的生產方式主要包含高鹽稀態發酵和低鹽固態發酵,醬油主要生產地區處于我國東部、南部和北部地區[2]。不同生產地區生產的醬油所用原材料存在較大差異,由此造成醬油的揮發性風味物質也存在較大的差異,因此對醬油揮發性風味物質的研究分析可間接鑒別醬油的生產地區和生產方式[3]。本文利用神經網絡建立醬油分類模型,以醬油揮發性風味物質為輸入參數,以醬油生產地區和發酵方式為輸出參數,對醬油進行兩種不同的分類,為進一步提高醬油生產地區和釀造方式的鑒別過程提供了參考。
1 遺傳算法與神經網絡
神經網絡包含輸入層、隱含層和輸出層,每一層級中包含若干神經元,各個神經元之間相互形成網絡狀拓撲結構,進行神經網絡之間的信息發送與接收,神經網絡中的信號脈沖強度由信號加權系數決定[4-6]。神經元是神經網絡中的基本結構單元,是一種非線性閾值處理器,可進行多信號輸入,經處理后形成單輸出。其中a1、a2、……an表示N組輸入信號,W1、W2、……Wn表示與輸入信號相對應的加權系數,SUM表示信號輸入總和,b表示閾值調整常數,f表示神經元閾值處理函數,t表示輸出信號。
遺傳算法是一種智能進化算法,通過自然界中的啟發搜索方式進行參數選擇,并進行過程優化,從而提供有效的算法方案[7]。遺傳算法優化后的數學解轉化成數字串,并進行重新編碼形成新的個體,遺傳算法的迭代過程利用生物進化的相關過程操作不斷進行迭代,計算個體之間的適應度函數,并取代上一代個體,完成一次獨立的遺傳迭代[8-10]。迭代過程重復進行,直到生成新的適應度,每一次迭代過程相互交叉變異,在所有空間中進行全局搜索,使每一個新個體都能形成最優解[11]。
2 遺傳算法神經網絡對醬油發酵方式的分類建模
