用于自動(dòng)駕駛車(chē)輛的融合注意力機(jī)制多目標(biāo)跟蹤算法
2022-01-13 05:15:42遲志誠(chéng)陳一凡
汽車(chē)安全與節(jié)能學(xué)報(bào) 2021年4期
張 平,遲志誠(chéng),陳一凡,惠 飛
(1. 長(zhǎng)安大學(xué) 汽車(chē)學(xué)院,西安 710064,中國(guó);2. 長(zhǎng)安大學(xué) 信息工程學(xué)院,西安 710064,中國(guó))
近年來(lái),多目標(biāo)跟蹤問(wèn)題(multiple object tracking,MOT)在智能交通、自動(dòng)駕駛等領(lǐng)域受到了大量關(guān)注,并具有重要的應(yīng)用前景[1-2]。例如,對(duì)于道路上行人和車(chē)輛的準(zhǔn)確跟蹤可以幫助自動(dòng)駕駛車(chē)輛做出更好的駕駛決策。要完成多目標(biāo)跟蹤,通常的流程是利用檢測(cè)器檢測(cè)圖像序列中的特征信息,然后跟蹤算法會(huì)基于檢測(cè)結(jié)果將相關(guān)目標(biāo)進(jìn)行關(guān)聯(lián)以實(shí)現(xiàn)目標(biāo)的跟蹤。目前,很多概率推斷模型已經(jīng)應(yīng)用于多目標(biāo)跟蹤中的數(shù)據(jù)關(guān)聯(lián),例如基于多假設(shè)跟蹤(multiple hypothesis tracking,MHT)[3],聯(lián)合概率數(shù)據(jù)關(guān)聯(lián)(joint probabilistic data association, JPDA)[4]等經(jīng)典的多目標(biāo)跟蹤方法,可以捕獲圖像序列中固有的時(shí)序相關(guān)信息。
隨著目標(biāo)檢測(cè)技術(shù)的不斷增強(qiáng),基于此的目標(biāo)跟蹤方法已成為主流框架。在這種以目標(biāo)檢測(cè)為核心的算法中,跟蹤框架的性能極大地依賴(lài)于對(duì)目標(biāo)的有效準(zhǔn)確的檢測(cè)。許多不同的圖像特征描述方法可以提取圖像特征并應(yīng)用于目標(biāo)檢測(cè)中。傳統(tǒng)方法是基于圖像底層特征,通過(guò)訓(xùn)練好的分類(lèi)器將圖像特征進(jìn)行分類(lèi)以確定目標(biāo)信息。
文獻(xiàn)[5]在支持向量機(jī)(support vector machine,SVM)的基礎(chǔ)上增加了自適應(yīng)增強(qiáng)算法(adaptive boosting, AdaBoost)作為粗細(xì)結(jié)合的兩級(jí)檢測(cè)方法以檢測(cè)出復(fù)雜背景下的多姿態(tài)行人目標(biāo)。文獻(xiàn)[6]設(shè)計(jì)將方向梯度直方圖(histogram of oriented gradient, HOG)與SVM結(jié)合的歸一化算法用于行人檢測(cè)方案。HOG可以很好地描述局部目標(biāo)的形狀,這使得該算法對(duì)于一些特定的圖像變化例如光照條件改變是有效的。但是此類(lèi)手工設(shè)計(jì)特征在一些目標(biāo)交互頻繁的復(fù)雜場(chǎng)景中,經(jīng)常會(huì)產(chǎn)生大量的漏檢和誤報(bào)問(wèn)題。