采用遺傳算法對神經網絡結構進行優化時,將78組醬油樣品進行分組,其中一組用來進行網絡訓練,包含63組數據,稱為訓練集,另外一組用來進行模型網絡測試,包含15組數據,稱為測試集[12]。本文通過利用神經網絡對醬油的發酵方式和生產地區進行分類,在建立發酵方式分類模型時,以靈敏度分析使用的28組揮發性成分和維度降低后的15種揮發性成分作為模型輸入參數,高鹽稀態和低鹽固態作為兩種輸出參數進行發酵方式分類。
利用神經網絡進行數據訓練之前,對輸入數據進行預處理,將檢測得到的揮發性成分含量進行歸一化處理,將所有數據進行壓縮,使其數值處于[-1,1]之間,獲取訓練輸出數據之后再將數據進行恢復,加速神經網絡訓練速率和精度。在進行發酵方式輸出數據訓練之前,將數據進行量化處理,生成二進制字符串編碼,高鹽稀態發酵方式表示為[-1,0],低鹽固態發酵方式表示為[0,1]。
3 遺傳算法神經網絡對醬油生產地區的分類建模
與發酵方式分類模型類似,對醬油發酵地區進行分類時,同樣使用靈敏度分析使用的28組揮發性成分和維度降低后的15種揮發性成分作為模型輸入參數,東部地區、南部地區以及北部地區作為3種輸出參數進行發酵地區分類。發酵地區分類數據量化處理時,東部地區表示為[0,1,0],南部地區表示為[0,0,1],北部地區表示為[1,0,0]。
4 分類模型性能評估
對訓練數據進行學習,采用遺傳算法對神經網絡進行優化,優化參數見表1。使用維度降低前的28組揮發性成分進行醬油發酵方式的分類,使用15組測試集數據的識別正確率來驗證醬油發酵方式分類模型效果,模型正確率驗證測試結果見表2。維度降低后,對訓練數據進行學習,采用遺傳算法對神經網絡進行優化,優化參數見表3。使用維度降低后的15組揮發性成分進行醬油發酵方式的分類,使用15組測試集數據的識別正確率來驗證醬油發酵方式分類模型效果,模型正確率驗證測試結果見表4。