近年來(lái),深度學(xué)習(xí)思想的興起和發(fā)展在多個(gè)計(jì)算機(jī)視覺(jué)相關(guān)領(lǐng)域取得了很好的應(yīng)用,相關(guān)檢測(cè)算法逐漸從傳統(tǒng)的手工設(shè)計(jì)特征提取方法轉(zhuǎn)變成了基于深度學(xué)習(xí)的特征提取算法。SORT算法[7]使用了Faster R-CNN[8]卷積神經(jīng)網(wǎng)絡(luò)對(duì)行人的外觀特征進(jìn)行建模,神經(jīng)網(wǎng)絡(luò)可以直接輸出目標(biāo)的位置和大小,使跟蹤算法可以快速實(shí)時(shí)運(yùn)行。為減少SORT算法中存在的頻繁更換目標(biāo)標(biāo)識(shí)(identity, ID)的問(wèn)題,Deep SORT[9]算法應(yīng)用在行人識(shí)別數(shù)據(jù)集上訓(xùn)練的廣域殘差網(wǎng)絡(luò),降低了跟蹤過(guò)程中ID值變換次數(shù)。文獻(xiàn)[10]在孿生神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)上融合擾動(dòng)感知模型,提高了算法在復(fù)雜場(chǎng)景下的跟蹤精確度。但是僅僅采用外觀特征是不夠的,因?yàn)閰?shù)量的增長(zhǎng)會(huì)帶來(lái)計(jì)算量的大幅增加,而單一外觀特征在一些復(fù)雜的場(chǎng)景下,如相似外觀和頻繁遮擋等情況下就容易受到干擾,無(wú)法正確地對(duì)目標(biāo)做區(qū)分并進(jìn)行有效的跟蹤。
針對(duì)上述多目標(biāo)跟蹤算法存在的一些問(wèn)題,為了進(jìn)一步提高跟蹤過(guò)程的魯棒性和準(zhǔn)確性,本文在目標(biāo)檢 測(cè) 算 法YOLO-v3網(wǎng) 絡(luò)(YOLO為“You Only Look Once”系列算法)[11]的基礎(chǔ)上融合注意力機(jī)制,通過(guò)對(duì)目標(biāo)特征圖的空間和通道兩個(gè)維度的特征施加不同的權(quán)重,在基本不影響實(shí)時(shí)性的前提下改進(jìn)了其對(duì)于關(guān)鍵特征的提取篩選能力,從而提高物體在形變和運(yùn)動(dòng)狀態(tài)改變時(shí)的檢測(cè)效果。
此外,增加了基于長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(long shortterm memory network, LSTM)以提取物體的運(yùn)動(dòng)特征。通過(guò)提取視頻流中幀與幀之間長(zhǎng)期的時(shí)序關(guān)系構(gòu)建目標(biāo)的運(yùn)動(dòng)模型,對(duì)每個(gè)目標(biāo)的軌跡進(jìn)行動(dòng)態(tài)建模。這樣當(dāng)出現(xiàn)僅僅依靠外觀特征無(wú)法正確區(qū)分目標(biāo)或者同一目標(biāo)因?yàn)檎趽鯇?dǎo)致目標(biāo)ID值頻繁變換的問(wèn)題時(shí),運(yùn)動(dòng)特征可以幫助算法正確分配目標(biāo)軌跡。在完成對(duì)象運(yùn)動(dòng)狀態(tài)的回歸和預(yù)測(cè)步驟之后,它們的特征表示將被結(jié)合起來(lái)以對(duì)檢測(cè)結(jié)果和軌跡進(jìn)行匹配,實(shí)現(xiàn)逐幀的目標(biāo)檢測(cè)和跟蹤。
1 多目標(biāo)跟蹤框架
1.1 整體框架
多目標(biāo)跟蹤整體框架如圖1所示。
對(duì)于給定圖像序列,首先進(jìn)入YOLOv3網(wǎng)絡(luò)的外觀特征提取模塊,在網(wǎng)絡(luò)末端的全連接層之前還增加了注意力機(jī)制,目的是為了提高跟蹤的準(zhǔn)確性和穩(wěn)定性;然后,通過(guò)長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)LSTM獲取物體在運(yùn)動(dòng)過(guò)程中的運(yùn)動(dòng)特征,提取時(shí)序相關(guān)特征表達(dá);最后,對(duì)LSTM網(wǎng)絡(luò)的輸出計(jì)算出目標(biāo)的相似度數(shù)值,最終匹配并關(guān)聯(lián)對(duì)象以完成整個(gè)多目標(biāo)跟蹤過(guò)程。