表1 維度降低前模型優化參數(發酵方式)Table 1 Model optimization parameters before dimension reduction (fermentation mode)
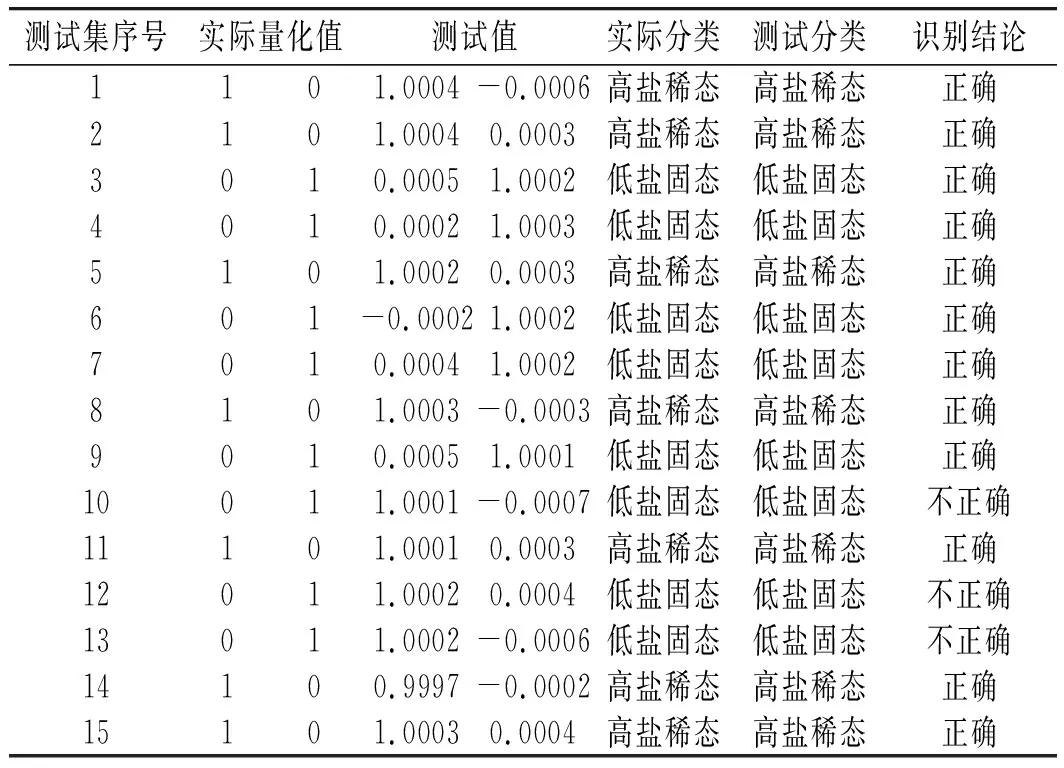
表2 維度降低前模型正確率測試結果(發酵方式)Table 2 Model accuracy test results before dimension reduction (fermentation mode)

表3 維度降低后模型優化參數(發酵方式)Table 3 Optimization of model parameters after dimension reduction (fermentation mode)
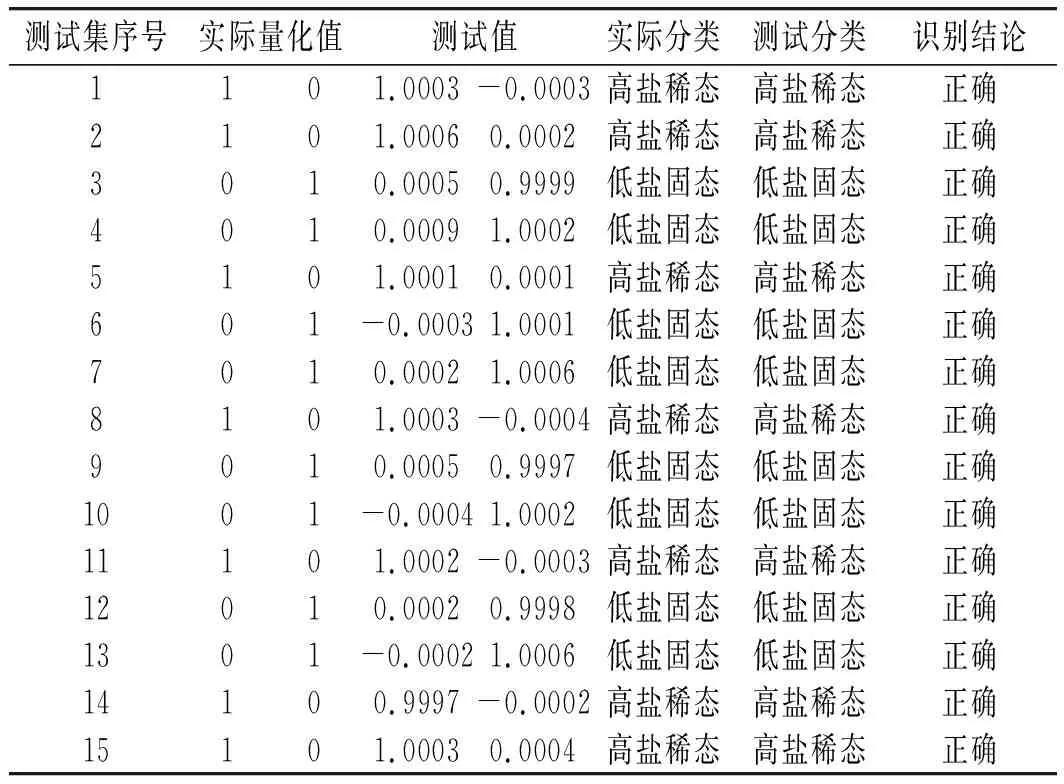
表4 維度降低后模型正確率測試結果(發酵方式)Table 4 Model accuracy test results after dimension reduction (fermentation mode)
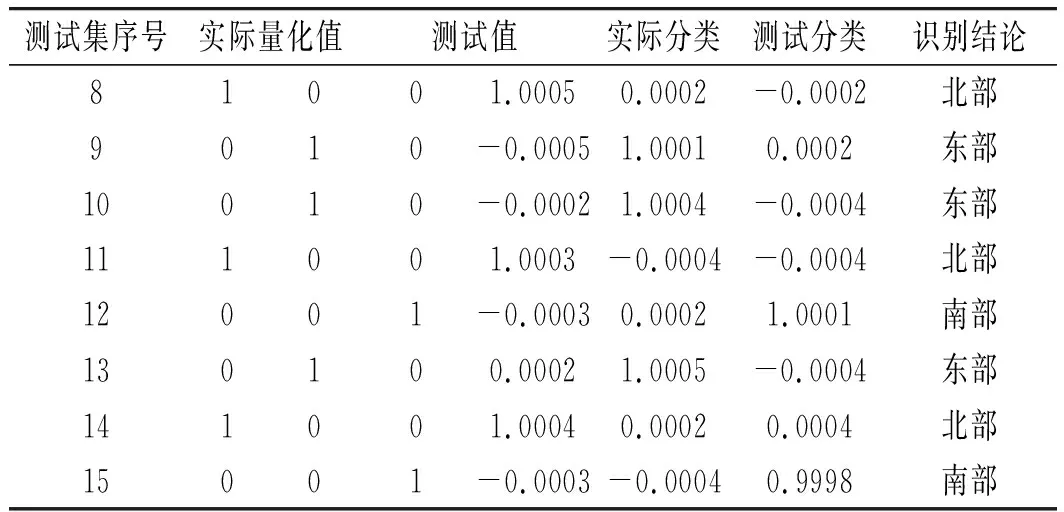
對訓練數據進行學習,采用遺傳算法對神經網絡進行優化,優化參數見表5。使用維度降低前的28組揮發性成分進行醬油生產地區的分類,使用15組測試集數據的識別正確率來驗證醬油生產地區分類模型效果,模型正確率驗證測試結果見表6。維度降低后,對訓練數據進行學習,采用遺傳算法對神經網絡進行優化,優化參數見表7。使用維度降低后的15組揮發性成分進行醬油生產地區的分類,使用15組測試集數據的識別正確率來驗證醬油生產地區分類模型效果,模型正確率驗證測試結果見表8。