本文整體框架是基于檢測(cè)的多目標(biāo)跟蹤方法,主要任務(wù)包括:目標(biāo)檢測(cè),特征提取,目標(biāo)匹配。研究中將目標(biāo)外觀特征和運(yùn)動(dòng)特征的提取作為跟蹤框架的關(guān)鍵部分。表1給出了多目標(biāo)跟蹤框架中各模塊的輸入以及輸出。

表1 各模塊輸入輸出
1.2 目標(biāo)檢測(cè)
構(gòu)建一個(gè)足夠準(zhǔn)確的外觀模型,對(duì)于目標(biāo)跟蹤問(wèn)題至關(guān)重要。YOLO-v3作為一種基于深度學(xué)習(xí)的檢測(cè)方法,已在計(jì)算效率和識(shí)別精度之間取得了很好的平衡[11]。本文基于該方法并融合后面介紹的注意力機(jī)制設(shè)計(jì)了外觀模型,目的是增強(qiáng)關(guān)鍵特征的提取篩選能力。YOLOv3算法主要由兩部分構(gòu)成,即Darknet-53骨干特征提取網(wǎng)絡(luò)和特征金字塔網(wǎng)絡(luò)。圖2給出了YOLO-v3算法的檢測(cè)流程。輸入的圖像數(shù)據(jù)先經(jīng)過(guò)Darknet-53骨干神經(jīng)網(wǎng)絡(luò)提取特征,再經(jīng)過(guò)金字塔結(jié)構(gòu)預(yù)測(cè)網(wǎng)絡(luò)對(duì)不同尺度目標(biāo)做出預(yù)測(cè)。
YOLO v3的檢測(cè)結(jié)果包括 (x,y,w,h,c,p),其中:x、y為目標(biāo)的位置,w、h為目標(biāo)的寬度、高度,c為置信度,p為目標(biāo)的類(lèi)別概率。置信度的作用是表明圖像中包含目標(biāo)的概率以及預(yù)測(cè)的邊界框位置的準(zhǔn)確性。置信度為
式中:IOU為預(yù)測(cè)候選框與原始真實(shí)框之間的重疊率,
式中:A表示區(qū)域面積,box表示某一方框,truth表示真實(shí)結(jié)果,pred表示預(yù)測(cè)結(jié)果。
預(yù)測(cè)過(guò)程會(huì)產(chǎn)生多余的邊界框,因此在隨后的步驟中,篩選層使用非極大值抑制操作,過(guò)濾掉IOU分?jǐn)?shù)小于閾值的檢測(cè)結(jié)果,選擇重疊度最大的檢測(cè)框作為最終的特征提取框進(jìn)行輸出。
1.3 注意力機(jī)制
通常,卷積神經(jīng)網(wǎng)絡(luò)的卷積運(yùn)算僅考慮局部區(qū)域進(jìn)行操作,感受野的面積受到卷積核的限制。如果想要捕獲更多圖像數(shù)據(jù)則需要通過(guò)堆疊卷積層來(lái)擴(kuò)大感受野,但是太多卷積層會(huì)導(dǎo)致算法的計(jì)算復(fù)雜度提高。引入注意力機(jī)制后,神經(jīng)網(wǎng)絡(luò)將能更關(guān)注目標(biāo)跟蹤任務(wù)的重點(diǎn)信息,提高目標(biāo)檢測(cè)的準(zhǔn)確性。本文采用的卷積模塊的注意力機(jī)制模塊(convolutional block attention module, CBAM)[12]如圖3所示。
在通道注意力的基礎(chǔ)上,進(jìn)一步加入空間注意力機(jī)制,整個(gè)注意力模塊可以從通道和空間兩個(gè)維度對(duì)特征進(jìn)行加權(quán)調(diào)整,定位到目標(biāo)跟蹤任務(wù)的有用信息,抑制目標(biāo)跟蹤任務(wù)的無(wú)關(guān)信息,從而有效應(yīng)對(duì)目標(biāo)跟蹤時(shí)遮擋、形變、光照、運(yùn)動(dòng)狀態(tài)變化等外部因素的影響。
若假設(shè)圖像輸入特征為Fi(Fi∈RH,W,C,H、W和C分別代表初始特征的高度、寬度和通道),輸出特征為Fo,中間特征為Fm,Mcha為通道注意力參數(shù),Mspa為空間注意力參數(shù),以 °表示矩陣的Hadamard積;則輸入輸出之間的關(guān)系如下:
式中:σ表示sigmoid函數(shù),MLP表示帶有一個(gè)隱藏層的多層感知機(jī),AvgPool表示平均池化,MaxPool表示最大池化,f7×7表示經(jīng)過(guò)7×7的卷積核。
通過(guò)式(3)和式(4)的矩陣乘法可以獲得加權(quán)目標(biāo)特征。第1步使用通道注意力參數(shù)完成對(duì)目標(biāo)特征的篩選,從而更好地提取目標(biāo)的通道信息;將篩選過(guò)的特征經(jīng)過(guò)第2步的空間注意力機(jī)制,得到加權(quán)目標(biāo)特征信息,最終的目標(biāo)特征圖與原圖像的特征圖維度一致。
通道注意力機(jī)制可以選擇性地增強(qiáng)與目標(biāo)跟蹤場(chǎng)景相匹配的特征。當(dāng)目標(biāo)的外觀發(fā)生變化時(shí),通道注意力可以使跟蹤框架更加注重圖像的某些特征,增強(qiáng)算法的魯棒性。但是,單一的通道注意力機(jī)制忽略了全局特征之間相互的位置關(guān)系。作為通道注意力機(jī)制的補(bǔ)充,空間注意力機(jī)制更加關(guān)注圖像的特定位置。兩種注意力機(jī)制相輔相成,從而達(dá)到對(duì)目標(biāo)增強(qiáng)和干擾抑制的效果。
1.4 運(yùn)動(dòng)模型
傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)對(duì)于處理短時(shí)序數(shù)據(jù)具有良好的表現(xiàn)。但是,該方法并不能捕獲長(zhǎng)時(shí)依賴(lài)關(guān)系,因?yàn)楫?dāng)通過(guò)反向傳播計(jì)算梯度時(shí),梯度將呈指數(shù)衰減,這使得神經(jīng)網(wǎng)絡(luò)靠前的卷積層權(quán)重參數(shù)無(wú)法更新。在梯度消失的情況下,RNN會(huì)喪失學(xué)習(xí)遠(yuǎn)處單元信息的能力,導(dǎo)致時(shí)間間隔長(zhǎng)的信息無(wú)法進(jìn)行有效傳遞。
作為RNN的變體,LSTM(如圖4所示)引入了3個(gè)控制門(mén)(分別是遺忘門(mén)、輸入門(mén)和輸出門(mén))以防止網(wǎng)絡(luò)權(quán)重隨時(shí)間傳播而衰減[13]。門(mén)是一種讓信息有選擇通過(guò)的機(jī)制。例如,如果LSTM單元從輸入序列中檢測(cè)到了一個(gè)重要的特征,遺忘門(mén)會(huì)決定它攜帶該信息的程度,因此它可以很容易攜帶一個(gè)長(zhǎng)時(shí)信息,捕獲潛在時(shí)序依賴(lài)。通過(guò)應(yīng)用這種策略,LSTM可以處理長(zhǎng)期依賴(lài)問(wèn)題,有助于遮擋時(shí)目標(biāo)跟蹤丟失的重新捕獲,進(jìn)而提升目標(biāo)跟蹤的穩(wěn)定性。
研究中,目標(biāo)檢測(cè)網(wǎng)絡(luò)提供的目標(biāo)特征信息將送入LSTM中進(jìn)行處理,循環(huán)神經(jīng)網(wǎng)絡(luò)會(huì)計(jì)算出圖像特定區(qū)域?qū)儆谀繕?biāo)或背景的概率,達(dá)到或超過(guò)預(yù)定義閾值的分?jǐn)?shù)將被識(shí)別為確定目標(biāo),可以為其保留外觀特征以供下一次迭代使用。
為了確保在復(fù)雜環(huán)境下目標(biāo)跟蹤的可行性和穩(wěn)定性,本文將融合注意力機(jī)制的YOLO-v3網(wǎng)絡(luò)與LSTM網(wǎng)絡(luò)相結(jié)合形成整體跟蹤框架。在訓(xùn)練階段,使用均方誤差損失函數(shù)來(lái)衡量目標(biāo)的預(yù)測(cè)位置(Bpre)和目標(biāo)的真實(shí)位置(Btar)之間的距離,即
式中:n為批次中訓(xùn)練樣本的數(shù)量。
2 數(shù)據(jù)集選擇及計(jì)算平臺(tái)設(shè)置