表5 維度降低前模型優化參數(生產地區)Table 5 Model optimization parameters before dimension reduction (production area)
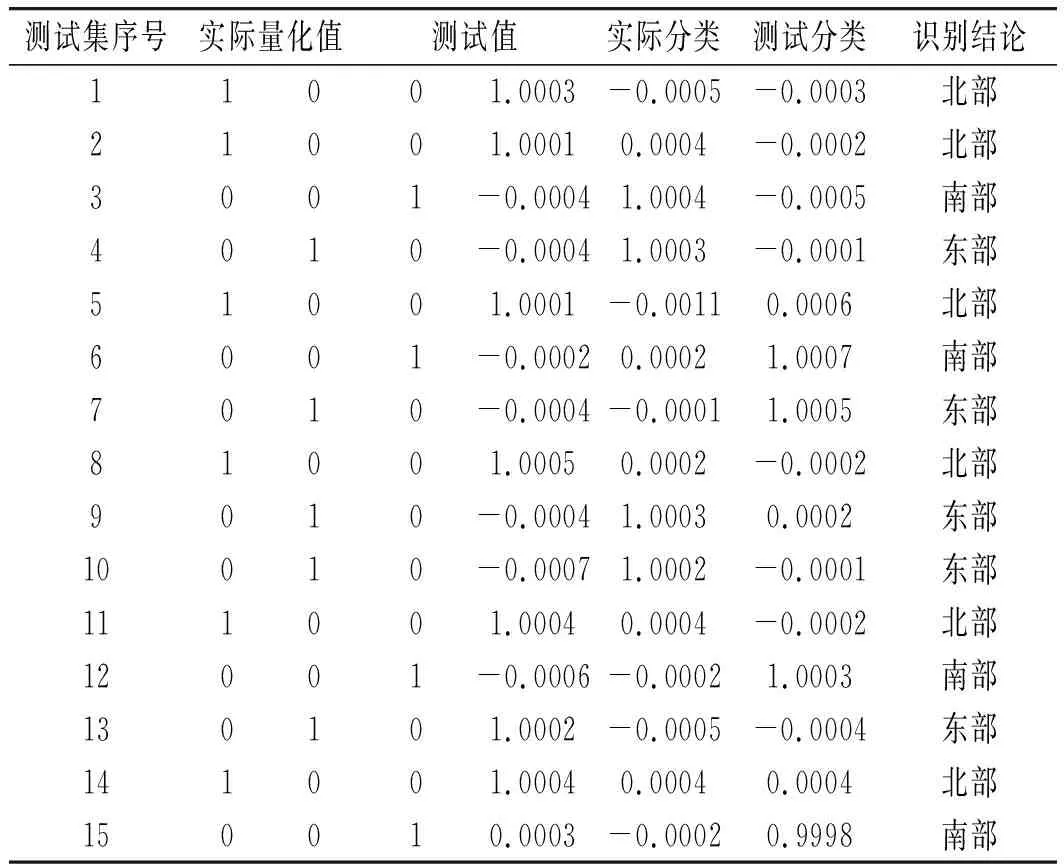
表6 維度降低前模型正確率測試結果(生產地區)Table 6 Model accuracy test results before dimension reduction (production area)

表7 維度降低后模型優化參數(生產地區)Table 7 Model optimization parameters after dimension reduction (production area)
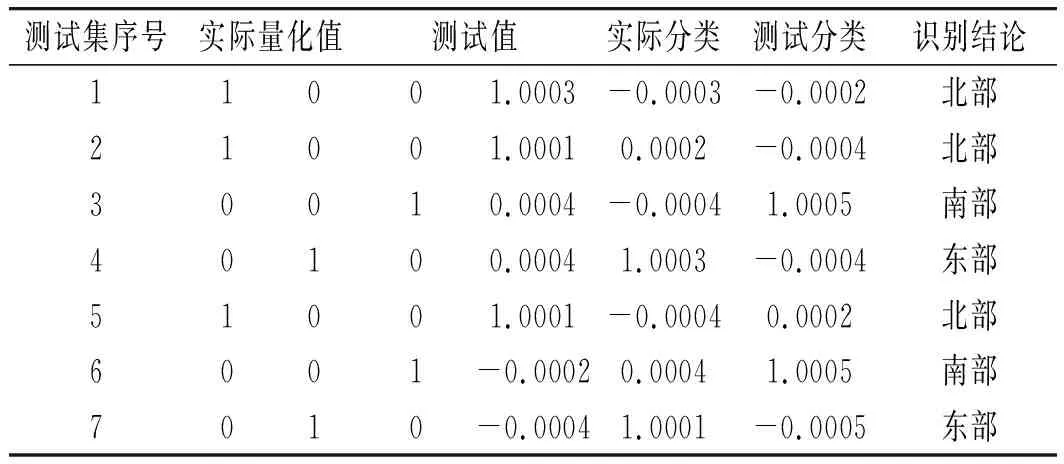
表8 維度降低后模型正確率測試結果(生產地區)Table 8 Model accuracy test results after dimension reduction (production area)
續 表
由表6和表8中數據可知,維度降低前,測試集數據識別正確率達到80%,表明醬油發酵方式分類模型和生產地區分類模型可基本滿足分類性能要求。維度降低后,測試集數據識別正確率達到100%,表明醬油發酵方式分類模型和生產地區分類模型可精確進行醬油發酵方式分類。
5 結論
本文利用遺傳算法和神經網絡相結合的方式,建立醬油發酵方式分類模型和醬油生產地區分類模型,并利用遺傳算法進行神經網絡結構優化,使分類模型識別精確度達到100%,為醬油發酵方式及生產地區的分類鑒別提供了理論論依據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