為了驗(yàn)證上述跟蹤框架的有效性,本文選擇比較常見(jiàn)的行人、車(chē)輛檢測(cè)數(shù)據(jù)集MOT16、KITTI和TUD-Crossing對(duì)算法進(jìn)行驗(yàn)證。研究中采用Adam優(yōu)化方法將損失函數(shù)值降到最低,在訓(xùn)練開(kāi)始之前,對(duì)數(shù)據(jù)集進(jìn)行了預(yù)處理將圖像縮小至512×512,以提高算法的運(yùn)行速度。由于圖像尺寸減小,設(shè)置訓(xùn)練過(guò)程中的批量大小(batch size)為64,以提高內(nèi)存利用率并減少訓(xùn)練時(shí)間。按照經(jīng)驗(yàn)值,設(shè)置學(xué)習(xí)率(learning rate)初始數(shù)值為0.001,權(quán)重衰減率為0.000 5,動(dòng)量為0.900。在整個(gè)迭代過(guò)程中的迭代周期(epochs)為200次。為了進(jìn)行狀態(tài)估計(jì)和跟蹤管理,LSTM網(wǎng)絡(luò)設(shè)置了300個(gè)隱藏單元。對(duì)于每次迭代,在序列中輸入6幀的長(zhǎng)度進(jìn)行訓(xùn)練。訓(xùn)練和驗(yàn)證工作在配備16 GB內(nèi)存 和NVIDIA GeForce GTX 1080Ti GPU的PC中 的TensorFlow平臺(tái)上完成。
由表2可知:相比于YOLO-v3神經(jīng)網(wǎng)絡(luò),融合了注意力機(jī)制的特征提取網(wǎng)絡(luò)實(shí)現(xiàn)了更好的目標(biāo)識(shí)別效果。添加注意力機(jī)制的YOLO-v3網(wǎng)絡(luò)在運(yùn)行速度基本一致的情況下,平均精確度(mean average precision, mAP)值比原來(lái)提高了1.9個(gè)百分點(diǎn)。因此,注意力機(jī)制可以提高網(wǎng)絡(luò)對(duì)目標(biāo)的檢測(cè)精度,實(shí)現(xiàn)檢測(cè)精度(mAP)和檢測(cè)速度(frame per second, FPS)之間的平衡。
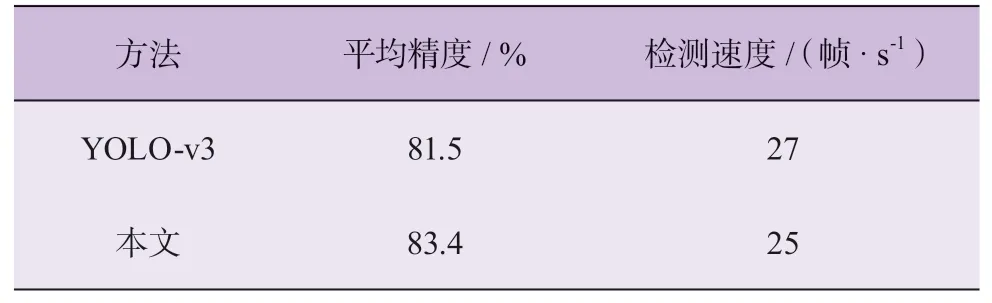
表2 特征提取效果對(duì)比
針對(duì)MOT16數(shù)據(jù)集有較為完善的多目標(biāo)跟蹤效果評(píng)價(jià)體系,具體評(píng)估指標(biāo)包括:多目標(biāo)跟蹤準(zhǔn)確度(MOTA↑),多目標(biāo)跟蹤精確度(MOTP↑),大部分(80%以上)軌跡被跟蹤到的軌跡占比(MT↑),大部分(80%以上)未被跟蹤到時(shí)的軌跡占比(ML↓),誤檢數(shù)(FP↓),漏檢數(shù)(FN↓),同一軌跡目標(biāo)ID值變換次數(shù)(IDS↓)。其中:“↑”表示高值高性能;“↓”表示低值高性能。
3 實(shí)驗(yàn)結(jié)果及分析
表3 給出了本文跟蹤算法和其他已有跟蹤算法(JPDA_m、LMP、AMIR、oICF、STAM、EAMTT)在MOT16數(shù)據(jù)集上表現(xiàn)結(jié)果的對(duì)比。
由表3可知:本文算法在多個(gè)評(píng)估指標(biāo)上都取得了較好的成績(jī)。與其他跟蹤器相比,本文算法獲得了最高的MOTA分?jǐn)?shù)和較高的MOTP分?jǐn)?shù)。這得益于目標(biāo)檢測(cè)框架輸出的精確目標(biāo)位置,因此也驗(yàn)證了所融合的注意力機(jī)制不僅較好地提高了特征提取的精確度,也提高了目標(biāo)跟蹤整體框架在持續(xù)跟蹤過(guò)程中的魯棒性。增加的注意力機(jī)制使目標(biāo)位置定位更加準(zhǔn)確,相應(yīng)的分類(lèi)損失以及置信度損失也會(huì)隨之降低。

表3 不同跟蹤算法的效果對(duì)比
本文算法得到了最高的MT分?jǐn)?shù)和較低的ML分?jǐn)?shù),即使在目標(biāo)運(yùn)動(dòng)過(guò)程中發(fā)生了遮擋現(xiàn)象,跟蹤框架中注意力機(jī)制和運(yùn)動(dòng)模型也可以繼續(xù)保持跟蹤對(duì)象的運(yùn)動(dòng)狀態(tài)。FP表示被認(rèn)為是正例但實(shí)際為負(fù)例的數(shù)據(jù),而FN表示被認(rèn)為是負(fù)例但實(shí)際為正例的數(shù)據(jù),本文算法得到了最低的FN分?jǐn)?shù)和較低的FP分?jǐn)?shù),說(shuō)明識(shí)別目標(biāo)的準(zhǔn)確性較好。本文算法獲得的IDS分?jǐn)?shù)較低,說(shuō)明跟蹤的穩(wěn)定性較好。
在MOT16數(shù)據(jù)集上的部分跟蹤結(jié)果見(jiàn)圖5。
本文所提方法可以在出現(xiàn)大量目標(biāo)的多幀圖像中做到連續(xù)跟蹤,同時(shí)對(duì)場(chǎng)景中出現(xiàn)的部分遮擋和目標(biāo)丟失仍能成功跟蹤。跟蹤框架中的注意力機(jī)制,可以使跟蹤器快速指向關(guān)注的目標(biāo),從而抓住跟蹤任務(wù)的重點(diǎn),當(dāng)有目標(biāo)形變或跟蹤丟失時(shí),該機(jī)制可以幫助跟蹤器快速搜索并檢測(cè)到原有目標(biāo);LSTM網(wǎng)絡(luò)通過(guò)捕獲視頻流中的時(shí)序關(guān)系,實(shí)時(shí)更新目標(biāo)的特征表示和運(yùn)動(dòng)軌跡,從而可以在更長(zhǎng)的時(shí)間序列中維持目標(biāo)的ID值。
圖5 還展示了本文多目標(biāo)跟蹤算法在KITTI和TUD-Crossing數(shù)據(jù)集上的良好測(cè)試效果。由此可知:本文所提跟蹤框架在多目標(biāo)跟蹤問(wèn)題上有著較好的綜合表現(xiàn)。
4 結(jié) 論
本文針對(duì)多目標(biāo)跟蹤問(wèn)題構(gòu)建了一種新的跟蹤框架。借鑒人類(lèi)視覺(jué)系統(tǒng)在多目標(biāo)跟蹤任務(wù)中的優(yōu)異表現(xiàn),在YOLOv3的基礎(chǔ)上融合了注意力機(jī)制,相對(duì)于其他特征提取算法,在基本不影響算法實(shí)時(shí)性的前提下改進(jìn)了對(duì)關(guān)鍵特征的提取篩選能力,有針對(duì)性地提高了整體跟蹤算法可靠度和準(zhǔn)確性,實(shí)現(xiàn)復(fù)雜場(chǎng)景下持續(xù)穩(wěn)定的目標(biāo)跟蹤。
利用LSTM網(wǎng)絡(luò)固有的循環(huán)結(jié)構(gòu),本文的跟蹤框架可以捕獲運(yùn)動(dòng)物體長(zhǎng)時(shí)的運(yùn)動(dòng)特征,并記錄跟蹤過(guò)程中物體的動(dòng)態(tài)外觀和運(yùn)動(dòng)變化,從而有助于長(zhǎng)時(shí)間跟蹤到目標(biāo)。
通過(guò)在目標(biāo)檢測(cè)數(shù)據(jù)集MOT16、KITTI和TUDCrossing上的計(jì)算驗(yàn)證,說(shuō)明了本文所提目標(biāo)跟蹤框架整體上具有很好的表現(xiàn),并將有望應(yīng)用于自動(dòng)駕駛領(lǐng)域。
猜你喜歡
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
中國(guó)衛(wèi)生(2015年9期)2015-11-10 03:11:12
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
中國(guó)衛(wèi)生(2014年3期)2014-11-12 13:18:12
中國(guó)火炬(2014年4期)2014-07-24 14:22:19
